طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی شبکه تصاویر واکنش گرا با CSS Grid Layout — از صفر تا صد
شما به عنوان یک توسعهدهنده فرانتاند حتماً تاکنون تجربیاتی در زمینه CSS داشتهاید، اما اغلب ما این روزها کار با CSS را از طریق فریمورکهایی مانند Bootstrap انجام میدهیم. برخی موقعیتها وجود دارند که مجبور خواهیم بود مستقیماً با CSS کار کنیم و یکی از آنها مواردی است که بخواهیم با سیستم Grid Layout کار کنیم. در این مقاله به طور عمده در مورد شیوه استفاده از CSS Grid Layout جهت ساختن یک شبکه از تصاویر صحبت خواهیم کرد.
ما قصد نداریم همه مشخصههای Grid Layout را بررسی کنیم، بلکه روی آن مشخصههایی متمرکز میشویم که برای اجرای وظیفه فوق مورد نیاز هستند.
CSS Grid Layout به چه معنی است؟
Grid Layout در CSS یک سیستم طرحبندی دوبُعدی برای وب است. شبکهها امکان سازماندهی محتوا در ردیفها و ستونها را به ما میدهند. طرحبندی یک صفحه وب با یک هدر، یک نوار کناری، ناحیه محتوای اصلی و یک فوتر (مانند تصویر 1 زیر) را تصور کنید. این اجزای صفحه وب نیازمند طرحبندی صحیحی روی صفحه هستند. Grid در CSS به ما کمک میکند که این کار را چنان که با بررسی یک مثال از شبکه تصاویر خواهیم دید، انجام دهیم.

در تصویر زیر شبکه تصاویری که از آن صحبت کردیم و میخواهیم بسازیم را مشاهده میکنید.

خوب هر چه تا اینجا در مورد تئوری صحبت کردیم کافی است. اینک نوبت کار عملی فرا رسیده است.
یک پوشه روی سیستم خود ایجاد کرد و نامی برای آن تعیین کنید. ما پوشه خودمان را Photogrid مینامیم. پوشه را در ویرایشگر متنی محبوب خود باز کنید. ما از VSCode استفاده میکنیم. 2 فایل ایجاد کنید که نام یکی index.html و دیگری main.css است. ما استایل های مورد نیاز را در فایل main.css مینویسیم. کد زیر را به فایل index.html کپی کنید:
همان طور که در قطعه کد فوق میبینید، 13 div ایجاد کردهایم که هر کدام یک تصویر دارد و از سرویس عکس Unsplash واکشی میشود. div کانتینر کلاسی از نوع container. دارد. توجه کنید که برخی از فرزندان div کانتینر، دارای کلاسهایی مانند big ،.vertical. و horizontal. هستند. ما این div-ها را به طرز متفاوتی سبکبندی خواهیم کرد. اینک نوبت به استایلدهی شبکه تصاویر رسیده است.
ایجاد استایل برای شبکه تصاویر
در فایل main.css استایلهایی برای شبکه تصاویر خود ایجاد میکنیم و کار خود را با کلاس container آغاز میکنیم.
در ادامه به اختصار در مورد کارکرد هر یک از مشخصههای فوق صحبت میکنیم.
توضیح مشخصههای استایل
برای این که با هر کانتینر مانند یک کانتینر شبکه رفتار شود، باید نوع display به صورت grid و یا grid-inline برای شبکههای درونخطی تعریف شده باشد. مشخصه grid-template-columns به تعریف ستونهایی از کانتینر شبکه میپردازد. شما میتوانید عرض ستون را با استفاده از یک کلیدواژه مانند auto-fit یا یک طول مانند 50px تعریف کنید. در مورد مثال فوق ما مقدار grid-template-columns را درون یک متد ()repeat تعریف میکنیم.
متد repeat نشان دهنده یک فرگمان تکراری از یک tracklist است. بنابراین یک مقدار مانند (repeat(3، 80px سه ستون ایجاد میکند که هر یک عرضی برابر با 80 پیکسل دارند. کلیدواژه auto-fit به مدیریت اندازههای ستون میپردازد. بدین ترتیب میتوانیم بیشتری تعداد ممکن ستونها را در ردیفی با طول مفروض قرار دهیم. برای نمونه یک مقدار grid-template-columns به صورت (repeat(auto-fit، 100px بیشترین تعداد ستونهایی که در div-های کانتینر شبکه وجود دارند با تنظیمات عرض 80 پیکسل تولید میکند. در نهایت تابع minmax به تعریف کمینه و بیشینه عرض هر ستون میپردازد. minmax برای ایجاد صفحههای واکنشگرا بسیار مفید است.
The grid-auto-rows اندازه یک ردیف شبکه را که به صورت صریح ایجاد شده است تعیین میکند. بنابراین بر اساس قطعه کد CSS فوق این بدان معنی است که هر div که در کانتینر شبکه داریم ارتفاعی برابر با 200 پیکسل خواهد داشت.
grid-gap اندازه فاصله بین ستونها و ردیفها را تعیین میکند. در مثال مورد بررسی، grid-gap آن مقدار 5 پیکسل هم برای فاصله بین ستونها و هم بین ردیفها است.
مشخصه grid-auto-flow به کنترل طرز کار الگوریتم auto-placement میپردازد و دقیقاً تعیین میکند که آیتمهای با جایگذاری خودکار چگونه در شبکه جابجا میشوند. در مثال مورد بررسی، ما از الگوریتم بستهبندی dense استفاده کردهایم که تلاش میکند آیتمهای کوچکی را که در ادامه میآیند، ابتدا در جاهای خالی شبکه پر کند. کامنت کردن آن خط موجب بروز برخی فضاهای خالی در شبکه ما خواهد شد.
تکمیل کد شبکه تصاویر
همان طور که میبینید توضیحهای فوق برای چند خط کد کمی زیاد محسوب میشوند، اما خوشبختانه شما اینک با فرایند کار به خوبی آشنا شدهاید. اکنون باید پا را فراتر گذاشته و شبکه تصاویر را تکمیل کنیم. ابتدا باید مطمئن شویم که همه تصاویر به طور صحیحی در div-ها قرار میگیرند. به این منظور کد زیر را در فایل CSS پس از کلاس container. قرار دهید.
این کد به تعیین عرض و ارتفاع همه تصاویر در شبکه بر اساس 100% کانتینرهایشان میپردازد. در نهایت به استایلدهی div-ها با کلاسهای verical ،.horizontal. و .big میپردازیم.
در این بخش به صحبت در مورد مشخصههای CSS در قطعه کد فوق میپردازیم.
مشخصه CSS به نام grid-column یک مشخصه اختصاری برای grid-column-start و grid-column-end است که اندازه شبکه و موقعیت درون شبکه را تعیین میکند. کلیدواژه span تعداد ردیفها یا ستونهایی که یک grid-column یا grid-row باید پوشش دهد تعیین میکند.
در مثال فوق، برای این که طول برخی تصاویر دو برابر بزرگتر باشد، مقدار grid-column را برای کلاس horizontal. برابر با span 2 و برای کلاس vertical. نیز برابر با span 2 تعیین میکنیم تا ارتفاع برخی تصاویر دو برابر از بقیه باشد. div-های دارای کلاس big. در هر دو گستره ردیف و ستون اندازهای دو برابر معمول دارند. اینک فایل index.html را در یک مرورگر باز کنید و خروجی را مشاهده کنید.
اگر علاقهمند هستید کد کامل را بینید، میتوانید به فایلهای زیر رجوع کنید:
فایل index.html
فایل main.css
نسخه نهایی باید چیزی مانند تصویر زیر باشد:
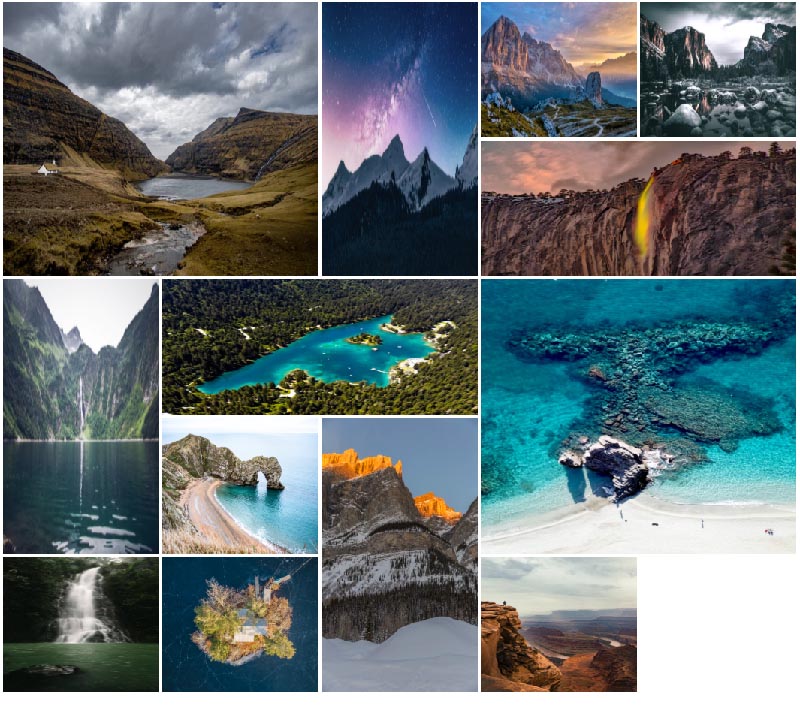
توجه داشته باشید که CSS Grid Layout مشخصههای زیاد دیگری دارد که احتمالاً مورد توجه شما قرار خواهند گرفت. بنابراین میتوانید بررسی آن را با مطالعه مستندات (+) آغاز کنید.
منبع: فرادرس
گزاره break و continue در ++C — راهنمای کاربردی
دو گزاره به نام گزاره break و continue در زبان برنامهنویسی ++C وجود دارند که به طور خاص برای تغییر در گردش نرمال یک برنامه استفاده میشوند. در برخی موارد میخواهیم که اجرای یک حلقه برای یک شرایط تست خاص رد شود و یا بدون بررسی شرط حلقه بیدرنگ خاتمه یابد. برای مطالعه بخش قبلی این سری مقالات آموزشی به لینک زیر مراجعه کنید:
حلقه while و do…while در ++C — راهنمای کاربردی
برای نمونه ممکن است بخواهیم روی دادههای افرادی با سنین مختلف به جز سنین بالاتر از 65 حلقهای تعریف کنیم. همچنین ممکن است بخواهیم نخستین فردی که 20 سال سن دارد را بیابیم. در چنین مواردی از گزارههای ;continue و ;break استفاده میکنیم.
گزاره break در ++C
گزاره break در ++C موجب خاتمه بیدرنگ یک حلقه میشود. این حلقه میتواند هر نوعی از قبیل for ،while و do..while و همچنین گزارهی switch شود.
ساختار break
در استفادههای عملی گزاره break تقریباً همواره درون بدنه یک گزاره شرطی یعنی if…else در حلقه استفاده میشود.
طرز کار گزاره break چگونه است؟

مثال 1: break در ++C
برنامه ++C برای افزودن همه اعداد وارد شده از سوی کاربر تا زمانی که کاربر عدد 0 وارد نماید:
خروجی
Enter a number: 4 Enter a number: 3.4 Enter a number: 6.7 Enter a number: -4.5 Enter a number: 0 Sum = 9.6
در برنامه فوق، عبارت تست همواره صحیح است. از کاربر تقاضا میشود که عدد دیگری را وارد کند هنگامی که کاربر مقدار 0 وارد میکند، عبارت تست درون گزاره if نادرست است و بدنه else اجرا میشود که موجب خاتمه حلقه میشود. در نهایت مجموع نمایش پیدا میکند.
گزاره continue در ++C
در برخی موارد ضروری است که از شرایط تست خاصی درون یک حلقه رد شویم. در چنین مواردی گزاره continue در زبان برنامهنویسی ++C استفاده میشود.
ساختار continue
در عمل گزاره ;continue تقریباً همیشه درون یک گزاره شرطی استفاده میشود.
کار با گزاره continue

مثال 2: گزاره continue در ++C
برنامه ++C برای نمایش عدد صحیح از 1 تا 10 به جز 6 و 9.
خروجی
1 2 3 4 5 7 8 10
در برنامه فوق، زمانی که i برابر با 6 یا 9 باشد، اجرای گزاره زیر درون حلقه با استفاده از گزاره ;Continue رد میشود:
cout << i << "\t";
بدین ترتیب به پایان بخش دیگری از مطالب راهنمای مفاهیم برنامهنویسی زبان ++C میپردازیم. برای مشاهده بخش بعدی این سری مطالب به لینک زیر رجوع کنید:
منبع: فرادرس
آموزش سوئیفت (Swift): کاربرد Enum با ژنریک و بستار – بخش پانزدهم
در این بخش از سری مقالات آموزش برنامهنویسی سوئیفت قصد داریم به صورت فشرده برخی از مفاهیم مهم این زبان برنامهنویسی شامل استفاده از Enum به همراه ژنریک و بستارها را با هم ترکیب کنیم و با روش عملی استفاده از آنها در کدنویسی آشنا شویم.
در بخش قبلی با مبانی روشهای ایجاد خطاهای سفارشی و استفاده از آنها در کد برای جلوگیری از کرش کردن برنامه آشنا شدیم. برای مطالعه بخش قبلی میتوانید به لینک زیر مراجعه کنید:
Enum به همراه ژنریک و بستار
در بخشهای قبلی این سری آموزشی در مورد Enum-ها صحبت کردیم و گفتم که Enum گزینههای مختلفی در اختیار شما قرار میدهد که میتوانید از میان آنها انتخاب کنید و به نوعی حالتهای مختلف را منحصر به آن گزینهها بکنید. ما میتوانیم از مقادیر متناظر با حالتهای Enum برای تعریف کردن نوعی که در زمان استفاده از Enum وهلهسازی خواهد شد استفاده کنیم.
چنان که میبینید امکان بسیار جالبی است. اگر ندانیم چه نوعی وارد خواهد شد، میتوانیم از ژنریک استفاده کنیم.
بدین ترتیب میتوانیم در زمان ایجاد یک address یا coordinate از هر نوع که میخواهیم، استفاده کنیم.

اکنون به بررسی روش استفاده ترکیبی از Enum به همراه ژنریک و بستار میپردازیم. این ترفند جالبی است که برنامهنویسان حرفهای از آن در کدهای خود استفاده میکنند.
البته اگر بگوییم درک طرز کار این روش آسان است، دروغ گفتهایم. حتی با وجود تورفتگیها، میبینیم که درک کد فوق دشوار است. اما جای نگرانی نیست، زیرا در ادامه، همه این موارد را جزء به جزء توضیح میدهیم.
Struct Download
این Struct منطق ما را نگهداری میکند. این Struct میتواند یک کلاس باشد، زیرا وظیفه اجرای فراخوانیهای شبکه را بر عهده دارد.
بدین ترتیب دو گزینه در اختیار ما قرار میگیرد که یکی (success(anything. و دیگری (failure(someError. است.
این متدی است که یک تابع میگیرد. آن تابع یک حالت را از Enum به نام Result میگیرد و چیزی هم بازگشت نمیدهد.
let session
این دستور یک «نشست» (Session) از URLSession با یک پیکربندی ephemeral میسازد. منظور از ephemeral این است که تنها در حافظه وجود دارد و به عبارتی معادل مرور خصوصی وب است.
let url
این دستور یک URL از رشتهای که به آن ارسال کردهایم، میسازد. این رشته میتواند هر صفحه وبی که میخواهید از آن دانلود کنید باشد.
کد فوق وظیفهای در اختیار ما قرار میدهد که با آن میتوانیم دادههای مورد نظر خود را دانلود کنیم. آن را میتوان مانند اسبی تصور کرد که میتوانیم آن را به هر کجا که میخواهیم برانیم. Data شامل دادههای باینری (0 و 1) است که دریافت میکنیم. response هدرهای پاسخی است که دریافت میشود و در ادامه در مورد آن بیشتر توضیح میدهیم.
error در صورت ناموفق بودن درخواست بازگشت مییابد و درک این نکته مهم است. چون در صورت دریافت یک خطای 404 (صفحه یافت نشد) در فراخوانی، میتوانید اطلاعات مربوطه را از response دریافت کنید. حتی اگر خطای 500 دریافت شود که به معنی ناموفق بودن چیزی در سرور است همچنان میتوان آن را در response مشاهده کرد. error برای ما به این معنی است که نتوانستهایم آن کاری را که میخواستیم اجرا کنیم و حتی درخواست را مقداردهی کنیم. بنابراین error به معنی خطای ما و نه خطای دیگران است.
این یک بررسی قبل از اجرا محسوب میشود. اگر خطایی دریافت شود، دیگر نیازی به اجرا نخواهد بود و کافی است با بازگشت خطا از همینجا خارج شویم.
ما قبلاً در مورد DispatchQueue.main.async صحبت کردهایم، بنابراین در اینجا میخواهیم فقط کد زیر را توضیح دهیم:
اعتبارزدایی
این کد اقدام به اعتبارزدایی و لغو میکند، یعنی هر کاری که انجام میدادید را متوقف کرده و session را پاک میکند، چون دیگر نیازی به آن نداریم. اما اگر بخواهیم defer را توضیح دهیم، باید بگوییم که defer برای اجرا کردن یک قطعه کد استفاده میشود و مهم نیست که چه کاری انجام مییابد، صرفاً باید قبل از اجرا شدن، تا زمانی که متد پایان مییابد صبر کند. در واقع شبیه به یک deinit برای متدها، تابعها و بستارها است.
سپس از (!completion(.failure(error استفاده میکنیم. completion از نام پارامتر در start میآید. failure. حالتی از Enum با نام Result و !error خطای به اجبار باز شده است که از بستار دریافت شده است. در این موقعیت این بهکارگیری اجبار، کار درستی محسوب میشود، چون قبلاً تهی نبودن آن را بررسی کردهایم و از آنجا که این کد اجرا میشود، به این معنی است که تهی نبوده است. در ادامه بررسیهای دیگری را نیز اجرا میکنیم.
دسترسی مستقیم به حالت
متأسفانه سوئیفت دسترسی مستقیم به «حالت» (State) کد ایجاد نمیکند؛ اما HTTPURLResponse چنین امکانی در اختیار ما قرار میدهد و میتوانیم نوع پاسخ را به یک HTTPURLResponse تغییر دهیم و باید موفق باشد. در این حالت بیدرنگ بررسی میکنیم که آیا پاسخ موفقی به صورت زیر داریم یا نه:
اگر هر دوی آنها درست باشند، در این صورت میتوانیم دادهها را به صورت امنی باز پس بفرستیم تا تجزیه شوند و یا هر کار دیگری که قصد انجام آن وجود دارد اجرا شود. ابتدا با استفاده از DispatchQueue.main.async مطمئن میشویم که این کار را روی صف اصلی انجام میدهیم و سپس از دستگیره completion استفاده میکنیم تا این کار را با ((!completion(.success(data به صورت باز کردن اجباری دادهها اجرا کنیم، چون هر سه پارامتر بستار، مقادیر غیر optimal هستند.
در انتهای تابع Start اقدام به فراخوانی ()task.resume میکنیم که وظیفه داده را اجرا میکند. زمانی که این فراخوانی پایان یافت، همه آن کد را که قبلاً بررسی کردیم اجرا میکنیم.
برای این که متوجه شوید همه این موارد در سمت دیگر که Start را فراخوانی میکنیم، چه طور به نظر میرسند، میتوانید کد زیر را ملاحظه کنید:
سخن پایانی
بدین ترتیب در این مقاله با ارائه یک مثال با روش اجرای یک فراخوانی شبکه آشنا شدیم. روش استفاده از قدرت Enum-ها به همراه تابعها و ژنریک ها برای کمک به بازگشت بستار نمایش یافت. همچنین نگاهی به escaping@ داشتیم و با طرز استفاده از آن بیشتر آشنا شدیم.
این راهحل شبکه یک راهحل بهینه نیست و صرفاً یکی از راهحلهای ممکن محسوب میشود. روشهای مختلفی برای اجرای این کار وجود دارد و بسته به شیوه استفاده از بستارها در Enum-ها ممکن است مسیرهای متفاوتی ایجاد شود.
با این که ممکن است در نگاه نخست کمی دشوار به نظر برسد، اما اگر چند بار آن را تمرین کنید با طرز کار آن آشنا میشوید. البته امکان تکمیل خودکار کد نیز در صورتی که به آن توجه داشته باشید کمک زیادی به این فرایند یادگیری میکند.
ما تا به این جا صحبتهای زیادی در مورد انواعِ مقداری داشتیم. سوئیفت عاشق انواعِ مقداری خود است؛ اما نوع دیگری از دادهها به نام انواعِ ارجاعی نیز وجود دارند انواع ارجاعی فریبنده هستند و در صورتی که به طرز صحیحی استفاده نشوند میتوانند خطرناک باشند. در بخش بعدی در مورد inout ،Lazy و Getters و Setters صحبت خواهیم کرد. inout به طور کامل در مورد ارجاعها است، Lazy به ارتقای عملکرد کد کمک میکند و getters و setters موجب تغییر در شیوه دسترسی به دادهها میشوند. موارد فوق در موقعیتهای مختلف برنامهنویسی مفید هستند. برای مطالعه بخش بعدی این نوشته به لینک زیر رجوع کنید:
الگوریتم چیست؟ — به زبان ساده
الگوریتم کلمهای است که بسیار با آن مواجه میشویم. اما وقتی در مورد الگوریتمهای یوتیوب یا فیسبوک صحبت میکنیم، منظورمان دقیقاً چیست؟ الگوریتمها چه هستند و چرا افراد تا این حد از آنها در هراس هستند؟
الگوریتمها، دستورالعمل حل مسئله هستند
ما در دنیایی زندگی میکنیم که گرچه رایانهها در لحظه لحظه زندگی ما نفوذ و رسوخ کردهاند، اما درک دقیقی از کارکرد آنها وجود ندارد. با این حال یک حوزه در علوم رایانه وجود دارد که هر فردی میتواند مبانی آن را درک کند. این زمینه از دانش رایانه به نام برنامهنویسی شناخته میشود.
برنامهنویسی صرفاً یک عنوان شغلی جذاب محسوب نمیشود؛ بلکه مبنای همه نرمافزارهای رایانهای از آفیس مایکروسافت تا نرمافزارهای سخنگوی تلفنی است. حتی اگر دانش شما از برنامهنویسی تنها منحصر به فیلمهای خیلی قدیمی و گزارشهای خبری زرد باشد، احتمالاً متوجه هستید که کار یک برنامهنویس چیست. برنامهنویس کدی را برای رایانه مینویسد و رایانه با استفاده از دستورالعملهای تعریف شده آن کد وظایفی را برای حل مسائل اجرا میکند.
اینک باید گفت که در دنیای دانش رایانه، الگوریتم در واقع عنوانی جذاب برای نامیدن کد است. هر مجموعه دستورالعمل که به یک رایانه اعلام کند مسائل را چگونه حل کند یک الگوریتم محسوب میشود؛ حتی اگر آن وظیفه بسیار آسان باشد. زمانی که رایانه خود را روشن میکنید، یک مجموعه از دستورالعملهای «شیوه روشن شدن» اجرا میشوند. زمانی که رایانه NASA از دادههای موج رادیویی خام برای رندر کردن یک عکس فضایی استفاده میکند، همچنان یک الگوریتم اجرا شده است.
واژهای چند بعدی
کلمه الگوریتم میتواند برای توصیف هر مجموعه دستورالعملی حتی در خارج از دنیای برنامهنویسی نیز مورد استفاده قرار گیرد. برای نمونه روش شما برای مرتبسازی ظروف در یک کابینت نیز یک الگوریتم محسوب میشود. همچنین روش شما برای شستن دستها پس از دستشویی نیز یک الگوریتم است.

اما نکته اینجا است که امروزه کلمه الگوریتم صرفاً برای برخی گفتگوهای فناوری بسیار خاص مورد استفاده قرار میگیرد. معمولاً نمیشنویم که کسی از الگوریتمهای «ریاضیات مقدماتی» یا الگوریتمهای «ابزار گرافیتی در نرمافزار Paint» صحبت کند. اما در عوض بسیار میشنویم که کاربران در مورد الگوریتمهای پیشنهاد دوست اینستاگرام یا الگوریتمهای گردآوری داده فیسبوک از گروههای خصوصی اعتراض میکنند.
اگر الگوریتم یک اصطلاح با معانی مختلف برای دستورالعملهای محاسباتی باشد، در این صورت چرا باید از آن منحصراً برای توصیف جنبههای گیجکننده، جادویی و یا حتی شریرانه دنیای دیجیتال استفاده کنیم؟
اغلب افراد از «الگوریتم» و «یادگیری ماشین» به جای هم استفاده میکنند

در گذشته، برنامهنویسان و فرهنگ عامه اغلب دستورالعملهای محاسباتی را به صورت کد مینامیدند. این وضعیت امروزه نیز تا حدودی زیادی برقرار است. یادگیری ماشین زمینه وسیع و مبهمی از محاسبات است که در آن به جای کد از الگوریتم استفاده میشود. بدیهی است که این مسئله نیز بر سردرگمی پیچیدگی موجود پیرامون کلمه الگوریتم میافزاید.
یادگیری ماشین مدتهای زیادی است که وجود دارد، اما صرفاً در طی حدوداً 15 سال اخیر بوده است که به بخش بزرگی از دنیای دیجیتال تبدیل شده است. با این که یادگیری ماشین مانند یک ایده پیچیده به نظر میرسد، اما درک آن کاملاً آسان است. برنامه نویسان نمیتوانند کدهای خاص را برای هر موقعیت نوشته و تست کنند و از این رو کدی را مینویسند که بتواند خودش کدنویسی کند.
یادگیری ماشین به مثابه هوش مصنوعی
یادگیری ماشین را میتوان مانند یک شکل عملی از هوش مصنوعی تصور کرد. اگر شما تعداد کافی از ایمیلهای رئیس خود را به صورت اسپم علامتگذاری کنید، در این صورت کلاینت ایمیل به صورت خودکار همه ایمیلهای رئیس را به صورت اسپم نمایش میدهد. به طور مشابه، گوگل از یادگیری ماشین برای مطمئن شدن از این که نتایج جستجوی یوتیوب مرتبط بودهاند بهره میگیرند. آمازون نیز از یادگیری ماشین استفاده میکند تا محصولاتی که بهتر است بخرید را به شما پیشنهاد کند.
البته یادگیری ماشین این مقدار هم زیبا و سرراست نیست. عنوان «یادگیری ماشین» نیز آن قدر پیچیده هست که موجب آزردگی برخی افراد شود. برخی از کاربردهای رایج یادگیری ماشین نیز از نظر اخلاقی بحث برانگیز هستند. الگوریتمهایی که فیسبوک برای دادهکاوی کاربران در سطح وب استفاده میکند، مثالی از جنبههای ناخوشایند یادگیری ماشین محسوب میشوند.
در اخبار به صورت مکرر در خصوص الگوریتم گوگل برای رتبهبندی نتایج جستجو، الگوریتم یوتیوب برای پیشنهاد ویدئو و الگوریتم فیسبوک برای تصمیمگیری در مورد مطالبی که در تایملاین دیده میشود مطالبی را میخوانیم. اینها همگی مواردی مستعد نزاع و بحثانگیز هستند.
چرا الگوریتمها بحث برانگیز هستند؟
Long Division ازجمله الگوریتمهای آشنا برای تقسیم اعداد است. این الگوریتم چنان ساده است که به جای رایانهها مورد استفاده کودکان مدرسهای است. پردازندههای رایانه از الگوریتم کاملاً متفاوتی برای تقسیم کردن اعداد استفاده میکنند، اما در هر حال نتیجه کار یکسان است.
در تبدیل گفتار به متن از یادگیری ماشین استفاده میشود، اما هیچ کس از الگوریتم تبدیل گفتار به متن صحبت نمیکند، چون یک پاسخ دقیق عینی وجود دارد که هر انسانی میتواند بیدرنگ شناسایی کند. برای هیچ کس مهم نیست که رایانهها چگونه گفتهها را تشخیص میدهند و آیا از یادگیری ماشین استفاده شده است یا نه. تنها نکته مهم برای ما این است که آیا رایانه پاسخ صحیحی داده است یا نه.
اما دیگر کاربردهای یادگیری ماشین از این مزیت ارائه پاسخ صحیح برخوردار نیستند. به همین دلیل است که الگوریتمها به موضوع معمول گفتگوهای رسانهای در عصر حاضر تبدیل شدهاند.
یک الگوریتم برای مرتبسازی الفبایی فهرست تنها روشی برای اجرای وظیفه تعریف شده است. اما الگوریتمی مانند الگوریتم گوگل برای رتبهبندی بهترین وبسایتها برای جستجو یا الگوریتم یوتیوب برای پیشنهاد بهترین ویدئو ابهام بیشتری دارد و یک وظیفه تعریف شده را اجرا نمیکند. در این حالت مردم میتوانند بحث کنند که آیا الگوریتم نتایجی را که باید تولید کند، ارائه میدهد یا نه و بدیهی است که افراد مختلف میتوانند نظرهای متفاوتی در این خصوص داشته باشند. اما در مثال مرتبسازی الفبایی یک فهرست، همه کس توافق دارند که فهرست نهایی از نظر الفبایی مرتب شده است و هیچ جایی برای بحث وجود ندارد.
چطور میتوانیم از واژه الگوریتم استفاده کنیم؟
الگوریتمها مبانی همه نرمافزارها هستند. بدون وجود الگوریتم هیچ تلفن یا رایانهای وجود نمیداشت و احتمالاً همین مقاله را نیز روی کاغذ میخواندید و شاید هم اصلاً نمیتوانستید آن را بخوانید.
اما توده مردم از واژه الگوریتم به عنوان یک اصطلاح همهکاره برای کدهای رایانهای استفاده نمیکنند. در واقع اغلب مردم تصور میکنند که تفاوتی بین کد رایانه و الگوریتم وجود دارد؛ در حالی که واقعاً چنین نیست. از آنجا که واژه الگوریتم با یادگیری ماشین مرتبط است، معنی آن تا حدودی در هالهای از ابهام قرار گرفته است و کاربرد آن به موارد خاصی محدود شده است.

آیا ما باید از واژه الگوریتم برای توصیف اغلب کدهای رایانهای استفاده کنیم؟ شاید این کار مناسبی نباشد، چون اغلب افراد منظور گفتههای شما را درک نخواهند کرد. زبان همواره در حال تغییر است و برای هر تغییری نیز همواره دلیل خوبی وجود دارد. افراد برای توصیف دنیای سردرگمکننده، مبهم و در برخی موارد مشکوک یادگیری ماشین به یک واژه نیاز دارند و فعلاً واژه الگوریتم این نقش را بر عهده گرفته است.
بدین ترتیب بهتر است به خاطر داشته باشید که یک الگوریتم (و یادگیری ماشین) در معنای اصلی خود مقداری کد است که برای حل وظایف نوشته شده است. هیچ ترفند جادویی در مورد الگوریتم وجود ندارد و در واقع نسخه پیچیدهتری از نرمافزار است که همگی با آن آشنا هستیم.
منبع: فرادرس
محاسبه فاکتوریل در جاوا — به زبان ساده
اگر یک عدد صحیح غیر منفی n وجود داشته باشد، فاکتوریل آن عدد به صورت حاصلضرب همه اعداد صحیح مثبت کمتر یا برابر با آن تعریف میشود. در این مقاله به بررسی روشهای مختلف محاسبه فاکتوریل یک عدد مفروض در زبان برنامهنویسی جاوا میپردازیم.
محاسبه فاکتوریل برای اعداد تا 20
در این بخش با روشهای متفاوتی اقدام به محاسبه فاکتوریل اعداد تا 20 میکنیم.
استفاده از حلقه for
در ادامه یک الگوریتم ساده فاکتوریل را با استفاده از حلقه for مشاهده میکنید:
راهحل فوق برای اعداد تا 20 به خوبی کار میکند. اما اگر تلاش کنیم فاکتوریل اعداد بالاتر از 20 را محاسبه کنیم، ناموفق خواهد بود، زیرا نتایج آن قدر بزرگ خواهد شد که در یک متغیر از نوع long جای نمیگیرد و موجب خطای «سرریز» (overflow) میشود.
در ادامه با روشهای دیگر محاسبه فاکتوریل در جاوا آشنا میشویم و باید توجه داشته باشیم که این روشها تنها برای اعداد کوچک پاسخگو هستند.
استفاده از Stream در جاوا 8
امکان استفاده از API مربوط به Stream در جاوا 8 برای محاسبه فاکتوریل به روشی آسان وجود دارد:
در این برنامه ابتدا از LongStream برای تعریف حلقهای روی اعداد بین 1 تا n استفاده میکنیم. سپس از ()reduce استفاده میکنیم که از یک مقدار شناسایی و تابع تجمیع در مرحله کاهش استفاده میکند.
استفاده از بازگشت (Recursion)
در این بخش مثالی از یک برنامه محاسبه فاکتوریل میبینیم که این بار از روشهای بازگشتی استفاده شده است:
استفاده از کلاس Apache Commons Math
Apache Commons Math یک کلاس به نام CombinatoricsUtils دارد که شامل یک متد فاکتوریل استاتیک است. ما میتوانیم از این متد نیز برای محاسبه فاکتوریل استفاده کنیم.
برای incude کردن Apache Commons Math باید وابستگی commons-math3 را به pom اضافه کنیم:
در ادامه مثالی از استفاده از کلاس CombinatoricsUtils را میبینید:
توجه داشته باشید که نوع بازگشتی مانند راهحلهای بومی جاوا long است.
این بدان معنی است که اگر مقدار محاسبه شده از Long.MAX_VALUE تجاوز کند، خطای MathArithmeticException صادر میشود. برای دریافت مقادیر بزرگتر باید از نوع بازگشتی متفاوتی استفاده کنیم.
محاسبه فاکتوریل برای اعداد بزرگتر از 20
در این بخش روشهایی را بررسی میکنیم که با آنها میتوان فاکتوریل اعداد بزرگتر از 20 را نیز محاسبه کرد.
استفاده از BigInteger
چنان که پیشتر اشاره کردیم، نوع داده long برای محاسبه فاکتوریل عدد n به شرط کمتر از 20 بودن مناسب است. برای مقادیر n بزرگتر میتوانیم از کلاس BigInteger در پکیج java.math استفاده کنیم که میتواند مقادیری تا 2^Integer.MAX_VALUE را نگهداری کند.
استفاده از Guava
کتابخانه Guava گوگل یک متد کاربردی برای محاسبه فاکتوریل اعداد بزرگ ارائه کرده است. برای include کردن این کتابخانه میتوانیم وابستگی guava را به pom اضافه کنیم:
اکنون میتوانیم از متد فاکتوریل استاتیک از کلاس BigIntegerMath برای محاسبه فاکتوریل عدد مفروض استفاده کنیم:
سخن پایانی
در این مقاله، با چند روش محاسبه فاکتوریل با استفاده از توابع هسته مرکزی جاوا و همچنین چند کتابخانه دیگر آشنا شدیم. ابتدا راهحلهایی را با استفاده از نوع داده long برای محاسبه فاکتوریل تا 20 محاسبه کردیم. سپس چند روش برای محاسبه فاکتوریل اعداد بزرگتر از 20 با استفاده از BigInteger را بررسی کردیم.
منبع: فرادرس