طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیکتابخانه React Native Navigation — راهنمای شروع به استفاده
در این مطلب به معرفی روش ساخت اپلیکیشنهای ریاکت با استفاده از نسخه کتابخانه React Native Navigation (+) میپردازیم. نسخه دوم کتابخانه React Native Navigation اخیراً انتشار یافته است. به همین مناسبت در این نوشته تلاش کردهایم به معرفی و بررسی آن بپردازیم. این کتابخانه یک پیادهسازی از ناوبری نیتیو و نه یک پیادهسازی مبتنی بر جاوا اسکریپت است. این بدان معنی است که این کتابخانه به طور معمول عملکرد بالاتری دارد و از تعاملها و گذار صفحه روانتری در مقایسه با دیگر راهحلهایی که پیادهسازی نیتیو ندارند برخوردار است.
نسخه 2 کتابخانه React Native Navigation در واقع یک بازنویسی از نسخه اول این کتابخانه است که برخی از مشکلات آن را که در انتشار اولیه پیدا شدند رفع کرده است. در این راهنما روش ساخت یک گردش کار احراز هویت واقعی را میسازیم که یک شبیهسازی از حالت احراز هویت با استفاده از AsyncStorage است. البته شما میتوانید از هر ارائهدهنده سرویس احراز هویت که خودتان انتخاب میکنید بهره بگیرید.
ارزش استفاده از گردش کار احراز هویت به عنوان دمو در این راهنما آن است که میتوانیم با سطح نسبتاً بزرگی از API مربوط به React Native Navigation آشنا شویم و با ناوبری مبتنی بر stack و tab کار کنیم. همچنین شیوه حل یک مسئله واقعی را در هنگام ساختن یک اپلیکیشن مشاهده خواهیم کرد که مسئلهی ساخت ناوبری برای ملاحظات احراز هویت کاربر است.
گردش کار چگونه است؟
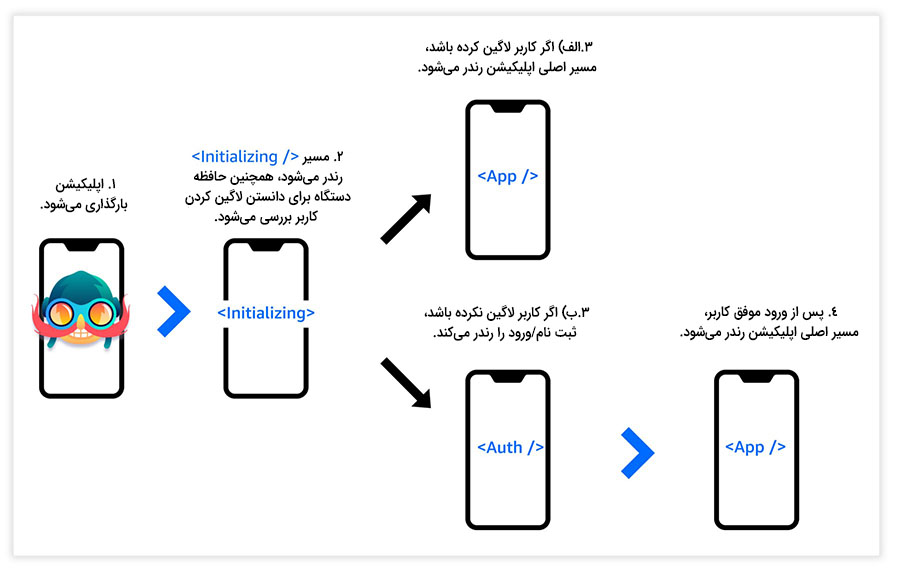
هنگامی که اپلیکیشن بارگذاری میشود، یک کامپوننت مقداردهی (Initializing) ابتدایی را بارگذاری میکنیم. همزمان بررسی میکنیم که آیا کاربری در حافظه دستگاه ذخیره شده است یا نه. اگر کاربری در حافظه دستگاه موجود باشد، مسیر Home را در یک ناوبری مبتنی بر stack رندر میکنیم.
اگر کاربری در حافظه دستگاه وجود نداشته باشد، کامپوننتهای auth (یعنی SignIn و SignUp) را در یک ناوبری مبتنی بر tab پیگیری میکنیم.
دقت کنید که این مقاله بخش اول یک مقاله دوبخشی است که در هر یک از بخشهای آن مطالب زیر عرضه میشوند:
- بخش اول: ایجاد گردش کار ناوبری و احراز هویت سر به سر با احراز هویت ساختگی برای استفاده با هر ارائهدهنده خدمات احراز هویت.
- بخش دوم: تعویض احراز هویت ساختگی با احراز هویت واقعی با استفاده از Amazon Cognito
سرآغاز
در آغاز کار باید یک پروژه ریاکت نیتیو را با استفاده از React Native CLI بسازیم:
react-native init RNNav2
سپس از npm یا yarn برای نصب ناوبری ریاکت نیتیو بهره میگیریم:
npm install react-native-navigation@alpha # or yarn add react-native-navigation@alpha
اینک باید وابستگیهای نیتیو را لینک کنیم و مقداری کد نیتیو نیز بنویسیم.
برای کسب راهنمایی در مورد روش یکپارچهسازی کتابخانه در iOS به این صفحه (+) مراجعه کنید. برای کسب راهنمایی در خصوص روش ادغام کتابخانه در سیستم عامل اندروید به این صفحه (+) رجوع کنید.
ایجاد فایلها
در این مرحله فایلهایی که برای این اپلیکیشن لازم هستند را ایجاد میکنیم. ابتدا یک پوشه به نام src در دایرکتوری root ایجاد میکنیم تا همه چیز را در آن جای دهیم:
mkdir src
سپس فایلهای زیر را در دایرکتوری src میسازیم:
cd src touch config.js Home.js Initializing.js SignIn.js SignUp.js screens.js navigation.js Screen2.js
کارکرد این فایلها را در ادامه توضیح دادهایم:
فایل config.js: این فایل برخی اطلاعات پیکربندی مقدماتی اپلیکیشن را در خود جای داده است که در مورد مثال ما شامل کلید AsyncStorage برای بازیابی کاربر از حافظه است.
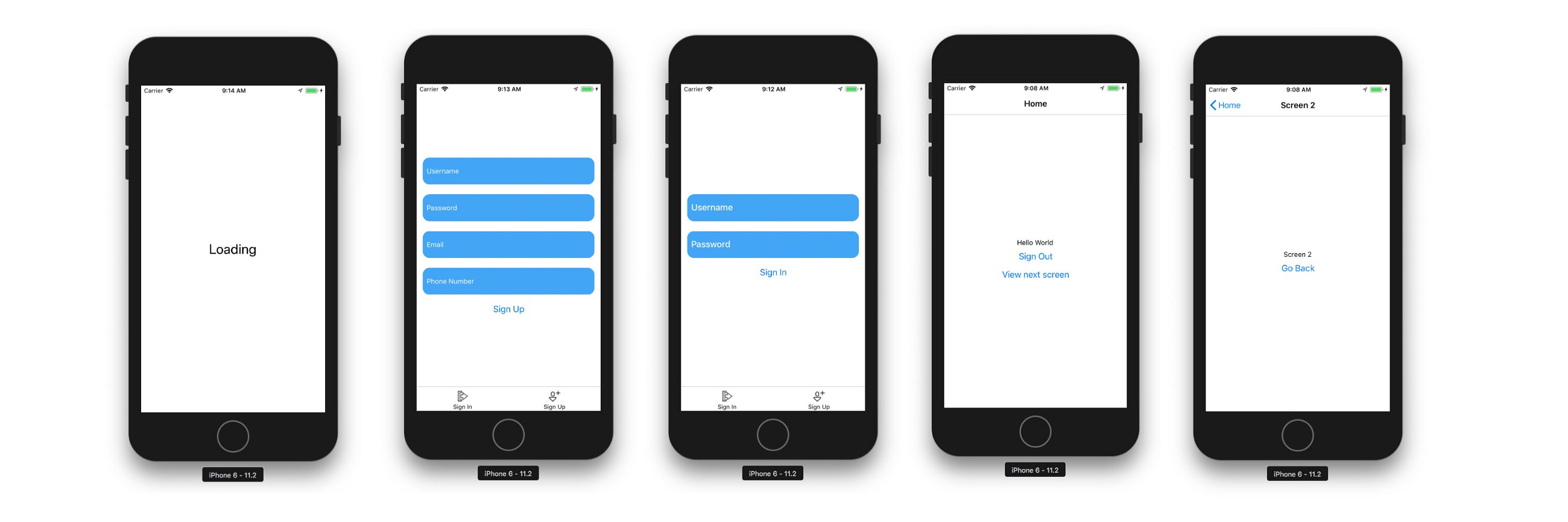
فایل Home.js: این فایل در صورت وارد شدن کاربر به حساب، شامل کامپوننت خواهد بود.
فایل Initializing.js: این فایل منطق مقداردهی اولیه را در خود جای میدهد و در زمان بارگذاری اپلیکیشن یک پیام برای کاربر نمایش میدهد.
فایل Signin.js / SignUp.js: این فایلها شامل فرمهای ثبت نام و ورود کاربر هستند. در فایل Signin.js یک بازهدایت کاربر به صفحه Home نیز تعبیه شده است.
فایل screens.js: این فایل پیکربندی صفحه را برای کتابخانه React Native Navigation در خود جای داده است.
فایل navigation.js: این فایل تابعهای ناوبری را در خود جای میدهد. ما دو تابع اصلی به نامهای ()goToAuth و ()goHome داریم.
فایل Screen2.js: این فایل شامل کامپوننت دیگری برای ناوبری به/از صفحه اصلی اپلیکیشن است که از ناوبری پشتهای stack بهره میگیرد.
ثبت کردن صفحهها
در زمان استفاده از React Native Navigation باید هر یک از صفحهها را که در اپلیکیشن ما استفاده خواهد شد ثبت کنیم.
به این منظور از متد registerComponent در کتابخانه React Native Navigation استفاده میکنیم. ما همه صفحههایی را که میخواهیم مقداردهی کنیم، در یک تابع منفرد قرار میدهیم و آن را پیش از ایجاد root ناوبری خود فراخوانی میکنیم.
در این کد یک تابع را ایجاد و اکسپورت کردهایم که ()Navigation.registerComponent را روی هر کامپوننتی که میخواهیم در ناوبری خود داشته باشیم، فراخوانی میکند.
ثبت اپلیکیشن
سپس فایل index.js را طوری بهروزرسانی میکنیم که پشته ناوبری ابتدایی اپلیکیشن تنظیم و مقداردهی شود.
در کد فوق تابع registerScreens را ایمپورت و فراخوانی میکنیم.
همچنین ریشه ابتدایی پشته اپلیکیشن را با فراخوانی Navigation.setRoot تعیین میکنیم و مسیرهای اولیه را که میخواهیم اپلیکیشن ما رندر کند به آن ارسال میکنیم. در این مورد root یک کامپوننت منفرد، به نام صفحه Initializing خواهد بود.
ایجاد تابعهای ناوبری
اکنون، نوبت ایجاد چند تابع با قابلیت استفاده مجدد رسیده است که میتوانیم از آن برای تعیین ریشه پشتههای مسیر درون اپلیکیشن بهره بگیریم.
مسیر ریشه یا root همان جایی است که پشته مسیر اصلی را در آن تعریف میکنیم. ما میخواهیم گزینه ریست کردن پشتهی ریشه را به مسیرهای احراز هویت و یا در صورت وارد شدن کاربر، به خود اپلیکیشن واقعی در اختیار داشته باشیم:
تصاویری که برای برگههای فوق استفاده میکنیم، به صورت زیر هستند. شما میتوانید آنها را ذخیره کرده و مورد استفاده قرار دهید.
تصویر برگه ورود (SignIn):
![]()
تصویر برگه ثبت نام (SignUp):
![]()
در فایل navigation.js دو تابع وجود دارد:
- goToAuth – این تابع پشته مسیر ریشه ما را به پیکربندی مسیر bottomTabs تنظیم میکند. هر برگه یک کامپوننت است که نام و برخی گزینهها برای آن پیکربندی شده است.
- goHome – این تابع پشته مسیر را به صورت ناوبری stack تعیین میکند و یک کامپوننت منفرد را به آرایه فرزندان یعنی کامپوننت Home ارسال میکند.
ذخیرهسازی کلید AsyncStorage در یک فایل پیکربندی
ما به بررسی AsyncStorage میپردازیم تا ببینیم آیا کاربر قبلاً ثبت نام کرده است یا نه. این کار در چند فایل صورت میگیرد. کلید AsyncStorage را در یک فایل جداگانه ذخیره میکنیم تا بتوانیم آن را به سادگی مورد استفاده مجدد قرار دهیم.
ایجاد صفحات
اکنون همه پیکربندیهای ناوبری را که لازم داشتیم ایجاد کردهایم و نوبت به آن رسیده است که صفحهها و کامپوننتهایی که مورد استفاده قرار خواهیم داد را بسازیم.
فایل Initializing.js

اگر به کلاس componentDidMount نگاه کنید میبینید که اغلب کارهای عمده در این فایل صورت میگیرند. ما AsyncStorage را بررسی میکنیم تا ببینیم آیا کاربری در حافظه دستگاه ذخیره شده است یا نه و در صورتی که چنین حالتی وجود داشته باشد صفحه Home را بارگذاری میکنیم و در غیر این صورت مسیرهای Auth یعنی SignIn و SignUp را بارگذاری خواهیم کرد.
زمانی که کلاس componentDidMount منطق مورد نیاز برای بررسی ذخیره شدن کاربر در دستگاه را اجرا میکند؛ یک پیام بارگذاری را برای کاربری نمایش میدهیم. سپس پشته مسیر را بر مبنای این که کاربر موجود است یا نه ریست میکنیم.
فایل Home.js
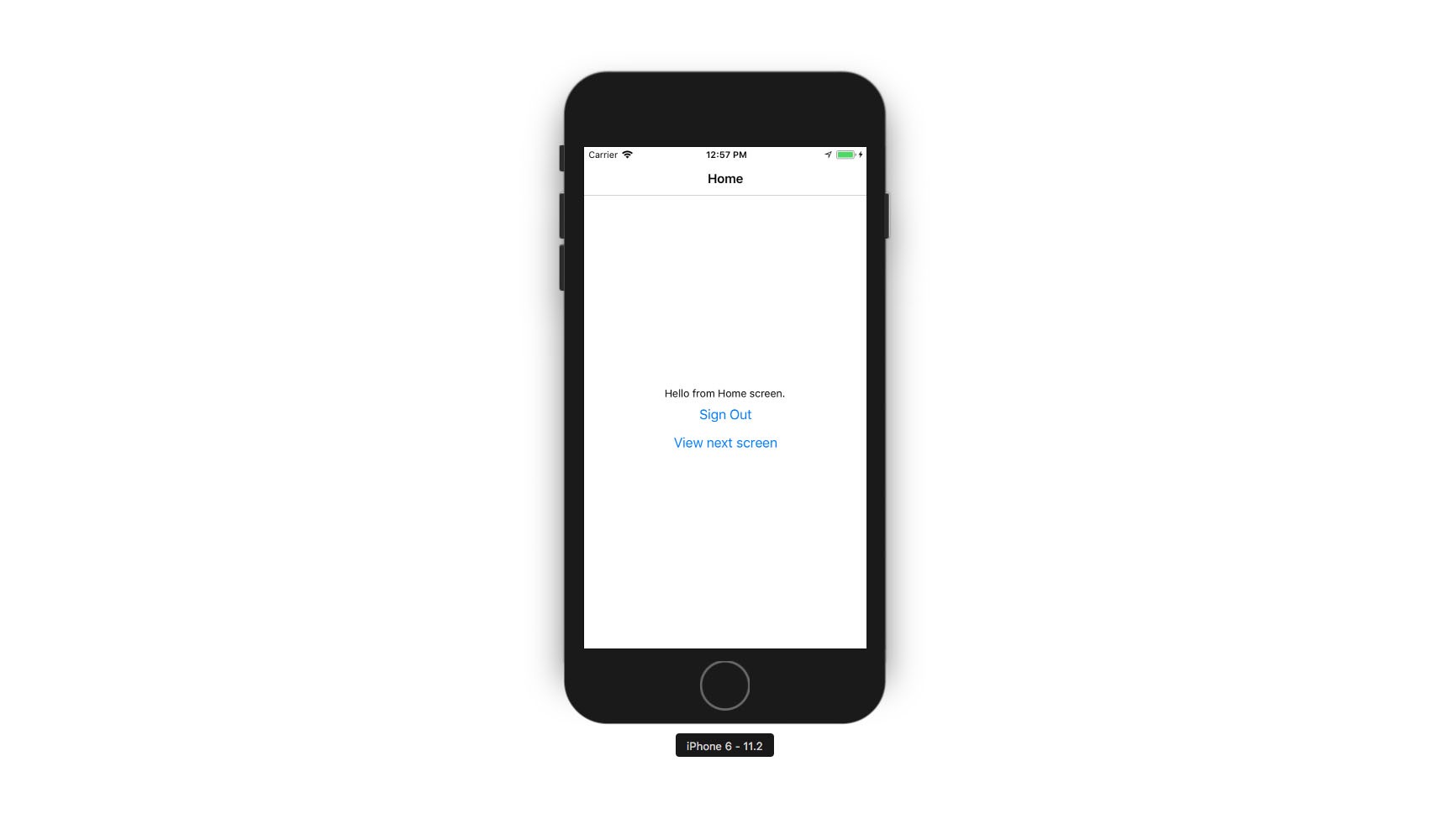
در این فایل یک پیام ابتدایی را برای کاربر رندر میکنیم و این گزینه را در اختیار وی قرار میدهیم که یا از برنامه خارج شود و یا به مسیر دیگری برود.
یک نکته متفاوت که باید در این بخش مورد اشاره قرار دهیم، روش فراخوانی متدهای ناوبری است. ما به جای استفاده از props مانند نسخه قدیمی (this.props.navigator.push) یعنی API مربوط به Navigation را ایمپورت کرده و Navigation.push را فراخوانی میکنیم.
همچنین متوجه یک تابع کلاس استاتیک به نام ()get options میشویم. این تابع را میتوان به تعریف کامپوننت ریاکت صفحه اضافه کرد و سبکبندی و مشخصهها را به ظاهر ناوبری افزود. در مورد مثال مورد بررسی، ما صرفاً یک مشخصه عنوان برای topBar استفاده کردهایم.
فایل Screen2.js

این فایل یک صفحه کاملاً ابتدایی است که صرفاً برای نمایش ناوبری در یک ناوبری پشتهای از صفحه Home مورد استفاده قرار میدهیم. نکتهای که باید اشاره کرد، شیوه فراخوانی تابع Navigation.pop است. این روش نیز از نسخه قدیمی API که در آن از props استفاده میشد (this.props.navigator.pop) متفاوت است و در نسخه 2 از API Navigation ایمپورت شده از کتابخانه React Native Navigation با نام استفاده میکنیم.
فایل SignUp.js

فایل SignUp.js در حال حاضر صرفاً یک محفظه خالی برای فرم ثبت نام محسوب میشود. میتوان از این محفظه برای پیادهسازی سرویس احراز هویت مورد استفاده بهره گرفت. در بخش بعدی این مقاله ما این فایل را طوری بهروزرسانی میکنیم که یک فرم ثبت نام واقعی با استفاده از AWS Amplify و Amazon Cognito باشد.
فایل SignIn.js
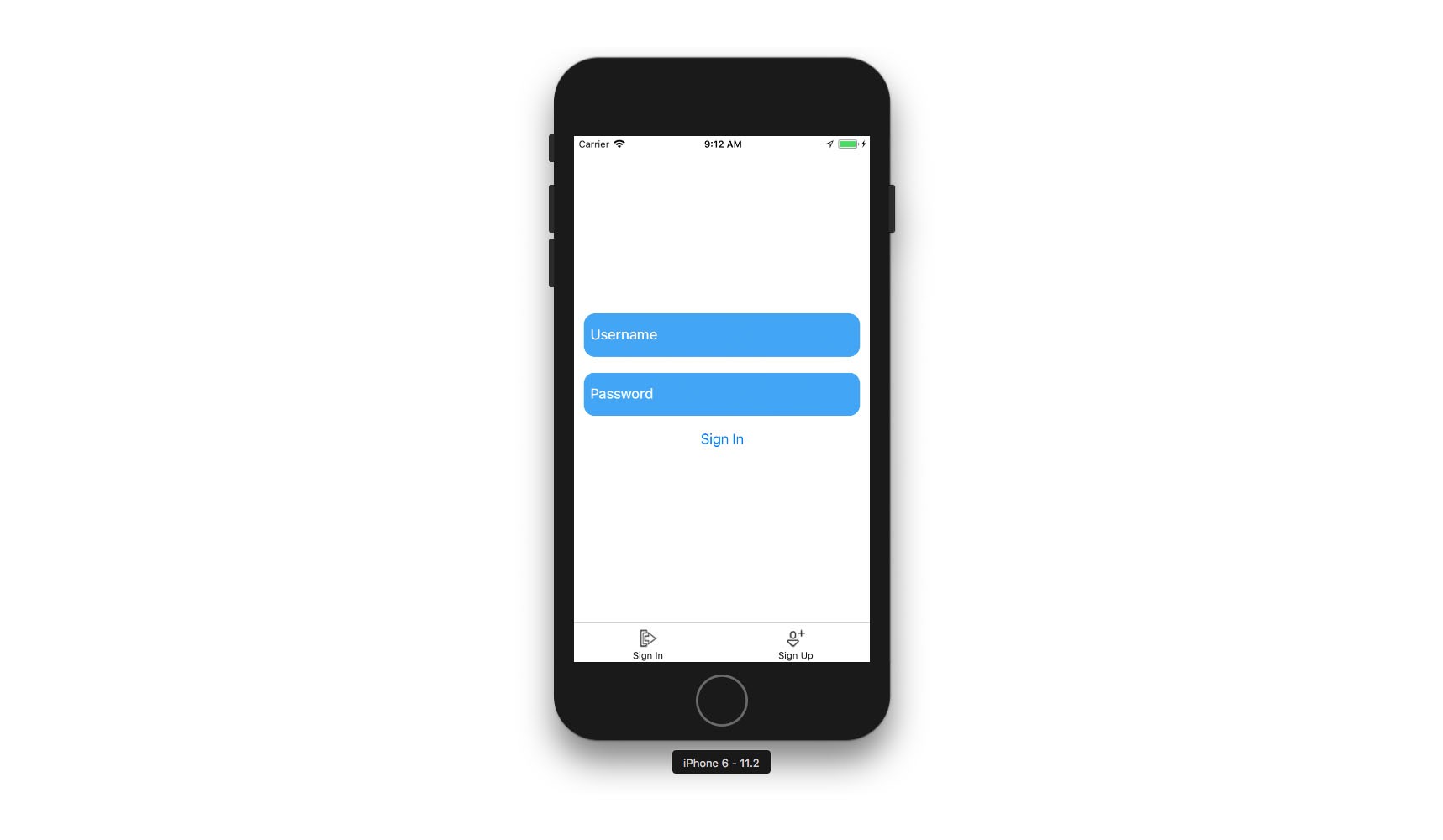
فایل SignIn.js
این کامپوننت شامل یک فرم ثبت نام ساده است. در متد کلاسی signIn یک ثبت نام موفق را با تعیین مشخصه نام کاربری در AsyncStorage شبیهسازی کردهایم و کاربر را به صفحه Home هدایت میکنیم. اینک باید بتوانیم اپلیکیشن را اجرا کنیم:
react-native run-ios # or react-native run-android
کد نهایی این پروژه را میتوانید در این ریپوی گیتهاب (+) ملاحظه کنید.
برای مطالعه قسمت بعدی این مطلب میتوانید روی لینک زیر کلیک کنید:
منبع: فرادرس
ویجت های دسترس پذیری فلاتر برای افراد کم توان — راهنمای پیشرفته
بسیاری از کاربران موبایل دارای محدودیتهای بینایی، فیزیکی یا ناشی از کهولت سن هستند و این موارد میتوانند مانعی جدی بر سر دیدن و استفاده از صفحههای لمسی باشند. همچنین کاربرانی وجود دارند که قوه شنوایی ضعیفی دارند و بدین ترتیب نمیتوانند صدای نوتیفیکیشنها و هشدارهای صوتی را بشنوند. بر اساس گزارش انجمن جهانی سلامت، بیش از یک میلیارد انسان با نوعی ناتوانی جسمی زندگی میکنند و بین 110 تا 190 میلیون نفر به دلیل چالشهایی که دارند، قادر به انجام وظایف زندگی روزمره خود نیستند. فناوری، به شرط طراحی صحیح میتواند تأثیر مثبت شگرفی روی زندگی چنین افرادی داشته باشد. فناوری میتواند افرادی را که با چنین مشکلاتی مواجه هستند، توانمند کند و آنها را قادر سازد که به بهرهوری و استقلال بیشتری دست پیدا کنند.
همه کاربران موبایل به یک روش با اپلیکیشنهای موبایل تعامل پیدا نمیکنند. از این رو همواره باید توجه داشته باشید که اپلیکیشنهای خود را برای همه افراد به شیوهای مناسب طراحی کنید. پیادهسازی صحیح دسترسپذیری میتواند منجر به بهبود کیفیت اپلیکیشن شما شود و تعداد نصبها را افزایش دهد. همچنین تأثیر زیادی روی میزان وفاداری کاربران به اپلیکیشن شما خواهد داشت.
در این مقاله قصد داریم نگاهی به ویجتهای دسترسپذیری فلاتر و شیوه کارکرد آنها داشته باشیم. فلاتر یک فریمورک برای برنامهنویسی کراس پلتفرم است که از سوی گوگل عرضه شده است. اگر میخواهید آشنایی بیشتری با فلاتر پیدا کنید، پیشنهاد میکنیم به مطلب زیر مراجعه کنید:
چگونه دسترسپذیری یک اپلیکیشن فلاتر را افزایش دهیم؟

فلاتر سه کامپوننت دارد که از دسترسپذیری پشتیبانی میکنند و در ادامه آنها را یک به یک بررسی میکنیم.
فونتهای بزرگ
برخی افراد زمانی که پیر میشوند دیگر نمیتوانند به خوبی ببینند و بسیاری دیگر نیز از بدو تولد با نقص بینایی مواجه هستند. این افراد غالباً مشکلاتی در خواندن متنهایی با اندازه پیشفرض که اغلب ما استفاده میکنیم، دارند. این نقیصه چنان شایع است که شاید یک میلیارد انسان یا بیشتر را درگیر کرده است. از این رو یکی از مهمترین موارد در زمان طراحی اپلیکیشن این است که بررسی کنیم وقتی کاربری میخواهد در بخش گزینههای دسترسپذیری، متن را بزرگ کند، اندازه متن به طرز صحیح افزایش پیدا کند.
در فلاتر محاسبات اندازه متن به صورت خودکار مدیریت میشوند. ویجت Text یک مشخصه به نام textScaleFactor دارد که به بیان ساده در آن اندازه فونت تعیین شده در مقدار textScaleFactor ضرب میشود تا اندازه فونتی که واقعاً روی صفحه و پیکسلهای منطقی رندر خواهد شد به دست آید. بنابراین اگر میخواهید اندازه متن 150% اندازه نرمال باشد، باید مقدار textScaleFactor را برابر با 1.5 تنظیم کنید.
یک نکته که باید همواره در خاطر داشته باشید این است که اگر textScaleFactor را به صورت دستی تنظیم کنید، محاسبات خودکار اندازه متن از تنظیمات دسترسپذیری کاربر نادیده گرفته میشوند. از این رو تنظیمات دسترسپذیری کاربر دیگر کار نخواهد کرد. اگر این وضعیت منجر به مشکل عمدهای برای کاربر شود، ممکن است کاربر تصمیم به لغو کردن نصب برنامه بگیرد.
اگر هیچ مقداری برای این مشخصه تعیین نکنید، مقدار بازگشتی MediaQueryData.textScaleFactor به همراه متغیر context مرتبط و یا در صورت عدم وجود context مقدار بازگشتی برابر با 1.0 خواهد بود که تأثیری روی اندازه متن ندارد.
اما مقیاسپذیر ساختن متن کافی نیست. اگر در زمان ایجاد «طرحبندی» (Layout) شرایط افزایش اندازه متن از سوی کاربران را به درستی پیشبینی نکرده باشید، ممکن است متن برش یابد و در نهایت موجب بروز مشکلات بیشتری برای کاربر شود که شاید در صورت عدم استفاده از دسترسپذیری اصلاً پیش نمیآمدند. به همین دلیل است که همواره باید کاملاً مطمئن شوید که متون مختلف در زمان تغییر تنظیمات دسترسپذیری به درستی نمایش پیدا کنند.
کنتراست کافی
هنگام پیادهسازی یک اینترفیس اپلیکیشن، باید رنگهای پیشزمینه و پسزمینه را با کنتراست رنگ کافی تعیین کنیم. «نسبت کنتراست» محاسبهای است که در زمان مشاهده یک اینترفیس روی دستگاه در شرایط نور شدید به دست میآید. این نسبت از 1 تا 21 متغیر است و افزایش یافتن آن به معنی کنتراست بالاتر است. ابزارهای زیادی مانند این ابزار (+) برای محاسبه نسبت کنتراست دو رنگ مجاور وجود دارند.
دستورهای W3C به صورت زیر هستند:
- دست کم 1:4.5 برای متن کوچک (کمتر از 18 پوینت از فونت معمولی یا 14 پوینت از فونت bold)
- دست کم 1:3.0 برای متنهای بزرگ (18 پوینت و بالاتر برای فونت معمولی و یا بالاتر از 14 پوینت برای فونتهای bold)
ابزارهای قرائت صفحه
ابزارهای قرائت صفحه برای توانمندسازی افراد با نقص بینایی در جهت استفاده از اپلیکیشنهای شما مانند هر نرمافزار دیگری ضروری هستند.
در اندروید، گوگل یک ابزار قرائت صفحه به نام TalkBack تعبیه کرده است. کاربران با استفاده از TalkBack میتوانند با استفاده از ژستها (یا سوایپ کردن) و یا کیبورد اکسترنال ورودی داشته باشند. هر عمل که از سوی کاربر اجرا شود یک خروجی صوتی ارائه میشود که به کاربر امکان میدهد بداند سوایپ وی موفق بوده است. این ابزارها میتوانند متن را برای کاربر بخوانند و کافی است وی تنها یک پاراگراف را لمس کند تا TalkBack شروع به خواندن آن بکند.
TalkBack
TalkBack میتواند به سادگی با استفاده از فشردن همزمان دکمههای صدا روی دستگاه به مدت 3 ثانیه فعال شود. از طریق منوی تنظیمات هم میتوان آن را فعال کرد.
VoiceOver
اپل نیز در iOS، یک نرمافزار قرائت صفحه دارد که VoiceOver نامیده میشود. VoiceOver نیز مانند TalkBack از ورودیهای با استفاده از ژست پشتیبانی میکند. با استفاده از VoiceOver میتوان نتایج اقدامات کاربر را به صورت شنیداری دریافت کرد. VoiceOver میتواند با کلیک کردن سه بار پشت سرهم دکمه home فعال شود، البته قبلاً بایستی VoiceOver را به میانبرهای دسترسپذیری اضافه کرده باشید. همچنین میتوانید با استفاده از منوی تنظیمات آن را فعال کنید.
اکنون که یک نرمافزار قرائت صفحه داریم، میخواهیم بدانیم وقتی روی یک اپلیکیشن فلاتر اجرا میشود چه اتفاقی میافتد. از آنجا که به محض ایجاد یک پروژه جدید در فلاتر یک اپلیکیشن نمونه به دست میآوریم، نیاز نیست که اپلیکیشن خاص خود را بنویسیم تا بتوانیم از امکان قرائت صفحه بهرهمند شویم. نکتهای که باید به خاطر داشته باشید این است که باید این کار را روی یک دستگاه واقعی انجام دهید و در این مورد، شبیهساز کار نمیکند.
روی دستگاه خود ابزار قرائت صفحه را فعال کرده و اپلیکیشن پیشفرض را باز کنید. بدین ترتیب خواهید دید که ابزار قرائت صفحه شروع به خواندن یک متن میکند. در ادامه نگاهی به طرز کار آن خواهیم داشت.
ویجت Semantics
فلاتر چندین ویجت دسترسپذیری در اختیار ما قرار میدهد که امکان ایجاد اپلیکیشنهایی با امکان دسترسی گسترده برای همه افراد را فراهم میسازد. میدهد. نخستین ویجت که بررسی میکنیم Semantics نام دارد. Semantics درخت ویجت را با توصیف فرزندانش، حاشیهنویسی میکند. شما میتوانید از این حاشیهنویسیها برای اعلام انواع چیزهای مختلف به افراد با نقص بینایی استفاده کنید.
برای نمونه میتوانید یک حاشیهنویسی اضافه کنید تا به این افراد اعلام کنید که متن چه هست، آیا یک دکمه انتخاب شده است و حتی میتوانید به کاربر چیزی در مورد کاری که انجام میدهد و همچنین موارد تپ کردن یا تپ ممتد (Long Tap) را با سرنخهای onTap و onLongPress به وی اعلام کنید.
بنابراین زمانی که میخواهید توصیفی در مورد یک ویجت داشته باشید، میتوانید آن را درون یک ویجت Semantics قرار دهید. بدین ترتیب متوجه میشوید که نرمافزار قرائت صفحه چگونه میتواند اپلیکیشن نمونه ما را بخواند.
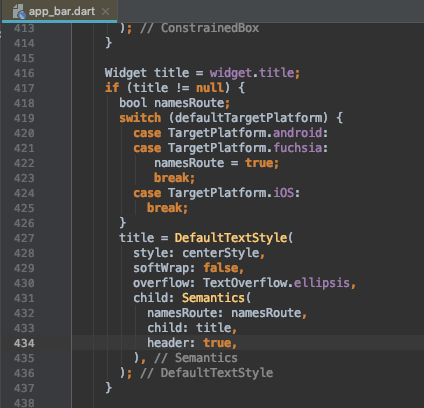
اگر کد فوق را بررسی کنید، میبینید که در صورت وجود یک عنوان، درون یک ویجت Semantics قرار میگیرد. در ویجتهای فلاتر میبینیم که در اغلب موارد ویجتهای دسترسپذیری از قبل پیادهسازی شدهاند. اما اگر Semantics را از کد منبع پاک کنید و اپلیکیشن را مجدداً اجرا کنید، میبینید که این بار TalkBalk دیگر نمیتواند عنوان را بخواند.
هنگامی که یک درخت ویجت ایجاد میکنید، فلاتر نیز یک درخت Semantics به همراه SemanticNodes ایجاد میکند. هر گره میتواند به ما کمک کند که ویجت متناظرش را به کمک ابزار قرائت صفحه توصیف کنیم. همچنین میتواند اقدامهای سفارشی یا از پیش تعریفشدهای از SemanticsAction داشته باشد.
سازنده ویجت Semantics
تا به این جا Semantics یک ابزار کاملاً جالب به نظر رسیده است، اما چگونه میتوانیم چنین ویجتی بسازیم؟ در ادامه سازنده آن را بررسی میکنیم:
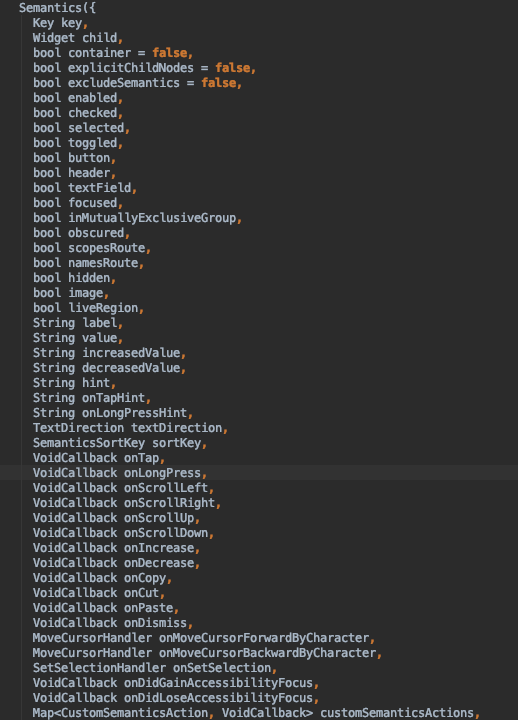
همان طور که میبینید سازنده استاندارد در زمان بسط دادن آن از کلاس پایه SingleChildRenderObjectWidget، برای Semantics مقدار زیادی مشخصههای مختلف ایجاد میکند. در سازنده دیگر Semantics.fromProperties به یک شیء SemanticsProperties به نام properties نیاز دارد. بر اساس مستندات، اگر بخواهید شیء Semantics خود را به صورت ثابت ایجاد کنید، باید به این ترتیب عمل کنید.
مشخصهها در کلاس SemanticsProperties برای تولید یک SemanticsNode در گره استفاده میشوند، اما این مورد را در ادامه بررسی خواهیم کرد. ما میخواهیم در حال حاضر به درک صحیحی از این مشخصهها برسیم، زیرا این موارد هستند که به ما امکان میدهند دسترسپذیری را به طرز مؤثری در اپلیکیشن پیادهسازی کرده و بهترین تجربهها را برای کاربران خود رقم بزنیم.
جدول موجود در این صفحه (+) را ملاحظه کنید. به خاطر داشته باشید که این مشخصهها به صورت پیشفرض null هستند. توضیحات به روشی نوشته شدهاند که انتظار میرود از سوی اغلب افراد درک شوند. همچنان که میبینید جدول فوق روشهای زیادی برای توصیف ویجت مرتبط ارائه میکند. برای نمونه مثالی از SDK فلاتر در مورد روش استفاده تیم فلاتر از SemanticsProperties را بررسی میکنیم.
Semantics برای یک ویجت ListTile به صورت زیر است. ListTile را میتوان به عنوان آیتم آخر نیز در نظر گرفت چون یک آیتم منفرد درون یک لیست است که شباهت زیادی به یک توییت منفرد در صفحه اصلی توییتر دارد.
طرز کار عناصر «معنا شناختی» (Semantics)
در ادامه به بررسی این کد و کارکرد آن برای کاربران میپردازم. قبل از چیز میتوانیم ببینیم که به یک شیء مستقل SemanticsProperties نیاز نداریم. با این وجود، میتوانیم چنین شیئی را با استفاده از سازندهای با نام fromProperties در کلاس Semantics بسازیم. ما میتوانیم برخی اطلاعات وضعیت ویجت را در زمان ایجاد شدنش ارسال کنیم. ما قادر هستیم ببینیم که فلگهای فعالشده و منتخب با مقادیری که درون سازنده ویجت تعریفشدهاند، تحریک میشوند.
اگر ListTile را هم اینک بسازیم، شروع به خواندن متن درون خود با صدای بلند میکند و همچنین اعلام میکند که متن فعال/غیرفعال و یا انتخاب شده یا نشده است. امکان تعیین دینامیک مقادیر برای ListTile جهت ایجاد اطلاعات معناشناختی سفارشی برای هر کادر منفرد وجود دارد:
تست عناصر معناشناختی
قطعه کد فوق یک «نمای لیست» (List View) با 5 عنصر میسازد و همه آنها را به جز عنصر دوم غیرفعال میکند. همچنین حالت منتخب عنصر نخست را به صورت true تعیین میکند. هنگامی که اپلیکیشن را با فعالسازی ابزار قرائت صفحه اجرا کنیم پیام زیر خوانده میشود:
Selected main title for 0 item, sub title for 0 item disabled
همان طور که میبینید، این پیام اطلاعاتی که در مورد هر آیتم ارائه کردیم را به کاربر انتقال میدهد. با این حال باید حالتهای دیگر را نیز تست کنیم تا از کارکرد صحیح آن مطمئن شویم. اگر یک بار روی آیتم دوم کلیک کنیم، عبارت زیر را میشنویم:
Main title for 1 item, sub title for 1 item
از آنجا که عنصر دوم انتخاب و فعال نشده است؛ میتوانیم مطمئن باشیم که آن نیز به صورت صحیحی کار میکند. با استفاده از TalkBalk، یک کلیک موجب میشود که ابزار قرائت صفحه به کار بیفتد؛ اما برای فعال کردن onTap در عمل به دو بار تپ کردن نیاز هست. برای تست آخرین حالت، روی سومین عنصر ضربه میزنیم. این بار پیام زیر را میشنویم:
Main title for 2 item, sub item for 2 item disabled
از آنجا که ما آن را انتخاب نکردهایم و غیر فعال است، به درستی اجرا شده است و میتوانیم مطمئن باشیم که به طرز صحیحی کار میکند. اکنون که درکی ابتدایی از ابزار Semantics و روش ساخت عناصر معناشناختی یافتیم، به بررسی عمیقتر این مفاهیم میپردازیم. اما قبل از آن باید در مورد مفهومی که قبلاً اشاره کردیم یعنی SemanticsNode بیشتر بدانیم.
درخت Semantics
همان طور که پیشتر اشاره شد، هنگامی که درخت ویجت ایجاد میشود یک درخت Semantics نیز همراه با آن ساخته میشود و این درخت است که مورد استفاده ابزارهای قرائت صفحه قرار میگیرد. در دنیای برنامهنویسی، منظور از «درخت» (tree) یک ساختمان داده شامل «گره» (node) و «برگ» (leaf) است.
در حالت مورد بررسی، SemanticsNodes گرههای ما هستند. هر SemanticsNode یک گره است که دادههای معناشناختی را به نمایش میگذارد. هر گره میتواند دادههای معناشناختی را برای یک یا چند ویجت پوشش دهد. هر SemanticsNode مقادیری دارد که میتواند از سوی اَعمال معناشناختی یا SemanticsAction فعال شوند. برای نمونه SemanticsProperties دارای پارامترهایی با عناوین increasedValue و decreasedValue برای اَعمال increase و decrease است. همچنین دارای یک «کلید» (key) برای شناسایی فهرست گرهها هستند.
این موارد در طی تجزیه درخت برای شناسایی گره صحیح در زمان بازسازی به کار میآیند. همچنین یک مقدار id برای شناسایی وجود دارد. برای نمونه مقدار id برای گره ریشه برابر با 0 است. این مقدار برای در زمان ایجاد گرههای فرزند به صورت خودکار تولید میشود.
علاوه بر آن میتوانیم اطلاعاتی در مورد گره و رابطه آن با گرههای دیگر بیابیم. از این رو میتوانیم در هر لحظه با استفاده از فلگ isPartOfNodeMerging بررسی کنیم که آیا با گرههای دیگر ادغام شده است یا نه. همچنین با استفاده از isMergedIntoParent میتوانیم بررسی کنیم که آیا قبلاً ادغام شده است یا نه. اگر یک ویجت چند فرزند داشته باشد که گردش خاص خود را دارند، میتوانیم از mergeAllDescendantsIntoThisNode برای ادغام همه آن گرهها در یک گره منفرد استفاده کنیم.
Semantics سفارشی
اکنون که درک بهتری از SemanticsNode ،SemanticsProperties و Semantics داریم، میتوانیم Semantics سفارشی خاص خود را بسازیم.
در کد فوق، ما از برچسب معناشناختی برای توصیف هر کانتینر استفاده میکنیم که در ListView مورد استفاده قرار میگیرد. هر کدام از این موارد یک کادر قرمزرنگ با ارتفاع و عرض 200 هستند. ما مقادیر enable و selected را از مثال فوق نگه داشتهایم. با این وجود، کنترلهای دیگری را نیز اضافه خواهیم کرد. یک callback برای onTop ایجاد میکنیم که برای دابل کلیک استفاده میشود و از onScrollDown نیز برای تست ژستها استفاده میکنیم. به طور کلی اپلیکیشن ما یک Snackbar نمایش میدهد که عبارت زیر را بیان خواهد کرد:
Item <related position> Clicked!
اگر onTop تحریک شود و یا زمانی که اسکرول میکنید (این کار در اندروید از طریق سوایپ کردن به چپ و سپس به سمت پایین انجام مییابد)، یک مدخل لاگ ایجاد میشود که نشان میدهد callback تحریک شده است.
مشاهده طرز کار همه این موارد تا به این جا جالب بوده است، اما زمانی که دقیقتر میشویم، سؤالات بیشتر و بیشتری برای ما ایجاد میشوند. زمانی که بخواهیم چند عنصر معناشناختی را در یک عنصر ادغام کنیم چه اتفاقی میافتد؟ یا اگر نخواهیم اطلاعات معناشناختی خاصی را به کاربر ارائه نکنیم چه رخ خواهد داد؟
ادغام عناصر معناشناختی
لازم نیست در مورد این مسائل نگران باشید، فلاتر همه این موارد را پوشش میدهد. امکان ادغام عناصر معناشناختی ویجتها با استفاده از MergeSemantics وجود دارد، حتی میتوانید برخی از آنها را با استفاده از ExcludeSemantics حذف کنید. علاوه بر اینها، فلاتر ویجتهای دیگری مانند BlockSemantics و IndexedSemantics نیز برای کارکردهای معناشناختی دارد که در ادامه به بررسی آنها میپردازیم.
به این منظور مثال قبلی را با استفاده از کد زیر بسط میدهیم:
همان طور که میبینید ما کد را کمی تغییر دادهایم. MergeSemantics را به عنوان root اضافه کردهایم. این بدان معنی است که همه عناصر معناشناختی فرزند موجود با هم ادغام میشوند و ابزار قرائت صفحه، همه آنها را یک جا ادغام میکند.
ضمناً یک ستون برای فرزندان درون کانتینر خود قرار میدهیم. در فرزند دوم در آیتم لیست، یعنی کانتینر دوم، میتوان دید که از BlockSemantics استفاده شده است. از این رو ویجتهای قبل از این گره نادیده گرفته میشوند و از سوی ابزارهای قرائت صفحه خوانده نمیشوند.
در فرزند سوم در آیتم لیست نیز یک ExcludeSemantics وجود دارد. بدین ترتیب ویجت فرزند این ویجت معناشناختی بخشی از درخت معناشناختی نخواهد بود. اپلیکیشن را بار دیگر اجرا میکنیم و عنصر نخست را بررسی میکنیم. در این زمان ابزار قرائت صفحه باید عبارت زیر را بخواند:
Selected Container with 200 width 200 height and red background second inside text of item 0 fourth inside text of item 0 disabled.
اندیسگذاری عناصر معناشناختی
همان طور که شاهد هستید، همه عناصر معناشناختی به جز آن که نمیخواهیم به اشتراک بگذاریم، در یک عنصر گرداوری شدهاند. ما هنوز یکی از عناصر معناشناختی که قبلاً اشاره کردیم، یعنی IndexedSemantics را بررسی نکردهایم. IndexedSemantics به ما کمک میکند که رد اطلاعات مرتبط را که به دسترسپذیری ابزارهای قرائت صفحه کمک میکنند حفظ کنیم. برای نمونه، با استفاده از ListView یک IndexedSemantics برای هر عنصر منفرد ایجاد خواهد شد.
اما در ListView ممکن است برخی عناصر باشند که کاربردی ندارند یعنی ممکن است عناصر جداسازی لیست باشند که هیچ کارکردی به جز بازنمایی دیداری ندارند. برای این که از قرائت این موارد برای کاربر جلوگیری کنیم، میتوانیم از IndexedSemantics به صورت زیر استفاده کنیم:
در این مثال، ابزارهای دسترسپذیری در زمان قرائت صفحه تنها عناصری را در نظر میگیرند که IndexedSemantics دارند و از روی باقی موارد رد میشوند.
سخن پایانی
دسترسپذیری موضوع مهمی است و هرگز نباید آن را نادیده گرفت. در زمان طراحی اپلیکیشن، همواره باید دسترسپذیری را در نظر داشت و اطمینان یافت که جنبههای دسترسپذیری به اپلیکیشن اضافه شدهاند و در دسترس همه افرادی که از گوشیهای هوشمند استفاده میکنند، قرار دارند. بدین ترتیب با اندکی تلاش بیشتر باعث میشویم، زندگی افراد بسیار زیادی آسانتر شود.
از آنجا که تیم فلاتر قبلاً عناصر معناشناختی را در اغلب ویجتها پیادهسازی کردهاند، اجرای آن برای ما آسانتر شده است. اما زمانی که یک ویجت سفارشی ایجاد میکنیم باید همواره عناصر معناشناختی را نیز به آن اضافه کنیم. به خاطر داشته باشید که هر فردی شایسته این است که بتواند از اپلیکیشن شما استفاده کند، بنابراین کمک کنید که بتوانند از اپلیکیشنتان استفاده کنند.
منبع: فرادرس
آموزش Node.js: معرفی NPM — بخش سوم
NPM اختصاری برای عبارت «مدیریت بسته نود.جیاس» (Node Package Manager) است. در ابتدای سال 2017 تعداد بستههای فهرست شده در رجیستری npm از مرز 350،000 بسته رد شد و به این ترتیب به بزرگترین رجیستری کد روی زمین تبدیل شد. بنابراین میتوانید مطمئن باشید که برای هر چیزی دست کم یک بسته وجود دارد. رجیستری npm در ابتدا به عنوان روشی برای دانلود و مدیریت وابستگیهای Node.js آغاز شد، اما مدتی است که به ابزاری تبدیل شده که برای فرانتاند جاوا اسکریپت نیز استفاده میشود. npm کارهای زیادی انجام میدهد. برای مطالعه بخش قبلی این سری مقالات آموزشی میتوانید به لینک زیر مراجعه کنید:
دانلودها
NPM دانلود وابستگیهای پروژه را مدیریت میکند.
نصب همه وابستگیها
اگر پروژهای یک فایل packages.json داشته باشد، با اجرای دستور زیر همه موارد نیاز پروژه در پوشه node_modules نصب میشوند. اگر خود این پوشه وجود نداشته باشد، ایجاد میشود.
npm install
نصب بسته منفرد
در npm امکان نصب یک بسته منفرد خاص با استفاده از دستور زیر وجود دارد:
npm install <package-name>
در اغلب موارد فلگهای بیشتری به دستورها اضافه میشود:
- save– : این فلگ بسته را نصب کرده و مدخلی را به بخش dependencies فایل package.json اضافه میکند.
- save-dev– : بسته را نصب میکند و مدخلی را به بخش devDependencies فایل package.json اضافه میکند.
تفاوت به طور عمده در این است که devDependencies عموماً ابزار توسعه محسوب میشوند و شبیه به یک کتابخانه تست هستند؛ در حالی که dependencies در زمان production اپلیکیشن بستهبندی میشود.
بهروزرسانی بستهها
بهروزرسانی با اجرای دستور زیر نیز به سادگی اجرا میشود:
npm update
npm همه بستهها را برای دریافت نسخه جدیدتری که شرطهای نسخهبندی شما را تأمین کند بررسی خواهد کرد. میتوان یک بسته منفرد را نیز برای بهروزرسانی تعیین کرد:
npm update <package-name>
نسخهبندی
npm علاوه بر دانلودهای ساده، به مدیریت «نسخهبندی» (versioning) نیز میپردازد، بنابراین میتوانید هر نسخه خاصی از یک بسته را تعیین کنید و یا یک نسخه بالاتر یا پایینتر از آنچه مورد نیاز است را «الزام» (require) کنید.
در اغلب موارد ممکن است متوجه شوید که یک کتابخانه تنها با نسخه اصلی انتشار یافته از یک کتابخانه دیگر سازگار است و یا یک باگ در آخرین نسخه از یک کتابخانه که همچنان رفع نشده است موجب بروز مشکلی شده است.
تعیین نسخه دقیق یک کتابخانه موجب میشود که همه افراد دقیقاً از همان نسخه استفاده کنند و بدین ترتیب کل تیم نسخه یکسانی را اجرا میکنند تا این که بار دیگر فایل package.json بهروزرسانی شود.
اجرای وظایف
فایل package.json از یک قالب به صورت زیر برای تعیین وظایف خط فرمان استفاده میکند:
npm <task-name>
برای نمونه:
استفاده از این ویژگی برای اجرای Webpack امر بسیار رایجی محسوب میشود:
بنابراین به جای تایپ کردن این دستورهای طولانی که به راحتی فراموش میشوند یا ممکن است غلط تایپ شوند میتوانید دستور زیر را اجرا کنید:
npm watch $ npm dev $ npm prod
NPM بستهها را در کجا نصب میکند؟
زمانی که یک بسته را با استفاده از npm (یا yarn) نصب میکنید، میتوانید 2 نوع نصب داشته باشید:
- نصب محلی
- نصب سراسری
زمانی که دستور npm install را وارد میکنید، به صورت پیشفرض اتفاقی مانند زیر رخ میدهد:
npm install lodash
این بسته در درخت فایل جاری و در پوشه فرعی node_modules نصب میشود.
زمانی که این اتفاق میافتد، npm مدخل lodash را در مشخصه dependencies فایل packages.json در پوشه کنونی وارد میکند. نصب سراسری نیز با استفاده از فلگ g- صورت میگیرد:
npm install -g lodash
زمانی که این اتفاق رخ بدهد، npm بسته را در پوشه محلی نصب نخواهد کرد؛ بلکه به جای آن بسته را در یک مکان سراسری نصب میکند. اما این مکان سراسری دقیقاً کجاست؟ دستور npm root –g به ما اعلام میکند که موقعیت دقیق بسته روی سیستم در کجا است.
روی یک سیستم macOS یا Linux این مکان میتواند در مسیر usr/local/lib/node_modules/ باشد. در سیستمهای ویندوزی این مسیر ممکن است به صورت C:\Users\YOU\AppData\Roaming\npm\node_modules باشد. اگر از nvm برای مدیریت نسخههای Node.js استفاده میکنید، این مکان میتواند متفاوت از مسیرهای فوق باشد. برای نمونه nvm در روی برخی سیستمها از مسیر Users/flavio/.nvm/versions/node/v8.9.0/lib/node_modules/ استفاده میکند.
شیوه استفاده یا اجرای بسته نصب شده با NPM
در این بخش روش include کردن و استفاده از بسته نصب شده در پوشه node_modules را بررسی میکنیم. در واقع میخواهیم بررسی کنیم هنگامی که یک بسته با استفاده از دستور npm در پوشه node_modules نصب شود یا به صورت سراسری نصب شود، چگونه میتوان در کد Node از آن استفاده کرد. فرض کنید بسته lodash را که یک کتابخانه محبوب از ابزارهای کاربردی جاوا اسکریپت است با استفاده از دستور زیر نصب کردهاید:
npm install lodash
بدین ترتیب بسته در پوشه محلی node_modules نصب میشود. برای استفاده از این کتابخانه در کدهای خودتان باید آن را با استفاده از کلیدواژه require در کد ایمپورت کنید:
const _ = require('lodash)اگر بسته یک فایل اجرایی باشد، فایل مربوطه باید در پوشه node_modules/.bin/ قرار گیرد. یک روش ساده برای نمایش این حالت cowsay (+) است. بسته cowsay یک برنامه خط فرمان ارائه میکند که میتواند برای تولید یک «cow say» استفاده شود. cowsay-ها برنامهای هستند که تصاویر ASCII از یک گاو یا بعضاً حیوانهای دیگر تولید میکنند که پیامی را بیان میکند.
زمانی که این بسته با استفاده از دستور زیر نصب میشود:
npm install cowsay
برای خود چند وابستگی در پوشه node_modules نصب میکند. یک پوشه پنهان bin. وجود دارد که شامل «پیوندهای نمادین» (Symbolic links) به فایلهای باینری cowsay است.
اجرای cowsay
برای اجرای cowsay کافی است عبارت زیر را وارد کنید:
./node_modules/.bin/cowsay
به این ترتیب برنامه مربوطه اجرا میشود، اما npx که در نسخههای اخیر npm (از نسخه 5.2 به بعد) گنجانده شده است، گزینه بسیار بهتری محسوب میشود. در این حالت کافی است دستور زیر را اجرا کنید:
npx cowsay
npx به این صورت مکان بسته شما را پیدا میکند.
به این ترتیب به پایان بخش سوم راهنمای آموزش Node.js میرسیم. در بخش بعدی این سلسله مقالات آموزشی در مورد فایل Package.json صحبت خواهیم کرد. بخش چهارم این سری مقالات را با رجوع به لینک زیر مطالعه کنید:
کامپوننت کانتینری در انگولار (Angular) — از صفر تا صد
در الگوی طراحی MVP برای نوشتن نرمافزار، استفاده از هر کتابخانه یا الگوی مدیریت «حالت» (State) اپلیکیشن آسان خواهد بود، چه کانتینرِ حالت، شبیه به redux مانند NgRx Store باشد و چه سرویسهای ساده قدیمی مانند آن چه در مثال Tour of Heroes باشد که در این راهنمای انگولار (+) معرفی شده است. MVP اختصاری برای عبارت «Model-View-Presenter» (مدل-نما-ارائه دهنده) است. در این مقاله به بررسی کامپوننت کانتینری در انگولار می پردازیم.
کامپوننتهای کانتینری در مرز لایهی ارائه قرار میگیرند و UI را با حالت اپلیکیشن یکپارچه میسازند. این کامپوننتها دو مقصود عمده دارند:
- کامپوننتهای کانتینری از یک گردش داده برای ارائه پشتیبانی میکنند.
- کامپوننتهای کانتینری رویدادهای خاص کامپوننت را به دستورهای حالت اپلیکیشن یا به زبان Redux/NgRx Store به اکشن ترجمه میکنند.
کامپوننتهای کانتینری میتوانند UI را با دیگر لایههای غیر ارائهای مانند I/O یا پیامرسانی نیز ادغام کنند. در این مقاله با فرایند استخراج یک کامپوننت کانتینری از یک کامپوننت ترکیبی آشنا میشویم. اغلب اصطلاحهایی که در این نوشته استفاده شدهاند، در آموزش رایگان آشنایی مقدماتی با AngularJS معرفی شدهاند. پیشنهاد میکنیم ابتدا این آموزش را ملاحظه کنید.
کامپوننتهای کانتینری
دلیل این که این کامپوننتها را کامپوننتهای کانتینری مینامیم، این است که شامل همه حالتهای مورد نیاز برای کامپوننتهای فرزند در «نما» (View)-یشان هستند. به علاوه، منحصراً شامل کامپوننتهای فرزند در نمای خود هستند و نه محتوای ارائهای. قالب یک کامپوننت کانتینری به طور کامل از کامپوننتهای فرزند و «اتصالهای داده» (data binding) تشکیل یافته است. منظور از اتصال داده روشی برای اتصال رابط کاربری به دادههای بکاند است.
روش مفید دیگر برای تعریف کامپوننتهای کانتینری این است که این کامپوننتها مانند کانتینرهای حمل کالا به طور کامل خودکفا هستند و میتوانند به صورت دلخواه در قالبهای کامپوننت جابجا شوند، زیرا هیچ مشخصات ورودی و خروجی ندارند.
کامپوننتهای کانتینری مشکل رویدادهای اتصال و مشخصههای bucket را از طریق چندین لایه از درخت کامپوننت حل کردهاند. این پدیده در جامعه ریاکت با عنوان «prop drilling» شناخته میشود.
مثال ساده
ما توضیح خود را از DashboardComponent در راهنمای Tour of Heroes آغاز میکنیم.
شناسایی دغدغههای ترکیبی
همچنان که میبینیم این کامپوننت دغدغههایی را در مورد لایههای افقی چندگانه در اپلیکیشن با هم در آمیخته است. قبل از هر چیز دغدغه ارائه وجود دارد. این مسئله ارائهای از hero-ها است که در یک قالب نمایش پیدا میکنند:
با این که ارائه، یک دغدغه مشروع برای یک کامپوننت UI محسوب میشود، اما این کامپوننت ترکیبی ارتباط تنگاتنگی با مدیریتِ حالت نیز دارد. در یک اپلیکیشن NgRx این کامپوننت میتوانست یک Store را تزریق کند و برای یک بخش از حالت اپلیکیشن با سلکتور حالت کوئری بزند. در مثال Tour of Heroes این کامپوننت یک HeroService تزریق میکند و در سراسر یک observable به دنبال قهرمانها کوئری میزند. سپس یک زیرمجموعه از ارائه برش مییابد و یک ارجاع در آن به مشخصه heroes ذخیره میشود.
قلاب چرخه عمر
لازم به ذکر است که کامپوننت داشبورد ترکیبی ما در لحظه OnInit از چرخه عمر خود قلاب میشود. این همان جایی است که در observable بازگشتی از HeroService#getHeroes ثبت نام میکند. این نقطه جای مناسبی برای این کار است، چون ثبت نام در یک observable موجب بروز عوارض ناخواستهای میشود که در یک سازنده یا مقداردهی اولیه مشخصه مطلوب نیست. برای توضیح بیشتر به این لینک (+) مراجع کنید.
به طور خاص، یک درخواست HTTP هنگام ثبت نام در observable بازگشتی از HeroService#getHeroes ارسال میشود. با دور نگه داشتن کد ناهمگام از سازندهها و متدهای مقداردهی مشخصه میتوانیم تست و استدلال در مورد کامپوننتها را آسانتر بکنیم. اگر در مورد مفاهیم پایه observable-های RxJS مطمئن نیستید، میتوانید به مطالعه این مقاله (+) بپردازید.
افراز کردن یک کامپوننت ترکیبی
برای جداسازی دغدغههای چندلایه در یک کامپوننت ترکیبی میتوانیم آن را به دو کامپوننت افراز کنیم که یکی کامپوننت کانتینر و دیگری کامپوننت ارائهای است.
کامپوننت کانتینری مسئول یکپارچهسازی UI با لایههای غیر ارائهای اپلیکیشن مانند لایههای مدیریت حالت اپلیکیشن و لایه «دائمی» (persistence) است.
زمانی که منطق غیر ارائهای در کامپوننت ترکیبی شناسایی شد، میتوان یک کامپوننت کانتینری را با جداسازی و استخراج تقریباً کامل این منطق از طریق برش کد منبع مدل کامپوننت و چسباندن آن در مدل کامپوننت کانتینری ایجاد کرد.
مدل کامپوننت ترکیبی نخست
مدل کامپوننت ترکیبی پس از استخراج کامپوننت کانتینری
پس از انتقال منطق به کامپوننت کانتینری چند گام برای تبدیل کامپوننت ترکیبی به یک کامپوننت ارائهای باقی میماند. این گامها را در مقالات بعدی مجله فرادرس در خصوص انگولار توضیح خواهیم داد. اما به اختصار بیان کنیم که شامل تغییر دادن نام تگ و تطبیق API اتصال داده با API مورد انتظار است که در قالب کامپوننت کانتینری استفاده شده است.
جداسازی و استخراج یکپارچگی لایهها
ما وابستگی HeroService را استخراج و یک جریان داده ایجاد کردهایم که با گردش داده در کامپوننت داشبورد ترکیبی مطابقت دارد. این همان مشخصه observable با نام $topHeroes است که یک pipeline از عملیات، روی observable بازگشتی از HeroService#getHeroes اضافه میکند.
پس از این که سرویس hero یک observable را صادر میکند، «جریان قهرمانهای برتر» (topHeroes Stream) نیز یک چنین مقداری را ارسال میکند؛ اما این کار صرفاً در زمان مشاهده شدن یعنی هنگامی که یک ثبت نام ایجاد شود اجرا خواهد شد. بدین ترتیب روی ارائه ارسالی از قهرمانها نگاشت میکنیم تا زیرمجموعهای از قهرمانها را که به کاربرانمان ارائه میشوند به دست آوریم.
اتصال کامپوننت ارائهای با استفاده از اتصالهای داده
پس از استخراج منطق یکپارچگی حالت اپلیکیشن، میتوانیم به طور موقت کامپوننت داشبورد را به صورت یک کامپوننت ارائهای تصور و فرض کنیم که یک مشخصه ورودی heroes داریم. این مشخصه را در قالب کامپوننت کانتینری داشبورد مشاهده کردیم.
گام نهایی در این فرایند استخراج کردن یک کامپوننت کانتینری برای اتصال آن به کامپوننت ارائهای حاصل از طریق اتصالهای داده است. یعنی اتصالهای مشخصه و اتصالهای رویداد در قالب کامپوننت کانتینری باید استفاده شوند.
app-dashboard-ui نام تگ کامپوننت داشبورد در زمان تبدیل شدن به کامپوننت ارائهای است. ما observable با نام $topHeroes را با استفاده از pipe–ی به نام async به مشخصه ورودی heroes آن وصل میکنیم.
همچنین متن عنوان را از کامپوننت ترکیبی استخراج میکنیم و آن را به صورت title در قالب کامپوننت کانتینری قرار میدهیم. در مقالات آینده مجله فرادرس در خصوص کامپوننتهای ارائهای در انگولار توضیح خواهیم داد که چه هنگام و چرا ممکن است بخواهیم این کار را انجام دهیم.
فعلاً از این مزیت آنی که کامپوننتهای داشبورد ارائهای قابلیت بازتعریف دغدغه برای بخش دیگری از اپلیکیشن را مییابند خشنود هستیم. بدین ترتیب عنوان کامپوننت میتواند زیرمجموعه متفاوتی از قهرمانها را که به آن ارائه شده است توصیف کند.
چه کسی ثبت نام را مدیریت میکند؟
در بخش قبل از شر قلاب چرخه عمری ngOnInit خلاص شدیم. مدل کامپوننت کانتینری ما جریان داده قهرمانها را با pipe کردن از observable موجود آمادهسازی میکند که موجب هیچ عارضه جانبی نمیشود یعنی ثبت نام صورت نمیگیرد.
اینک سؤال این است که پس ثبت نام در کجا مقداردهی میشود؟ پاسخ این است که انگولار ثبت نام را برای ما مدیریت میکند. ما به صورت اعلانی به انگولار دستور میدهیم که observable قهرمانهای برتر را با استفاده از pipe-ی به نام async در قالب کامپوننت کانتینری ثبت نام کند.
در نتیجه یک ثبت نام صورت میگیرد که از چرخه عمر کامپوننت داشبورد ارائهای پیروی میکند و قهرمانها را به مشخصه ورودی heroes ارسال میکند.
بدین ترتیب اینکه از شر مدیریت دستی ثبت نام رها شدهایم، موجب خشنودی ما میشود چون کاری دشوار و مستعد بروز خطا است. اگر فراموش کنیم اشترک خود را از یک observable که هرگز تکمیل نشده است قطع کنیم، ممکن است در ادامهی نشست اپلیکیشن چند اجرای ثبت نام داشته باشیم و بدین ترتیب با نشت حافظه مواجه شویم.
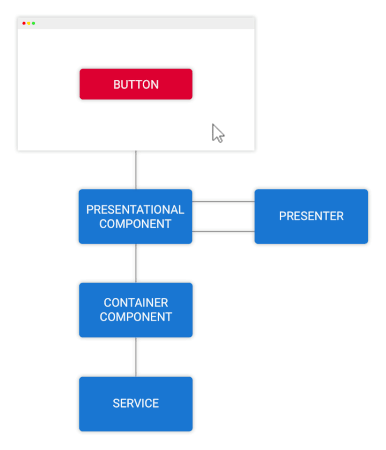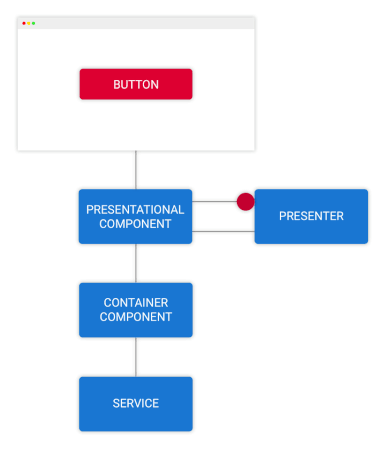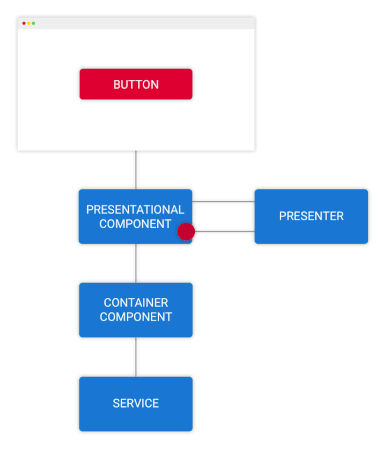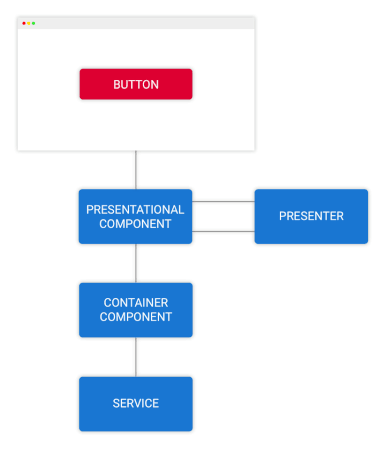
گردش دادهها در کامپوننت کانتینری
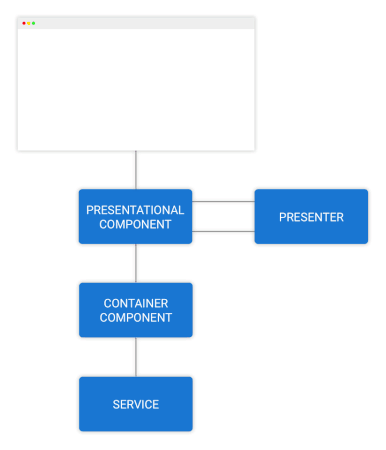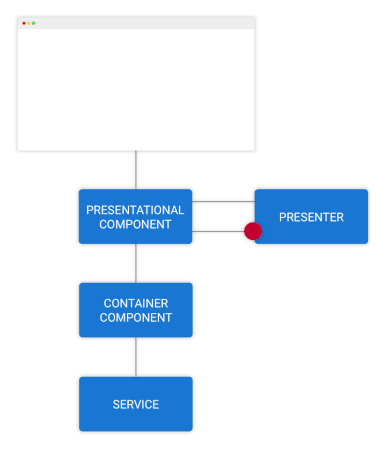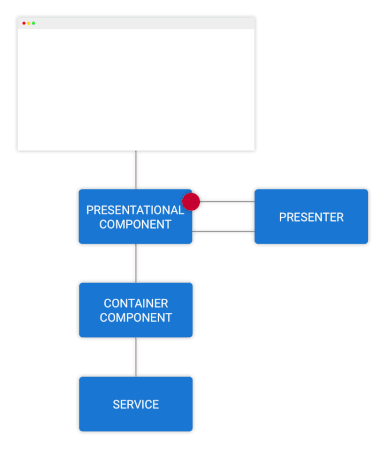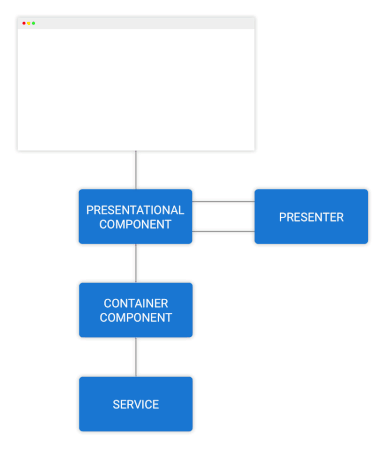
در شکل فوق ویژگی داشبورد را در یک نمودار گنجاندهایم و میبینیم که کامپوننت کانتینری چگونه از قهرمانها مطلع میشود. این قهرمانها از سرویس heroes از طریق یک observable درخواست شدهاند.
کامپوننت کانتینری، قهرمانهای برتر را که به مشخصه ورودی کامپوننت ارائهای ارسال میشوند، محاسبه میکند. ارائه قهرمانها میتواند از طریق یک ارائهدهنده پیش از نمایش نهایی به کاربر در DOM ارسال شود؛ اما کامپوننت کانتینری از آن مطلع نیست، زیرا تنها در مورد API اتصال داده کامپوننت ارائهای اطلاع دارد.
مثال پیشرفته
اینک به عنوان یک مثال پیشرفته به بررسی HeroesComponent از راهنمای Tour of Heroes انگولار میپردازیم که در ابتدای این مقاله معرفی کردیم.
جداسازی یکپارچگیهای لایه
در نگاه نخست، این کامپوننت ممکن است کوچک، ساده و معصوم به نظر برسد. با بررسی دقیقتر به نظر میرسد که این کامپوننت دغدغههای مختلفی دارد. همانند مثال قبلی، قلاب چرخه عمری ngOnInit و متد getHeroes اختصاص به کوئری کردن بخشی از حالت اپلیکیشن دارند.
متد delete به حالت دائمی مرتبط است و به جایگزین کردن مشخصه heroes با یک ارائه میپردازد که در آن قهرمان حذف شده، فیلتر شده است. این متد با حالت دائمی نیز مرتبط است چون یک قهرمان را از طریق سرویس hero از حالت سرور نیز حذف میکند.
در نهایت باید گفت که متد add به تعامل کاربر مرتبط است، زیرا نام قهرمان را پیش از ایجاد قهرمانی که دغدغه لایههای حالتِ دائمی و اپلیکیشن است اعتبارسنجی میکند.
استخراج یکپارچگیهای لایه
اینک که گردش کار را تشخیص دادهایم، میتوانیم از شر مقاصد سیستم چندلایه یا استخراج آنها به یک کامپوننت کانتینری رها شویم.
همانند مثال ساده قبلی، وابستگی HeroService را در یک کامپوننت کانتینری استخراج میکنیم. ما حالت این قهرمانها را در یک مشخصه heroes «تغییرپذیر» (mutable) نگهداری میکنیم.
این فرایند به همراه راهبرد پیشفرض شناسایی تغییر عمل میکند، اما ما میخواهیم عملکرد آن را با استفاده از راهبرد شناسایی تغییر OnPush بهبود ببخشیم. به این منظور به یک observable برای مدیریت حالت قهرمانها نیاز داریم.
سرویس hero یک observable بازگشت میدهد که ارائهای از قهرمانها ارسال میکند، اما باید از حذف و اضافه قهرمانها نیز پشتیبانی کند. یک راهحل این است که یک observable مقید به حالت با یک BehaviorSubject بسازیم.
با این وجود برای استفاده از یک سوژه باید observable سرویس hero را ثبت نام کنیم که موجب عوارض جانبی میشود. اگر observable پس از ارسال یک مقدار منفرد تکمیل نشود، میبایست فرایند ثبت نام خودمان را نیز مدیریت کنیم تا از بروز نشت حافظه جلوگیری کنیم.
به علاوه باید حالت قهرمانها را هنگام حذف یا اضافه کردن یک قهرمان کاهش دهیم. این وضعیت به سرعت تبدیل به وضعیتی پیچیده میشود.
مدیریت حالت
برای ردگیری حالت اپلیکیشن به روشی واکنشی، یک کتابخانه کوچک به نام rxjs-multi-scan (+) وجود دارد. عملگر ترکیب کتابخانه multiScan چند observable را از طریق یک عملیات اسکن منفرد برای محاسبه حالت جاری ادغام میکند. اما این کار از طریق یک تابع کاهنده عموماً کوچک برای هر منبع observable صورت میگیرد. این عملگر یک حالت اولیه را به عنوان پارامتر آخر خود ارسال میکند.
هر پارامتر فرد به جز پارامتر حالت اولیه، یک observable منبع و موارد پیرو آن حتی پارامتر، خود یک تابع کاهنده برای حالت اسکن شده محسوب میشود.
در مورد مثال ما، حالت اولیه یک ارائه خالی است هنگامی که observable بازگشتی از HeroService#getHeroes یک ارائه از قهرمانها را ارسال میکند؛ آنها را در حالت کنونی تجمیع میکند.
ما یک Subject از نوع RxJS برای هر تعامل کاربر میسازیم که یکی برای افزودن قهرمان و دیگری برای حذف قهرمان است. هر زمان که یک قهرمان از طریق مشخصه heroAdd خصوصی ارسال شود، تابع کاهنده متناظر در عملیات multiScan آن را به حالت جاری الحاق میکند.
هنگامی که قهرمان حذف شود، قهرمان مورد نظر از طریق سوژه heroRemove ارسال میشود که یک فیلتر روی قهرمانهای کنونی راهاندازی میکند تا قهرمان موصوف را فیلتر کند.
راهبردهای بهروزرسانی حالت دائمی
بدین ترتیب دیدیم که امکان حذف و اضافه یک قهرمان در متدهای عمومی add و delete وجود دارد. هر زمان که یک قهرمان اضافه میشود، ما از یک راهبرد بهروزرسانی بدبینانه استفاده میکنیم و ابتدا قهرمان را از طریق سرویس hero در حالت سرور ذخیره میکنیم و تنها در صورتی که این فرایند موفق باشد، به بهروزرسانی حالت دائمی در $heroes انجام مییابد.
در حال حاضر، ما خطاها را در زمان بهروزرسانی حالت سرور مدیریت نمیکنیم. این وضعیت به این صورت قابل مشاهده است که دستگیره error در پارامتر observer به نام subscribe به صورت noop است. فرض کنید میخواهیم یک پیام toast به کاربر نشان دهیم که عملیات را مجدداً اجرا کند، این کار باید در دستگیره error صورت بگیرد.
زمانی که یک قهرمان حذف میشود، از راهبرد بهروزرسانی خوشبینانه استفاده میکنیم و ابتدا قهرمان را از حالت دائمی سرور حذف میکنیم و متعاقب آن قهرمان را از حالت سرور نیز حذف میکنیم. اگر حذف کردن ناموفق باشد، حالت دائمی را با افزودن مجدد قهرمان به $heroes از طریق سوژه theheroAdd مجدداً اضافه میکنیم.
این یک بهبود نسبت به پیادهسازی اولیه محسوب میشود که در آن خطاهای سرور در زمان حذف یک قهرمان مدیریت نشده بودند.
گردش رویدادها به سوی کامپوننت کانتینری
فرض کنید به صورت دستی ویژگی قهرمانها را به نمودار گردش کار شکل 2 اضافه کنیم. شیوه ورود نام قهرمان و سپس کلیک شدن دکمه add را بصریسازی کنید.
یک متد برای مدلسازی کامپوننت ارائهای با عنوان نام قهرمان جدید فراخوانی میشود. کامپوننت ارائهای میتواند منطق تعامل کاربر را پیش از ارسال نام قهرمان به صورت یک رویداد از طریق یکی از مشخصههای خروجیاش نمایندگی کند.
کامپوننت کانتینری از نام قهرمانی که به سرویس hero ارسال شده است مطلع میشود و در نهایت حالت دائمی را در مدل کامپوننت کانتینری بهروزرسانی میکند.
در ادامه قهرمانهای بهروزرسانی شده اقدام به مطلع ساختن کامپوننت ارائهای میکنند و گردش دادهها همانند تصویر شماره 1 تداوم مییابد.
حالت اپلیکیشن یک دغدغه متفاوت است
لازم به اشاره است که گرچه حالت اپلیکیشن میتواند خاص یک ویژگی اپلیکیشن باشد، اما حالت قهرمانها در چندین زمینه از مثال Tour of Heroes استفاده میشود. همان طور که پیشتر اشاره کردیم، این حالت دائمی است که بخش حالت سرور را بازتاب میدهد. به طور ایدهآل، کامپوننت کانتینری قهرمانهای ما نباید رأساً اقدام به مدیریت حالت دائمی بکنند؛ بلکه به جای آن باید سرویس hero، یا store در اپلیکیشن که از NgRx Store استفاده میکند این کار را انجام دهد.
علیرغم این که حالت قهرمان در یک کامپوننت کانتینری خاص ویژگی مدیریت میشود، این حالت در اپلیکیشن ثابت است. دلیل این امر آن است که داشبورد هر بار که مقداردهی شود از سرویس hero حالت سرور قهرمانها را میپرسد که موجب میشود درخواست HTTP حالت دائمی را مقداردهی کند.
در این سری مقالات انگولار تلاش ما بر این است که روی کامپوننتهای انگولار متمرکز شویم. برای انجام این تلاش سرویسها را تغییر نخواهیم داد. اگر میخواهید حالت قهرمانها را در سرویس hero که به آن تعلق دارد قرار دهید، میتوانید مدیریت حالت را از این کامپوننت کانتینری خارج کنید.
بدین ترتیب میبینیم زمانی که دغدغهها را از هم متمایز کنیم، جداسازی نوع خاصی از منطق و قرار دادن آن در لایه اپلیکیشن که به آن تعلق دارد چه قدر آسان میشود.
کار با دادههای «تغییرناپذیر» (Immutable)
در کامپوننت قهرمانهای ترکیبی، متد Array#push برای افزودن یک قهرمان به حالت قهرمانها استفاده میشود. این امر موجب تغییر یافتن ارائه میشود، یعنی یک ارجاع جدید ایجاد نمیشود. با این که این وضعیت از سوی راهبرد شناسایی تغییر پیشفرض انگولار پشتیبانی میشود، اما ما گزینه ارتقای عملکرد را با راهبرد شناسایی تغییر OnPush در همه کامپوننتهای خود انتخاب میکنیم.
برای این که این راهبرد کار کند، باید هر زمان که یک قهرمان اضافه میشود، یک ارجاع ارائه جدید ارسال کنیم. این کار با استفاده از عملگر spread (…) در یک literal ارائه، برای کپی کردن قهرمانها از مقدار کنونی قهرمانها و گنجاندن قهرمان اضافی صورت میگیرد. ارائه جدید به observer-های مشخصه $heroes ارسال میشود.
منطق بخش جامانده
اگر در حین مطالعه این مقاله همراه با ما کدنویسی کرده باشید، ممکن است متوجه شده باشید که منطق اعتبارسنجی در کامپوننت قهرمانهای ترکیبی نادیده گرفته شده است. این کار عامدانه صورت گرفته است، زیرا نه جزء دغدغههای حالت اپلیکیشن و نه حالت دائمی نیست.
اتصال کامپوننت ارائهای با استفاده از API اتصال داده
گام نهایی، اتصال کامپوننت کانتینری به API اتصال داده کامپوننت ارائهای در قالب کامپوننت کانتینری است.
همانند مثال ساده ابتدای این مقاله ما مشخصه ورودی heroes را با pipe کردن از طریق async به مشخصه observable وصل میکنیم. بدین ترتیب هر بار که حالت قهرمان تغییر یابد، یک ارجاع ارائه جدید به کامپوننت ارائهای ارسال خواهد شد.
به خاطر داشته باشید که وقتی ما از pipe-ی به نام async استفاده میکنیم؛ انگولار ثبت نام ما در observable به نام $heroes را مدیریت میکند، به طوری که از چرخه عمر کامپوننت ارائهای پیروی میکند.
اتصالهای رویداد
کاربران ما در کامپوننت قهرمانهای ارائهای میتوانند حالت اپلیکیشن را از طریق حذف یا اضافه کردن قهرمانها تغییر دهند. ما انتظار داریم که کامپوننت ارائهای هر بار که کاربر یک قهرمان را حذف یا اضافه میکند، یک قهرمان را از طریق مشخصه خروجی ارسال کند بنابراین متد add کامپوننت کانتینری را به رویداد add کامپوننت ارائهای وصل میکند.
به طور مشابه، ما اقدام به اتصال متد delete به رویداد remove میکنیم. ما نام این متد را به این جهت delete گذاردهایم که عملکرد Intent، حذف قهرمان از حالت سرور، در عین حفظ همگامی حالت دائمی است.
با این که حذف کردن خود یک intent است که میتوان انتظار داشت از سوی کامپوننت کانتینری مدیریت شود، کامپوننت ارائهای نباید به جز در مورد حالت UI محلی در خصوص حالت اپلیکیشن دغدغه داشته باشد. کامپوننت ارائهای زمانی که کاربر تقاضای حذف یک قهرمان را میکند، تنها یک رویداد خاص کامپوننت ارسال میکند رویداد remove از طریق کامپوننت کانتینری heroes یک دستور به حالت دائمی ارسال میکند که انتظار میرود به نوبه خود حالت اپلیکیشن را تغییر دهد. حالت جدید به مشخصههای ورودی کامپوننت به شکل ارجاع ارائه جدید گردش مییابد.
بهکارگیری راهبرد شناسایی تغییر OnPush
در زمان ساخت یک کامپوننت کانتینری باید مطمئن شویم که از observable-ها برای استریم کردن حالت اپلیکیشن استفاده میکنیم. همزمان با ساختمانهای داده تغییرناپذیر که به طور اختصاری در observable-ها وجود دارند، نیز کار میکنیم.
بدین ترتیب میتوانیم از راهبرد شناسایی تغییر OnPush در کامپوننت کانتینری استفاده کنیم ، چون Pipe به نام async شناسایی تغییر را زمانی تحریک میکند که مقادیر از طریق یک observable ارسال شده باشند. از آنجا که در زمان کار با ساختمانهای داده تغییرناپذیر یک ارجاع جدید به همراه هر مقدار جدید ارسال میشود، امکان بهکارگیری راهبرد شناسایی تغییر OnPush در مورد کامپوننتهای ارائهای نیز وجود دارد.
نامگذاری و ساختار فایل
ما کار خود را با HeroesComponent آغاز میکنیم که 4 فیلد مرتبط دارد:
- استایلشیت خاص کامپوننت
- قالب کامپوننت
- مجموعه تست کامپوننت
- مدل کامپوننت
ما HeroesContainerComponent و مجموعه تست آن را اضافه میکنیم. یک کامپوننت کانتینری به ندرت استایل دارد و از این رو تنها سه فایل مورد نیاز هستند.
تصمیم ما این است که آنها را در یک دایرکتوری منفرد نگهداری کنیم و فایلهای کامپوننت کانتینری را مشابه فایلهای کامپوننت ترکیبی نامگذاری کنیم، به جز این که پسوند فایلها به جای component. به صورت container. خواهد بود.
لازم به ذکر است که شما میتوانید فایلها، دایرکتوریها و کلاسها را هر طور که دوست دارید نامگذاری کنید. این یک الگوی طراحی است و لزوماً قواعد سفت و سختی در مورد آن وجود ندارد.
اگر به قالبها و استایلشیت های «درونخطی» (inline) علاقهمند هستید و یا میخواهید دایرکتوریها کامپوننت ترکیبی و فایلهای کامپوننتت کانتینری را جدا کنید، کاملاً دستتان در مورد این تغییرات باز است و میتوانید هر آن چه را که به صلاح تیم شما است انجام دهید.
جمعبندی
برای استخراج یک کامپوننت کانتینری از یک کامپوننت ترکیبی این مراحل را طی میکنیم:
- یکپارچگی را جداسازی کرده و به صورت لایههای غیر ارائهای در یک کامپوننت کانتینری استخراج میکنیم.
- اجازه میدهیم کامپوننت کانتینری حالت اپلیکیشن را از طریق observable-ها استریم کند.
- کامپوننت کانتینری را با اتصالهای داده به کامپوننت ارائهای وصل میکنیم.
- راهبرد شناساییِ تغییر OnPush را به کار میگیریم.
به خاطر داشته باشید که کامپوننتهای کانتینری دو مقصود اصلی دارند:
- کامپوننتهای کانتینری از گردش دادهها برای ارائه پشتیبانی میکنند.
- کامپوننتهای کانتینری رویدادهای خاص کامپوننت را به دستورهای حالت اپلیکیشن یا همان اکشنها برحسب اصطلاحهای Redux/NgRx Store ترجمه میکنند. یکی از بزرگترین مزیتهای استفاده از کامپوننتهای کانتینری این است که میزان تستپذیری را افزایش میدهند.
منبع: فرادرس
مرتب سازی حبابی و پیاده سازی آن — از صفر تا صد
«مرتبسازی حبابی» (Bubble Sort)، یکی از انواع الگوریتمهای مرتبسازی محسوب میشود. این الگوریتم مرتبسازی از جمله الگوریتمهای مبتنی بر مقایسه است که در آن، جفت عنصرهای همجوار با یکدیگر مقایسه شده و در صورتی که دارای ترتیب صحیحی نباشند، با یکدیگر جا به جا میشوند. الگوریتم مرتب سازی حبابی برای مجموعه دادههای بزرگ مناسب نیست، زیرا پیچیدگی زمانی آن در حالت میانگین و بدترین حالت برابر با (Ο(n2 است، که در آن n تعداد کل عناصر مجموعه داده محسوب میشود. در این مطلب، ابتدا یک مثال از الگوریتم مرتبسازی حبابی ارائه و سپس، «روندنما» (Flow Chart)، شبه کد و پیادهسازی آن در زبانهای «پایتون» (Python)،«جاوا» (Java)، «سی» (C) و «سیپلاسپلاس» (++C)، «پیاچپی» (PHP) و «سیشارپ» (#C) ارائه شده است. شایان توجه است که الگوریتمهای مرتبسازی از جمله مباحث بسیار مهم در «ساختمان داده» (Data Structure) هستند.
الگوریتم مرتب سازی حبابی چطور کار میکند؟
برای تشریح چگونگی عملکرد الگوریتم مرتب سازی حبابی، از یک مثال استفاده شده است. در این مثال، یک آرایه غیر مرتب در نظر گرفته شده است. با توجه به اینکه الگوریتم مرتب سازی حبابی از مرتبه (Ο(n2 است، آرایه انتخاب شده کوچک در نظر گرفته میشود. آرایه در نظر گرفته شده: ( ۴ ۲ ۸ ۱ ۵ ) است. مرتبسازی حبابی برای این آرایه، به صورت زیر انجام میشود.
۱. ابتدا، دو عنصر اول آرایه با یکدیگر مقایسه میشوند و با توجه به آنکه ۵ از ۱ بزرگتر است (۱<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 5 1 4 2 8 ) –> ( 1 5 4 2 8 )
۲. در اینجا، عناصر دوم و سوم آرایه مقایسه میشوند و با توجه به اینکه ۵ از ۴ بزرگتر است (۴<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 5 4 2 8 ) –> ( 1 4 5 2 8 )
۳. اکنون، عنصر سوم و چهارم آرایه مقایسه میشوند و با توجه به اینکه ۲ از ۵ کوچکتر است (۲<۵)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 4 5 2 8 ) –> ( 1 4 2 5 8 )
۴. در اینجا، عنصر چهارم و پنجم آرایه مقایسه میشود و چون ۵ از ۸ کوچکتر است (۵<۸) دو عنصر در جای خود بدون هر گونه جا به جایی باقی میمانند؛ چون در واقع، ترتیب (صعودی) در آنها رعایت شده است.
( 1 4 2 5 8 ) –> ( 1 4 2 5 8 )
اکنون یک دور کامل در آرایه زده شد. دومین دور نیز به شیوه بیان شده در بالا انجام میشود.
۱. جا به جایی اتفاق نمیافتد.
( 1 4 2 5 8 ) –> ( 1 4 2 5 8 )
۲. با توجه به بزرگتر بودن ۴ از ۲ (۲<۴)، این دو عنصر با یکدیگر جا به جا میشوند.
( 1 4 2 5 8 ) –> ( 1 2 4 5 8 )
۳. جا به جایی اتفاق نمیافتد.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
۴. جا به جایی اتفاق نمیافتد.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
در حال حاضر، آرایه مرتب شده است، اما الگوریتم نمیداند که آیا کار به پایان رسیده یا خیر؛ بنابراین، به یک دور کامل دیگر بدون انجام هرگونه جا به جایی نیاز دارد تا بفهمد که مرتبسازی با موفقیت به پایان رسیده است.
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
( 1 2 4 5 8 ) –> ( 1 2 4 5 8 )
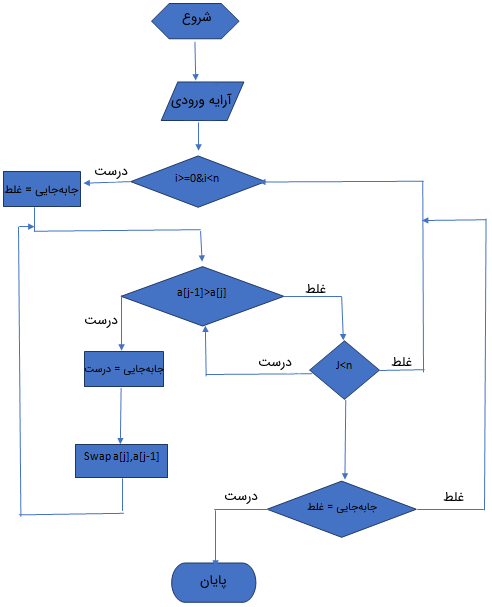
شبه کد الگوریتم مرتب سازی حبابی
در ادامه، پیادهسازی الگوریتم مرتب سازی حبابی در زبانهای برنامهنویسی گوناگون انجام شده و آرایه {۹۰ ,۱۱ ,۲۲ ,12 ,۲۵ ,۳۴ ,۶۴} به عنوان ورودی به قطعه کدها داده شده است. بنابراین، خروجی نهایی همه قطعه کدها، به صورت زیر خواهد بود.
11 12 22 25 34 64 90
پیادهسازی الگوریتم مرتب سازی حبابی در پایتون
پیادهسازی الگوریتم مرتب سازی حبابی در جاوا
پیادهسازی الگوریتم مرتب سازی حبابی در C و ++C
پیادهسازی الگوریتم مرتب سازی حبابی در PHP
پیادهسازی الگوریتم مرتب سازی حبابی در سی شارپ
پیاده سازی بهینه الگوریتم مرتب سازی حبابی
تابع معرفی شده در بالا در حالت متوسط و بدترین حالت، برابر با (O(n*n است. بدترین حالت تنها هنگامی به وقوع میپیوندد که آرایه به ترتیب معکوسی مرتب شده باشد. پیچیدگی زمانی تابع مذکور در بهترین حالت برابر با (O(n است و این حالت تنها هنگامی اتفاق میافتد که آرایه مرتب شده باشد. تابع بالا را میتوان به این شکل بهینه کرد که اگر حلقه داخلی منجر به هیچ جا به جایی نشود، فرایند متوقف شود. در ادامه، نمونه کد مربوط به تابع بهینه شده، در زبانهای برنامهنویسی گوناگون از جمله پایتون (نسخه ۳) ارائه شده است.
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در پایتون
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در جاوا
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در ++C
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در PHP
پیادهسازی بهینه الگوریتم مرتب سازی حبابی در #C
جمعبندی
الگوریتم مرتبسازی حبابی با توجه به سادگی که دارد، معمولا برای معرفی مفهوم مرتبسازی مورد استفاده قرار میگیرد. در گرافیک کامپیوتری، این الگوریتم مرتبسازی با توجه به توانایی که برای تشخیص خطاهای خیلی کوچک (مانند جا به جایی تنها دو عنصر) در آرایههای تقریبا مرتب شده و رفع آن با پیچیدگی خطی (2n) دارد، از محبوبیت زیادی برخوردار است. برای مثال، در الگوریتم «پر کردن چند ضلعی» (Polygon Filling Algorithm) که خطهای محدود کننده به وسیله مختصات x در یک خط اسکن مشخص مرتبسازی شدهاند (خطی موازی محور x) و با افزایش y ترتیب آنها در تقاطع دو خط تغییر میکند (دو عنصر جا به جا میشوند)، مورد استفاده قرار میگیرد.
منبع: فرادرس