طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیراهنمای سریع Regex — فهرست کاربردی
«عبارتهای منظم» (Regular Expressions) که اصطلاحاً regex یا regexp نامیده میشوند در زمان استخراج اطلاعات از هر متنی کاملاً مفید هستند. این عبارتها برای جستجو و یافتن مطابقت یک یا چند الگوی جستجوی خاص مورد استفاده قرار میگیرند. بدین ترتیب میتوان توالی خالصی از کاراکترهای ASCII یا یونیکد را یافت. زمینههای کاربرد regex از اعتبارسنجی تا تجزیه/جایگزینی رشتهها، ترجمه دادهها به قالبهای دیگر و وب اسکرپینگ متفاوت است.
یکی از جالبترین قابلیتهای Regex این است که پس از یادگیری ساختار آن میتوانید در تقریباً همه زبانهای برنامهنویسی شامل JavaScript ،Java ،VB ،C# ،C / C++ ،Python ،Perl ،Ruby ،Delphi ،R ،Tcl و بسیاری دیگر استفاده کنید. تنها تفاوت در این است که برخی زبانها از برخی قابلیتهای پیشرفتهتر و نسخههای ساختار متفاوت پشتیبانی میکنند.
در ادامه برخی نمونهها را مورد بررسی قرار داده و در مورد هر کدام توضیح میدهیم.
موضوعات ابتدایی Regex
در این بخش برخی موضوعات کاملا مقدماتی مرتبط با regex را مورد بررسی قرار میدهیم.
مهارها – ^ و $
- The^ – با هر رشتهای که با The آغاز شود تطبیق مییابد.
- $end – با هر رشتهای که به کلمه end خاتمه یابد تطبیق مییابد.
- $The end^ – تطبیق دقیق رشتهای را تعریف میکند، یعنی رشته مورد جستجو باید با The آغاز و با end خاتمه یابد.
- roar – با هر رشتهای که کلمه roar در آن باشد تطبیق مییابد.
سورها – * + ? و {}
- *abc – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه صفر یا چند c داشته باشد تطبیق مییابد.
- +abc – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه یک یا چند کاراکتر c داشته باشد تطبیق مییابد.
- ?abc – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه صفر یا یک کاراکتر c داشته باشد تطبیق مییابد.
- {abc{2 – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه دقیقاً 2 کاراکتر c داشته باشد تطبیق مییابد.
- {,abc{2 – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه 2 یا بیشتر کاراکتر c داشته باشد تطبیق مییابد.
- {abc{2,5 – با هر رشتهای که در ابتدایش کاراکترهای ab و در ادامه 2 تا 5 کاراکتر c داشته باشد تطبیق مییابد.
- *(a(bc – با هر رشتهای که در ابتدایش کاراکتر a و در ادامه صفر یا چند کپی از دنباله bc داشته باشد تطبیق مییابد.
- {a(bc){2,5 – با هر رشتهای که در ابتدایش کاراکتر a و در ادامه 2 تا 5 کپی از دنباله bc داشته باشد تطبیق مییابد.
عملگر OR – | یا []
- (a(b|c – با هر رشتهای که یک کاراکتر a و در ادامه b یا c داشته باشد تطبیق مییابد.
- [a[bc – همانند regex قبلی است.
دستههای کاراکتر – d \w \s\ و .
- d\ – با یک کاراکتر منفرد که رقم باشد تطبیق مییابد.
- w\ – با یک کاراکتر کلمه (کاراکتر حرفی/عددی به علاوه زیرخط) تطبیق مییابد.
- s\ – با کاراکتر خالی تطبیق مییابد (شامل tab و line break نیز میشود).
- . – با هر کاراکتری تطبیق مییابد.
باید از عملگر (.) با احتیاط استفاده کنید، چون در اغلب موارد کلاس یا کلاس کاراکتر منفی آن (که در ادامه معرفی میکنیم) سریعتر و بسیار دقیقتر است. حالت نفی d ،\w\ و s\ به ترتیب D ،\W\ و S\ هستند. برای نمونه D\ تطبیق معکوس را با توجه به آن چیزی که با d\ به دست میآید ارائه میکند.
- D\ – با یک کاراکتر غیر رقمی منفرد تطبیق مییابد.
برای این که به صورت عملی از آن استفاده کنید، باید کاراکترها را با استفاده از \ به صورت escape درآورید چون معنای خاصی دارند.
- d\$\ – با رشتهای تطبیق مییابد که یک $ پیش از یک رقم دارد.
توجه کنید که میتوانید کاراکترهای غیر قابل چاپ مانند t\، خطوط جدید n\، بازگشتهای carriage یعنی r\ را نیز تطبیق دهید.
فلگها
تا به این جا در مورد شیوه ساخت یک regex مطالبی آموختیم، اما یک مفهوم بنیادی به نام فلگ را فراموش کردهایم.
Regex معمولاً به صورت /abc/ ارائه میشود که الگوی جستجو به وسیله دو کاراکتر اسلش متمایز شده است. در انتهای عبارت منظم میتوان یک فلگ با مقادیر زیر تعیین کرد (امکان ترکیب کردن آنها با هم نیز وجود دارد):
- g (سراسری یا global) – پس از نخستین تطبیق بازگشت نمییابد و جستجوهای بعدی را از انتهای مورد مطابقت قبلی آغاز میکند.
- m (چندخطی یا multi-line) – زمانی که ^ و $ به جای کل رشته با ابتدا و انتهای یک خط مطابقت داشته باشند.
- i (غیر حساس یا insensitive) – موجب میشود که کل عبارت منظم از حالت حساس به حروف کوچک یا بزرگ خارج شود. برای نمونه aBc/i/ میتواند با AbC تطبیق یابد.
موضوعات سطح متوسط
در این بخش برخی مباحث regex را بررسی میکنیم که فراتر از سطح مقدماتی قبلی هستند، اما هنوز وارد حیطه پیشرفته نشدهایم.
گروهبندی و capture – ()
- (a(bc – پرانتزها یک گروه تشکیل میدهند که مقدار bc را به دست میدهد.
- *(a(?:bc – ما با استفاده از : ? گروه capturing را غیر فعال میکنیم.
- (a(?<foo>bc – با استفاده از <foo>? یک نام برای گروه خود تعیین میکنیم.
این عملگر در مواردی که لازم است اطلاعات از رشتهها یا دادهها با استفاده از زبان برنامهنویسی خاصی استخراج شود کاملاً مفید خواهند بود. هر رخداد چندگانه به وسیله چند گروه به دست میآید و در یک آرایه کلاسیک عرضه میشود، یعنی میتوان با استفاده از یک اندیس روی نتیجه تطبیق به هر رخداد مجزا دسترسی داشت.
اگر بخواهیم برای گروههای خود نامگذاری کنیم، میتوانیم مقادیر گروه را با استفاده از نتیجه تطبیق یافته مانند یک دیکشنری به دست آوریم که در آن کلیدها نام هر گروه خواهند بود.
عبارتهای براکت – []
- [abc] – با هر رشتهای که یک a یا ab یا a c داشته باشد، تطبیق مییابد و معادل a|b|c است.
- [a-c] – همانند قبلی است.
- [a-fA-F0-9] – با رشتهای تطبیق مییابد که نماینده یک رقم هگزادسیمال منفرد است و حساسیت به حروف کوچک یا بزرگ ندارد.
- [0-9]% – با رشتهای تطبیق مییابد که پیش از علامت % یک کاراکتر از 0 تا 9 دارد.
- [^a-zA-Z] – با رشتهای تطبیق مییابد که حرفی از a تا z یا از A تا Z ندارد. در این حالت ^ به عنوان منفی عبارت استفاده میشود.
به خاطر داشته باشید که درون عبارتهای براکتی، همه کاراکترهای خاص (شامل بک اسلش \) قدرت خاص خود را از دست میدهند. بدین ترتیب قاعده scape قابل استفاده نیست.
تطبیق Greedy و Lazy
سورها یعنی * + {} عملگرهای حریص (Greedy) هستند، بنابراین مورد تطبیق را تا آنجا که ممکن است روی متن مورد نظر گسترش میدهند.
برای نمونه <+.> با <div>simple div</div> در عبارت This is a <div> simple div</div> test تطبیق مییابد. برای این که تنها تگ div تطبیق یابد، میتوانیم از یک ? استفاده کنیم تا آن را تنبل (Lazy) کنیم:
- <?+.> – با هر کاراکتری که یک یا چند بار درون < و > آمده باشد تطبیق مییابد و در صورت نیاز گسترش مییابد.
توجه داشته باشید که یک راهحل بهتر عدم استفاده از . به نفع یک regex صریحتر است:
- <+[<>^]> – با هر کاراکتری به جز > یا < که یک یا چند بار درون < و > قرار داشته باشد تطبیق مییابد.
موضوعات پیشرفته
در این بخش، برخی مباحث پیشرفته مرتبط با regex را مورد بررسی قرار میدهیم.
کرانها – b\ و B\
babc\b\ – یک جستجوی «صرفاً کل کلمه» اجرا میکند.
b\ نشاندهنده یک مهار مانند caret است (مشابه $ و ^ است) و با موقعیتهایی تطبیق مییابد که یک طرف یک کاراکتر کلمه (مانند w\) است و طرف دیگر کاراکتر کلمه نیست، مثلاً میتواند ابتدای یک رشته یا یک کاراکتر فاصله باشد.
حالت نفی این کران به صورت B\ است. این کران با همه موقعیتهای تطبیق مییابد که b\ تطبیق پیدا نکند و میتوان از آن برای یافتن الگوی جستجویی استفاده کرد به طور کامل در کاراکترهای کلمهای احاطه شده است.
Babc\B\ تنها در صورتی تطبیق مییابد که الگو به صورت کامل در کاراکترهای کلمه احاطه شده باشد.
ارجاع به عقب – 1\
([abc])\1
استفاده از 1\ موجب میشود که نتیجه با همان متنی تطبیق پیدا کند که در گروه نخست capture مطابقت یافته است.
([abc])([de])\2\1
میتوان از 2\ (3\، 4\ و غیره) نیز برای شناسایی همان متنی که در گروه capture مورد دوم (سوم و چهارم و غیره) تطبیق مییابد استفاده کرد.
(?<foo>[abc])\k<foo> میتوان نام foo را روی گروهی قرار داد و آن را بعداً مورد اشاره قرار داد. نتیجه همان regex نخست است.
گشتن در سمت جلو و عقب (=?) و (=>?)
d(?=r)با یک d تنها در صورتی تطبیق مییابد که در ادامه r آمده باشد، اما r بخشی از تطبیق regex کلی نخواهد بود.
(?<=r)d
تنها در صورتی با یک d تطبیق پیدا میکند که قبل از آن یک r آمده باشد، اما r جزئی از تطبیق regex کلی نخواهد بود.
همچنین میتوان از عملگر نفی نیز استفاده کرد:
d(?!r)
تنها در صورتی با یک d تطبیق مییابد که در ادامه r نیامده باشد، اما r بخشی از تطبیق regex کلی نخواهد بود.
(?<!r)d
تنها در صورتی با یک d تطبیق پیدا میکند که قبل از آن یک r نیامده باشد، اما r جزئی از تطبیق regex کلی نخواهد بود.
جمعبندی
چنان که دیدیم کاربردهای اپلیکیشن regex میتوانند کاملاً متنوع باشند. مطمئناً شما دست کم یکی از این وظایف را تاکنون در زمان اجرای وظایف توسعه نرمافزار خود مشاهده کردهاید. در ادامه این کاربردها را در یک فهرست خلاصه جمعبندی کردهایم.
- اعتبارسنجی داده – برای نمونه آیا یک رشته زمانی به درستی ترکیب یافته است یا نه.
- کاوش داده – به خصوص وب اسکرپینگ که در آن همه صفحههایی که شامل مجموعه خاص از کلمات هستند در نهایت با ترتیب خاصی پیدا میشوند.
- دستکاری دادهها – تبدیل داده از قالب خام به یک قالب دیگر.
- تجزیه متن – برای نمونه گردآوری همه پارامترهای GET در URL و دریافت یک متن که درون یک مجموعه از پرانتزها قرار دارد.
- جایگزینی رشته – برای نمونه در زمان کدنویسی در یک IDE برای ترجمه کلاس جاوا به سی شارپ در شیء JSON متناظر باید (;) با (,) جایگزین شوند، به حالت حروف کوچک درآید و hc اعلان نوع خودداری شود.
- هایلایت کردن ساختار، تغییر دادن نام فایلها، بررسی بستهها و بسیاری کاربردهای دیگر که با رشتهها سرور کار دارند و دادهها باید متنی باشد، همگی با استفاده از regex قابل اجرا هستند.
منبع" فرادرس
مفیدترین ترفندهای پایتون — فهرست کاربردی
در این مقاله به بررسی ترفندهای مفید و مهم زبان برنامهنویسی پایتون میپردازیم. شما با بهرهگیری از این ترفندهای پایتون میتوانید در زمان و تلاش خود صرفهجویی زیادی بکنید.
خارج کردن آیتمهای آرایه از حالت فشرده
با استفاده از روش معرفیشده در مثال زیر میتوانید آیتمهای آرایه را برحسب نامشان مورد دسترس قرار دهید:
تعویض متغیرها
در مثال زیر با روشی آشنا میشوید که امکان تعویض متغیرها را فراهم میسازد:
پروفایل و آمار کد
با استفاده از کتابخانههای معرفیشده در کد زیر میتوانید به برخی آمار مرتبط با کد پایتون خود دسترسی پیدا کنید:
تکرار رشته
شاید برخی اوقات لازم باشد که یک رشته را به مقدار معینی تکرار کنیم. البته انجام این کار در مورد تعداد پایین به صورت دستی بهصرفهتر است، اما زمانی که تعداد بالا باشد، میتوانید از روش زیر برای تکرار رشته کمک بگیرید:
برش دادن
با استفاده از روش ساده معرفیشده در کد زیر میتوانید یک رشته را به هر نوع و طولی که دوست دارید برش دهید:
معکوسسازی
در کد زیر مثالی از روش معکوس سازی یک رشته را مشاهده میکنید:
اندیس منفی
اگر میخواهید از آخرین کاراکتر یک رشته آغاز کنید، میتوانید از اندیس منفی استفاده کنید:
مجموعههای متقاطع
برای این که بتوانید آیتمهای مشترک دو مجموعه را به دست آورید، میتوانید از کد زیر استفاده کنید:
تفاوت مجموعهها
برای به دست آوردن اختلاف بین مجموعهها، یعنی آیتمهایی که در اشتراک دو مجموعه نیستند به روش زیر عمل میکنیم:
اجتماع کالکشنها
برای به دست آوردن ترکیب صریح دو مجموعه از کد زیر استفاده میکنیم:
آرگومانهای اختیاری
با ارائه یک مقدار پیشفرض برای یک آرگومان میتوان آرگومانهای اختیاری ارسال کرد:
آرگومانهای ناشناس با استفاده از arguments*
اگر تابع شما میتواند هر تعداد آرگومان دریافت کند در این صورت میتوانید یک کاراکتر ستاره (*) در ابتدای نام پارامتر قرار دهید:
دیکشنری به عنوان آرگومان با استفاده از arguments**
با بهرهگیری از arguments** میتوان تعداد متغیری از آرگومانهای کلیدواژه را به یک تابع ارسال کرد. بدین ترتیب میتوان مقادیر دیکشنری را به عنوان آرگومانهای کلیدواژه ارسال کرد:
تابع با خروجیهای چندگانه
اگر تابعی الزام به بازگشت مقادیر چندگانه داشته باشد، در این صورت:

حلقههای تکخطی
با استفاده از روش زیر میتوانید حلقههای تکخطی بنویسید:
ترکیب کردن لیستها با استفاده از Zip
در مثال زیر روشی مشاهده میکنید که:
- چند کالکشن میگیرد و یک کالکشن جدید بازمیگرداند.
- کالکشن جدید شامل آیتمهایی است که در آن هر آیتم شامل عناصری از هر کالکشن ورودی است.
- این روش امکان پیمایش چند کالکشن را به طور همزمان فراهم میسازد:
آزادسازی حافظه
فرایند garbage collection دستی را میتوان به صورت زمانبندیشده یا با سازوکاری مبتنی بر رویداد اجرا کرد:
استفاده از دکوراتورها
- دکوراتورها میتوانند بر کارکرد کد بیفزایند. آنها اساساً تابعهایی هستند که شیءها / تابعهای دیگر را فراخوانی میکنند. آنها تابعهای قابل فراخوانی هستند و از این رو شیئی بازگشت میدهند که میتوان در ادامه هنگامی که تابع دکوراتور اجرا میشود، فراخوانی شود.
- دکوراتورها امکان برنامهنویسی «جنبه گرا» (aspect-oriented) را فراهم میسازند.
- ما میتوانیم یک کلاس/تابع را پوشش دهیم و سپس هر زمان که تابعی فراخوانی شود، یک کد خاص اجرا میشود.
مثال زیر شیوه نمایش نام تابع را نمایش میدهد. این تنها یک کد مثالی است که نشان میدهد چگونه میتوانیم یک دکوراتور را فراخوانی کنیم. میتوان از دکوراتورها برای فراخوانی لاگرها، اجرای عملیات امنیتی و موارد دیگر استفاده کرد.
اکنون از آن در تابع خود استفاده میکنیم:
Unzip کردن
در کد زیر با روش Unzip کردن آشنا میشویم:
الحاق کالکشن
در این بخش با کد مرتبط با روش الحاق دو کالکشن مختلف با هم آشنا میشویم:
دسترسی به حافظه یک شیء
در برخی موارد لازم است که مستقیماً به آدرس حافظه یک متغیر دسترسی داشته باشیم:
نمایش دایرکتوری جاری
برای نمایش دایرکتوری کنونی که در آن قرار دارید، میتوانید از کد زیر استفاده کنید:
نمایش ماژولهای ایمپورت شده
برای دیدن این که کدام ماژولها در برنامه ایمپورت شدهاند میتوانید از کد زیر استفاده کنید:
دریافت شناسه پردازش جاری
برای این که شناسه پردازش جاری را به دست آورید میتوانید از کد زیر استفاده کنید:
بدین ترتیب به پایان این مقاله میرسیم. امیدواریم از مطالعه این نکات و ترفندهای زبان برنامهنویسی پایتون لذت برده باشید.
انتخاب رویکرد مناسب در برنامه نویسی ناهمگام جاوا اسکریپت — راهنمای جامع
در آخرین بخش از این سری مقالات برنامه نویسی ناهمگام جاوا اسکریپت بررسی مختصری در خصوص تکنیکها و قابلیتهای مختلف کدنویسی داریم که در طی این دوره آموزش داده شده است. همچنین بررسی میکنیم که باید از کدام رویکردها استفاده کنیم و برخی توصیهها و یادآوریها در مورد تلههای رایج ارائه شدهاند.
پیشنیاز مطالعه این نوشته داشتن سواد مقدماتی رایانه و درک معقولی از مبانی جاوا اسکریپت است. هدف از این مقاله نیز آشنا ساختن مخاطب با روش تشخیص زمان مناسب استفاده از تکنیکهای مختلف برنامهنویسی ناهمگام است. برای مطالعه بخش قبلی این سری مقالات آموزشی به لینک زیر رجوع کنید:
Callback-های ناهمگام
Callback-ها عموماً در API-های به سبک قدیم مشاهده میشوند که در آنها تابعی به عنوان پارامتر به تابع دیگر ارسال میشود و زمانی که یک عملیات ناهمگام تکمیل شد فراخوانی میشود و callback نیز به نوبه خود کاری روی نتیجه اجرا میکند. callback-ها تا قبل از promise-ها استفاده میشدند و کارایی و انعطاف مورد نیاز را نداشتند. بنابراین تنها در موارد ضرورت باید از آنها استفاده کرد.
استفاده از Callback در موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله (callback-های بازگشتی) | بله (callback-های تو در تو) | خیر |
نمونه کد
در ادامه مثالی را مشاهده میکنید که یک منبع را از طریق API به نام XMLHttpRequest بارگذاری میکند:
تلهها
- Callback-های تو در تو میتوانند پیچیده باشند و خوانش دشواری پیدا کنند که به نام جهنم callback مشهور است.
- Callback-های ناموفق باید به ازای هر سطح از تودرتو سازی یک بار فراخوانی شوند، در حالی که با استفاده از promise-ها میتوان از یک بلوک ()catch. منفرد برای مدیریت خطاها در کل زنجیره استفاده کرد.
- Callback-های ناهمگام چندان مناسب نیستند.
- Callback-های promise همواره در ترتیب صحیحی که در صف رویداد قرار گرفتهاند فراخوانی میشوند، در حالی که Callback-های ناهمگام چنین نیستند.
سازگاری مرورگر
مرورگرها پشتیبانی نسبتاً خوبی از Callback دارند، گرچه پشتیبانی دقیق از Callback-ها در API-ها به هر API خاص بستگی دارد. برای اطلاع از پشتیبانی هر API باید به مستندات آن مراجعه کنید.
()setTimeout
()setTimeout متدی است که امکان اجرای یک تابع پس از مقدار زمان دلخواه را فراهم میسازد.
()setTimeout برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| بله | بله (timeout-های بازگشتی) | بله (timeout-های تو در تو) | خیر |
نمونه کد
در کد زیر مرورگر به مدت دو ثانیه منتظر خواهد ماند تا تابع ناهمگام اجرا شود و سپس پیام هشدار را نمایش میدهد:
تلهها
با کدی مانند زیر میتوان از فراخوانیهای ()setTimeout بازگشتی برای اجرای مکرر یک تابع به روشی مشابه ()setInterval استفاده کرد:
البته تفاوتی بین ()setTimeout و ()setInterval بازگشتی وجود دارد:
- ()setTimeout بازگشتی تضمین میکند که دستکم مقدار زمان تعیینشده (در این مثال 100 میلیثانیه) بین دو اجرای تابع زمان وجود خواهد داشت، یعنی کد اجرا خواهد شد و سپس تا قبل از اجرای مجدد، 100 میلیثانیه صبر خواهد کرد. بازه زمانی مورد نظر صرف نظر از مدت زمانی که کد برای اجرا صبر میکند همان خواهد بود.
- در زمان استفاده از ()setInterval، بازه مورد نظر که انتخاب میکنیم شامل زمانی خواهد بود که طول میکشد تا کد منتظر اجرا بماند. فرض کنید اجرای کد 40 میلیثانیه طول بکشد، در این صورت بازه انتظار مورد نظر در نهایت 60 میلیثانیه خواهد بود.
زمانی که انتظار میرود کد، زمان اجرایی طولانیتر از بازهی تعیین شده داشته باشد، بهتر است از ()setTimeout بازگشتی استفاده کنیم. بدین ترتیب بازه زمانی ثابتی بین اجراها لحاظ میشود و مهم نیست که اجرای کد جه قدر طول بکشد. بدین ترتیب از بروز خطا اجتناب میشود.
سازگاری مرورگر
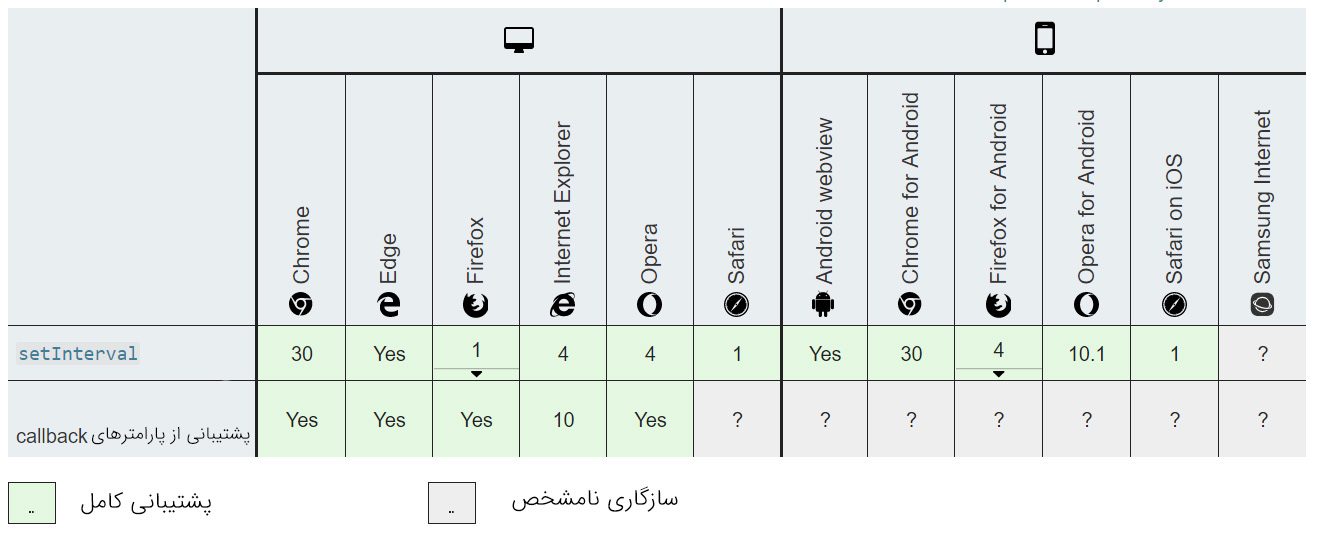
()setInterval
()setInterval متدی است که امکان اجرای مکرر تابع را با بازه انتظار تنظیم شده بین هر اجرا فراهم میسازد. ()setInterval به اندازه ()requestAnimationFrame کارآمد نیست، اما امکان انتخاب نرخ فریم. نرخ اجرا را میدهد.
برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله | نه (مگر این که یکسان باشد) | خیر |
نمونه کد
تابع زیر یک شیء ()Date ایجاد میکند، رشته زمانی را با استفاده از ()toLocaleTimeString از آن استخراج میکند و سپس آن را در رابط کاربری نمایش میدهد. سپس آن را هر ثانیه یک بار با استفاده از ()setInterval اجرا میکنیم و جلوهای شبیه به یک ساعت دیجیتالی ایجاد میکنیم که هر ثانیه یک بار بهروزرسانی میشود:
تلهها
نرخ فریم برای سیستمی که انیمیشن روی آن اجرا میشود، بهینهسازی نشده و ممکن است ناکارآمد باشد. به جز در مواردی که نیاز به نرخ فریم پایینتر (آهستهتر) داشته باشیم، عموماً بهتر است از ()requestAnimationFrame استفاده کنیم.
سازگاری مرورگر
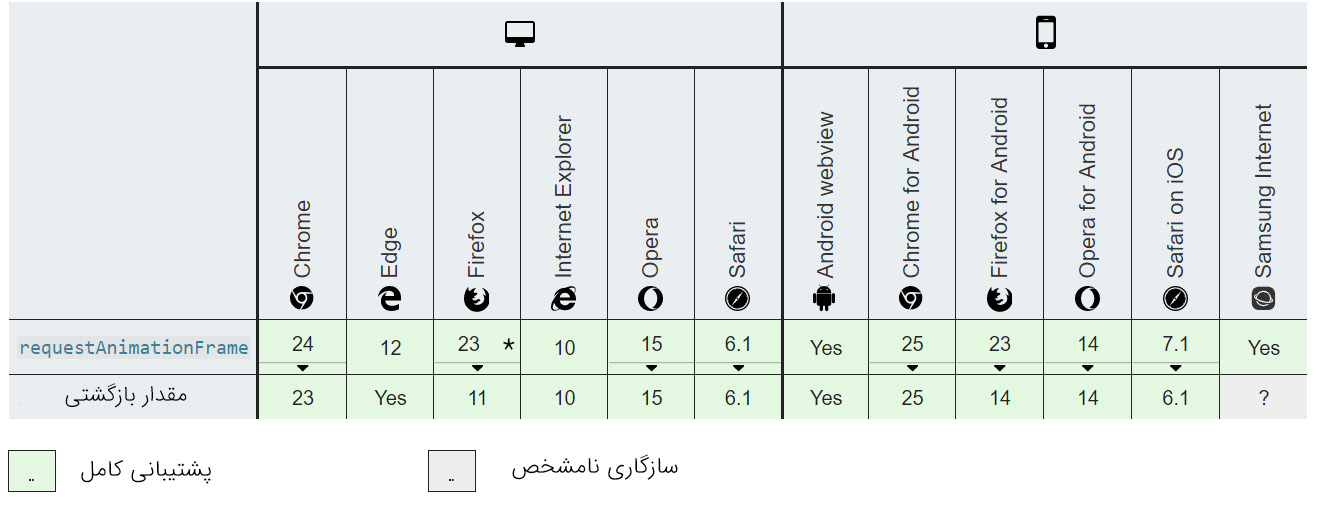
()requestAnimationFrame
()requestAnimationFrame متدی است که امکان اجرای مکرر تابع را به روشی کارآمد فراهم میسازد. بهترین نکته در مورد این متد آن است که بهترین نرخ فریم ممکن را برای مرورگر/سیستم جاری به دست میدهد. شما باید در صورت امکان از این متد به جای ()setInterval() / setTimeout بازگشتی استفاده کنید، مگر این که به نرخ فریم خاصی نیاز داشته باشید.
برای موارد زیر مناسب است/ نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله | خیر (مگر این که یکسان باشد) | خیر |
نمونه کد
در مثال زیر یک اسپینر ساده انیمیت شده را میبینید:
تلهها
هنگام استفاده از متد ()requestAnimationFrame امکان انتخاب یک نرخ فریم خاص وجود ندارد. اگر نیاز داشته باشید که انیمیشن با نرخ فریم کُندتری کار کند، باید از ()setInterval یا ()setTimeout بازگشتی استفاده کند.
سازگاری مرورگر
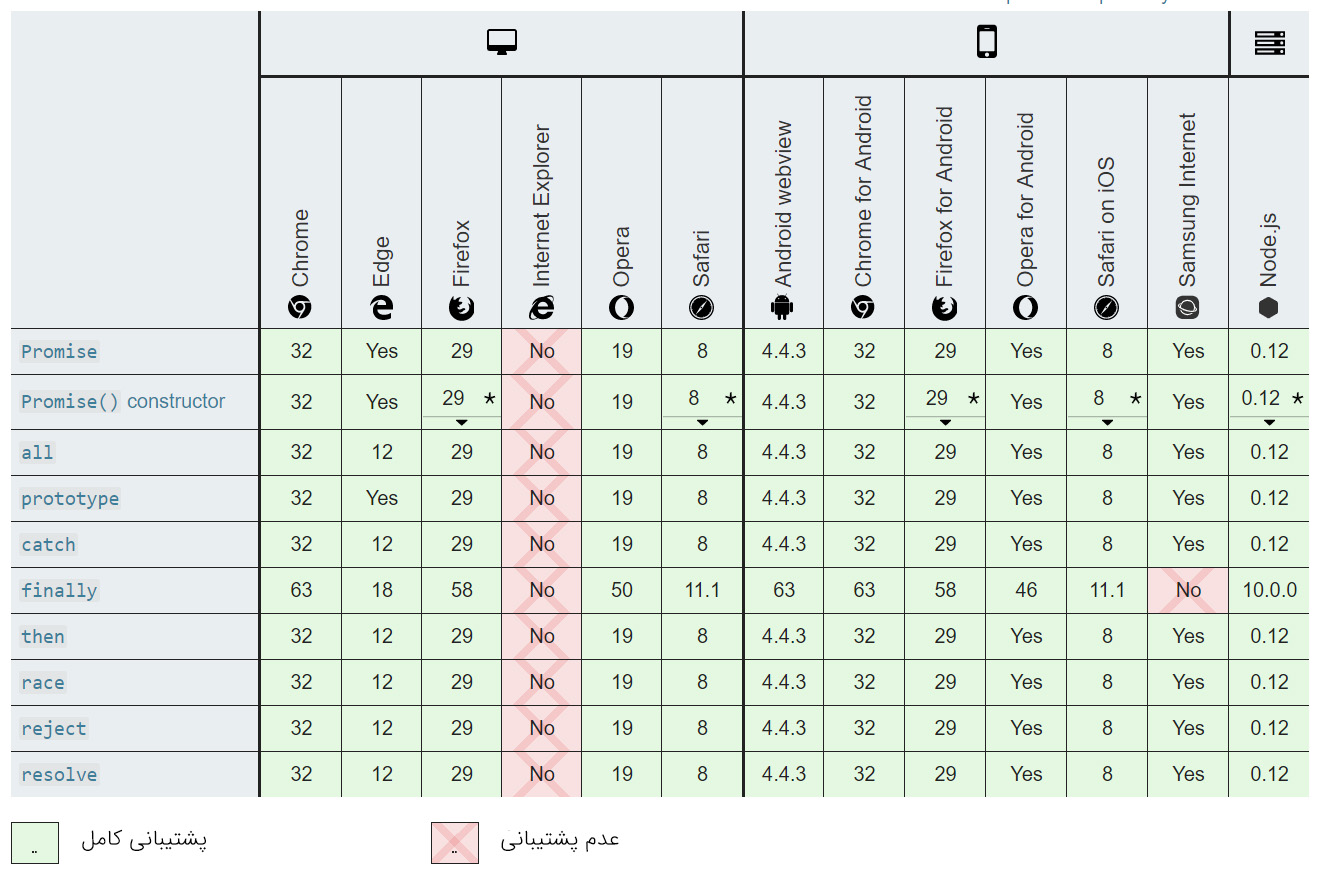
Promise-ها
Promise-ها قابلیتی از جاوا اسکریپت هستند که امکان اجرای عملیات ناهمگام را میدهند و تا زمانی که تابع به طور کامل اجرا نشده است منتظر میمانند تا بر اساس نتیجه آن عملیات دیگر را اجرا کنند. Promise-ها ستون فقرات جاوا اسکریپت مدرن ناهمگام محسوب میشوند.
برای موارد زیر مناسب است / نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | بله | به بخش ()Promise.all در ادامه مراجعه کنید. |
نمونه کد
کد زیر یک تصویر را از سرور واکشی کرده و آن را درون یک عنصر <img> نمایش میدهد:
تلهها
زنجیرههای Promise میتوانند پیچیده باشند و تجزیه آنها دشوار باشد. اگر چند Promise را به صورت تو در تو تعریف کنید، ممکن است در نهایت با همان مشکل جهنم callback مواجه شوید. برای مثال به کد زیر توجه کنید:
بهتر است از قدرت زنجیرهسازی Promise-ها برای ایجاد ساختار مسطحتر و با تجزیه آسانتر استفاده کنید:
یا حتی:
سازگاری مرورگر
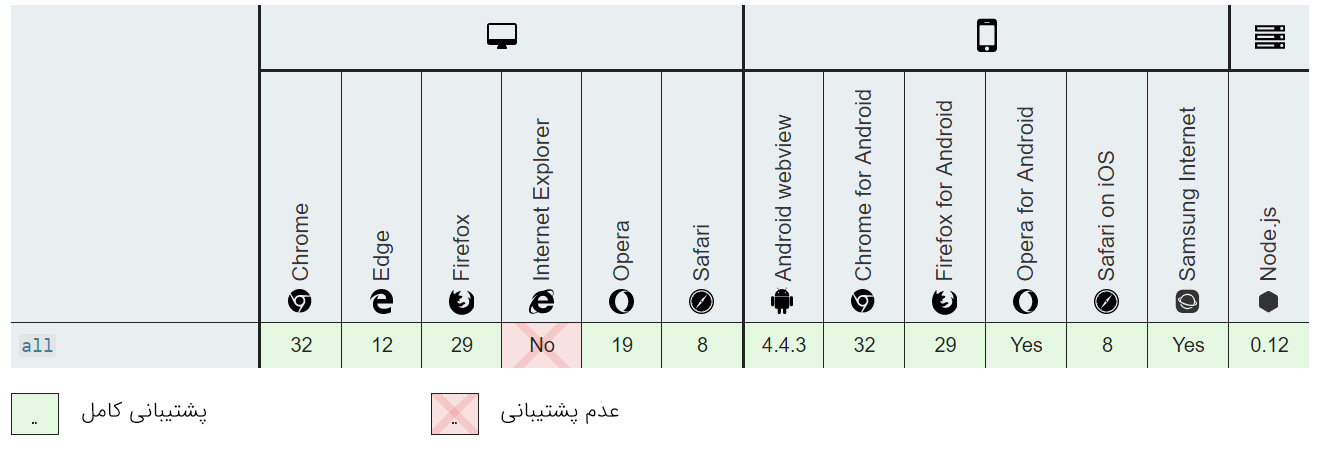
()Promise.all
یکی از قابلیتهای جاوا اسکریپت این است که میتوان منتظر چند Promise ماند تا این Promise-ها به پایان برسند. و یک عملیات دیگر بر مبنای نتایج این Promise-ها اجرا کرد.
برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | خیر | بله |
نمونه کد
در مثال زیر چند منبع از سرور واکشی میشوند و از ()Promise.all استفاده میشود تا زمانی که همه منابع آماده شدند منتظر بماند و سپس همه آنها را نمایش میدهد:
تلهها
اگر یک ()Promise.all رد شود، در این صورت یک یا چند مورد از Promise-هایی که درون پارامترهای آرایه آن وارد شده باید رد شوند، در غیر این صورت Promise-ها کلاً بازگشت نمییابند. بدین ترتیب باید آنها را یک به یک بررسی کنید تا ببینید کدام یک بازگشت یافتهاند.
سازگاری مرورگر
Async/await
Async/await یک ساختار نمادین (Syntactic sugar) است که بر مبنای promise-ها ساخته شده و امکان اجرای عملیات ناهمگام را با استفاده از ساختاری فراهم میکند که بیشتر شبیه نوشتن کد callback همگام است.
برای موارد زیر مناسب است/ نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | بله | بله (در ترکیب با ()Promise.all) |
نمونه کد
مثال زیر یک بازنویسی از مثال Promise سادهای است که قبلاً دیدیم و تصاویر را واکشی کرده و نمایش میداد و این بار با استفاده Async/await نوشته شده است:
تلهها
- از عملگر await نمیتوان درون یک تابع غیر ناهمگام یا در سطح بالای ساختار کد استفاده کرد. این موضوع در برخی موارد موجب نیاز به ایجاد پوشش تابعی اضافی میشود که در برخی شرایط ممکن است دشوار باشد، اما در اغلب موارد ارزشش را دارد.
- پشتیبانی مرورگر برای async/await به اندازه Promise-ها مناسب است. اگر میخواهید از async/await استفاده کنید، اما در مورد پشتیبانی مرورگرهای قدیمی دغدغه دارید، میتوانید از کتابخانه BabelJS استفاده کنید. این کتابخانه امکان نوشتن اپلیکیشنها را با استفاده از جدیدترین کدهای جاوا اسکریپت میدهد و سپس تغییرات مورد نظر را بسته به نیاز در مورد مرورگرهای کاربر اعمال میکند.
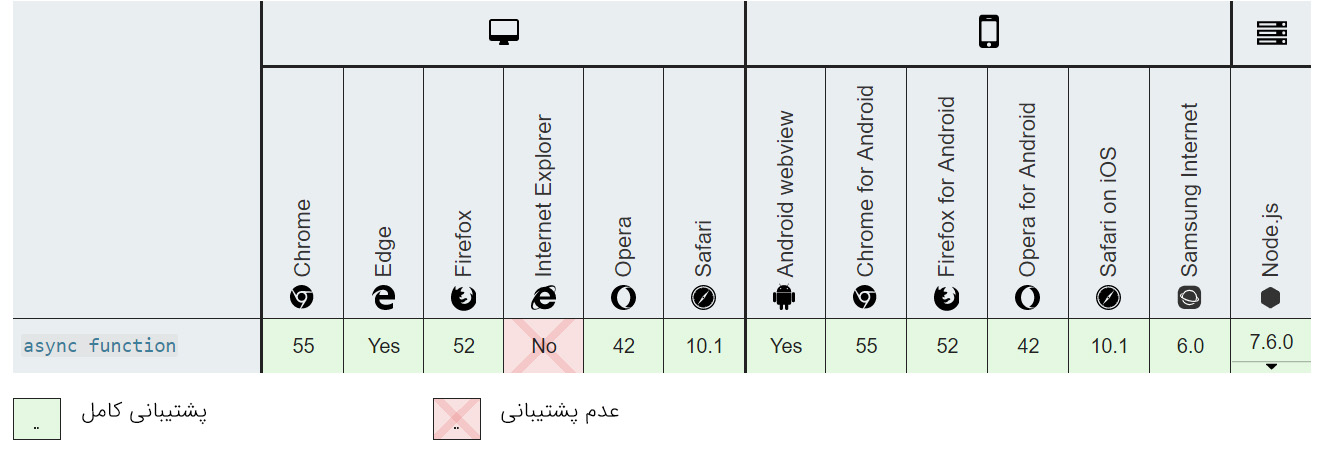
سازگاری مرورگر
بدین ترتیب به پایان این مقاله میرسیم.
منبع: فرادرس
موارد استثنا در پایتون — راهنمای کاربردی
در هر زبان برنامهنویسی شاهد حضور دو نوع خطا هستیم که یکی خطاهای کامپایل و دیگری خطاهای زمان اجرا است. خطاهای کامپایل در زمان کامپایل کردن کد منبع و در نتیجهی ساختار یا معناشناسی نادرست رخ میدهند. در این مقاله به بررسی موارد استثنا در پایتون می پردازیم. به مثال زیر توجه کنید:
در کد فوق پرانتز انتهایی فراموش شده است و در نتیجه خطای ساختاری رخ داده که در زمان تلاش برای اجرای کد بروز مییابد. این خطا در زمان کامپایل کردن کد ظاهر میشود و از این رو خطای کامپایل نام دارد (به طور خاص خطای ساختاری یا نحوی نامیده میشود) برای اصلاح این خطا در خط فوق، کافی است یک پرانتز انتهایی در آخر خط قرار دهیم، یعنی باید ساختار/معناشناسی کد را به صورت زیر اصلاح کنیم:
از سوی دیگر خطاهای زمان اجرا زمانی رخ میدهند که برنامه در حال اجرا است. این خطاها در نتیجه زمینه/ ورودی غیر معمول در یک قطعه کد اجرایی حاصل میشوند. یعنی یک برنامه که از نظر ساختاری و معناشناختی صحیح است بسته به زمینه اجرایی و ورودی برنامه ممکن است خطا داشته باشد یا نداشته باشد. به مثال زیر توجه کنید:
کد فوق از نظر ساختاری و معناشناختی صحیح است و هیچ خطایی تولید نمیکند. نتیجه پس از اجرای برنامه res=20 خواهد بود. اینک به کد زیر توجه کنید:
با این که کد از نظر ساختاری و معناشناختی صحیح است، اما در زمان اجرا خطایی صادر میکند. دلیل خطا تلاش برای تقسیم بر صفر است که تعریف نشده است. این نمونهای از خطای زمان اجرا به دلیل ورودی نامعمول است. این خطاهای زمان اجرا به نام «استثنا» (Exception) نیز شناخته میشوند.
نمونههایی از خطاهای زمان اجرا که به دلیل زمینه یا چارچوب پدید میآیند، اجرا کردن یک برنامه (که از کارکردهای خاص سیستم عامل استفاده میکند) روی یک سیستم ناسازگار است.
چرا خطاهای زمان اجرا بد هستند؟
دلیل بد بودن خطاهای زمان اجرا این است که در زمان وقوع، موجب خاتمه یافتن برنامه میشوند.
موقعیتی را تصور کنید که یک برنامه ماشین حساب ساختهایم که عملیات ابتدایی حساب (+، -، * و /) را روی دو عدد اجرا میکند. این برنامه از کاربر دو عدد میخواهد و عملیات مورد نظر را نیز میپرسد تا روی اعداد اجرا کند. فرض کنید برنامه در حلقه اجرا میشود، یعنی زمانی که 3 ورودی را درخواست کرد (دو عملوند و یک عملگر) محاسبه را اجرا کرده و نتیجه را نمایش میدهد، و سپس منتظر وارد کردن 3 ورودی بعدی میماند و نتایج آنها را نیز محاسبه و نمایش میدهد و همین طور تا آخر ادامه میدهد.
این برنامه کار خود را به درستی انجام میدهد تا این که عملیات تقسیم بر صفر پیش بیاید (مثلاً 25/0). در این ورودی، برنامه یک خطای زمان اجرا/استثنا صادر میکند، چون نمیتواند نتیجه را تحلیل کند و بیدرنگ خاتمه مییابد. شما باید برنامه را از نو آغاز کنید و مجدداً مقادیر را وارد نمایید تا چنین ورودی پیش بیاید. این فقط یک برنامه ماشین حساب ساده است که راهاندازی مجدد آن چند ثانیه طول میکشد، اما نرمافزاری که راهاندازی مجدد آن دقایق یا ساعتها طول میکشد چطور؟ گاهی اوقات نیز کلاً امکان راهاندازی مجدد وجود ندارد و این وضعیت نامناسبی ایجاد میکند.
آیا راهی برای جلوگیری از وقوع استثنا وجود دارد؟ نه، ما نمیتوانیم از وقوع استثناها جلوگیری کنیم، اما میتوانیم آنها را طوری مدیریت کنیم که موجب خاتمه یافتن برنامه نشوند.
منظور از مدیریت استثنا چیست؟ معنی مدیریت استثنا این است که وقتی اتفاق میافتد نگذاریم برنامه را پایان دهد و برنامه بتواند به اجرای خود ادامه دهد.
استثنا چگونه مدیریت میشود؟ در بخشهای بعدی این مقاله به بررسی همین موضوع خواهیم پرداخت.
هر آنچه تاکنون مطرح کردیم در مورد همه زبانهای برنامهنویسی که از استثنا و مدیریت آنها پشتیبانی میکنند، قابل تعمیم است. اینک نوبت آن رسیده است که بحث را به یک زبان خاص یعنی پایتون محدود کنیم. از این بخش به بعد همه مواردی که مطرح میشوند مختص زبان برنامهنویسی پایتون هستند مگر این که صراحتاً چیز دیگری قید شده باشد.
استثناها در پایتون
اینک به بررسی روش مدیریت استثناها در پایتون میپردازیم.
مدیریت استثناها
برای مدیریت استثناها در پایتون چند روش وجود دارد که در ادامه هر یک از آنها را به تفصیل مورد بررسی قرار خواهیم داد.
بلوک try-except ابتدایی
استثناها از طریق یک گزاره try مدیریت میشوند که ساختار مقدماتی آن به صورت زیر است:
کدی که مشکوک به ایجاد استثنا است زیر بند try یک گزاره try قرار میگیرد. کدی که باید در زمان بروز استثنا برای مدیریت آن اجرا شود نیز زیر بند except قرار میگیرد. به مثال زیر توجه کنید:
خروجی برای ورودی متفاوت:
>>> divide(50، 2) Result = 25 >>> divide(50، 0) Divisor is zero; Division is impossible
گزاره try به صورت زیر عمل میکند:
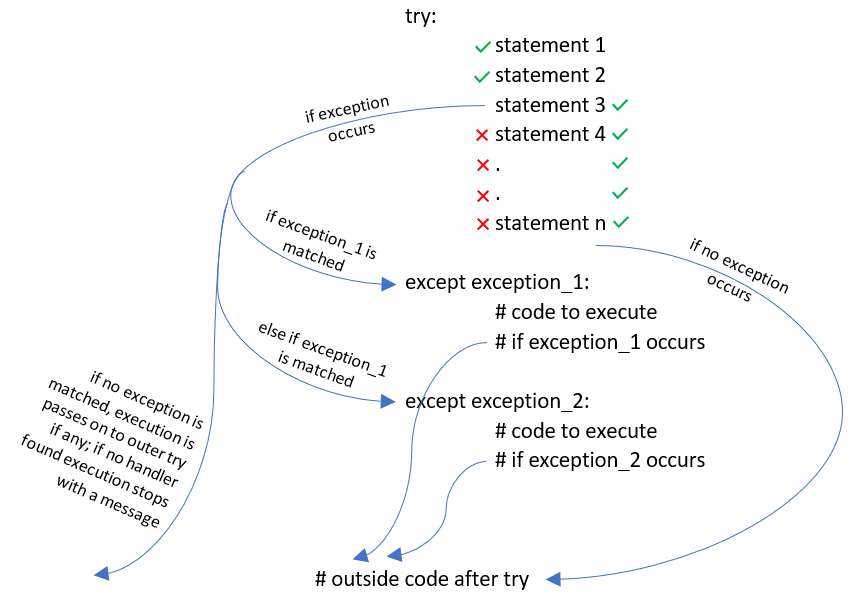
بندهای چندگانه except
این امکان هست که یک کد بیش از یک نوع استثنا ایجاد کند. مثلاً استثناها ممکن است از انواع ValueError ،AttributeError ،KeyError و غیره باشند. اینها مواردی از استثناهای داخلی هستند یعنی در خود پایتون موجود هستند. برای مشاهده لیست کامل آنها به این لینک (+) مراجعه کنید. شما میتوانید استثناها را خودتان نیز تولید و صادر کنید! در ادامه در این مورد بیشتر توضیح خواهیم داد.
اما اینک سؤال این است که چگونه میتوان استثناهای چندگانه (هم داخلی و هم سفارشی) که از کد موجود در بلوک try ناشی میشوند را مدیریت کرد؟ آیا پایتون پشتیانی خاصی از این وضعیت دارد؟ بله چنین است. بدین منظور باید از بندهای چندگانه except استفاده کنیم. به مثال زیر توجه کنید:
>>> int_value = int(a)
این گزاره ممکن است موجب بروز ValueError یا TypeError شود یا کلاً هیچ نوع استثنایی ایجاد نکند و همه اینها به نوع و مقدار متغیر a بستگی دارد. فرض کنید a= 3.2 یا ‘a = ‘1200 باشد در این صورت هیچ استثنایی تولید نمیشود؛ اما اگر ‘a=’12k باشد، در این صورت ValueError رخ میدهد. همچنین اگر [a= [1، 2 باشد در این صورت استثنای TypeError بروز مییابد.
روش مدیریت هر دوی آنها به صورت زیر است:
کد فوق صرفاً نردبانی از بندهای except است و استثناهایی دارد که قرار است مدیریت شوند. نکتهای که باید توجه داشت این است که ترتیب مدیریت باید صحیح باشد.
Exception در بند except به مدیریت استثناهایی از یک نوع یا مشتق از آن میپردازد. اما معکوس آن صحیح نیست یعنی Exception در بند except به مدیریت خطای پایه از نوعی که مشتق شده نمیپردازد. برای نمونه کد زیر به ترتیب مقادیر B ،C و D را نمایش میدهد:
توجه کنید که اگر بندهای except معکوس بودند (یعنی except به نام B اول بود، موارد نمایش یافته به صورت B ،B ،B بودند و نخستین بند except منطبق تحریک میشد. برای بصریسازی بهتر به تصویر زیر توجه کنید:
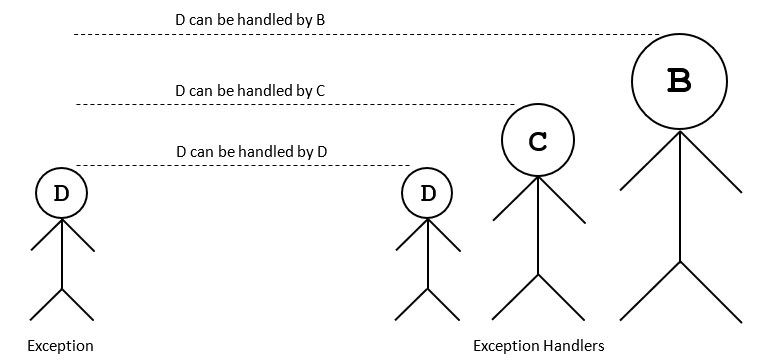
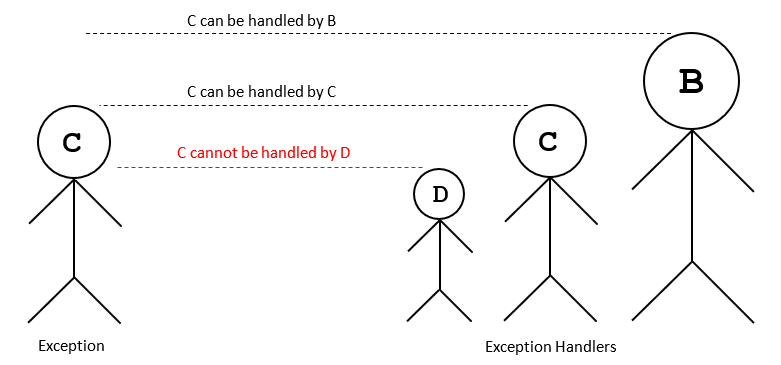
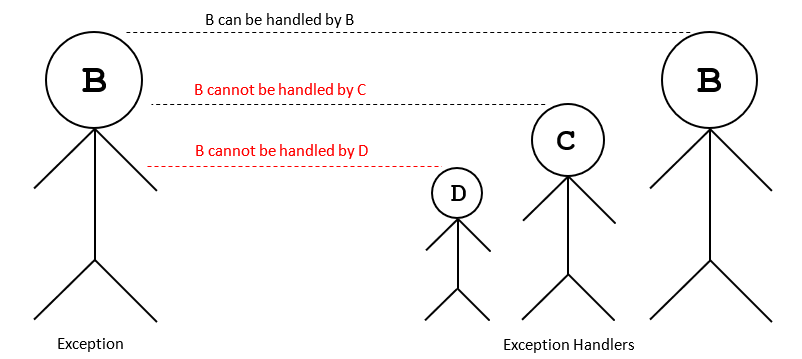
در این تصویر در سمت راست نوعی استثنا رخ داده است، سمت چپ مدیران استثنا هستند که D از C مشتق میشود و C نیز از B مشتق میشود.
استثناهای چندگانه در یک بند except منفرد
یک حالت کوتاهتر (البته نه همیشه) برای ساختار فوق نیز وجود دارد. ساختار کلی آن به صورت زیر است:
و مثالی از آن به صورت زیر است:
یعنی همه استثناهایی که قصد داشتیم مدیریت کنیم در یک چندتایی ترکیب میکنیم. استثناهایی که در این چندتاییها ستاند با ترتیب ظهورشان در چندتایی مطابقت دارند. قاعده بخش قبلی در این بخش نیز صدق میکند. میتوان هر دو این رویکردها را با هم ترکیب نیز کرد یعنی یک نردبان از بندهای except داشت که هر یک بیش از یک استثنا (در چندتایی) را مدیریت میکنند.
در نهایت سؤال این است که تفاوت بین دو رویکرد فوق چیست و هر کدام در چه موقعیتی بهتر هستند؟
تفاوت دو رویکرد فوق در شیوه پاسخدهی در زمان مدیریت استثناها است.
- اگر میخواهید یک قطعه کد را برای همه استثناهای مدیریتشده اجرا کنید، در این صورت از رویکرد دوم استفاده کنید. این رویکرد از تکرار قطعه کد در بندهای except چندگانه جلوگیری میکند.
- اگر میخواهید بسته به نوع استثناهایی که مدیریت میکنید، قطعه کدهای متفاوتی داشته باشید، در این صورت از رویکرد اول استفاده کنید. البته اجرای این کار با استفاده از رویکرد دوم نیز میسر است و مثالی از روش اجرای آن به صورت زیر است:
اما بهتر است که از رویکرد اول برای چنین حالتهایی استفاده کنید، زیرا درک آن آسانتر است و از پشتیبانی ارائه شده از سوی خود زبان به جای یک راهحل مانند فوق بهره میگیرد.
تعیین نام مستعار
به خط زیر در کد بخش قبل توجه کنید:
except (exception_1، exception_2،..) as e:
این استثنایی است (هستند) که یک نام برای آن تعیین شده است. این کار از نظر فنی «aliasing» یا تعیین نام مستعار نامیده میشود.
در زمان تعیین نام مستعار، میتوانیم با استفاده از یک نام رایج به استثنا (ها) دسترسی داشته باشیم. این حالت در زمانی مفید خواهد بود که بخواهیم از خصوصیتهای استثنایی که مدیریت میشود بهره بگیریم. تعیین نام مستعار از طریق کلیدواژه as صورت میگیرد. ساختار آن به صورت زیر است:
در کد فوق <alias> را باید با نام مستعار مورد نظر خود جایگزین کنید. به مثال زیر توجه کنید:
خروجی:
('Invalid name')شما میتوانید از هر عنوانی برای نام مستعار استفاده کنید. بدیهی است که امکان استفاده از کلیدواژههای داخلی میسر نیست. به طور معمول از e استفاده میشود.
نکته: اگر میخواهد برای یک استثنای منفرد نام مستعار تعیین کنید در این صورت استفاده از پرانتزهای پیرامونی اختیاری است. اما در صورتی که مانند مثال فوق از استثناهای چندگانه استفاده میکنید، پرانتزها الزامی هستند.
بند else
برخی اوقات با حالتی مواجه میشویم که میخواهیم یک قطعه کد را تنها و تنها در صورتی اجرا کنیم که کد زیر بند try هیچ استثنایی ایجاد نکرده باشد. به مثال زیر توجه کنید:
مسئله: تابعی به نام divide بنویسید که a را بر b تقسیم کند (به عنوان پارامتر ارسال میشود) و موارد زیر را در خروجی نمایش دهد:
- اگر b برابر با صفر بود، در این صورت عبارت «امکان تقسیم بر صفر وجود ندارد.» را نمایش دهد.
- در غیر این صورت <Output = <quotient را نمایش دهد که quotient حاصل تقسیم است.
راهحل
خروجی
>>> divide(20، 10) Output = 2.0 >>> divide(20، 0) Cannot divide by zero
بند else اختیاری است و در صورت حضور، همواره از بند except تبعیت میکند. کد زیر بند else تنها زمانی اجرا خواهد شد که بند زیر try هیچ استثنایی صادر نکند. اگر استثنایی در بلوک try صادر شود، در این صورت بلوک else اجرا نخواهد شد بلکه بند except آن را مدیریت خواهد کرد.
بند Finally
گزاره try یک بند دیگر به نام Finally نیز دارد که اساساً برای پاکسازی اقدامات استفاده میشود. این بند پس از همه بندهای دیگر میآید. بند Finally در هر حالتی صرف نظر از این که استثنایی رخ داده یا نداده باشد اجرا خواهد شد. بند Finally لزوماً نیازی به وجود بندهای else یا except ندارد. به مثال زیر توجه کنید:
خروجی
>>> divide(2، 1)
Output = 2.0
Executing finally clause
>>> divide(2، 0)
Cannot divide by zero
Executing finally clause
>>> divide("2"، "1")
Executing finally clause
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
File "<stdin>"، line 3، in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'بند Finally همواره پیش از ترک گزاره try اجرا خواهد شد و مهم نیست که استثنایی رخ داده است یا نه. زمانی که یک استثنا در بند try رخ دهد و از سوی بند except مدیریت نشود (و یا در بند except یا else رخ دهد) در واقع مجدداً پس از اجرای بند Finally رخ داده است (فراخوانی سوم به تابع divide را در بخش قبل ببینید). بند Finally در مسیر خروجی زمانی که از یک گزاره break ،continue یا return استفاده شده باشد همچنان اجرا خواهد شد.
کاربردهای عملی بند Finally برای آزادسازی منابع مانند فایلها یا اتصالهای پایگاه داده و مواردی از این دست است. فرق بین داشتن کدی داخل بند Finally و نوشتن آن خارج از این بند و پس از گزاره try چیست؟ به بیان ساده فرق بین دو حالت زیر چیست؟
تفاوت دو کد فوق تنها زمانی مشخص میشود که استثنایی (در هر یک از بندهای try ،except یا else) رخ دهد و مدیریت نشده باشد. در این حالت:
- کد اول عبارت ‘Leaving the function’ را نمایش داده و استثنا را مجدداً صادر میکند.
- کد دوم عبارت ‘Leaving the function’ را نمایش نمیدهد و استثنا به کد بیرونی ارسال میشود.
برای جمعبندی باید اشاره کنیم که فرق بین دو سناریوی فوق این است که کد موجود در بند Finally حتی در صورتی که استثنایی رخ داده باشد (و مدیریت نشده باشد) اجرا میشود؛ اما کدی که در ادامه گزاره try میآید چنین حالتی ندارد.
ایجاد استثناها
در این بخش با روش ایجاد دستی استثناها و همچنین ایجاد استثناهای سفارشی آشنا میشویم.
ایجاد استثناهای داخلی
پایتون روشی برای ایجاد دستی یک استثنا ارائه کرده است. این کار از طریق کلیدواژه raise صورت میپذیرد.
>>> raise AssertionError('Asserted statement is incorrect')
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
raise AssertionError('Asserted statement is incorrect')
AssertionError: Asserted statement is incorrectکلیدواژه raise تنها یک آرگومان میگیرد که یا یک کلاس استثنا است (که از کلاس Exception مشتق میشود) و یا یک وهله از استثنا است. در کد مثال فوق، آرگومان یک وهله از استثنا با پیام رشتهای است. این پیام رشتهای (اختیاری) زمانی که ارسال شود، خطا را توصیف میکند.
اگر آرگومان یک کلاس استثنا باشد، در این صورت سازنده آن بدون هیچ آرگومانی به صورت زیر فراخوانی میشود:
>>> raise AssertionError Traceback (most recent call last) File "<stdin>"، line 1، in <module> raise AssertionError AssertionError
تعریف و ایجاد استثناهای سفارشی
پیش از این که به معرفی روش ایجاد استثناهای سفارشی بپردازیم ابتدا به این سؤال پاسخ میدهیم که اساساً این کار چه ضرورتی دارد. موارد خاصی وجود دارند که در آنها استثناهای داخلی نمیتوانند برای توصیف معنیدار خطای رخ داده، مورد استفاده قرار گیرند.
برای نمونه فرض کنید تابع سادهای داریم که تعداد واحدهای (برق) مصرفی بین دو خوانش مجزا را محاسبه میکند. اگر هر کدام از خوانش ها منفی باشند، تابع استثنای ValueError ایجاد میکند و فرض میکند که واحدهای مصرفی محاسبهشده منفی هستند. در این صورت میخواهیم یک استثنا ایجاد شود (برای مثال NegativeConsumptionError). اما این استثنا جزء استثناهای داخلی پایتون نیست. البته ما همچنان میتوانیم از استثنای داخلی ValueError برای مدیریت این مورد نیز استفاده کنیم. اگر بخواهیم از ValueError برای این خطا استفاده کنیم، در این صورت هیچ روشی برای کد فراخوانی کننده electricity_consumption جهت ایجاد تمایز بین ‘Negative reading’ and ‘Negative consumption’ وجود نخواهد داشت.
با استفاده از استثنای داخلی ValueError
با استفاده از استثنای سفارشی
روش تعریف استثنای سفارشی چگونه است؟
برای تعریف یک استثنای سفارشی باید یک کلاس تعریف کنید که از کلاس Exception مشتق میشود یا یک کلاس فرعی از آن بسازید. در ادامه یک مثال ساده را ملاحظه میکنید:
یک رویه رایج، ایجاد کلاس مبنا برای استثناهای تعریف شده از سوی ماژول و ایجاد کلاس فرعی از آن برای ایجاد کلاسهای استثنای خاص برای شرایط خطای متفاوت است. زمانی که استثنای مبنا را برای یک ماژول تعریف کردیم و سپس از آن کلاس فرعی برای تعریف استثناهای خاص ساختیم، میتوانیم به سادگی همه استثناها را که از آن ناشی میشوند با استفاده از استثنای مبنا مدیریت کنیم.
همچنین میتوانید خصوصیتهایی روی استثناهای سفارشی تعیین کنید که با استفاده از دستگیرههایی قابل بازیابی باشند. به مثال زیر توجه کنید:
خروجی
2 # 3 Unknown operator
Logger.exception
ما در همه کدهای عملی خود از لاگرها استفاده میکنیم، چون لاگرها کار دیباگ گردن را تسهیل میکنند. لاگرها در پایتون، پشتیبانی خاصی برای استثناها دارند. از این رو در ادامه مقداری در مورد آنها توضیح میدهیم.
متد مربوطه ()logger.exception نام دارد. به کد زیر توجه کنید:
خروجی کد فوق یک رد پشته کامل از استثنا است که مدیریت شده است و صرفاً یک توصیف متنی از استثنا محسوب نمیشود. مزیتهای آن به شرح زیر هستند:
دیگر نیاز نداریم از نامهای مستعار برای استثناها استفاده کنیم، مگر اینکه آن را درون بند except نیاز داشته باشیم، چون استثنای رخ داده به صورت ضمنی در ()logger.exception قرار دارد.
علاوه بر ردگیری پشته، ()logger.exception یک پیام روی رد پشته نیز نمایش میدهد. بدین ترتیب خروجی لاگ قطعه کد به صورت زیر خواهد بود:
ERROR: Exception while performing division — handled Traceback (most recent call last): File "<stdin>"، line 1، in <module> raise ZeroDivisionError ZeroDivisionError
نکته 1: ()logger.exception پیامها را با سطح ERROR لاگ میکند.
نکته 2: ()logger.exception باید تنها از یک دستگیره استثنا فراخوانی شود.
بدین ترتیب به پایان این مقاله میرسیم.
منبع" فرادرس
موارد استثنا در پایتون — راهنمای کاربردی
در هر زبان برنامهنویسی شاهد حضور دو نوع خطا هستیم که یکی خطاهای کامپایل و دیگری خطاهای زمان اجرا است. خطاهای کامپایل در زمان کامپایل کردن کد منبع و در نتیجهی ساختار یا معناشناسی نادرست رخ میدهند. در این مقاله به بررسی موارد استثنا در پایتون می پردازیم. به مثال زیر توجه کنید:
در کد فوق پرانتز انتهایی فراموش شده است و در نتیجه خطای ساختاری رخ داده که در زمان تلاش برای اجرای کد بروز مییابد. این خطا در زمان کامپایل کردن کد ظاهر میشود و از این رو خطای کامپایل نام دارد (به طور خاص خطای ساختاری یا نحوی نامیده میشود) برای اصلاح این خطا در خط فوق، کافی است یک پرانتز انتهایی در آخر خط قرار دهیم، یعنی باید ساختار/معناشناسی کد را به صورت زیر اصلاح کنیم:
از سوی دیگر خطاهای زمان اجرا زمانی رخ میدهند که برنامه در حال اجرا است. این خطاها در نتیجه زمینه/ ورودی غیر معمول در یک قطعه کد اجرایی حاصل میشوند. یعنی یک برنامه که از نظر ساختاری و معناشناختی صحیح است بسته به زمینه اجرایی و ورودی برنامه ممکن است خطا داشته باشد یا نداشته باشد. به مثال زیر توجه کنید:
کد فوق از نظر ساختاری و معناشناختی صحیح است و هیچ خطایی تولید نمیکند. نتیجه پس از اجرای برنامه res=20 خواهد بود. اینک به کد زیر توجه کنید:
با این که کد از نظر ساختاری و معناشناختی صحیح است، اما در زمان اجرا خطایی صادر میکند. دلیل خطا تلاش برای تقسیم بر صفر است که تعریف نشده است. این نمونهای از خطای زمان اجرا به دلیل ورودی نامعمول است. این خطاهای زمان اجرا به نام «استثنا» (Exception) نیز شناخته میشوند.
نمونههایی از خطاهای زمان اجرا که به دلیل زمینه یا چارچوب پدید میآیند، اجرا کردن یک برنامه (که از کارکردهای خاص سیستم عامل استفاده میکند) روی یک سیستم ناسازگار است.
چرا خطاهای زمان اجرا بد هستند؟
دلیل بد بودن خطاهای زمان اجرا این است که در زمان وقوع، موجب خاتمه یافتن برنامه میشوند.
موقعیتی را تصور کنید که یک برنامه ماشین حساب ساختهایم که عملیات ابتدایی حساب (+، -، * و /) را روی دو عدد اجرا میکند. این برنامه از کاربر دو عدد میخواهد و عملیات مورد نظر را نیز میپرسد تا روی اعداد اجرا کند. فرض کنید برنامه در حلقه اجرا میشود، یعنی زمانی که 3 ورودی را درخواست کرد (دو عملوند و یک عملگر) محاسبه را اجرا کرده و نتیجه را نمایش میدهد، و سپس منتظر وارد کردن 3 ورودی بعدی میماند و نتایج آنها را نیز محاسبه و نمایش میدهد و همین طور تا آخر ادامه میدهد.
این برنامه کار خود را به درستی انجام میدهد تا این که عملیات تقسیم بر صفر پیش بیاید (مثلاً 25/0). در این ورودی، برنامه یک خطای زمان اجرا/استثنا صادر میکند، چون نمیتواند نتیجه را تحلیل کند و بیدرنگ خاتمه مییابد. شما باید برنامه را از نو آغاز کنید و مجدداً مقادیر را وارد نمایید تا چنین ورودی پیش بیاید. این فقط یک برنامه ماشین حساب ساده است که راهاندازی مجدد آن چند ثانیه طول میکشد، اما نرمافزاری که راهاندازی مجدد آن دقایق یا ساعتها طول میکشد چطور؟ گاهی اوقات نیز کلاً امکان راهاندازی مجدد وجود ندارد و این وضعیت نامناسبی ایجاد میکند.
آیا راهی برای جلوگیری از وقوع استثنا وجود دارد؟ نه، ما نمیتوانیم از وقوع استثناها جلوگیری کنیم، اما میتوانیم آنها را طوری مدیریت کنیم که موجب خاتمه یافتن برنامه نشوند.
منظور از مدیریت استثنا چیست؟ معنی مدیریت استثنا این است که وقتی اتفاق میافتد نگذاریم برنامه را پایان دهد و برنامه بتواند به اجرای خود ادامه دهد.
استثنا چگونه مدیریت میشود؟ در بخشهای بعدی این مقاله به بررسی همین موضوع خواهیم پرداخت.
هر آنچه تاکنون مطرح کردیم در مورد همه زبانهای برنامهنویسی که از استثنا و مدیریت آنها پشتیبانی میکنند، قابل تعمیم است. اینک نوبت آن رسیده است که بحث را به یک زبان خاص یعنی پایتون محدود کنیم. از این بخش به بعد همه مواردی که مطرح میشوند مختص زبان برنامهنویسی پایتون هستند مگر این که صراحتاً چیز دیگری قید شده باشد.
استثناها در پایتون
اینک به بررسی روش مدیریت استثناها در پایتون میپردازیم.
مدیریت استثناها
برای مدیریت استثناها در پایتون چند روش وجود دارد که در ادامه هر یک از آنها را به تفصیل مورد بررسی قرار خواهیم داد.
بلوک try-except ابتدایی
استثناها از طریق یک گزاره try مدیریت میشوند که ساختار مقدماتی آن به صورت زیر است:
کدی که مشکوک به ایجاد استثنا است زیر بند try یک گزاره try قرار میگیرد. کدی که باید در زمان بروز استثنا برای مدیریت آن اجرا شود نیز زیر بند except قرار میگیرد. به مثال زیر توجه کنید:
خروجی برای ورودی متفاوت:
>>> divide(50، 2) Result = 25 >>> divide(50، 0) Divisor is zero; Division is impossible
گزاره try به صورت زیر عمل میکند:
بندهای چندگانه except
این امکان هست که یک کد بیش از یک نوع استثنا ایجاد کند. مثلاً استثناها ممکن است از انواع ValueError ،AttributeError ،KeyError و غیره باشند. اینها مواردی از استثناهای داخلی هستند یعنی در خود پایتون موجود هستند. برای مشاهده لیست کامل آنها به این لینک (+) مراجعه کنید. شما میتوانید استثناها را خودتان نیز تولید و صادر کنید! در ادامه در این مورد بیشتر توضیح خواهیم داد.
اما اینک سؤال این است که چگونه میتوان استثناهای چندگانه (هم داخلی و هم سفارشی) که از کد موجود در بلوک try ناشی میشوند را مدیریت کرد؟ آیا پایتون پشتیانی خاصی از این وضعیت دارد؟ بله چنین است. بدین منظور باید از بندهای چندگانه except استفاده کنیم. به مثال زیر توجه کنید:
>>> int_value = int(a)
این گزاره ممکن است موجب بروز ValueError یا TypeError شود یا کلاً هیچ نوع استثنایی ایجاد نکند و همه اینها به نوع و مقدار متغیر a بستگی دارد. فرض کنید a= 3.2 یا ‘a = ‘1200 باشد در این صورت هیچ استثنایی تولید نمیشود؛ اما اگر ‘a=’12k باشد، در این صورت ValueError رخ میدهد. همچنین اگر [a= [1، 2 باشد در این صورت استثنای TypeError بروز مییابد.
روش مدیریت هر دوی آنها به صورت زیر است:
کد فوق صرفاً نردبانی از بندهای except است و استثناهایی دارد که قرار است مدیریت شوند. نکتهای که باید توجه داشت این است که ترتیب مدیریت باید صحیح باشد.
Exception در بند except به مدیریت استثناهایی از یک نوع یا مشتق از آن میپردازد. اما معکوس آن صحیح نیست یعنی Exception در بند except به مدیریت خطای پایه از نوعی که مشتق شده نمیپردازد. برای نمونه کد زیر به ترتیب مقادیر B ،C و D را نمایش میدهد:
توجه کنید که اگر بندهای except معکوس بودند (یعنی except به نام B اول بود، موارد نمایش یافته به صورت B ،B ،B بودند و نخستین بند except منطبق تحریک میشد. برای بصریسازی بهتر به تصویر زیر توجه کنید:
در این تصویر در سمت راست نوعی استثنا رخ داده است، سمت چپ مدیران استثنا هستند که D از C مشتق میشود و C نیز از B مشتق میشود.
استثناهای چندگانه در یک بند except منفرد
یک حالت کوتاهتر (البته نه همیشه) برای ساختار فوق نیز وجود دارد. ساختار کلی آن به صورت زیر است:
و مثالی از آن به صورت زیر است:
یعنی همه استثناهایی که قصد داشتیم مدیریت کنیم در یک چندتایی ترکیب میکنیم. استثناهایی که در این چندتاییها ستاند با ترتیب ظهورشان در چندتایی مطابقت دارند. قاعده بخش قبلی در این بخش نیز صدق میکند. میتوان هر دو این رویکردها را با هم ترکیب نیز کرد یعنی یک نردبان از بندهای except داشت که هر یک بیش از یک استثنا (در چندتایی) را مدیریت میکنند.
در نهایت سؤال این است که تفاوت بین دو رویکرد فوق چیست و هر کدام در چه موقعیتی بهتر هستند؟
تفاوت دو رویکرد فوق در شیوه پاسخدهی در زمان مدیریت استثناها است.
- اگر میخواهید یک قطعه کد را برای همه استثناهای مدیریتشده اجرا کنید، در این صورت از رویکرد دوم استفاده کنید. این رویکرد از تکرار قطعه کد در بندهای except چندگانه جلوگیری میکند.
- اگر میخواهید بسته به نوع استثناهایی که مدیریت میکنید، قطعه کدهای متفاوتی داشته باشید، در این صورت از رویکرد اول استفاده کنید. البته اجرای این کار با استفاده از رویکرد دوم نیز میسر است و مثالی از روش اجرای آن به صورت زیر است:
اما بهتر است که از رویکرد اول برای چنین حالتهایی استفاده کنید، زیرا درک آن آسانتر است و از پشتیبانی ارائه شده از سوی خود زبان به جای یک راهحل مانند فوق بهره میگیرد.
تعیین نام مستعار
به خط زیر در کد بخش قبل توجه کنید:
except (exception_1، exception_2،..) as e:
این استثنایی است (هستند) که یک نام برای آن تعیین شده است. این کار از نظر فنی «aliasing» یا تعیین نام مستعار نامیده میشود.
در زمان تعیین نام مستعار، میتوانیم با استفاده از یک نام رایج به استثنا (ها) دسترسی داشته باشیم. این حالت در زمانی مفید خواهد بود که بخواهیم از خصوصیتهای استثنایی که مدیریت میشود بهره بگیریم. تعیین نام مستعار از طریق کلیدواژه as صورت میگیرد. ساختار آن به صورت زیر است:
در کد فوق <alias> را باید با نام مستعار مورد نظر خود جایگزین کنید. به مثال زیر توجه کنید:
خروجی:
('Invalid name')شما میتوانید از هر عنوانی برای نام مستعار استفاده کنید. بدیهی است که امکان استفاده از کلیدواژههای داخلی میسر نیست. به طور معمول از e استفاده میشود.
نکته: اگر میخواهد برای یک استثنای منفرد نام مستعار تعیین کنید در این صورت استفاده از پرانتزهای پیرامونی اختیاری است. اما در صورتی که مانند مثال فوق از استثناهای چندگانه استفاده میکنید، پرانتزها الزامی هستند.
بند else
برخی اوقات با حالتی مواجه میشویم که میخواهیم یک قطعه کد را تنها و تنها در صورتی اجرا کنیم که کد زیر بند try هیچ استثنایی ایجاد نکرده باشد. به مثال زیر توجه کنید:
مسئله: تابعی به نام divide بنویسید که a را بر b تقسیم کند (به عنوان پارامتر ارسال میشود) و موارد زیر را در خروجی نمایش دهد:
- اگر b برابر با صفر بود، در این صورت عبارت «امکان تقسیم بر صفر وجود ندارد.» را نمایش دهد.
- در غیر این صورت <Output = <quotient را نمایش دهد که quotient حاصل تقسیم است.
راهحل
خروجی
>>> divide(20، 10) Output = 2.0 >>> divide(20، 0) Cannot divide by zero
بند else اختیاری است و در صورت حضور، همواره از بند except تبعیت میکند. کد زیر بند else تنها زمانی اجرا خواهد شد که بند زیر try هیچ استثنایی صادر نکند. اگر استثنایی در بلوک try صادر شود، در این صورت بلوک else اجرا نخواهد شد بلکه بند except آن را مدیریت خواهد کرد.
بند Finally
گزاره try یک بند دیگر به نام Finally نیز دارد که اساساً برای پاکسازی اقدامات استفاده میشود. این بند پس از همه بندهای دیگر میآید. بند Finally در هر حالتی صرف نظر از این که استثنایی رخ داده یا نداده باشد اجرا خواهد شد. بند Finally لزوماً نیازی به وجود بندهای else یا except ندارد. به مثال زیر توجه کنید:
خروجی
>>> divide(2، 1)
Output = 2.0
Executing finally clause
>>> divide(2، 0)
Cannot divide by zero
Executing finally clause
>>> divide("2"، "1")
Executing finally clause
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
File "<stdin>"، line 3، in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'بند Finally همواره پیش از ترک گزاره try اجرا خواهد شد و مهم نیست که استثنایی رخ داده است یا نه. زمانی که یک استثنا در بند try رخ دهد و از سوی بند except مدیریت نشود (و یا در بند except یا else رخ دهد) در واقع مجدداً پس از اجرای بند Finally رخ داده است (فراخوانی سوم به تابع divide را در بخش قبل ببینید). بند Finally در مسیر خروجی زمانی که از یک گزاره break ،continue یا return استفاده شده باشد همچنان اجرا خواهد شد.
کاربردهای عملی بند Finally برای آزادسازی منابع مانند فایلها یا اتصالهای پایگاه داده و مواردی از این دست است. فرق بین داشتن کدی داخل بند Finally و نوشتن آن خارج از این بند و پس از گزاره try چیست؟ به بیان ساده فرق بین دو حالت زیر چیست؟
تفاوت دو کد فوق تنها زمانی مشخص میشود که استثنایی (در هر یک از بندهای try ،except یا else) رخ دهد و مدیریت نشده باشد. در این حالت:
- کد اول عبارت ‘Leaving the function’ را نمایش داده و استثنا را مجدداً صادر میکند.
- کد دوم عبارت ‘Leaving the function’ را نمایش نمیدهد و استثنا به کد بیرونی ارسال میشود.
برای جمعبندی باید اشاره کنیم که فرق بین دو سناریوی فوق این است که کد موجود در بند Finally حتی در صورتی که استثنایی رخ داده باشد (و مدیریت نشده باشد) اجرا میشود؛ اما کدی که در ادامه گزاره try میآید چنین حالتی ندارد.
ایجاد استثناها
در این بخش با روش ایجاد دستی استثناها و همچنین ایجاد استثناهای سفارشی آشنا میشویم.
ایجاد استثناهای داخلی
پایتون روشی برای ایجاد دستی یک استثنا ارائه کرده است. این کار از طریق کلیدواژه raise صورت میپذیرد.
>>> raise AssertionError('Asserted statement is incorrect')
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
raise AssertionError('Asserted statement is incorrect')
AssertionError: Asserted statement is incorrectکلیدواژه raise تنها یک آرگومان میگیرد که یا یک کلاس استثنا است (که از کلاس Exception مشتق میشود) و یا یک وهله از استثنا است. در کد مثال فوق، آرگومان یک وهله از استثنا با پیام رشتهای است. این پیام رشتهای (اختیاری) زمانی که ارسال شود، خطا را توصیف میکند.
اگر آرگومان یک کلاس استثنا باشد، در این صورت سازنده آن بدون هیچ آرگومانی به صورت زیر فراخوانی میشود:
>>> raise AssertionError Traceback (most recent call last) File "<stdin>"، line 1، in <module> raise AssertionError AssertionError
تعریف و ایجاد استثناهای سفارشی
پیش از این که به معرفی روش ایجاد استثناهای سفارشی بپردازیم ابتدا به این سؤال پاسخ میدهیم که اساساً این کار چه ضرورتی دارد. موارد خاصی وجود دارند که در آنها استثناهای داخلی نمیتوانند برای توصیف معنیدار خطای رخ داده، مورد استفاده قرار گیرند.
برای نمونه فرض کنید تابع سادهای داریم که تعداد واحدهای (برق) مصرفی بین دو خوانش مجزا را محاسبه میکند. اگر هر کدام از خوانش ها منفی باشند، تابع استثنای ValueError ایجاد میکند و فرض میکند که واحدهای مصرفی محاسبهشده منفی هستند. در این صورت میخواهیم یک استثنا ایجاد شود (برای مثال NegativeConsumptionError). اما این استثنا جزء استثناهای داخلی پایتون نیست. البته ما همچنان میتوانیم از استثنای داخلی ValueError برای مدیریت این مورد نیز استفاده کنیم. اگر بخواهیم از ValueError برای این خطا استفاده کنیم، در این صورت هیچ روشی برای کد فراخوانی کننده electricity_consumption جهت ایجاد تمایز بین ‘Negative reading’ and ‘Negative consumption’ وجود نخواهد داشت.
با استفاده از استثنای داخلی ValueError
با استفاده از استثنای سفارشی
روش تعریف استثنای سفارشی چگونه است؟
برای تعریف یک استثنای سفارشی باید یک کلاس تعریف کنید که از کلاس Exception مشتق میشود یا یک کلاس فرعی از آن بسازید. در ادامه یک مثال ساده را ملاحظه میکنید:
یک رویه رایج، ایجاد کلاس مبنا برای استثناهای تعریف شده از سوی ماژول و ایجاد کلاس فرعی از آن برای ایجاد کلاسهای استثنای خاص برای شرایط خطای متفاوت است. زمانی که استثنای مبنا را برای یک ماژول تعریف کردیم و سپس از آن کلاس فرعی برای تعریف استثناهای خاص ساختیم، میتوانیم به سادگی همه استثناها را که از آن ناشی میشوند با استفاده از استثنای مبنا مدیریت کنیم.
همچنین میتوانید خصوصیتهایی روی استثناهای سفارشی تعیین کنید که با استفاده از دستگیرههایی قابل بازیابی باشند. به مثال زیر توجه کنید:
خروجی
2 # 3 Unknown operator
Logger.exception
ما در همه کدهای عملی خود از لاگرها استفاده میکنیم، چون لاگرها کار دیباگ گردن را تسهیل میکنند. لاگرها در پایتون، پشتیبانی خاصی برای استثناها دارند. از این رو در ادامه مقداری در مورد آنها توضیح میدهیم.
متد مربوطه ()logger.exception نام دارد. به کد زیر توجه کنید:
خروجی کد فوق یک رد پشته کامل از استثنا است که مدیریت شده است و صرفاً یک توصیف متنی از استثنا محسوب نمیشود. مزیتهای آن به شرح زیر هستند:
دیگر نیاز نداریم از نامهای مستعار برای استثناها استفاده کنیم، مگر اینکه آن را درون بند except نیاز داشته باشیم، چون استثنای رخ داده به صورت ضمنی در ()logger.exception قرار دارد.
علاوه بر ردگیری پشته، ()logger.exception یک پیام روی رد پشته نیز نمایش میدهد. بدین ترتیب خروجی لاگ قطعه کد به صورت زیر خواهد بود:
ERROR: Exception while performing division — handled Traceback (most recent call last): File "<stdin>"، line 1، in <module> raise ZeroDivisionError ZeroDivisionError
نکته 1: ()logger.exception پیامها را با سطح ERROR لاگ میکند.
نکته 2: ()logger.exception باید تنها از یک دستگیره استثنا فراخوانی شود.
بدین ترتیب به پایان این مقاله میرسیم.
منبع" فرادرس