طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیآموزش SELinux در CentOS 7 – بخش اول: مفاهیم پایه
SELinux یا «لینوکس با بهبودهای امنیتی» (Security Enhanced Linux) سازوکار کنترل دسترسی پیشرفتهای است که در اغلب توزیعهای مدرن لینوکس تعبیه شده است. این ساز و کار در ابتدا از سوی سازمان امنیت ملی ایالاتمتحده برای حفاظت از سیستمهای رایانهای در برابر نفوذ بدافزارها و دستکاری دادهها طراحی شد. در طی زمان، SELinux در سطح عمومی نیز منتشر شده است و توزیعهای مختلف لینوکس آن را در کد خود استفاده میکنند.
بسیاری از مدیران سیستم، SELinux را نوعی اقلیم ناشناخته تلقی میکنند. این موضوع میتواند دلهرهآور و در برخی موارد کاملاً سردرگم کننده باشد. با این وجود، یک سیستم SELinux کاملاً پیکربندی شده میتواند ریسکهای امنیتی را تا حدود زیادی کاهش دهد و کسب اطلاع در مورد آن میتواند به عیبیابی پیامهای خطای مرتبط با دسترسی کمک کند. در این راهنما در مورد مفاهیم اساسی SELinux، بستههای آن، دستورات و فایلهای پیکربندی توضیح میدهیم و پیامهای خطایی که هنگام انکار دسترسی نمایش مییابند را مورد بررسی قرار خواهیم داد. همچنین چند نمونه عملی از اجرای عملی SELinux را میبینیم.
دقت کنید که دستورها، بستهها و فایلهای نمایش یافته در این راهنما روی توزیع CentOS 7 تست شدهاند. این مفاهیم روی توزیعهای دیگر نیز به همین ترتیب هستند. در این راهنما دستورها را با حساب کاربری root اجرا میکنیم؛ مگر این که خلاف آن ذکر شده باشد. اگر به حساب کاربری root روی سیستم خود دسترسی ندارید و از حساب دیگری با دسترسیهای sudo استفاده میکنید، باید در ابتدای دستورها از کلیدواژه sudo استفاده کنید.

چرا باید از SELinux استفاده کنیم؟
پیش از آغاز توضیحات، ابتدا میبایست چند مفهوم را درک کنیم. SELinux مفهومی به نام MAC یعنی «کنترل دسترسی اجباری» (Mandatory Access Control) را پیادهسازی کرده است. این مفهوم بر مبنای آن چه از قبل در هر توزیع لینوکس دیگر وجود دارد، یعنی DAC، «کنترل دسترسی اختیاری» (Mandatory Access Control) پیادهسازی شده است. برای درک DAC ابتدا باید با شیوه عملکرد امنیت فایل در لینوکس آشنا باشیم.
در مدل کلاسیک امنیت ما سه نهاد داریم: کاربر (User)، گروه (Group) و دیگران (Other) که به ترتیب با حروف u، g و o نمایش مییابند. این سه نهاد میتوانند ترکیبی از مجوزهای خواندن، نوشتن و اجرا (به ترتیب با حروف اختصاری r، w و x) را روی یک فایل یا دایرکتوری داشته باشند. اگر کاربر به نام jo فایلی را در دایرکتوری home ایجاد کند، دسترسی خواندن/نوشتن را به آن فایل دارد و از این رو جزو گروه jo است. نهاد «Other» احتمالاً به این فایل دسترسی نخواهد داشت. در قطعه کد زیر میتوانیم محتوای فرضی دایرکتوری home را برای کاربر jo ببینیم. لازم نیست این کاربر را ایجاد کنید، چون ما تعداد زیادی از کاربران را در ادامه این راهنما ایجاد خواهیم کرد.
دستوری را مانند زیر اجرا کنید:
دستور فوق خروجی مانند زیر خواهد داشت:
اینک jo میتواند این دسترسی را تغییر دهید. jo میتواند دسترسی به این فایل را به کاربران و گروههای دیگر اعطا کرده (یا محدود سازد) و یا مالک فایل را تغییر دهد. این اقدامات میتوانند باعث شوند که فایل در معرض دستکاری حسابهایی قرار گیرد که نباید به آن دسترسی داشته باشند. Jo میتواند دسترسی فایل را محدود سازد تا امنیت بیشتری ایجاد شود؛ اما این کار اختیاری است. هیچ روشی برای مدیر سیستم وجود ندارد که این رویه را برای همه فایلهای روی سیستم الزامی کند.
مثال دیگری را در نظر بگیرید: وقتی یک پردازش لینوکس اجرا میشود، ممکن است به صورت کاربر root یا حساب دیگری با دسترسیهای superuser اجرا شود. این بدان معنی است که اگر یک هکر کلاهسیاه (بدکار) کنترل اپلیکیشن را به دست گیرد، میتواند از این اپلیکیشن برای دسترسی به همه منابعی که حساب کاربری دسترسی دارد استفاده کند. از آنجا که پردازشها با دسترسی حساب root فعالیت میکنند، یعنی میتوان به همه چیز روی سیستم لینوکس دسترسی داشت.
مثلاً حالتی را تصور کنید که میخواهید کاربران را از اجرای شل اسکریپت در دایرکتوری home باز دارید. این وضعیت در مواردی که توسعهدهندگان روی یک سیستم production مشغول کار هستند، پیش میآید. شما ممکن است بخواهید آنها بتوانند فایلهای log را ببینند؛ اما نمیخواهید از دستورهای su یا sudo استفاده کنند و همچنین نمیبایست هیچ اسکریپتی را از دایرکتوریهای home خود اجرا کنند. این کار به چه روشی میسر است؟
SELinux روشی برای تنظیم دقیق الزامات کنترل چنین دسترسیهایی محسوب میشود. با استفاده از SELinux میتوان تعریف کرد که یک کاربر یا پردازش چه کارهایی میتوانند انجام دهند. بدین ترتیب هر پردازش به دامنه خودش محدود میشود و این پردازش میتواند تنها با انواع خاصی از فایلها و پردازشهای دیگر از دامنههای مجاز تعامل داشته باشد. این کار باعث میشود که هکرها از سوءاستفاده از پردازش برای دسترسی در سطح سیستم باز بمانند.
راهاندازی یک سیستم تست
برای این که مفاهیم مطرح شده را بهتر درک کنیم، باید یک سرور تست بسازیم که هم به عنوان یک وبسرور و هم سرور SFTP عمل میکند. کار خود را با نصب CentOS 7 به صورت بسته کمینه (minimal package) آغاز میکنیم و سپس آپاچی و vsftp را روی سرور نصب میکنیم. با این وجود، هیچ یک از این اپلیکیشنها را پیکربندی نمیکنیم.
همچنین چند حساب کاربری تست در سرور کلود خود ایجاد میکنیم. از این حسابها در موقعیتهای مختلف در سراسر این راهنما استفاده خواهیم کرد. در نهایت بستههای مرتبط با SELinux را نصب خواهیم کرد. این امر جهت تضمین این نکته است که میتوانیم با جدیدترین دستورهای SELinux کار کنیم.
نصب سرویسهای آپاچی و SFTP
ابتدا به صورت کاربر root وارد سرور میشویم و دستور زیر را برای نصب Apache اجرا میکنیم:
خروجی دستور فوق نشان میدهد که این بسته دانلود شده و اجازه نصب از شما میخواهد:
با زدن دکمه y میتوانیم daemon را برای Apache نصب کنیم:
Daemon را به صورت دستی آغاز میکنیم:
با اجرای دستور service httpd status میبینیم که سرویس در حال اجرا است:
سپس اقدام به نصب vsftp میکنیم:
خروجی دستور فوق چیزی شبیه زیر است:
با زدن دکمه y بسته نصب میشود.
سپس از دستور service vsftpd start برای آغاز daemon مربوط به vsftpd استفاده میکنیم. خروجی دستور فوق چیزی شبیه زیر خواهد بود:
نصب بستههای SELinux
چند بسته از سوی SELinux مورد استفاده قرار میگیرند. برخی از آنها به طور پیشفرض نصب میشوند. در ادامه فهرستی از توزیعهای مبتنی بر Red Hat را میبینید:
- policycoreutils: ابزارهایی برای مدیریت SELinux ارائه میکند.
- policycoreutils-python: ابزارهایی برای مدیریت SELinux ارائه میکند.
- selinux-policy: سیاست ارجاع SELinux را ارائه میکند.
- selinux-policy-targeted: سیاست هدفگیری SELinux را ارائه میکند.
- libselinux-utils: ابزارهایی برای مدیریت SELinux ارائه میکند.
- setroubleshoot-server: ابزارهایی برای توصیف پیامهای گزارش حسابرسی ارائه میکند.
- setools: ابزارهایی برای نظارت بر گزارش حسابرسی، کوئری زدن به سیاستها و مدیریت چارچوب فایل ارائه میکند.
- setools-console: ابزارهایی برای نظارت بر گزارش حسابرسی، کوئری زدن به سیاستها و مدیریت چارچوب فایل ارائه میکند.
- mcstrans: ابزارهای برای ترجمه سطوح مختلف قالب از آسان به دشوار ارائه میکند.
برخی از این موارد از قبل روی سیستم نصب شدهاند. برای بررسی این که کدام بستههای SELinux روی سیستم CentOS 7 نصب هستند، میتوانید چند دستور مانند دستور زیر اجرا کنید. پس از عبارت grep باید کلمات جستجوی مختلفی را با حساب کاربری root وارد کنید:
خروجی دستور فوق چیزی شبیه زیر است:
اینک میتوانیم اقدام به نصب بستهها با دستور زیر بکنیم. دقت کنید که yum بستههایی که از قبل داشته باشید را بهروزرسانی میکند. برای این که چنین کاری صورت نگیرد، میتوانید صرفاً بستههایی که روی سیستم خود ندارید را نصب کنید:
اکنون سیستمی داریم که همه بستههای SELinux روی آن بارگذاری شده است. همچنین سرورهای Aapche و SFTP را نیز با پیکربندیهای پیشفرض در حال اجرا داریم. ضمناً چهار حساب کاربری معمولی برای تست کردن علاوه بر حساب کاربری root ایجاد کردهایم.

حالتهای SELinux
اینک نوبت کار با SELinux رسیده است و از این رو کار خود را با بررسی حالتهای SELinux آغاز میکنیم. در هر زمان SELinux میتواند در یکی از حالتهای ممکن زیر باشد:
- Enforcing
- Permissive
- Disabled
SELinux در حالت Enforcing، سیاستهای خود را روی سیستم لینوکس الزام میکند تا مطمئن شود که همه تلاشهای دسترسی غیرمجاز از سوی کاربران و پردازشها انکار میشود. انکار دسترسی در فایلهای گزارش مربوطه نیز نوشته میشود. در ادامه به بررسی بیشتر سیاستهای SELinux و گزارشهای حسابرسی خواهیم پرداخت.
حالت Permissive را میتوان نوعی حالت نیمه فعال دانست. در این حالت، SELinux سیاستهای خود را الزام نمیکند و بنابراین هیچ نوع دسترسی انکار نمیشود. با این وجود، هر گونه تخطی از سیاستها در گزارشهای حسابرسی ثبت خواهد شد. این روشی عالی برای تست SELinux پیش از بردن آن به حالت الزامی است. حالت disabled از نامش مشخص است که باعث میشود، سیستم از وضعیت امنیتِ بهبود یافته خارج شود.
بررسی حالتها و وضعیتهای SELinux
میتوان با اجرای دستور getenforce به بررسی حالت کنونی SELinux پرداخت:
SELinux در حال حاضر باید غیر فعال باشد و از این رو خروجی مانند زیر خواهد بود:
همچنین میتوان دستور sestatus را اجرا کرد:
زمانی که SELinux غیر فعال باشد، خروجی به صورت زیر خواهد بود:
فایل پیکربندی SELinux
فایل پیکربندی اصلی برای SELinux در مسیر /etc/selinux/config قرار دارد. میتوان دستور زیر را برای نمایش محتوای آن اجرا کرد:
خروجی دستور فوق به صورت زیر خواهد بود:
در این فایل دو دایرکتیو وجود دارند. دایرکتیو SELinux که حالت آن را مشخص میکند و سه مقدار ممکن دارد که قبلاً بررسی کردیم.
دایرکتیو SELINUXTYPE سیاستی که استفاده خواهد شد را تعیین میکند. مقدار پیشفرض به صورت targeted است. SELinux در سیاست targeted، امکان سفارشیسازی و تنظیم دقیق مجوزهای کنترل دسترسی را ارائه میکند. مقدار ممکن دیگر «MLS» یا همان «امنیت چند سطحی» (multilevel security) است که حالت پیشرفتهای برای حفاظت محسوب میشود. ضمناً در نوع MLS باید بستههای دیگری را نیز نصب کرد.

فعالسازی و غیر فعالسازی SELinux
فعالسازی SELinux نسبتاً ساده است؛ اما غیر فعالسازی آن چنین نیست و باید در فرایندی دومرحلهای صورت بگیرد. ما فرض میکنیم که SELinux در حال حاضر غیر فعال است و شما همه بستههای آن را در مراحل قبل نصب کردهاید.
در گام نخست باید فایل etc/selinux/config/ را ویرایش کنیم تا دایرکتیو SELinux به حالت Permissive برود.
محتوای فایل را به صورت زیر تنظیم کنید:
تنظیم SELinux در حالت Permissive در ابتدا امری ضروری است، زیرا پیش از آن که از حالت enforced در SELinux استفاده کنیم، هر فایل در سیستم باید برچسب زمینهای خاص خود را داشته باشد. در صورتی که همه فایلها دارای برچسب مناسب نباشند، ممکن است پردازشهایی که در دامنههای محدودشده اجرا میشوند، از کار بیفتند، زیرا نمیتوانند به فایلها در چارچوب (context) صحیح دسترسی یابند. این مسئله میتواند منجر به مشکلات boot شود و سیستم نتواند آغاز به کار بکند یا با خطاهایی همراه باشد. دو مفهوم چارچوب (context) و دامنه را در ادامه توضیح خواهیم داد.
اینک دستور ریبوت را اجرا میکنیم:
در فرایند ریبوت همه فایلهای موجود در سرور با چارچوب SELinux برچسبگذاری میشوند. از آنجا که سیستم در حالت permissive است، SELinux خطاها و انکار دسترسیها را گزارش میکند؛ اما آنها را متوقف نمیسازد.
بار دیگر به عنوان کاربر root وارد سیستم شوید. سپس در محتوای فایل var/log/messages/ به دنبال رشته «SELinux is preventing» بگردید.
اگر خطایی گزارش نشده باشد، میتوانیم با امنیت به مرحله بعد برویم. با این وجود، جستجو در فایل /var/log/messages به دنبال عبارت «SELinux» نیز ایده خوبی محسوب میشود. ما در سیستم خود دستور زیر را اجرا کردیم:
این دستور پیامهای خطای مرتبط با دسکتاپ GNOME را نشان میدهد که در حال اجرا است. این امر زمانی رخ میدهد که SELinux یا در حالت غیر فعال و یا permissive باشد:
این نوع خطاها ایرادی ندارند.
در مرحله دوم، باید فایل پیکربندی را ویرایش کنیم تا دایرکتیو SELINUX را در فایل /etc/sysconfig/selinux از حالت permissive به enforcing تغییر دهیم:
سپس سرور را بار دیگر ریبوت میکنیم:
زمانی که سرور دوباره روشن شد، میتوانیم با اجرای دستور sestatus وضعیت SELinux را بررسی کنیم. اینک باید جزییات در مورد سرور مشاهده کنیم:
فایل var/log/messages/ را بررسی کنید:
باید خطایی وجود نداشته باشد. خروجی چیزی شبیه زیر خواهد بود:
بررسی حالتها و وضعیتهای SELinux (بار دیگر)
میتوانید دستور getenforce را برای بررسی حالت کنونی SELinux اجرا کنید:
اگر سیستم در حالت enforcing باشد، خروجی به صورت زیر خواهد بود:
در صورتی که SELinux غیر فعال شده باشد، با خروجی زیر مواجه خواهید شد:
میتوانیم با اجرای دستور sestatus تصویر بهتری از سیستم داشته باشیم:
اگر SELinux غیر فعال نشده باشد، خروجی وضعیتهای کنونی، حالت کنونی، حالت تعریف شده در فایل پیکربندی و نوع سیاست را نشان میدهد:
وقتی SELinux غیر فعال باشد، خروجی به صورت زیر است:
همچنین میتوان با استفاده از دستور setenforce به طور موقت بین حالتهای enforcing و permissive سوئیچ کرد (دقت کنید که وقتی SELinux غیر فعال باشد، نمیتوانیم دستور setenforce را اجرا کنیم.
ابتدا حالت SELinux را در سیستم CentOS 7 از حالت enforcing به permissive تغییر میدهیم:
با اجرای دستور sestatus مشخص میشود که حالت کنونی از حالت تعریف شده در فایل پیکربندی متفاوت است:
با دستور زیر به حالت enforcing بازگردید:
سیاست SELinux

مهمترین بخش موتور امنیت SELinux، سیاست (policy) آن است. منظور از سیاست چنان که از نامش مشخص است، مجموعهای از قواعد است که امنیت و دسترسیها به همه چیز را روی سیستم تعیین میکنند. زمانی که میگوییم «همه چیز»، منظور ما کاربران، نقشها، پردازشها و فایلها است. این سیاست است که شیوه ارتباط هر یک از این نهادها با همدیگر را تعیین میکند.
برخی اصطلاحات پایه
برای درک سیاست باید برخی اصطلاحات پایه را یاد بگیریم. در ادامه وارد جزییات خواهیم شد؛ اما در این بخش مقدمه کوتاهی ارائه میکنیم. سیاست SELinux دسترسی کاربر به نقشها، دسترسی نقش به دامنهها و دسترسی دامنهها به نوعها را تعیین میکند.
کاربران (Users)
SELinux مجموعهای از کاربران پیشساخته دارد. هر کاربر معمولی لینوکس به یکی از کاربران SELinux نگاشت میشود.
در لینوکس این کاربر است که یک پردازش را اجرا میکند. این وضعیت میتواند به این صورت باشد که کاربری به نام jo یک سند را در ویرایشگر vi باز کند یا یک حسابِ سرویس اقدام به اجرای daemon مربوط به httpd بکند. در دنیای SELinux هر پردازش (یک daemon یا برنامه اجرایی) به نام «فاعل» (subject) نامیده میشود.
نقشها (Roles)
نقش مانند دروازهای است که بین کاربر و پردازش قرار میگیرد. نقش تعریف میکند که کدام کاربران میتوانند به یک پردازش دسترسی داشته باشند. نقشها مانند گروهها نیستند؛ بلکه شبیه فیلتر هستند. یعنی یک کاربر میتواند در هر زمان یک نقش را بر عهده بگیرد و یا نقشی به وی اعطا شود. تعریف نقش در سیاست SELinux مشخص میکند که کدام کاربران به آن نقش دسترسی داشته باشند. همچنین مشخص میسازد که کدام دامنههای پردازش به خود نقش دسترسی دارند. نقشها به این دلیل تعریف شدهاند که SELinux مفهومی به نام «کنترل دسترسی مبتنی بر نقش» (Role Based Access Control) یا RBAC را پیادهسازی کند.
فاعلها و اشیا
یک فاعل (subject) پردازشی است که میتواند به طور بالقوه روی یک شیء یا مفعول (object) تأثیر بگذارد.
منظور از شیء در SELinux هر چیزی است که میتوان روی آن کاری انجام داد. این چیز میتواند یک فایل، دایرکتوری، یک پورت یا سوکت tcp، کرسر، یا شاید یک سرور X باشد. این اقدامها که فاعل میتواند روی یک شیء انجام دهد، مجوزهای فاعل (permissions) نام دارند.
دامنهها برای فاعلها
دامنه (domain) چارچوبی است که یک فاعل SELinux درون آن میتواند اجرا شود. این چارچوب (context) مانند یک پوششی پیرامون فاعل را احاطه کرده است. این چارچوب است که تعیین میکند هر پردازش چه کار میتواند انجام بدهد یا ندهد. برای نمونه، دامنه تعریف میکند که چه فایلها، دایرکتوریها، لینکها، دستگاهها یا پورتهایی در دسترس فاعل هستند.
انواع مختلف برای اشیا
یک نوع (type) چارچوبی برای زمینه فایل است که مقصود فایل را تعیین میکند. برای مثال، چارچوب یک فایل میتواند تعیین کند که یک صفحه وب است یا این که به دایرکتوری /etc تعلق دارد و یا این که مالک فایل یک کاربر SELinux خاص است. چارچوب فایل، به زبان SELinux، نوعِ آن خوانده میشود.
سیاست SELinux چیست؟
سیاست SELinux دسترسی کاربر به نقشها، دسترسی نقشها به دامنهها و دسترسی دامنهها به نوعها را تعیین میکند. ابتدا کاربر برای ورود به یک نقش، مجوز مییابد و سپس نقش باید اجازه دسترسی به دامنهای را پیدا کند. دامنه به نوبه خود محدود شده است تا تنها به نوعهای خاصی از فایلها دسترسی داشته باشد.
خود سیاست شاخهای از قواعدی است که تعیین میکند کدام کاربران میتوانند کدام نقشها را انتخاب کنند و این نقشها مجوز دسترسی به کدام دامنهها را دارند. این دامنه به نوبه خود میتواند به نوعهای خاصی دسترسی داشته باشد. در تصویر زیر این مفهوم نمایش یافته است:
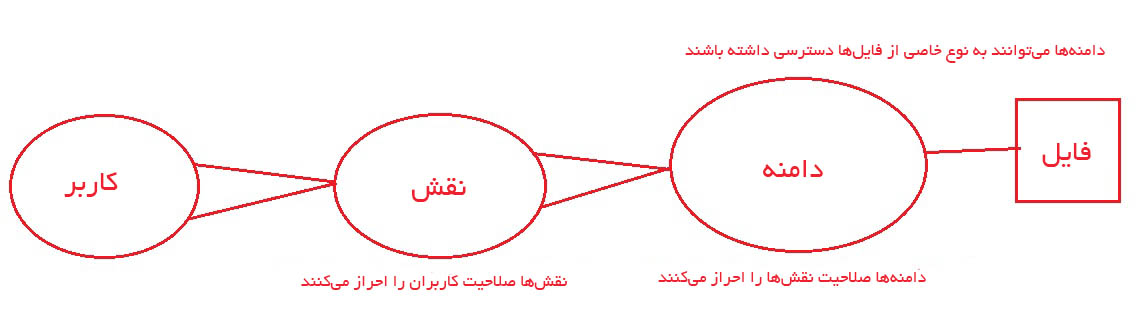
نکتهای که در خصوص اصطلاحات مطرح شده باید اشاره بکنیم این است که یک پردازش که در دامنه خاصی اجرا میشود، میتواند تنها عملیات خاصی را روی انواع خاصی از شیءها انجام دهد که این وضعیت Type Enforcement یا به اختصار TE نامیده میشود.
اگر به موضوع سیاستها بازگردیم، پیادهسازی سیاست SELinux نیز به طور پیشفرض به صورت targeted است. اگر به خاطر داشته باشید در فایل پیکربندی SELinux که قبلاً دیدیم، دایرکتیو SELINUXTYPE باید به صورت targeted تعیین شده باشد. معنی این حرف آن است که SELinux به طور پیشفرض تنها محدود به پردازشهای خاصی در سیستم است (یعنی تنها پردازشهایی که هدفگیری شدهاند). پردازشهایی که هدفگیری نشدهاند، در دامنههای نامحدود فعالیت میکنند.
جایگزین حالت فوق مدل «انکار به طور پیشفرض» است که در آن هر پردازشی انکار میشود؛ مگر این که از سوی سیاست خاصی تأیید شده باشد. چنین حالتی بسیار امن خواهد بود؛ اما همزمان به این معنی است که توسعهدهندهها باید همه مجوزهایی احتمالی که هر پردازشی ممکن است زمانی روی هر شیء احتمالی ممکن است نیاز داشته باشد را از قبل پیشبینی کرده باشند. رفتار پیشفرض SELinux تنها به پردازشهای خاصی مربوط است.
رفتار سیاست SELinux
سیاست SELinux چیزی نیست که جایگزین امنیت DAC کلاسیک شود. اگر یک قاعده DAC دسترسی یک کاربر را به فایلی محدود سازد، سیاست SELinux نمیتواند چنین مجوزی بدهد، زیرا خط نخست دفاعی قبلاً دسترسی را محدود کرده است. تصمیمات امنیتی SELinux تنها پس از این که امنیت DAC ارزیابی شدند، مورد استفاده قرار میگیرند.
زمانی که یک سیستم با SELinux فعال آغاز به کار میکند، این سیاست در حافظه بارگذاری میشود. سیاست SELinux در قالب ماژولار است و بسیار شبیه ماژولهای کرنل است که در زمان بوت شدن بارگذاری میشوند. از طرفی نیز همانند ماژولهای کرنل میتوانند به صورت دینامیک در زمان اجرا به حافظه اضافه یا حذف شوند. انباره سیاست (policy store) که از سوی SELinux استفاده میشود، ماژولهایی که بارگذاری شدهاند را ردگیری میکند. دستور sestatus نام انبار سیاست را نشان میدهد. دستور semodule –l ماژولهای سیاست SELinux را که در حال حاضر در حافظه بارگذاری شدهاند نشان میدهد.
برای درک عملی، دستور semodule را اجرا میکنیم:
خروجی چیزی شبیه زیر خواهد بود:
دستور semodule میتواند در تعدادی از وظایف دیگر مانند نصب، حذف، بارگذاری مجدد، ارتقا، فعالسازی و غیر فعالسازی ماژولهای سیاست SELinux مورد استفاده قرار گیرد.
احتمالاً اکنون علاقهمند هستید که بدانید فایلهای ماژول در کجا قرار میگیرند. اغلب توزیعهای مدرن شامل نسخههای باینری ماژولها به عنوان بخشی از بستههای SELinux هستند. فایل سیاست دارای پسوند.pp است. در CentOS 7 میتوانیم دستور زیر را اجرا کنیم:
فهرستی که در خروجی نمایش مییابد تعدادی از فایلهای با پسوند.pp را نشان میدهد. اگر به دقت نگاه کنید متوجه میشوید که به اپلیکیشنهای مختلف تعلق دارند:
با این وجود، فایلهای pp. از سوی انسان قابل خواندن نیستند.
طرز کار ماژول سازی SELinux چنین است که وقتی سیستم بوت میشود، ماژول سیاست در آنچه که به نام سیاست فعال (active policy) مینامیم ترکیب میشود. سپس این سیاست در حافظه بارگذاری میشود. نسخه باینری ترکیب شده از سیاست بارگذاری شده را میتوانید در دایرکتوری etc/selinux/targeted/policy/ مشاهده کنید:
بدین ترتیب سیاست فعال دیده میشود:
تغییر تنظیمات بولی SELinux
![]()
با این که نمیتوان فایلهای ماژول سیاست را خواند، اما روش آسانی برای تغییر دادن تنظیمات آن وجود دارد. این کار از طریق مقادیر بولی SELinux صورت میپذیرد.
برای مشاهده طرز کار آن باید دستور semanage boolean –l را اجرا کنید:
این دستور سوئیچهای مختلفی که میتوان روش یا خاموش کرد را نشان میدهد و همچنین کار هر یک و وضعیت کنونیشان نمایش مییابد:
میتوان دید که گزینه نخست به daemon FTP امکان میدهد که به دایرکتوریهای home کاربر دسترسی داشته باشند. این تنظیمات در زمان کنونی خاموش هستند.
برای تغییر دادن هر یک از تنظیمات میتوان از دستور setsebool استفاده کرد. به عنوان مثال فرض کنید، وضعیت دسترسی نوشتن FTP ناشناس را بررسی کنیم:
این دستور نشان میدهد که سوئیچ در حال حاضر خاموش است:
سپس مقدار بولی را تغییر میدهیم تا فعال شود:
اگر یک بار دیگر این مقدار را بررسی کنیم، تغییر را مشاهده میکنیم:
مقادیر بولی تغییر یافته دائمی نیستند. پس از ریبوت این تغییرات به حالت پیشین خود باز میگردند. برای این که تغییرات دائمی شوند، باید از سوئیچ P- در دستور setsebool استفاده کنید.
نتیجهگیری
در این بخش از راهنمای SELinux تلاش کردیم تا برخی مفاهیم پایه آن را توضیح دهیم. دیدیم که SELinux میتواند باعث امنیت سیستم شود. در ادامه با روش فعالسازی آن و حالتهای اجراییاش آشنا شدیم. همچنین موضوع سیاستهای SELinux را نیز بررسی کردیم.
- برای مطالعه بخش دوم این مطلب میتوانید از این لینک استفاده کنید: آموزش SELinux در CentOS 7 — بخش دوم: فایل ها و پردازش ها
منبع: فرادرس
بهینه سازی سرعت و عملکرد حافظه های SSD — به زبان ساده
با این که حافظه های SSD سرعتهای بسیار بالایی ارائه میکنند؛ اما اغلب کاربران ممکن است از درایوهایی استفاده کنند که به طور صحیحی پیکربندی نشده است و از این موضوع نیز بیخبر باشند. دلیل این مسئله آن است که درایوهای SSD از ابتدا با تنظیمات بهینه عرضه نمیشوند. پیش از آن که درایو به بیشینه عملکردی خود برسد، کاربر باید چندین کار آمادهسازی و تنظیم را روی آن انجام دهد. به طور خاص حالت AHCI در تنظیمات BIOS/EFI باید مورد استفاده قرار گیرد و درایورهای مناسب AHCI باید نصب شوند. به علاوه، باید فیرمویر SSD به جدیدترین نسخه ارتقا یابد تا تأیید شود که درایورهای صحیحی نصب شدهاند.
برخی اصطلاحهای فنی
در این بخش برخی از اصطلاحهای فنی در مورد SSD را معرفی میکنیم.
Garbage Collection
به وسیله گردآوری موارد بیاستفاده میتوان جلوی ازکارافتادن درایوهای SSD را گرفت. دلیل ضرورت این کار آن است که درایوهای SSD نمیتوانند بلوکهای حافظه را صرفاً با نوشتن دادههای بیمعنی مانند روشی که دیسکهای قدیمی مبتنی بر پلاتر انجام میدادند، پاک کنند. پیش از آن که کنترلر SSD بتواند یک بلوک را بنویسد، باید آن را بخواند تا بتواند برای حذف نشانهگذاری کند. این فرایند دومرحلهای خواندن-نوشتن برای پاک کردن سلولهای فلش (flash) ممکن است زمان زیادی طول بکشد.
چاره کار استفاده از روشهای Garbage collection در پسزمینه از طریق خواندن و نشانهگذاری بلوکها به صورت پاک شده در زمان بیکاری رایانه است. این فرایند به نام idle garbage collection نیز شناخته میشود که مستقل از سیستم عامل فعالیت میکند. بنابراین روی ویندوز، لینوکس و همچنین مک کار میکند. فعالسازی garbage collection در پسزمینه، صرفاً نیازمند این است که از حساب خود خارج شده و رایانه را برای چند ساعت در حال اجرا حفظ کنید.

TRIM
TRIM میتواند مشکلات پاک کردن حافظه فلش را با کارکرد در سطح سیستم عامل رفع کند. به جای این که کنترلر SSD تعیین کند که کدام بلوکها میتواند پاک شوند، سیستم عامل این نقش را بر عهده میگیرد. متأسفانه TRIM به طور کامل به سازگاری درایور و سیستم عامل وابسته است. بنابراین اگر مشکلی در سیستم عامل یا درایورهای نصب شده رخ بدهد، TRIM نمیتواند وظیفه خود را انجام دهد.
تمایز BIOS/EFI
«سیستم پایه ورودی خروجی» (BIOS) در سالهای اخیر به وسیله «رابط فیرمویر بسط یافته» (EFI) در رایانههای جدید، جایگزین شده است. با این وجود از نظر کارکردی میتوان همچنان با هر دو سیستم به روش یکسانی تعامل داشت.
فعالسازی AHCI در BIOS/EFI
در این بخش روش فعالسازی AHCI را در هر دو محیط BIOS و EFI توضیح میدهیم.
فعالسازی AHCI در محیط BIOS
تفاوت زیادی بین فعالسازی ACHI در یک محیط EFI با BIOS وجود ندارد. با این وجود، به دلیل این که محیطهای پیش از بوت مختلف دارای طراحی و اصطلاحهای متفاوتی هستند، در این زمینه تنها میتوان راهنماییهای کلی ارائه کرد. تصاویری که در ادامه ارائه شدهاند ممکن است به طور کامل با آن چه روی سیستم خود مشاهده میکنید، مطابقت نداشته باشند. برای فعالسازی AHCI ابتدا باید کارهای زیر را انجام دهیم:
- روی سیستم خود کلید F مربوطه برای ورود به BIOS/EFI را بزنید. این کلید بسته به تولیدکنندههای مادربورد متفاوت است. در اغلب موارد این کلید یکی از موارد F8، F10، F12 یا Del است.
- زمانی که وارد BIOS یا EFI شدید، به دنبال عبارتهایی مانند «hard drive» یا «storage» بگردید و روی آن کلیک کنید.
- این تنظیمات را از IDE یا RAID به AHCI تغییر دهید.
در این مرحله به طور معمول باید کلید F10 را بزنید تا تنظیمات ذخیره شده و از محیط BIOS/EFI خارج شوید. با این حال ممکن است در مورد خاص شما، این کلید فرق داشته باشد؛ در هر حال مطمئن شوید که تنظیمات ذخیره شده و سپس خارج شوید.
ویندوز
اگر درایورهای AHCI را در ویندوز نصب کرده باشید در این صورت در زمان بوت شدن رایانه با صفحه آبی مرگ مواجه میشود.. ویندوز 7 نخستین نسخه از ویندوز است که دستور TRIM را دارد و نسخههای قبلی ویندوز چنین امکانی نداشتند.
هشدار: اگر در ابتدای راهاندازی رایانهتان آن را در حالت IDE قرار دهید، فعالسازی ACHI در ویندوز موجب میشود که در هنگام بوت شدن، با صفحه آبی مرگ روبرو شوید. خوشبختانه مایکروسافت فرایند نصب آن را کاملاً ساده کرده است. کافی است این بسته اصلاحی (+) را از وبسایت مایکروسافت دانلود کرده و نصب کنید.
Mac OSX
در سیستمهای OS X قدیمیتر از Lion، باید TRIM را به صورت دستی نصب کنید. در این لینک (+) میتوانید راهنماییهایی در این خصوص ملاحظه کنید.
لینوکس
لینوکس از سال 2008 TRIM را پیادهسازی کرده است. شما میتوانید با پیروی از این دستورالعملها (+) آن را نصب کنید.
در تصویر زیر نمونهای از محیط پیش از بوت EFI را ملاحظه میکنید:
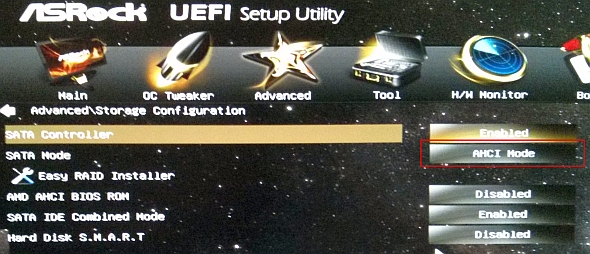
در تصویر زیر نیز محیط پیش از بوت BIOS را میبینید:
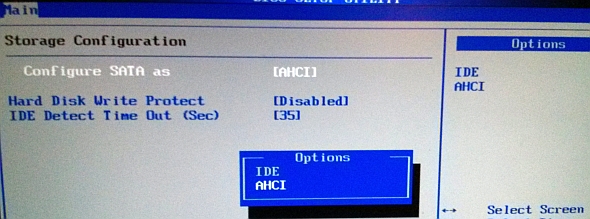
دانلود درایور صحیح برای TRIM
TRIM باعث بهبود درایو شما میشود و از لنگ زدن و کند شدن آن جلوگیری میکند. برخلاف درایوهای پلاتر، درایوهای SSD دادههایی را که برای حذف نشانهگذاری شدهاند، بازنویسی نمیکنند. چنین سلولهایی به نام سلول «کثیف» (dirty) نامیده میشوند. پیش از آن که بتوان در این سلولهای کثیف، دادهای را نوشت، باید یک دستور TRIM برای پاک کردن اجرا کرد. زمانی که TRIM به طور صحیحی کار میکند، کنترلر SSD مطمئن میشود که بلوکهای بیاستفاده پاک شدهاند و در نتیجه منجر به تجربه استفاده بدون توقف میشود. با این وجود، اگر یک مشکل فنی یا خطای پیکربندی وجود داشته باشد، TRIM ممکن است عمل نکند و فضای درایو پر شود. در چنین مواردی درایو به شدت کند میشود.
خوشبختانه خصوصیت garbage collection در پسزمینه تقریباً روی همه کنترلرهای دارای فیرمویر مدرن تعبیه و جایگزین TRIM ناقص شده است. گرچه درایوهای SSD مدرن غیر اینتل garbage collection را به عنوان یک ویژگی استاندارد عرضه کردهاند؛ با این وجود، همه درایوها از garbage collection در پسزمینه استفاده نمیکنند. فعالسازی garbage collection تنها نیازمند این است که از سیستم خارج شد و آن را در حالت روشن بگذارید بماند.
به طور کلی، متخصصان پیشنهاد میکنند برای تراشههای اینتل درایورهای ذخیرهسازی رسمی اینتل (+) و برای تراشههای AMD از درایورهای مایکروسافت استفاده شود. برای تضمین این که درایورهای مایکروسافت نصب شدهاند میتوانید در ویندوز به بخش Device Manager رفته و از قسمت «Disk Drives» گزینه SSD را انتخاب کنید. سپس کافی است درایورها را بهروزرسانی کنید. ویندوز به طور خودکار آنها را نصب میکند.
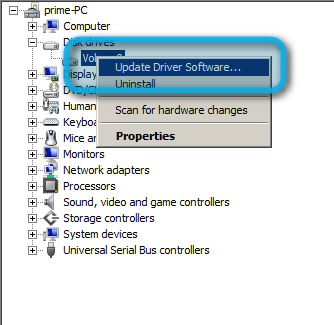
اطمینان از پشتیبانی تراشهها از TRIM
متأسفانه همه تراشهها به خصوص درون آرایه RAID از TRIM پشتیبانی نمیکنند. تراشههای سری 7 اینتل معمولاً از TRIM در هر نوع RAID پشتیبانی میکنند. با این وجود تراشههای سری 6 پشتیبانی غیر رسمی دارند. به علاوه لینوکس علیرغم برخی مشکلات، از TRIM مبتنی بر نرمافزار در آرایههای RAID پشتیبانی میکند.
بهروزرسانی فیرمویر SSD
اغلب درایوهای SSD وقتی تازه به بازار ارائه شده بودند، از باگهای مختلفی رنج میبردند. خوشبختانه این باگها با بهروزرسانیهای مکرر به شکل وصلههای فیرمویر رفع شدند. این وصلهها یا به صورت تخریبی بودند که باعث میشدند همه دادههای روی درایو پاک شود و یا غیر تخریبی بودند. در هر حالت شما باید پیش از بهروزرسانی فیرمویر از دادههای خود پشتیبان تهیه کنید.
برای تهیه پشتیبان از دادهها، کافی است آنها را با استفاده از ابزاری مانند Clonzilla به یک درایو بیرونی کپی کنید. برای کسب اطلاعات بیشتر در این خصوص میتوانید از این «راهنمای پشتیبانگیری» استفاده کنید.
با این که بهروزرسانی فیرمویر SSD ممکن است با خطراتی همراه باشد؛ اما میتواند از بروز مشکلاتی در آینده جلوگیری کند. در هر صورت پیش از بهروزرسانی باید به طور کامل تحقیق کنید و دریایید که کدام درایوها نیازمند بهروزرسانی فیرمویر هستند.
درایوهای ارزانقیمت نخرید

برخی درایوهای SSD ارزانقیمت هر چه قدر هم که مراقب باشید و فیرمویرشان را بهروزرسانی کنید باز از کار میافتند. درایوهایی که از نسل دوم کنترلرها به نام Sandforce استفاده میکنند در اغلب موارد از کار میافتند. خوشبختانه درایوهای SSD مدرن مشکلات کمتری نسبت به مدلهای اولیه دارند. با این وجود، باید هنگام خرید SSD به طور کامل تحقیق و نظرات کاربران را مطالعه کنید.
سخن پایانی
عملکرد SSD به طور پیشفرض از سوی کارخانه بهینهسازی نشده است و شما باید برخی اقدامات ضروری را در این خصوص انجام دهید. ابتدا تلاش کنید که AHCI را در BIOS/EFI خود فعال کنید. سپس بررسی کنید که تراشه (مادربورد) شما با TRIM سازگاری دارد یا نه. سوم برسی کنید که آیا درایو نیازمند بهروزرسانی فیرمویر است یا نه. شما نیز میتوانید دیدگاهها و پیشنهادهای خود را در بخش نظرات با ما و دیگر خوانندگان فرادرس در میان بگذارید.
منبع: فرادرس
آموزش Node.js: آشنایی با npm و npx — بخش پنجم
در بخش قبلی این سری مقالات آموزش Node.js به توضیح برخی ویژگیهای فایل Package.json پرداختیم. اینک به توضیح npm و npx میپردازیم. برای مطالعه بخش قبلی میتوانید به لینک زیر مراجعه کنید:
برای دیدن آخرین نسخه از پکیج npm نصب شده شامل وابستگیهایش از دستور زیر استفاده کنید:
npm list
مثال:
❯ npm list /Users/flavio/dev/node/cowsay └─┬ cowsay@1.3.1 ├── get-stdin@5.0.1 ├─┬ optimist@0.6.1 │ ├── minimist@0.0.10 │ └── wordwrap@0.0.3 ├─┬ string-width@2.1.1 │ ├── is-fullwidth-code-point@2.0.0 │ └─┬ strip-ansi@4.0.0 │ └── ansi-regex@3.0.0 └── strip-eof@1.0.0
همچنین میتوانید فایل package-lock.json را باز کنید، اما نیازمند کمی کاوش است. دستور npm list –g نیز کار فوق را اما منحصراً در مورد پکیجهای سراسری انجام میدهد.
برای دریافت پکیجهای سطح بالا، یعنی آنها را که به npm گفتهاید نصب کند و در package.json لیست شدهاند، دستور زیر را اجرا کنید:
npm list --depth=0
خروجی:
❯ npm list --depth=0 /Users/flavio/dev/node/cowsay └── cowsay@1.3.1
میتوان نسخه یک پکیج خاص را از طریق تعیین نام آن به دست آورد:
❯ npm list cowsay /Users/flavio/dev/node/cowsay └── cowsay@1.3.1
این دستور در مورد وابستگیهای پکیجهای نصب شده نیز اجرا میشود:
❯ npm list minimist /Users/flavio/dev/node/cowsay └─┬ cowsay@1.3.1 └─┬ optimist@0.6.1 └── minimist@0.0.10
اگر میخواهید ببینید آخرین نسخه پکیج روی یک ریپازیتوری چیست دستور زیر را اجرا کنید:
npm view [package_name] version
خروجی:
❯ npm view cowsay version
نصب یک نسخه قدیمیتر از یک پکیج npm
نصب نسخههای قدیمیتر از یک پکیج npm در برخی موارد میتواند برای حل یک مشکل تطبیقپذیری مناسب باشد. شما می توانید یک نسخه قدیمی از یک پکیج npm را با استفاده از ساختار @ نصب کنید:
npm install <package>@<version>
مثال:
npm install cowsay
دستور فوق نسخه 1.3.1 (که آخرین نسخه در زمان نگارش این مقاله است) را نصب میکند، برای نصب نسخه 1.2.0 میتوانید از دستور زیر استفاده کنید:
npm install cowsay@1.2.0
همین کار را میتوان با استفاده از پکیجهای سراسری نیز اجرا کرد:
npm install -g webpack@4.16.4
همچنین ممکن است بخواهید همه نسخههای قبلی یک پکیج را نصب کنید. این کار با اجرای دستور زیر ممکن است:
npm view <package> versions
خروجی:
❯ npm view cowsay versions [ '1.0.0', '1.0.1', '1.0.2', '1.0.3', '1.1.0', '1.1.1', '1.1.2', '1.1.3', '1.1.4', '1.1.5', '1.1.6', '1.1.7', '1.1.8', '1.1.9', '1.2.0', '1.2.1', '1.3.0', '1.3.1' ]
بهروزرسانی همه وابستگیهای Node به آخرین نسخهها
هنگامی که یک پکیج را با استفاده از دستور <npm install <packagename نصب میکنید، جدیدترین نسخههای ممکن پکیج دانلود میشوند و در پوشه node_modules قرار میگیرند و یک مدخل متناظر به فایل package.json و package-lock.json اضافه میشود که در پوشه جاری حضور دارند.
npm وابستگیها را محاسبه کرده و جدیدترین نسخههای آنها را نیز نصب میکند. فرض کنید میخواهید پکیج cowsay را نصب کنید که یک ابزار جالب خط فرمان است که امکان ایجاد شکل یک «گاو» در حال بیان یک پیام را میدهد. هنگامی که دستور npm install cowsay را اجرا کنید، مدخل زیر به فایل package.json اضافه خواهد شد:
و در ادامه خروجی package-lock.json را مشاهده میکنید که برای وضوح بیشتر در آن وابستگیهای تودرتو حذف شدهاند:
اینک این 2 فایل به ما میگویند که نسخه نصب شده cowsay 1.3.1 است. قاعده ما برای بهروزرسانی به صورت 1.3.1^ است که بر اساس قواعد نسخهبندی npm بدان معنی است که میتواند انتشارهای فرعی و وصلهها یعنی 0.13.1، 0.14.0 و غیره را بهروزرسانی کند.
اگر یک انتشار فرعی یا وصله وجود داشته باشد و دستور npm update را وارد کنیم، نسخه نصبی بهروزرسانی میشود و فایل package-lock.json با نسخه جدید پر میشود، اما فایل package.json بیتغییر باقی میماند. برای یافتن انتشارهای جدید پکیجها میتوانید دستور npm outdated را وارد کنید.
در ادامه فهرستی از پکیجهای تاریخ گذشته را در یک ریپازیتوری که اخیراً بهروزرسانی نشدهاند مشاهده میکنید:
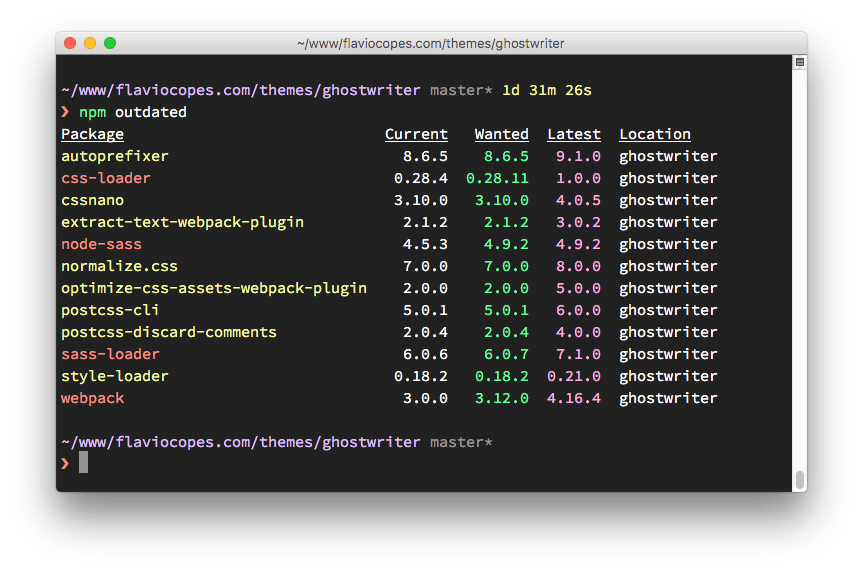
برخی از این بهروزرسانیها انتشار اصلی هستند. اجرای دستور npm update نسخه این موارد را بهروزرسانی نخواهد کرد. انتشارهای اصلی هرگز به این روش بهروزرسانی نمیشوند، چون آنها (برحسب تعریف) تغییرهای گسستهای ایجاد میکنند و npm میخواهید شما را در برابر بروز مشکلات محافظت کند.
برای بهروزرسانی یک نسخه اصلی از همه پکیجها، باید پکیج npm-check-updates را به صورت سراسری نصب کنید:
npm install -g npm-check-updates
و سپس دستور زیر را اجرا کنید:
ncu –u
دستور فوق همه نسخههای موجود در فایل package.json را به dependencies و devDependencies بهروزرسانی میکند به طوری که npm میتواند نسخه جدید اصلی را نصب کند.
اکنون آماده هستید که بهروزرسانی را اجرا کنید:
npm update
اگر پروژه را بدون وابستگیهای node_modules دانلود کردهاند و میخواهید ابتدا نسخههای جدید را نصب کنید، میتوانید دستور زیر را اجرا کنید:
npm install
نسخهبندی معناشناختی با استفاده از npm
نسخهبندی معناشناختی یک قرارداد است که به نسخههای مختلف معنا میبخشد. اگر در مورد پکیجهای Node تنها یک نکته مهم وجود داشته باشد، آن این است که همه افراد روی استفاده از نسخهبندی معناشناختی در تعیین اعداد نسخه توافق دارند.
مفهوم نسخهبندی معناشناختی ساده است. همه نسخهها سه رقم به صورت x.y.z دارند که هرکدام معنی مشخصی دارند:
- رقم نخست نشاندهنده نسخه اصلی است.
- رقم دوم نشاندهنده نسخه فرعی است.
- رقم سوم نشاندهنده نسخه وصله است.
زمانی که یک انتشار جدید انجام مییابد، اعداد به صورت تصادفی انتساب نمییابند، بلکه قواعد خاصی وجود دارند:
- عدد اصلی نسخه زمانی افزایش مییابد که تغییرهای ناسازگاری با نسخههای قبلی در API ایجاد شده باشد.
- نسخههای فرعی زمانی اضافه میشوند که یک کارکرد به روش سازگار با نسخههای قبل اضافه شده باشد.
- نسخه وصله نیز شامل اصلاحیههای باگ مطابق با نسخههای قبلی است.
این قرارداد از سوی همه زبانهای برنامهنویسی پذیرش یافته است و بسیار مهم است که همه پکیجهای npm به آن پایبند باشند، چون کل سیستم به آن وابسته است.
چرا نسخهبندی معنایی مهم است؟
از آنجا که npm برخی قواعد را تعیین کرده است، میتوانیم در زمان اجرای دستور npm update از این قواعد در فایل package.json استفاده کنیم تا نسخهای را که میتواند پکیج را به آن بهروزرسانی کند انتخاب کنیم.
در این قواعد از نمادهای زیر استفاده میشود:
- ~
- >
- >=
- <
- <=
- =
- –
- ||
در ادامه هر یک از نمادهای فوق را توضیح میدهیم:
نماد ^: اگر قاعدهای به صورت 0.13.0^ بنویسیم، وقتی که دستور npm update را اجرا میکنید، میتوانید انتشارهای فرعی و وصله را بهروزرسانی کند. برای مثال 0.13.1، 0.14.0 و غیره.
نماد ~: اگر قاعدهای به صورت 0.13.0~ بنویسید هنگامی که دستور npm update را اجرا میکنید، تنها نسخههای وصله بهروزرسانی میشوند. بین ترتیب 0.13.1 درست است، اما 0.14.0 چنین نیست.
نماد >: بدین ترتیب هر نسخهای بالاتر از عددی که ذکرمی شود قابل قبول خواهد بود.
نماد >=: هر نسخهای برابر یا بالاتر از آن که تعیین کردهاید مورد قبول است.
نماد <=: هر نسخهای برابر با پایینتر از عددی تعیین شده قابل قبول است.
نماد <: هر نسخهای پایینتر از عدد ذکر شده مورد پذیرش است.
نماد =: عدد دقیق نسخه مورد قبول است.
نماد –: بازهای از نسخهها مورد قبول است.
نماد | |: چند بازه با هم ترکیب میشوند برای مثال: < 2.1 || > 2.6
شما میتوانید برخی از این نمادها را با هم ترکیب کنید، برای نمونه از 1.0.0 || >=1.1.0 <1.2.0 استفاده کنید تا از نسخه 1.0.0 یا یکی از انتشارهای 1.1.0 به بالا اما پایینتر از 1.2.0 استفاده کنید.
قواعد دیگری نیز وجود دارند:
- بدون نماد: شما تنها نسخه دقیقی را که تعیین شده (برای نمونه 1.2.1) میپذیرید.
- Latest: در این حالت تنها از آخرین نسخه موجود استفاده میشود.
لغو نصب پکیجهای npm به صورت محلی یا سراسری
برای لغو نصب پکیجهایی که قبلاً به صورت محلی با استفاده از <npm install <package-name در پوشه node_modules نصب شدهاند، باید دستور زیر را اجرا کنید:
npm uninstall <package-name>
با استفاده از فلگ s- یا save— این عملیات نیز موجب حذف ارجاع در فایل package.json میشود.
اگر پکیج یک وابستگی توسعه باشد، در بخش devDependencies در فایل package.json فهرست شده است و باید از فلگ D / –save-dev- برای حذف آن از فایل استفاده کنید:
npm uninstall -S <package-name> npm uninstall -D <package-name>
اگر پکیج به صورت سراسری نصب شده باشد، باید فلگ g / –global- را اضافه کنید:
npm uninstall -g <package-name>
مثال:
npm uninstall -g webpack
و میتوانید این دستور را از هر جایی که میخواهید روی سیستم اجرا کنید، چون پوشهای که اکنون در آن قرار دارید اهمیتی ندارد.
پکیجهای محلی یا سراسری npm
اینک شاید بپرسید نصب محلی پکیجها بهتر است یا نصب سراسری آنها و دلیل آن چیست؟ تفاوت اصلی بین پکیجهای محلی و سراسری به شرح زیر است:
پکیجهای محلی
این پکیجها در همان دایرکتوری که دستور <npm install <package-name اجرا میشود، نصب خواهند شد و در پوشه node_modules زیر این دایرکتوری قرار میگیرند.
پکیجهای سراسری
این پکیجها در یک مکان منفرد در سیستم قرار میگیرند که موقعیت دقیق آن به تنظیمات سیستم وابسته است و مهم نیست که دستور <npm install -g <package-name از کجا اجرا شده باشد.
در کد هر دو پکیج به طرز یکسانی «الزام» (require) میشوند:
require('package-name')اینک شاید بپرسید که پکیجها را باید به چه روشی نصب کنید؟ به طور کلی همه پکیجها باید به صورت محلی نصب شوند. بین ترتیب این اطمینان حاصل میشود که میتوانید اپلیکیشنهای مختلفی روی سیستم خود داشته باشید که در صورت نیاز نسخههای متفاوتی از هر پکیج را اجرا کنند.
بهروزرسانی یک پکیج سراسری موجب میشود که همه پروژهها از انتشارهای جدید استفاده کنند و همان طور که حدس میزنید این وضعیت ازنظر نگهداری اپلیکیشنها یک کابوس محسوب میشود، چون برخی پکیجها ممکن است با وابستگیهای دیگر ناسازگار باشند.
وقتی همه پروژهها نسخههای محلی خود را از یک پکیج دارند، حتی اگر به نظر بیاید که موجب هدررفت منابع میشود، اما این هزینه در برابر عواقب منفی نصب سراسری پکیجها ناچیز است.
یک پکیج زمانی باید به صورت سراسری نصب شود که دستور اجرایی داشته باشد که بتوانید از پوسته (CLI) اجرا کنید و در روی پروژهها قابلیت استفاده مجدد داشته باشد. همچنین میتوانید دستورهای اجرایی را به صورت محلی و با استفاده از npx اجرا کنید، اما برخی پکیجها وقتی که به صورت سراسری نصب میشوند بهتر هستند.
نمونههایی از پکیجهای سراسری که ممکن است بشناسید، به شرح زیر هستند:
- npm
- create-react-app
- vue-cli
- grunt-cli
- mocha
- react-native-cli
- gatsby-cli
- forever
- nodemon
شما ممکن است از قبل برخی پکیجها را روی سیستم خود داشته باشید که به صورت سراسری نصب شده باشند. آنها را میتوان با اجرای دستور زیر در خط فرمان مشاهده کرد:
npm list -g --depth 0
وابستگیهای dependencies و devDependencies
چه زمانی میتوان گفت که یک پکیج، وابستگی (dependency) است و چه هنگام میتوان آن را وابستگی توسعه (DevDependency) نامید؟
زمانی که یک پکیج npm را با استفاده از دستور زیر نصب میکنید، آن را به صورت یک وابستگی نصب کردهاید:
npm install <package-name>
این پکیج به صورت خودکار در فایل package.json و زیر dependencies فهرست میشود. زمانی که فلگ D- را اضافه میکنید یا از فلگ save-dev- استفاده میکنید، پکیج را به صورت یک وابستگی توسعه نصب میکنید و به فهرست devDependencies اضافه میشود.
وابستگیهای توسعه به این منظور ارائه شدهاند که پکیجهایی صرفاً در محیط توسعه اپلیکیشن نصب شوند و قرار نیست در محیط عرضه نهایی (Production) حضور داشته باشند. برای نمونه پکیجهای تست، webpack یا Babel چنین خصوصیتهایی دارند.
زمانی که به محیط Production میرویم، اگر دستور npm install را وارد کنیم و آن پوشه شامل فایل package.json باشد، این پکیجها به صورتی نصب میشوند که npm تصور میکند این یک توزیع توسعه (Development) است.
بدین ترتیب باید فلگ production– را طوری تنظیم کنید (npm install –production) که از نصب این وابستگیهای توسعه جلوگیری کند.
Node Package Runner به نام npx
npx یک روش بسیار جالب برای اجرای کدهای Node.js محسوب میشود و قابلیتهای مفید زیادی ارائه کرده است. در این بخش یک دستور بسیار قدرتمند را معرفی میکنیم که از نسخه 5.2 npm به بعد وجود داشته است. این نسخه که در جولای 2017 انتشار یافته به نام npx شناخته میشود. اگر نمیخواهید npm را نصب کنید، میتوانید آن را به صورت یک پکیج مستقل نصب کنید. npx امکان اجرای کد ساخته شده با Node.js و انتشار یافته از طریق ریپازیتوری npm را فراهم میکند.
اجرای آسان دستورهای محلی
توسعهدهندگان Node.js عادت دارند که اغلب دستورهای اجرایی را به صورت پکیجهای سراسری منتشر کنند تا بیدرنگ در دسترسشان بوده و قابلیت اجرایی داشته باشند. این روش پردردسری است، زیرا عملاً امکان نصب نسخههای مختلفی از یک دستور واحد وجود ندارد. اجرای دستور npx commandname به صورت خودکار باعث میشود که ارجاع صحیحی از دستور در مسیر جاری کاربر، بدون نیاز به دانستن مسیر دقیق و بدون الزام نصب سراسری پکیج، درون پوشه node_modules یک پروژه پیدا شود.
اجرای دستورها بدون نیاز به نصب
npm قابلیت عالی دیگری نیز دارد که امکان اجرای دستورها بدون نصب آنها را فراهم میسازد. این قابلیت بسیار مفید است چون:
- نیاز به نصب هیچ چیزی وجود ندارد.
- میتوان نسخههای مختلفی از یک دستور را با استفاده از ساختار @vrsion اجرا کرد.
یک نمایش نوعی برای استفاده از npx دستور cowsay است. cowsay یک «گفته گاوی» نمایش میدهد که در آن دستوری نوشته شده است. برای نمونه cowsay کاراکترهای زیر را روی صفحه نمایش میدهد:
این وضعیت زمانی است که دستور cowsay را قبلاً به صورت سراسری از npm نصب کرده باشید، در غیر این صورت زمانی که دستور را اجرا کنید، با خطایی مواجه میشوید.
npx امکان اجرای آن دستور npm را بدون الزام به نصب محلی فراهم میسازد:
npx cowsay "Hello"
همان طور که میبینید این یک دستور جالب بیفایده است. سناریوهای دیگر به صورت زیر هستند:
اجرای ابزار CLI مربوط به Vue برای ایجاد اپلیکیشنهای جدید و اجرای آنها با دستور زیر:
npx vue create my-vue-app
ایجاد اپلیکیشن ریاکت جدید با استفاده از :create-react-app:
npx create-react-app my-react-app
و موارد بسیار دیگر؛ زمانی که آن را دانلود کنید، کد دانلود شده پاک میشود.
اجرای برخی کدها با نسخههای مختلف Node.js
با استفاده از @ میتوان اقدام به تعیین نسخه و ترکیب کردن آنها با پکیج npm در node کرد:
npx node@6 -v #v6.14.3 npx node@8 -v #v8.11.3
این وضعیت کمک میکند که دیگر از ابزارهایی مانند nvm یا دیگر ابزارهای مدیریت نسخه Node استفاده نکنیم.
اجرای مستقیم قطعه کدهای دلخواه از یک URL
npx شما را محدود به پکیجهای انتشار یافته روی رجیستری npm نمیکند. بدین ترتیب برای مثال میتوان کدی را که در یک gist گیتهاب قرار دارد اجرا کرد:
npx https://gist.github.com/zkat/4bc19503fe9e9309e2bfaa2c58074d32
البته هنگام اجرای کدی که روی آن کنترل ندارید، باید مراقب باشید چون چنان که میدانید قدرت زیاد نیاز به مسئولیتپذیری زیادی هم دارد. بدین ترتیب به پایان بخش پنجم از سری مقالات آموزش جامع Node.js رسیدیم و توضیحاتی که در مورد npm وجود داشت را به پایان بردیم. در بخش بعدی در مورد حلقهها، و تایمرها در Node.js خواهیم خواند. برای مطالعه بخش بعدی به لینک زیر رجوع کنید:
احراز هویت کاربر با React Native Navigation — راهنمای کاربردی
در بخش قبلی این مطلب در مورد کتابخانه React Native Navigation صحبت کردیم. در بخش دوم و پایانی این سری مقالات به بررسی روشهای احراز هویت کاربر به کمک این کتابخانه خواهیم پرداخت. برای مطالعه بخش قبلی به لینک زیر مراجعه کنید:
کار خود را از جایی که در بخش اول باقی مانده بود از سر میگیریم و اینک میخواهیم با استفاده از AWS یک بخش واقعی ثبت نام و ورود کاربر به اپلیکیشن بسازیم. بدین منظور از AWS Amplify برای اتصال به AWS و از Amazon Cognito برای مدیریت کاربران استفاده میکنیم. اگر کد بخش قبلی را نوشتهاید، میتوانید شروع به کار روی آن بکنید، اما اگر آن کد را ندارید میتوانید از این ریپو (+) استفاده کنید.
ایجاد سرویس Auth
از root پروژه ریاکت نیتیو آغاز میکنیم و یک پروژه جدید AWS را طوری مقداردهی میکنیم که بتوانیم احراز هویت را اضافه کنیم. به این منظور باید AWS Mobile CLI را نصب و پیکربندی کنیم:
npm i -g awsmobile-cli awsmobile configure
زمانی که CLI را نصب و پیکربندی کردید، یک پروژه جدید AWS را مقداردهی کنید:
awsmobile init
این دستور چند کار به شرح زیر انجام میدهد:
- یک پروژه جدید Mobile Hub در حساب AWS ما ایجاد میکند.
- چند وابستگی را به صورت aws-amplify و aws-amplify-react-native درون پروژه نصب میکند.
- فایلهای پیکربندی محلی با اسامی awsmobile.js و aws-exports.js اضافه میکند که امکان ویرایش محلی پیکربندی از طریق cli و ارسال تغییرات به پروژه Mobile Hub را در کنسول AWS فراهم میسازد.
سپس باید یک وابستگی نیتیو به پروژه React Native خود اضافه کنیم:
react-native link amazon-cognito-identity-js
اینک باید بخش ثبت نام کاربر را به پروژه AWS خود اضافه کنیم:
awsmobile user-signin enable
و آن را به کنسول AWS ارسال کنیم:
awsmobile user-signin enable
اکنون باید کارکرد ثبت نام کاربر ما فعال و آماده استفاده باشد. کل پروژه Mobile Hub را میتوان در حساب AWS با اجرای دستور awsmobile console از خط فرمان مشاهده کرد. همچنین میتوانید از کنسول Amazon Cognito بازدید کنید تا پیکربندی آن را ببینید.
نوشتن اپلیکیشن ریاکت نیتیو
اکنون که سرویس ایجاد شده است، باید اپلیکیشن را بهروزرسانی کنیم تا از آن استفاده کند. ابتدا باید فایل index.js را بهروزرسانی کنیم تا از پیکربندی موجود در فایل aws-exports.js استفاده کرده و با AWS Amplify کار کند.
فایل index.js
فایل SignUp.js
در فایل SignUp.js تابع signUp را بهروزرسانی میکنیم تا ثبت نام کاربر جدید را مدیریت کرده و یک تابع confirmSignUp جدید برای MFA بسازیم.
در این فایل SignUp.js دو فرم ابتدایی داریم که یکی برای ثبت نام کاربر جدید و دیگری برای تأیید ثبت نام با استفاده از MFA است. فرم تأیید ثبت نام به کاربر امکان میدهد که کد MFA خود را برای شناسایی این که این کد را دریافت کرده است وارد کند. ما این دو فرم را بر اساس مقدار بولی this.state.showConfirmationForm نمایش داده یا پنهان میکنیم که مقدار آن در متدهای کلاس signUp و confirmSignUp تعیین میشود.
متدهایی که برای ثبت نام و تأیید ثبت نام از AWS Amplify استفاده میکنیم، به ترتیب Auth.signUp و Auth.confirmSignUp نام دارند.
فایل SignIn.js
این فایل برای بهروزرسانی تابع signIn جهت مدیریت ثبت نام کاربر و ایجاد تابع جدید confirmSignIn برای MFA استفاده میشود.
فایل SignIn.js
منطق این کامپوننت بسیار مشابه آن چیزی است که در SignUp.js دیدیم و تنها یک تفاوت وجود دارد. زمانی که Auth.signIn را فراخوانی میکنیم، مقدار بازگشتی از فراخوانی متد را در حالت (State) خود ذخیره میکنیم تا بعدتر در Auth.confirmSignIn استفاده کنیم. زمانی که (Auth.confirmSignIn(user, confirmationCode را فراخوانی میکنیم، این شیء کاربر را همراه با کد احراز هویت دریافتی از MFA به آن ارسال میکنیم.
فایل Initializing.js
زمانی که کاربر وارد حساب خود در اپلیکیشن شد، میتوانیم از طریق فراخوانی کردن Auth.currentAuthenticatedUser اطلاعاتی در مورد کاربر بازیابی کنیم. اگر یک کاربر ثبت نام کرده باشد، این تابع موفق خواهد بود و میتوانیم اپلیکیشن اصلی را بارگذاری کنیم. اگر این رویه ناموفق باشد، میتوانیم مسیریابیهای احراز هویت یعنی SignIn و SignUp را بارگذاری کنیم.
برای پیادهسازی این وضعیت باید کامپوننت Auth را از AWS Amplify ایمپورت کرده و متد چرخه عمر componentDidMount را بهروزرسانی کنیم تا کاربر را بررسی کند:
برای مشاهده نسخه نهایی این کامپوننت به این لینک (+) مراجعه کنید.
فایل Home.js
آخرین کاری که باید انجام دهیم، بهروزرسانی دکمه SignOut است تا در زمان کلیک شدن، کاربر را عملاً از اپلیکیشن خارج کند. به این منظور میتوانیم دستگیره onPress را الحاق کنیم تا متد Auth.signOut را از AWS Amplify فراخوانی کند:
برای مشاهده نسخه نهایی این کامپوننت به این صفحه (+) مراجعه کنید.
سخن پایانی
راهاندازی و اجرای احراز هویت کاربر به کمک ترکیبی از Amazon Cognito و AWS Amplify کار واقعاً سرراستی محسوب میشود. تکنیکهایی که در این راهنما استفاده کردیم، به همراه کتابخانه React Native Navigation کار میکنند و البته با ارائهدهندگان خدمات احراز هویت دیگر نیز به خوبی اجرا خواهند شد.
وقتی از ناوبری در ریاکت نیتیو صحبت میکنیم، دو کتابخانه بسیار کارآمد وجود دارند که یکی React Navigation و دیگری React Native Navigation است. کتابخانه React Navigation نگهداری بسیار خوبی دارد و کاملاً به بلوغ رسیده است. این کتابخانه تقریباً هر چیزی را که بخواهید انجام میدهد و تیم نگهداری آن کار فوقالعادهای در رسیدگی به مشکلات و تبدیل کردن به یک کتابخانه درجه یک انجام دادهاند.
React Native Navigation نیز گزینه مناسبی محسوب میشود و از سوی تیم توسعهدهنده به خوبی نگهداری شده است. React Native Navigation نسخه 2 اخیراً وارد فاز آلفا شده و ممکن است برخی قابلیتها هنوز عرضه نشده باشند که در این مورد میتوانید issue بدهید یا درخواست pull کنید.
منبع: فرادرس
گزاره switch..case در ++C — راهنمای کاربردی
در بخشهای قبلی (+) این سری مقالات آموزش زبان برنامهنویسی ++C با گزاره if..else..if آشنا شدیم که امکان اجرای یک قطعه کد را در میان گزینههای مختلف فراهم میسازد. با این حال اگر قصد دارید مقدار یک متغیر منفرد را با استفاده از گزارههای متوالی if..else..if بررسی کنید، بهتر است به جای آن از گزاره switch..case استفاده کنید. برای مطالعه بخش قبلی این سری ملاقات آموزشی زبان برنامهنویسی ++C به لینک زیر مراجعه کنید:
گزاره switch اگر نه همیشه، دستکم در اغلب موارد سریعتر از گزاره if…else است. ضمناً ساختار گزاره سوئیچ سادهتر و درک آن آسانتر است.
ساختار گزاره switch…case در زبان ++C
در شبه کد فوق تصور کنید مقدار n برابر با constant2 باشد. کامپایلر بلوک کدی را اجرا خواهد کرد با گزاره case مرتبط هستند تا این که به انتهای بلوک سوئیچ برسد یا با گزاره break مواجه شود. گزاره break برای جلوگیری از اجرای کد در case بعدی استفاده میشود.
فلوچارت گزاره switch
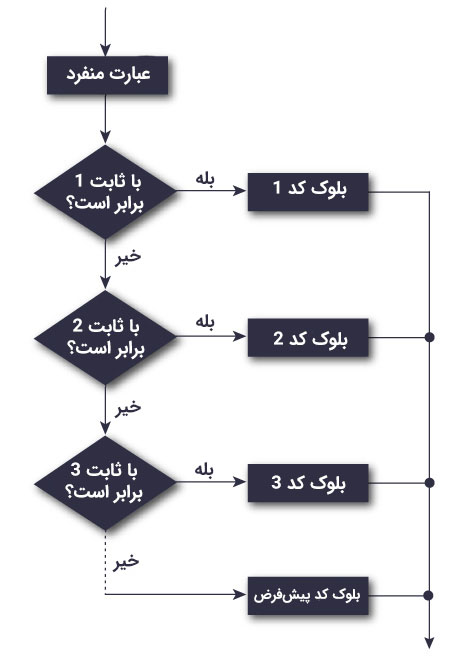
شکل فوق نشان میدهد که گزاره switch چگونه کار میکند و شرایط مختلف چگونه درون بند case سوئیچ بررسی میشوند.
مثالی از گزاره switch در ++C
Enter an operator (+, -, *, /): + - Enter two operands: 2.3 4.5 2.3 - 4.5 = -2.2
عملگر (-) که از سوی کاربر وارد میشود در متغیر 0 ذخیره میشود. دو عملوند 2.3 و 4.5 به ترتیب در متغیرهای num1 و num2 ذخیره میشوند. سپس کنترل برنامه به دستور زیر میرسد:
cout << num1 << " - " << num2 << " = " << num1-num2;
در نهایت گزاره break موجب اتمام گزاره switch میشود. اگر گزاره break استفاده نشود، همه case-های بعد از حالت صحیح نیز اجرا خواهند شد. برای مشاهده بخش بعدی این مطلب به لینک زیر رجوع کنید: