طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیچند نخی (Multi-Threading) در سیستم عامل — راهنمای جامع
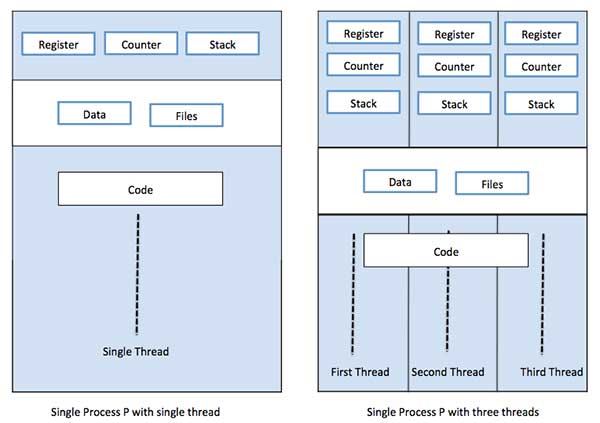
منظور از نخ (thread) یک گردش اجرایی از طریق کد پردازشی است که شمارنده برنامه خاص خود را برای ردگیری دستورالعملهای اجرایی بعدی دارد. هر نخ شامل ثباتهای سیستم که متغیرهای کاری کنونی را نگهداری میکنند و پشتهای که شامل تاریخچه اجرایی است نیز میشود. در این نوشته به معرفی مفهوم محاسبات چند نخی در سیستمهای عامل میپردازیم.
هر نخ اطلاعاتی شامل قطعه کد، قطعه داده و فایلهای باز را با نخهای همتایش به اشتراک میگذارد. زمانی که یک نخ آیتم حافظه قطعهای از کد را تغییر میدهد، همه نخهای دیگر میتوانند آن را ببینند.
یک نخ به نام پردازش سبک (lightweight process) نیز نامیده میشود. نخها روشی برای بهبود عملکرد برنامه از طریق موازیسازی ارائه میکنند. نخها نشاندهنده یک رویکرد نرمافزاری برای بهبود عملکرد سیستم عامل از طریق کاهش نخ بالاسری هستند. نخ بالاسری (overhead thread) معادل یک پردازش کلاسیک است.
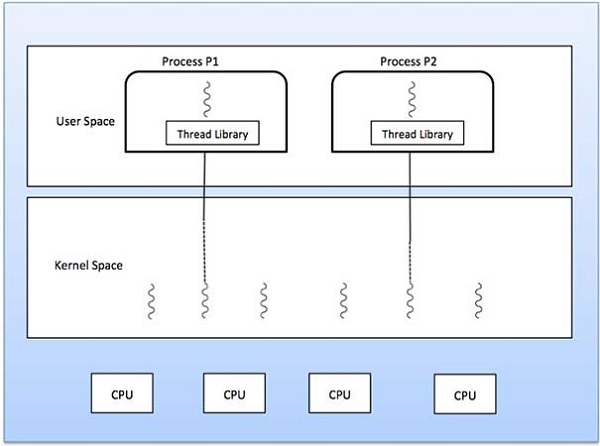
هر نخ صرفاً به یک پردازش تعلق دارد و هیچ نخی نمیتواند به خارج از پردازش خودش حرکت کند. در واقع هر نخ، گردش کنترل مجزایی را نمایش میدهد. نخها در پیادهسازی سرورهای شبکه و وبسرور با موفقیت استفاده شدهاند. آنها همچنین بنیان مناسبی برای اجرای موازی اپلیکیشن روی پردازندههای چندهستهای با حافظه مشترک محسوب میشوند. در تصویر زیر، طرز کار یک پردازش تک نخی و چند نخی نمایش یافته است.
تفاوتهای بین پردازش و نخ
| ردیف | پردازش | نخ |
|---|---|---|
| 1 | پردازش وزن سنگینی دارد و منابع زیادی مصرف میکند. | نخ وزن سبکی دارد و منابع کمتری نسبت به پردازش میگیرد. |
| 2 | سوئیچ کردن بین پردازشها نیازمند تعامل با سیستم عامل است. | سوئیچ کردن بین نخها نیازی به تعامل با سیستم عامل ندارد. |
| 3 | در محیطهای چند پردازشی، هر پردازش کد یکسانی را اجرا میکند؛ اما حافظه و منابع فایل مخصوص خود را دارد. | همه نخها مجموعه یکسانی از فایلهای باز و پردازشهای فرزند را دارند. |
| 4 | اگر یک پردازش مسدود شود، در این صورت پردازش دیگری نمیتواند اجرا شود تا این که پردازش اول از حالت قفل شده خارج شود. | زمانی که یک نخ مسدود شده و به حالت انتظار برود، نخ دوم میتواند همان وظیفه را اجرا کند. |
| 5 | پردازشهای چندگانه بدون استفاده از نخها از منابع بیشتری استفاده میکنند. | پردازشهای دارای چند نخ از منابع کمتری استفاده میکنند. |
| 6 | در پردازشهای چندگانه هر پردازش به طور مستقل از دیگران عمل میکند. | یک نخ میتواند دادههای نخ دیگر را خوانده، نوشته و تغییر دهد. |
مزیتهای نخ
- نخها زمان سوئیچ زمینه را کاهش میدهند.
- استفاده از نخ باعث همزمانی درون یک پردازش میشود.
- ارتباط کارآمدی صورت میگیرد.
- ایجاد سوئیچهای زمینه برای نخها بسیار بهصرفهتر است.
- نخها امکان استفاده از معماری چندپردازندهای را در مقیاس و کارآمدی بالاتر فراهم میکنند.
انواع نخ
نخها به دو روش زیر پیادهسازی میشوند:
- نخهای در سطح کاربر – این نخها از سوی کاربران مدیریت میشوند.
- نخهای در سطح کرنل – سیستم عامل نخهای ایجاد شده در سطح کرنل که همان هسته سیستم عامل است، مدیریت میکند.
نخهای در سطح کاربر
در این حالت کرنل مدیریت نخ از وجود نخها اطلاعی ندارد. کتابخانه نخ شامل کد لازم برای ایجاد و تخریب نخ، ارسال پیام و داده بین نخها، زمانبندی اجرای نخ و ذخیرهسازی و بازیابی زمینههای نخ است. اپلیکیشن با یک نخ منفرد آغاز میشود.
مزیتها
- سوئیچ کردن بین نخها نیازمند دسترسی به کرنل نیست.
- نخهای در سطح کاربر روی هر سیستم عاملی اجرا میشوند.
- زمانبندی نخهای در سطح کاربر میتوان خاص یک اپلیکیشن باشد.
- نخهای سطح کاربر به طور سریعی ایجاد و مدیریت میشوند.
معایب
- در یک سیستم عامل معمولی اغلب فراخوانیهای سیستم مسدود میشوند.
- اپلیکیشن چند نخی نمیتواند از مزیت چند پردازشی بهرهمند شود.
نخهای سطح کرنل
در این حالت مدیرت نخ از سوی کرنل اجرا میشود و هیچ کدِ مدیریت نخی در سطح اپلیکیشن وجود ندارد. نخهای کرنل مستقیماً از سوی سیستم عامل پشتیبانی میشوند. هر اپلیکیشن میتواند طوری برنامهنویسی شود که چند نخی باشد. همه نخهای درون یک اپلیکیشن در یک پردازش منفرد پشتیبانی میشوند.
کرنل اطلاعات زمینهای را برای پردازش به صورت یک کل نگهداری میکند و اطلاعات نخهای منفرد درون پردازش قرار دارد. زمانبندی از سوی کرنل بر مبنای نخها صورت میگیرد. کرنل ایجاد نخ، زمانبندی و مدیریت آنها را در فضای کرنل اجرا میکند. نخهای کرنل به طور کلی فرایند ایجاد و مدیریت کُندتری نسبت به نخهای کاربر دارند.
مزیتها
- کرنل میتواند به طور همزمان چند نخ از یک پردازش را روی چند پردازش زمانبندی کند.
- اگر یک نخ در پردازش مسدود شود، کرنل میتواند نخ دیگری را روی همان پردازش زمانبندی کند.
- روالهای کرنل خودشان چند نخی هستند.
معایب
- نخهای کرنل عموماً فرایند ایجاد و مدیریت کندتری نسبت به نخهای کاربر دارند.
- انتقال کنترل از یک نخ به نخ دیگر درون یک پردازش نیازمند مد سوئیچ روی کرنل است.
مدلهای چند نخی
برخی از سیستمهای عامل ترکیبی از نخهای سطح کاربر و کرنل ارائه میکنند. سولاریس نمونه مناسبی از این رویکرد ترکیبی است. در یک سیستم ترکیبی چندین نخ درون اپلیکیشن یکسان میتوانند به طور موازی روی چندپردازنده اجرا شوند و بدین ترتیب انسداد سیستم الزامی برای مسدود شدن کل پردازش ندارد. مدلهای چند نخی سه نوع هستند:
- رابطه چند به جند
- رابطه چند به یک
- رابطه یک به یک
مدل چند به چند
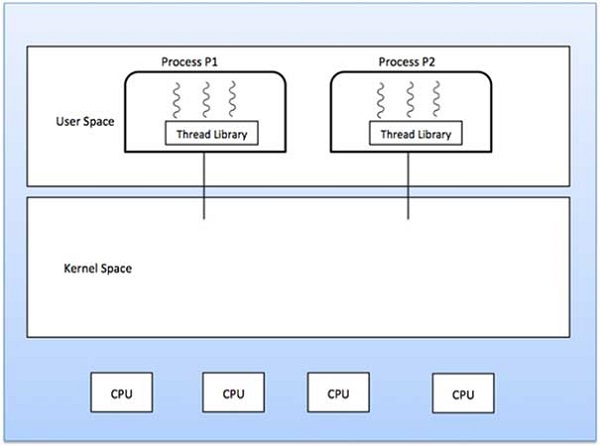
در مدل چند به چند هر تعداد از نخهای کاربر که وجود داشته باشند، به تعداد برابر یا کمتری از نخهای کرنل تقسیم میشوند.
در نمودار زیر مدل نخ بندی چند به چندی را میبینید که 6 نخ در سطح کاربر به 6 نخ در سطح کرنل تقسیم شدهاند. در این مدل توسعهدهندهها میتوانند به هر تعداد که دوست دارند نخهای در سطح کاربر ایجاد کنند و نخهای معادل کرنل میتوانند به طور موازی روی یک ماشین چندپردازندهای اجرا شوند. این مدل بهترین دقت را روی همزمانی ارائه میکند و زمانی که یک نخ فراخوانی انسداد سیستم را اجرا میکند، کرنل میتواند نخ دیگری برای اجرا زمانبندی کند.
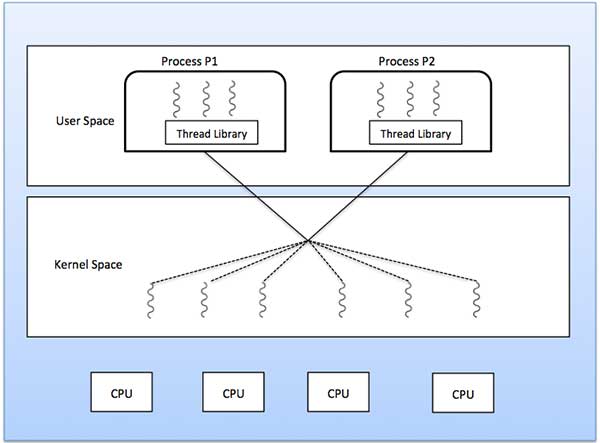
مدل چند به یک
مدل چند به یک نخهای سطح کاربر را به یک نخ در سطح کرنل نگاشت میکند. مدیریت نخ در فضای کاربر به وسیله کتابخانه نخ انجام میپذیرد. زمانی که یک نخ موجب انسداد سیستم میشود، کل پردازش مسدود خواهد شد. در این حالت، هر زمان تنها یک نخ میتواند به کرنل دسترسی داشته باشد و از این رو چندین نخ نمیتوانند به طور موازی در محیط چندپردازندهای اجرا شوند.
اگر کتابخانههای در سطح کاربر در سیستم عامل به طرزی پیادهسازی شوند که سیستم از آنها پشتیبانی نکند، در این صورت نخهای کرنل میتوانند از مدلهای رابطه چند به یک استفاده کنند.
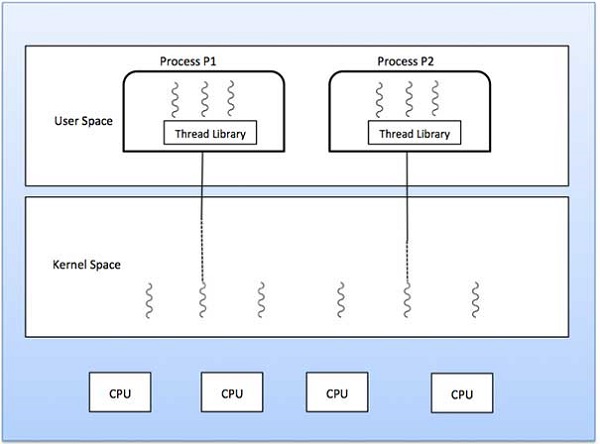
مدل یک به یک
در مدل رابطه یک به یک برای هر نخ در سطح کاربر یک نخ در سطح کرنل وجود دارد. در این مدل همزمانی بیشتری نسبت به مدل چند به یک وجود دارد. این مدل امکان اجرای نخ دیگر در هنگام انسداد سیستمی یک نخ را فراهم میسازد. این مدل از اجرای چنین نخ به طور موازی روی محیطهای چندپردازندهای پشتیبانی میکند.
عیب این مدل آن است که ایجاد نخهای در سطح کاربر، نیازمند نخهای متناظری در سطح کرنل است. OS/2، ویندوز NT و ویندوز 2000 از مدل رابطه یک به یک استفاده میکنند.
تفاوتهای بین نخهای سطح کاربر و سطح کرنل
| ردیف | نخهای سطح کاربر | نخهای سطح کرنل |
|---|---|---|
| 1 | نخهای سطح کاربر ایجاد و مدیریت سریعتری دارند. | نخهای سطح کرنل ایجاد و مدیریت کندتری دارند. |
| 2 | نخهای سطح کاربر توسط کتابخانه نخ در سطح کاربر پیادهسازی میشوند. | سیستم عامل از ایجاد نخهای سطح کرنل پشتیبانی میکند. |
| 3 | نخهای سطح کاربر یکسان هستند و میتوانند روی هر سیستم عاملی اجرا شوند. | نخهای سطح کرنل خاص هر سیستم عامل هستند. |
| 4 | اپلیکیشنهای چند نخی نمیتوانند از مزیت چندپردازندهای بودن بهرهمند شوند. | رویههای کرنل خودشان چند نخی هستند. منبع: فرادرس |
چگونه از گیت (Git) به طرز موثرتری استفاده کنیم؟ — به زبان ساده
گیت نرمافزار بسیار مفیدی است که به منظور کمک به فرایند توسعه پروژههای برنامهنویسی استفاده میشود. گیت هیچ الزام خاصی برای زبان برنامهنویسی یا ساختار فایل ندارد و همه چیز بر عهده برنامهنویس گذارده شده است تا گردش کاری خود را سازماندهی کند.
در این نوشته فرض شده که شما گیت را روی سیستم خود نصب کردهاید و تنظیمات پیکربندی عمومی (مانند نام کاربری و ایمیل) را نیز به طرز صحیحی تنظیم کردهاید. اگر چنین نیست، میتوانید از مقاله «نصب گیت (Git) روی اوبونتو» کمک بگیرید.
پیش از استفاده از گیت برای توسعه کد، بهتر است گردش کار خود را طرحریزی کنید. تصمیمگیری در مورد گردش کار معمولاً مبتنی بر اندازه و مقیاس پروژه صورت میگیرد. برای این که درکی اولیه از گیت داشته باشید، طراحی یک گردش کاری ساده و تک انشعابی (single branch) کافی خواهد بود. به طور پیشفرض نخستین شاخه از هر پروژه گیت به نام «مستر» (master) نامیده میشود. در این راهنما با روش ساخت شاخههای دیگر نیز آشنا میشویم.
در ادامه نخستین پروژه خود را به نام «testing» میسازیم. اگر از قبل پروژهای دارید که میخواهید به گیت ایمپورت کنید، میتوانید به بخش «تبدیل پروژه به محیط فضای کار» مراجعه کنید.
ایجاد فضای کار (workspace)
همان طور که هر کس دوست دارد محیط کاری تمیز و مناسبی داشته باشد، این مسئله در مورد محل کدنویسی نیز به خصوص در حالتی که همزمان روی چند پروژه کار شود، صدق میکند. پیشنهاد خوب در این زمینه آن است که پوشهای به نام git روی دایرکتوری home سیستم خود داشته باشید که زیرپوشههای آن هر یک به یک پروژه مستقل اختصاص داشته باشند.
نخستین کاری که باید برای ایجاد محیط کاری خود انجام دهید، به صورت زیر است:
user@host ~ $ mkdir -p ~/git/testing; cd ~/git/testing
دستور فوق دو کار انجام میدهد:
- یک دایرکتوری به نام git در دایرکتوری home ایجاد میکند و سپس یک زیردایرکتوری به نام testing داخل آن ایجاد میکند. در واقع پروژه ما درون این زیردایرکتوری ذخیره خواهد شد.
- ما را به این زیردایرکتوری میبرد.
زمانی که وارد این دایرکتوری شدیم، باید چند فایل ایجاد کنیم که پروژه ما را تشکیل خواهند داد. در این مرحله هم میتوانید چند فایل ساختگی به منظور تست ایجاد کنید و یا این که فایلها/دایرکتوریهایی که میخواهید واقعاً بخشی از پروژه شما باشند را ایجاد کنید.
ما با استفاده از دستور زیر یک فایل تست ایجاد میکنیم که در ریپازیتوری که ایجاد میکنیم، استفاده خواهد شد:
user@host ~/git/testing $ touch file
زمانی که فایلهای پروژه در فضای کاری آماده شدند، باید شروع به ردگیری فایلها با گیت بکنیم. در مرحله بعدی این فرایند توصیف خواهد شد.
تبدیل یک پروژه موجود به محیط فضای کاری
زمانی که همه فایلها در محیط کاری گیت آماده شدند، باید به گیت بگوییم که میخواهیم از دایرکتوری جاری به عنوان محیط گیت استفاده کنیم:
user@host ~/git/testing $ git init Initialized empty Git repository in /home/user/git/testing/.git/
زمانی که ریپازیتوری خالی اولیه خود را راهاندازی کردیم، میتوانیم فایلها را به آن اضافه کنیم. در ادامه همه فایلها و دایرکتوریها را به ریپازیتوری جدیداً ایجاد شده اضافه میکنیم:
user@host ~/git/testing $ git add.
در این حالت بنا به مصداق ضربالمثل «بیخبری، خوشخبری است»، اگر هیچ خروجی دیده نشود، یعنی همه چیز به درستی پیش رفته است. متأسفانه گیت در همه موارد در صورت بروز اشکال، اطلاعرسانی نمیکند.
هر زمان که مواردی را به فایلها اضافه کنید یا تغییری ایجاد کنید، باید یک پیام کامیت (commit) بنویسید. در بخش بعدی توضیح میدهیم که پیام کامیت چیست و چگونه میتوان آن را نوشت.
ایجاد یک پیام کامیت
پیام کامیت، پیام کوتاهی است که تغییراتی که صورت گرفته است را توضیح میدهد. این پیام برای ارسال تغییرات کد به ریپازیتوری که پوش (push) نامیده میشود ضروری است و روش مناسبی برای ارتباط با همکاران توسعهدهنده محسوب میشود که میخواهند تغییرات را مشاهده کنند. در این بخش روش ایجاد کامیت را توضیح میدهیم.
پیامهای کامیت به طور کلی کوتاه هستند و در یک یا دو جمله تغییراتی که ایجاد شدهاند را توضیح میدهند. توضیح همه تغییراتی که صورت گرفته است، پیش از ارسال هر پوش رویه مناسبی است. شما میتوانید به هر تعداد که دوست دارید پوش کنید. تنها الزام برای هر کامیت این است که باید دست کم یک فایل وجود داشته باشند و همچنین پیامی برای آن تنظیم شود. هر Push باید دست کم یک کامیت داشته باشد.
اگر مثال خود را پیگیری کنیم میتوانیم پیام نخستین کامیت خود را به صورت زیر تنظیم کنیم:
user@host ~/git/testing $ git commit -m "Initial Commit" -a [master (root-commit) 1b830f8] initial commit 0 files changed create mode 100644 file
دو پارامتر مهم در دستور فوق وجود دارد. نخست پارامتر m- است که مشخص میسازد پیام کامیت ما در ادامه آمده است. پارامتر دوم a- است که تعیین میکنید میخواهیم پیام کامیت ما در مورد همه فایلهای اضافه شده یا تغییر یافته اعمال شود. این وضعیت برای نخستین کامیت مشکلی ندارد؛ اما به طور کلی باید فایلها یا دایرکتوریهای منفردی که میخواهیم کامیت کنیم را تعیین نماییم. همچنین میتوانیم دستور زیر را برای تعیین فایل خاصی که کامیت میکنیم، به کار بگیریم:
user@host ~/git/testing $ git commit -m "Initial Commit" file
برای افزودن فایلها یا دایرکتوریهای دیگر باید یک فهرست جداشده با کاراکتر اسپیس به انتهای دستور فوق اضافه کنید.
پوش کردن تغییرات به سرور ریموت
ما تا این مرحله از این راهنما، همه کارهای خود را روی سرور محلی انجام دادهایم. با این که استفاده محلی از گیت، مواردی که میخواهید روش آسانی برای کنترل نسخه فایلهایتان داشته باشید، گزینه ایدهآلی محسوب میشود؛ اما اگر میخواهید با تیمی از توسعهدهندگان کار کنید باید تغییرات را به یک سرور ریموت پوش کنید. در ادامه روش این کار را توضیح میدهیم.
در مرحله نخست باید بتوانیم کد خود را از طریق یک URL که مربوط به ریپازیتوری است به آن پوش کنیم و یک نام نیز برای آن تعیین کنیم. برای پیکربندی ریپازیتوری ریموت جهت استفاده و دیدن همه سرورهای ریموت (شما میتوانید چند سرور ریموت داشته باشید) باید دستور زیر را وارد کنید:
user@host ~/git/testing $ git remote add origin ssh://git@git.domain.tld/repository.git user@host ~/git/testing $ git remote -v origin ssh://git@git.domain.tld/repository.git (fetch) origin ssh://git@git.domain.tld/repository.git (push)
دستور نخست یک سرور ریموت به نام «origin» اضافه میکند و URL را به صورت ssh://git@git.domain.tld/repository.git تنظیم میکند.
شما میتوانید نام ریموت را هر چیزی که دوست دارید بگذارید؛ اما URL باید به یک ریپازیتوری ریموت واقعی اشاره کند. برای نمونه اگر بخواهید کد خود را به گیتهاب پوش کنید، باید از ریپازیتوری دارای URL ارائه شده از سوی گیتهاب استفاده کنید. زمانی که ریموت پیکربندی شد میتوانید کد خود را پوش کنید.
با دستور زیر میتوان کد را به سرور ریموت پوش کرد:
user@host ~/git/testing $ git push origin master Counting objects: 4, done. Delta compression using up to 2 threads. Compressing objects: 100% (2/2), done. Writing objects: 100% (3/3), 266 bytes, done. Total 3 (delta 1), reused 1 (delta 0) To ssh://git@git.domain.tld/repository.git 0e78fdf..e6a8ddc master -> master
دستور git push به گیت میگوید که میخواهید تغییرات را پوش کنید. در دستور فوق «origin» نام سرور ریموت اخیراً پیکربندیشده ما است و «master» نیز نام نخستین شاخه یا branch ما محسوب میشود. در آینده هر کامیتی را که بخواهید به سرور پوش کنید، میتوانید به سادگی از دستور git push استفاده کنید.
امیدواریم این مقاله درکی مقدماتی از طرز کار گیت به شما ارائه کرده باشد و بتوانید از آن به طرز مؤثری برای کار با همکارانتان استفاده کنید. در بخش بعدی این سری از مقالات، تحلیل عمیقتری از برنچهای گیت و دلیل کارآمدی آنها خواهیم داشت.
چگونه از گیت (Git) به طرز موثرتری استفاده کنیم؟ — به زبان ساده
گیت نرمافزار بسیار مفیدی است که به منظور کمک به فرایند توسعه پروژههای برنامهنویسی استفاده میشود. گیت هیچ الزام خاصی برای زبان برنامهنویسی یا ساختار فایل ندارد و همه چیز بر عهده برنامهنویس گذارده شده است تا گردش کاری خود را سازماندهی کند.
در این نوشته فرض شده که شما گیت را روی سیستم خود نصب کردهاید و تنظیمات پیکربندی عمومی (مانند نام کاربری و ایمیل) را نیز به طرز صحیحی تنظیم کردهاید. اگر چنین نیست، میتوانید از مقاله «نصب گیت (Git) روی اوبونتو» کمک بگیرید.
پیش از استفاده از گیت برای توسعه کد، بهتر است گردش کار خود را طرحریزی کنید. تصمیمگیری در مورد گردش کار معمولاً مبتنی بر اندازه و مقیاس پروژه صورت میگیرد. برای این که درکی اولیه از گیت داشته باشید، طراحی یک گردش کاری ساده و تک انشعابی (single branch) کافی خواهد بود. به طور پیشفرض نخستین شاخه از هر پروژه گیت به نام «مستر» (master) نامیده میشود. در این راهنما با روش ساخت شاخههای دیگر نیز آشنا میشویم.
در ادامه نخستین پروژه خود را به نام «testing» میسازیم. اگر از قبل پروژهای دارید که میخواهید به گیت ایمپورت کنید، میتوانید به بخش «تبدیل پروژه به محیط فضای کار» مراجعه کنید.
ایجاد فضای کار (workspace)
همان طور که هر کس دوست دارد محیط کاری تمیز و مناسبی داشته باشد، این مسئله در مورد محل کدنویسی نیز به خصوص در حالتی که همزمان روی چند پروژه کار شود، صدق میکند. پیشنهاد خوب در این زمینه آن است که پوشهای به نام git روی دایرکتوری home سیستم خود داشته باشید که زیرپوشههای آن هر یک به یک پروژه مستقل اختصاص داشته باشند.
نخستین کاری که باید برای ایجاد محیط کاری خود انجام دهید، به صورت زیر است:
user@host ~ $ mkdir -p ~/git/testing; cd ~/git/testing
دستور فوق دو کار انجام میدهد:
- یک دایرکتوری به نام git در دایرکتوری home ایجاد میکند و سپس یک زیردایرکتوری به نام testing داخل آن ایجاد میکند. در واقع پروژه ما درون این زیردایرکتوری ذخیره خواهد شد.
- ما را به این زیردایرکتوری میبرد.
زمانی که وارد این دایرکتوری شدیم، باید چند فایل ایجاد کنیم که پروژه ما را تشکیل خواهند داد. در این مرحله هم میتوانید چند فایل ساختگی به منظور تست ایجاد کنید و یا این که فایلها/دایرکتوریهایی که میخواهید واقعاً بخشی از پروژه شما باشند را ایجاد کنید.
ما با استفاده از دستور زیر یک فایل تست ایجاد میکنیم که در ریپازیتوری که ایجاد میکنیم، استفاده خواهد شد:
user@host ~/git/testing $ touch file
زمانی که فایلهای پروژه در فضای کاری آماده شدند، باید شروع به ردگیری فایلها با گیت بکنیم. در مرحله بعدی این فرایند توصیف خواهد شد.
تبدیل یک پروژه موجود به محیط فضای کاری
زمانی که همه فایلها در محیط کاری گیت آماده شدند، باید به گیت بگوییم که میخواهیم از دایرکتوری جاری به عنوان محیط گیت استفاده کنیم:
user@host ~/git/testing $ git init Initialized empty Git repository in /home/user/git/testing/.git/
زمانی که ریپازیتوری خالی اولیه خود را راهاندازی کردیم، میتوانیم فایلها را به آن اضافه کنیم. در ادامه همه فایلها و دایرکتوریها را به ریپازیتوری جدیداً ایجاد شده اضافه میکنیم:
user@host ~/git/testing $ git add.
در این حالت بنا به مصداق ضربالمثل «بیخبری، خوشخبری است»، اگر هیچ خروجی دیده نشود، یعنی همه چیز به درستی پیش رفته است. متأسفانه گیت در همه موارد در صورت بروز اشکال، اطلاعرسانی نمیکند.
هر زمان که مواردی را به فایلها اضافه کنید یا تغییری ایجاد کنید، باید یک پیام کامیت (commit) بنویسید. در بخش بعدی توضیح میدهیم که پیام کامیت چیست و چگونه میتوان آن را نوشت.
ایجاد یک پیام کامیت
پیام کامیت، پیام کوتاهی است که تغییراتی که صورت گرفته است را توضیح میدهد. این پیام برای ارسال تغییرات کد به ریپازیتوری که پوش (push) نامیده میشود ضروری است و روش مناسبی برای ارتباط با همکاران توسعهدهنده محسوب میشود که میخواهند تغییرات را مشاهده کنند. در این بخش روش ایجاد کامیت را توضیح میدهیم.
پیامهای کامیت به طور کلی کوتاه هستند و در یک یا دو جمله تغییراتی که ایجاد شدهاند را توضیح میدهند. توضیح همه تغییراتی که صورت گرفته است، پیش از ارسال هر پوش رویه مناسبی است. شما میتوانید به هر تعداد که دوست دارید پوش کنید. تنها الزام برای هر کامیت این است که باید دست کم یک فایل وجود داشته باشند و همچنین پیامی برای آن تنظیم شود. هر Push باید دست کم یک کامیت داشته باشد.
اگر مثال خود را پیگیری کنیم میتوانیم پیام نخستین کامیت خود را به صورت زیر تنظیم کنیم:
user@host ~/git/testing $ git commit -m "Initial Commit" -a [master (root-commit) 1b830f8] initial commit 0 files changed create mode 100644 file
دو پارامتر مهم در دستور فوق وجود دارد. نخست پارامتر m- است که مشخص میسازد پیام کامیت ما در ادامه آمده است. پارامتر دوم a- است که تعیین میکنید میخواهیم پیام کامیت ما در مورد همه فایلهای اضافه شده یا تغییر یافته اعمال شود. این وضعیت برای نخستین کامیت مشکلی ندارد؛ اما به طور کلی باید فایلها یا دایرکتوریهای منفردی که میخواهیم کامیت کنیم را تعیین نماییم. همچنین میتوانیم دستور زیر را برای تعیین فایل خاصی که کامیت میکنیم، به کار بگیریم:
user@host ~/git/testing $ git commit -m "Initial Commit" file
برای افزودن فایلها یا دایرکتوریهای دیگر باید یک فهرست جداشده با کاراکتر اسپیس به انتهای دستور فوق اضافه کنید.
پوش کردن تغییرات به سرور ریموت
ما تا این مرحله از این راهنما، همه کارهای خود را روی سرور محلی انجام دادهایم. با این که استفاده محلی از گیت، مواردی که میخواهید روش آسانی برای کنترل نسخه فایلهایتان داشته باشید، گزینه ایدهآلی محسوب میشود؛ اما اگر میخواهید با تیمی از توسعهدهندگان کار کنید باید تغییرات را به یک سرور ریموت پوش کنید. در ادامه روش این کار را توضیح میدهیم.
در مرحله نخست باید بتوانیم کد خود را از طریق یک URL که مربوط به ریپازیتوری است به آن پوش کنیم و یک نام نیز برای آن تعیین کنیم. برای پیکربندی ریپازیتوری ریموت جهت استفاده و دیدن همه سرورهای ریموت (شما میتوانید چند سرور ریموت داشته باشید) باید دستور زیر را وارد کنید:
user@host ~/git/testing $ git remote add origin ssh://git@git.domain.tld/repository.git user@host ~/git/testing $ git remote -v origin ssh://git@git.domain.tld/repository.git (fetch) origin ssh://git@git.domain.tld/repository.git (push)
دستور نخست یک سرور ریموت به نام «origin» اضافه میکند و URL را به صورت ssh://git@git.domain.tld/repository.git تنظیم میکند.
شما میتوانید نام ریموت را هر چیزی که دوست دارید بگذارید؛ اما URL باید به یک ریپازیتوری ریموت واقعی اشاره کند. برای نمونه اگر بخواهید کد خود را به گیتهاب پوش کنید، باید از ریپازیتوری دارای URL ارائه شده از سوی گیتهاب استفاده کنید. زمانی که ریموت پیکربندی شد میتوانید کد خود را پوش کنید.
با دستور زیر میتوان کد را به سرور ریموت پوش کرد:
user@host ~/git/testing $ git push origin master Counting objects: 4, done. Delta compression using up to 2 threads. Compressing objects: 100% (2/2), done. Writing objects: 100% (3/3), 266 bytes, done. Total 3 (delta 1), reused 1 (delta 0) To ssh://git@git.domain.tld/repository.git 0e78fdf..e6a8ddc master -> master
دستور git push به گیت میگوید که میخواهید تغییرات را پوش کنید. در دستور فوق «origin» نام سرور ریموت اخیراً پیکربندیشده ما است و «master» نیز نام نخستین شاخه یا branch ما محسوب میشود. در آینده هر کامیتی را که بخواهید به سرور پوش کنید، میتوانید به سادگی از دستور git push استفاده کنید.
امیدواریم این مقاله درکی مقدماتی از طرز کار گیت به شما ارائه کرده باشد و بتوانید از آن به طرز مؤثری برای کار با همکارانتان استفاده کنید. در بخش بعدی این سری از مقالات، تحلیل عمیقتری از برنچهای گیت و دلیل کارآمدی آنها خواهیم داشت.
اطلاعات پایگاه داده در MySQL — راهنمای جامع
سه نوع اطلاعات پایگاه داده MySQL وجود دارند که میتوان به دست آورد:
- اطلاعاتی در مورد نتیجه کوئریها – این اطلاعات شامل چند رکورد هستند که تحت تأثیر عبارتهای SELECT، UPDATE یا DELETE قرار گرفتهاند.
- اطلاعاتی در مورد جدولها و پایگاههای داده – این اطلاعات شامل مواردی در مورد ساختار پایگاه داده و جدولها میشود.
- اطلاعاتی در مورد سرور MySQL – این مورد نیز شامل وضعیت سرورهای پایگاه داده، شماره نسخه و مواردی از این دست است.
دریافت همه این اطلاعات در خط اعلان MySQL کار آسانی است؛ اما هنگام استفاده از PERL یا PHP باید API های مختلفی را به طور صریح فراخوانی کنیم تا همه این اطلاعات را به دست آوریم.
به دست آوردن تعداد ردیفهایی که از یک کوئری تأثیر پذیرفتهاند
در این بخش روش کسب این اطلاعات را معرفی میکنیم.
مثال PERL
در اسکریپتهای DBI، تعداد ردیفهای تأثیر پذیرفته به وسیله ()do یا از طریق دستور ()execute بازگشت مییابد و این مسئله به چگونگی اجرای کوئری وابسته است.
مثال PHP
در زبان برنامهنویسی PHP، میتوان تابع ()mysql_affected_rows را برای یافتن تعداد ردیفهایی که توسط یک کوئری تغییر یافته است، فراخوانی کرد.
لیست کردن جدولها و پایگاههای داده
لیست کردن همه پایگاههای داده و جدولهای موجود در یک سرور پایگاه داده کار آسانی است. اما در صورتی که دسترسیهای کافی نداشته باشید، ممکن است با نتایج null مواجه شوید.
به جز روشی که در کد زیر برای این منظور استفاده شده است، میتوان از کوئریهای SHOW TABLES یا SHOW DATABASES برای دریافت لیستی از جدولها یا پایگاههای داده در PHP یا PERL استفاده کرد.
مثال PERL
مثال PHP
دریافت فراداده سرور
چند دستور مهم در MySQL وجود دارند که میتوان در اعلان MySQL یا با استفاده از اسکریپتهایی مانند PHP اجرا کرد و اطلاعات مختلفی در مورد سرور پایگاه داده به دست آورد.
| دستور | توضیح |
|---|---|
| ()SELECT VERSION | رشته معرف نسخه سرور |
| ()SELECT DATABASE | نام پایگاه داده جاری (در صورت نبودن، خالی است) |
| ()SELECT USER | نام کاربری جاری |
| SHOW STATUS | نمایش وضعیت سرور |
| SHOW VARIABLES | نمایش متغیرهای پیکربندی سرور |
در این نوشته برخی از دستورها و کوئریهایی که برای دریافت اطلاعاتی در مورد پایگاه داده MySQL در محیطهای مختلف وجود دارند، معرفی کردیم.
منبع: فرادرس