طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیپیاده سازی درخت دودویی در جاوا — راهنمای جامع
در این مقاله به بررسی روش پیادهسازی درخت دودویی در جاوا میپردازیم. ما در این راهنما از یک درخت دودویی مرتب استفاده میکنیم که شامل مقادیر عدد صحیح (int) است.
درخت دودویی در جاوا
درخت دودویی یک ساختمان داده بازگشتی است که در آن هر گره حداکثر میتواند دو فرزند داشته باشد. نوع رایجی از درخت دودویی به نام درخت جستجوی دودویی شناخته میشود که در آن هر گره مقداری دارد که بزرگتر یا مساوی مقادیر گره زیردرخت چپ خود است و کمتر یا مساوی مقادیر گره در زیردرخت راستش است.
در زیر بازنمایی مختصری از این نوع درخت دودویی را میبینید:
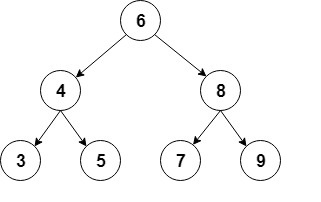
ما برای پیادهسازی این درخت از یک کلاس کمکی Node استفاده میکنیم که مقادیر int را ذخیره میکند و ارجاعی به هر فرزند نگه میدارد:
در ادامه گره آغازین درخت را که «ریشه» (Root) نامیده میشود اضافه میکنیم:
عملیات رایج
در این بخش برخی از رایجترین عملیات که میتوان روی یک درخت دودویی اجرا کرد را بررسی میکنیم.
درج عنصر
نخستین عملیاتی که بررسی میکنیم درج گرههای جدید در درخت دودویی است. ابتدا باید مکانی را بیابیم که میخواهیم گره جدید را به صورت ترتیبی اضافه کنیم تا کل درخت مرتب باقی بماند. برای درج گره جدید قواعد زیر را با آغاز از گره ریشه پیگیری میکنیم:
- اگر مقدار گره جدید کمتر از گره کنونی باشد، به فرزند سمت چپ میرویم.
- اگر مقدار گره جدید بزرگتر از گره جاری باشد، به فرزند سمت راست میرویم.
- زمانی که گره کنونی null باشد، به گره رسیدهایم و میتوانیم گره جدید را در این موقعیت درج کنیم.
ابتدا یک متد بازگشتی برای انجام این عملیات درج ایجاد میکنیم:
سپس متد عمومی را ایجاد میکنیم که فرایند بازگشتی را از گره ریشه آغاز میکند:
اکنون بررسی میکنیم که چگونه میتوانیم از این متد برای ایجاد درخت در مثال خود استفاده کنیم:
یافتن یک عنصر
در این بخش یک متد اضافه میکنیم تا بررسی کنیم آیا درخت شامل مقدار خاصی است یا نه. همانند عملیات قبل ابتدا یک متد بازگشتی مینویسیم تا درخت را پیمایش کنیم:
در این متد با مقایسه مقدار مورد نظر با مقادیر گره جاری به جستجوی آن میپردازیم و سپس بسته به نتیجه مقایسه، ادامه کار را در فرزندان سمت چپ یا راست ادامه میدهیم.
سپس متد عمومی را ایجاد میکنیم که از گره ریشه آغاز میشود.
اکنون میتوانیم یک تست ساده بنویسیم که تأیید کند آیا درخت واقعاً شامل عنصر درج شده است یا نه.
همه گرههای اضافه شده باید در درخت موجود باشند.
حذف یک عنصر
عملیات رایج دیگری که روی درختهای دودویی استفاده میشود، حذف یک گره از درخت است. ابتدا باید گرهی را که میخواهیم حذف کنیم به روشی که قبلاً معرفی کردیم بیابیم:
زمانی که گره مورد نظر را یافتیم، 3 حالت متفاوت وجود دارد:
- این گره هیچ فرزندی ندارد: این سادهترین حالت است و کافی است که گره را در والدینش با مقدار null عوض کنیم.
- گره مورد نظر دقیقاً یک فرزند دارد: در این حالت در گره والد، این گره را با آن فرزند عوض میکنیم.
- گره مورد نظر دو فرزند دارد: این پیچیدهترین حالت است، چون نیازمند سازماندهی مجدد درخت است.
در ادامه شیوه پیادهسازی حالت نخست را میبینید که در آن گره مورد نظر یک برگ است:
اکنون به بررسی حالتی میپردازیم که گره یک فرزند دارد:
در کد فوق یک فرزند غیر تهی بازگشت میدهیم تا بتواند به گره والد انتساب یابد.
در نهایت باید حالتی را مدیریت کنیم که گره دو فرزند دارد. در این حالت ابتدا باید گرهی را که جایگزین گره حذف شده خواهد شد بیابیم. به این منظور از کوچکترین گرهی که در زیردرخت سمت راست گره مورد نظر قرار دارد استفاده میکنیم:
سپس کمترین مقدار را به گرهی که باید حذف شود انتساب میدهیم و سپس آن را از زیردرخت راست حذف میکنیم.
در نهایت متد عمومی را ایجاد میکنیم که فرایند حذف را از ریشه آغاز میکند:
اکنون بررسی میکنیم که آیا عملیات حذف مطابق انتظار پیش میرود یا نه.
پیمایش یک درخت
در این بخش روشهای مختلف پیمایش یک درخت را بررسی میکنیم و جستجوهای «عمق-اول» و «سطح-اول» را بررسی میکنیم. ما از همان درختی که قبلاً استفاده کردیم بهره میگیریم و ترتیب پیمایش را در هر حالت نمایش میدهیم.
جستجوی عمق-اول
جستجوی عمق-اول نوعی از پیمایش است که ابتدا تا حد امکان به عمق درخت میرود همه فرزندان را بررسی میکند و سپس به کاوش همنیاها میپردازد. چند روش برای اجرای جستجوی عمق-اول وجود دارد که به صورت پیشترتیبی، میانترتیبی و پسترتیبی نامیده میشوند. پیمایش میانترتیبی شامل بازدید زیردرخت چپ در وهله اول است و سپس گره ریشه بازدید میشود و در نهایت زیردرخت راست مورد بازدید قرار میگیرد.
اگر این متد را فراخوانی کنیم، پیمایش میانترتیبی در کنسول به صورت زیر نمایش پیدا میکند:
3 4 5 6 7 8 9
در پیمایش پیشترتیبی ابتدا گره ریشه مورد بازدید قرار میگیرد، سپس زیردرخت چپ و در نهایت زیردرخت راست بازدید میشود:
خروجی پیمایش پیشترتیبی در کنسول به صورت زیر خواهد بود:
6 4 3 5 8 7 9
در روش پیمایش پسترتیبی، ابتدا زیردرخت چپ مورد بازدید قرار میگیرد و سپس زیردرخت راست و در نهایت گره ریشه بازدید میشود:
خروجی پیمایش پسترتیبی گرهها به صورت زیر است:
3 5 4 7 9 8 6
جستجوی سطح-اول
این نوع جستجو نیز یکی دیگر از روشهای رایج پیمایش درخت است و در آن ابتدا همه گرههای یک سطح مورد بازدید قرار میگیرند و سپس به سطح بعدی مراجعه میشود. این نوع از پیمایش به نام پیمایش ترتیب سطح نیز نامید میشود و در آن همه سطوح درخت با آغاز از ریشه و از چپ به راست مورد بازدید قرار میگیرد.
برای پیادهسازی این نوع جستجو از «صف» (Queue) استفاده میکنیم تا گرهها را در هر سطح به ترتیب حفظ کنیم. به این منظور هر گره را از لیست استخراج و مقدار آن را پرینت میکنیم، سپس فرزندانش را به صف اضافه میکنیم:
در این حالت، ترتیب گرهها به صورت زیر خواهد بود:
6 4 8 3 5 7 9
سخن پایانی
در این مقاله با شیوه پیادهسازی درخت دودویی در جاوا و رایجترین عملیات مربوط به آن آشنا شدیم. مانند همیشه همه کدهای معرفی شده در این مقاله را میتوانید در این آدرس گیتهاب (+) مشاهده کنید.
منبع: فرادرس
ساختمان های داده در جاوا اسکریپت — به زبان ساده
امروزه شاهد هستیم که منطق تجاری وباپلیکیشنها به مرور از بکاند به سمت فرانتاند در حال جابجایی است و از این رو خبرگی در زمینه «مهندسی فرانتاند» از هر زمان دیگری اهمیت بیشتری یافته است. مهندسان فرانتاند امروزه به کتابخانههای view از قبیل React وابسته هستند تا بهرهوری را بالا ببرند. کتابخانههای view به نوبه خود به کتابخانههای «حالت» (State) مانند Redux وابسته هستند تا دادهها را مدیریت کنند. در مجموع ریاکت و ریداکس در پارادایم برنامهنویسی واکنشی مشارکت دارند که در آن UI در واکنش به تغییرهای داده اقدام به بهروزرسانی ریاکت میکند. در این مطلب به بررسی ساختمان های داده در جاوا اسکریپت خواهیم پرداخت.
در عصر حاضر بکاند به طور فزایندهای صرفاً به عنوان یک سرور API عمل کرده و نقاط انتهایی لازم برای بازیابی و بهروزرسانی دادهها را عرضه میکند. در واقع، بکاند صرفاً پایگاه داده را به فرانتاند فوروارد میکند و انتظار دارد که مهندسان فرانتاند همه منطق کنترلر را مدیریت کنند. محبوبیت رو به تزاید میکروسرویسها و GraphQL گواهی بر این روند رو به رشد است.
در حال حاضر انتظار میرود که مهندسان فرانتاند علاوه برداشتن درکی زیباییشناسانه از HTML و CSS، بر جاوا اسکریپت نیز مسلط باشند. از آنجا که ذخیره دادهها در سمت کلاینت به عنوان نسخههایی تکراری از پایگاه داده روی سرور تلقی میشود، کسب دانش دقیق از ساختمانهای داده رایج به امری ضروری تبدیل شده است. درواقع، سطح خبرگی یک مهندس را میتوان از توانایی وی برای تمییز زمان و چرایی استفاده از یک ساختمان داده، استنباط کرد.
برنامه نویسان بد از کد نگران هستند، اما برنامه نویسان خوب در مورد ساختمان داده و روابط آن دغدغه دارند.
– لینوس تروالدز، خالق لینوکس و گیت
در سطوح بالا اساساً سه نوع ساختمان داده وجود دارد: «پشته» (Stack)، «صف» (Queue) و ساختارهای شبیه آرایه که تنها تفاوتشان در شیوه درج و حذف آیتمها است. لیستهای پیوندی، درخت و گراف ساختمانهایی با گره هستند که به گرههای دیگر ارجاع میدهند. جداول هَش برای ذخیره و مکانیابی دادهها به تابعهای هش وابسته هستند.
برحسب پیچیدگی، پشتهها و صفها سادهترین ساختمانهای داده هستند و میتوانند از لیستهای پیوندی ساخته شوند. درختها و گرافها پیچیدهترین ساختمانهای داده هستند که مفهوم لیست پیوندی را بسط دادهاند. جداول هش نیاز دارند از این ساختمانهای داده برای کارکرد پایدار بهره بگیرند. برحسب کارایی، لیستهای پیوندی بهینهترین ساختمان داده برای ثبت و ذخیره دادهها محسوب میشوند، در حالی که جداول هش برای جستجو و بازیابی دادهها بالاترین کارایی را دارند.
در این مقاله برای توضیح علت و روشن ساختن زمان استفاده از هر کدام از این ساختمانهای داده از ترتیب این وابستگیها تبعیت خواهیم کرد.
پشته
بدیهی است که مهمترین پشته در جاوا اسکریپت «پشته فراخوانی» (call stack) است که هر زمان یک تابع را اجرا میکنیم آن را به دامنه تابع ارسال میکنیم. از نظر برنامهنویسی پشته فراخوانی صرفاً یک آرایه با دو عملیات اصلی یعنی push و pop است. عملیات push عناصری را به ابتدای آرایه اضافه میکند در حالی که عملیات pop عناصر را از همان مکان حذف میکند. به بیان دیگر پشته از پروتکل «ورودی اول، خروجی اول» به اختصار FIFO تبعیت میکند.
در ادامه مثالی از یک پشته را در کد جاوا اسکریپت میبینید. دقت کنید که میتوانیم ترتیب پشته را معکوس کنیم و انتهای پشته به ابتدا بیاید و ابتدا به انتها برود. در چنین حالتی میتوانیم از متدهای unshift و shift به ترتیب به جای عملیات push و pop استفاده کنیم.
زمانی که تعداد آیتمها افزایش پیدا میکند، push/pop به طور فزایندهای کارایی بیشتری نسبت به unshift/shift پیدا میکنند، زیرا در حالت دوم هر آیتم باید مجدداً اندیسگذاری شود، اما در حالت اول چنین الزامی وجود ندارد.
صف
جاوا اسکریپت یک زبان برنامهنویسی «رویداد-محور» (event-driven) است که امکان پشتیبانی از عملیات غیر مسدودساز را فراهم میسازد. مرورگر به صورت داخلی تنها یک نخ دارد که کل کد جاوا اسکریپت را روی آن اجرا میکند و از «صف رویداد» (event queue) برای صفبندی شنوندهها و از «حلقه رویداد» (event loop) برای گوش دادن به رویدادهای ثبت شده استفاده میکند. برای پشتیبانی از ناهمگامی در یک محیط تک نخی (برای صرفهجویی در منابع پردازنده و بهبود تجربه وب) تابعهای شنونده از صف خارج میشوند و تنها زمانی اجرا میشوند که پشته فراخوانی خالی شود. Promise-ها به این معماری رویداد-محور وابسته هستند که امکان اجرای کد ناهمگام به «سبک همگام» را فراهم میسازد و دیگر عملیات را مسدود نمیکند.
از نظر برنامهنویسی، صفها صرفاً آرایهای هستند که دو عملیات عمده یعنی unshift و pop دارند. unshift آیتمها را در انتهای آرایه صفبندی میکند در حالی که pop آنها را از ابتدای آرایه از صف خارج میکند. به بیان دیگر صفها از پروتکل «ورودی اول، خروجی اول» یا FIFO تبعیت میکنند. اگر جهت عوض شود میتوانیم unshift و pop را به ترتیب با push و shift عوض کنیم.
مثالی از کدنویسی صف در عمل به صورت زیر است:
لیستهای پیوندی
لیستهای پیوندی نیز همانند آرایهها به ذخیرهسازی عناصر داده با ترتیب متوالی میپردازند. اما لیستهای پیوندی به جای این که دادهها را اندیسگذاری کنند، از اشارهگر برای اشاره به عناصر دیگر بهره میگیرند. نخستین گره به نام head خوانده میشود در حالی که گره آخر tail نام دارد. در یک لیست پیوندی یکطرفه، هر گره تنها یک اشارهگر به گره بعدی دارد. در این وضعیت head جایی است که مسیر حرکت ما تا انتهای لیست از آنجا آغاز میشود. در لیست پیوندی دوطرفه، یک اشارهگر به گره قبلی نیز نگهداری میشود. از این رو میتوانیم از tail نیز آغاز کنیم و در جهت معکوس به سمت head حرکت کنیم.
در لیستهای پیوندی عملیات درج و حذف دارای زمان ثابتی است، زیرا میتواند صرفاً اشارهگرها را عوض کرد. اجرای عملیات مشابه در آرایهها دارای پیچیدگی زمانی خطی است، زیرا آیتمهای بعدی نیز باید جابجا شوند. ضمناً لیستهای پیوندی میتوانند تا جایی که فضا اجازه میدهد بسط یابند. با این وجود حتی آرایههای دینامیک که به طور خودکار تغییر اندازه میدهند نیز ممکن است به طور غیرمترقبهای پرهزینه شوند. البته همواره تعادلی بین این مزایا و معایب وجود دارد. برای گشتن به دنبال یک عنصر و ویرایش کردن آن در لیست پیوندی ممکن است لازم باشد کل طول لیست را بپیماییم که از نظر زمانی دارای پیچیدگی خطی خواهد بود. در حالی که با وجود اندیس در آرایهها چنین عملیاتی بسیار سادهتر است.
لیستهای پیوندی نیز همچون آرایهها میتوانند به صورت پشته عمل کنند. این کار به سادگی اجرا میشود بدین ترتیب که head به عنوان تنها مکان برای درج و حذف عناصر استفاده میشود. لیستهای پیوندی میتوانند به صوت صف نیز مورد استفاده قرار گیرند. این وضعیت با استفاده از یک لیست پیوندی دوطرفه میسر میشود که در آن عملیات درج در tail رخ میدهد و عملیات حذف در head انجام مییابد و یا برعکس. در مورد تعداد بالای عناصر، این روش پیادهسازی صف بسیار کارآمدتر از استفاده از آرایه است، زیرا عملیات shift و unshift در ابتدای آرایه زمان خطی دارند و نیازمند اندیسگذاری مجدد همه عناصر بعدی هستند.
لیستهای پیوندی در هر دو سمت کلاینت و سرور مفید هستند. در سمت کلاینت کتابخانههای مدیریت «حالت» (State) مانند ریداکس منطق میانافزاری خود را به روشی مانند لیست پیوندی سازماندهی میکنند. زمانی که اکشن ارسال میشود این کتابخانه آن را از یک میانافزار به دیگری pipe میکند و همین طور تا آخر میرود تا این که پیش از رسیدن به «کاهندهها» (Reducers) همه میانافزارها را بازدید کرده باشد. در سمت سرور فریمورکهای وب مانند Express نیز منطق میانافزاری خود را به روش مشابهی سازماندهی میکنند. زمانی که یک درخواست دریافت میشود، از یک میانافزار به دیگری pipe میشود تا این که یک پاسخ صادر شود.
نمونهای از لیست پیوندی دوطرفه را در مثال زیر ملاحظه میکنید:
درخت
«درخت» (Tree) شبیه به لیست پیوندی است به جز این که هر آیتم در آن به گرههای فرزند زیادی ارجاع میدهد و ساختاری سلسله مراتبی دارد. به بیان دیگر هر گره نمیتواند بیش از یک والد داشته باشد. «مدل شیء سند» (Document Object Model) یا به اختصار DOM چنین ساختاری است که ریشه آن گره html است که به گرههای body و head تقسیم میشود و سپس به همه تگهای آشنای خانواده html انشعاب مییابد. وراثت پروتوتایپی و ترکیببندی با استفاده از کامپوننتهای ریاکت نیز در پس زمینه، ساختارهای درخت را بازتولید میکنند. البته DOM مجازی ریاکت به عنوان یک بازنمایی درون حافظهای از DOM نیز ساختاری درختی دارد.
درخت جستجوی دودویی درخت خاصی است، زیرا در آن هر گره نمیتواند بیش از دو فرزند داشته باشد. فرزند چپ باید مقداری کمتر یا برابر با والد خود داشته باشد، در حالی که فرزند راست باید مقدار بزرگتری داشته باشد. درخت جستجوی دودویی به این ترتیب سازماندهی یافته و متعادل شده است و بنابراین میتوانیم در طی یک زمان لگاریتمی به دنبال هر آیتمی بگردیم، زیرا میتوانیم در هر تکرار نیمی از انشعاب باقیمانده را نادیده بگیریم. درج و حذف نیز میتواند در زمان لگاریتمی اجرا شود. به علاوه کوچکترین و بزرگترین مقدار میتواند به سادگی به ترتیب در برگهای انتهای سمت چپ و انتهای سمت راست مشاهده شود.
پیمایش درخت به دو شیوه افقی و عمودی اجرا میشود. «پیمایش عمق-اول» (Depth-First Traversal) یا به اختصار DFT در جهت عمودی صوت میگیرد و یک الگوریتم بازگشتی مناسبتر از نوع تکراری است. گرهها میتوانند به روشهای پیشترتیبی، میانترتیبی یا پسترتیبی پیمایش شوند. اگر لازم باشد ریشهها را پیش از بازرسی برگها بررسی کنیم، باید روش پیشترتیبی را انتخاب کنیم. اما اگر نیاز باشد که برگها قبل از ریشه بررسی شوند، باید از روش پسترتیبی استفاده کنیم. روش میانترتیبی نیز چنان که از نامش مشخص است امکان پیمایش گرهها به روش متوالی را فراهم میسازد. این مشخصه موجب شده است که درخت جستجوی دودویی برای مرتبسازی بهینه باشد.
در روش «پیمایش سطح-اول» (Breadth-First Traversal) که به اختصار BFT نامیده میشود، از جهتگیری افقی استفاده میشود و رویکرد تکرار مناسبتر از رویکرد بازگشتی است. این پیمایش نیازمند استفاده از صف برای ردگیری همه گرههای فرزند در هر تکرار است. با این حال، حافظه مورد نیاز برای چنین صفی ممکن است سنگین باشد. اگر شکل درخت بیشتر عریض است تا عمیق، BFT گزینه بهتری نسبت به DFT محسوب میشود. ضمناً مسیری که BFT بین هر دو گره طی میکند، کوتاهترین مسیر ممکن است. نمونهای از کد درخت جستجوی دودویی را در ادامه ملاحظه میکنید:
گراف
اگر در یک درخت امکان این باشد که هر گره بیش از یک والد داشته باشد، آن را گراف مینامیم. یالی که گرهها را در گراف به هم وصل میکند، میتواند جهتدار یا غیر جهتدار، وزندار یا بیوزن باشد. یالهای دو جهته و وزندار، شبیه بُردار هستند.
وراثتهای چندگانه به شکل Mixin و اشیای داده که روابط چند به چند دارند ساختمانهای داده گراف را ایجاد میکنند. یک شبکه اجتماعی و خود اینترنت نیز گراف محسوب میشوند. پیچیدهترین گراف برحسب ماهیت، مغز انسان است که الگوریتمهای شبکه عصبی تلاش میکنند با شبیهسازی آن به ماشینها نوعی فراهوشمندی بدهند.
نمونهای از کد گراف به صورت زیر است:
جداول هش
جداول هش ساختمانهای شبه دیکشنری هستند که از جفت کلید/مقدار استفاده میکنند. مکان حافظه برای هر جفت بر اساس تابع هش تعیین میشود که یک کلید میپذیرد و آدرسی که جفت باید درج و بازیابی شود را بازمیگرداند. در صورتی که دو یا چند کلید به آدرس یکسانی تبدیل شوند، تصادم رخ میدهد. برای افزایش پایداری باید getter و setter، این رویدادها را پیشبینی کنند و اطمینان حاصل کنند که همه دادهها میتوانند بازیابی شوند و هیچ دادهای بازنویسی نمیشوند. به طور معمول linked lists سادهترین راهحل هستند. داشتن جداول بسیار بزرگ نیز در این زمینه کمک زیادی خواهد کرد.
اگر بدانیم که آدرسهای ما توالیهای عدد صحیح هستند، میتوانیم صرفاً از Arrays برای ذخیرهسازی جفتهای کلید-مقدار استفاده کنیم. برای نگاشتهای آدرس پیچیدهتر میتوانیم از Maps یا Objects استفاده کنیم. جداول هش به طور میانگین زمان ثابتی برای درج و جستجو دارند. به دلیل تصادم و تغییر اندازه، این هزینه ناچیز میتواند به صورت زمان خطی رشد کند. با این حال در عمل میتوانیم تصور کنیم که تابعهای هش به قدر کافی هوشمند هستند که تصادم و تغییر اندازه نادر و ارزان است. اگر کلیدها نماینده آدرسها باشند و زمانی که به هیچ هش کردن نیاز نباشد، میتوان از یک object literal استفاده کرد. البته همواره تعادلی بین مزیتها و معایب وجود دارند. تناظر ساده بین کلید و مقدار و ارتباط ساده بین کلیدها و آدرسها، روابط بین دادهها را قربانی میکند. از این رو جداول هش برای مرتبسازی دادهها اصلاً بهینه نیستند.
اگر کفه تصمیم شما به سمت بازیابی سنگینتر است تا ذخیرهسازی، هیچ ساختمان داده دیگری نمیتواند سرعتی که جداول هش برای گشتن، درج، و حذف ارائه میکنند در اختیار شما قرار دهد. در نتیجه هیچ جای شگفتی نیست که از جداول هش تقریباً در همه جا استفاده میشود. از پایگاه داده تا سرور و کلاینت، جداول هش و به طور خاص تابعهای هش برای عملکرد و امنیت اپلیکیشنهای نرمافزاری حیاتی هستند. سرعت کوئریهای پایگاه داده تا حدود زیادی به نگهداری اندیسهای جدولی که به رکوردهای مرتبشده اشاره میکنند وابسته است. بدین ترتیب جستجوهای دودویی میتوانند در زمان لگاریتمی اجرا شوند که ارتقای عملکرد عظیمی به خصوص در حوزه کلانداده محسوب میشود.
در هر دو سمت کلاینت و سرور کتابخانههای محبوب زیادی وجود دارند که از memorization برای بیشینهسازی عملکرد بهره میگیرند. با حفظ سوابق ورودیها و خروجیها در جدول هش، تابعها برای ورودیهای یکسان صرفاً یک بار اجرا میشوند. کتابخانه محبوب Reselect از این راهبرد کَش کردن برای بهینهسازی تابعها در اپلیکیشنهایی که از ریداکس استفاده میکنند بهره میگیرد. در واقع موتور جاوا اسکریپت در پس زمینه از جداول هش به نام heap برای ذخیرهسازی همه variables و primitives که ایجاد کردیم بهره میگیرد. این موارد از طریق اشارهگرها به پشته فراخوانی مورد دسترسی قرار میگیرند.
خود اینترنت برای عملکرد صحیحش بر مبنای الگوریتمهای هش کردن بنا شده است. ساختار اینترنت به طوری است که هر رایانهای میتواند با رایانه دیگر از طریق شبکهای از دستگاههای به هم متصل ارتباط برقرار کند. هر زمان که یک دستگاه وارد اینترنت میشود خود به یک روتر تبدیل میشود که جریان دادهها میتوانند از آن بگذرند. اما این یک شمشیر دو لبه است. معماری نامتمرکز به این معنی است که هر دستگاهی در شبکه میتواند بستههای داده را مورد شنود قرار دهد و آنها را که رله میکند دستکاری نماید. تابعهای هش مانند MD5 و SHA256 نقشی حیاتی در جلوگیری از چنین حملههای «مرد میانی» (Man-in-the-Middle) دارند. تجارت الکترونیک در بستر HTTPS تنها به این جهت امن است که این تابعهای هش مورد استفاده قرار میگیرند.
فناوری بلاکچین که از اینترنت الهام گرفته به دنبال این است که ساختار وب را در سطح پروتکل، متنباز کند. بلاکچین با بهرهگیری از تابعهای هش برای ایجاد «اثرانگشتهای تغییرناپذیر» (immutable fingerprints) برای هر بلوک داده کاری کرده است که اساساً کل پایگاه داده امکان حضور آزادانه روی وب برای همه افرادی که قصد مشارکت دارند پیدا کند. بلاکچین از نظر ساختاری صرفاً لیستهای پیوندی یکطرفهای از درختهای دودوییِ هشهای رمزنگاریشده است.
هش کردن چنان جنبه رمزنگاریشدهای دارد که با استفاده از آن میتوان یک پایگاه داده از تراکنشهای مالی را طوری ایجاد و بهروزرسانی کرد که هر کس به آن دسترسی آزاد داشته باشد. نتیجه ضمنی خارقالعاده این وضعیت قدرت شگفتانگیز خلق پول بوده است. کاری که روزگاری صرفاً تحت سلطه دولتها و بانکهای مرکزی بود؛ اما امروزه هر کس میتواند پول خاص خود را خلق کند. این همان بینش کلیدی بود که بنیانگذار «اتریوم» (Ethereum) و مبدع ناشناس بیتکوین درک کردهاند.
همچنان که رفتهرفته پایگاههای داده بیشتری باز میشوند، نیاز به مهندسان فرانتاند خبره که بتوانند همه سطوح پیچیدگیهای رمزنگارانه سطح پایین را تجزیه کرده و همچنین ترکیب کنند، بیشتر حس میشود. در چنین آیندهای عامل تمایز اصلی تجربه کاربری خواهد بود.
در کد زیر میتوانید نمونهای از جدول هش را ملاحظه کنید:
سخن پایانی
همچنان که منطق تجاری به صورت فزایندهای در حال جابجایی از سمت سرور به سمت کلاینت است، لایه داده در فرانتاند رواج بیشتری مییابد. مدیریت صحیح این لایه نیازمند چیرگی بر ساختمانهای داده است که منطق تجاری بر مبنای آن شکل میگیرد. هیچ ساختمان دادهای برای همه موقعیتها کامل محسوب نمیشود، چون بهینهسازی برای یک مشخصه عموماً موجب ضعف در مشخصه دیگر میشود. برخی ساختارها در ذخیرهسازی دادهها کارآمدتر هستند، در حالی که برخی دیگر برای جستجوی دادهها کارایی بیشتری دارند. به طور معمول، یکی از اینها قربانی دیگری میشود.
در یک انتها، لیستهای پیوندی برای ذخیرهسازی بهینه هستند و میتوان پشته و صف را با زمان خطی ساخت. در سمت دیگر هیچ ساختمان دیگری نمیتواند با سرعت جستجوی جدول هش (زمان ثابت) برابری کند. ساختمانهای درخت در میانه این طیف (زمان لگاریتمی) قرار میگیرند و تنها یک گراف میتواند ماهیت پیچیدهترین ساختار طبیعی یعنی مغز انسان را (با زمان چندجملهای) نمایش دهد. کسب مجموعه مهارتهای مورد نیاز برای تمییز زمان و توضیح چرایی استفاده از یک ساختمان داده نشانهای از تواناییهای یک مهندس کاملاً خبره است.
نمونههایی از این ساختمانهای داده را میتوانید هر کجا از پایگاه داده، تا سرور، تا کلاینت و حتی خود زبان جاوا اسکریپت ببینید. این ساختمانهای داده سوییچهای روشن و خاموش روی تراشههای سیلیکونی را به اشیای شبه زندهای تبدیل میکنند. گرچه این اشیا صرفاً دیجیتالی هستند اما تأثیری که روی جامعه دارند کاملاً شگرف است. این که شما امکان مطالعه این مقاله به صورت امن و رایگان را به دست آوردهاید، مدیون معماری خارقالعاده اینترنت و سازماندهی دادههای آن است. با این حال این تنها یک شروع است. هوش مصنوعی و بلاکچینهای نامتمرکز در دهههای آتی ماهیت انسان و نقش موسسههایی که بر زندگی ما حکمرانی میکنند را بازتعریف خواهند کرد. بینشهای وجودگرایانه و واسطهزدایی از نهادها جزء خصوصیات اینترنت هستند که نهایتاً در حال رسیدن به بلوغ هستند.
تابع های ++C — به زبان ساده
در این مقاله هر آن چه باید در مورد تابع های ++C بدانید را آموزش میدهیم. از جمله این که چه نوع تابعهایی در زبان برنامهنویسی ++C وجود دارند و مثالهایی از شیوه استفاده از آنها ارائه میکنیم. در برنامهنویسی منظور از تابع گزارهای است که کدها را برای اجرای وظیفه خاصی گروهبندی میکند. برای مطالعه بخش قبلی این مجموعه مقالات آموزشی میتوانید به لینک زیر رجوع کنید:
بسته به این که تابع از قبل تعریف شده باشد یا از سوی برنامهنویس ایجاد شود دو نوع تابع وجود دارد:
- تابع کتابخانه
- تابع تعریف شده از سوی کاربر
تابع کتابخانه
تابعهای کتابخانه تابعهای داخلی زبان برنامهنویسی ++C هستند. برنامهنویس میتواند با فراخوانی مستقیم تابع از این تابعهای کتابخانه استفاده کند و نیازی نیست که آنها را خودش بنویسد.
مثال 1
خروجی
Enter a number: 26 Square root of 26 = 5.09902
در مثال فوق، تابع کتابخانه ()sqrt برای محاسبه ریشه مربع یک عدد استفاده میشود. به کد <include <cmath# در برنامه فوق توجه کنید. در این کد cmath یک فایل «هدر» (Header) است. تعریف تابع ()sqrt یعنی بدنه تابع در فایل هدر cmath قرار دارد. زمانی که فایل cmath را با استفاده از دستور <include <cmath# در برنامه خود بگنجانید، میتوانید از همه تابعهای تعریف شده در آن استفاده کنید.
تابع تعریف شده از سوی کاربر
++C به برنامهنویس امکان میدهد که تابع خاص خود را تعریف کند. تابع تعریف شده از سوی کاربر به گروهبندی کد میپردازد تا وظیفه خاصی را اجرا کند و این گروه کد یک نام (شناسه) دارد. زمانی که تابع از هر بخش از برنامه فراخوانی شود، کدهای تعریف شده در بدنه تابع را اجرا میکند.
طرز کار تابعهای تعریف شده از سوی کاربر
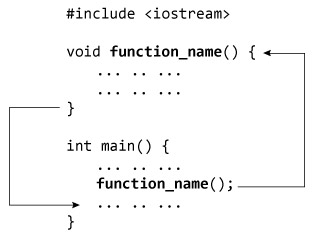
به تصویر فوق توجه کنید. زمانی که یک برنامه شروع به اجرا میکند، سیستم تابع ()main را فراخوانی میکند، یعنی سیستم شروع به اجرای کد از تابع ()main میکند. زمانی که کنترل برنامه به ()function_name درون ()main برسد، به ()void function_name انتقال مییابد و همه کدهای درون آن را اجرا میکند. سپس کنترل برنامه مجدداً به تابع main بازمیگردد و چنان که در تصویر فوق مشخص است، کد پس از فراخوانی ()function_name اجرا میشود.
مثال 2
برنامه ++C زیر، دو عدد صحیح را با هم جمع میکند. یک تابع به نام ()add ایجاد میکنیم تا اعداد صحیح را با هم جمع کند و مجموع را در تابع ()main نمایش دهد.
خروجی
Enters two integers: 8 -4 Sum = 4
اعلان پروتوتایپ تابع
اگر یک تابع تعریف شده از سوی کاربر پس از تابع ()main تعریف شود، کامپایلر خطایی نمایش خواهد داد. دلیل این امر آن است که کامپایلر از وجود تابع تعریف شده از سوی کاربر، نوع آرگومانهای ارسالی به تابع و نوع بازگشتی آن ناآگاه است.
پروتوتایپ تابع در ++C یک اعلان از تابع بدون بدنه است که اطلاعاتی را در مورد تابع تعریف شده از سوی کاربر در اختیار کامپایلر قرار میدهد. پروتوتایپ تابع در مثال فوق به صورت زیر است:
int add(int، int);
چنان که ملاحظه میکنید، در پروتوتایپ تابع هیچ بدنهای ندارد. ضمناً تنها نوع بازگشتی آرگومانها ذکر شده و خبری از خود آرگومانها نیست. پروتوتایپ تابع را میتوان به شکل زیر نیز اعلان کرد، اما لزومی به نوشتن آرگومانها وجود ندارد:
int add(int a، int b);
نکته: در صورتی که تابع تعریف شده کاربر پیش از تابع ()main قرار داشته باشد، اعلان پروتوتایپ ضروری است.
فراخوانی تابع
برای اجرای کد بدنه تابع، تابع تعریف شده از سوی کاربر باید احضار یا فراخوانی شود. در برنامه فوق دستور زیر:
درون ()main تابع تعریف شده کاربر را فراخوانی میکند. بدین ترتیب تابع یک عدد صحیح بازگشت میدهد که در متغیر add ذخیره میشود.
تعریف تابع
خود تابع به صورت تعریف تابع مورد ارجاع قرار میگیرد. تعریف تابع در برنامه فوق به صورت زیر است:
زمانی که تابعی فراخوانی میشود، کنترل به گزاره اول بدنه تابع انتقال مییابد. سپس گزارههای دیگر در بدنه تابع به ترتیب اجرا میشوند. هنگامی که همه کدهای درون تعریف تابع اجرا شدند، کنترل برنامه به برنامه فراخوانی کننده بازگشت مییابد.
ارسال آرگومان به تابع
پارامتر آرگومان در برنامهنویسی، اشاره به دادههایی دارد که در زمان فراخوانی تابع به آن ارسال میشوند. در مثال فوق، دو متغیر num1 وnum2 در طی فراخوانی تابع به آن ارسال میشوند. این آرگومانها به نام آرگومانهای واقعی شناخته میشوند. مقدار num1 و num2 به ترتیب با متغیرهای a و b مقداردهی میشوند. این آرگومانهای a و b به نام آرگومانهای صوری شناخته میشوند.
این وضعیت در شکل زیر نمایش یافته است:

نکاتی در مورد ارسال آرگومانها
- تعداد آرگومانهای واقعی و آرگومانهای صوری باید یکسان باشند. تنها استثنا در زمان Overload کردن تابع است.
- نوع آرگومان واقعی اول باید با نوع آرگومان صوری اول مطابقت داشته باشد. به طور مشابه، نوع آرگومان واقعی دوم باید با نوع آرگومان صوری دوم مطابقت پیدا کند و همین طور تا آخر.
- میتوان تابعی را بدون ارسال آرگومان نیز فراخوانی کرد. تعداد آرگومانهای ارسالی به یک تابع به شیوهای که برنامهنویس برای حل مسئله مربوطه انتخاب کرده است وابستگی دارد.
- در برنامه فوق، هر دو آرگومان از نوع int هستند، اما لزومی نیست که هر دو آرگومان از نوع واحدی باشند.
گزاره بازگشت
هر تابعی میتواند با استفاده از گزاره Return یک مقدار منفرد به برنامه فراخوانی کننده بازگشت دهد. در برنامه فوق، مقدار add از تابع تعریف شده از سوی کاربر با استفاده از گزاره زیر به برنامه فراخوانی کننده بازگشت مییابد:
return add;
تصویر زیر طرز کار گزاره return را نشان میدهد:

در برنامه فوق، مقدار add درون تابع تعریف شده کاربر به تابع فراخوانی کننده بازگشت مییابد. سپس این مقدار در متغیر sum ذخیره میشود. توجه داشته باشید که متغیر بازگشت یافته یعنی add از نوع int و متغیر sum نیز از نوع int است. ضمناً توجه کنید که نوع بازگشتی یک تابع در اعلان تابع تعریف میشود:
int add(int a، int b)
عبارت int در دستور اعلان فوق به این معنی است که این تابع باید مقداری با نوع int بازگشت دهد. اگر هیچ مقداری به تابع فراخوانی کننده بازگشت نیابد، در این صورت باید از void استفاده کنید. بدین ترتیب به پایان این بخش از سری مقالات آموزش ++C میرسیم.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
منبع: فرادرس
آموزش ساخت یک اپلیکیشن آیفون (بخش نهم) — به زبان ساده
در این بخش از سری مقالات آموزش ساخت یک اپلیکیشن آیفون قصد داریم از طرحبندی xib به نام NewsTableViewCell که در بخش هفتم ایجاد کردیم در استوریبورد خود استفاده کنیم. این فرایند ساده است و در آن از BFWControls.framework استفاده میکنیم که در بخش هشتم ساختیم. در این مسیر مطالبی در خصوص کلاسها و زیرکلاسها و شیوه تغییر یک سوپرکلاس و اتصال خروجی خواهیم آموخت. برای مطالعه بخش قبلی این مجموعه مقالات آموزشی به لینک زیر مراجعه کنید.
کلون کردن پروژه
اگر بخش قبلی این سری مقالات را مطالعه کرده باشید، در این صورت هر آن چه برای مطالعه این بخش لازم است را در اختیار دارید و میتوانید به بخش «کلاسها و زیرکلاسها» در ادامه مراجعه کنید.
اگر میخواهید این راهنما را از صفر شروع کنید، میتوانید پروژهای که تا اینجا ساختیم را با طی مراحل زیر دانلود کنید:
- اپلیکیشن ترمینال را از پوشه Application باز کنید.
- در ترمینال دستور cd ~/Documents را وارد کرده و دکمه Return (در ویندوز Enter) را بزنید.
- کد زیر را در ترمینال وارد کرده و Return را بزنید:
git clone --recurse-submodules --branch Start-Tutorial-9 https://bitbucket.org/barefeetware/lego-tutorial-social.git
فرایند دانلود را در ترمینال تعقیب کنید منتظر بمانید تا به پایان برسد. سپس در پوشه Docuuments، زیرپوشه lego-tutorial-social را باز کنید. در ادامه فایل Social.xcode.proj را باز کنید.
در این راهنما ما فرض کردهایم که شما با مطالبی که در بخشهای قبلی مورد بحث قرار گرفتند، آشنایی دارید. اگر در این مورد اطمینان کافی ندارید، میتوانید به بخشهای قبلی این راهنما مراجعه کرده و آنها را مطالعه کنید.
کلاسها و زیرکلاسها
در Xcode بخش Main.storyboard را انتخاب کرده و اسکرول کنید تا صحنه News که شامل لیستی از آیتمهای خبری است پدیدار شود. نخستین سلول را با کلیک کردن روی آن انتخاب کنید. در پنل Inspector در سمت راست، روی آیکون سوم کلیک کنید (آیکون آن شبیه به یک کارت شناسایی است). بدین ترتیب بخش Identity Inspector نمایش پیدا میکند.
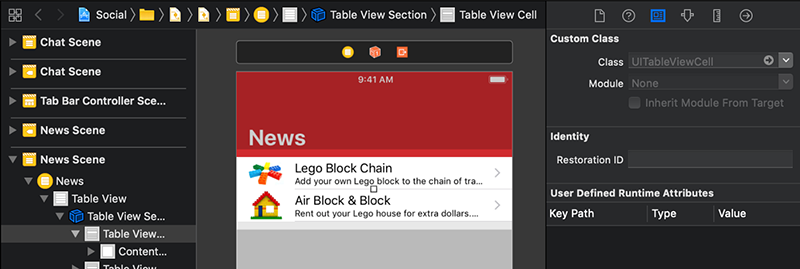
Identity Inspector نشان میدهد که Class انتخاب شده سلول به صورت UITableViewCell است.
هر شیء بصری که تا اینجا به اپلیکیشن خود اضافه کردهایم، نوعی «نما» (view) بوده است. یک نمای تصویر شامل یک تصویر است. یک نمای برچسب، متن را در خود جای میدهد. همین طور نمای پشتهای، نماهای دیگر را در خود میگنجاند. همه اینها نامهای خاصی دارند. از آنجا که این view-ها از سوی فریمورک UIKit عرضه شدهاند نام آنها UIView ،UIImageView ،UILabel ،UIStackView ،UITableView ،UITableViewCel و از این دست است. انواع بسیار بیشتری از «نما» (View) مانند UISwitch ،UISlider ،UISegmentedControl و UIActivityIndicatorView نیز وجود دارند که هنوز مورد استفاده قرار ندادهایم.
UIView را میتوان نوعی طبقهبندی یا کلاس در نظر گرفت که همه نماهای از نوع خاص را در خود جای میدهد. برحسب اصطلاحهای برنامهنویسی UIView یک سوپرکلاس است. همه نماهای دیگر مانند UILabel ،UIImageView و غیره زیرکلاس UIView محسوب میشوند.
زمانی که یک زیرکلاس را در سوئیفت که زبان برنامهنویسی iOS است، نامگذاری میکنیم، عموماً پسوند سوپرکلاس را کپی میکنیم. به همین دلیل است که UIImageView و UIStackView دارای پسوند view هستند که از UIView میآید. البته برخی استثناها نیز مانند UILabel وجود دارند. این نما UILabelView نامگذاری نشده است، اگر چه زیرکلاسی از UIView محسوب میشود.
در بخش هفتم این سری مقالات آموزشی ما یک زیرکلاس از UITableViewCell ساختیم که نام آن را NewsTableViewCell گذاردیم.
در فیلد Class در بخش Identity Inspector عبارت News را با حرف بزرگ N وارد کنید تا Xcode با تکمیل کردن عبارت ورودی شما زیرکلاس UITableViewCell را نمایش دهد.
کلید Return کیبورد را بزنید.
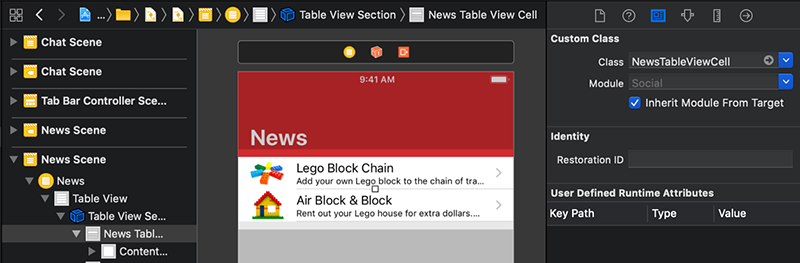
بدین ترتب ما کلاس سلول را از UITableViewCell عمومی به زیرکلاس سفارشی خودمان عوض کردیم.
ساخت کلاس با Xib
تا به اینجا همه چیز به خوبی پیش رفته است، اما از نظر بصری هیچ چیز تغییر نیافته است. در بخش هفتم این سری آموزشی، یک کلاس به نام NewsTableViewCell ایجاد کردیم. همچنین یک فایل xib ساختیم که شامل طرحبندی مورد نظر ما بود. اینک انتظار داریم که پس از تغییر دادن کلاس سلول صحنه News آن طرحبندی ظاهر شود. با این حال این اتفاق نیفتاده است.
دلیل این مسئله آن است که گرچه Xcode در زمان ساخت زیرکلاس NewsTableViewCell به ما پیشنهاد کرد که فایل XIB نیز برای آن بسازیم؛ اما در عمل از طرحبندی آن فایل xib استفاده نمیکند. بدین منظور باید مقداری کدنویسی کنیم. خوشبختانه این وضعیت از سوی BFWControls.framework که در بخش 8 به پروژه اضافه کردیم، مدیریت میشود.
BFWControls شامل زیرکلاسی از UITableViewCell به نام NibTableViewCell است که وظیفه استفاده از طرحبندی xib را بر عهده دارد. برای این که کلاس سلول سفارشی این قابلیت را داشته باشد، کافی است آن را به صورت زیرکلاسی از NibTableViewCell تغییر دهیم. ما این کار را برای آن کلاس انجام میدهیم. جای هیچ نگرانی هم نیست، چون این کار کاملاً ساده است.
ویرایش کد
در پنل Project Navigator گزینه NewsTableViewCell.swift را انتخاب کنید، چنان که احتمالاً حدس میزنید، این همان فایلی است که شامل کد سوئیفت برای این کلاس است.
ابتدا باید کد پیشفرضی که لازم نداریم و در حال حاضر هم کاری برای ما انجام نمیدهد را پاک کنیم. به این منظور همه خطوط متن را بین آکولادهای باز و بسته انتخاب کنید.
با زدن کلید Delete روی کیبورد این کد را حذف کنید.
ایمپورت کردن یک فریمورک
باید به این فایل کد اعلام کنیم که از کد موجود در فریمورک BFWControls استفاده کند و به این منظور از کلیدواژه import استفاده میکنیم. زیر عبارت موجود import UIKit یک خط به صورت import BFWControls اضافه کنید.
تغییر سوپرکلاس
چنان که مشاهده میکنید در انتهای عبارت class NewsTableViewCell یک دونقطه (:) و سپس نام سوپرکلاس UITableViewCell قرار گرفته است. ما باید این سوپرکلاس را به NibTableViewCell تغییر دهیم تا بتوانیم از قابلیتهای آن استفاده کنیم.
سوپرکلاس را به NibTableViewCell تغییر دهید. به این منظور کافی است UI را با Nib عوض کنید.
اگر تا پیش از این import BFWControls را اضافه نکردهاید، در این صورت Xcode ممکن است هشدار زیر را نمایش دهد:
Use of undeclared type ‘NibTableViewCell’
معنی آن این است که Xcode نمیداند NibTableViewCell چیست.
IBDesignable
در نهایت باید به Xcode اعلام کنیم که میخواهیم NewsTableViewCell نه تنها در زمان اجرا بلکه درزمان طراحی یعنی زمانی که مشغول تماشای سلول سفارشی در Interface Builder مانند استوریبورد هستیم نیز مورد استفاده قرار گیرد.
به این منظور عبارت IBDesignable@ را پیش از class اضافه کنید.
تا به اینجا همه کار به پایان رسیده است. ما NewsTableViewCell را طوری تغییر دادهایم که یک زیرکلاس از NibTableViewCell در BFWControls باشد و از Xcode خواستهایم که آن را در زمان طراحی نیز در سازنده اینترفیس نمایش دهد.
نمایش وهلهای از سلول سفارشی
در این زمان با انتخاب فایل Main.storyboard در پنل Project Navigator به آن بازگردید و Attributes Inspector را انتخاب کنید.
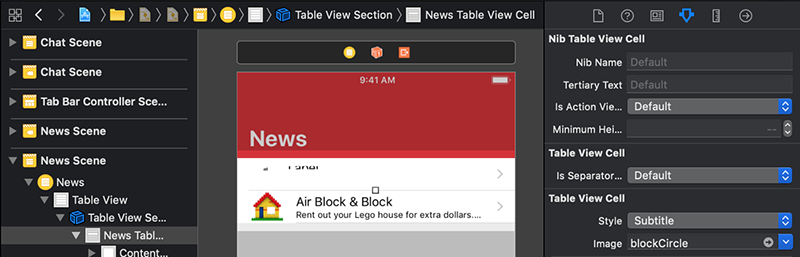
اینک Attributes Inspector یک بخش Nib Table View Cell اضافی با Tertiary Text و دیگر خصوصیتها دارد. اگر Attributes Inspector محتوای خالی نشان میدهد در یک بخش خالی بوم (مثلاً بین صحنهها) کلیک کنید و سپس روی آیتم ابتدایی News دوباره کلیک کنید تا انتخاب شود.
Xcode در طی چند ثانیه، بخشهایی از پروژه را که نیازمند بهروزرسانی سلولها هستند با طرحبندی سفارشی میسازد. سلول انتخابی هم اکنون ظاهر متفاوتی دارد، اما کمی فشرده شده است. دستگیره انتخاب سلول منتخب را به سمت پایین بکشید تا ارتفاع آن به 180 پوینت برسد.
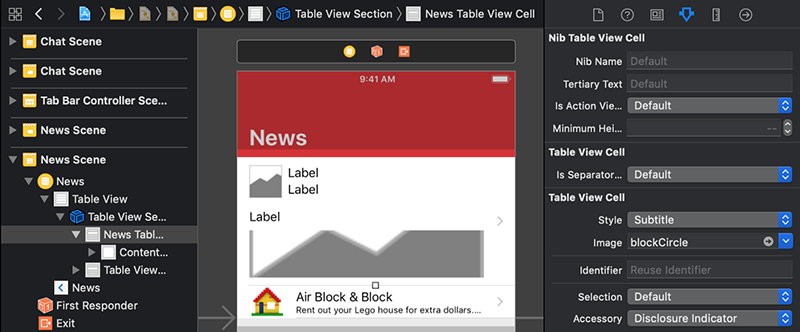
زمانی که سلول را میکشید تا بزرگتر شود، میبینید که طرحبندی سفارشیتان ظاهر میشود. کار به همین سادگی است. اکنون استوریبورد از طرحبندی xib سفارشیشده ما در سلولهای تازه استفاده میکند.
Connections Inspector
اکنون ما طرحبندی موردنظر خودمان را روی سلولها اعمال کردهایم، اما همچنان تصاویر پیشفرض و متن Label روی سلولها نمایش پیدا میکنند. در واقع ما از Xcode خواستهایم که از طرحبندی xib استفاده کند، اما تصاویر و متن را از این وهله به دست میآورد. ما باید به xib برگردیم و برچسبها و نماهای تصویر را به خروجی مناسب وصل کنیم تا کد بداند که متن، متن تفصیلی، تصاویر و غیره را کجا قرار دهد.
به این منظور فایل NewsTableViewCell.xib را در Project Navigator انتخاب کنید. در Document Outline یک بار روی News Table View Cell کلیک کنید. همچنین میتوانید در فضای خالی بوم کلیک کرده و سپس یک بار روی لبه سلول کلیک کنید.
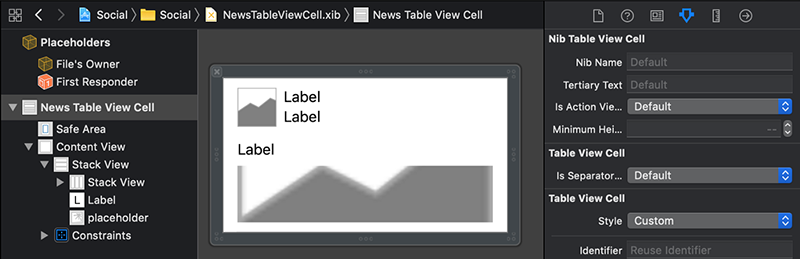
در پنل Inspector سمت راست، روی آیکون سمت راست (فلش داخل دایره) کلیک کنید تا بخش Connections Inspector نمایش پیدا کند.
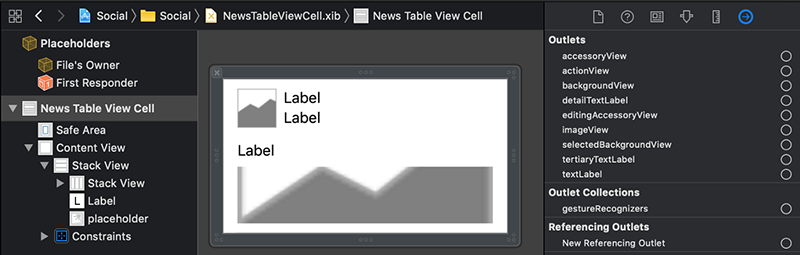
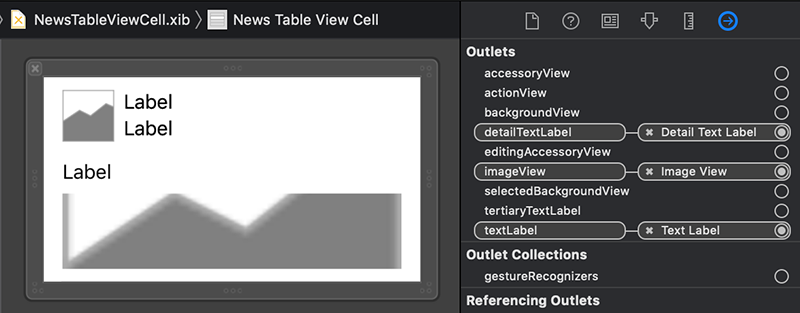
بخش نخست با عنوان Outlets همه خروجیهایی که میتوان کلاس NewsTableViewCell را به آنها وصل کرد نمایش میدهد. از آنجا که ما هنوز هیچ خروجی به فایل کد NewsTableViewCell خود اضافه نکردهایم. این لیست از خروجیها از سوپرکلاس خود یعنی NibTableViewCell ارث میبرند.
اتصال خروجی
برای این که NewsTableViewCell بداند که متن، متن تفصیلی و تصویر را در هر وهله باید کجا قرار دهد، باید هر خروجی را به نمای تصویر یا برچسب مطلوب در طرحبندی وصل کنیم.
در کنار textLabel در سمت راست دایره را تا Label اول بکشید و رها کنید.
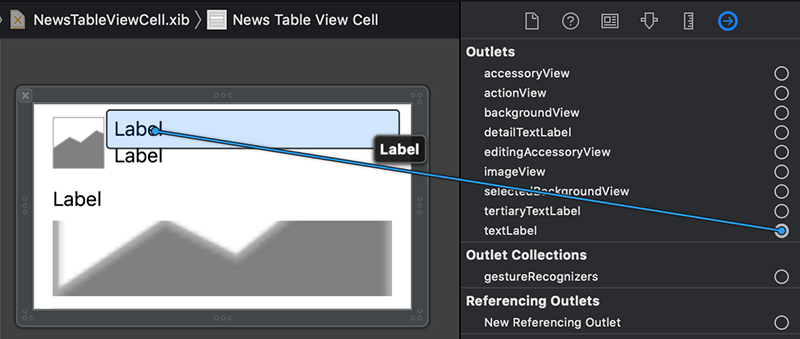
به طور مشابه textLabel را به Label پایینی وصل کنید.
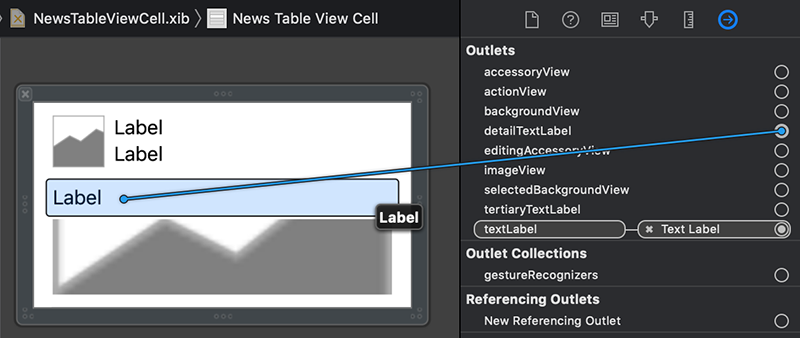
خروجی imageView را به نمای تصویر کوچک فوقانی وصل کنید.
رفرش کردن نماها
به فایل Main.storyboard بازگردید. اگر بهروزرسانی نشده است، گزینه Refresh All Views را از منوی Editor انتخاب کنید.

Xcode متن و تصویر را برای این سلول فوقانی در طرحبندی که برای NewsTableViewCell طراحی کردیم نمایش میدهد. در ادامه سلول دوم را بررسی میکنیم. آن را با یک بار کلیک کردن رویش انتخاب کنید. دستگیره انتخاب آن را چنان به سمت پایین بکشید که ارتفاعش به حدود 180 پوینت برسد.

سلول دوم همچنان سلول پیشفرض کلاس UITableViewCell است. توجه داشته باشید که وقتی ارتفاع افزایش مییابد، نمای تصویر میتواند بزرگتر شود تا با تصویر تطبیق پیدا کند.
اگر طرحبندی سلول اول مانند آن چه در تصویر فوق میبینید، کمی در هم به نظر میرسد، گزینه Refresh All Views را مجدداً از منوی Editor انتخاب کنید. این تراز شدن نامناسب صرفاً موقتی است و مربوط به تماشای پیشنمایش سازنده اینترفیس در زمان طراحی است و تأثیری روی زمان اجرا نخواهد داشت.

زمانی که سلول دوم همچنان در حالت انتخاب قرار دارد، همانند دفعه پیش، در Identity Inspector کلاس را به NewsTableViewCell تغییر دهید.
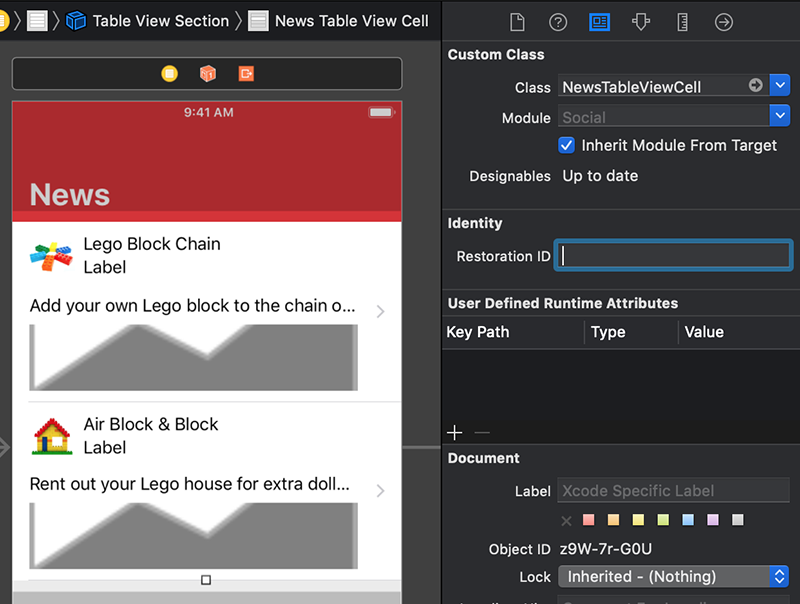
اکنون هر دو سلول NewsTableViewCell هستند و از طرحبندی NewsTableViewCell.xib استفاده میکنند. بدین ترتیب هر سلول تصویر و متن مورد نظر خود را نمایش میدهد.
متنهای پیشفرض
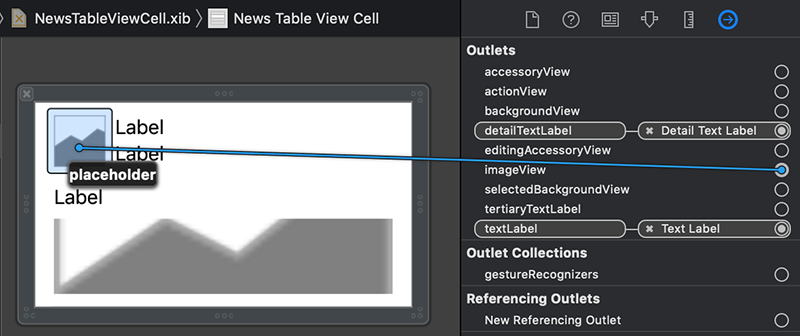
در این مرحله سلول سفارشی ما به خوبی کار میکند. هر وهله یک طرحبندی سفارشی و محتوای منفرد در خروجیهای textLabel، detailTextLabel و imageView نمایش میدهد. با این حال، چنان که مشاهده میکنید، ما یک نمای تصویر دوم و یک برچسب متنی سوم هم داریم که در حال حاضر تصویر پیشفرض و متن پیشفرض Label را نمایش میدهند. ما باید خروجیهای محتوا را برای اینها طوری تغییر دهیم که بتوانیم محتوایی به آنها انتساب دهیم.
سوپرکلاس NibTableViewCell از قبل شامل یک برچسب متنی سوم به نام tertiaryTextLabel است. تنها کاری که باید انجام دهیم اتصال آن به xib است و این فرایند شبیه کار است که قبلاً برای textLabel و detailTextLabel انجام دادیم. فایل NewsTableViewCell.xib را در Project Navigator انتخاب کنید.
سه برچسب همگی متن پیشفرض Label را دارند که موجب میشود شناسایی آنها در نگاه نخست کمی دشوار باشد. بنابراین ابتدا متن پیشفرض آنها را عوض میکنیم.
روی هر یک از سه برچسب دوبارکلیک کنید تا محتوای آن انتخاب شود و سپس متن اول را به صورت [Text]، متن برچسب انتهایی را به صورت [Detail Text] و متن برچسب میانی را به صورت [Tertiary Text] تغییر دهید. اطمینان حاصل کنید که براکت های باز و بسته ([]) را نیز استفاده کردهاید.
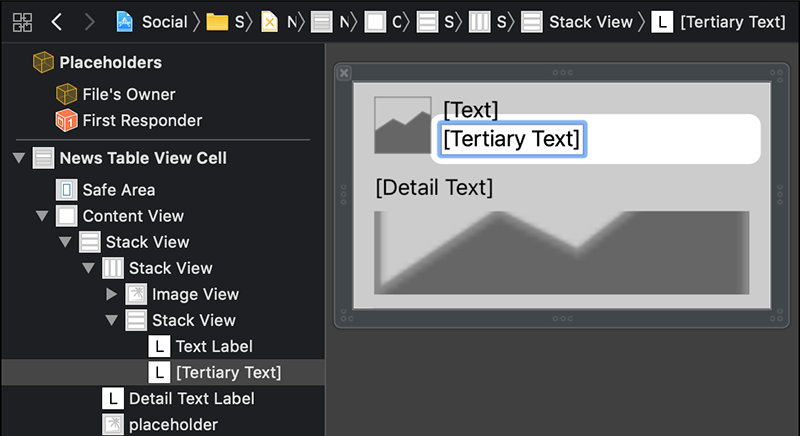
بر روی بوم، کانتینر سلول بیرونی را انتخاب کنید. در پنل Inspector سمت راست، گزینه Connections Inspector را انتخاب کنید. خروجی را به برچسب متن میانی با متن پیشفرض وصل کنید.
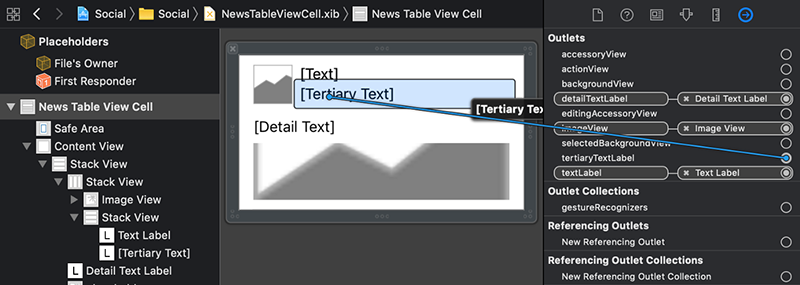
مجدداً Main.storyboard را انتخاب کنید.
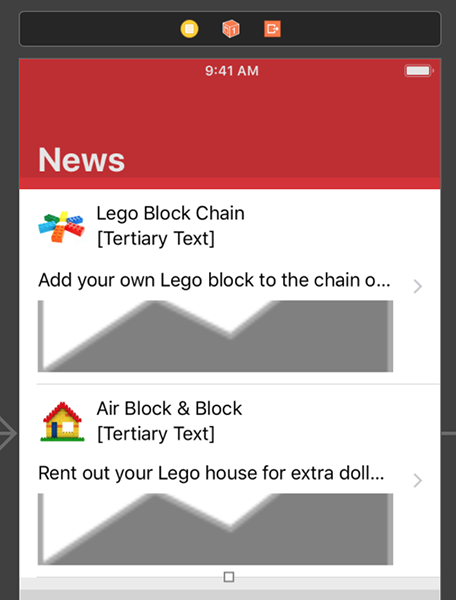
توجه کنید که متن پیشفرض Label برای برچسب سوم در هر وهله از سلول با [Tertiary Text] عوض میشود. اینک اپلیکیشن را اجرا کنید.
اگر توجه کنید میبینید که متن پیشفرض در زمان اجرا حذف میشود. سوپرکلاس NibTableViewCell متن پیشفرض را در صورتی که بین کروشه باز و بسته قرار داشته باشد به طور خودکار حذف میکند.
متن سوم
کلاس UITableViewCell شامل textLabel و detailTextLabel است که NibTableViewCell را کنار میزند. به همین دلیل است که NewsTableViewCell به صوت خودکار از متن عنوان و متن جزییات تفصیلی سلول اصلی در استوریبورد استفاده کرد.
با این حال این برچسب متن سوم به نام tertiaryTextLabel در سوپرکلاس UITableViewCell وجود ندارد. ما باید روش دیگری برای درج متن در آن پیدا کنیم. کلاس NibTableViewCell این کار را با استفاده از خصوصیت Tertiary Text انجام میدهد.
به Xcode بازگردید. سلول اول را در صحنه News انتخاب کنید. Attributes Inspector را انتخاب کنید.
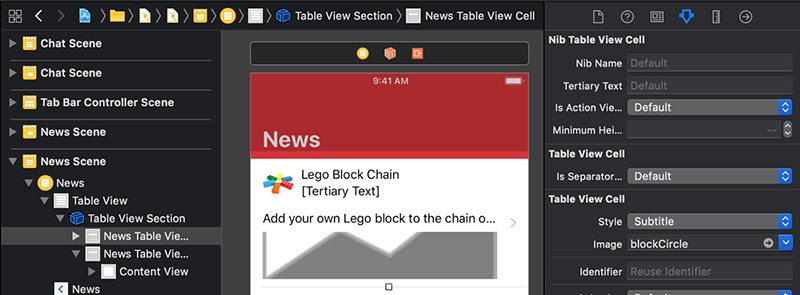
در فیلد Tertiary Text در Attributes Inspector یک تاریخ ساده مانند October 9, 12:32pm وارد کنید.
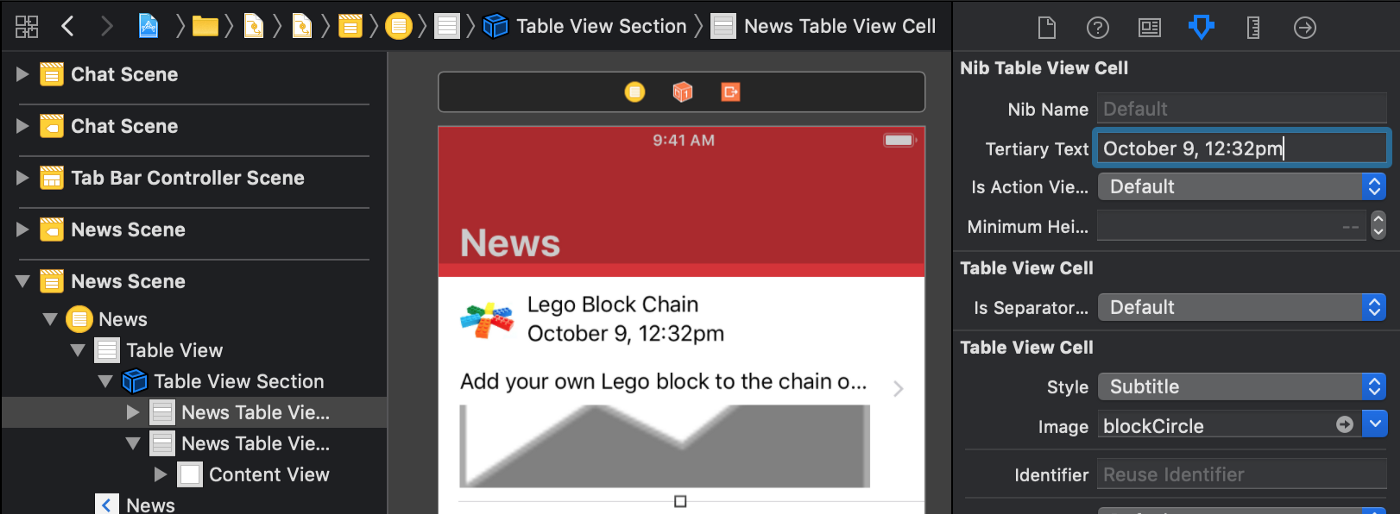
پس از این که دکمه Return را بزنید میبینید که متن در برچسب متن سوم نیز ظاهر میشود. به طور مشابه سلول دوم را انتخاب کرده و مقدار Tertiary Text را به صورت October 10, 2:13pm وارد کنید.
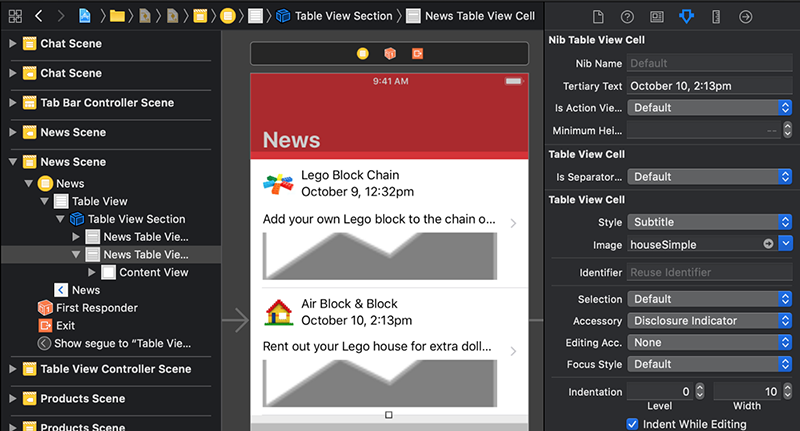
کامیت کردن تغییرات
چنان که در انتهای همه بخشهای قبلی انجام دادیم، این بار نیز باید تغییراتی که روی پروژه اجرا میکنیم را کامیت کنیم تا ذخیره شوند. به این منظور مراحل زیر را اجرا کنید:
- گزینه Commit Changes را از منوی Source Control انتخاب کنید.
- توضیحی مانند زیر وارد کنید:
NewsTableViewCell: changed to a subclass of NibTableViewCell. Added placeholder text. Connected outlets.
- روی دکمه Commit کلیک کنید.
جمعبندی
اکنون NewsTableViewCell ترکیبی از طرحی بندی فایل xib با متن و تصویری از هر وهله از استوریبورد است.تصویر دوم همچنان یک تصویر پیشفرض است. در بخش بعدی یعنی بخش دهم این سری مقالات آموزش ساخت اپلیکیشن آیفون، یک خروجی سفارشی برای آن میسازیم و خصوصیتهایی را ارائه میکنیم که بتوانیم این تصویر تفصیلی را سفارشیسازی بکنیم. برای مطالعه بخش بعدی این سری مقالات به لینک زیر بروید:
منبع: فرادرس
برنامه تشخیص درخت بودن یک گراف — راهنمای کاربردی
در این مطلب، برنامه تشخیص درخت بودن یک گراف در زبانهای برنامهنویسی گوناگون شامل ++C، «پایتون» (Python) و «جاوا» (Java) ارائه شده است. در واقع، هدف نوشتن تابعی است که یک گراف بدون جهت را دریافت کرده و بررسی کند که آیا درخت است یا نه. در صورتی که گراف یک درخت بود «مقدار یک» و در غیر این صورت، «مقدار صفر» را بازگرداند. برای مثال، گراف زیر یک درخت است.
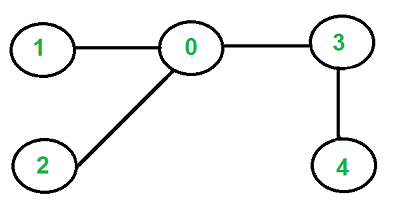
اما، گراف زیر یک درخت نیست.

یک گراف بدون جهت، در صورتی درخت است که مشخصات زیر را داشته باشد:
- هیچ دوری نداشته باشد.
- گراف همبند باشد.
برای یک گراف بدون جهت، میتوان از الگوریتمهای «جستجوی اول سطح» (Breadth-First Search | BFS) یا «جستجوی اول عمق» (Depth-First Search | DFS) برای تشخیص وجود دو ویژگی بالا استفاده کرد. شایان ذکر است، برای مطالعه بیشتر پیرامون گراف و درخت، مطالعه مطالب «گراف — تعاریف و انواع آن به زبان ساده» و «درخت در گراف — به زبان ساده» توصیه میشود.
روش شناسایی دور در یک گراف بدون جهت
همانطور که پیشتر بیان شد، برای تعیین درخت بودن یا نبودن یک گراف بدون جهت، میتوان از الگوریتمهای BFS یا DFS استفاده کرد. برای هر یک از راسهای بازدید شده v، اگر یک راس همجوار u وجود داشته باشد که پیش از این بازدید شده باشد و u والد v نباشد، یک دور در گراف وجود دارد. اگر چنین راس همجواری برای هیچ یک از راسها یافت نشود، هیچ دوری در گراف وجود ندارد.
روش شناسایی همبندی در یک گراف بدون جهت
از آنجا که گراف بدون جهت است، میتوان کار را با استفاده از الگوریتم BFS یا DFS و از هر راسی آغاز کرد و بررسی کرد که آیا همه راسها دسترسی پذیر هستند یا خیر. در صورتی که همه راسها دسترسی پذیر باشند، گراف همبند است و در غیر این صورت همبند نیست.
برنامه تشخیص درخت بودن یک گراف در ++C
برنامه تشخیص درخت بودن یک گراف در جاوا
برنامه تشخیص درخت بودن یک گراف در پایتون
خروجی
Graph is Tree Graph is not Tree
منبع: فرادرس