طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیمرتب سازی حبابی و پیاده سازی آن — از صفر تا صد
«مرتبسازی حبابی» (Bubble Sort)، یکی از انواع الگوریتمهای مرتبسازی محسوب میشود. این الگوریتم مرتبسازی از جمله الگوریتمهای مبتنی بر مقایسه است که در آن، جفت عنصرهای همجوار با یکدیگر مقایسه شده و در صورتی که دارای ترتیب صحیحی نباشند، با یکدیگر جا به جا میشوند. الگوریتم مرتب سازی حبابی برای مجموعه دادههای بزرگ مناسب نیست، زیرا پیچیدگی زمانی آن در حالت میانگین و بدترین حالت برابر با (Ο(n2 است، که در آن n تعداد کل عناصر مجموعه داده محسوب میشود. در این مطلب، ابتدا یک مثال از الگوریتم مرتبسازی حبابی ارائه و سپس، «روندنما» (Flow Chart)، شبه کد و پیادهسازی آن در زبانهای «پایتون» (Python)،«جاوا» (Java)، «سی» (C) و «سیپلاسپلاس» (++C)، «پیاچپی» (PHP) و «سیشارپ» (#C) ارائه شده است. شایان توجه است که الگوریتمهای مرتبسازی از جمله مباحث بسیار مهم در «ساختمان داده» (Data Structure) هستند.
الگوریتم مرتب سازی حبابی چطور کار میکند؟
برای تشریح چگونگی عملکرد الگوریتم مرتب سازی حبابی، از یک مثال استفاده شده است. در این مثال، یک آرایه غیر مرتب در نظر گرفته شده است. با توجه به اینکه الگوریتم مرتب سازی حبابی از مرتبه (Ο(n2 است، آرایه انتخاب شده کوچک در نظر گرفته میشود. آرایه در نظر گرفته شده: ( ۴ ۲ ۸ ۱ ۵ ) است. مرتبسازی حبابی برای این آرایه، به صورت زیر انجام میشود.
۱. ابتدا، دو عنصر اول آرایه با یکدیگر مقایسه میشوند و با توجه به آنکه ۵ از ۱ بزرگتر است (۱<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 5 1 4 2 8 ) –> ( 1 5 4 2 8 )
۲. در اینجا، عناصر دوم و سوم آرایه مقایسه میشوند و با توجه به اینکه ۵ از ۴ بزرگتر است (۴<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 5 4 2 8 ) –> ( 1 4 5 2 8 )
۳. اکنون، عنصر سوم و چهارم آرایه مقایسه میشوند و با توجه به اینکه ۲ از ۵ کوچکتر است (۲<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 4 5 2 8 ) –> ( 1 4 2 5 8 )
۴. در اینجا، عنصر چهارم و پنجم آرایه مقایسه میشود و چون ۵ از ۸ کوچکتر است (۵<۸) دو عنصر در جای خود بدون هر گونه جا به جایی باقی میمانند؛ چون در واقع، ترتیب (صعودی) در آنها رعایت شده است.
( 1 4 2 5 8 ) –> ( 1 4 2 5 8 )
اکنون یک دور کامل در آرایه زده شد. دومین دور نیز به شیوه بیان شده در بالا انجام میشود.
۱. جا به جایی اتفاق نمیافتد.
( 1 4 2 5 8 ) –> ( 1 4 2 5 8 )
۲. با توجه به بزرگتر بودن ۴ از ۲ (۲<۴)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 4 2 5 8 ) –> ( 1 2 4 5 8 )
۳. جا به جایی اتفاق نمیافتد.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
۴. جا به جایی اتفاق نمیافتد.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
در حال حاضر، آرایه مرتب شده است، اما الگوریتم نمیداند که آیا کار به پایان رسیده یا خیر؛ بنابراین، به یک دور کامل دیگر بدون انجام هرگونه جا به جایی نیاز دارد تا بفهمد که مرتبسازی با موفقیت به پایان رسیده است.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
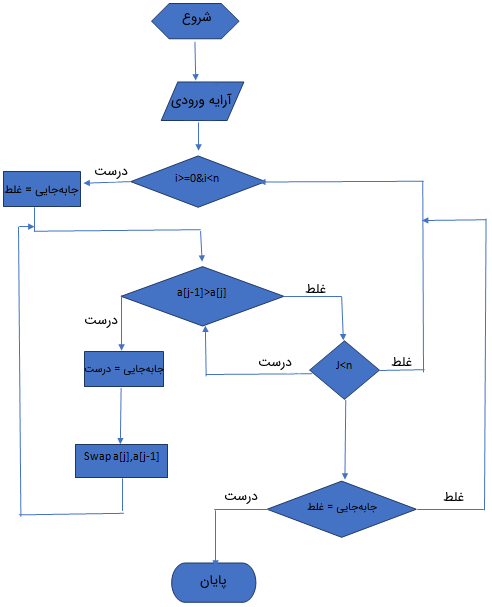
شبه کد الگوریتم مرتب سازی حبابی
در ادامه، پیادهسازی الگوریتم مرتب سازی حبابی در زبانهای برنامهنویسی گوناگون انجام شده و آرایه {۹۰ ,۱۱ ,۲۲ ,12 ,۲۵ ,۳۴ ,۶۴} به عنوان ورودی به قطعه کدها داده شده است. بنابراین، خروجی نهایی همه قطعه کدها، به صورت زیر خواهد بود.
11 12 22 25 34 64 90
پیادهسازی الگوریتم مرتب سازی حبابی در پایتون
پیادهسازی الگوریتم مرتب سازی حبابی در جاوا
پیادهسازی الگوریتم مرتب سازی حبابی در C و ++C
پیادهسازی الگوریتم مرتب سازی حبابی در PHP
پیادهسازی الگوریتم مرتب سازی حبابی در سی شارپ
پیاده سازی بهینه الگوریتم مرتب سازی حبابی
تابع معرفی شده در بالا در حالت متوسط و بدترین حالت، برابر با (O(n*n است. بدترین حالت تنها هنگامی به وقوع میپیوندد که آرایه به ترتیب معکوسی مرتب شده باشد. پیچیدگی زمانی تابع مذکور در بهترین حالت برابر با (O(n است و این حالت تنها هنگامی اتفاق میافتد که آرایه مرتب شده باشد. تابع بالا را میتوان به این شکل بهینه کرد که اگر حلقه داخلی منجر به هیچ جا به جایی نشود، فرایند متوقف شود. در ادامه، نمونه کد مربوط به تابع بهینه شده، در زبانهای برنامهنویسی گوناگون از جمله پایتون (نسخه ۳) ارائه شده است.
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در پایتون
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در جاوا
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در ++C
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در PHP
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در #C
جمعبندی
الگوریتم مرتبسازی حبابی با توجه به سادگی که دارد، معمولا برای معرفی مفهوم مرتبسازی مورد استفاده قرار میگیرد. در گرافیک کامپیوتری، این الگوریتم مرتبسازی با توجه به توانایی که برای تشخیص خطاهای خیلی کوچک (مانند جا به جایی تنها دو عنصر) در آرایههای تقریبا مرتب شده و رفع آن با پیچیدگی خطی (2n) دارد، از محبوبیت زیادی برخوردار است. برای مثال، در الگوریتم «پر کردن چند ضلعی» (Polygon Filling Algorithm) که خطهای محدود کننده به وسیله مختصات x در یک خط اسکن مشخص مرتبسازی شدهاند (خطی موازی محور x) و با افزایش y ترتیب آنها در تقاطع دو خط تغییر میکند (دو عنصر جا به جا میشوند)، مورد استفاده قرار میگیرد.
منبع: فرادرس
Promise.all در جاوا اسکریپت — از صفر تا صد
Promise-ها در جاوا اسکریپت یکی از API-های قدرتمند هستند که به اجرای عملیات ناهمگام کمک میکنند. Promise.all عملیات ناهمگام را به سطح بالاتری ارتقا داده است و به گروهبندی promise-ها کمک کرده است. به بیان دیگر با استفاده از Promise.all در جاوا اسکریپت میتوان گروهی از عملیات «همزمان» (concurrent) را اجرا کرد.
پیشنیاز مطالعه این مطلب آن است که با مفهوم Promise در جاوا اسکریپت آشنا باشید. اگر چنین نیست پیشنهاد میکنیم، مقاله «Promise در جاوا اسکریپت و کاربردهای آن — به زبان ساده» را مطالعه کنید.
Promise.all چیست؟
Promise.all در واقع یک promise است که ارائه از Promise-ها را به عنوان ورودی (عنصر تکرارپذیر = iterable) میگیرد. سپس وقتی که همه promise-ها پاسخ داده شوند یا هر یک از آنها رد شوند، Promise.all نیز به پایان میرسد.
برای نمونه فرض کنید 10 Promise دارید که عملیات ناهمگامی برای یک فراخوانی شبکه یا اتصال پایگاه داده اجرا میکنند. لازم است که بدانید همه Promise-ها چه زمانی پاسخ داده میشوند و یا لازم است صبر کنید تا همه آنها به پایان برسند. بدین ترتیب همه آنها را به Promise.all میفرستید و سپس Promise.all خودش به عنوان یک Promise زمانی که هر 10 Promise پاسخ داده شوند و یا هر یک از آنها رد شوند، به پایان میرسد.
به کد زیر توجه کنید:
همان طور که میبینید، ما یک ارائه را به Promise.all ارسال کردهایم و زمانی که هر سه Promise پاسخ داده شوند، Promise.all نیز پایان مییابد و خروجی در کنسول ارائه میشود.
به مثال زیر نیز توجه کنید:
در مثال فوق، Promise.all در طی 2000 میلیثانیه پس از این که خروجی به صورت یک ارائه در کنسول ارائه شود پایان مییابد.
ترتیب Promise-ها
یک نکته جالب در مورد Promise.all این است که ترتیب Promise-ها در آن حفظ میشود. نخستین Promise در ارائه به عنوان نخستین عنصر ارائه خروجی ارائه میشود، Promise دوم عنصر دوم ارائه است و همین طور تا آخر.
به مثال زیر نیز توجه کنید:
همان طور که میبینید اگر یکی از Promise-ها رد شود، همه موارد باقیمانده Promise-ها نیز شکست میخورند. در این صورت Promise.all نیز رد خواهد شد.
در برخی موارد ما به چنین موقعیتی نیاز نداریم. در واقع در این موارد لازم است که همه Promise-ها صرف نظر از این که یکی از آنها رد شود یا نه اجرا شوند و احتمالاً مورد رد شده را نیز در ادامه میتوان مدیریت کرد. مدیریت این وضعیت به صورت زیر ممکن است:
کاربردهای Promise.all
فرض کنید لازم است تعداد زیادی عملیات ناهمگام مانند ارسال انبوه ایمیلهای بازاریابی به هزاران کاربر را انجام دهید. شبه کد ساده آن چنین میتواند باشد:
مثال فوق سرراست است. اما چندان کارآمد نیست. در نقطهای از زمان، پشته بسیار سنگین میشود و جاوا اسکریپت با انبوهی از درخواستهای باز اتصال HTTP مواجه خواهد بود که میتوانند سرور را کار بیندازند.
یک رویکرد ساده و کارآمد میتواند این باشد که این کار در دستهبندیهای مختلف انجام یابد. 500 کاربرِ نخست انتخاب و ایمیلها ارسال میشوند و صبر میکنیم تا همه اتصالهای HTTP بسته شوند. سپس دسته بعدی را پردازش میکنیم و همین طور تا آخر. مثال زیر را در نظر بگیرید:
سناریوی دیگری را در نظر بگیرید. فرض کنید لازم است یک API بسازیم که اطلاعاتی را از API-های شخص ثالث میگیرد و همه پاسخها را از آن API-ها تجمیع میکند.
در این حالت Promise.all بهترین روش برای انجام این کار است. چگونگی آن را در کد زیر ملاحظه میکنید:
سخن پایانی
در پایان باید اشاره کنیم که Promise.all بهترین روش برای تجمیع یک گروه از Promise-ها در یک Promise منفرد است. این یکی از بهترین روشها برای رسیدن به «همزمانی» (Concurrency) در جاوا اسکریپت است. امیدواریم از مطالعه این نوشته بهره برده باشید.
بارگذاری مجموعه داده بزرگ در یادگیری عمیق — راهنمای کاربردی
یکی از مهمترین گامها طی فرایند «دادهکاوی» (Data Mining) و «یادگیری ماشین» (Machine Learning)، گردآوری دادهها و ساختاردهی به مجموعه داده است. این مبحث در حوزه «یادگیری عمیق» (Deep Learning) نیز مانند دیگر روشهای یادگیری ماشین مطرح است. قراردادهای گوناگونی برای ذخیرهسازی و ساختاردهی به مجموعه دادههای تصاویر روی دیسک به منظور تسریع و کارا کردن «بارگذاری» (Load) و استفاده از آنها هنگام آموزش و ارزیابی مدلیهای یادگیری عمیق وجود دارد.
هنگامی که مجموعه داده دارای ساختار باشد، کاربر میتواند از ابزارهایی مانند کلاس ImageDataGenerator در کتابخانه یادگیری عمیق«کرس» (Keras)، برای بارگذاری خودکار مجموعه دادههای «آموزش» (Train)، «تست» (Test Data Set) و «ارزیابی» (Evaluation) استفاده کند. علاوه بر آن، مولد به تدریج تصاویر موجود در مجموعه داده را بارگذاری میکند و به کاربر این امکان را میدهد تا با مجموعه دادههای کوچک و بسیار بزرگ شامل هزاران یا میلیونها تصویری که در حافظه سیستم ممکن است جا نشوند کار کند. در این مطلب، روش ساختاردهی به یک مجموعه داده تصاویر و بارگذاری تدریجی آن هنگام برازش و ارزیابی یک مدل یادگیری عمیق آموزش داده میشود. محورهای کلی مورد بررسی در این مطلب عبارتند از:
- چگونگی سازماندهی مجموعه دادههای آموزش، تست و اعتبارسنجی حاوی تصاویر در یک ساختار پوشه سازگار
- چگونگی استفاده از کلاس ImageDataGenerator برای بارگذاری تدریجی تصاویر برای یک مجموعه داده موجود
- چگونگی استفاده از مولد داده آماده شده برای آموزش، ارزیابی و انجام پیشبینی با مدل یادگیری عمیق
این آموزش به سه بخش کلی ساختار پوشه مجموعه داده، ساختار مجموعه داده نمونه و چگونگی بارگذاری تدریجی تصاویر تقسیم شده است و مباحث بیان شده در بالا طی این سر فصلها آموزش داده میشوند .
ساختار پوشه مجموعه داده
یک راهکار استاندارد برای طرحریزی دادههای تصویری به منظور مدلسازی وجود دارد. پس از آنکه تصاویر گردآوری شدند، کاربر باید ابتدا آنها را بر اساس مجموعه داده، یعنی مجموعه دادههای آموزش، تست و ارزیابی و سپس، بر اساس «دسته» (Class) تصاویر مرتبسازی کند. برای مثال، یک مساله «دستهبندی» تصاویر مفروض است که طی آن باید تصاویر خودروها را بر مبنای رنگ آنها (مثلا: خودروی قرمز، خودرو آبی و دیگر موارد) دستهبندی کرد. ابتدا، یک پوشه data/ وجود دارد که کاربر دادههای تصاویر را در آن ذخیرهسازی میکند. سپس، یک پوشه /data/train برای مجموعه داده آموزش و یک پوشه /data/test برای مجموعه داده تست وجود دارد. همچنین، این امکان وجود دارد که یک پوشه /data/validation نیز برای مجموعه داده ارزیابی در طول آموزش وجود داشته باشد. بنابراین، موارد زیر وجود دارند.
در هر پوشه مجموعه داده، زیرپوشههایی وجود دارند. در هر پوشه، یک زیر پوشه برای هر کلاس وجود دارد که فایلهای تصاویر در آن قرار دارند. برای مثال، زیرپوشهها به صورت زیر هستند.
بدین شکل، برای مثال تصاویر خودروهای قرمز در پوشه دسته مناسب قرار میگیرد. برای مثال:
باید به خاطر داشت که فایلهای مشابهی در پوشههای /red و /blue قرار نمیگیرد؛ در عوض در هر یک از این پوشهها، تصاویر متفاوتی به ترتیب از خودروهای قرمز و آبی وجود دارد. همچنین، باید به خاطر داشت که تصاویر متفاوتی در مجموعه دادههای آموزش، تست و اعتبارسنجی وجود دارد. اسامی فایلهای استفاده شده برای تصاویر معمولا اهمیتی ندارد، زیرا همه تصاویر با پسوندهای فایل داده شده فراخوانی میشوند. یک قرارداد خوب برای نامگذاری، در صورتی که امکان تغییر نام فایلها وجود داشته باشد، استفاده از اسامی است که در امتداد آنها اعداد قرار دارند (مثلا دنبالههای ترتیبی از اعداد که با چندین صفر به عنوان پیش شماره شروع میشوند)، برای مثال image0001.jpg. این راهکار در صورتی که هزاران تصویر برای هر دسته وجود داشته باشد، بسیار مناسب است.
ساختار مجموعه داده نمونه
میتوان ساختار مجموعه داده را با یک مثال که در زیر بیان شده، پی ریزی کرد. فرض میشود که کاربر در حال دستهبندی تصاویر خودروها به شیوهای که پیشتر بیان شد است. به طور مشخص، یک مساله دستهبندی دودویی، یعنی دستهبندی خودروها در دو دسته قرمز و آبی، وجود دارد. باید ساختار پوشهای که در بخش پیشین بیان شد، ساخته شود.
اکنون، پوشههای مذکور ساخته میشوند. سپس، تعدادی تصویر در هر یک از آنها قرار میگیرد. میتوان از «جستجوی تصاویر کریتیو کامنز» ( Creative Commons Image Search) [+] برای پیدا و دانلود کردن تصاویری با گواهینامههایی که استفاده از آنها را برای مصارف گوناگون مجاز میسازد استفاده کرد. در ادامه، از دو تصویر بیان شده در زیر استفاده شده است.
- تصویر خودرو قرمز از «دنیس ژارویس» (Dennis Jarvis)
- تصویر خودرو آبی از «»ویل اسمیث» (Bill Smith)


تصاویر را باید دانلود و در پوشه کاری جاری ذخیره کرد. خودرو قرمز را باید با نام «red_car_01.jpg» و خودرو آبی را با نام «blue_car_01.jpg» ذخیره کرد. اکنون، باید تصاویر متفاوتی برای هر یک مجموعه دادههای آموزش، تست و اعتبارسنجی داشت. با توجه به آنکه هدف از این مطلب شیوه ساختاردهی و بارگذاری دادهها است و برای دور نشدن از تمرکز اصلی مطلب، از فایلهای تصاویر مشابهی در هر یک از این مجموعه دادهها استفاده میشود. اما، جوری وانمود میشود که گویی آنها با یکدیگر متفاوت هستند.
بنابراین، باید کپیهایی از فایل «red_car_01.jpg» را در پوشههای /data/train/red ،/data/test/red و /data/validation/red قرار دارد. همچنین، باید کپیهایی از فایل «blue_car_01.jpg» را در پوشههای /data/train/blue/ ،data/test/blue و /data/validation/blue قرار داد. اکنون، قالب یک مجموعه داده خیلی پایهای که مشابه با ساختار درختی زیر است، ایجاد شده (ساختار درختی قابل مشاهده در زیر، خروجی دستور tree است).
data ├── test │ ├── blue │ │ └── blue_car_01.jpg │ └── red │ └── red_car_01.jpg ├── train │ ├── blue │ │ └── blue_car_01.jpg │ └── red │ └── red_car_01.jpg └── validation ├── blue │ └── blue_car_01.jpg └── red └── red_car_01.jpg
در ادامه، اسکرینشاتی از ساختار پوشهها ارائه شده است که با استفاده از پنجره Finder در «مکاواس» (macOS) گرفته شده است.
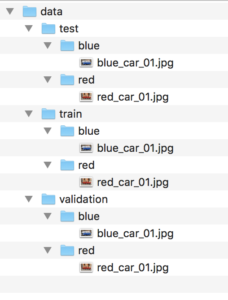
اکنون که ساختار پوشه پایهای وجود دارد، کار بارگذاری دادهها از فایل برای استفاده با مدلسازی مورد استفاده قرار میگیرد.
بارگذاری تدریجی دادهها برای مدل یادگیری عمیق
این امکان وجود دارد که کدی نوشته شود تا دادهها به صورت دستی بارگذاری شوند و دادههای آماده برای مدلسازی را بازگرداند. این کار شامل ایجاد ساختار برای مجموعه داده، بارگذاری دادههای تصاویر و بازگرداندن ورودی (آرایههای پیکسل) و خروجی (عدد صحیح دسته) میشود. خوشبختانه، نیاز به نوشتن این کد از پایه نیست. بلکه، میتوان از کلاس ImageDataGenerator فراهم شده توسط Keras استفاده کرد. مزیت اصلی استفاده از این کلاس برای بارگذاری دادهها آن است که تصاویر برای یک مجموعه داده در دستهها بارگذاری میشوند، بدین معنا که میتوان از آن هم برای بارگذاری مجموعه دادههای کوچک و هم مجموعه دادههای تصویری بسیار بزرگ با هزاران یا میلیونها تصویر استفاده کرد.
به جای بارگذاری همه تصاویر در حافظه، تنها تصاویر کافی را میتوان در حافظه برای دستههای کنونی و ریزدستههای احتمالی آینده، هنگام ارزیابی مدل یادگیری عمیق مورد استفاده قرار داد. در این مطلب، به فرایند مذکور بارگذاری تدریجی گفته میشود، زیرا مجموعه داده به تدریج از فایل بارگذاری میشود و فقط میزان دادهای که فورا مورد نیاز است را بازیابی میکند. دو مزیت دیگر استفاده از کلاس ImageDataGenerator، عبارتند از اینکه میتوان از آن برای تغییر مقایسه خودکار مقادیر تصاویر استفاده کرد و همچنین، میتواند به صورت خودکار نسخه کامل شده تصاویر را تولید کرد. این مبحث به بررسی جداگانهای نیاز دارد و از حوصله این بحث خارج است. در ادامه، بر چگونگی استفاده از کلاس ImageDataGenerator برای بارگذاری دادهها از فایل تمرکز میشود. الگوی استفاده از کلاس ImageDataGenerator به صورت زیر است.
- ساخت و پیکربندی یک نمونه از کلاس ImageDataGenerator
- بازیابی یک «تکرارگر» (Iterator) با فراخوانی تابع ()flow_from_directory
- استفاده از تکرارگر در فاز آموزش یا ارزیابی مدل
اکنون، نگاه دقیقتری به هر یک از گامها انداخته میشود. سازنده برای ImageDataGenerator، حاوی آرگومانهای زیادی برای تعیین چگونگی دستکاری دادههای تصاویر پس از بارگذاری آنها، شامل تغییر مقیاس پیکسلها و تکمیل دادهها است. نیاز به هیچ یک از این ویژگیها در این وهله نیست؛ بنابراین، پیکربندی ImageDataGenerator آسان است.
سپس، نیاز به یک تکرارگر برای بارگذاری تدریجی دادهها برای یک مجموعه داده مجرد است. این کار، نیازمند فراخوانی تابع ()flow_from_directory و تعیین پوشه مجموعه داده، مانند test ،train و validation است. تابع همچنین امکان پیکربندی جزئیات بیشتر مرتبط با بارگذاری دادهها را فراهم میکند. توجه به این نکته نیز لازم است که آرگومان «target_size» به کاربر امکان بارگذاری همه تصاویر در اندازه مشخص را میدهد؛ این قابلیت معمولا هنگام مدلسازی مورد نیاز است. پیشفرض تابع روی تصاویر مربعی با اندازه ۲۵۶ در ۲۵۶ است.
تابع همچنین امکان تعیین نوع وظیفه دستهبندی را با استفاده از آرگومان «class_mode» فراهم میکند؛ با این آرگومان میتوان به طور خاص تعیین کرد که نوع دستهبندی «دودویی» (Binary) یا دستهبندی چند دستهای «طبقهای» (Categorical) باشد. «batch_size» به طور پیشفرض برابر با ۳۲ است؛ بدین معنا که ۳۲ تصویر انتخاب شده به صورت تصادفی از سرتاسر کلاسها در مجموعه داده در هر دسته هنگام آموزش بازگردانده میشوند. گاهی ممکن است دستههای بزرگتر و گاه دستههای کوچکتر مورد نیاز باشد. همچنین، ممکن است کاربر بخواهد هنگام ارزیابی مدل دستهها را به ترتیب قطعی باز گرداند که در این صورت، باید «shuffle» روی False تنظیم شود. گزینههای زیاد دیگری نیز وجود دارد که با مطالعه مستندات API کرس میتوان با آنها آشنا شد. میتوان از ImageDataGenerator مشابهی برای آمادهسازی تکرارگرها برای پوشههای جداگانه مجموعه داده استفاده کرد. این کار هنگامی مفید واقع میشود که تغییر مقیاس پیکسل مشابهی روی چندین مجموعه داده (آموزش، تست و اعتبارسنجی) اعمال شود.
هنگامی که تکرارگر آماده شد، میتوان از آن هنگام برازش و ارزیابی یک مدل یادگیری عمیق استفاده کرد. برای مثال، برازش یک مدل با مولد داده را میتوان با فراخوانی تابع ()fit_generator روی مدل و پاس دادن تکرارگر آموزش (train_it) کسب کرد. تکرارگر اعتبارسنجی (val_it) هنگام فراخوانی این تابع با آرگومان «validation_data» قابل تعیین است. آرگومان «steps_per_epoch» باید برای آموزش تکرارگر به منظور تعریف اینکه چه تعداد دسته از تصاویر یک «دوره» (epoch) یکتا راتعریف میکند، مورد استفاده قرار میگیرد. برای مثال، اگر ۱۰۰۰ تصویر در مجموعه داده آموزش وجود داشته باشد (در سرتاسر همه دستهها) و اندازه دسته برابر با ۶۴ باشد، steps_per_epoch برابر با ۱۶ یا 1000/64 خواهد بود. به طور مشابه، اگر تکرارگر اعتبارسنجی اعمال شود، آرگومان «validation_steps» باید به منظور تعیین تعداد دستهها در مجموعه داده اعتبارسنجی یک دوره را تعریف کند.
هنگامی که مدل برازش داده شد، میتوان روی مجموعه داده تست با استفاده از تابع ()evaluate_generator و پاس دادن آن به تکرارگر تست (test_it) ارزیابی شود. آرگومان «steps» تعداد دستههای نمونه را برای تکرار گام (to step through) هنگام ارزیابی مدل پیش از توقف تعریف میکند.
در نهایت، اگر کاربر بخواهد از مدل برازش برای انجام پیشبینی روی مجموعه داده بسیار بزرگ استفاده کند، به همین شکل میتواند تکرارگری برای آن مجموعه داده بسازد (برای مثال predict_it) و تابع ()predict_generator را روی مدل فراخوانی کند.
اکنون میتوان از مجموعه داده کوچک تعریف شده در بخش قبلی برای نشان دادن چگونگی تعریف یک نمونه ImageDataGenerator و آمادهسازی تکرارگر مجموعه داده استفاده کرد. مثال کاملی از این مورد، در ادامه آمده است.
با اجرای مثال بالا، ابتدا یک نمونه از ImageDataGenerator با همه پیکربندیهای پیشفرض ساخته میشود. سپس، سه تکرارگر، برابر مجموعه دادههای دستهبندی دودویی آموزش، تست و ارزیابی ساخته میشود. هنگامی که هر تکرارگر ساخته شد، میتوان پیغام دیباگ را که تعداد تصاویر و دستههای کشف و آماده شده را گزارش میکند، مشاهده کرد. در نهایت، تکرارگر آموزش که برای برازش مدل مورد استفاده قرار خواهد گرفت تست میشود. اولین دسته از تصاویر بازیابی میشود و میتوان تصدیق کرد که اندازه دسته حاوی دو تصویر است، زیرا کلا دو تصویر وجود دارد. همچنین، میتوان تایید کرد که تصاویر بارگذاری شدند و ابعاد آنها به ۲۵۶ سطر در ۲۵۶ ستون پیکسل تغییر پیدا کرده و دادههای پیکسل تغییر مقیاس داده نشدهاند و در طیف [۲۵۵, ۰] باقی مانده است.
جمعبندی
در این مطلب، چگونگی ساختاردهی به یک مجموعه داده تصاویر و بارگذاری تدریجی آن هنگام برازش و ارزیابی یک مدل یادگیری عمیق آموزش داده شد. به طور خاص، چگونگی سازماندهی مجموعه دادههای تصویر آموزش، تست و اعتبارسنجی در یک ساختار پوشه سازگار مورد بررسی قرار گرفت. همچنین، چگونگی استفاده از کلاس ImageDataGenerator برای بارگذاری تدریجی تصاویر برای یک مجموعه داده بیان شد. در نهایت، چگونگی استفاده از یک مولد داده آماده شده برای آموزش، ارزیابی و انجام پیشبینی با یک مدل یادگیری عمیق تشریح شد.
منبع: فرادرس
ویژگی های مدرن ++C که باید بدانید — راهنمای کاربردی
زبان برنامهنویسی ++C در طی زمان تکامل زیادی یافته است. البته این تکامل در طی یک شب رخ نداده است. زمانی بود که ++C فاقد دینامیسم بود، اما اینک آن وضعیت دیگر وجود ندارد. همه چیز از زمانی که کمیته استانداردسازی ++C تصمیم گرفت اوضاع را تغییر دهد آغاز شد. این زبان برنامهنویسی از سال 2011 به صورت یک زبان دینامیک و مداوماً در حال تکامل ظاهر شده است و با معرفی ویژگی های مدرن ++C به زبانی تبدیل شده که افراد زیادی به آن دل بستهاند.
البته نباید تصور کنید که این زبان برنامهنویسی آسانتر شده است. ++C همچنان اگر نگوییم دشوارترین زبان برنامهنویسی است، دستکم یکی از دشوارترینها محسوب میشود که استفاده گستردهای دارد، اما ++C در نسخههای اخیر نسبت به نسخههای قدیمی، کاربرپسندتر شده است. در این مقاله قصد داریم برخی از ویژگیهای جدید (از نسخه 11++C به بعد که البته شاید همچنان قدیمی محسوب شود) را بررسی کنیم که هر توسعهدهندهای باید بداند.
کلیدواژه auto
هنگامی که 11++C در ابتدا کلیدواژه auto را معرفی کرد، موجب گشایش زیادی در این زبان شد. ایده auto این بود که کامپایلر ++C به جای این که شما را مجبور کند هر بار نوع داده خود را اعلان کنید، بتواند نوع دادههای شما را در زمان کامپایل کردن تشخیص دهد. بدین ترتیب داشتن انواع دادهای مانند زیر کار را بسیار راحتتر میکند:

به خط پنجم نگاه کنید. شما نمیتوانید چیزی را بدون استفاده از initializer اعلان کنید. این وضعیت در عمل مفید است. خط 5 اجازه نمیدهد کامپایلر بداند داده از چه نوعی است.
سیر تکامل auto
در ابتدا auto چیزی محدود بود. سپس در نسخههای بعدی این زبان، توان زیادی به آن داده شد.

در خط 7 و 8 از مقداردهی براکت دار استفاده کردهایم. این نیز یکی از ویژگیهایی است که در نسخه 11++C اضافه شده است. به خاطر داشته باشید که در صورت استفاده از auto باید روشی باشد که کامپایلر با استفاده از آن بتواند نوع داده را استنتاج کند. اینک سؤال مفید این است که اگر کد زیر را بنویسیم چه اتفاقی میافتد؟
آیا نتیجه اجرای کد فوق یک خطای کامپایل یا یک بردار است؟ در واقع 11++C مفهومی به شکل زیر معرفی کرده است:
این لیست با مقداردهی داخل براکت، در صورت اعلان شدن با auto به عنوان یک کانتینر سبک تلقی میشود. در نهایت همان طور که قبلاً اشاره کردیم، استنتاج نوع از سوی کامپایلر میتواند در مواردی که ساختمان داده پیچیدهای وجود دارد کاملاً مفید باشد:

در کد فوق خط 25 را بررسی کنید. عبارت auto [v1،v2] = itr.second به صورت لفظی یک ویژگی جدید در ++C محسوب میشود. نام این ویژگی «اتصال ساختیافته» (structured binding) است. در نسخههای قبلی این زبان باید هر متغیر به صورت مستقل استخراج میشد، اما اتصال ساختیافته این کار را آسانتر ساخته است.
به علاوه اگر خواسته باشید دادهها را با استفاده از ارجاع به دست آورید، کافی است نمادی به صورت زیر اضافه کنید:
عبارت لامبدا
در نسخه 11++C عبارتهای لامبدا معرفی شدند که چیزی مانند «تابعهای بینام» (anonymous functions) در جاوا اسکریپت هستند. عبارتهای لامبدا اشیای تابع هستند که فاقد نام هستند و متغیرها را روی دامنههای مختلف بر اساس نوعی ساختار منسجم به دست میآورند. همچنین میتوان آنها را به متغیر انتساب داد.
لامبداها در صورتی که قرار باشد کار سریع و کوچکی درون کد انجام شود؛ اما نوشتن یک تابع کامل مجزا برای آن وقتگیر باشد، بسیار مفید خواهند بود. استفاده رایج دیگر از این عبارتها به صورت تابعهای مقایسه است.

مثال فوق حرفهای زیادی برای گفتن دارد.
ابتدا توجه کنید که چگونه مقداردهی براکتی بار زیادی را از عهده شما بر میدارد. سپس ژنریکهای ()begin و ()end وجود دارند که آنها نیز جزء قابلیتهای اضافه شده در 11++C هستند. پس از آن تابع لامبدا به عنوان یک مقایسه کننده برای دادهها آمده است. پارامترهای تابع لامبدا به صورت auto تعریف میشوند که در نسخه 14++C اضافه شده است. تا پیش از این نسخه نمیتوانستیم از auto برای پارامترهای تابع استفاده کنیم.
توضیح براکتها
دقت کنید که چگونه عبارتهای لامبدا با یک براکت مربعی [] آغاز میشوند. بدین ترتیب دامنه لامبدا یعنی میزان نفوذی که روی متغیرها و اشیای محلی دارد تعریف میشود.
به طور خلاصه این وضعیت در ++C مدرن به شرح زیر است:
- [] – هیچ چیز دریافت نمیشود. بنابراین نمیتوانید از هیچ متغیر محلی با دامنه خارج از عبارت لامبدا استفاده کنید. در این حالت تنها میتوان از پارامترها استفاده کرد.
- [=] – شیءهای محلی (متغیرها و پارامترهای محلی) در دامنه به وسیله مقدار دریافت میشوند. میتوان از آنها استفاده کرد، اما امکان تغییر دادن آنها وجود ندارد.
- [&] – اشارهگر this به صورت «با مقدار» دریافت میشود.
- [this] – اشارهگر this با مقدار دریافت میشود.
- [a، &b] – شیء a با مقدار و شیء b با ارجاع دریافت میشود.
بدین ترتیب اگر بخواهیم دادهها را در داخل تابع لامبدا به نوعی قالب دیگر تبدیل کنیم، میتوانیم با بهرهگیری از دامنهبندی از لامبدا استفاده کنیم. برای نمونه:

در مثال فوق اگر متغیرهای محلی را با مقدار یعنی به صورت [factor] در عبارت لامبدا دریافت کنیم، نمیتوانیم factor را در 5 تغییر دهیم. زیرا چنین اجازهای نداریم.
در نهایت توجه کنید که ما val را به صورت با ارجاع دریافت میکنیم. این امر تضمین میکند که هر تغییری درون تابع لامبدا اتفاق بیفتد، در عمل موجب تغییر vector خواهد شد.
گزارههای init درون if و switch
یکی دیگر از ویژگیهای جذاب ++C هفده گزارههای init است. به مثال زیر توجه کنید:

به ظاهر اینک میتوانیم متغیرها را درون بلوک if/switch مقداردهی کرده و شرطها را بررسی کنیم. این وضعیت برای حفظ انسجام و تمیزی کد بسیار حائز اهمیت است. شکل کلی به صورت زیر است:
اجرای وظیفه فوق در زمان کامپایل با constexpr
تصور کنید نوعی عبارت برای ارزیابی دارید و مقدار آن از زمان مقداردهی اولیه به بعد تغییر نخواهد یافت. بدین ترتیب میتوان مقدار را از پیش محاسبه کرد و سپس به عنوان یک ماکرو از آن استفاده کرد. روش دیگر این است که از ویژگی constexpr که در ++C یازده ارائه شده است بهره گرفت.
برنامهنویسان علاقهمند هستند که محیط زمان اجرای برنامه را تا حد امکان سبک کنند. بنابراین اگر عملیاتی وجود داشته باشد که کامپایلر میتواند انجام دهد و بار را از عهده زمان اجرا بردارد موجب بهبود زمان اجرای برنامه خواهد شد.

کد فوق نمونه بسیار رایجی از constexpr است.
از آنجا که ما تابع محاسبه فیبوناچی را به صورت constexpr اعلان کردهایم، کامپایلر (fib(20 را از قبل در زمان کامپایل محاسبه میکند. بنابراین پس از کامپایل کردن میتواند خط زیر را:
با خط زیر جایگزین کند:
توجه کنید که آرگومان ارسالی یک مقدار const است. این یکی از نکات مهم تابعهای اعلانشده با constexpr است. آرگومانهای ارسالی باید constexpr یا const باشند؛ در غیر این صورت تابع به صورت یک تابع نرمال رفتار میکند که در زمان کامپایل هیچ محاسبه قبلی صورت نمیگیرد.
متغیرها نیز میتوانند constexpr باشند. در چنین حالتی چنان که میتوان حدس زد، این متغیرها باید در زمان کامپایل ارزیابی شوند. در غیر این صورت ممکن است با خطای کامپایل مواجه شوید.
نکته جالب این است که بعدتر و در نسخه C++17 به صورت constexpr-if و constexpr-lambda نیز معرفی شدند.
چندتاییها
چندتایی با tuple دقیقاً همانند pair مجموعهای از مقادیر با اندازه ثابت از انواع دادههای مختلف است.
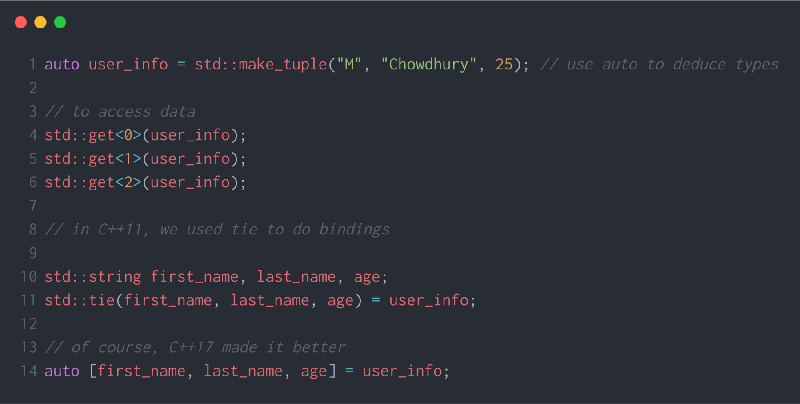
برخی اوقات استفاده از std::array به جای tuple راحتتر است. array مشابه آرایه ساده C به همراه چند کارکرد دیگر است که در کتابخانه استاندارد ++C وجود دارند. این ساختمان داده در نسخه 11++C معرفی شده است.
استنتاج آرگومان قالب کلاس
چنان که میبینید نام ویژگی فوق کاملاً گویای کارکرد آن است. از نسخه 17++C این ایده مطرح شد که استنتاج آرگومان برای قالبهای کلاس استاندارد نیز اتفاق بیفتد. تا پیش از آن این امکان صرفاً برای قالبهای تابع میسر بود. در نتیجه امکان نوشتن کد زیر مهیا شد:
استنتاج به صورت ضمنی انجام مییابد. این وضعیت در مورد tuple بسیار کار را راحتتر میکند.
توجه داشته باشید که این ویژگی در صورتی که به طور کامل با قالبهای ++C آشنا نباشید، چندان به کار شما نخواهد آمد.
اشارهگرهای هوشمند
اشارهگرها میتوانند واقعاً دردسرساز باشند. به دلیل میزانی از آزادی که زبانهایی مانند ++C در اختیار برنامه نویسان قرار میدهند، در برخی موارد ممکن است موجب شوند که این برنامه نویسان به خود آسیب بزنند. و در اغلب موارد اشارهگرها موجب وارد آمدن این آسیب میشوند.
خوشبختانه در نسخه 11++C ایده اشارهگرهای هوشمند مطرح شد. این اشارهگرها نسبت به اشارهگرهای معمولی بسیار راحتتر هستند. اشارهگرهای هوشمند به برنامه نویسان کمک میکنند تا با آزاد کردن حافظه در موارد ممکن از بروز نشت حافظه جلوگیری کنند. همچنین امنیت exception را موجب میشوند.
ما میتوانستیم در این مقاله در مورد اشارهگرهای هوشمند توضیحهای زیادی بنویسیم، اما گویا جزییات مهم زیادی در مورد آنها وجود دارد که توضیح دادن همه آنها به یک مقاله جداگانه و اختصاصی نیاز دارد.
سخن پایانی
بدین ترتیب به پایان این مقاله میرسیم. به خاطر داشته باشید که ++C عملاً ویژگیهای بسیار جدیدی در نسخههای اخیر خود افزوده است. شما میتوانید این موارد را در صورتی که علاقهمند باشید مورد بررسی قرار دهید. برای نمونه این ریپازیتوری گیتهاب (+) موارد آموزشی نسبتاً جامعی را در این خصوص گردآوری کرده است.
منبع: فرادرس
تمرین ساخت شیئ در جاوا اسکریپت (بخش دوم) — راهنمای کاربردی
این مقاله در واقع یک آزمون ارزیابی است که در آن انتظار میرود شما بتوانید از دموی توپهای جهنده که در بخش قبلی با هم ساختیم به عنوان یک نقطه شروع استفاده کرده و با بهرهگیری از مفاهیم اشیای جاوا اسکریپت برخی ویژگیهای جدید و جذاب را به این توپها اضافه کنید.
شروع
برای شروع ابتدا کدهای زیر را در فایلهایی با نام مشخص شده در یک دایرکتوری جدید روی سیستم خود کپی کنید.
فایل index-finished.html
فایل style.css
فایل main-finished.js
شرح پروژه
دموی توپهای جهندهای که در بخش قبل ساختیم بسیار جالب بود، اما اکنون میخواهیم آن را با افزودن یک دایره شیطانی که از سوی کاربر کنترل میشود، تعاملپذیرتر کنیم. این دایره شیطانی توپهایی که به درونش بیفتد را میبلعد. همچنین میخواهیم مهارتهای ساخت شیء شما را از طریق ایجاد یک شیء ()Shape که توپها و دایره شیطانی از آن به ارث میرسند ارزیابی کنیم. در نهایت میخواهیم یک شمارنده امتیاز نیز برای ردگیری تعداد توپهایی که روی صفحه باقیمانده است بسازیم.
در تصویر زیر ایدهای از آن چه قرار است در آخر این مقاله ساخته باشیم، به دست میآورید:
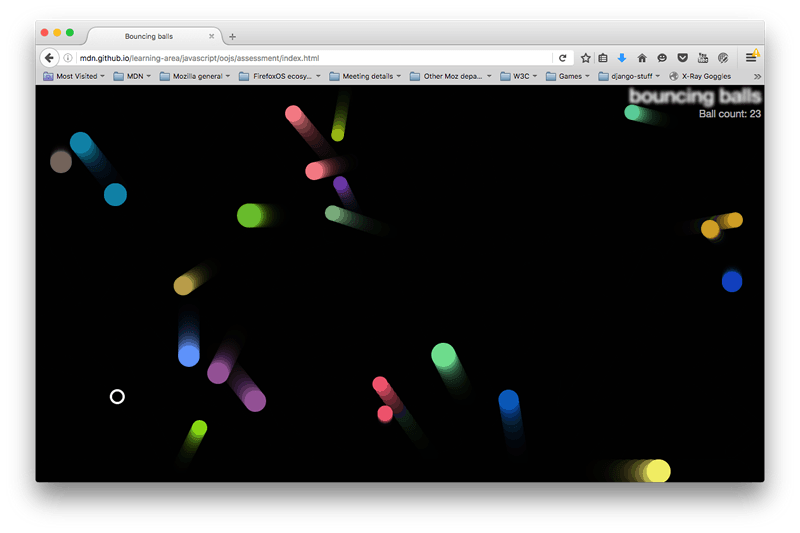
همچنین برای این که ایده بهتری از برنامه نهایی داشته باشید میتوانید به این لینک (+) مراجعه کنید. البته از شما انتظار داریم که سورس کد این مثال را نگاه نکنید و خودتان کار را به پیش ببرید.
مراحل تکمیل پروژه
در این بخش مراحلی که باید انجام دهید را توضیح دادهایم.
ایجاد اشیای جدید
قبل از هر چیز باید سازنده ()Ball قبلی را طوری تغییر دهید که به یک سازنده ()Shape تبدیل شود و یک سازنده ()Ball جدید به آن اضافه کنید:
- سازنده ()Shape باید به همان روشی که سازنده ()Ball در مقاله قبلی انجام داده بود، به تعریف مشخصههای x ،y ،velX و velY بپردازد، اما مشخصههای color و size به روش متفاوتی تعریف خواهند شد.
- در این سازنده جدید باید مشخصههایی به نام exists وجود داشته باشد که برای ردگیری وجود یا عدم وجود توپ در برنامه استفاده میشود. این مشخصه در مواردی که دایره توپها را میبلعد به کار میآید و میبایست نوع بولی (true/false) داشته باشد.
- سازنده ()Ball باید مشخصههای x ،y ،velX ،velY و exists را از سازنده ()Shape به ارث ببرد.
- همچنین باید مشخصههای color و size را به همان روشی که از سوی سازنده ()Ball تعریف شده بود در سازنده ()Shape تعریف کنیم.
- به خاطر داشته باشید که prototype و constructor سازنده ()Ball را به طرز متناسبی تنظیم کنید.
تعاریف متدهای ()draw() ،update و ()collisionDetect میتوانند به همان روشی که در مطلب قبلی تعریف کردیم باقی بمانند.
همچنین باید یک پارامتر جدید به فراخوانی سازنده (…) ()new Ball اضافه کنید. پارامتر exists باید پنجمین پارامتر و دارای مقدار true باشد.
در این مرحله کد را بارگذاری مجدد کنید. عملکرد آن به وسیله شیءهایی که بازطراحی کردهایم، باید مانند دموی قبلی باشد.
تعریف کردن ()EvilCircle
اینک زمان آن رسیده است که شخصیت منفی داستان یعنی ()EvilCircle را طراحی کنیم. در این داستان تنها یک دایره شیطانی به عنوان شخصیت منفی وجود دارد، اما به هر حال باید آن را به وسیله سازندهای که از ()Shape به ارث میرسد تعریف کنیم. شما ممکن است بخواهید در ادامه دایره دیگری به برنامه اضافه کنید که کنترل آن دست بازیکن دیگری باشد و یا چند دایره شیطانی داشته باشید که از سوی رایانه کنترل میشوند. البته شما احتمالاً نمیخواهید همه دنیا را با استفاده از یک دایره شیطانی منفرد ببلعید، اما در این مطلب ارزیابی به همان یک دایره اکتفا میکنیم.
سازنده ()EvilCircle باید x ،y ،velX ،velY و exists را از ()Shape به ارث ببرد، اما velX و velY همواره باید برابر با 20 باشند.
این کار با کدی مانند زیر ممکن است:
این کد همچنین باید مشخصههای خود را به صورت زیر تعریف کند:
- color — ‘white’
- size — 10
یک بار دیگر به خاطر داشته باشید که باید مشخصههایی که به ارث میرسند را به صورت پارامتر در سازنده تعریف کنید و مشخصههای prototype و constructor را نیز به طور متناسبی تعیین کنید.
تعریف کردن متدهای ()EvilCircle
()EvilCircle باید چهار متد داشته باشد که هر کدام را در ادامه توضیح دادهایم:
متد ()draw
این متد همان منظوری را دنبال میکند که متد ()draw شیء ()Ball داشت. یعنی وهلهای از شیء را روی بوم ترسیم میکند. روش کار آن نیز به صورت مشابه است و از این رو میتوانید تعریف Ball.prototype.draw را کپی کرده و در ادامه تغییرهای زیر را در آن ایجاد کنید:
ما میخواهیم دایره شیطانی تو پر نباشد بلکه صرفاً یک لبه بیرونی داشته باشد. این وضعیت از طریق بهروزرسانی fillStyle و ()fill به strokeStyle و ()stroke ممکن خواهد بود.
همچنین میخواهیم که ضخامت لبه این دایره کمی بیشتر باشد تا بتوان دایره شطانی را راحتتر مشاهده کرد. این وضعیت از طریق تنیم مقدار linewidth در جایی پس از فراخوانی ()beginPath ممکن خواهد بود.
متد ()checkBounds
این متد همان کاری را انجام میدهد که بخش اول تابع ()update برای شیء ()Ball اجرا میکرد، یعنی بررسی میکند که آیا دایره شیطانی با لبه صفحه برخورد میکند یا نه و از این کار ممانعت میکند. در این مورد نیز میتوانید بخش زیادی از تعریف Ball.prototype.update را کپی کنید، اما چند تغییر را به صورت زیر باید در آن ایجاد نمایید:
شما باید دو خط آخر را پاک کنید، چون ما نمیخواهیم موقعیت دایره شیطانی را در هر فریم به صورت خودکار بهروزرسانی کنیم، بلکه آن را به طرز دیگری که در ادامه مشاهده میکنید، جابجا خواهیم کرد.
درون گزارههای ()if، اگر تستها مقدار true بازگشت دهند، لازم نیست velX/velY بهروزرسانی شوند، چون ما میخواهیم به جای آن مقدار x/y را تغییر دهیم تا دایره شیطانی با یک جهش خفیف به صفحه بازگردد. افزودن یا کسر کردن مشخصه size دایره شیطانی نیز میتواند مفید باشد.
متد ()setControls
این متد یک شنونده رویداد onkeydown به شیء window اضافه میکند به طوری که وقتی کلید خاصی روی کیبورد فشرده شود، میتوانیم دایره را به اطراف جابجا کنیم. قطعه کد زیر را میتوانید درون تعریف متد قرار دهید:
بنابراین هر زمان که کلیدی فشرده میشود، مشخصه keyCode شیء رویداد مورد بررسی قرار میگیرد تا مشخص شود کدام کلید فشرده شده است. اگر این کلید یکی از کلیدهای تعریف شده باشد در این صورت دایره شیطانی در جهتهای چپ/راست/بالا/پایین حرکت میکند.
به عنوان نکته جانبی تلاش کنید بدانید که کدهای کلید تعیین شده به کدام کلیدهای کیبورد نگاشت میشوند. نکته جانبی دوم نیز این است که بررسی کنید چرا باید کدی مانند زیر داشته باشیم؟
و اقدام به تعیین موقعیت درون آن بکنیم؟ راهنمایی: این مورد به دامنهبندی مرتبط است.
متد ()collisionDetect
این متد به روشی کاملاً مشابه متد ()collisionDetect در شیء ()BAll عمل میکند و از این رو میتوانید آن کد را به عنوان مبنایی برای این متد جدید کپی کنید. اما چند تفاوت کوچک وجود دارند که در ادامه توضیح میدهیم:
در گزاره if بیرونی دیگر نیازی به بررسی این که توپ موجود در مرحله تکرار کنونی همان توپی است که بررسی میشود نداریم، چون دیگر چنین توپی وجود ندارد و با یک دایره شیطانی طرف هستیم! در عوض باید بررسی کنیم که آیا توپی که بررسی میشود وجود دارد یا نه. اگر توپ وجود نداشته باشد، به این معنی است که قبلاً از سوی دایره بلیعده شده است و از این رو نیازی به بررسی مجدد آن نداریم.
در گزاره if داخلی دیگر نیازی به تغییر دادن رنگهای اشیا در زمان تشخیص تصادم نداریم. در عوض باید هر توپی را که با دایره شیطانی برخورد میکند به صورت ناموجود علامتگذاری کنیم. آیا روش انجام این کار را میدانید؟
قرار دادن دایره شیطانی در برنامه
اکنون کار تعریف کردن دایره شیطانی به پایان رسیده است و باید عملاً آن را در صفحه ببینیم. به این منظور باید تغییراتی در تابع ()loop خود ایجاد کنیم.
- قبل از هر چیز، یک وهله جدید از دایره شیطانی (با تعیین پارامترها) میسازیم سپس متد ()setControls آن را فراخوانی میکنیم. دقت کنید که انجام این دو کار تنها یک بار صورت میگیرد و در هر تکرار حلقه نباید مجدداً اجرا شود.
- درزمانی که حلقه شروع به بررسی همه توپها و فراخوانی تابعهای ()draw() ،update و ()collisionDetect برای هر کدام از آنها میکند، باید مطمئن شویم که این کار صرفاً برای توپهای موجود یعنی آنهایی که قبلاً از سوی دایره شیطانی بلعیده نشدهاند انجام مییابد.
- متدهای ()draw() ،update و ()collisionDetect وهله دایره شیطانی را در هر بار تکرار حلقه فراخوانی کنید.
پیادهسازی شمارنده امتیاز
برای پیادهسازی بخش شمارنده امتیاز باید مراحل زیر را طی کنید:
- در فایل HTML یک عنصر <p> درست زیر عنصر <h1> اضافه کنید که شامل متن « :Ball count» باشد.
- در فایل CSS قاعده زیر را به انتهای فایل اضافه کنید:
- در فایل جاوا اسکریپت، بهروزرسانیهای زیر را اجرا کنید:
- متغیری بسازید که یک ارجاع به پاراگراف نگهداری کند.
- شماره تعداد توپهای روی صفحه را به هر نوعی که دوست دارید حفظ کنید.
- هر بار که توپی به صفحه اضافه میشود، شماره را افزایش دهید و آن را روی صفحه بهروزرسانی کنید.
- هر بار که توپی از سوی دایره شیطانی بلعیده میشود، شماره را کاهش داده و آن را روی صفحه بهروزرسانی کنید.
نکات و سرنخها
این ارزیابی کاملاً چالشبرانگیز است و از این رو باید هر گام را به آرامی و با دقت طی کنید. شاید بهتر باشد یک کپی جداگانه از هر مرحله که موفق شدید عملیاتی کنید حفظ کنید، بدین ترتیب میتوانید در صورت بروز مشکل به آخرین نسخهای که کار میکند بازگردید.
سخن پایانی
اگر این بخش ارزیابی را به صورت قسمتی از این دوره کامل از سلسله مقالات آموزش جاوا اسکریپت مطالعه میکنید، اینک باید بتوانید کار خود را در اختیار یک مربی قرار دهید تا به شما نمره بدهد. اگر این سری مقالات را به صورت خودآموز دنبال میکنید، میتوانید کدهایی که نوشتهاید را با نسخه کامل شده (+) مقایسه کنید و کار خود را مورد ارزیابی قرار دهید.