طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیقالبهای گیت هاب برای درخواستهای Pull یکپارچه و هوشمندانه — راهنمای کاربردی
در این مقاله قصد داریم یک روش بهتر، آسانتر و کارآمدتر برای حفظ یکپارچگی در میان درخواستهای pull گیتهاب و حتی سفارشیسازی کامل آنها در یک تیم توسعه معرفی کنیم. امکان این کار به کمک قالب های گیت هاب فراهم شده است.
مشکلات رایج
اگر تاکنون به عنوان یک توسعهدهنده نرمافزار با گیتهاب کارکرده باشید، چه این کار را به صورت انفرادی انجام داده باشید و چه بخشی از یک تیم بوده باشید، احتمالاً با مشکلاتی که در ادامه معرفی خواهیم کرد آشنا هستید.
درج پیامهای کامیت خیلی کوتاه
نخستین مشکل رایج پیام کامیت بیمعنی است. این پیامها عموماً چندین بار ارسال میشوند، چون ما توسعهدهندگان تنبلی هستیم و عادت داریم تغییرات مختلف را با پیامهای یکسانی به گیتهاب پوش کنیم و هیچ توجه نداریم که آن تغییرات هیچ ارتباطی با پیام مربوطه ندارند.

نکته: اگر میخواهید برخی پیامهای کامیت جالب و سرگرمکننده را بخوانید، سری به این وبسایت (+) بزنید. با رفرش کردن صفحه پیامهای کامیت عجیبوغریبی را مشاهده خواهید کرد.
درخواستهای Pull کاملاً معماگونه
احتمالاً یک درخواست pull مانند درخواست زیر را در یک ریپو دیدهاید (و یا ارسال کردهاید). تلاش نکنید انکار کنید! نام و جزییات جهت حفظ حریم خصوصی پنهان شدهاند:
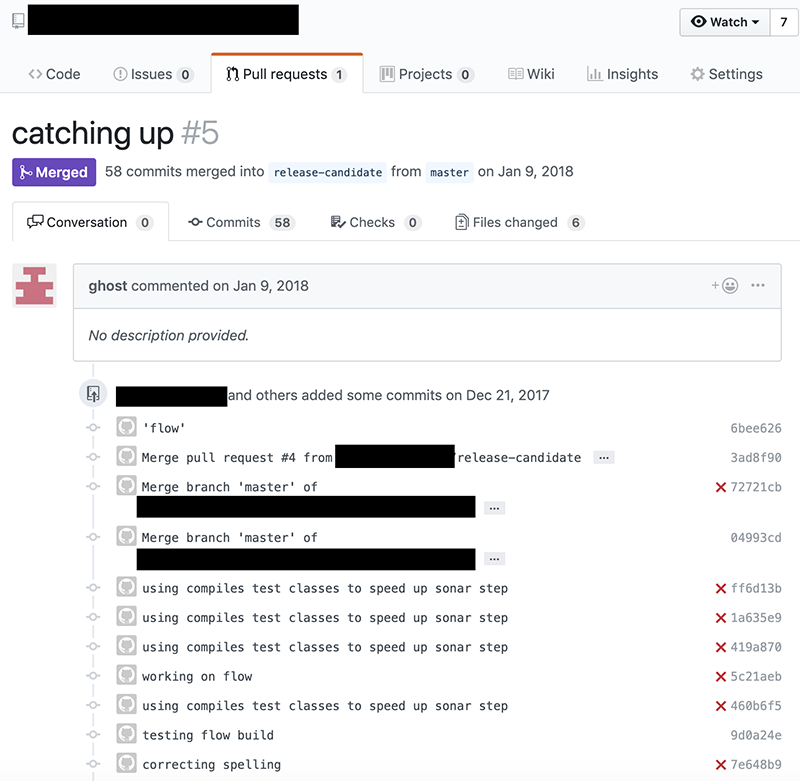
تصویر فوق یک درخواست pull واقعی روی گیتهاب است و پیامهای کامیت فراوانی دارد که معنی بسیار کمی دارند و برای کسی که به آنها نگاه میکند جزییات چندانی از آنچه در حال اتفاق افتادن است ارائه نمیکنند.
در این مرحله، ممکن است با خود فکر کنید، این کار در واقع شبیه همان کاری است که خودتان قبلاً دیدهاید (انجام دادهاید) و مشکل چندانی ایجاد نمیکند.
اگر یک توسعهدهنده منفرد هستید که روی پروژه شخصی خود کار میکنید، همواره از همه چیز در کدبیس اطلاع دارید و شاید حق با شما باشد. اما اگر در حال کار با تیمی متشکل از 10 یا 20 توسعهدهنده دیگر هستید و یک اپلیکیشن میسازید که از سوی صدها یا هزاران نفر استفاده میشود و توسعهدهندگان دیگر باید تغییراتی که شما ایجاد کردهاید را ببینند و تشخیص دهند که کد منطقی است یا نه و در ادامه هیچ مشکلی در شاخه master کد ایجاد نمیکند، در این صورت با یک مشکل بسیار بزرگ مواجه هستیم.
راهحلها
برای حل این مشکلها چند راهحل مختلف وجود دارند که ممکن است گذشته تجربه کرده باشید.
گزینه 1: فرایند کاملاً دستی
یک مجموعه نسبی از الزامات داریم که باید به هر درخواست pull جدید اضافه کنیم. این موارد چیزهایی مانند این هستند:
- لینکهایی به روند قابلیتی که مشغول کار روی آن هستیم روی backlog.
- لینکهایی به Jenkiks خودکار که شاخه ما بر مبنای آن ساخته شده و درون QA توزیع یافته است.
- لینکهایی به شاخه قابلیت برای تست کردن.
- گزارش پوشش کد
- لینکهای به PR-های مرتبط در ریپوهای دیگر و غیره.
این راهحل به درستی کار میکند، مگر این که افراد اضافه کردن یکی یا چند مورد از این لینکها را فراموش کنند (یا به آن اهمیت ندهند) و یک سیستم صورتبندی برای اعضای جدید که به تیم ملحق میشوند نداشته باشیم تا بدانند قالب PR-هایشان باید چگونه باشد.
گزینه 2: قالبی که باید کپی شده و هر بار در PR چسبانده شود
تلاش دوم ما کمی غیر دستیتر است. در این روش از یک قالب درخواست pull استفاده میشود که تیم میتواند در یک فایل txt. در اسلک نگهداری کند و آن را در یکی از کانالهای تیم توسعه پین کند. ظاهر آن میتواند به صورت زیر باشد:
Story
Jira, Pivotal Tracker, (link to where the story you worked on lives)
PR Branch
URL to the automated branch build for feature testing
Code Coverage
URL to the automated code coverage report run during the automated build process
e2e
URL to the automated end to end tests run against the feature branch
UX Approved
yes / no
Newman
yes / no
Related PR’s
TBD
اما در این حالت هم اعضای تیم باید بروند و دنبال قالب بگردند، قالببندی نشانهگذاری آن را کپی کنند و آن را درون همه درخواستهای pull وارد کرده و محتوای آن را نیز پر کنند.
این گزینه بهتری محسوب میشود، زیرا دستکم قالب تضمین میکند که احتمال فراموش کردن موارد مختلف کمتر است، اما همچنان مستعد خطا است. در اغلب موارد افراد تیم به سراغ PR-های قدیمی میروند، آن را باز میکنند و محتوای آن را کپی کرده و در PR جدید میچسبانند. البته این کار اشکالی ندارد، اما گاهی افراد فراموش میکنند که لینک استوری را بهروز کنند یا لینک سربهسر تست را درج نمیکنند و مشکل پیش میآید.
این بهترین راهحلی بود که اعضای تیم میتوانستند داشته باشند تا این که برخی توسعهدهندگان تازهکار به تیم ما اضافه شدند. زمانی که راهحل بهینه خود یعنی قالب PR را که استفاده میکردیم به اعضای جدید تیم نشان دادیم، آنها پرسیدند که چرا از قالبهای گیتهاب استفاده نمیکنیم؟ پاسخ ما این بود که: «چون هیچ یک از ما تاکنون چیزی در مورد آن نشنیدهایم!» در نهایت بدین ترتیب با این مفهوم به شدت جالب و البته آسان آشنا شدیم.
گزینه 3: قالبهای گیت هاب؛ روش خودکار برای انجام درخواست Pull
این گزینه راهحل بهتری محسوب میشود و در واقع راهحلی است که هرکس باید استفاده کند. قالبهای گیتهاب ابداع بسیار جالبی از سوی گیتهاب برای درخواستهای pull و همچنین issue-ها محسوب میشوند. از آنجا که PR-ها دغدغه هر تیم توسعهای هستند، به مستندات گیتهاب مراجعه کردیم تا در مورد آن بیشتر بدانیم:
زمانی که یک قالب درخواست pull به ریپازیتوری خود اضافه کنید، مشارکتکنندگان در پروژه به صورت خودکار محتوای قالب را در بدنه درخواست pull خود مشاهده خواهند کرد.
این همان چیزی است که هر تیم توسعهای نیاز دارد. این روش تضمین میکند که همه درخواستهای pull یک شکل هستند و لازم نیست اعضای تیم در مورد آن نگرانی داشته باشند. راهاندازی آن نیز بسیار آسان است.
راهاندازی قالبهای گیت هاب در یک پروژه
با این که راهاندازی یک قالب PR بسیار سرراست است، اما برای سهولت هر چه بیشتر در ادامه مراحل آن را توضیح دادهایم.
گام 1: افزودن یک پوشه /github. به ریشه پروژه
مستندات این بخش بیان میکنند که میتوان یک قالب PR را در خود ریشه دایرکتوری پروژه یا در پوشهای به نام /docs یا /github. اضافه کرد. از آنجا که ما میخواهیم پوشه PR را در اغلب موارد که مشغول توسعه هستیم نادیده بگیریم. تصمیم گرفتیم پوشه قالب را درون پوشه /github. بسازیم:
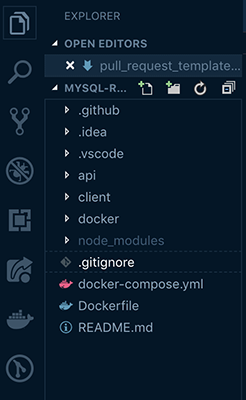
گام 2: افزودن فایل نشانهگذاری pull_request_template.md درون پوشه
برای این که گیتهاب به صورت خودکار قالببندی را از فایل نشانهگذاری برای قالبهای PR بردارد، باید نام فایل را pull_request_template.md بگذارید. در ادامه نمونهای از قالبی که تیم ما استفاده میکند را میبینید:
Tracker ID: #ADD LINK TO PIVOTAL STORY
Unit tests completed?: (Y/N)
PR Branch #ADD LINK TO PR BRANCH
Code Coverage & Build Info #ADD LINK TO JENKINS CONSOLE
E2E Approved #ADD LINK TO PASSING E2E TESTS
Windows Testing #HAS WINDOWS BEEN TESTED?
Related PR #ADD ANY RELATED PULL REQUESTS
UX Approved #ADD UX APPROVAL IF NEEDED
گام 3: افزودن این فایلها به شاخه master و آمادهسازی همه درخواستهای PR
در ادامه تصویری از یک ریپازیتوری را میبینید که قالب درخواست PR به آن اضافه شده و یک درخواست pull نیز به عنوان نمونه ایجاد شده است:
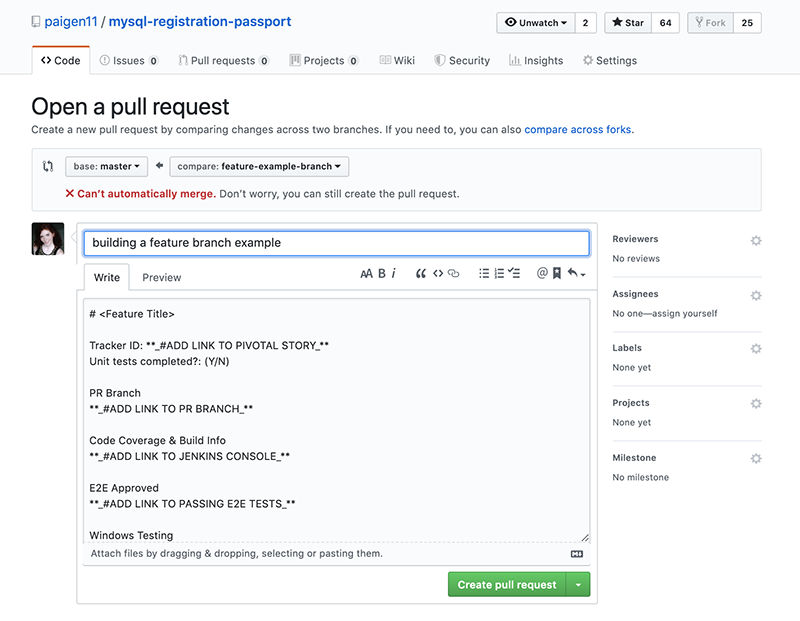
افزودن یک قالب PR استاندارد به هر ریپازیتوری دقیقاً به همین سادگی است.
سخن پایانی
زمانی که با تیمی از توسعهدهندگان سر و کار داریم که روی محصولی حساس مشغول کار هستند، درخواستهای pull یک ضرورت حیاتی محسوب میشوند، اما به کمک امکان pull_request_templates در گیتهاب این مشکل میتواند به آسانی مرتفع شود.
مزیتهای قالبهای صورتبندی شده PR زیاد هستند، اما برخی از آنها که میتوان اشاره کرد میزان انعطافپذیری آنها است. مهم نیست که تیم شما چه چیزی را مورد بررسی و پذیرش قرار میدهد، یک درخواست Pull را میتوان به سادگی در هر ریپازیتوری جای داده و پیادهسازی کرد. این همان نوع از سهولت کار توسعهدهندهها است که برای صورتبندی موارد ضروری مانند PR-ها به آن نیاز داریم.
یادگیری ماشین در اندروید با ML Kit برای فایربیس — از صفر تا صد
آن روزها که استفاده از قابلیتهای یادگیری ماشین تنها روی کلود امکان داشت و این مسئله نیازمند توان محاسباتی بالا، سختافزار پیشرفته و مواردی از این دست بود، گذشته است. امروزه دستگاههای موبایل بسیار قدرتمندتر شدهاند و الگوریتمهای ما نیز کارایی بالاتری یافتهاند. همه این موارد منجر به این نتیجه شده است که بهرهگیری از یادگیری ماشین روی دستگاههای همراه امکان یافته است و دیگر صرفاً یک نظریه عملی-تخیلی محسوب نمیشود. در این نوشته به بررسی عملی یک پروژه یادگیری ماشین در اندروید با استفاده از ML Kit برای «فایربیس» (Firebase) میپردازیم.
مقدمه
یادگیری ماشین امروزه روی دستگاههای گوناگون در همه جا استفاده میشود. نمونههایی از این مسئله به شرح زیر هستند:
- دستیار هوشمند: کورتانا، Siri و دستیار گوگل نمونههایی از این دستیارها هستند. دستیار گوگل در کنفرانس IO امسال یک بهروزرسانی عمده دریافت کرده است و عمده توجه بر روی افزایش ظرفیتهای یادگیری ماشین آن روی دستگاههای همراه بوده است.
- فیلترهای اسنپچت: اسنپچت از یادگیری ماشین برای تشخیص چهرههای انسان و قرار دادن فیلترهای 3 بعدی مانند عینک، کلاه، و.. روی آنها استفاده میکند.
- پاسخ هوشمند: پاسخ هوشمند (Smart Replay) یک از قابلیتهای بسیاری از دستگاههای امروزی است و در اپلیکیشنهای چت مانند واتس اپ و غیره استفاده میشود؛ هدف آن ارائه پیغامهای از پیش تعریف شدهای است که میتوانید از آنها را در پاسخ به پیامهای دریافتی گوناگون خود بهره بگیرید.
- گوگل لنز: با این که این سرویس همچنان در مراحل ابتدایی خود است، اما از مدلهای یادگیری ماشین برای شناسایی و برچسبگذاری اشیا استفاده میکند.
این فهرست را میتوان بسیار ادامه داد، بنابراین به این مقدار اکتفا میکنیم. در این مقاله به بررسی شیوههای استفاده از یادگیری ماشین در اپلیکیشنهای اندروید و هوشمندتر ساختن آنها میپردازیم.
ML Kit برای فایربیس چیست؟
ML Kit برای فایربیس یک SDK موبایل است که گنجاندن ظرفیتهای یادگیری ماشین در اپلیکیشنها را برای توسعهدهندگان موبایل آسانتر ساخته است. این کیت شامل API های پیشساخته زیر است:
- بازشناسی متن: این API برای بازشناسی و استخراج متن از تصاویر استفاده میشود.
- تشخیص چهره: برای تشخیص چهره و نشانهگذاری بخشهای مختلف چهره همراه با مرزهای آن استفاده میشود.
- تشخیص و ردگیری شیء: برای تشخیص، ردگیری و طبقهبندی اشیا در تصاویر دوربین و عکسهای از پیش ثبت شده استفاده میشود.
- برچسبگذاری تصویر: شناسایی اشیا، مکانها، فعالیتها، گونههای حیوانات و مواردی از این دست.
- اسکن بارکد: برای اسکن و پردازش بارکدها استفاده میشود.
- تشخیص مکان: برای شناسایی امکان معروف و شناخته شده در تصاویر به کار میرود.
- شناسه زبان: برای تشخیص زبان یک متن استفاده میشود.
- ترجمه روی دستگاه: متن نمایش داده شده روی یک دستگاه را از یک زبان به زبانی دیگر ترجمه میکند.
- پاسخ هوشمند: پاسخهای متنی هوشمندانهای بر مبنای پیامهای قبلی تولید میکند.
ML Kit در اصل و به زبان ساده، راهکاری است که با آن میتوانید از پیچیدگیها بهرهگیری از یادگیری ماشین در اپلیکیشنهای خود برای تلفنهای هوشمند بکاهید.
چه چیزی خواهیم ساخت؟
ما در این مقاله از ظرفیت تشخیص چهره ML Kit برای شناسایی چهرهها در یک تصویر استفاده میکنیم. بدین منظور تصاویر را از طریق دوربین میگیریم و اینترفیس را روی آن اجرا میکنیم.
برای استفاده از ML Kit لازم است که یک حساب «فایربیس» (Firebase) داشته باشید. اگر چنین حسابی ندارید به این صفحه (+) مراجعه کنید و یک حساب باز کنید. توجه داشته باشید در زمان نگارش مقاله، این حساب برای دسترسی ایرانیان مسدود بوده است و برای دسترسی به آن نیاز به استفاده از پراکسی وجود دارد.
ایجاد یک پروژه روی فایربیس
زمانی که یک حساب کاربری روی فایربیس باز کردید، به این صفحه (+) بروید و روی add project کلیک کنید.
یک نام به پروژه خود بدهید و روی Create کلیک کنید. ممکن است چند ثانیه طول بکشد تا پروژه شما آماده شود. سپس در ادامه یک اپلیکیشن اندروید به پروژه خود اضافه میکنیم.
افزودن اپلیکیشن
اندروید استودیو را باز کنید و یک پروژه جدید با یک اکتیویتی خالی اضافه کنید. سپس روی Tools -> Firebase کلیک کنید. بدین ترتیب دستیار فایربیس در پنل سمت راست باز میشود. در فهرست گزینهها، ML Kit را انتخاب کرده و روی گزینه زیر کلیک کنید:
Use ML Kit to detect faces in images and video
احتمالاً از شما درخواست میشود که اندروید استودیو خود را به یک اپلیکیشن در فایربیس وصل کنید. روی connect کلیک کرده و در پروژه فایربیس خود sign in کنید. زمانی که اندروید استودیو اجازه دسترسی به پروژه فایربیس را داد، از شما خواسته میشود که یک پروژه انتخاب کنید. پروژهای را که در گام قبلی ایجاد کردید انتخاب کنید. پس از آن باید ML Kit را به اپلیکیشن خود اضافه کنید که یک فرایند تک کلیکی محسوب میشود. زمانی که کار اضافه کردن وابستگیها به پایان رسید، آماده هستید که اپلیکیشن خود را ایجاد کنید.
پیکربندی AndroidManifest.xml
شما باید فایل AndroidManifest.xml خود را طوری ویرایش کنید که امکان یادگیری ماشین آفلاین در اپلیکیشن اندروید خود را داشته باشید. متا-تگ زیر را درست زیر تگ اپلیکیشن خود وارد کنید.
ضمناً قصد داریم یک قابلیت دوربین به اپلیکیشن خود اضافه کنیم و از این رو یک تگ permission در مانیفست اضافه میکنیم.
افزودن یک دوربین به اپلیکیشن
برای افزودن دوربین به اپلیکیشن باید CameraKit مربوط به WonderKiln را اضافه کنیم. برای استفاده از CameraKit وابستگیهای زیر را در فایل build.gradle سطح اپلیکیشن اضافه میکنیم.
نکته: اگر میخواهید از کاتلین در اپلیکیشن اندروید خود استفاده کنید، باید وابستگیهای کاتلین نیز در آن گنجانده شوند.
پروژه را Sync کنید تا وابستگیها دانلود شوند. سپس یک CameraKitView در فایل لیآوت activity_main.xml اضافه میکنیم. به این منظور کد زیر را در فایل لیآوت اضافه کنید.
همچنین یک دکمه به زیر صفحه اضافه میکنیم تا به وسیله آن عکس بگیریم.
پیکربندی دوربین
ما دوربین را در فایل MainActivity.kt مقداردهی میکنیم. به این منظور برخی متدهای چرخه عمر را override خواهیم کرد و درون این متدها، متدهای چرخه عمر را برای دوربین فراخوانی میکنیم:
از اندروید نسخه M به بعد باید مجوزهای زمان اجرا را نیز تقاضا کنیم. این وضعیت از سوی خود کتابخانه CameraKit مربوط به WonderKiln مدیریت میشود. به این منظور کافی است متد زیر را override کنیم:
عکس گرفتن
ما با فشردن دکمه یک عکس میگیریم و آن را به دتکتور ارسال میکنیم. سپس یک مدل یادگیری ماشین روی تصویر اعمال میکنیم تا چهره را شناسایی کنیم. یک onclicklistener روی دکمه و درون تابع onClick تنظیم میکنیم و درون آن تابع captureImage مربوط به ویوی Camera را فراخوانی میکنیم.
در ادامه مقدار byteArray دریافتی را در یک bitmap دیکود میکنیم و سپس bitmap را به یک اندازه معقول مقیاسبندی مینماییم. این اندازه اساساً باید به اندازه camera_view ما باشد.
اکنون زمان آن فرا رسیده است که دتکتور ما روی bitmap اجرا شود. به این منظور تابع جداگانه runDetector() اجرا میکنیم.
شروع تشخیص
این بخش اصلی اپلیکیشن ما است. ما یک دتکتور روی تصویر ورودی اجرا میکنیم. ابتدا یک FirebaseVisionImage از bitmap دریافتی تهیه میکنیم.
سپس نوبت آن میرسد که برخی گزینهها مانند performanceMode ،countourMode ،landmarkMode و غیره را اضافه کنیم.
اکنون دتکتور خود را با استفاده از گزینهها میسازیم.
در نهایت، نوبت آن میرسد که فرایند شناسایی را شروع کنیم. ما با استفاده از این دتکتور تابع detectInImage را فراخوانی کرده و تصویر را به آن ارسال میکنیم. در ادامه callback-هایی برای موفقیت یا شکست دریافت میکنیم.
طرز کار تابع runDetector به صورت زیر است:
ایجاد کادر پیرامونی
برای ایجاد یک کادر پیرامونی که چهرههای شناساییشده را احاطه کند، باید دو view ایجاد کنیم. ویوی اول یک ویوی رویی شفاف است که روی آن کادر را رسم میکنیم. سپس کادر واقعی را روی تصویر قرار میدهیم.
فایل GraphicOverlay.java به صورت زیر است:
کادر مستطیلی واقعی به صورت زیر است:
اینک زمان آن رسیده که این ویوی graphicOverlay را در فایل لیآوت activity_main.xml خود اضافه کنیم.
در نهایت فایل activity_main.xml به صورت زیر درمیآید:
اینک زمان آن است که کادر پیرامونی چهرههای شناسایی شده را رسم کنیم. ما با استفاده از دتکتور چهرهها را در تابع ()processFaceResult دریافت کردهایم.
در ادامه حلقهای روی همه چهرهها تعریف کرده و یک کادر روی هر چهره به صورت زیر اضافه میکنیم:
سخن پایانی
در نهایت اپلیکیشن ما چیزی مانند تصویر زیر خواهد بود:
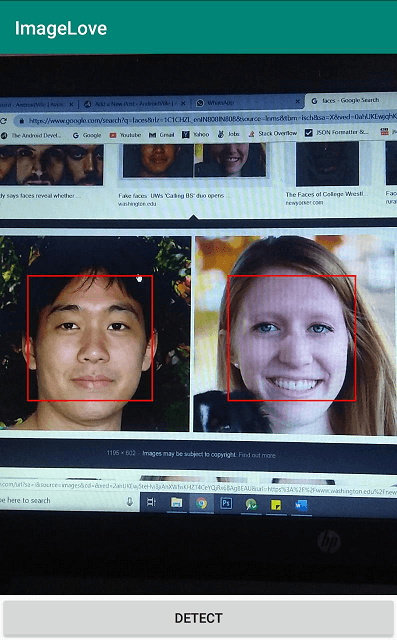
شما میتوانید سورس کد این اپلیکیشن را از این صفحه گیتهاب (+) دانلود کنید. روی این کد کار کنید و ایدههای مختلفی که برای پیادهسازی یادگیری ماشین در اپلیکیشنهای اندرویدی دارید امتحان نمایید.
برنامه بررسی وجود دور در گراف بدون جهت — راهنمای کاربردی
در این مطلب، برنامه بررسی وجود دور در گراف بدون جهت در زبانهای برنامهنویسی «سیپلاسپلاس» (++C)، «پایتون» (Python) و«جاوا» (Java) ارائه شده است. در ادامه، مساله تعریف و همراه با مثالی حل میشود. یک گراف بدون جهت داده شده است. هدف آن است که بررسی شود آیا دوری در گراف وجود دارد یا نه. برای مثال، گراف زیر دارای دور 1-2-۰-1 است.

پیش از این، در مطلبی با عنوان «برنامه تشخیص وجود دور در گراف جهت دار — راهنمای کاربردی»، روش پیدا کردن دور در گراف جهت دار مورد بررسی قرار گرفت. پیچیدگی زمانی الگوریتم مجموعههای مجزا برابر با (O(ELogV است. میتوان همچون گراف جهتدار، از «جستجوی اول عمق» (Depth First Search | DFS) برای شناسایی دور در گرافهای بدون جهت در زمان (O(V+E استفاده کرد. پیمایش گراف داده شده با استفاده از DFS انجام میشود. برای هر راس بازدید شده V، اگر راس همسایه u وجود دارد که پیش از این بازدید شده باشد و u والد v نباشد، دور در گراف وجود دارد. اگر چنین راس مجاوری برای هیچ راسی یافت نشود، گفته میشود که گراف فاقد دور است. فرض این رویکرد آن است که هیچ دو یال موازی بین دو راس وجود نداشته باشد.
برنامه بررسی وجود دور در گراف بدون جهت در ++C
برنامه بررسی وجود دور در گراف بدون جهت در جاوا
برنامه بررسی وجود دور در گراف بدون جهت در پایتون
خروجی
Graph contains cycle Graph doesn't contain cycle
پیچیدگی زمانی
برنامه، یک پیمایش ساده DFS را در گراف انجام میدهد و گراف با استفاده از لیست همجواری نشان داده میشود. بنابراین، پیچیدگی زمانی از درجه (O(V+E است.
منبع: فرادرس
جستجوی دودویی — به زبان ساده
در این مطلب، الگوریتم جستجوی دودویی (Binary Search) مورد بررسی قرار گرفته و پیادهسازی آن در زبانهای برنامهنویسی گوناگون انجام شده است.
جستجوی دودویی
در جستجوی دودویی (Binary Search)، جستجو در یک آرایه مرتب شده، با تقسیم تکرار شونده بازه جستجو به نصف، انجام میشود. کار با بازهای که کل آرایه را پوشش میدهد، آغاز میشود. اگر مقدار کلید جستجو برابر با عنصر میانی باشد، اندیس آن بازگردانده میشود. در غیر این صورت، اگر مقدار کلید جستجو کمتر از عنصری باشد که در میانه بازه قرار دارد، بازه شکسته شده و جستجو در نیمه کمتر ادامه پیدا میکند. در صورتی که مقدار کلید جستجو بزرگتر از اندیس میانی آرایه باشد، جستجو در نیمه بیشتر (حاوی مقادیر بزرگتر) آرایه ادامه پیدا میکند. کار شکستن آرایه به دو نیم و انتخاب نیمهای که جستجو باید در آن انجام شود، مکررا و تا هنگامی که عنصر مورد نظر در آرایه یافته شود و یا مشخص شود که عنصر مورد نظر در آرایه وجود ندارد، ادامه خواهد داشت.
مثالی از جستجوی دودویی
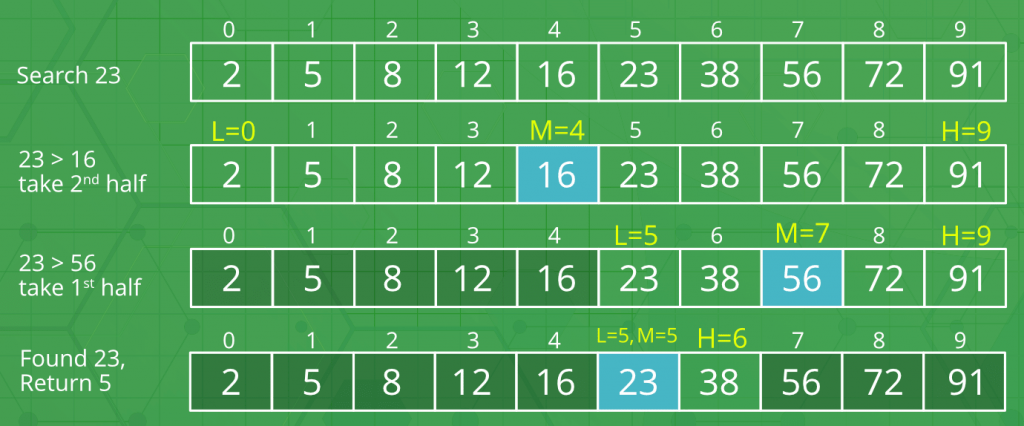
آرایه مرتب شده []arr شامل n عنصر موجود است. هدف، نوشتن تابعی است که یک عنصر داده شده x را در آرایه مذکور ([]arr) جستجو کند. یک رویکرد ساده برای انجام این کار، استفاده از «جستجوی خطی» (Linear Search) است. پیچیدگی زمانی الگوریتم جستجوی خطی، (O(n است. رویکرد دیگر، انجام کار مشابهی با استفاده از «جستجوی دودویی» (Binary Search) است. ایده اصلی نهفته در پس جستجوی دودویی، استفاده از اطلاعات موجود در آرایه مرتب شده و کاهش پیچیدگی زمانی به (O(Log n است. در جستجوی دودویی اساسا نیمی از عناصر تنها پس از یک مقایسه حذف میشوند. برای انجام جستجو، از الگوریتم زیر استفاده میشود.
- x با عنصر میانی آرایه مقایسه میشود.
- اگر x با عنصر میانی آرایه یکی بود، اندیس عنصر میانی را بازگردان.
- در غیر این صورت، اگر x بزرگتر از عنصر میانی بود، امکان دارد x در نیمه سمت راست آرایه، پس از عنصر میانی، قرار داشته باشد (شایان توجه است که همانطور که پیشتر اشاره شد، آرایه مرتب شده است. پس در این حالت، نیمهای با مقادیر بزرگتر برای ادامه جستجو گزینش میشود).
- در غیر این صورت، اگر x از عنصر میانی آرایه کوچکتر باشد، آرایه به دو نیمه شکسته شده و جستجو در نیمه سمت چپ (با مقادیر کوچکتر از میانه)، ادامه پیدا میکند.
در ادامه، پیادهسازی الگوریتم جستجوی دودویی به صورت بازگشتی، در زبانهای برنامهنویسی C++ ،C، «جاوا» (Java)، «پایتون» (Python)، «سیشارپ» (#C) و PHP ارائه شده است.
کد بازگشتی الگوریتم جستجوی دودویی در C
کد بازگشتی الگوریتم جستجوی دودویی در ++C
کد بازگشتی الگوریتم جستجوی دودویی در جاوا
کد بازگشتی الگوریتم جستجوی دودویی در پایتون
کد بازگشتی الگوریتم جستجوی دودویی در #C
کد بازگشتی الگوریتم جستجوی دودویی در PHP
خروجی
Element is present at index 3
در ادامه، کد مربوط به پیادهسازی الگوریتم جستجوی دودویی به صورت «تکرار شونده» (Iterative) ارائه شده است.
کد تکرار شونده الگوریتم جستجوی دودویی در C
کد تکرار شونده الگوریتم جستجوی دودویی در ++C
کد تکرار شونده الگوریتم جستجوی دودویی در جاوا
کد تکرار شونده الگوریتم جستجوی دودویی در پایتون
کد تکرار شونده الگوریتم جستجوی دودویی در #C
کد تکرار شونده الگوریتم جستجوی دودویی در PHP
خروجی
Element is present at index 3
پیچیدگی زمانی
پیچیدگی زمانی جستجوی دودویی را میتوان به صورت زیر نوشت:
T(n) = T(n/2) + c
رابطه بازگشتی بالا را میتوان با استفاده از روش «درخت بازگشتی» (Recursive tree) یا «قضیه اصلی واکاوی (تحلیل) الگوریتمها» (Master method) حل کرد. این رابطه، در حالت دوم قضیه اصلی تحلیل الگوریتمها صدق میکند و راهکار بازگشتی به صورت (Theta(Logn است.
«فضای کمکی» (Auxiliary Space)، اگر پیادهسازی به صورت تکرار شونده باشد برابر با (O(1 و در صورتی که بازگشتی باشد، از مرتبه (O(Logn فضای پشته فراخوانی بازگشتی است.