طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیاشتراک گذاری کد بین اندروید و iOS با ++C — از صفر تا صد
در این مقاله به توضیح روش اشتراک گذاری کد بین سیستمهای عامل اندروید و iOS با استفاده از کدنویسی در زبان ++C میپردازیم.
چرا باید کد را به اشتراک گذاشت؟
اغلب توسعهدهندگان حرفهای علاقهمند هستند که اپلیکیشنهای نیتیو بنویسند و به باور این دسته بهترین UX از طریق رابط کاربری روان و بومی به دست میآید. اگر چه غالباً ضروری است که لایه ارائه نیتیو باشد، به طور عکس منطق تجاری اپلیکیشن را میتوان به اشتراک گذاشت. زمانی که منطق تجاری اپلیکیشن به اشتراک گذارده میشود، میتوان کد آن را یک بار نوشت و از این رو هزینه نگهداری کاهش مییابد و امکان طراحی رفتار مشابهی بین سیستمهای عامل اندروید و iOS پدید میآید.
در اغلب پروژهها دستکم بخشی از کد هست که میتوان بین سیستمهای عامل مختلف به اشتراک گذاشت. این بخشها شامل منطق پایگاه داده، اعتبارسنجی کاربر و نظایر آن میشود. در اغلب این موارد، از ++C به عنوان یک زبان مشترک استفاده میشود. در این مقاله، ما با روش انجام این کار و مزایا و معایب استفاده از ++C برای توسعه اپلیکیشنهای موبایل آشنا میشویم.
++C روی موبایل
سیستمهای عامل موبایل امروزه به دو دسته iOS و اندروید تقسیم میشوند.
iOS
++C در سیستم عامل iOS یک شهروند درجه یک محسوب میشود. اگر شما نیز این روزها همچنان به این زبان برنامهنویسی میکنید، میتوانید به سادگی با تغییر دادن فایل منبع از پسوند m. به nm. شروع به کدنویسی برای این سیستم عامل بکنید. البته این تغییر برخی ترفندهای جالب دیگر را نیز در سوئیفت در اختیار ما قرار میدهد. در سوی دیگر سوئیفت هیچ همکاری متقابلی با ++C ندارد. شما میتوانید تابعهای C و ++C را به هم مرتبط کنید؛ اما باید از یک پوشش ++Objective-C برای عرضه کلاسها بهره بگیرید.
اندروید
اندروید نیز با استفاده از کیت توسعه نیتیو (NDK) میتواند از ++C در مواردی که به کدهای با عملکرد بالا نیاز هست یا لازم است کتابخانههایی بر مبنای کدهای موجود ساخته شود استفاده کند. اینترفیس نیتیو جاوا (JNI) شیوه تعامل بین این کد نیتیو و بایتکد نوشته شده در جاوا یا کاتلین را تعیین میکند. پس از راهاندازی زنجیره ابزار، این فرایند به سادگی تعریف کردن و استفاده از متدهای نیتیو در جاوا خواهد بود:
اعلان تابع در سمت پیادهسازی C نیز چنین است:
در روزهای آغازین اشتراک کد در ++C نوشتن چنین اعلانهای رمزآلودی، بخشی جداییناپذیر از فرایند توسعه محسوب میشد. خوشبختانه در سال 2014، Dropbox ابزاری به نام Djinni را منتشر ساخت که میتوانست هر دو اتصال Objective-C++ و JNI را تولید کند.
Djinni
Djinni از یک زبان تعریف اینترفیس (IDL) ساده برای توصیف اینترفیسی که از سوی ++C عرضه میشود، استفاده کرده است. این IDL از رکوردها برای شیءهای مقدار خالص داده و از اینترفیسها برای اشیایی که در یکی از محیطهای ++C یا Objective-C/Java پیادهسازی میشوند بهره میگیرد.
Djinni از انواع مختلفی از داده از enum، بولی، عدد، رشته تا آرایه و نگاشت برای تعریف اینترفیس برای هر نوع اشتراک کدبیس پشتیبانی میکند و امکان پیادهسازی انواع داده سفارشی را نیز در صورت نیاز دارد. برای کسب اطلاعات بیشتر در مورد آن میتوانید به این صفحه (+) مراجعه کنید.
متأسفانه دراپباکس اخیراً اعلام کرده است که نگهداری از Djinni را متوقف میکند. اما این پروژه به قدر کافی بالغ و پایدار است که بتوان بر مبنای آن کدنویسی کرد و تصور نمیشود در طی زمان معقولی در آینده مشکل چندانی پیش بیاید.
تنظیم Djinni
هر پروژهای یک ریپازیتوری GIT دارد که شامل تعاریف اینترفیس و کد ++C اشتراکی است. متأسفانه Djinni تنها یک فایل IDL میپذیرد. از این رو باید برای هر IDL در ریپازیتوری یک فراخوانی به djinni/run داشته باشیم. در حال حاضر فرایند Make برای اندروید به صورت دستی آغاز میشود. روی iOS این فرایند به صورت یک Run Script Phase به فرایند build اضافه شده است.
روی هر دو پلتفرم پیادهسازی ++C به همراه فایلهای تولید شده مستقیماً به پروژه اضافه میشوند. همچنین یک کتابخانه استاتیک ساخته میشود، اما افزودن همه چیز به یک پروژه موجب میشود که فرایند توسعه و دیباگ کردن به مقدار زیادی آسانتر شود. روی اندروید، CMakeList را راهاندازی میکنیم که شامل همه فایلها در چند دایرکتوری است. اما روی iOS به صورت دستی فایلهای جدید را اضافه میکنیم.
افزودن کد جدید ++C
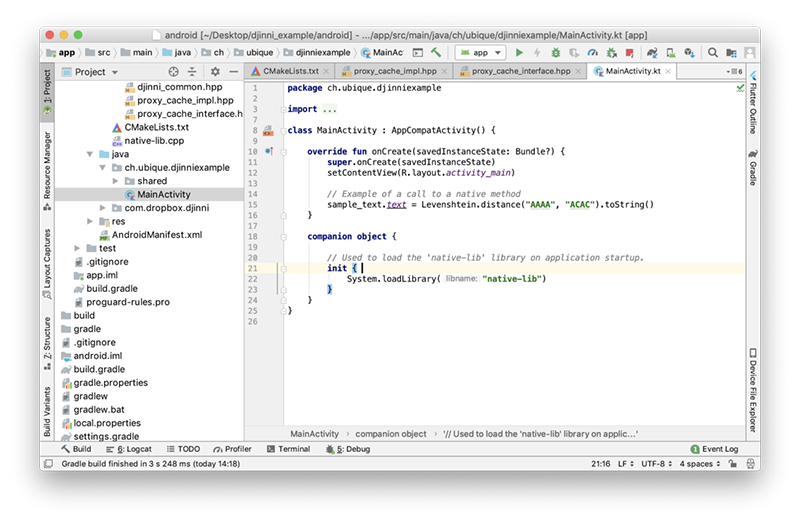
در این بخش مراحلی را که برای افزودن یک قابلیت جدید به کدبیس اشتراکی نیاز داریم توضیح دادهایم. در این مثال، کار خود را از سمت Xcode/iOS آغاز میکنیم، اما شما میتوانید کار خود را از سمت اندروید نیز شروع کنید. ما میخواهیم فاصله بین دو رشته را محاسبه کنیم. این مسئله به نام «فاصله لوناشتاین» (Levenshtein Distance) مشهور است.
تعریف اینترفیس
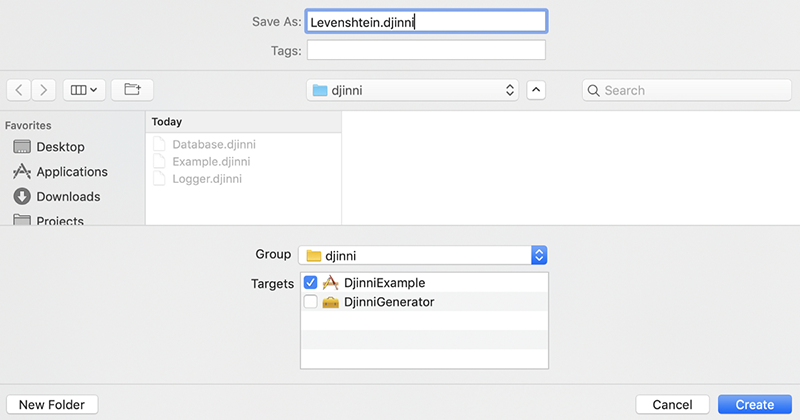
ابتدا باید یک فایل جدید IDL برای تعریف اینترفیس اضافه کنیم. Makefile ما انتظار دارد که یک فایل با پسوند.jinni دریافت کند. پیادهسازی آن کاملاً سرراست است. ما یک اینترفیس جدید تعریف میکنیم و c+ را نیز اضافه میکنیم تا به djinni اعلام کنیم که اینترفیس ++C را پیادهسازی خواهیم کرد. سپس یک متد استاتیک اضافه میکنیم که دو رشته را گرفته و یک عدد صحیح باز میگرداند.
تولید فایلها
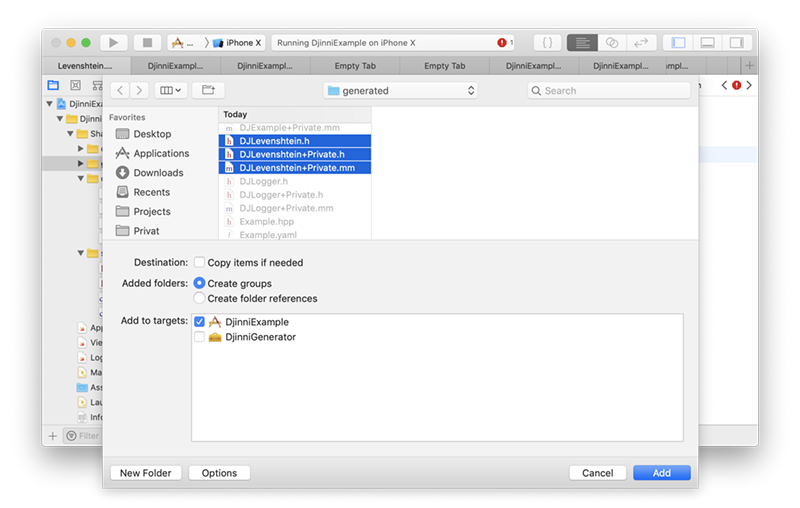
پس از افزودن یک فایل جدید IDL پروژه خود را یک بار build میکنیم تا فایلهای bridging جدید تولید شوند. سپس آنها را به صورت دستی به پروژه Xcode اضافه میکنیم. برای این که فایلها در اختیار سوئیفت قرار گیرند، باید آنها را به هدر bridging نیز اضافه کنیم. چنان که پیشتر اشاره شد، باید Make را به صورت دستی فراخوانی کنیم تا فایلها را برای bridging مربوط به JNI اندروید تولید کند.
پیادهسازی ++C
در نهایت میتوانیم شروع به پیادهسازی «منطق تجاری» (business logic) کوچک خود بکنیم. ابتدا یک فایل ++C میسازیم و آن را به پروژه Xcode اضافه میکنیم. در واقع ما صرفاً اعلان تابع را از هدر عمومی کپی کرده و به پیادهسازی حاصل از Rosettacode (+) اضافه کردیم.
استفاده در پروژهها
کار به همین سادگی بود که شرح دادیم، ما فاصله را در ++C پیادهسازی کردیم و اینک میتوان آن را در Objective-C ،Swift ،Java یا Kotlin استفاده کرد.
سخن پایانی
آیا ++C زبان مناسبی برای نوشتن یک پروژه اپلیکیشن موبایل محسوب میشود؟ پاسخ این است که اگر تمایل به نوشتن کد ++C داشته باشید چنین است و این تنها شرط لازم و کافی برای چنین کاری محسوب میشود. یک پیکربندی با سازماندهی مناسب از djinni بخش عمدهای از دشواری پل زدن بین سیستمهای عامل را رفع میکند، اما موجب کاهش پیچیدگی نوشتن کدهای ++C نمیشود. وقتی به زبانهای Objective-C ،Swift ،Java یا Kotlin کدنویسی میکنید، احتمال بروز باگ خطرناک در اپلیکیشن کم است، اما در زمان کدنویسی ++C چنین امری کاملاً محتمل است. در هر حال، اگر تیم شما از قبل تجربهای در کدنویسی به زبان ++C دارد و آن را زبان مناسبی میداند، میتوانید با استفاده از این زبان به شدت سریع و بالغ و دارای پشتیبانی مناسب اقدام به اشتراک کد بین پلتفرمهای مختلف بکنید.
مزیتها
- هر دو پلتفرم اندروید و iOS خودشان بر مبنای ++C توسعه یافتهاند و از این رو زبان رسمی آنها است و کاملاً پشتیبانی میشود.
- ++C سریع و بالغ است.
- Djinni بخش عمده دشواری پل زدن را به خصوص از طریق JNI از میان برمیدارد.
معایب
- یادگیری ++C دشوار است.
- بروز خطا در ++C بسیار محتملتر است.
- برای تعریف اینترفیسها به یک زبان سوم نیاز دارید.
- متدهای بصری تولید شده به صورت خودکار، یک سطح غیرضروری از انتزاع محسوب میشوند.
- پشتیبانی دیباگر به اندازه زبانهای ابتدایی پلتفرمها خوب نیست.
- در نهایت با پیچیدگیهای کدنویسی به زبان ++C روبرو خواهید بود.
در سالهای اخیر بسیاری از اپلیکیشنهای بزرگ از این تکنیک اشتراک کد از طریق ++C و Djinni استفاده کردهاند. این تکنیک امکان بهرهبرداری حداکثری از سختافزار موجود، تکرارهای سریع بدون نگرانی از واگرایی و تمرکز روی نکتهای که برای همه توسعهدهندگان مهم است، یعنی ایجاد یک تجربه کاربری عالی را فراهم ساخته است.
مرتب سازی هیپ (Heap Sort) در جاوا — راهنمای جامع
در این راهنما با طرز کار مرتبسازی و روش پیادهسازی آن در جاوا آشنا میشویم. مرتبسازی هیپ یا Heap Sort چنان که از نامش برمیآید بر مبنای ساختمان داده هیپ اجرا میشود. برای درک صحیح هیپ ابتدا باید با ساختمان آن و روش پیادهسازیاش آشنا شویم.
ساختمان داده هیپ
هیپ یک ساختمان داده خاص مبتنی بر درخت است و از این رو هیپ را گرههایی تشکیل میدهند. ما عناصر هیپ را به این گرهها انتساب میدهیم. هر گره شامل دقیقاً یک عنصر است. ضمناً گرهها میتوانند فرزندانی داشته باشند. اگر یک گره هیچ فرزندی نداشته باشد آن را برگ مینامیم. آنچه هیپ را خاص میسازد دو چیز است:
- مقدار هر گره باید کمتر یا مساوی مقادیر ذخیره شده در فرزندان آن باشد.
- هیپ یک درخت کامل است یعنی کمترین ارتفاع ممکن را دارد.
به دلیل قاعده اول فوق کمترین عنصر همواره در ریشه درخت قرار میگیرد. روش الزام این قواعد نیز به نوع پیادهسازی وابسته است. هیپها عموماً برای پیادهسازی صفهای اولویت استفاده میشوند، زیرا هیپ یک پیادهسازی کاملاً کارآمد برای استخراج عنصر با کمترین (یا بیشترین) مقدار محسوب میشود.
انواع هیپ
هیپ گونههای بسیار مختلفی دارد که تنها تفاوت آنها از نظر برخی جزییات پیادهسازی با هم متفاوت هستند. برای نمونه آن چه در بخش فوق توصیف کردیم، یک Min-Heap یا هرم کمینه است، زیرا مقدار والد همواره کمتر از فرزندانش است. به طور جایگزین میتوان Max-Heap یا هرم بیشینه نیز داشت که در آن والد همواره بزرگتر از فرزندانش است. از این رو بزرگترین عنصر در گره ریشه قرار خواهد داشت.
ما میتوانیم از میان پیادهسازیهای مختلف درخت یکی را برای هیپ انتخاب کنیم. سرراستترین گزینه درخت دودویی است. در درخت دودویی هر گره میتواند حداکثر دو فرزند داشته باشد. ما آنها را برگ چپ و برگ راست مینامیم. سادهترین روش برای الزام به قاعده دوم بخش فوق استفاده از درخت دودویی کامل است. یک درخت دودویی کامل داری قواعد سادهای به شرح زیر است:
- اگر یک گره تنها یک فرزند داشته باشد، این گره باید برگ چپ باشد.
- تنها گره سمت راست روی عمیقترین سطح میتواند دقیقاً یک فرزند داشته باشد.
- برگها میتوانند صرفاً در عمیقترین سطح باشند.
در مثالهای زیر نمونههایی از قواعد فوق را میبینید:
درختهای 1، 2، 4، 5 و 7 از قواعد فوق پیروی میکنند. درختهای 3 و 6 از قاعده 1 تخطی کردهاند. درختهای 8 و 9 از قاعده دوم تخطی کردهاند و درخت شماره 10 قاعده سوم را نقض میکند.
ما در این راهنما روی Min-Heap با پیادهسازی درخت دودویی متمرکز میشویم.
درج عناصر
ما باید همه عملیات را به ترتیبی پیادهسازی کنیم که هیپ بدون تغییر بماند. بدین ترتیب میتوانیم هیپ را با استفاده از درجهای مکرر بسازیم. بنابراین در ادامه روی یک عمل درج منفرد متمرکز میشویم:
- یک برگ جدید بسازید که سمت راستترین جایگاه ممکن روی عمیقترین سطح است و آیتم را در این گره ذخیره کنید.
- اگر این عنصر کمتر از والدینش باشد، جای آنها را با هم عوض میکنیم.
- گام 2 را تا زمانی که عنصر کمتر از والدینش باشد و یا به ریشه جدید تبدیل شود ادامه میدهیم.
توجه کنید که گام 2 فوق، قاعده هیپ را نقض نمیکند، زیرا اگر مقدار یک گره را با مقدار کمتر عوض کنیم همچنان کمتر از فرزندانش خواهد بود.
در ادامه یک مثال عملی را بررسی میکنیم. فرض کنید میخواهیم مقدار 4 را در این هیپ درج کنیم:
نخستین گام این است که یک برگ جدید ایجاد میکنیم تا مقدار 4 را در آن وارد نماییم:
از آنجا که 4 کمتر از والد خود، 6 است، جای آنها را با هم عوض میکنیم:
اکنون بررسی میکنیم که آیا 4 کمتر از والد خود است یا نه. از آنجا که والد آن 2 است، در این مرحله متوقف میشویم. هیپ همچنان معتبر است و ما مقدار 4 را درج کردهایم.
اکنون تصور کنید میخواهیم مقدار 1 را در این هیپ درج کنیم:
ما باید جای 1 و 4 را تعویض کنیم:
اکنون باید جای 1 و 2 را عوض کنیم:
از آنجا که 1 به ریشه جدید تبدیل شده است در این مرحله متوقف میشویم.
پیادهسازی هیپ در جاوا
از آنجا که از درخت دودویی کامل استفاده میکنیم، میتوانیم آن را با یک آرایه پیادهسازی کنیم. هر عنصر آرایه یک گره در درخت محسوب میشود. هر گره با اندیسهای آرایه از چپ به راست و از بالا به پایین به روش زیر نشانهگذاری میشود:
تنها کاری که باید انجام دهیم، این است که دقت کنیم چه تعداد عنصر باید در درخت ذخیره کنیم. بدین ترتیب اندیس عنصر بعدی که میخواهیم درج کنیم، اندازه آرایه خواهد بود.
با این روش اندیسگذاری میتوانیم اندیس گرههای والد و فرزند را محاسبه کنیم:
- والد: 2/ (index – 1)
- فرزند چپ: 2index +2
- فرزند راست: 2index + 2
از آنجا که نمیخواهیم دردسر تخصیص مجدد آرایه را داشته باشیم، آن پیادهسازی را با بهرهگیری از ArrayList از آن چه که هست بازهم سادهتر میکنیم.
پیادهسازی یک درخت دودویی کامل چیزی مانند زیر است:
کد فوق تنها عنصر جدیدی به انتهای درخت اضافه میکند. از این رو باید عنصر جدید را در صورت لزوم به سمت بالا پیمایش کنیم. این کار را با کد زیر میتوانیم انجام دهیم:
دقت داشته باشید که چون نیاز داریم عناصر را مقایسه کنیم، باید آنها را با استفاده از java.util.Comparable پیادهسازی کنیم.
مرتبسازی هیپ
از آنجا که ریشه هیپ همواره شامل کوچکترین عنصر است، ایده اصلی مرتبسازی هیپ کاملاً ساده است: گرههای ریشه را تا زمانی که هیپ کاملاً خالی شود، حذف میکنیم. تنها کاری که باید انجام دهیم یک عملیات حذف است که هیپ را در حالت سازگار حفظ میکند. ما باید مطمئن شویم که ساختار درخت دودویی یا مشخصه هیپ نقض نمیشود.
برای این که ساختار حفظ شود نمیتوانیم هیچ عنصری را به جز برگ منتهیالیه سمت راست حذف کنیم. بنابراین ایده کار این است که گره ریشه را حذف کنیم و برگ سمت راست را در گره ریشه ذخیره کنیم. اما این عملیات قطعاً مشخصه هیپ را نقض میکند. بنابراین اگر ریشه جدید بزرگتر از هر یک از گرههای فرزندش باشد، آن را با کمترین فرزندش عوض میکنیم. از آنجا که گره کوچکترین فرزند، کوچکتر از همه گرههای فرزند دیگر است، مشخصه هیپ نقض نمیشود.
این کار تعویض را تا زمانی که عنصر به یک برگ تبدیل شود و یا کمتر از همه فرزندانش باشد، ادامه میدهیم. برای مثال، در هیپ زیر میخواهیم ریشه را از درخت حذف کنیم:
ابتدا برگ آخر را در ریشه قرار میدهیم:
سپس از آنجا که بزرگتر از هر دو فرزند خود است، آن را با کمترین فرزندش یعنی 2 عوض میکنیم:
4 کمتر از 6 است و بنابراین در این مرحله متوقف میشویم.
پیادهسازی مرتبسازی هیپ در جاوا
بر اساس همه آن چه تا به اینجا گفتیم، حذف کردن ریشه (popping) کاری مانند زیر است:
چنان که پیشتر گفتیم، مرتبسازی صرفاً به ایجاد هیپ و حذف کردن مکرر ریشه مربوط است:
کارکرد این الگوریتم را با تست زیر میتوانیم بررسی کنیم:
توجه کنید که امکان ارائه یک پیادهسازی که مرتبسازی درجا انجام دهد نیز وجود دارد. این کار بدان معنی است که نتیجه را در همان آرایهای که عناصر را در خود دارد ارائه کنیم. به علاوه در این روش به هیچ تخصیص حافظه آنی نیاز نداریم. با این حال، درک آن پیادهسازی کمی دشوارتر خواهد بود.
پیچیدگی زمانی
مرتبسازی هیپ دو مرحله کلیدی دارد که یک درج کردن عنصر و دیگری حذف گره ریشه است. هر دو مرحله دارای پیچیدگی زمانی (O(log n هستند. از آنجا که هر دو مرحله n بار تکرار میشوند، پیچیدگی مرتبسازی کلی برابر با (O(n log n خواهد بود.
دقت کنید که ما به هزینه تخصیص مجدد آرایه اشاره نکردیم، اما از آنجا که پیچیدگی آن (O(n است تأثیری روی پیچیدگی کلی نخواهد داشت. ضمناً چنان که پیشتر گفتیم، امکان پیادهسازی مرتبسازی به صورت درجا نیز وجود دارد. بدین ترتیب نیازی به تخصیص مجدد آرایه هم وجود نخواهد داشت. همچنین باید اشاره کنیم که در هیپ 50% از عناصر برگ هستند و 75% از آنها عناصری هستند که در پایینترین سطح قرار دارند. از این رو اغلب عملیات درج، به چیزی بیش از دو گام نیاز نخواهند داشت.
توجه داشته باشید که در دادههای دنیای واقعی، الگوریتم Quicksort کارآمدتر از مرتبسازی هیپ است. نکته اینجا است که الگوریتم مرتبسازی هیپ همواره سناریوی بدترین حالت یعنی پیچیدگی زمانی (O(n log n را دارد.
سخن پایانی
در این راهنما، یک پیادهسازی از هیپ دودویی و مرتبسازی هیپ را مورد برسی قرار دادیم. با این که پیچیدگی زمانی آن در اغلب موارد (O(n log n است، اما بهترین الگوریتم در دنیای واقعی محسوب نمیشود.
دسترسی به موقعیت جغرافیایی در React Native و Expo — راهنمای کاربردی
موقعیتهای جغرافیایی به صورت یک API ارائه شدهاند که متدهای مختلفی برای استفاده در یک وب اپلیکیشن دارند. به طور مشابه، React Native از این API بهره میگیرد و در آن به صورت polyfill ارائه شده است. موقعیت جغرافیایی قابلیتی ضروری برای اپلیکیشنهای موبایل محسوب میشود. برخی از اپلیکیشنهای مشهور موبایل که برای اغلب کارکردهای خود از آن استفاده میکنند، شامل گوگل مپس، اوبر و… هستند. در این مقاله، با دو روش مختلف برای یکپارچهسازی API مختصات جغرافیایی در یک اپلیکیشن React Native آشنا میشویم. این کار با استفاده از Expo و همچنین از طریق react-native-cli اجرا خواهد شد. همچنین با روش درخواست مجوزهای اپلیکیشن آشنا میشویم.
در همین راستا قصد داریم یک قابلیت آنی را پیادهسازی کنیم که در این نوع اپلیکیشنها به صورت متداول استفاده میشود و آن درخواست «مجوزهای کاربر» (USER Permissions) است. درخواست مجوز در react-native-cli ممکن است کمی پیچیده باشد، اما پس از خواندن این مقاله مطمئناً پیادهسازی آن برای شما آسانتر خواهد بود.
آغاز کار با Expo
ما در این مقاله از expo-cli استفاده میکنیم. با اجرای دستورهای زیر میتوانید یک پروژه Expo را پیکربندی کرده و راهاندازی کنید.
npm install -g expo-cli expo-cli init find-me # select blank template & traverse into a newly created directory npm run ios # for Window users، run npm run android
در این مرحله با صفحه خوشامدگویی مواجه میشوید. ما کار خود را از همین جا آغاز میکنیم و ابتدا فایل App.js را ویرایش میکنیم.
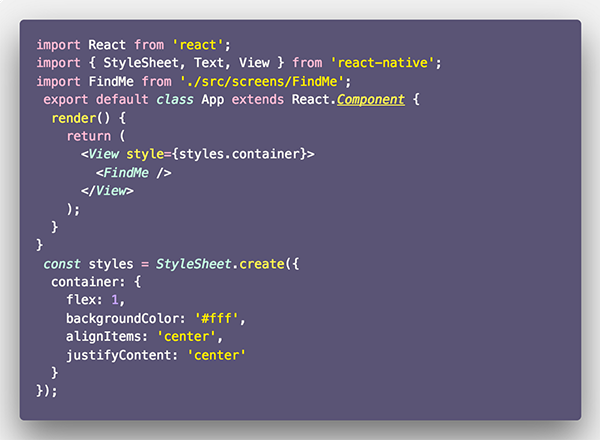
یک فایل جدید برای کامپوننت FindMe در مسیر src -> screens -> FindMe -> index.js ایجاد میکنیم. درون این فایل صرفاً یک متن را نمایش خواهیم داد.
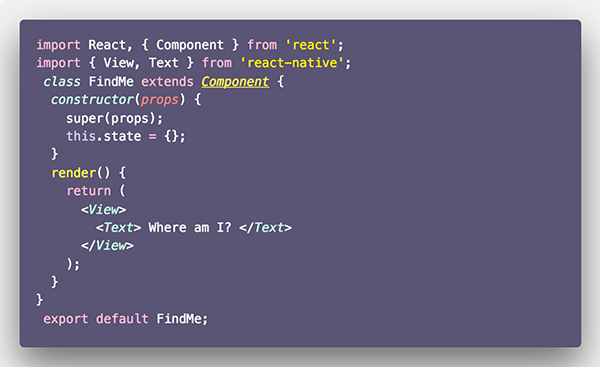
بدین ترتیب اپلیکیشن ما اکنون اینگونه به نظر میرسد:

دسترسی به API موقعیت جغرافیایی
API مربوط به Geolocation به صورت یک شیء سراسری به نام navigator در React Native حضور دارد و این وضعیت مشابه وب است. این API از طریق navigator.geolocation در کد منبع ما قابل دسترسی است و نیازی به ایمپورت کردن آن وجود ندارد.
ما در این مقاله با توجه به مقاصد آموزشی خود، از متد getCurrentPosition از API مربوط به Geolocation استفاده میکنیم. این متد به اپلیکیشن موبایل امکان میدهد که مکان کاربر را درخواست کند و سه پارامتر به صورت callback موفقیت، callback شکست و یک شیء پیکربندی نیز میپذیرد.
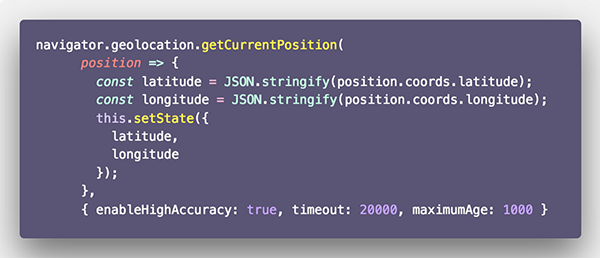
نخستین callback یک آرگومان position دارد که شیئی با مشخصههای زیر است:
اکنون این قابلیت را در کامپوننت FindME پیادهسازی میکنیم:
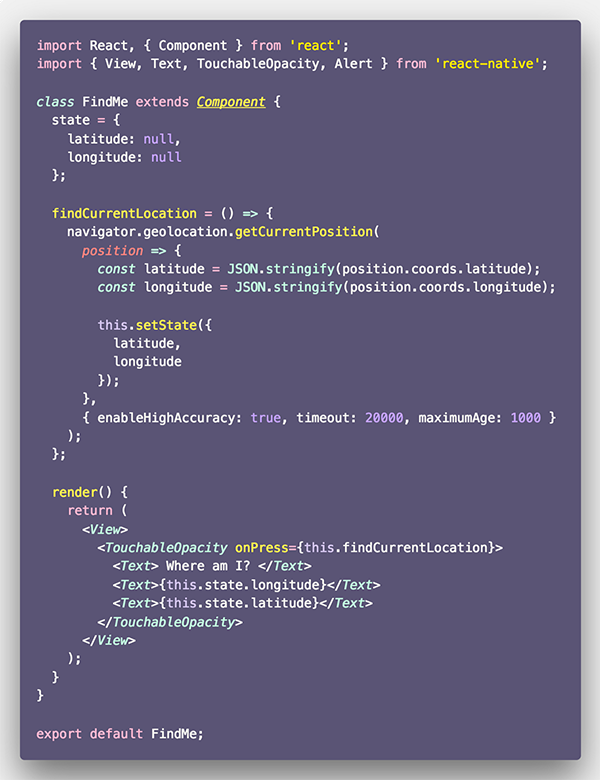
کار خود را با ایمپورت کردن TouchableOpcaity آغاز میکنیم. این یک پوشش است که به طور صحیحی به لمسهای کاربر پاسخ میدهد. در یک اپلیکیشن موبایل میتوان از این موارد بهرهبرداری کرد. آن را میتوان مانند یک دکمه در وب اپلیکیشن تصور کرد. این پوشش اخیراً ایمپورت شده یک prop به نام onPress میپذیرد که از آن برای فراخوانی تابعی که مانند مقدار تعریف شده استفاده خواهد شد. در این مثال نام آن findCurrentLocation است.
تابع findCurrentLocation منطق مربوط به واکشی مکان کاربر را نگهداری میکند. همچنین از حالت محلی برای نمایش مختصات دریافتی از شیء position استفاده میکنیم. متن Where Am I اکنون قابل کلیک کردن است.

تا به اینجا بخش اپلیکیشن به پایان رسیده است. اینک نوبت آن رسیده است که با شیوه افزودن مجوزها به اپلیکیشن آشنا شویم.
استفاده از Expo Permissions
در زمان ارسال درخواست برای دریافت اطلاعات یک کاربر چه مکان باشد و چه هر اطلاعات حساس دیگر روی دستگاه، شما به عنوان توسعهدهنده موظف هستید ابتدا درخواست مجوز بکنید. این فرایند چه در زمان توسعه اپلیکیشن و چه در زمان استفاده از اپلیکیشن یک بار رخ میدهد. اغلب دسترسیها زمانی درخواست میشوند که کاربر اپلیکیشن را برای اولین بار اجرا میکند.
Expo همه API-های دسترسی که برای این اپلیکیشن دمو یا هر اپلیکیشن دیگری که با Expo ساخته میشود را یکپارچهسازی کرده است. این API متدهای مختلفی برای انواع دستگاهها که ممکن است نیاز به درخواست مجوز داشته باشند را شامل میشود. این مجوز دسترسیها میتوانند شامل مکان دوربین، ضبط صدا، مخاطبین، گالری تصاویر، تقویم، یادآوریها (فقط iOS) و اعلانها باشد. ما قصد داریم از Location استفاده کنیم.
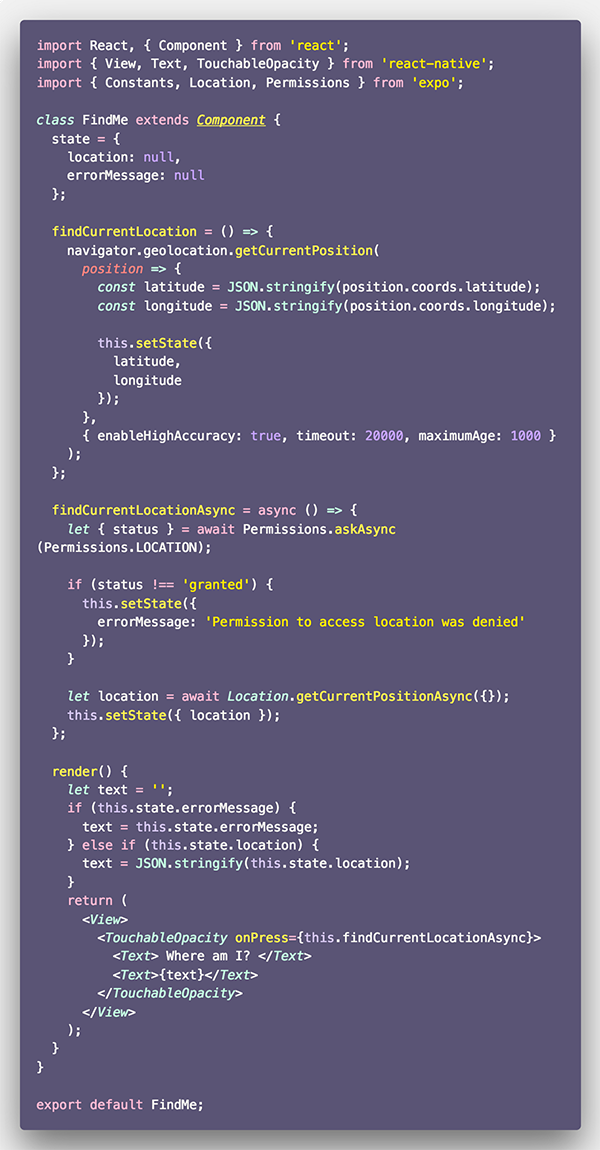
در این مرحله ما «حالت» (State) خود را کمی تغییر میدهیم. بدین ترتیب دیگر کل شیء geolocation و errorMessage را در صوت بروز خطا نگهداری نخواهد کرد. findCurrentLocation بدون تغییر باقی میماند. در واقع ما از آن استفاده نخواهیم کرد. Expo متدی دارد که این کار را برای ما انجام میدهد. این متد getCurrentPositionAsync نام دارد. این متد صرفاً مکان کاربر و مشخصههای دیگر ارائه شد از سوی getCurrentPosition را در صورتی که مجوز اعطا شده باشد، واکشی میکند. در متد رندر prop به نام onPress یک متد دیگر را فراخوانی میکند که findCurrentLocationAsync نام دارد و منطق مربوط به درخواست مجوز و واکشی دادههای مکان را پس از این که دسترسی کاربر اعطا شد اجرا میکند. اگر مجوز ارائه نشده باشد، پیام خطایی صادر میشود و در غیر این صورت مکان بهروزرسانی خواهد شد.
آخرین گام مربوط به کاربران اندروید است. فایل app.json را باز کنید و به بخش permissions بروید.

اگر دکمه Allow فشرده شود، نتیجه زیر عاید میشود:

توجه کنید که در حالت توسعه و اجرا کردن اپلیکیشن در شبیهساز، دسترسیها تنها یک بار تقاضا میشوند. برای اجرای مجدد آن، باید اپلیکیشن را از شبیهساز حذف کرده و دستور شروع اپلیکیشن Expo را مجدداً بدهید.
کد کامل این اپلیکیشن را از این آدرس (+) دانلود کنید.
استفاده از react-native-cli
استفاده از react-native-cli به این معنی است که باید مجوزها را خودتان تنظیم کنید، با این حال، منطق دریافت مکان کاربر همان خواهد بود.
npm install -g react-native-cli react-native init findCoordsApp
هیچ قالبی در react-native-cli وجود ندارد از این رو زمانی که دایرکتوری ایجاد شود، آن را بررسی کرده و دستور npm start را اجرا کنید تا ببینید آیا همه چیز به درستی نصب شده است یا نه. زمانی که این پروژه را در یک IDE یا ویرایشگر کد باز کنید، نخستین چیزی که متوجه خواهید شد این است که تغییرهای زیادی در ساختار فایلها و پوشهها وجود دارد. Expo در مقایسه با این روش ساختار پروژه کوچکتری دارد. پوشههای مختلف build مانند /android و /ios برای هر پلتفرم وجود دارند. همچنین میتوانید از flow استفاده کنید که مشابه TypeScript است و از سوی فیسبوک به صورت متنباز عرضه شده است.
ما صرفاً فایل App.js را با درج کد زیر اصلاح میکنیم:
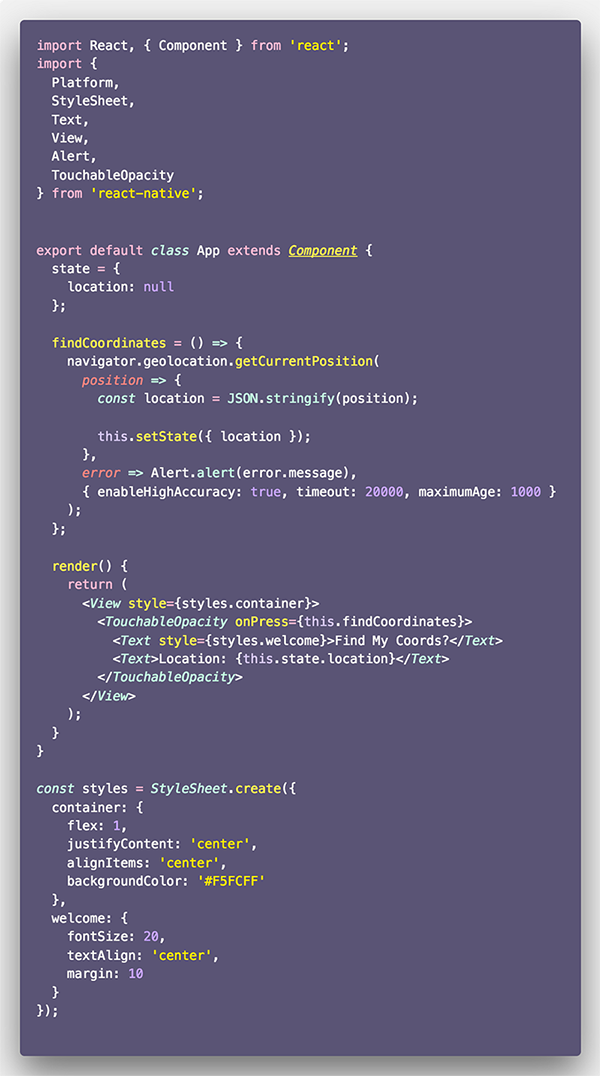
توجه داشته باشید که findCoordinates به روشی مانند اپلیکیشن Expo عمل میکند و ضمناً کد موجود در تابع ()render دقیقاً همان است. گام بعدی ما تنظیم مجوزها است.
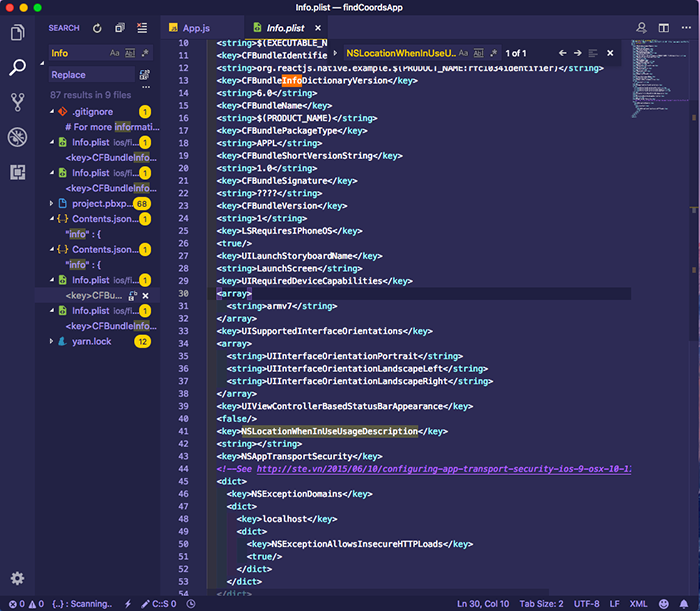
موقعیت جغرافیایی در iOS به صورت پیشفرض در زمان ایجاد پروژه با استفاده از react-native-cli فعال شده است. برای استفاده از آن کافی است یک کلید را در info.plist قرار دهید که درون دایرکتوری ios/findCoordsApp قرار دارد.
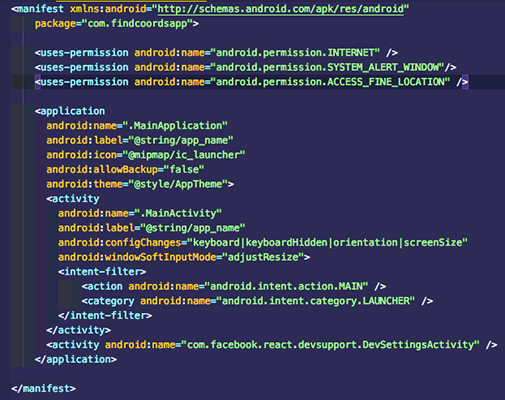
برای اندروید باید خط زیر را در فایل android/app/src/AndroidManifest.xml اضافه کنیم:
اکنون اگر اپلیکیشن را اجرا کنید با صفحه زیر مواجه میشوید:

روی متن کلیک کنید تا از شما سؤال شود آیا میخواهید به اپلیکیشن دسترسی به مکان بدهید یا نه. ما به منظور نمایش موضوع، از یک شبیهساز اندروید استفاده میکنیم، چون قبلاً در بخش Expo دیدیم که روی شبیهساز iOS چگونه عمل میکند.

اگر دکمه Allow را بزنید، نتیجه زیر حاصل میشود:

کد کامل این اپلیکیشن را در این ریپازیتوری گیتهاب (+) ملاحظه کنید. اگر قصد دارید در مورد API موقعیت جغرافیایی در اپلیکیشنهای ریاکت نیتیو بیشتر بدانید به مستندات رسمی (+) مراجعه کنید.
منبع: فردارس
سفارشی کردن پایگاه داده MySQL در داکر — راهنمای کاربردی
سفارتوسعهدهندگان زیادی از داکر برای راهاندازی یک پایگاه داده محلی استفاده میکنند. بدین ترتیب تست کردن کد و نوشتن دادهها بدون نصب و پیکربندی ابزارهای زیاد ممکن خواهد بود. در این مقاله، با روش سفارشی کردن پایگاه داده داکر آشنا میشویم. با این که مراحل کار برای پایگاه داده MySQL توضیح داده میشود، اما PostgreSQL نیز روال مشابهی دارد. با ما همراه باشید و یک MySQL سفارشی بسازید که شامل جداول و دادههای مطلوب شما باشد.
ایجاد اسکریپتهای SQL
ما اسکریپتهای SQL خود را ایجاد خواهیم کرد که شامل آن دسته از گزارههای SQL هستند که میخواهیم روی پایگاه داده خود اجرا کنیم. یک دایرکتوری ایجاد میکنیم که در آن کار خواهیم کرد. ضمناً یک دایرکتوری فرعی ایجاد میکنیم که اسکریپتهای sql. را در آن ذخیره میکنیم.
mkdir -p ~/my-mysql/sql-scripts $ cd ~/my-mysql/sql-scripts
ما میخواهیم پایگاه داده خود را با یک جدول به نام «کارمندان» (employees) سفارشیسازی کنیم. جدول باید شامل یک ردیف با یک کارمند و ستونهای نام، نام خانوادگی، دپارتمان و ایمیل (first name ،last name ،department و email) باشد.
یک فایل به نام CreateTable.sql بسازید. این فایل شامل گزاره SQL برای ایجاد جدولی به نام employees خواهد بود. ما میخواهیم چهار ستون به جدول اضافه کنیم.
یک فایل به نام InsertData.sql بسازید. این فایل شامل گزاره ما برای درج دادهها در جدول employees است.
دستور tree را اجرا کنید تا تأیید شود که دو اسکریپت وجود دارد و در دایرکتوری درستی ذخیره شده است.
ایجاد یک ایمیج داکر برای پایگاه داده سفارشی شده MySQL
اکنون که اسکریپتها آماده هستند، میتوانیم یک Dockerfile بنویسیم تا ایمیج داکر خود را بر مبنای ایمیج رسمی MySQL (+) بسازیم.
cd ~/my-mysql/ $ vi Dockerfile
محتوای داکرفایل به صورت زیر است:
# Derived from official mysql image (our base image) FROM mysql # Add a database ENV MYSQL_DATABASE company # Add the content of the sql-scripts/ directory to your image # All scripts in docker-entrypoint-initdb.d/ are automatically # executed during container startup COPY./sql-scripts/ /docker-entrypoint-initdb.d/
ایمیج داکر خود را بسازید:
cd ~/my-mysql/ $ docker build -t my-mysql. Sending build context to Docker daemon 4.608kB Step 1/2: FROM mysql latest: Pulling from library/mysql Digest: sha256:691c55aabb3c4e3b89b953dd2f022f7ea845e5443954767d321d5f5fa394e28c Status: Downloaded newer image for mysql:latest ---> 5195076672a7 Step 2/2: ADD sql-scripts/ /docker-entrypoint-initdb.d/ ---> 25065c3d93c0 Successfully built 25065c3d93c0 Successfully tagged my-mysql:latest
و کانتینر MySQL خود را از ایمیج بسازید:
docker run -d -p 3306:3306 --name my-mysql \ -e MYSQL_ROOT_PASSWORD=supersecret my-mysql
اینک میتوانیم روال کار را تأیید کنیم. درون کانتینر از exec استفاده خواهیم کرد:
چنان که میبینید اسکریپت کار میکند. بدین ترتیب ما ایمیج داکر پایگاه داده MySQL سفارشی خودمان را داریم. این راهحلی عالی برای توسعه محلی بین چند توسعهدهنده است. با اشترک ایمیج داکر هر توسعهدهنده میتواند با شروع کانتینر از ایمیج پایگاه داده مربوطه استفاده کند.
با این وجود، لازم به اشاره است که این راهحل همواره هم بهترین راهحل نیست:
- اگر دادههای زیادی وارد کنید، اندازه ایمیج به مقدار زیادی افزایش خواهد یافت.
- زمانی که دادهها بهروزرسانی میشوند، باید یک ایمیج جدید بسازیم.
به همین دلیل است که روش دیگری برای سفارشیسازی MySQL داکر نیز وجود دارد.
استفاده از Bind Mounts برای سفارشی کردن پایگاه داده MySQL در داکر
در بخش آخر، اسکریپتها را درون کانتینر رسمی داکر MySQL سوار میکنیم.
docker run -d -p 3306:3306 --name my-mysql \ -v ~/my-mysql/sql-scripts:/docker-entrypoint-initdb.d/ \ -e MYSQL_ROOT_PASSWORD=supersecret \ -e MYSQL_DATABASE=company \ Mysql
بدین ترتیب بار دیگر اسکریپت تأیید میشود. از همان مراحل که قبلاً اجرا کردیم استفاده میکنیم: exec درون کانتینر استفاده میشود تا وجود جدول و دادهها بررسی شود.
این روش انعطافپذیر است، اما توزیع آن در میان توسعهدهندهها کمی دشوارتر خواهد بود. همه توسعهدهندهها باید اسکریپتها را در دایرکتوری خاصی در سیستم محلی خود ذخیره کنند و باید در زمان اجرای دستور docker run به یک دایرکتوری خاص اشاره کنند..
منبع: فرادرس
منبعشی کردن پایگاه داده MySQL در داکر — راهنمای کاربردی
معرفی جاوا اسکریپت ناهمگام — به زبان ساده
در این مقاله به اختصار به بررسی مشکلات مرتبط با جاوا اسکریپت ناهمگام میپردازیم. همچنین برخی از تکنیکهای مختلف برنامهنویسی ناهمگام که میتوان مورد استفاده قرار دارد را بررسی میکنیم و نشان میدهیم که این تکنیکها چگونه میتوانند به حل برخی از مسائل کمک کنند. برای مطالعه بخش قبلی به لینک زیر رجوع کنید.
پیشنیازها
- سواد مقدماتی رایانه
- درکی نسبی از مبانی جاوا اسکریپت
هدف از این مقاله آشنا ساختن مخاطب با جاوا اسکریپت ناهمگام، تفاوت آن با جاوا اسکریپت همگام و کاربردهای آن است.
جاوا اسکریپت همگام
برای این که بتوانیم معنی جاوا اسکریپت «ناهمگام» (Asynchronous) را بدانیم باید ابتدا مطمئن شویم که معنی جاوا اسکریپت «همگام» (Synchronous) را میدانیم. در این بخش برخی از اطلاعاتی که در مقاله قبلی این سری ارائه شده است را جمعبندی میکنیم.
بخش عمدهای از کارکردهایی که در بخش قبلی این سری آموزشی مشاهده کردیم در واقع تکنیکهای برنامهنویسی همگام بودند. در این روش شما کد اجرا میشود و نتیجه به محض این که مرورگر بتواند کد را اجرا کند بازگشت مییابد. به مثال ساده زیر توجه کنید:
در این مثال یک دکمه وجود دارد که پس از یک میلیون بار محاسبه تاریخ، عبارتی را روی صفحه نمایش میدهد. آن را عملاً در این آدرس (+) مشاهده کنید.
در بلوک کد فوق کارهای زیر یکی پس از دیگری اجرا میشوند:
- یک ارجاع به عنصر <button> به دست میآید که در DOM قرار دارد.
- یک شنونده رویداد اضافه میشود که وقتی دکمه کلیک شد، کارهای زیر را انجام میدهد:
- یک پیام هشدار ()alert ظاهر میشود.
- زمانی که هشدار بسته شود، یک عنصر <p> ایجاد میشود.
- سپس نوعی محتوای متنی به آن اضافه میشود.
- در نهایت پاراگراف به بدنه سند اضافه خواهد شد.
زمانی که هر کدام از این عملیات در حال پردازش هستند، هیچ کار دیگری اجرا نخواهد شد و به این ترتیب رندر کردن صفحه متوقف میشود. دلیل این مسئله را در بخش قبلی این سری مقالات گفتیم و این است که جاوا اسکریپت یک زبان تک نخی است. در هر زمان تنها یک کار میتواند اجرا شود که روی نخ main اجرا میشود و هر چیز دیگری تا زمان تکمیل شدن آن عملیات متوقف خواهد بود.
بنابراین در مثال فوق، پس از این که روی دکمه کلیک کردید، پاراگراف ظاهر نمیشود تا این که دکمه OK را در کادر هشدار کلیک کنید. میتوانید آن را خودتان بررسی کنید:
نکته: به خاطر داشته باشید که ()alert گرچه برای نمایش عملیات انسداد همگام مفید است، اما استفاده از آن در اپلیکیشنهای واقعی فاجعه محسوب میشود.
جاوا اسکریپت ناهمگام
به دلایلی که در بخش قبلی نشان دادیم، بسیاری از قابلیتهای API وب به خصوص آنهایی که به نوعی منابع دسترسی مییابند یا آن را از یک محل خارجی واکشی میکنند، هم اینک از کدنویسی ناهمگام برای اجرا استفاده میکنند. برای نمونه واکشی فایل از شبکه یا دسترس به پایگاه داده و بازگشت داده از آن، دسترسی به استریم ویدئو از یک دوربین وب یا پخش تصاویر نمایشگر روی یک هدست VR شامل این عملیات میشود.
چرا عادت به کار با کد ناهمگام دشوار است؟ برای پاسخ به این سؤال یک مثال ساده را بررسی میکنیم. وقتی یک تصویر را از سرور واکشی میکنید، نمیتوانید بیدرنگ نتیجهای را بازگشت دهید. این بدان معنی است که شِبه کد زیر عملی نخواهد بود:
دلیل این مسئله آن است که نمیدانید چه قدر طول میکشد تا تصویر دانلود شود و از این رو زمانی که خط دوم اجرا شود (به احتمال زیاد در تمام موارد) خطایی ایجاد میشود، چون response هنوز موجود نیست. به جای آن باید از کد خود بخواهید صبر کند تا response بازگشت یابد و سپس تلاش کند تا هر کاری دیگری با آن انجام دهد.
دو نوع عمده از سبک کد ناهمگام وجود دارد که در جاوا اسکریپت با آن مواجه میشویم. یکی Callback-های سبک قدیمی است و دیگری کد به سبک Promise. در ادامه این مقاله هر کدام از آنها را به نوبت بررسی میکنیم.
Callback-های ناهمگام
Callback-های ناهمگام تابعهایی هستند که در زمان فراخوانی یک تابع به صورت پارامتر استفاده میشوند و شروع به اجرا در پس زمینه میکنند. زمانی که کد پس زمینه اجرای خود را تمام کند، تابع Callback را فراخوانی میکند تا بداند که کار انجام یافته است و یا اطلاع دهد که اتفاق خاصی رخ داده است. استفاده از Callback روشی نسبتاً قدیمی محسوب میشود، گرچه همچنان در برخی API-های قدیمیتر اما رایج استفاده میشود.
نمونهای از یک Callback ناهمگام، پارامتر دوم ()addEventListener است که در بخش قبلی دیدیم:
پارامتر نخست نوع رویدادی است که منتظر وقوع آن هستیم و پارامتر دوم یک تابع Callback است که در زمان اجرای رویداد احضار میشود.
زمانی که یک تابع Callback را به صورت یک پارامتر به تابع دیگری ارسال میکنیم، صرفاً تعریف تابع را به صورت پارامتر میفرستیم و تابع Callback بیدرنگ اجرا نخواهد شد. نام آن Callback یعنی فراخوانی بازگشتی است و برحسب نام خود به صورت ناهمگام جایی در بدنه تابع قرار گرفته و در زمان مقتضی اجرا خواهد شد. تابعی که Callback را در خود احاطه کرده، مسئول اجرای تابع Callback در زمان مقتضی است.
شما میتوانید تابعهای خاصی را بنویسید که شامل Callback باشند. در مثال زیر یک تابع Callback را میبینیم که منبعی را از طریق API به نام XMLHttpRequest بارگذاری میکند:
ما در این کد یک تابع به نام ()displayImage ایجاد کردهایم که یک blob ارسالی را به صورت یک URL شیء را نمایش میدهد و سپس یک تصویر ایجاد میکند تا URL را در آن نمایش دهد و آن را به <body> سند الصاق میکند.
با این حال، در ادامه یک تابع ()loadAsset ایجاد میکنیم که یک Callback به عنوان پارامتر میگیرد و همراه با آن یک URL برای واکشی و نوع محتوا را نیز دریافت میکند. این تابع از XMLHttpRequest که عموماً به اختصار XHR نامیده میشود، برای واکشی منبع از URL مفروض استفاده میکند و سپس پاسخ را در Callback ارسال میکند تا هر کاری که لازم است روی آن اجرا کند. در این حالت، callback روی درخواست XHR منتظر میماند تا دانلود کردن منبع به پایان برسد. این کار با استفاده از دستگیره رویداد onload صورت میپذیرد و سپس تصویر را به Callback ارسال میکند.
Callback-ها متنوع هستند و نه تنها امکان کنترل ترتیب اجرای تابعها و این که چه دادههایی به آنها ارسال میشوند را دارند، بلکه امکان فرستادن دادهها به تابعهای مختلف بر اساس شرایط خاص را نیز فراهم میسازند. بنابراین میتوانید کارهای مختلفی مانند ()processJSON() ،displayText و غیره برای اجرا روی یک پاسخ دانلود شده تعریف کرد.
توجه داشته باشید که همه Callback-ها ناهمگام نیستند و برخی از آنها به صورت همگام اجرا میشوند. به عنوان مثال، زمانی که از ()Array.prototype.forEach برای تعریف حلقه روی آیتمهای یک آرایه استفاده میکنید، در واقع از یک Callback همگام استفاده کردهاید.
در این مثال، روی یک آرایه متشکل از نام خدایان یونان باستان حلقهای تعریف کردیم و شماره اندیس و مقدار آنها را در کنسول نمایش میدهیم. پارامتر مورد انتظار ()forEach یک تابع Callback است که خودش دو پارامتر میگیرد که یکی ارجاعی به نام آرایه و دیگری مقدار اندیسهاست. با این حال این تابع منتظر چیزی نمیماند و بیدرنگ اجرا میشوند.
Promise-ها
Promise-ها سبک جدیدی از کد ناهمگام هستند که در API-های مدرن وب مشاهده میشوند. مثال خوبی از آن در API به نام ()fetch دیده میشود که اساساً نسخه مدرنتر و کارآمدتری از XMLHttpRequest است. در ادامه مثال کوچکی را ملاحظه میکنید که دادهها را از سرور واکشی میکند:
در کد فوق ()fetch یک پارامتر منفرد میگیرد که URL منبعی است که میخواهیم از شبکه واکشی کنیم و یک Promise بازگشت میدهد. Promise شیئی است که تکمیل یا شکست عملیات ناهمگام را نمایش میدهد. این پارامتر یک حالت واسط را نمایش میدهد. در واقع این روشی است که مرورگر استفاده میکند تا اعلام کند: «من قول میدهم به زودی با پاسخ بازخواهم گشت» و از این رو نام آن Promise یعنی «قول» است.
عادت به استفاده از این مفهوم نیاز به تمرین کردن دارد. در عمل کمی شبیه به گربه شرودینگر است. هیچ کدام از وضعیتها هنوز اتفاق نیفتادهاند و از این رو عملیات واکشی در حال حاضر منتظر نتیجه عملیات مرورگر است تا عملیات خود را در زمانی در آینده به پایان ببرد. در ادامه سه بلوک کد دیگر نیز داریم که در انتهای ()fetch قرار دارند:
- بلوکهای ()then: هر دو این بلوکها شامل یک تابع Callback هستند که در صورت موفق بودن عملیات قبلی اجرا میشوند و هر Callback یک ورودی در نتیجه موفق بودن عملیات قبلی میگیرد، به طوری که میتواند به پیش برود و کار دیگری را اجرا کند. هر بلوک ()then. یک Promise دیگر بازگشت میدهد، یعنی میتوان چند بلوک ()then را به هم زنجیر کرد به طوری که چند عملیات ناهمگام به ترتیب و یکی پس از دیگری اجرا شوند.
- بلوک ()catch: در انتهای کد در صورتی اجرا میشود که بلوکهای ()then ناموفق باشند. این وضعیت شبیه به بلوکهای try…catch همگام است که در آن یک شیء خطا درون ()catch قرار میگیرد و میتواند برای گزارش نوع خطایی که رخ داده است مورد استفاده قرار گیرد. توجه کنید که گرچه آن try…catch همگام در مورد Promise-ها جواب نمیدهد، اما با ساختار async/await که در ادامه معرفی خواهیم کرد کار میکند.
در بخشهای بعدی این سری مقالات آموزشی با Promise-ها بیشتر آشنا خواهید شد و اگر اکنون نکته مبهمی برایتان وجود دارد لازم نیست نگران باشید. کافی است به ادامه مطالعه مقالههای این سری بپردازید.
صف رویداد
عملیات ناهمگام مانند Promise در یک «صف رویداد» (event queue) قرار میگیرد که پس از پایان پردازش نخ اصلی اجرا میشود، به طوری که کد جاوا اسکریپت بعدی را مسدود نمیکند. عملیات صفبندی شده به محض این که امکانپذیر باشد، اجرا میشوند و نتایج آنها در محیط جاوا اسکریپت بازگشت مییابد.
مقایسه Promise با Callback
Promise-ها مشابهتهایی با Callback های سبک قدیم دارند. آنها اساساً یک شیء را بازگشت میدهند که به جای الزام به ارسال Callback به یک تابع، به تابعهای Callback الصاق مییابند.
با این حال، Promise-ها به طور اختصاص برای مدیریت عملیات ناهمگام ساخته شدهاند و مزیتهای زیادی نسبت به Callback-های قدیمی دارند که در فهرست زیر به برخی از آنها اشاره کردهایم:
- شما میتوانید چند عملیات ناهمگام را با استفاده از چند عملیات ()then. به هم زنجیر کنید و نتیجه یکی را به عنوان ورودی به دیگری ارسال کنید. اجرای این کار با Callback-ها بسیار دشوارتر است و در اغلب موارد به وضعیتی به نام «هرم مرگ» یا «جهنم Callback» منتهی میشود.
- Callback-های Promise همواره با ترتیب مشخصی که در صف رویداد قرار گرفتهاند فراخوانی میشوند.
- مدیریت خطا بسیار بهتر است، چون همه خطاها از سوی یک بلوک منفرد ()catch. در انتهای بلوک کد مدیریت میشوند و دیگر لازم نیست به صورت منفرد در هر سطح از هرم خطایابی شود.
ماهیت کد ناهمگام
در ادامه مثال دیگری را بررسی میکنیم که ماهیت کد ناهمگام را بیشتر روشن میسازد و نشان میدهد که وقتی از ترتیب اجرای کد به درستی آگاه نباشیم و تلاش کنیم با کد ناهمگام همانند کد همگام برخورد کنیم، چه نوع مشکلاتی میتوانند بروز یابند. مثال زیر تا حدودی مشابه آن چیزی است که قبلاً دیدیم. یک تفاوت آن است که ما در این کد تعدادی گزاره ()console.log نیز گنجاندهایم که ترتیب کدی که شما ممکن است فکر کنید اجرا میشود را نمایش میدهد.
مرورگر کار خود را با اجرای کد آغاز میکند و نخستین گزاره ()console.log یعنی پیام «Starting» را میبینید و آن را اجرا میکند، سپس متغیر image را ایجاد میکند.
در ادامه به خط بعدی میرود و شروع به اجرای بلوک ()fetch میکند، اما از آنجا که ()fetch به صورت ناهمگام بدون مسدودسازی اجرا میشود، اجرای کد پس از کد مبتنی بر Promise ادامه مییابد و بدین طریق به گزاره ()console.log نهایی میرسد و خروجی یعنی پیام «!All done» را در کنسول ارائه میکند.
تنها زمانی که بلوک ()fetch به صورت کامل پایان یابد و نتیجهاش را از طریق بلوکهای ()then. ارائه کند، در نهایت پیام ()console.log دوم یعنی «(;It worked» ظاهر میشود. بنابراین پیامها در ترتیبی متفاوت از آن چه احتمالاً انتظار داشتید ظاهر میشوند:
- Starting
- All done!
- It worked:)
اگر این وضعیت موجب سردرگمی شما شده است، مثال کوچکتر زیر را در نظر بگیرید:
رفتار این بلوک کد کاملاً مشابه است، پیامهای اول و سوم ()console.log بیدرنگ نمایش پیدا میکنند، اما گزاره دوم مسدود میشود تا این که دکمه ماوس را کلیک کنید. مثال قبلی نیز به روش مشابهی عمل میکند به جز این که به جای کلیک کردن ماوس، کد پیام دوم مسدود میشود تا زنجیره Promise منبعی را واکشی کرده و آن را روی صفحه نمایش دهد.
در یک مثال از کدی که پیچیدهتر از این دو است، این تنظیمات میتواند موجب بروز مشکل شود، چون نمیتوان هیچ بلوک کد ناهمگامی را که نتیجهای بازگشت میدهد و نتیجه آن در ادامه مورد نیاز خواهد بود در بلوک کد ناهمگام گنجاند. نمیتوان تضمین کرد که تابع ناهمگام پیش از این که مرورگر بلوک همگام را پردازش بکند بازگشت خواهد یافت.
برای این که این مشکل را در عمل مشاهده کنیم ابتدا یک کپی از کد زیر روی سیستم خود ایجاد کنید:
سپس فراخوانی ()console.log را به صورت زیر تغییر دهید:
اینک باید به جای پیام سوم، یک خطا در کنسول مشاهده کنید:
TypeError: image is undefined; can't access its "src" property
دلیل این امر آن است که مرورگر تلاش میکند، گزاره ()console.log سوم را اجرا کند و بلوک ()fetch هنوز اجرای خود را تمام نکرده است و از این رو متغیر image هنوز مقداری ندارد.

یادگیری عملی: همه کدها را ناهمگام بنویسید
برای حل مشکلی که در مثال ()fetch دیدیم و برای این که گزاره ()console.log سوم در ترتیب مطلوب نمایش پیدا کند، باید کاری کنیم که گزاره ()console.log سوم نیز به صورت ناهمگام اجرا شود. این کار از طریق انتقال آن به درون بلوک ()then. که به انتهای دومی زنجیر شده است، امکانپذیر خواهد بود. همچنین میتواند به سادگی آن را به درون بلوک ()then سوم برد. تلاش کنید این مشکل را به این ترتیب اصلاح کنید.
نکته: اگر با مشکل مواجه شدید میتوانید از کد زیر کمک بگیرید:
سخن پایانی
جاوا اسکریپت در ابتداییترین شکل خود یک زبان برنامهنویسی همگام، مسدودکننده و تک نخی است بدین معنی که در این زبان در هر لحظه تنها یک عملیات اجرا میشود. اما مرورگرهای وب تابعها و API-هایی تعریف میکنند که امکان ثبت تابعهایی که باید به صورت ناهمگام اجرا شوند را میدهند. بدین ترتیب میتواند این تابعها را به صورت ناهمگام در زمانی که رویداد خاصی اتفاق افتاد مانند گذشت زمان معین، تعامل کاربر با ماوس یا رسیدن دادهای از شبکه، اجرا کرد. این به آن معنی است که میتوان اجازه داد کد چندین کار را همزمان اجرا کند و در عین حال نخ اصلی نیز مسدود یا متوقف نشود.
این که بخواهیم کد خود را به صورت ناهمگام و یا همگام اجرا کنیم به کاری که قرار است انجام دهیم وابسته است. مواردی وجود دارند که میخواهیم چیزی بیدرنگ بارگذاری و اجرا شود. برای نمونه زمانی که نوعی استایل تعریف شده از سوی کاربر را روی یک صفحه وب اعمال میکنیم میخواهیم که این کار در سریعترین حالت ممکن اجرا شود.
اما اگر عملیاتی اجرا میکنیم که زمانبر خواهد بود مثلاً به پایگاه داده کوئری میزنیم و از نتایج آن برای ایجاد قالب استفاده میکنیم بهتر است آن را از نخ اصلی خارج کنیم و این کار را به صوت ناهمگام به پایان ببریم. شما در طی زمان خواهید آموخت که چه زمانی باید از تکنیکهای ناهمگام و چه هنگام از کدهای همگام استفاده کنید. برای مطالعه بخش بعدی این مطلب به لینک زیر رجوع کنید:
منبع: فرادرس