طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیانتخاب رویکرد مناسب در برنامه نویسی ناهمگام جاوا اسکریپت — راهنمای جامع
در آخرین بخش از این سری مقالات برنامه نویسی ناهمگام جاوا اسکریپت بررسی مختصری در خصوص تکنیکها و قابلیتهای مختلف کدنویسی داریم که در طی این دوره آموزش داده شده است. همچنین بررسی میکنیم که باید از کدام رویکردها استفاده کنیم و برخی توصیهها و یادآوریها در مورد تلههای رایج ارائه شدهاند.
پیشنیاز مطالعه این نوشته داشتن سواد مقدماتی رایانه و درک معقولی از مبانی جاوا اسکریپت است. هدف از این مقاله نیز آشنا ساختن مخاطب با روش تشخیص زمان مناسب استفاده از تکنیکهای مختلف برنامهنویسی ناهمگام است. برای مطالعه بخش قبلی این سری مقالات آموزشی به لینک زیر رجوع کنید:
Callback-های ناهمگام
Callback-ها عموماً در API-های به سبک قدیم مشاهده میشوند که در آنها تابعی به عنوان پارامتر به تابع دیگر ارسال میشود و زمانی که یک عملیات ناهمگام تکمیل شد فراخوانی میشود و callback نیز به نوبه خود کاری روی نتیجه اجرا میکند. callback-ها تا قبل از promise-ها استفاده میشدند و کارایی و انعطاف مورد نیاز را نداشتند. بنابراین تنها در موارد ضرورت باید از آنها استفاده کرد.
استفاده از Callback در موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله (callback-های بازگشتی) | بله (callback-های تو در تو) | خیر |
نمونه کد
در ادامه مثالی را مشاهده میکنید که یک منبع را از طریق API به نام XMLHttpRequest بارگذاری میکند:
تلهها
- Callback-های تو در تو میتوانند پیچیده باشند و خوانش دشواری پیدا کنند که به نام جهنم callback مشهور است.
- Callback-های ناموفق باید به ازای هر سطح از تودرتو سازی یک بار فراخوانی شوند، در حالی که با استفاده از promise-ها میتوان از یک بلوک ()catch. منفرد برای مدیریت خطاها در کل زنجیره استفاده کرد.
- Callback-های ناهمگام چندان مناسب نیستند.
- Callback-های promise همواره در ترتیب صحیحی که در صف رویداد قرار گرفتهاند فراخوانی میشوند، در حالی که Callback-های ناهمگام چنین نیستند.
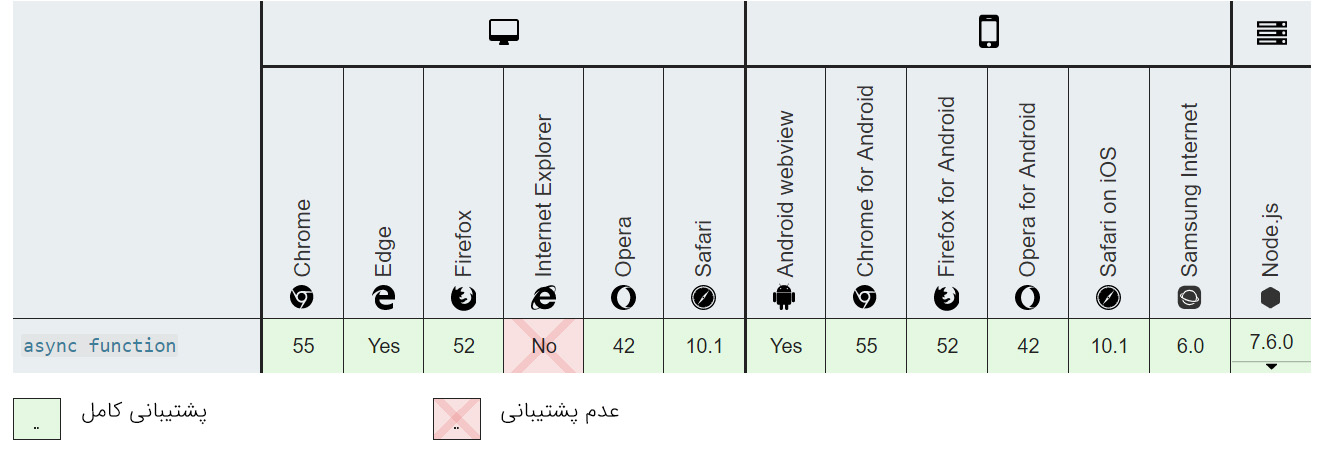
سازگاری مرورگر
مرورگرها پشتیبانی نسبتاً خوبی از Callback دارند، گرچه پشتیبانی دقیق از Callback-ها در API-ها به هر API خاص بستگی دارد. برای اطلاع از پشتیبانی هر API باید به مستندات آن مراجعه کنید.
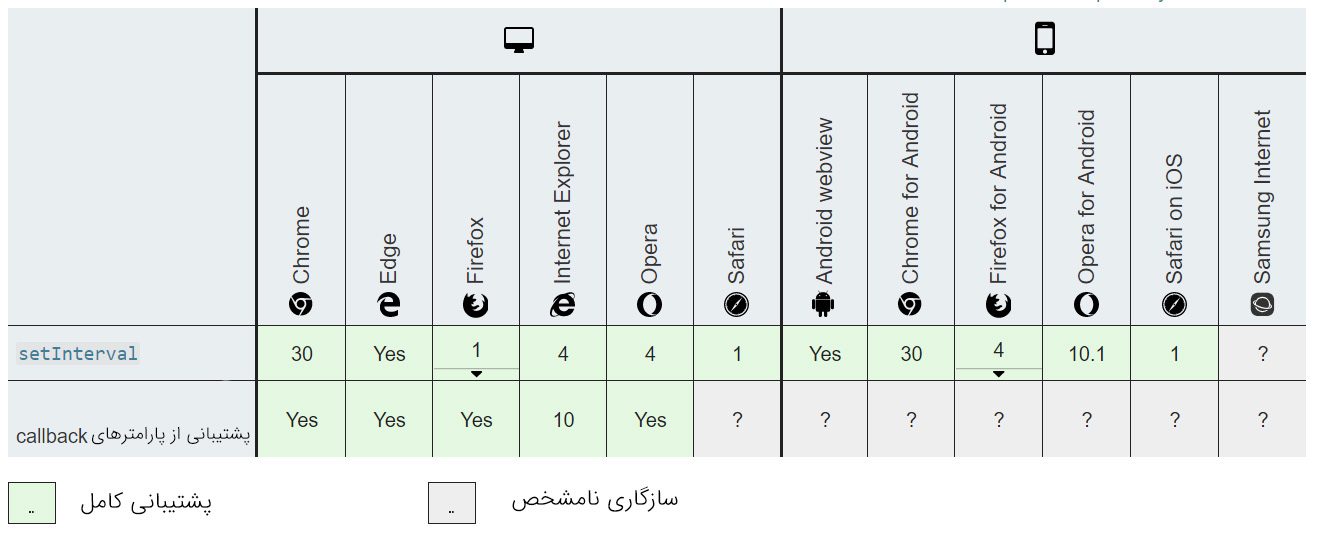
()setTimeout
()setTimeout متدی است که امکان اجرای یک تابع پس از مقدار زمان دلخواه را فراهم میسازد.
()setTimeout برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| بله | بله (timeout-های بازگشتی) | بله (timeout-های تو در تو) | خیر |
نمونه کد
در کد زیر مرورگر به مدت دو ثانیه منتظر خواهد ماند تا تابع ناهمگام اجرا شود و سپس پیام هشدار را نمایش میدهد:
تلهها
با کدی مانند زیر میتوان از فراخوانیهای ()setTimeout بازگشتی برای اجرای مکرر یک تابع به روشی مشابه ()setInterval استفاده کرد:
البته تفاوتی بین ()setTimeout و ()setInterval بازگشتی وجود دارد:
- ()setTimeout بازگشتی تضمین میکند که دستکم مقدار زمان تعیینشده (در این مثال 100 میلیثانیه) بین دو اجرای تابع زمان وجود خواهد داشت، یعنی کد اجرا خواهد شد و سپس تا قبل از اجرای مجدد، 100 میلیثانیه صبر خواهد کرد. بازه زمانی مورد نظر صرف نظر از مدت زمانی که کد برای اجرا صبر میکند همان خواهد بود.
- در زمان استفاده از ()setInterval، بازه مورد نظر که انتخاب میکنیم شامل زمانی خواهد بود که طول میکشد تا کد منتظر اجرا بماند. فرض کنید اجرای کد 40 میلیثانیه طول بکشد، در این صورت بازه انتظار مورد نظر در نهایت 60 میلیثانیه خواهد بود.
زمانی که انتظار میرود کد، زمان اجرایی طولانیتر از بازهی تعیین شده داشته باشد، بهتر است از ()setTimeout بازگشتی استفاده کنیم. بدین ترتیب بازه زمانی ثابتی بین اجراها لحاظ میشود و مهم نیست که اجرای کد جه قدر طول بکشد. بدین ترتیب از بروز خطا اجتناب میشود.
سازگاری مرورگر
()setInterval
()setInterval متدی است که امکان اجرای مکرر تابع را با بازه انتظار تنظیم شده بین هر اجرا فراهم میسازد. ()setInterval به اندازه ()requestAnimationFrame کارآمد نیست، اما امکان انتخاب نرخ فریم. نرخ اجرا را میدهد.
برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله | نه (مگر این که یکسان باشد) | خیر |
نمونه کد
تابع زیر یک شیء ()Date ایجاد میکند، رشته زمانی را با استفاده از ()toLocaleTimeString از آن استخراج میکند و سپس آن را در رابط کاربری نمایش میدهد. سپس آن را هر ثانیه یک بار با استفاده از ()setInterval اجرا میکنیم و جلوهای شبیه به یک ساعت دیجیتالی ایجاد میکنیم که هر ثانیه یک بار بهروزرسانی میشود:
تلهها
نرخ فریم برای سیستمی که انیمیشن روی آن اجرا میشود، بهینهسازی نشده و ممکن است ناکارآمد باشد. به جز در مواردی که نیاز به نرخ فریم پایینتر (آهستهتر) داشته باشیم، عموماً بهتر است از ()requestAnimationFrame استفاده کنیم.
سازگاری مرورگر
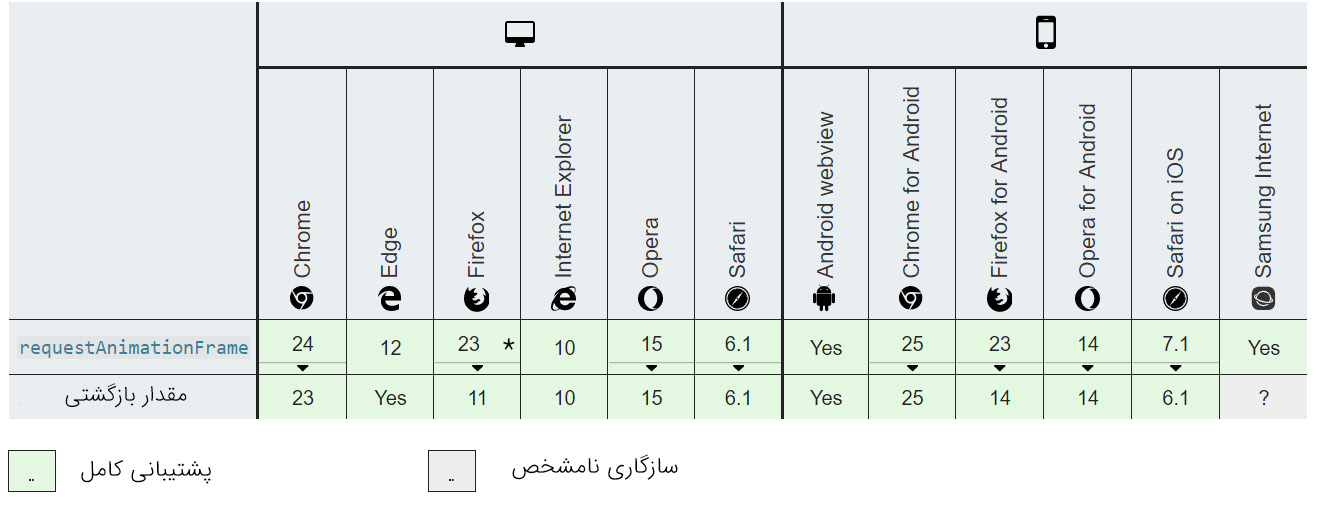
()requestAnimationFrame
()requestAnimationFrame متدی است که امکان اجرای مکرر تابع را به روشی کارآمد فراهم میسازد. بهترین نکته در مورد این متد آن است که بهترین نرخ فریم ممکن را برای مرورگر/سیستم جاری به دست میدهد. شما باید در صورت امکان از این متد به جای ()setInterval() / setTimeout بازگشتی استفاده کنید، مگر این که به نرخ فریم خاصی نیاز داشته باشید.
برای موارد زیر مناسب است/ نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | بله | خیر (مگر این که یکسان باشد) | خیر |
نمونه کد
در مثال زیر یک اسپینر ساده انیمیت شده را میبینید:
تلهها
هنگام استفاده از متد ()requestAnimationFrame امکان انتخاب یک نرخ فریم خاص وجود ندارد. اگر نیاز داشته باشید که انیمیشن با نرخ فریم کُندتری کار کند، باید از ()setInterval یا ()setTimeout بازگشتی استفاده کند.
سازگاری مرورگر
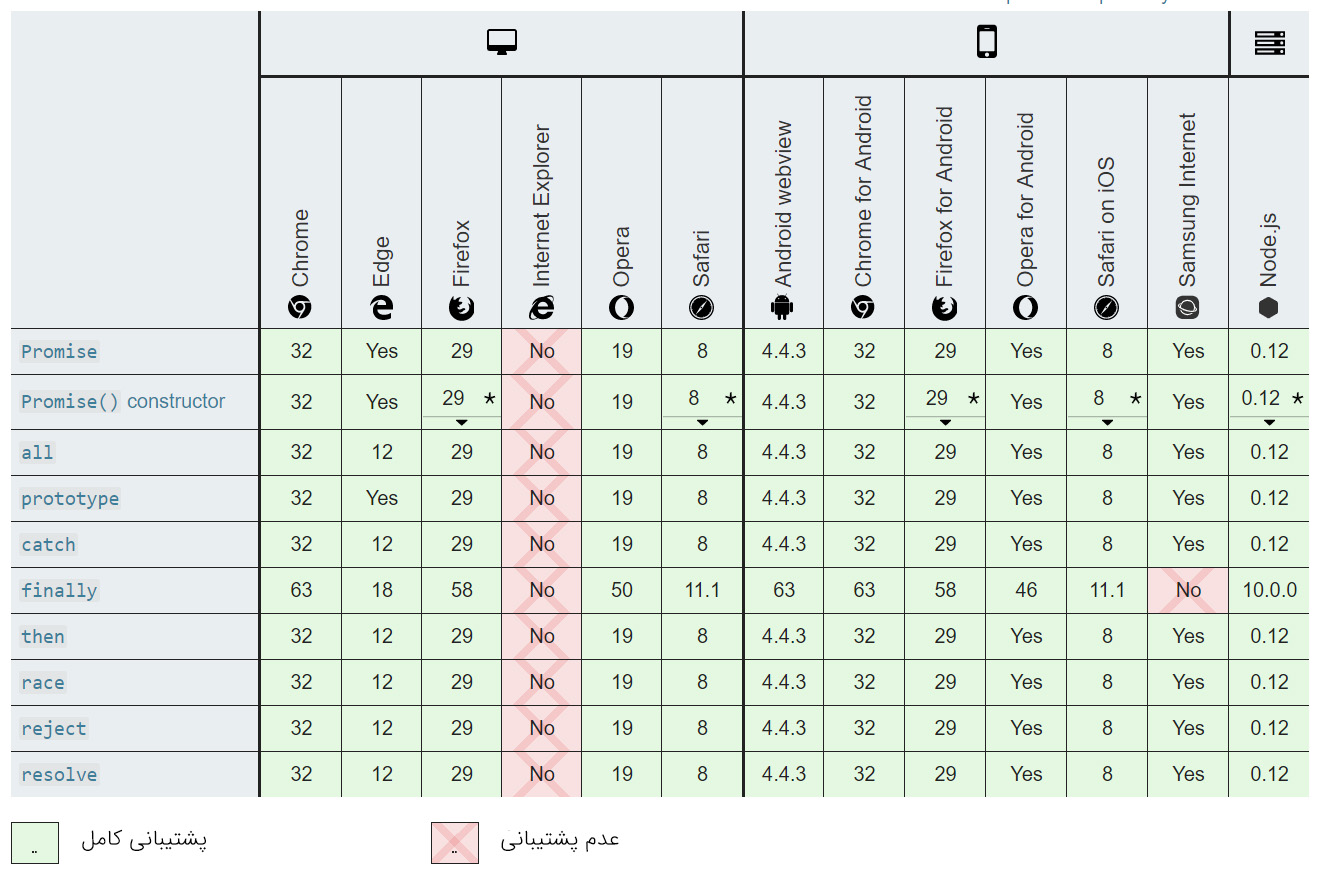
Promise-ها
Promise-ها قابلیتی از جاوا اسکریپت هستند که امکان اجرای عملیات ناهمگام را میدهند و تا زمانی که تابع به طور کامل اجرا نشده است منتظر میمانند تا بر اساس نتیجه آن عملیات دیگر را اجرا کنند. Promise-ها ستون فقرات جاوا اسکریپت مدرن ناهمگام محسوب میشوند.
برای موارد زیر مناسب است / نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | بله | به بخش ()Promise.all در ادامه مراجعه کنید. |
نمونه کد
کد زیر یک تصویر را از سرور واکشی کرده و آن را درون یک عنصر <img> نمایش میدهد:
تلهها
زنجیرههای Promise میتوانند پیچیده باشند و تجزیه آنها دشوار باشد. اگر چند Promise را به صورت تو در تو تعریف کنید، ممکن است در نهایت با همان مشکل جهنم callback مواجه شوید. برای مثال به کد زیر توجه کنید:
بهتر است از قدرت زنجیرهسازی Promise-ها برای ایجاد ساختار مسطحتر و با تجزیه آسانتر استفاده کنید:
یا حتی:
سازگاری مرورگر
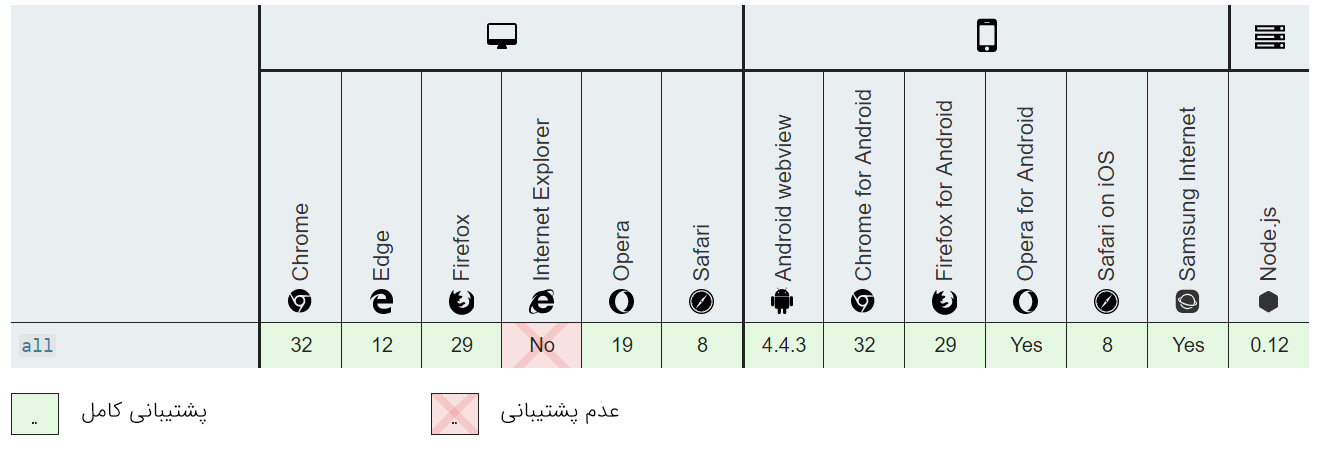
()Promise.all
یکی از قابلیتهای جاوا اسکریپت این است که میتوان منتظر چند Promise ماند تا این Promise-ها به پایان برسند. و یک عملیات دیگر بر مبنای نتایج این Promise-ها اجرا کرد.
برای موارد زیر مناسب است/نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | خیر | بله |
نمونه کد
در مثال زیر چند منبع از سرور واکشی میشوند و از ()Promise.all استفاده میشود تا زمانی که همه منابع آماده شدند منتظر بماند و سپس همه آنها را نمایش میدهد:
تلهها
اگر یک ()Promise.all رد شود، در این صورت یک یا چند مورد از Promise-هایی که درون پارامترهای آرایه آن وارد شده باید رد شوند، در غیر این صورت Promise-ها کلاً بازگشت نمییابند. بدین ترتیب باید آنها را یک به یک بررسی کنید تا ببینید کدام یک بازگشت یافتهاند.
سازگاری مرورگر
Async/await
Async/await یک ساختار نمادین (Syntactic sugar) است که بر مبنای promise-ها ساخته شده و امکان اجرای عملیات ناهمگام را با استفاده از ساختاری فراهم میکند که بیشتر شبیه نوشتن کد callback همگام است.
برای موارد زیر مناسب است/ نیست:
| عملیات با تأخیر منفرد | عملیات مکرر | عملیات ترتیبی چندگانه | عملیات همزمان چندگانه |
|---|---|---|---|
| خیر | خیر | بله | بله (در ترکیب با ()Promise.all) |
نمونه کد
مثال زیر یک بازنویسی از مثال Promise سادهای است که قبلاً دیدیم و تصاویر را واکشی کرده و نمایش میداد و این بار با استفاده Async/await نوشته شده است:
تلهها
- از عملگر await نمیتوان درون یک تابع غیر ناهمگام یا در سطح بالای ساختار کد استفاده کرد. این موضوع در برخی موارد موجب نیاز به ایجاد پوشش تابعی اضافی میشود که در برخی شرایط ممکن است دشوار باشد، اما در اغلب موارد ارزشش را دارد.
- پشتیبانی مرورگر برای async/await به اندازه Promise-ها مناسب است. اگر میخواهید از async/await استفاده کنید، اما در مورد پشتیبانی مرورگرهای قدیمی دغدغه دارید، میتوانید از کتابخانه BabelJS استفاده کنید. این کتابخانه امکان نوشتن اپلیکیشنها را با استفاده از جدیدترین کدهای جاوا اسکریپت میدهد و سپس تغییرات مورد نظر را بسته به نیاز در مورد مرورگرهای کاربر اعمال میکند.
سازگاری مرورگر
بدین ترتیب به پایان این مقاله میرسیم.
منبع: فرادرس
موارد استثنا در پایتون — راهنمای کاربردی
در هر زبان برنامهنویسی شاهد حضور دو نوع خطا هستیم که یکی خطاهای کامپایل و دیگری خطاهای زمان اجرا است. خطاهای کامپایل در زمان کامپایل کردن کد منبع و در نتیجهی ساختار یا معناشناسی نادرست رخ میدهند. در این مقاله به بررسی موارد استثنا در پایتون می پردازیم. به مثال زیر توجه کنید:
در کد فوق پرانتز انتهایی فراموش شده است و در نتیجه خطای ساختاری رخ داده که در زمان تلاش برای اجرای کد بروز مییابد. این خطا در زمان کامپایل کردن کد ظاهر میشود و از این رو خطای کامپایل نام دارد (به طور خاص خطای ساختاری یا نحوی نامیده میشود) برای اصلاح این خطا در خط فوق، کافی است یک پرانتز انتهایی در آخر خط قرار دهیم، یعنی باید ساختار/معناشناسی کد را به صورت زیر اصلاح کنیم:
از سوی دیگر خطاهای زمان اجرا زمانی رخ میدهند که برنامه در حال اجرا است. این خطاها در نتیجه زمینه/ ورودی غیر معمول در یک قطعه کد اجرایی حاصل میشوند. یعنی یک برنامه که از نظر ساختاری و معناشناختی صحیح است بسته به زمینه اجرایی و ورودی برنامه ممکن است خطا داشته باشد یا نداشته باشد. به مثال زیر توجه کنید:
کد فوق از نظر ساختاری و معناشناختی صحیح است و هیچ خطایی تولید نمیکند. نتیجه پس از اجرای برنامه res=20 خواهد بود. اینک به کد زیر توجه کنید:
با این که کد از نظر ساختاری و معناشناختی صحیح است، اما در زمان اجرا خطایی صادر میکند. دلیل خطا تلاش برای تقسیم بر صفر است که تعریف نشده است. این نمونهای از خطای زمان اجرا به دلیل ورودی نامعمول است. این خطاهای زمان اجرا به نام «استثنا» (Exception) نیز شناخته میشوند.
نمونههایی از خطاهای زمان اجرا که به دلیل زمینه یا چارچوب پدید میآیند، اجرا کردن یک برنامه (که از کارکردهای خاص سیستم عامل استفاده میکند) روی یک سیستم ناسازگار است.
چرا خطاهای زمان اجرا بد هستند؟
دلیل بد بودن خطاهای زمان اجرا این است که در زمان وقوع، موجب خاتمه یافتن برنامه میشوند.
موقعیتی را تصور کنید که یک برنامه ماشین حساب ساختهایم که عملیات ابتدایی حساب (+، -، * و /) را روی دو عدد اجرا میکند. این برنامه از کاربر دو عدد میخواهد و عملیات مورد نظر را نیز میپرسد تا روی اعداد اجرا کند. فرض کنید برنامه در حلقه اجرا میشود، یعنی زمانی که 3 ورودی را درخواست کرد (دو عملوند و یک عملگر) محاسبه را اجرا کرده و نتیجه را نمایش میدهد، و سپس منتظر وارد کردن 3 ورودی بعدی میماند و نتایج آنها را نیز محاسبه و نمایش میدهد و همین طور تا آخر ادامه میدهد.
این برنامه کار خود را به درستی انجام میدهد تا این که عملیات تقسیم بر صفر پیش بیاید (مثلاً 25/0). در این ورودی، برنامه یک خطای زمان اجرا/استثنا صادر میکند، چون نمیتواند نتیجه را تحلیل کند و بیدرنگ خاتمه مییابد. شما باید برنامه را از نو آغاز کنید و مجدداً مقادیر را وارد نمایید تا چنین ورودی پیش بیاید. این فقط یک برنامه ماشین حساب ساده است که راهاندازی مجدد آن چند ثانیه طول میکشد، اما نرمافزاری که راهاندازی مجدد آن دقایق یا ساعتها طول میکشد چطور؟ گاهی اوقات نیز کلاً امکان راهاندازی مجدد وجود ندارد و این وضعیت نامناسبی ایجاد میکند.
آیا راهی برای جلوگیری از وقوع استثنا وجود دارد؟ نه، ما نمیتوانیم از وقوع استثناها جلوگیری کنیم، اما میتوانیم آنها را طوری مدیریت کنیم که موجب خاتمه یافتن برنامه نشوند.
منظور از مدیریت استثنا چیست؟ معنی مدیریت استثنا این است که وقتی اتفاق میافتد نگذاریم برنامه را پایان دهد و برنامه بتواند به اجرای خود ادامه دهد.
استثنا چگونه مدیریت میشود؟ در بخشهای بعدی این مقاله به بررسی همین موضوع خواهیم پرداخت.
هر آنچه تاکنون مطرح کردیم در مورد همه زبانهای برنامهنویسی که از استثنا و مدیریت آنها پشتیبانی میکنند، قابل تعمیم است. اینک نوبت آن رسیده است که بحث را به یک زبان خاص یعنی پایتون محدود کنیم. از این بخش به بعد همه مواردی که مطرح میشوند مختص زبان برنامهنویسی پایتون هستند مگر این که صراحتاً چیز دیگری قید شده باشد.
استثناها در پایتون
اینک به بررسی روش مدیریت استثناها در پایتون میپردازیم.
مدیریت استثناها
برای مدیریت استثناها در پایتون چند روش وجود دارد که در ادامه هر یک از آنها را به تفصیل مورد بررسی قرار خواهیم داد.
بلوک try-except ابتدایی
استثناها از طریق یک گزاره try مدیریت میشوند که ساختار مقدماتی آن به صورت زیر است:
کدی که مشکوک به ایجاد استثنا است زیر بند try یک گزاره try قرار میگیرد. کدی که باید در زمان بروز استثنا برای مدیریت آن اجرا شود نیز زیر بند except قرار میگیرد. به مثال زیر توجه کنید:
خروجی برای ورودی متفاوت:
>>> divide(50، 2) Result = 25 >>> divide(50، 0) Divisor is zero; Division is impossible
گزاره try به صورت زیر عمل میکند:
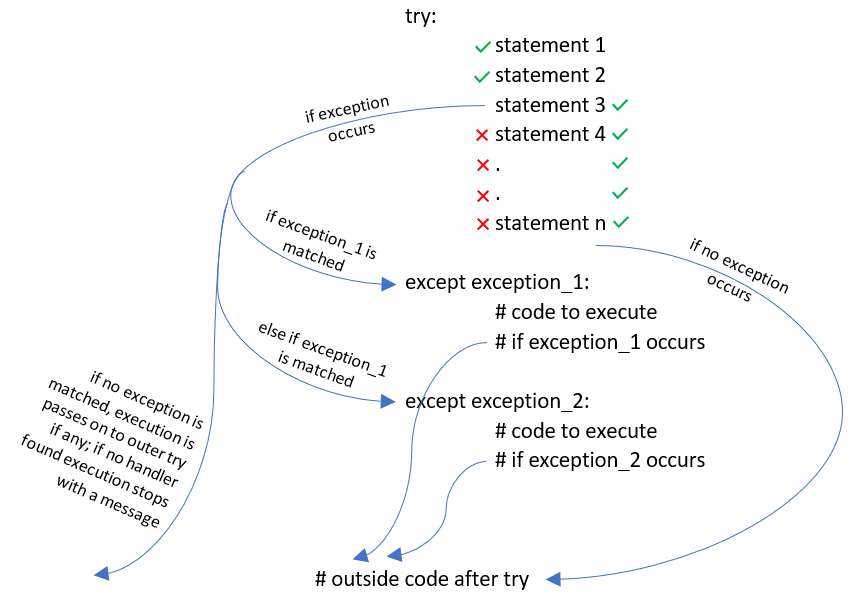
بندهای چندگانه except
این امکان هست که یک کد بیش از یک نوع استثنا ایجاد کند. مثلاً استثناها ممکن است از انواع ValueError ،AttributeError ،KeyError و غیره باشند. اینها مواردی از استثناهای داخلی هستند یعنی در خود پایتون موجود هستند. برای مشاهده لیست کامل آنها به این لینک (+) مراجعه کنید. شما میتوانید استثناها را خودتان نیز تولید و صادر کنید! در ادامه در این مورد بیشتر توضیح خواهیم داد.
اما اینک سؤال این است که چگونه میتوان استثناهای چندگانه (هم داخلی و هم سفارشی) که از کد موجود در بلوک try ناشی میشوند را مدیریت کرد؟ آیا پایتون پشتیانی خاصی از این وضعیت دارد؟ بله چنین است. بدین منظور باید از بندهای چندگانه except استفاده کنیم. به مثال زیر توجه کنید:
>>> int_value = int(a)
این گزاره ممکن است موجب بروز ValueError یا TypeError شود یا کلاً هیچ نوع استثنایی ایجاد نکند و همه اینها به نوع و مقدار متغیر a بستگی دارد. فرض کنید a= 3.2 یا ‘a = ‘1200 باشد در این صورت هیچ استثنایی تولید نمیشود؛ اما اگر ‘a=’12k باشد، در این صورت ValueError رخ میدهد. همچنین اگر [a= [1، 2 باشد در این صورت استثنای TypeError بروز مییابد.
روش مدیریت هر دوی آنها به صورت زیر است:
کد فوق صرفاً نردبانی از بندهای except است و استثناهایی دارد که قرار است مدیریت شوند. نکتهای که باید توجه داشت این است که ترتیب مدیریت باید صحیح باشد.
Exception در بند except به مدیریت استثناهایی از یک نوع یا مشتق از آن میپردازد. اما معکوس آن صحیح نیست یعنی Exception در بند except به مدیریت خطای پایه از نوعی که مشتق شده نمیپردازد. برای نمونه کد زیر به ترتیب مقادیر B ،C و D را نمایش میدهد:
توجه کنید که اگر بندهای except معکوس بودند (یعنی except به نام B اول بود، موارد نمایش یافته به صورت B ،B ،B بودند و نخستین بند except منطبق تحریک میشد. برای بصریسازی بهتر به تصویر زیر توجه کنید:
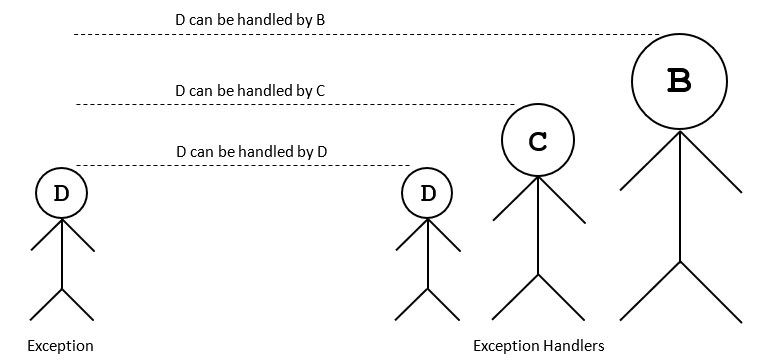
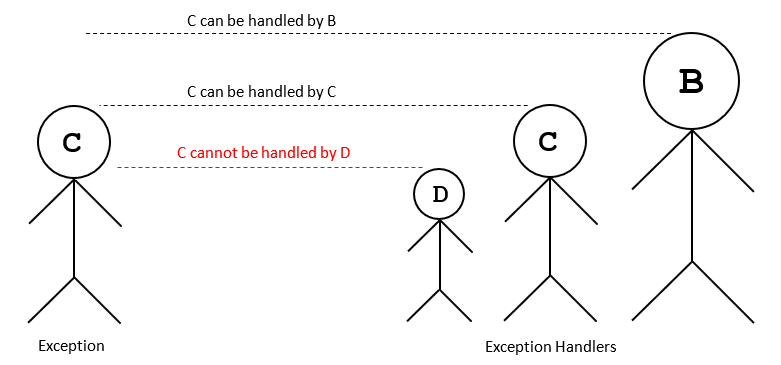
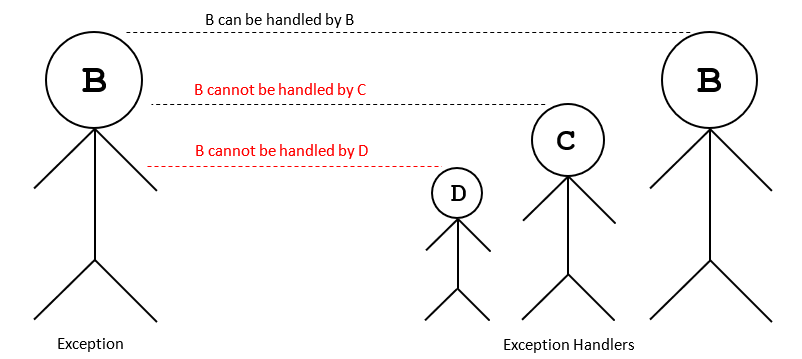
در این تصویر در سمت راست نوعی استثنا رخ داده است، سمت چپ مدیران استثنا هستند که D از C مشتق میشود و C نیز از B مشتق میشود.
استثناهای چندگانه در یک بند except منفرد
یک حالت کوتاهتر (البته نه همیشه) برای ساختار فوق نیز وجود دارد. ساختار کلی آن به صورت زیر است:
و مثالی از آن به صورت زیر است:
یعنی همه استثناهایی که قصد داشتیم مدیریت کنیم در یک چندتایی ترکیب میکنیم. استثناهایی که در این چندتاییها ستاند با ترتیب ظهورشان در چندتایی مطابقت دارند. قاعده بخش قبلی در این بخش نیز صدق میکند. میتوان هر دو این رویکردها را با هم ترکیب نیز کرد یعنی یک نردبان از بندهای except داشت که هر یک بیش از یک استثنا (در چندتایی) را مدیریت میکنند.
در نهایت سؤال این است که تفاوت بین دو رویکرد فوق چیست و هر کدام در چه موقعیتی بهتر هستند؟
تفاوت دو رویکرد فوق در شیوه پاسخدهی در زمان مدیریت استثناها است.
- اگر میخواهید یک قطعه کد را برای همه استثناهای مدیریتشده اجرا کنید، در این صورت از رویکرد دوم استفاده کنید. این رویکرد از تکرار قطعه کد در بندهای except چندگانه جلوگیری میکند.
- اگر میخواهید بسته به نوع استثناهایی که مدیریت میکنید، قطعه کدهای متفاوتی داشته باشید، در این صورت از رویکرد اول استفاده کنید. البته اجرای این کار با استفاده از رویکرد دوم نیز میسر است و مثالی از روش اجرای آن به صورت زیر است:
اما بهتر است که از رویکرد اول برای چنین حالتهایی استفاده کنید، زیرا درک آن آسانتر است و از پشتیبانی ارائه شده از سوی خود زبان به جای یک راهحل مانند فوق بهره میگیرد.
تعیین نام مستعار
به خط زیر در کد بخش قبل توجه کنید:
except (exception_1، exception_2،..) as e:
این استثنایی است (هستند) که یک نام برای آن تعیین شده است. این کار از نظر فنی «aliasing» یا تعیین نام مستعار نامیده میشود.
در زمان تعیین نام مستعار، میتوانیم با استفاده از یک نام رایج به استثنا (ها) دسترسی داشته باشیم. این حالت در زمانی مفید خواهد بود که بخواهیم از خصوصیتهای استثنایی که مدیریت میشود بهره بگیریم. تعیین نام مستعار از طریق کلیدواژه as صورت میگیرد. ساختار آن به صورت زیر است:
در کد فوق <alias> را باید با نام مستعار مورد نظر خود جایگزین کنید. به مثال زیر توجه کنید:
خروجی:
('Invalid name')شما میتوانید از هر عنوانی برای نام مستعار استفاده کنید. بدیهی است که امکان استفاده از کلیدواژههای داخلی میسر نیست. به طور معمول از e استفاده میشود.
نکته: اگر میخواهد برای یک استثنای منفرد نام مستعار تعیین کنید در این صورت استفاده از پرانتزهای پیرامونی اختیاری است. اما در صورتی که مانند مثال فوق از استثناهای چندگانه استفاده میکنید، پرانتزها الزامی هستند.
بند else
برخی اوقات با حالتی مواجه میشویم که میخواهیم یک قطعه کد را تنها و تنها در صورتی اجرا کنیم که کد زیر بند try هیچ استثنایی ایجاد نکرده باشد. به مثال زیر توجه کنید:
مسئله: تابعی به نام divide بنویسید که a را بر b تقسیم کند (به عنوان پارامتر ارسال میشود) و موارد زیر را در خروجی نمایش دهد:
- اگر b برابر با صفر بود، در این صورت عبارت «امکان تقسیم بر صفر وجود ندارد.» را نمایش دهد.
- در غیر این صورت <Output = <quotient را نمایش دهد که quotient حاصل تقسیم است.
راهحل
خروجی
>>> divide(20، 10) Output = 2.0 >>> divide(20، 0) Cannot divide by zero
بند else اختیاری است و در صورت حضور، همواره از بند except تبعیت میکند. کد زیر بند else تنها زمانی اجرا خواهد شد که بند زیر try هیچ استثنایی صادر نکند. اگر استثنایی در بلوک try صادر شود، در این صورت بلوک else اجرا نخواهد شد بلکه بند except آن را مدیریت خواهد کرد.
بند Finally
گزاره try یک بند دیگر به نام Finally نیز دارد که اساساً برای پاکسازی اقدامات استفاده میشود. این بند پس از همه بندهای دیگر میآید. بند Finally در هر حالتی صرف نظر از این که استثنایی رخ داده یا نداده باشد اجرا خواهد شد. بند Finally لزوماً نیازی به وجود بندهای else یا except ندارد. به مثال زیر توجه کنید:
خروجی
>>> divide(2، 1)
Output = 2.0
Executing finally clause
>>> divide(2، 0)
Cannot divide by zero
Executing finally clause
>>> divide("2"، "1")
Executing finally clause
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
File "<stdin>"، line 3، in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'بند Finally همواره پیش از ترک گزاره try اجرا خواهد شد و مهم نیست که استثنایی رخ داده است یا نه. زمانی که یک استثنا در بند try رخ دهد و از سوی بند except مدیریت نشود (و یا در بند except یا else رخ دهد) در واقع مجدداً پس از اجرای بند Finally رخ داده است (فراخوانی سوم به تابع divide را در بخش قبل ببینید). بند Finally در مسیر خروجی زمانی که از یک گزاره break ،continue یا return استفاده شده باشد همچنان اجرا خواهد شد.
کاربردهای عملی بند Finally برای آزادسازی منابع مانند فایلها یا اتصالهای پایگاه داده و مواردی از این دست است. فرق بین داشتن کدی داخل بند Finally و نوشتن آن خارج از این بند و پس از گزاره try چیست؟ به بیان ساده فرق بین دو حالت زیر چیست؟
تفاوت دو کد فوق تنها زمانی مشخص میشود که استثنایی (در هر یک از بندهای try ،except یا else) رخ دهد و مدیریت نشده باشد. در این حالت:
- کد اول عبارت ‘Leaving the function’ را نمایش داده و استثنا را مجدداً صادر میکند.
- کد دوم عبارت ‘Leaving the function’ را نمایش نمیدهد و استثنا به کد بیرونی ارسال میشود.
برای جمعبندی باید اشاره کنیم که فرق بین دو سناریوی فوق این است که کد موجود در بند Finally حتی در صورتی که استثنایی رخ داده باشد (و مدیریت نشده باشد) اجرا میشود؛ اما کدی که در ادامه گزاره try میآید چنین حالتی ندارد.
ایجاد استثناها
در این بخش با روش ایجاد دستی استثناها و همچنین ایجاد استثناهای سفارشی آشنا میشویم.
ایجاد استثناهای داخلی
پایتون روشی برای ایجاد دستی یک استثنا ارائه کرده است. این کار از طریق کلیدواژه raise صورت میپذیرد.
>>> raise AssertionError('Asserted statement is incorrect')
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
raise AssertionError('Asserted statement is incorrect')
AssertionError: Asserted statement is incorrectکلیدواژه raise تنها یک آرگومان میگیرد که یا یک کلاس استثنا است (که از کلاس Exception مشتق میشود) و یا یک وهله از استثنا است. در کد مثال فوق، آرگومان یک وهله از استثنا با پیام رشتهای است. این پیام رشتهای (اختیاری) زمانی که ارسال شود، خطا را توصیف میکند.
اگر آرگومان یک کلاس استثنا باشد، در این صورت سازنده آن بدون هیچ آرگومانی به صورت زیر فراخوانی میشود:
>>> raise AssertionError Traceback (most recent call last) File "<stdin>"، line 1، in <module> raise AssertionError AssertionError
تعریف و ایجاد استثناهای سفارشی
پیش از این که به معرفی روش ایجاد استثناهای سفارشی بپردازیم ابتدا به این سؤال پاسخ میدهیم که اساساً این کار چه ضرورتی دارد. موارد خاصی وجود دارند که در آنها استثناهای داخلی نمیتوانند برای توصیف معنیدار خطای رخ داده، مورد استفاده قرار گیرند.
برای نمونه فرض کنید تابع سادهای داریم که تعداد واحدهای (برق) مصرفی بین دو خوانش مجزا را محاسبه میکند. اگر هر کدام از خوانش ها منفی باشند، تابع استثنای ValueError ایجاد میکند و فرض میکند که واحدهای مصرفی محاسبهشده منفی هستند. در این صورت میخواهیم یک استثنا ایجاد شود (برای مثال NegativeConsumptionError). اما این استثنا جزء استثناهای داخلی پایتون نیست. البته ما همچنان میتوانیم از استثنای داخلی ValueError برای مدیریت این مورد نیز استفاده کنیم. اگر بخواهیم از ValueError برای این خطا استفاده کنیم، در این صورت هیچ روشی برای کد فراخوانی کننده electricity_consumption جهت ایجاد تمایز بین ‘Negative reading’ and ‘Negative consumption’ وجود نخواهد داشت.
با استفاده از استثنای داخلی ValueError
با استفاده از استثنای سفارشی
روش تعریف استثنای سفارشی چگونه است؟
برای تعریف یک استثنای سفارشی باید یک کلاس تعریف کنید که از کلاس Exception مشتق میشود یا یک کلاس فرعی از آن بسازید. در ادامه یک مثال ساده را ملاحظه میکنید:
یک رویه رایج، ایجاد کلاس مبنا برای استثناهای تعریف شده از سوی ماژول و ایجاد کلاس فرعی از آن برای ایجاد کلاسهای استثنای خاص برای شرایط خطای متفاوت است. زمانی که استثنای مبنا را برای یک ماژول تعریف کردیم و سپس از آن کلاس فرعی برای تعریف استثناهای خاص ساختیم، میتوانیم به سادگی همه استثناها را که از آن ناشی میشوند با استفاده از استثنای مبنا مدیریت کنیم.
همچنین میتوانید خصوصیتهایی روی استثناهای سفارشی تعیین کنید که با استفاده از دستگیرههایی قابل بازیابی باشند. به مثال زیر توجه کنید:
خروجی
2 # 3 Unknown operator
Logger.exception
ما در همه کدهای عملی خود از لاگرها استفاده میکنیم، چون لاگرها کار دیباگ گردن را تسهیل میکنند. لاگرها در پایتون، پشتیبانی خاصی برای استثناها دارند. از این رو در ادامه مقداری در مورد آنها توضیح میدهیم.
متد مربوطه ()logger.exception نام دارد. به کد زیر توجه کنید:
خروجی کد فوق یک رد پشته کامل از استثنا است که مدیریت شده است و صرفاً یک توصیف متنی از استثنا محسوب نمیشود. مزیتهای آن به شرح زیر هستند:
دیگر نیاز نداریم از نامهای مستعار برای استثناها استفاده کنیم، مگر اینکه آن را درون بند except نیاز داشته باشیم، چون استثنای رخ داده به صورت ضمنی در ()logger.exception قرار دارد.
علاوه بر ردگیری پشته، ()logger.exception یک پیام روی رد پشته نیز نمایش میدهد. بدین ترتیب خروجی لاگ قطعه کد به صورت زیر خواهد بود:
ERROR: Exception while performing division — handled Traceback (most recent call last): File "<stdin>"، line 1، in <module> raise ZeroDivisionError ZeroDivisionError
نکته 1: ()logger.exception پیامها را با سطح ERROR لاگ میکند.
نکته 2: ()logger.exception باید تنها از یک دستگیره استثنا فراخوانی شود.
بدین ترتیب به پایان این مقاله میرسیم.
منبع" فرادرس
موارد استثنا در پایتون — راهنمای کاربردی
در هر زبان برنامهنویسی شاهد حضور دو نوع خطا هستیم که یکی خطاهای کامپایل و دیگری خطاهای زمان اجرا است. خطاهای کامپایل در زمان کامپایل کردن کد منبع و در نتیجهی ساختار یا معناشناسی نادرست رخ میدهند. در این مقاله به بررسی موارد استثنا در پایتون می پردازیم. به مثال زیر توجه کنید:
در کد فوق پرانتز انتهایی فراموش شده است و در نتیجه خطای ساختاری رخ داده که در زمان تلاش برای اجرای کد بروز مییابد. این خطا در زمان کامپایل کردن کد ظاهر میشود و از این رو خطای کامپایل نام دارد (به طور خاص خطای ساختاری یا نحوی نامیده میشود) برای اصلاح این خطا در خط فوق، کافی است یک پرانتز انتهایی در آخر خط قرار دهیم، یعنی باید ساختار/معناشناسی کد را به صورت زیر اصلاح کنیم:
از سوی دیگر خطاهای زمان اجرا زمانی رخ میدهند که برنامه در حال اجرا است. این خطاها در نتیجه زمینه/ ورودی غیر معمول در یک قطعه کد اجرایی حاصل میشوند. یعنی یک برنامه که از نظر ساختاری و معناشناختی صحیح است بسته به زمینه اجرایی و ورودی برنامه ممکن است خطا داشته باشد یا نداشته باشد. به مثال زیر توجه کنید:
کد فوق از نظر ساختاری و معناشناختی صحیح است و هیچ خطایی تولید نمیکند. نتیجه پس از اجرای برنامه res=20 خواهد بود. اینک به کد زیر توجه کنید:
با این که کد از نظر ساختاری و معناشناختی صحیح است، اما در زمان اجرا خطایی صادر میکند. دلیل خطا تلاش برای تقسیم بر صفر است که تعریف نشده است. این نمونهای از خطای زمان اجرا به دلیل ورودی نامعمول است. این خطاهای زمان اجرا به نام «استثنا» (Exception) نیز شناخته میشوند.
نمونههایی از خطاهای زمان اجرا که به دلیل زمینه یا چارچوب پدید میآیند، اجرا کردن یک برنامه (که از کارکردهای خاص سیستم عامل استفاده میکند) روی یک سیستم ناسازگار است.
چرا خطاهای زمان اجرا بد هستند؟
دلیل بد بودن خطاهای زمان اجرا این است که در زمان وقوع، موجب خاتمه یافتن برنامه میشوند.
موقعیتی را تصور کنید که یک برنامه ماشین حساب ساختهایم که عملیات ابتدایی حساب (+، -، * و /) را روی دو عدد اجرا میکند. این برنامه از کاربر دو عدد میخواهد و عملیات مورد نظر را نیز میپرسد تا روی اعداد اجرا کند. فرض کنید برنامه در حلقه اجرا میشود، یعنی زمانی که 3 ورودی را درخواست کرد (دو عملوند و یک عملگر) محاسبه را اجرا کرده و نتیجه را نمایش میدهد، و سپس منتظر وارد کردن 3 ورودی بعدی میماند و نتایج آنها را نیز محاسبه و نمایش میدهد و همین طور تا آخر ادامه میدهد.
این برنامه کار خود را به درستی انجام میدهد تا این که عملیات تقسیم بر صفر پیش بیاید (مثلاً 25/0). در این ورودی، برنامه یک خطای زمان اجرا/استثنا صادر میکند، چون نمیتواند نتیجه را تحلیل کند و بیدرنگ خاتمه مییابد. شما باید برنامه را از نو آغاز کنید و مجدداً مقادیر را وارد نمایید تا چنین ورودی پیش بیاید. این فقط یک برنامه ماشین حساب ساده است که راهاندازی مجدد آن چند ثانیه طول میکشد، اما نرمافزاری که راهاندازی مجدد آن دقایق یا ساعتها طول میکشد چطور؟ گاهی اوقات نیز کلاً امکان راهاندازی مجدد وجود ندارد و این وضعیت نامناسبی ایجاد میکند.
آیا راهی برای جلوگیری از وقوع استثنا وجود دارد؟ نه، ما نمیتوانیم از وقوع استثناها جلوگیری کنیم، اما میتوانیم آنها را طوری مدیریت کنیم که موجب خاتمه یافتن برنامه نشوند.
منظور از مدیریت استثنا چیست؟ معنی مدیریت استثنا این است که وقتی اتفاق میافتد نگذاریم برنامه را پایان دهد و برنامه بتواند به اجرای خود ادامه دهد.
استثنا چگونه مدیریت میشود؟ در بخشهای بعدی این مقاله به بررسی همین موضوع خواهیم پرداخت.
هر آنچه تاکنون مطرح کردیم در مورد همه زبانهای برنامهنویسی که از استثنا و مدیریت آنها پشتیبانی میکنند، قابل تعمیم است. اینک نوبت آن رسیده است که بحث را به یک زبان خاص یعنی پایتون محدود کنیم. از این بخش به بعد همه مواردی که مطرح میشوند مختص زبان برنامهنویسی پایتون هستند مگر این که صراحتاً چیز دیگری قید شده باشد.
استثناها در پایتون
اینک به بررسی روش مدیریت استثناها در پایتون میپردازیم.
مدیریت استثناها
برای مدیریت استثناها در پایتون چند روش وجود دارد که در ادامه هر یک از آنها را به تفصیل مورد بررسی قرار خواهیم داد.
بلوک try-except ابتدایی
استثناها از طریق یک گزاره try مدیریت میشوند که ساختار مقدماتی آن به صورت زیر است:
کدی که مشکوک به ایجاد استثنا است زیر بند try یک گزاره try قرار میگیرد. کدی که باید در زمان بروز استثنا برای مدیریت آن اجرا شود نیز زیر بند except قرار میگیرد. به مثال زیر توجه کنید:
خروجی برای ورودی متفاوت:
>>> divide(50، 2) Result = 25 >>> divide(50، 0) Divisor is zero; Division is impossible
گزاره try به صورت زیر عمل میکند:
بندهای چندگانه except
این امکان هست که یک کد بیش از یک نوع استثنا ایجاد کند. مثلاً استثناها ممکن است از انواع ValueError ،AttributeError ،KeyError و غیره باشند. اینها مواردی از استثناهای داخلی هستند یعنی در خود پایتون موجود هستند. برای مشاهده لیست کامل آنها به این لینک (+) مراجعه کنید. شما میتوانید استثناها را خودتان نیز تولید و صادر کنید! در ادامه در این مورد بیشتر توضیح خواهیم داد.
اما اینک سؤال این است که چگونه میتوان استثناهای چندگانه (هم داخلی و هم سفارشی) که از کد موجود در بلوک try ناشی میشوند را مدیریت کرد؟ آیا پایتون پشتیانی خاصی از این وضعیت دارد؟ بله چنین است. بدین منظور باید از بندهای چندگانه except استفاده کنیم. به مثال زیر توجه کنید:
>>> int_value = int(a)
این گزاره ممکن است موجب بروز ValueError یا TypeError شود یا کلاً هیچ نوع استثنایی ایجاد نکند و همه اینها به نوع و مقدار متغیر a بستگی دارد. فرض کنید a= 3.2 یا ‘a = ‘1200 باشد در این صورت هیچ استثنایی تولید نمیشود؛ اما اگر ‘a=’12k باشد، در این صورت ValueError رخ میدهد. همچنین اگر [a= [1، 2 باشد در این صورت استثنای TypeError بروز مییابد.
روش مدیریت هر دوی آنها به صورت زیر است:
کد فوق صرفاً نردبانی از بندهای except است و استثناهایی دارد که قرار است مدیریت شوند. نکتهای که باید توجه داشت این است که ترتیب مدیریت باید صحیح باشد.
Exception در بند except به مدیریت استثناهایی از یک نوع یا مشتق از آن میپردازد. اما معکوس آن صحیح نیست یعنی Exception در بند except به مدیریت خطای پایه از نوعی که مشتق شده نمیپردازد. برای نمونه کد زیر به ترتیب مقادیر B ،C و D را نمایش میدهد:
توجه کنید که اگر بندهای except معکوس بودند (یعنی except به نام B اول بود، موارد نمایش یافته به صورت B ،B ،B بودند و نخستین بند except منطبق تحریک میشد. برای بصریسازی بهتر به تصویر زیر توجه کنید:
در این تصویر در سمت راست نوعی استثنا رخ داده است، سمت چپ مدیران استثنا هستند که D از C مشتق میشود و C نیز از B مشتق میشود.
استثناهای چندگانه در یک بند except منفرد
یک حالت کوتاهتر (البته نه همیشه) برای ساختار فوق نیز وجود دارد. ساختار کلی آن به صورت زیر است:
و مثالی از آن به صورت زیر است:
یعنی همه استثناهایی که قصد داشتیم مدیریت کنیم در یک چندتایی ترکیب میکنیم. استثناهایی که در این چندتاییها ستاند با ترتیب ظهورشان در چندتایی مطابقت دارند. قاعده بخش قبلی در این بخش نیز صدق میکند. میتوان هر دو این رویکردها را با هم ترکیب نیز کرد یعنی یک نردبان از بندهای except داشت که هر یک بیش از یک استثنا (در چندتایی) را مدیریت میکنند.
در نهایت سؤال این است که تفاوت بین دو رویکرد فوق چیست و هر کدام در چه موقعیتی بهتر هستند؟
تفاوت دو رویکرد فوق در شیوه پاسخدهی در زمان مدیریت استثناها است.
- اگر میخواهید یک قطعه کد را برای همه استثناهای مدیریتشده اجرا کنید، در این صورت از رویکرد دوم استفاده کنید. این رویکرد از تکرار قطعه کد در بندهای except چندگانه جلوگیری میکند.
- اگر میخواهید بسته به نوع استثناهایی که مدیریت میکنید، قطعه کدهای متفاوتی داشته باشید، در این صورت از رویکرد اول استفاده کنید. البته اجرای این کار با استفاده از رویکرد دوم نیز میسر است و مثالی از روش اجرای آن به صورت زیر است:
اما بهتر است که از رویکرد اول برای چنین حالتهایی استفاده کنید، زیرا درک آن آسانتر است و از پشتیبانی ارائه شده از سوی خود زبان به جای یک راهحل مانند فوق بهره میگیرد.
تعیین نام مستعار
به خط زیر در کد بخش قبل توجه کنید:
except (exception_1، exception_2،..) as e:
این استثنایی است (هستند) که یک نام برای آن تعیین شده است. این کار از نظر فنی «aliasing» یا تعیین نام مستعار نامیده میشود.
در زمان تعیین نام مستعار، میتوانیم با استفاده از یک نام رایج به استثنا (ها) دسترسی داشته باشیم. این حالت در زمانی مفید خواهد بود که بخواهیم از خصوصیتهای استثنایی که مدیریت میشود بهره بگیریم. تعیین نام مستعار از طریق کلیدواژه as صورت میگیرد. ساختار آن به صورت زیر است:
در کد فوق <alias> را باید با نام مستعار مورد نظر خود جایگزین کنید. به مثال زیر توجه کنید:
خروجی:
('Invalid name')شما میتوانید از هر عنوانی برای نام مستعار استفاده کنید. بدیهی است که امکان استفاده از کلیدواژههای داخلی میسر نیست. به طور معمول از e استفاده میشود.
نکته: اگر میخواهد برای یک استثنای منفرد نام مستعار تعیین کنید در این صورت استفاده از پرانتزهای پیرامونی اختیاری است. اما در صورتی که مانند مثال فوق از استثناهای چندگانه استفاده میکنید، پرانتزها الزامی هستند.
بند else
برخی اوقات با حالتی مواجه میشویم که میخواهیم یک قطعه کد را تنها و تنها در صورتی اجرا کنیم که کد زیر بند try هیچ استثنایی ایجاد نکرده باشد. به مثال زیر توجه کنید:
مسئله: تابعی به نام divide بنویسید که a را بر b تقسیم کند (به عنوان پارامتر ارسال میشود) و موارد زیر را در خروجی نمایش دهد:
- اگر b برابر با صفر بود، در این صورت عبارت «امکان تقسیم بر صفر وجود ندارد.» را نمایش دهد.
- در غیر این صورت <Output = <quotient را نمایش دهد که quotient حاصل تقسیم است.
راهحل
خروجی
>>> divide(20، 10) Output = 2.0 >>> divide(20، 0) Cannot divide by zero
بند else اختیاری است و در صورت حضور، همواره از بند except تبعیت میکند. کد زیر بند else تنها زمانی اجرا خواهد شد که بند زیر try هیچ استثنایی صادر نکند. اگر استثنایی در بلوک try صادر شود، در این صورت بلوک else اجرا نخواهد شد بلکه بند except آن را مدیریت خواهد کرد.
بند Finally
گزاره try یک بند دیگر به نام Finally نیز دارد که اساساً برای پاکسازی اقدامات استفاده میشود. این بند پس از همه بندهای دیگر میآید. بند Finally در هر حالتی صرف نظر از این که استثنایی رخ داده یا نداده باشد اجرا خواهد شد. بند Finally لزوماً نیازی به وجود بندهای else یا except ندارد. به مثال زیر توجه کنید:
خروجی
>>> divide(2، 1)
Output = 2.0
Executing finally clause
>>> divide(2، 0)
Cannot divide by zero
Executing finally clause
>>> divide("2"، "1")
Executing finally clause
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
File "<stdin>"، line 3، in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'بند Finally همواره پیش از ترک گزاره try اجرا خواهد شد و مهم نیست که استثنایی رخ داده است یا نه. زمانی که یک استثنا در بند try رخ دهد و از سوی بند except مدیریت نشود (و یا در بند except یا else رخ دهد) در واقع مجدداً پس از اجرای بند Finally رخ داده است (فراخوانی سوم به تابع divide را در بخش قبل ببینید). بند Finally در مسیر خروجی زمانی که از یک گزاره break ،continue یا return استفاده شده باشد همچنان اجرا خواهد شد.
کاربردهای عملی بند Finally برای آزادسازی منابع مانند فایلها یا اتصالهای پایگاه داده و مواردی از این دست است. فرق بین داشتن کدی داخل بند Finally و نوشتن آن خارج از این بند و پس از گزاره try چیست؟ به بیان ساده فرق بین دو حالت زیر چیست؟
تفاوت دو کد فوق تنها زمانی مشخص میشود که استثنایی (در هر یک از بندهای try ،except یا else) رخ دهد و مدیریت نشده باشد. در این حالت:
- کد اول عبارت ‘Leaving the function’ را نمایش داده و استثنا را مجدداً صادر میکند.
- کد دوم عبارت ‘Leaving the function’ را نمایش نمیدهد و استثنا به کد بیرونی ارسال میشود.
برای جمعبندی باید اشاره کنیم که فرق بین دو سناریوی فوق این است که کد موجود در بند Finally حتی در صورتی که استثنایی رخ داده باشد (و مدیریت نشده باشد) اجرا میشود؛ اما کدی که در ادامه گزاره try میآید چنین حالتی ندارد.
ایجاد استثناها
در این بخش با روش ایجاد دستی استثناها و همچنین ایجاد استثناهای سفارشی آشنا میشویم.
ایجاد استثناهای داخلی
پایتون روشی برای ایجاد دستی یک استثنا ارائه کرده است. این کار از طریق کلیدواژه raise صورت میپذیرد.
>>> raise AssertionError('Asserted statement is incorrect')
Traceback (most recent call last):
File "<stdin>"، line 1، in <module>
raise AssertionError('Asserted statement is incorrect')
AssertionError: Asserted statement is incorrectکلیدواژه raise تنها یک آرگومان میگیرد که یا یک کلاس استثنا است (که از کلاس Exception مشتق میشود) و یا یک وهله از استثنا است. در کد مثال فوق، آرگومان یک وهله از استثنا با پیام رشتهای است. این پیام رشتهای (اختیاری) زمانی که ارسال شود، خطا را توصیف میکند.
اگر آرگومان یک کلاس استثنا باشد، در این صورت سازنده آن بدون هیچ آرگومانی به صورت زیر فراخوانی میشود:
>>> raise AssertionError Traceback (most recent call last) File "<stdin>"، line 1، in <module> raise AssertionError AssertionError
تعریف و ایجاد استثناهای سفارشی
پیش از این که به معرفی روش ایجاد استثناهای سفارشی بپردازیم ابتدا به این سؤال پاسخ میدهیم که اساساً این کار چه ضرورتی دارد. موارد خاصی وجود دارند که در آنها استثناهای داخلی نمیتوانند برای توصیف معنیدار خطای رخ داده، مورد استفاده قرار گیرند.
برای نمونه فرض کنید تابع سادهای داریم که تعداد واحدهای (برق) مصرفی بین دو خوانش مجزا را محاسبه میکند. اگر هر کدام از خوانش ها منفی باشند، تابع استثنای ValueError ایجاد میکند و فرض میکند که واحدهای مصرفی محاسبهشده منفی هستند. در این صورت میخواهیم یک استثنا ایجاد شود (برای مثال NegativeConsumptionError). اما این استثنا جزء استثناهای داخلی پایتون نیست. البته ما همچنان میتوانیم از استثنای داخلی ValueError برای مدیریت این مورد نیز استفاده کنیم. اگر بخواهیم از ValueError برای این خطا استفاده کنیم، در این صورت هیچ روشی برای کد فراخوانی کننده electricity_consumption جهت ایجاد تمایز بین ‘Negative reading’ and ‘Negative consumption’ وجود نخواهد داشت.
با استفاده از استثنای داخلی ValueError
با استفاده از استثنای سفارشی
روش تعریف استثنای سفارشی چگونه است؟
برای تعریف یک استثنای سفارشی باید یک کلاس تعریف کنید که از کلاس Exception مشتق میشود یا یک کلاس فرعی از آن بسازید. در ادامه یک مثال ساده را ملاحظه میکنید:
یک رویه رایج، ایجاد کلاس مبنا برای استثناهای تعریف شده از سوی ماژول و ایجاد کلاس فرعی از آن برای ایجاد کلاسهای استثنای خاص برای شرایط خطای متفاوت است. زمانی که استثنای مبنا را برای یک ماژول تعریف کردیم و سپس از آن کلاس فرعی برای تعریف استثناهای خاص ساختیم، میتوانیم به سادگی همه استثناها را که از آن ناشی میشوند با استفاده از استثنای مبنا مدیریت کنیم.
همچنین میتوانید خصوصیتهایی روی استثناهای سفارشی تعیین کنید که با استفاده از دستگیرههایی قابل بازیابی باشند. به مثال زیر توجه کنید:
خروجی
2 # 3 Unknown operator
Logger.exception
ما در همه کدهای عملی خود از لاگرها استفاده میکنیم، چون لاگرها کار دیباگ گردن را تسهیل میکنند. لاگرها در پایتون، پشتیبانی خاصی برای استثناها دارند. از این رو در ادامه مقداری در مورد آنها توضیح میدهیم.
متد مربوطه ()logger.exception نام دارد. به کد زیر توجه کنید:
خروجی کد فوق یک رد پشته کامل از استثنا است که مدیریت شده است و صرفاً یک توصیف متنی از استثنا محسوب نمیشود. مزیتهای آن به شرح زیر هستند:
دیگر نیاز نداریم از نامهای مستعار برای استثناها استفاده کنیم، مگر اینکه آن را درون بند except نیاز داشته باشیم، چون استثنای رخ داده به صورت ضمنی در ()logger.exception قرار دارد.
علاوه بر ردگیری پشته، ()logger.exception یک پیام روی رد پشته نیز نمایش میدهد. بدین ترتیب خروجی لاگ قطعه کد به صورت زیر خواهد بود:
ERROR: Exception while performing division — handled Traceback (most recent call last): File "<stdin>"، line 1، in <module> raise ZeroDivisionError ZeroDivisionError
نکته 1: ()logger.exception پیامها را با سطح ERROR لاگ میکند.
نکته 2: ()logger.exception باید تنها از یک دستگیره استثنا فراخوانی شود.
بدین ترتیب به پایان این مقاله میرسیم.
منبع" فرادرس
آموزش ساخت یک اپلیکیشن آیفون (بخش یازدهم) — به زبان ساده
در این بخش از سری مقالات آموزش ساخت اپلیکیشن آیفون از چند سازوکار استفاده میکنیم تا امکان رشد محتوا را فراهم سازیم و به سلولها امکان دهیم که ار تنظیم خودکار اندازه بهره بگیرند. در بخش قبلی در مورد خصوصیتهای سلول News اپلیکیشن خود صحبت کردیم و چنان که دیدیم هنگامیکه سلول را در زمان اجرا مشاهده میکنیم، متن و تصویر تفصیلی، هر دو برش پیدا میکنند و محتوای کامل خود را نمایش نمیدهند. برای مشاهده بخش قبلی این مجموعه مطلب آموزشی میتوانید به لینک زیر مراجعه کنید:
ارتفاع پیشفرض سلول
زمانی که لیآوت NewsTableViewCell را ایجاد کردیم، قیدی برای حاشیههای فوقانی و تحتانی آن در نظر گرفتیم. بدین ترتیب سلول میتواند ارتفاعی را که برای نمایش محتوایش نیاز دارد (یعنی اندازه ثابت ذاتی) بداند. اگر متن یا تصویر بزرگتر از این شوند، سلول میداند که باید ارتفاع بیشتری پیدا کند.
یک نمای جدولی به صورت پیشفرض و به طور خودکار ارتفاع سلولهایش را برابر با محتوایش تنظیم میکند. هر دو سلول را در صحنه News انتخاب کنید. یک روش برای انجام این کار کلیک کردن روی یک سلول و نگهداشتن کلید Shift و کلیک روی سلول دیگر است. Size Inspector (آیکون خط کش) را انتخاب کنید.
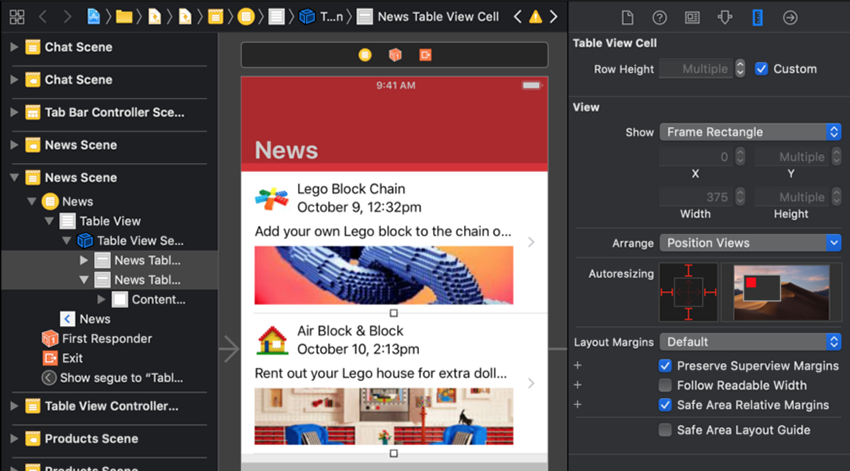
در کنار برچسب Row Height در بخش Size Inspector کادر انتخاب Custom را غیر فعال کنید.
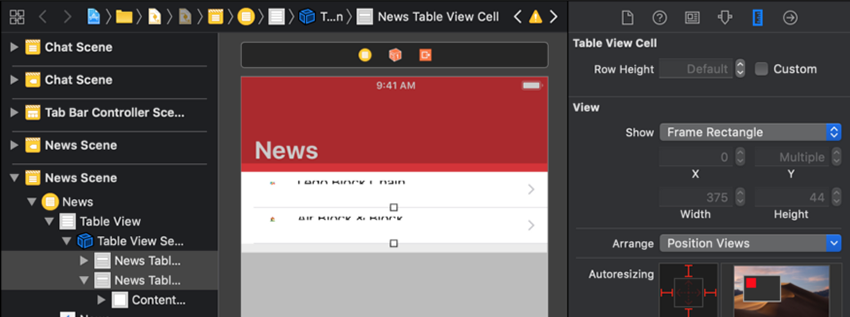
بدین ترتیب فیلد Row Height به صورت Default درمیآید. بنابراین ارتفاع سلولها در این بوم تا مقدار 44 پوینت کاسته میشود و دیگر نمیتوانید محتوا را ببینید. اکنون اپلیکیشن را اجرا کنید.
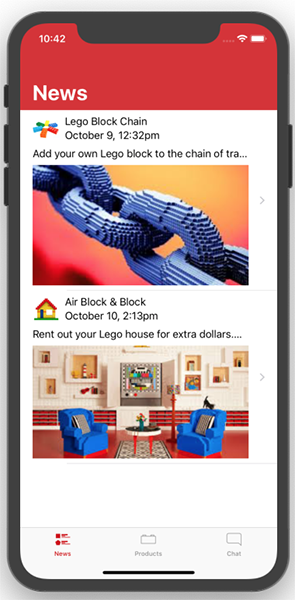
در زمان اجرا، نمای جدولی به صورت دینامیک ارتفاع سلولها را طوری تنظیم میکند که با محتوا مطابقت یابند. اما در زمان طراحی سلولها تنها 44 پوینت ارتفاع دارند و پیشنمایش کاملی ایجاد نمیشود.
این وضعیت بغرنجی است. اگر از یک ارتفاع سفارشی استفاده کنیم، سلولها در زمان طراحی ارتفاع مفیدی دارند، اما در زمان اجرا تنظیم نمیشوند. اگر از ارتفاع پیشفرض استفاده کنیم، محتوای سلول در زمان طراحی فشرده میشود، اما در زمان اجرا به صورت دینامیک تنظیم میشود. خوشبختانه میتوانیم ارتفاع سلولها را در «سازنده اینترفیس» (Interface Builder) یعنی در زمان طراحی به هر مقداری که مناسب به نظر میرسد تغییر دهیم و کنترلر نما را به صورت دینامیک برای ارتفاع هر سلول تنظیم کنیم تا با محتوا در زمان اجرا مطابقت پیدا کند.
ارتفاع سلول کنترلر نما
چنان که پیشتر گفتیم، هر نما یک کنترلر نما دارد که شامل کدی است که آن را اجرا میکند. کنترلر نما، چنان که از نامش برمیآید، به کنترل همه نماهای درون صحنه در زمان اجرا میپردازد و این مسئله شامل ارتفاع سلول نیز میشود. ما درون کنترلر برای تنظیم دینامیک ارتفاع سلولها به کد نیاز داریم. خوشبختانه این کد در فریمورک BFWControl از قبل برای ما نوشته شده است.
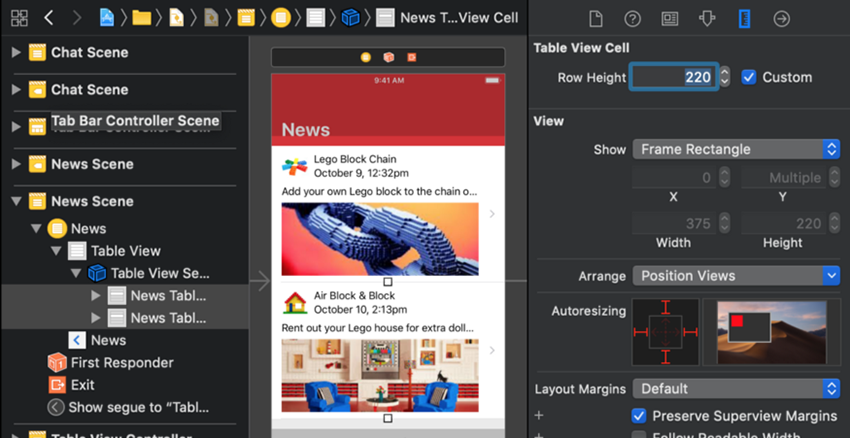
قبل از هر چیز باید سلولها را در سازنده اینترفیس به حالت ارتفاع پیشنمایش مفید بازگردانیم. به xcode بروید و با انتخاب دو سلول در بخش Size Inspector مقدار 220 را برای Row Height وارد کنید.
ما میتوانیم ارتفاع ردیف را طوری وارد کنیم که پیشنمایش معقولی از سلولها در استوریبورد به دست بدهد. همچنین میتوانیم ارتفاع آنها را با کشیدن دستگیره تحتانی سلول چنان که قبلاً انجام دادیم تنظیم کنیم.
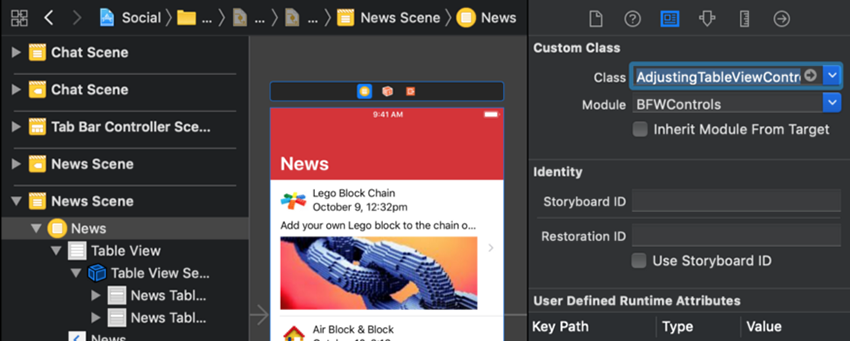
در ادامه به کنترلر نما اعلام میکنیم که ارتفاع هر سلول را در زمان اجرا طوری تنظیم کند که با ارتفاع ذاتی محتوایش مطابقت داشته باشد. به این منظور کافی است نمای کنترلر نما را به صورت AdjustingTableViewController تغییر داده و خصوصیت intrinsicHeightCells را فعال کنیم.
کنترلر نمای جدولی را با کلیک کردن روی آیکون زردرنگ در نوار عنوان انتخاب کنید. در ادامه در سمت پنل سمت راست Identity Inspector را انتخاب کنید.

در Identity Inspector در فیلد Class عبارت Adj را وارد کرده و گزینه AdjustingTableViewController را از منوی بازشدنی انتخاب کنید. Return یا Tab را بزنید. در این مرحله Xcode به صورت خودکار عبارت Module را به مقدار BFWControls تنظیم میکند چون جایی است که کلاس در آن قرار دارد.
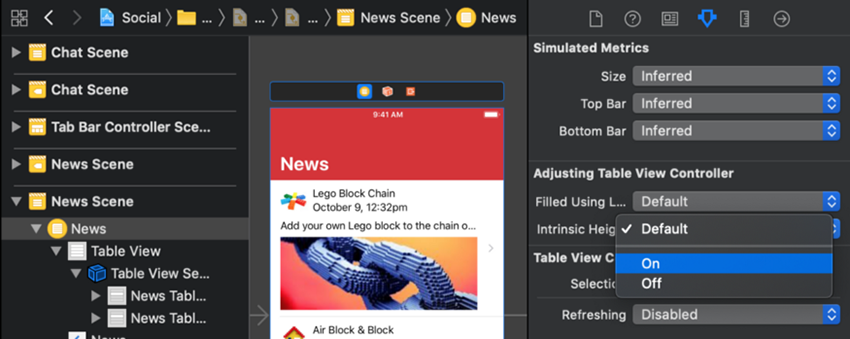
به پنل Attributes Inspector بروید. در این زمان با یک بخش جدید مواجه میشوید که عنوان آن Adjusting Table View Controller است. روی منوی بازشدنی کنار Intrinsic Height Cells کلیک کرده و آن را از Default به On تغییر دهید.
اپلیکیشن را اجرا کنید.
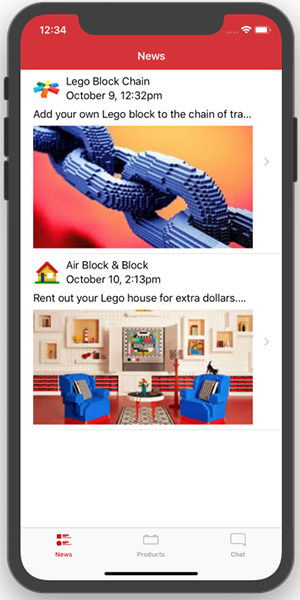
چنان که مشاهده میکنید، کنترلر نما به صورت خودکار ارتفاع هر سلول را بر مبنای محتوای آن تنظیم کرده است. این همان نتیجهای است که در زمان تنظیم Row Height هر سلول به صورت Default به دست میآید. با این حال اکنون ما مقدار Row Height را روی 220 تنظیم کردهایم و در زمان اجرا آن را به ارتفاع ذاتی هر سلول override کردهایم.
تعداد خطوط در برچسب
متن درون هر سلول در حال حاضر تنها یک خط اشغال میکند. بدیهی است که متن تفصیلی در هر سلول به فضای بیشتری برای جای گرفتن نیاز دارد و این مسئله به وسیله (…) مورد اشاره قرار گرفته است. در این بخش برچسبهای متنی را تغییر میدهیم تا در بیش از یک خط قرار گیرند.
چنان که میدانید، هر سلول در صحنه News وهلهای از کلاس NewsTableViewCell است. برچسبهای متنی درون آن کلاس و لیآوت، تحت کنترل NewsTableViewCell.xib هستند. هر برچسب یک مشخصه numberOfLines دارد که در بخش Attributes Inspector به صورت Lines ظاهر میشود. مقدار پیشفرض 1 است، اما میتوانیم آنها را به 2، 3 یا هر مقداری که خطوط ما برای آن برچسب نیاز دارند تغییر دهیم. برای این که تعداد خطوط بیشینه متن نامحدود باشند میتوانید مقدار 0 وارد کنید.
فایل NewsTableViewCell.xib را در Project Navigator انتخاب کنید. یکبار روی برچسب [Detail Text] (برچسب انتهایی) کلیک کنید و Attributes Inspector را انتخاب نمایید. در فیلد Lines مقدار 1 را به 0 تغییر دهید و دکمه Return را بزنید.
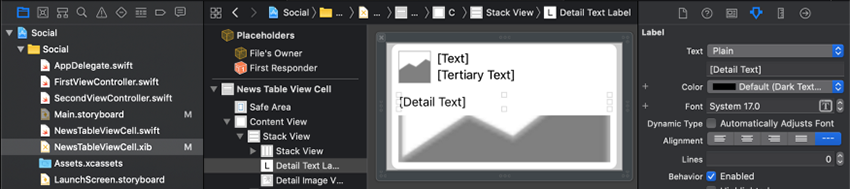
به Main.storyboard بازگردید. اینک باید ببینید که برچسبها خطوط متنی بیشتری را نمایش میدهند. اگر چنین نیست، در منوی Editor گزینه Refresh All Views را انتخاب کنید.
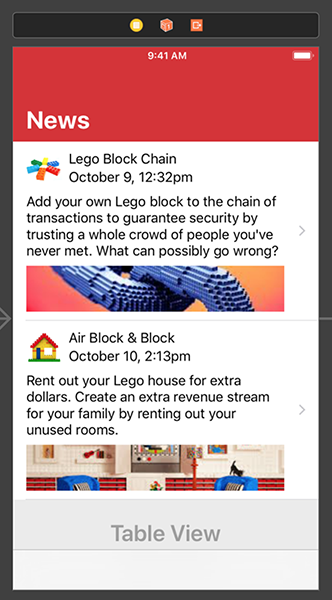
از آنجا که سلولها در سازنده اینترفیس (زمان طراحی) ارتفاع ثابتی دارند، Xcode ارتفاع نمایان نمای تصویر را کاهش داده تا فضای بیشتری برای متن باز شود.
اگر دوست دارید میتوانید ارتفاع سلولها را در سازنده اینترفیس تغییر دهید، چون ارتفاع زمان اجرا اکنون به طور مستقل و از سوی کنترلر نما تعیین میشود. اینک اپلیکیشن را اجرا کنید.
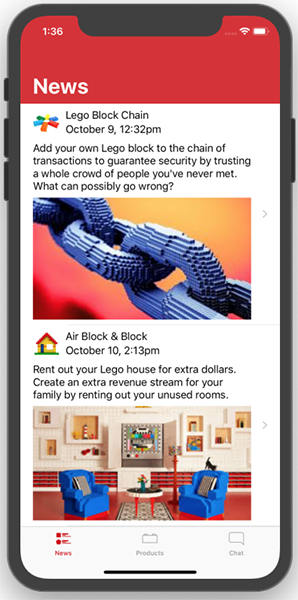
توجه کنید که روی شبیهساز iPhone XR، تعداد خطوط مورد نیاز برای هر برچسب متن تفصیلی متفاوت است و کنترلر نما به صورت دینامیک اندازه سلولها را مستقل از هم تعیین میکند.
استایل متن
تا به اینجا برچسبهای متنی ما همگی از استایل فونت پیشفرض بهره میگیرند. در ادامه مقداری تمایز بین برچسبها ایجاد میکنیم.
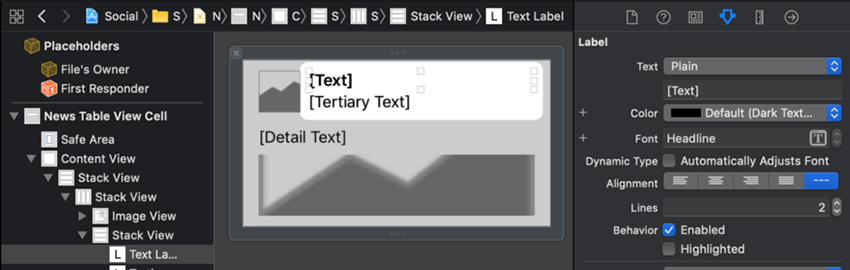
به Xocde بازگردید. فایل NewsTableViewCell.xib را انتخاب کنید. برچسب [Text] را انتخاب کرده و به Attributes Inspector بروید.
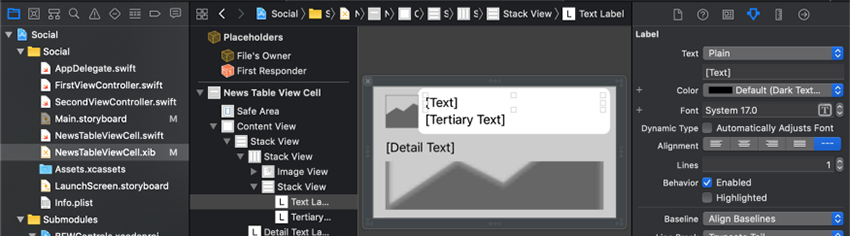
در Attributes Inspector روی آیکون T در فیلد Font کلیک کنید. در فیلد Font که باز میشود گزینه Headline را از بخش Text Styles انتخاب کنید.
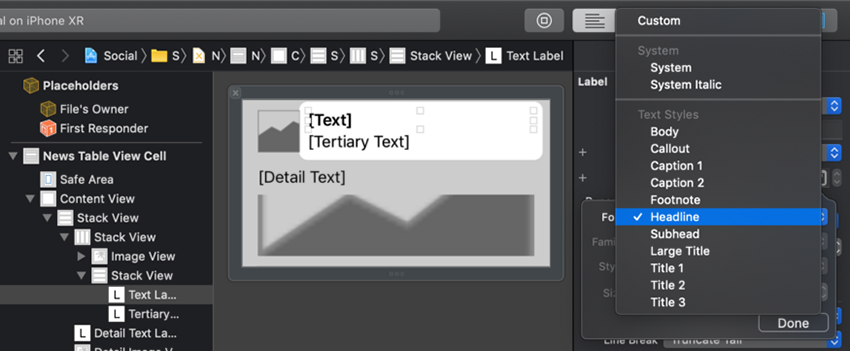
تعداد Lines را روی 2 قرار دهید. بدین ترتیب عنوان میتواند بسته به نیاز یک یا دو خط اشغال کند.
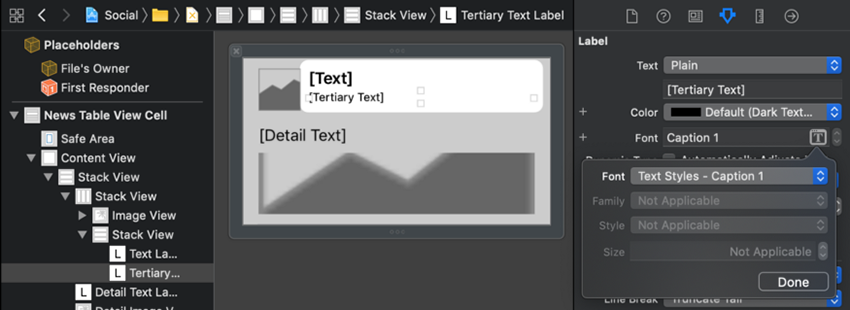
برچسب [Tertiary Text] را انتخاب کرده و گزینه استایل متنی Caption 1 را انتخاب کنید.
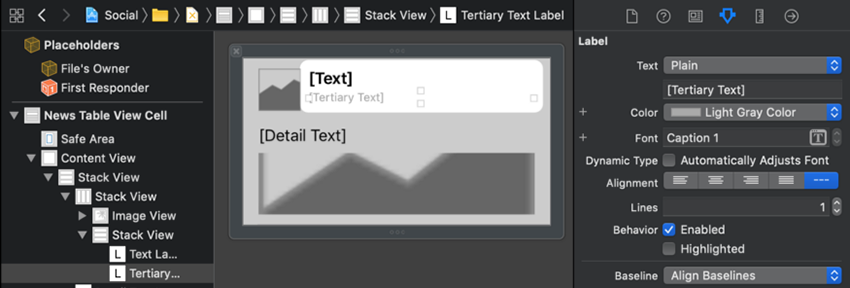
همزمان با انتخاب برچسب [Tertiary Text] در بخش Attributes Inspector منوی بازشدنی Color را به Light Gray Color تغییر دهید.
اپلیکیشن را اجرا کنید.
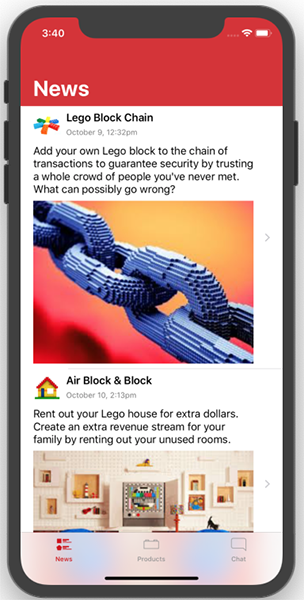
چنان که ملاحظه میکنید، هر وهله از NewsTableViewCell استایل متنی جدیدی دارد. ارتفاع برچسبها، نماهای پشتهای و سلولها هر کدام محتوای با اندازه اندکی متفاوت دارند.
کامیت کردن تغییرات
همانند بخشهای قبلی کارهای زیر را برای کامیت کردن تغییرات پروژه انجام میدهیم:
- گزینه Commit Changes را از منوی Source Control انتخاب کنید.
- توضیحی مانند زیر وارد کنید:
ews: auto adjusting cell heights; text styles
- روی دکمه Commit کلیک کنید.
جمعبندی
اکنون سلولهای News ما استایلهای متنی دارند، اندازه فونتشان متفاوت است و به صورت خودکار ارتفاع سلول را تنظیم میکنند. در بخش بعدی این سری مقالات آموزشی از همه آنچه تاکنون آموختهایم بهره میگیریم تا سلولهای با تنظیم خودکار برای صحنه Products بسازیم.
منبع: فرادرس
ساخت اپلیکیشن مدیریت هزینه های مالی با جاوا اسکریپت — از صفر تا صد
در این مقاله، شیوه ایجاد یک اپلیکیشن کوچک و کارآمد را بررسی میکنیم که تاریخچه هزینههای مالی شما را نگهداری میکند. این اپلیکیشن مدیریت هزینه های مالی امکان گردآوری همه رسیدها را در یک پوشه «دراپباکس» (Dropbox) فراهم میسازد و سپس میتوانید با کلیک روی یک دکمه آنها را به صورت ماهانه تنظیم کنید.
اپلیکیشنی که قصد ساخت آن را داریم به طور خاص زمانی مفید است که میخواهید هزینههای شخصی خود را حسابداری کنید چون به صورت معمول این کار را به شکل ماهانه انجام میدهیم. اینکه همه هزینههای مالی انجام شده طی یک ماه را یک جا و در یک پوشه واحد گردآوری کنیم، موجب صرفهجویی زیادی در زمانمان میشود.
در این راهنما موارد زیر بررسی شدهاند:
- ایجاد یک حساب دراپباکس و راهاندازی محیط توسعه پروژه
- ایجاد UI با استفاده از جاوا اسکریپت خالص که شامل مراحل واکشی دادهها، رندر کردن عناصر، مدیریت مقدماتی «حالت» (State) و ناوبری ساده است.
- برخی متدهای API دراپباکس برای دریافت و جابجایی فایلها نیز مورد استفاده قرار میگیرند.
راهاندازی دراپباکس
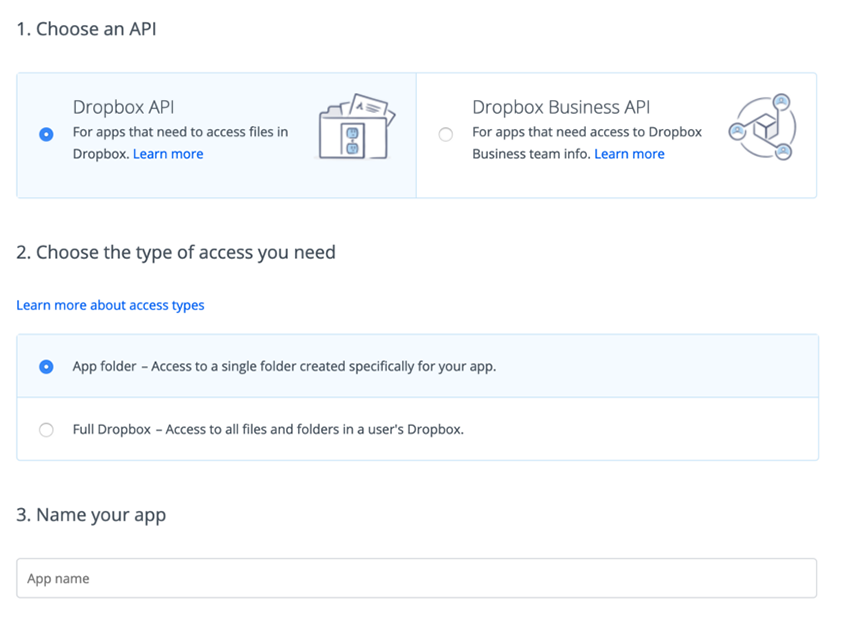
برای ساختن اپلیکیشنی بر مبنای دراپباکس، ابتدا باید یک حساب دراپباکس (+) داشته باشید. پس از این که در این وب سایت ثبت نام کردید، به بخش توسعهدهندگان (+) بروید. در این بخش در منوی سمت چپ داشبورد گزینه My apps را انتخاب کرده و روی Create app کلیک کنید.
تنظیمات زیر را انتخاب کرده و نام یکتایی برای اپلیکیشن خود انتخاب کنید.
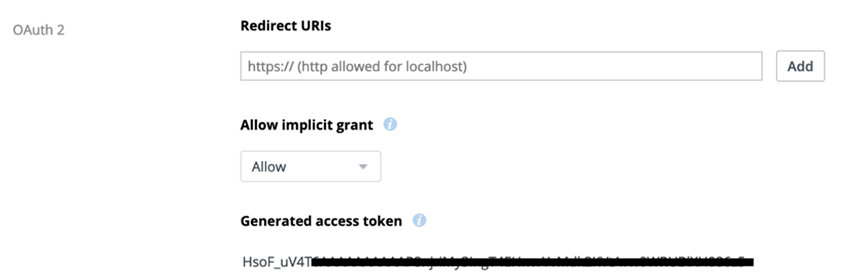
در داشبورد، به بخش OAuth 2 زیر Generated access token بروید و روی دکمه Generate کلیک کنید تا یک accessToken برای API به دست آورید. این توکن دسترسی را برای استفاده آتی ذخیره کنید.
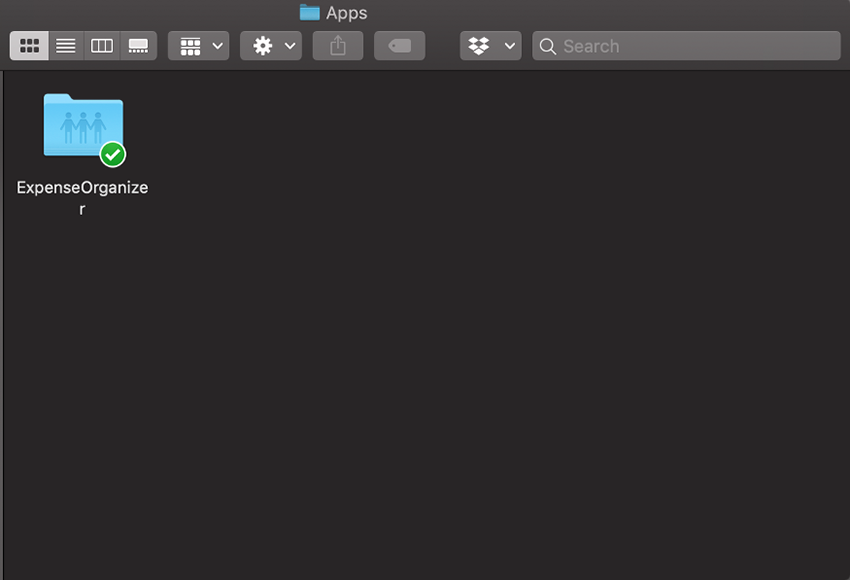
اکنون میتوانیم اپلیکیشن دسکتاپ دراپباکس (+) را نصب کنیم. با استفاده از اطلاعات احراز هویت جدید که به دست آوردید وارد اپلیکیشن شوید تا بتوانید پوشهای را که همان نام اپلیکیشن اخیراً ایجادشده را دارد مشاهده میکنید. ما در این مقاله از نام ExpenseOrganizer استفاده کردهایم.
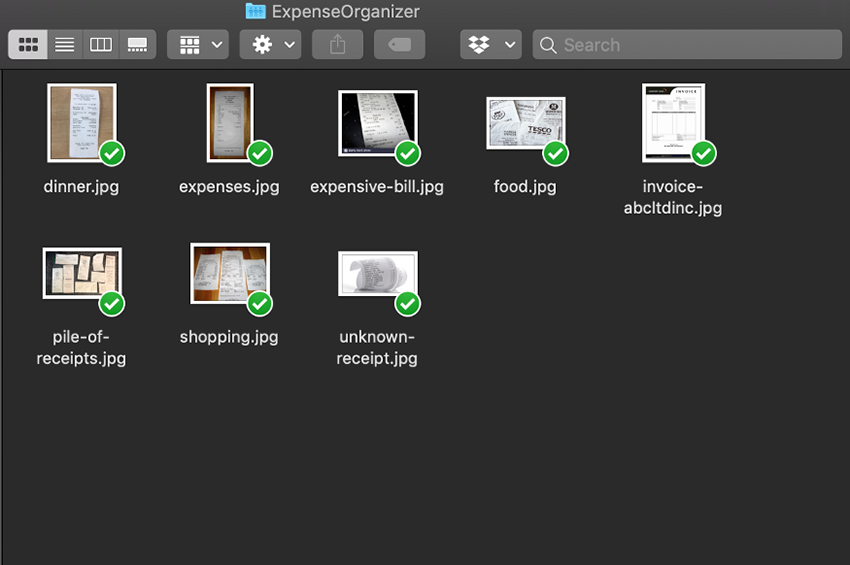
برخی رسیدها و فاکتورهای خود را در این پوشه قرار دهید تا بتوانید از طریق API به آنها دسترسی داشته باشید و در زمان اتمام پروژه آنها را در پوشههای مشخصی دستهبندیشدهای به صورت زیر داشته باشید:
راهاندازی کدبیس
اکنون باید کدبیس خود را راهاندازی کنیم. ما از سادهترین ساختار ممکن استفاده میکنیم که یک فایل index.html با لینکهای به فایل جاوا اسکریپت و یک استایلشیت است. همچنین باید یک نام برای اپلیکیشن خود در تگ <title> قرار دهیم.
نکته: کد نهایی این راهنما را میتوانید در این صفحه (+) مشاهده کنید و میتوانید در صورت علاقه آن را کلون کنید. با این حال باید کلید API دراپباکس خود را به پروژه اضافه کنید تا کار کند.
نصب و افزودن دراپباکس
اکنون باید کتابخانه دراپباکس را در پروژه خود نصب کنیم. به طور معمول به این منظور باید کاری مانند زیر انجام دهیم:
npm install dropox # or yarn add dropbox
با این حال در کد Scrimba که در بخش قبل معرفی کردیم، ما صرفاً کتابخانه دراپباکس را به صورت یک وابستگی در نوار کناری چپ اضافه کردهایم چون روش افزودن پکیجهای npm در Scrimba چنین است.
گام بعدی ایمپورت کردن دراپباکس و ایجاد یک وهله از کلاس Dropbox است. ما آن را dbx مینامیم و توکن خود را به آن ارسال میکنیم و کتابخانه منتخبمان را که در این مورد fetch است واکشی میکنیم. اگر ترجیح میدهید از axios با هر کتابخانه واکشی دیگر استفاده کنید، میتوانید از آن استفاده کنید و هیچ مشکلی وجود ندارد.
دریافت و نمایش هزینهها
در این بخش مراحلی که برای دریافت و نمایش هزینهها مورد نیاز است را مورد بررسی قرار میدهیم.
واکشی کردن دادهها
برای نمایش دادهها در اپلیکیشن باید ابتدا آنها را واکشی کنیم. بدین منظور رسیدهایی که در پوشه دراپباکس خود داریم را دریافت میکنیم.
به این منظور میتوانیم از متد ()filesListFolder استفاده کنیم. این متد نام یک پوشه را میگیرد و یک Promise بازگشت میدهد که وقتی resolve شود، محتوای پوشه را در اختیار ما قرار میدهد. البته این متد یک فوت کوزهگری دارد، زیرا برای تعیین یک مسیر ریشه (پوشه مبنایی که در آن هستیم) باید یک رشته خالی به صورت ‘ ‘ بنویسیم و نوشتن آن به صورت ‘/’ صحیح نیست.
زمانی که این متد را برای بازیابی فایلها از حساب دراپباکس فراخوانی کنیم، باید چیزی مانند تصویر زیر ببینیم:

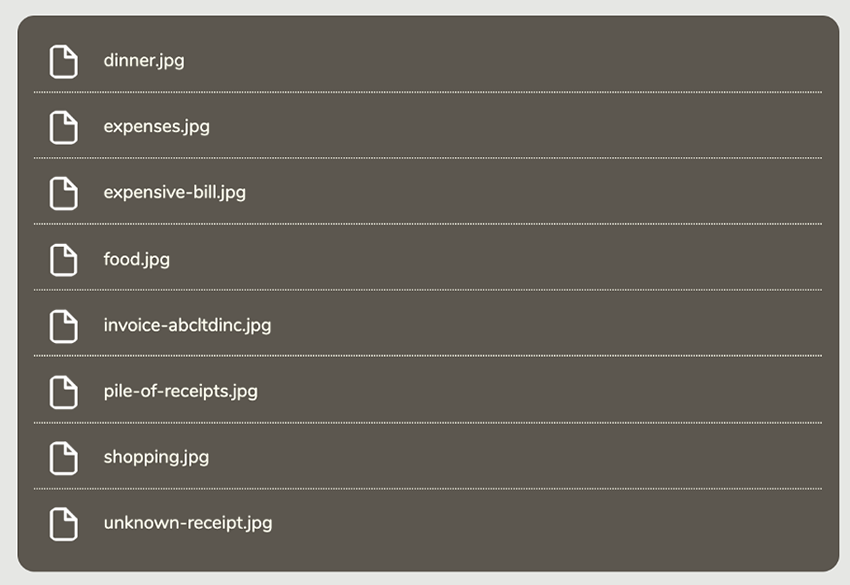
بنابراین ما یک آرایه entries داریم که آرایهای از شیءها است. هر شیء در آرایه entries، فایل ما (و در ادامه برخی از آنها میتوانند پوشههایی باشند که دادههایمان را در آنها سازماندهی میکنیم) به همراه تگهای tag ،name ،id و مشخصههای زیاد دیگر ارائه شده است. اینک تابعی مینویسیم که هر فایل را نمایش میدهد. tag مشخصهای است که نوع مدخل بازیابی شده را مشخص میکند که یک file یا یک folder است.
زمانی که همه فایلها را واکشی کردیم، آنها را در اپلیکیشن خود ذخیره میکنیم. ما میتوانیم شیئی به نام state برای انجام این کار بسازیم. همچنین میتوانیم آرایهای داشته باشیم که files را نگهداری کند و یک رشته نیز بسازیم که رد rootPath ما را ذخیره کند.
رندر کردن دادهها
یکی از روشهای رندر کردن دادهها این است که یک لیست نامرتب <ul> به کد HTML خود اضافه کنیم، آن را با جاوا اسکریپت انتخاب کرده و با فایلهای واکشی شده از دراپباکس مقداردهی کنیم. در این مرحله یک placeholder به صورت Loading… به فایل index.html خود اضافه میکنیم که به محض نمایش فایلهای واکشی شده بازنویسی خواهد شد.
اینک میتوانیم fileListElem را بسازیم که لیست نامرتب را انتخاب میکند.
ما میتوانیم همه فایلهای مرتبسازی شده به صورت الفبایی را به fileListElem.innerHTML اضافه کنیم تا مطمئن شویم که پوشهها را ابتدا قرار دادهایم. سپس هر پوشه و فایل را با استفاده از (”)join به یک <id> نگاشت (map) میکنیم تا از رندر کردن آرایه به جای رشته جلوگیری کنیم.
اما در این مرحله هیچ چیز روی صفحه نمایش نمییابد. دلیل این مسئله آن است که باید دادهها را واکشی کرده و سپس فایلها را با ()renderFiles رندر کنیم. در ادامه یک تابع کمکی ()init به این منظور میسازیم.
میتوان حالت را استخراج و بهروزرسانی کرده و ()renderFiles را در یک متد جداگانه درج کرد.
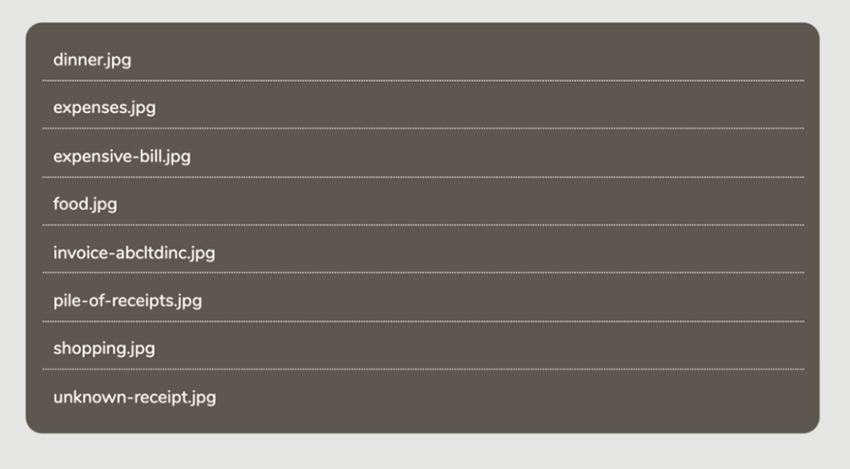
اکنون ()init را به انتهای فایل index.js اضافه میکنیم تا کل فرایند راهاندازی شده و فایلها نمایش پیدا کنند. بدین ترتیب لیست فایلهای ما نمایش مییابد گرچه کمی خلوت به نظر میرسد.
میتوان آن را بهبود بخشید و برای این لیست آیتمها یک آیکون پوشه و فایل پیشفرض قرار داد.
برای این که همه چیز زیباتر به نظر برسد، یک فایل به نام icon.js میسازیم و آیکونهای base64 SVG را آنجا اضافه میکنیم. دلیل استفاده از این نوع آیکون آن است که کاربرد آنها در این راهنما راحتتر است و دیگر نیازی به رفتن به جای دیگر و دانلود کردن آنها وجود ندارد.
اینک میتوانیم آیکونها را در فایل index.js ایمپورت کنیم:
در این مرحله map. را در renderFiles خود بهروزرسانی میکنیم تا آیکونهای جدید را شامل شود.
اکنون فایل ما زیباتر به نظر میرسد.
سازماندهی فایلها و پوشهها
قابلیت اصلی اپلیکیشن ما در این است که با یک کلیک همه فایلها درون پوشه جابجا میشوند و بر حسب سال و سپس درون هر پوشه بر حسب ماه سازماندهی میشوند. قبل از هر چیز باید یک دکمه در فایل index.js بسازیم.

در وهله دوم مقداری کد جاوا اسکریپت به آن اضافه میکنیم.
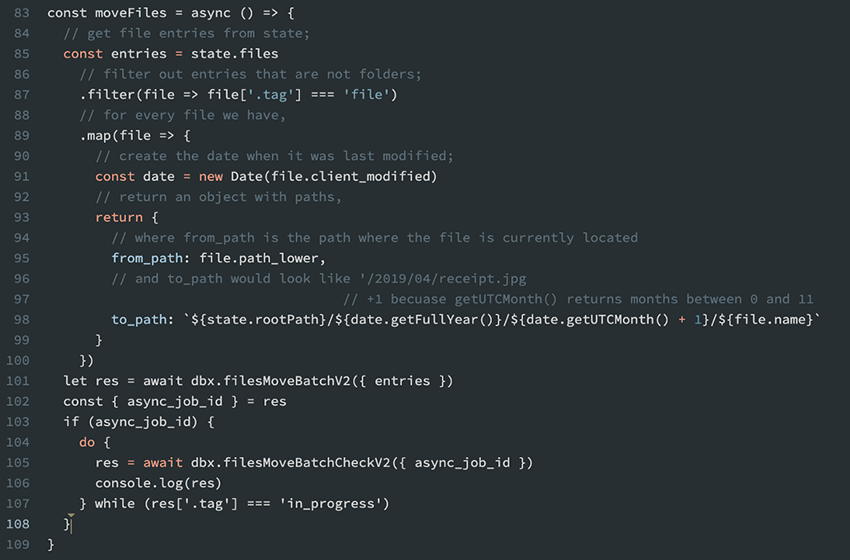
ما در انتهای این راهنما مجدداً به سراغ این دکمه میآییم تا تابعی که فایلها را جابجا میکند را تکمیل کنیم. برای جابجایی فایلها میتوانیم از ()filesMoveBatchV2 استفاده کنیم. این متد فایلها را به صورت دستهای از یک پوشه به پوشه دیگر جابجا میکند. در این مورد ما میخواهیم فایلها را از پوشه root به پوشههای با نام مجزا جابجا کنیم.
این متد زمانی که به صورت بخشی از تابع async استفاده شود، بهترین پیادهسازی خود را خواهد داشت.
این متد entries را میپذیرد که آرایهای از شیءها است و شامل مشخصههای from_path و to_path است.
()filesMoveBatchV2 اگر فراخوانی بیدرنگ موفق باشد و در واقع فایلهای معدودی برای پردازش ارائه شده باشند، مقدار success بازگشت میدهد.
با این حال در مورد حجم جابجایی بالا، شیئی به همراه یک مشخصه به نام async_job_id بازگشت میدهد و معنی آن این است که فراخوانی شما اجرا شده است و باید آن را در مرحله بعدی یعنی زمانی که تکمیل شده و دیگر در حالت in_progress نیست، با فراخوانی filesMoveBatchCheckV2 بررسی کنیم.
اینک مسیرهای صحیح را برای شیء entries پیادهسازی میکنیم و آن را به ()moveFiles اضافه میکنیم.
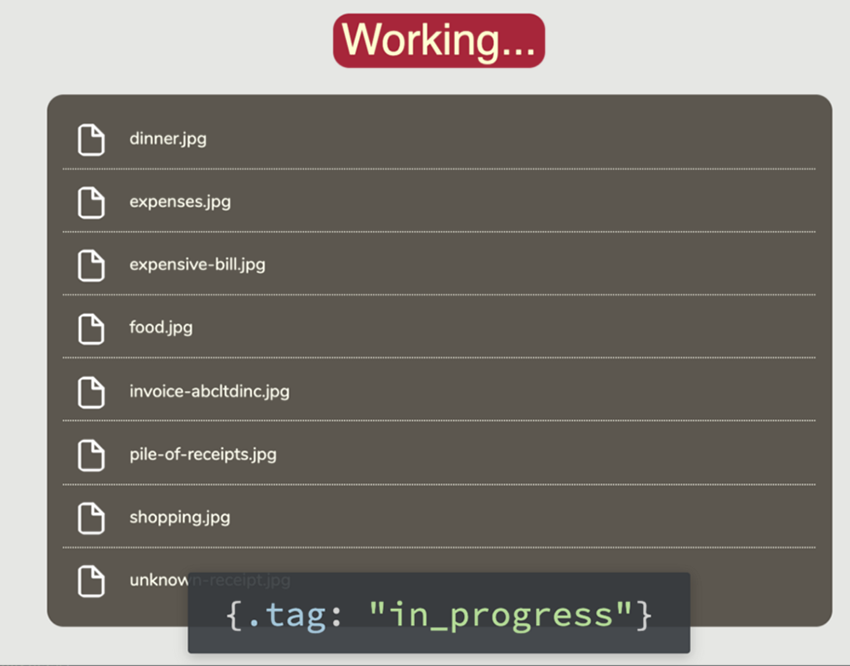
برای تکمیل این قابلیت باید ()moveFiles را به دکمه Organise وصل کنیم. همچنین خوب است که متن دکمه را طوری بهروزرسانی کنیم که نشان دهد پردازش جابجایی فایلها آغاز شده و در زمان اتمام کار به حالت عادی بازگردانیم.
اکنون وقتی روی دکمه کلیک کنیم، میبینیم که تغییریافته و پیام in_progress در لاگ console دیده میشود. این صرفاً برای ما است تا ببینیم که دراپباکس فایلها را جابجا میکند.
زمانی که کار پایان یافت، پوشه سالانه به دست میآید.

چنان که میبینید همه رسیدهای مثال ما مربوط به یک سال هستند. برای این که بتوانید به داخل پوشه آنگاه کنید باید بتوانید روی آنها کلیک کنید و به این منظور باید قابلیت ناوبری را تکمیل کرده باشیم. در ادامه به پیادهسازی بخش ناوبری اپلیکیشن خود میپردازیم.
ناوبری در اپلیکیشن
ناوبری در دراپباکس عملاً شبیه به ناوبری در پوشههای فایل اکسپلورر در ویندوز یا نرمافزار Finder روی سیستمهای مک است. تنها چیزی که لازم داریم این است که پوشهای که در آن قرار داریم را عوض کنیم. در ادامه ابتدا این فرایند را به صورت دستی بررسی میکنیم و سپس کد آن را نیز مینویسیم تا پردازش به صورت خودکار اجرا شود.
اگر rootPath را در state تغییر دهیم و صفحه را بارگذاری مجدد کنیم:
همه فایلهای آوریل 2019 را به دست میآوریم:

یک بار دیگر state را به صورت دستی بهروزرسانی میکنیم تا به پوشه آوریل یعنی ماه شماره 4 برویم و صفحه را بهروزرسانی میکنیم:
بدین ترتیب همه رسیدها را مشاهده میکنید:
برای این که این فرایند کمی سادهتر شود، باید یک فیلد input اضافه کنیم، به طوری که بتوانیم نام پوشهای که میخواهیم به آن برویم را وارد کنیم و نیاز نباشد که هر بار از hard-code استفاده کنیم. بدین ترتیب فیلد input را درون یک عنصر <form> قرار میدهیم که در ادامه مشاهده میکنید.
همچنین در ادامه صفحه خود را با طراحی یک هدر زیبا در index.html زیباتر میسازیم.
اینک صفحه اپلیکیشن ما به صورت زیر در آمده است:
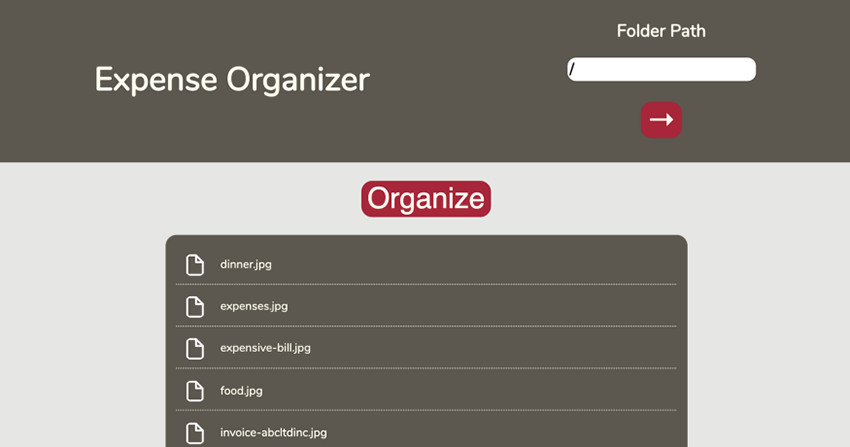
چنان که مشاهده میکنید، یک دکمه نیز برای تأیید مسیری که میخواهیم برویم تعبیه کردهایم. درون فایل index.js تلاش میکنیم state را به همان چیزی که بود بازگردانیم.
همچنین کمی کد جاوا اسکریپت اضافه میکنیم تا rootPath را با مقادیری از فیلد input بهروزرسانی کنیم:
بدین ترتیب کار ما به پایان رسیده و ناوبری اپلیکیشن عملیاتی شده است.

سخن پایانی
بدین ترتیب ما موفق شدیم با پیگیری مراحل معرفی شده در این راهنما اپلیکیشنی بسازیم که به رسیدهای مالی ما سر و سامان میبخشد. این موفقیت بزرگی محسوب میشود. اگر همچنان حس میکنید که موفق نشدهاید همه مفاهیم مطرحشده در این راهنما را به خوبی متوجه نشدهاید پیشنهاد میکنیم به صفحه کد منبع این اپلیکیشن (+) نیز سری بزنید تا توضیحات را با تفصیل بیشتری مشاهده کنید.
منبع: فرادرس