طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیالگوریتم بهینه سازی کلونی مورچگان در جاوا — راهنمای کاربردی
در این مقاله به توضیح مفهوم «بهینهسازی کلونی مورچگان» (ant colony optimization) یا به اختصار ACO میپردازیم و کدهای نمونه آن را نیز ارائه میکنیم.
طرز کار الگوریتم کلونی مورچگان چگونه است؟
ACO یک الگوریتم ژنتیک است که از رفتار طبیعی مورچهها الهام گرفته است. برای درک کامل الگوریتم ACO باید با مفاهیم مقدماتی آن آشنا باشیم.
- مورچهها از «فرمیون» (pheromone) برای یافتن کوتاهترین مسیر بین خانه و منبع غذایی استفاده میکنند.
- فرمیونها به سرعت تبخیر میشوند.
- مورچهها مسیرهای کوتاهتر با فرمیونهای چگالتر را ترجیح میدهند.
در ادامه مثال سادهای از الگوریتم کلونی مورچگان را که به صورت مسئله فروشنده دورهگرد مطرح شده، مورد بررسی قرار میدهیم. در مثال زیر باید کوتاهترین مسیر بین همه گرههای گراف را بیابیم.
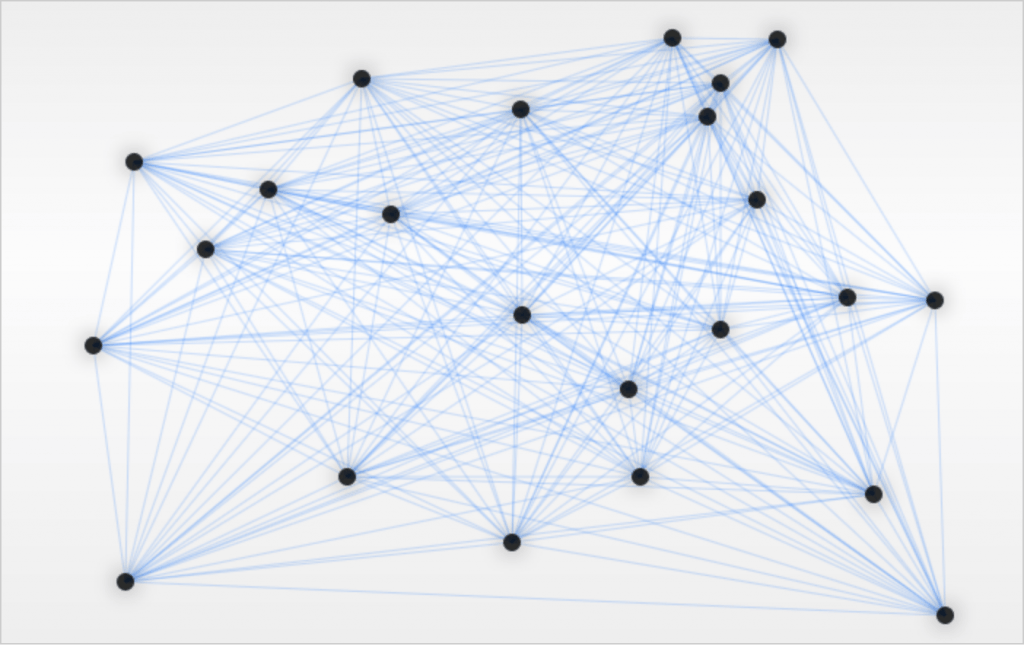
مورچهها با پیروی از رفتار طبیعیشان شروع به جستجوی مسیرهای جدید در مرحله کاوش میکنند. مسیرهای آبی پررنگ نشاندهنده مواردی هستند که نسبت به بقیه بیشتر استفاده شدهاند؛ در حالی که مسیرهای سبزرنگ نماینده کوتاهترین مسیر کنونی پیدا شده است:
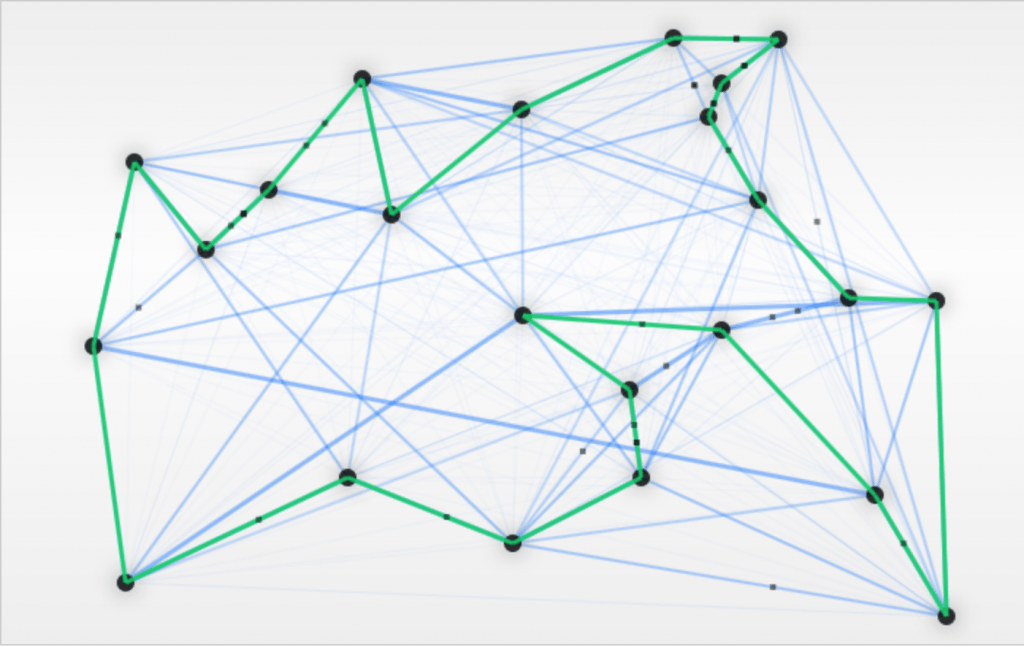
در نتیجه به کوتاهترین مسیر بین همه گرهها دست پیدا کردهایم:

برای مشاهده یک ابزار زیبای مبتنی بر GUI برای آزمودن ACO میتوانید به این آدرس (+) مراجعه کنید.
پیادهسازی جاوا
در این بخش به بررسی روش موردنیاز برای پیادهسازی بهینهسازی کلونی مورچگان در زبان برنامهنویسی جاوا میپردازیم.
پارامترهای ACO
ابتدا پارامترهای الگوریتم ACO را که در کلاس AntColonyOptimization اعلان شدهاند، بررسی میکنیم:
پارامتر c نشاندهنده عدد اولیه «مسیرها» (trails) در ابتدای شبیهسازی است. به علاوه، alpha به کنترل اهمیت فرمیون میپردازد؛ در حالی که beta اولویت مسافت را کنترل میکند. به طور کلی در بهترین نتایج پارامتر بتا باید بزرگتر از آلفا باشد.
سپس متغیر «تبخیر» (evaporation) نشان میدهد که چه درصدی از فرمیون در هر تکرار تبخیر میشود؛ در حالی که Q اطلاعاتی در مورد مقدار کلی فرمیون باقیمانده روی مسیر از سوی هر مورچه و antFactor نیز تعداد مورچههای هر شهر را نشان میدهد. در نهایت باید مقداری تصادفی بودن به شبیهسازیهای خود اضافه کنیم که این وظیفه نیز به پارامتر ranfomFactor محول شده است.
ایجاد مورچهها
هر مورچه امکان بازدید از یک شهر خاص را دارد، همه شهرهای بازدید شده را به خاطر میسپارد و رد طول مسیر را نگه میدارد:
تنظیم مورچهها
در ابتدای کار، باید پیادهسازی کد ACO خود را از طریق ارائه ماتریسهای مسیرها و مورچهها، مقداردهی اولیه بکنیم:
سپس باید ماتریس مورچگان را با یک شهر تصادفی مقداردهی بکنیم:
در هر تکرار این حلقه، عملیات زیر اجرا میشوند:
جابجایی مورچهها
کار خود را با متد ()moveAnts آغاز میکنیم. به این منظور باید شهر بعدی را برای همه مورچهها تنظیم کنیم و مسیر هر مورچه را برای پیمودن از سوی مورچههای دیگر به خاطر بسپاریم:
مهمترین بخش، انتخاب مناسب شهر بعدی برای بازدید است. ما باید شهر بعدی را بر مبنای منطق احتمال انتخاب کنیم. ابتدا بررسی میکنیم که آیا مورچه باید از یک شهر تصادفی بازدید کند یا نه:
اگر هیچ شهر تصادفی را انتخاب نکرده باشیم، باید احتمالهای انتخاب شهر بعدی را نیز محاسبه کنیم و به خاطر داشته باشیم که مورچه ترجیح میدهد، مسیر قویتر و کوتاهتر را بپیماید. این کار از طریق مرتبسازی احتمال رسیدن به هر شهر در آرایه ممکن است:
پس از آن که احتمالها را محاسبه کردیم، میتوانیم با کد زیر در مورد این که به کدام شهر باید برویم تصمیمگیری کنیم:
بهروزرسانی مسیرها
در این مرحله، باید مسیرها و میزان فرمیون باقیمانده را بهروزرسانی کنیم:
بهروزرسانی بهترین انتخاب
این آخرین مرحله برای هر تکرار است. ما باید بهترین انتخاب را بهروزرسانی کنیم تا ارجاع آن را حفظ کنیم:
پس از اجرای همه تکرارها، نتیجه نهایی بهترین مسیر مشخص شده از سوی ACO را نشان خواهد داد. توجه داشته باشید که با افزایش تعداد شهرها، احتمال یافتن کوتاهترین مسیر کاهش مییابد.
نتیجهگیری
در این راهنما به معرفی الگوریتم بهینهسازی کلونی مورچگان پرداختیم. شما میتوانید با مطالعه این مقاله بدون هیچ دانش قبلی و صرفاً به کمک مهارتهای ابتدایی برنامهنویسی رایانه، با الگوریتمهای ژنتیک آشنا شوید.
کد کامل این راهنما را میتوانید در این ریپوی گیتهاب (+) ملاحظه کنید.
منبع: فرادرس
ابزار آنالیز استاتیک کد در اندروید استودیو — راهنمای مقدماتی
آنالیز استاتیک یا آنالیز استاتیک کد نوعی از آنالیز است که بر مبنای برخی قواعد تعیینشده و پیش از اجرای برنامه و معمولاً حتی پیش از تست unit، روی کد منبع اعمال میشود. این نوعی از دیباگ کردن است که بدون اجرای برنامه انجام مییابد و معمولاً نخستین گام در جهت آنالیز کد محسوب میشود. از آنجا که این آنالیز بر مبنای برخی قواعد تعیینشده اجرا میشود به حفظ قراردادهای درون تیم توسعه برای نگهداری از کد کمک میکند.
اجرای این آنالیز به صورت دستی در طی فرایند مرور کد ممکن است، اما در این حالت احتمال بروز خطاهای انسانی بالا است و چندان کارآمد یا مؤثر نیست. برای حل این مشکل برخی ابزارهای خودکار سازی جالب مانند lint ابداع شدهاند که اینک به صورت آماده در اندروید استودیو جای گرفتهاند و میتوانیم از آنها استفاده کنیم. در این نوشته، قصد داریم از یک چنین ابزاری بهره جسته و به عنوان نمونه یک پروژه اندروید را مورد بررسی قرار دهیم.
Lint کردن به چه معنا است؟
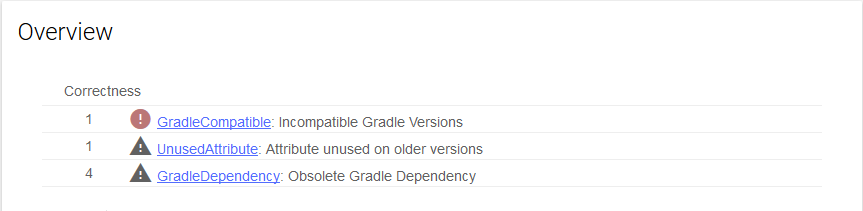
Lint کردن با پیروی از قواعدی که در یک فایل پیکربندی مانند lint.xml تعریف شدهاند صورت میگیرد. سپس ابزار lint این قواعد را با فایلهای کد منبع بررسی میکند. برای این که درک بهتری به دست آورید به تصویر زیر مراجعه کنید:
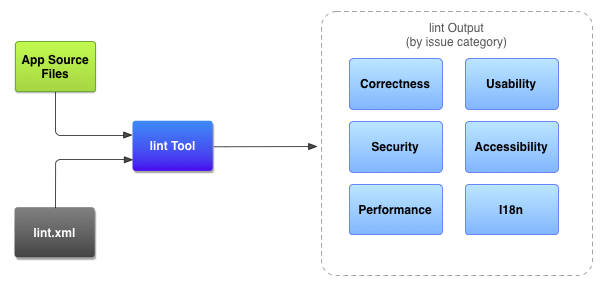
استفاده از Lint در پروژه
دو روش برای انجام این کار وجود دارد که یکی از آنها بهرهگیری از اندروید استودیو و دیگری استفاده از ترمینال و gradle است.
استفاده از اندروید استودیو
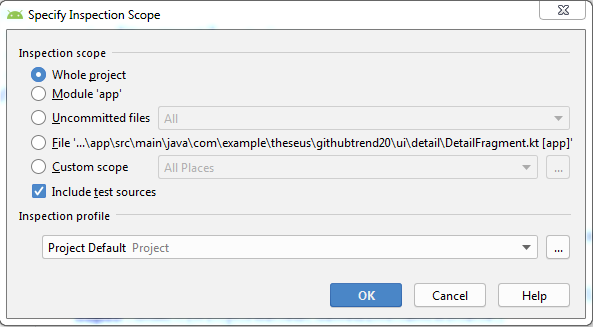
دو روش برای اجرای ابزار lint روی کد منبع وجود دارد. میتوان این کار را از نوارابزار Analyze > Inspect Code اجرا کرد. سپس یک کادر گفتگو باز میکنیم که در آن میتوان دامنه کد منبع را برای اجرای ابزار lint تعیین کرد. در تصویر زیر مثالی از آن را میبینید:
پس از مدتی اندروید استودیو نتایج را در پنجره Inspection results به صورت تصویر زیر نمایش میدهد:
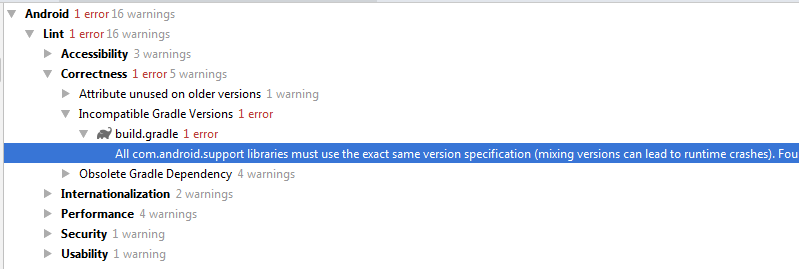
استفاده از gradle
برای اجرای lint از gradle، میتوانید از دستورهای زیر استفاده کنید.
- روی ویندوز: gradlew lint
- روی لینوکس یا مک: gradlew lint/.
دقت کنید که هنگام اجرای دستورهای فوق gradle به صورت پیشفرض lint را روی بیلد release اجرا میکند. جهت اجرای آن روی یک بیلد متفاوت مانند debug میتوانید نام بیلد را به صورت gradlew lintDebug اضافه کنید. پس از این که کار lint کردن پایان یافت، نتایج در قالب html و xml ایجاد میشوند.
![]()
توجه کنید که اگر هر گونه خطای lint وجود داشته باشد، اندروید استودیو نمیتواند نتایج را تولید کند و از این رو باید خطوط زیر را در فایل سطح gradle اپلیکیشن خود اضافه کنید:
سفارشیسازی قواعد Lint کردن
شاید نیازهای شما یا قراردادهای کدنویسی تیم از پیکربندی پیشفرض متفاوت باشد. بنابراین میتوانید تنظیمات را در فایل gradle به صورت زیر تغییر دهید:
در مثال فوق، بررسی lint را برای هشدار ContentDescription در کل پروژه غیرفعال کردهایم. اگر نمیخواهید این وضعیت را روی کل پروژه اعمال کنید و میخواهید آن را صرفاً روی چند فایل به کار بگیرید، میتوانید روی فایلهای جاوا یا کاتلین از یک annotation به صورت SupressLint@ استفاده کنید و روی فایلهای xml نیز میتوانید از tools:ignore استفاده کنید. مثال زیر را بررسی کنید:
در مورد فایلهای xml از کد زیر استفاده کنید:
اگر به خاطر داشته باشید کمی پیشتر اشاره کردیم که ابزار lint از فایل پیکربندی lint.xml استفاده میکند. شما میتوانید فایل lint.xml خاص خود را بسازید و قواعد مرتبط با نیازهای خود را تعیین کنید. در مثال زیر ما فایل lint.xml خود را ایجاد کردهایم و یک قاعده برای نادیده گرفتن هشدار missing contentDescription تعیین کردهایم.
پس از آن باید ارجاعی به فایل gradle به صورت زیر ایجاد کنیم:
توجه داشته باشید که در حالت فوق، قواعد lint که در فایل lint.xml تعیینشدهاند، روی کل ماژول اعمال میشوند. اگر میخواهید آن را روی مسیر خاصی به کار بگیرید، میتوانید به صورت زیر عمل کنید:
سخن پایانی
بدین ترتیب به پایان این مقاله میرسیم. تلاش کنید در پروژه بعدی خود از این ابزار جذاب استفاده کرده و کدهای با کیفیت بالاتری تولید کنید. امیدواریم از خواندن این مقاله لذت برده باشید. هر گونه دیدگاه یا پیشنهاد خود را میتوانید در بخش نظرات این نوشته با ما و دیگر خوانندگان فرادرس در میان بگذارید.
منبع: فرادرس
طراحی اسکریپت ژنتیک در پایتون — به زبان ساده
در این مقاله در خصوص برخی آرگومانهای خط فرمان و ورودی کاربر صحبت میکنیم که طراحی اسکریپت ژنتیک را در پایتون میسر ساختهاند.
ساخت رابطهای کاربری
در این بخش مراحل ابتدایی برای ساخت یک رابط کاربری با استفاده از ورودی تعاملی کاربر و آرگومانهای خط فرمان را مورد بررسی قرار میدهیم. کدی که در این مقاله ارائه شده است، در طی بخشهای بعدی این سری مقالات بهبود خواهد یافت.
در هنگام طراحی یک اسکریپت، همواره باید کاربر را در نظر داشت. در اغلب موارد، زمانی که یک اسکریپت را برای حل یک مشکل مینویسیم، این احتمال وجود دارد که مشکل افراد دیگری را نیز حل کنیم. با در نظر داشتن این ذهنیت همواره باید میزان سهولت استفاده از برنامه خودتان از سوی افراد دیگر را نیز مورد توجه قرار دهید. ما در این مقاله با پیروی از یک سری قواعد کلی مثالهایی از اسکریپتهای ژنتیک ارائه میکنیم، اما ایدههای مطرح شده در آن میتوانند به صورت گستردهای برای طراحی هر برنامه دیگری نیز استفاده شوند.
سناریوی زیر را در نظر بگیرید. ما میخواهیم یک توالی DNA را مورد جستجو قرار دهیم و تعیین کنیم که آیا دو جایگاه آنزیم محدودکننده در بالاتر از یک آستانه تعیینشده وجود دارند یا نه. برای نمونه آیا توالی آنزیمهای محدودکننده برای EcoRI و HindIII در یک توالی DNA بیش از 5، 10 یا 15 بار حضور دارند؟
بدین ترتیب برنامه پایتون ما باید شرایط زیر را داشته باشد:
- انعطافپذیر باشد: یعنی کاربر امکان جستجوی جایگاههای محدودکننده یا در واقع هر موتیف DNA در یک توالی DAN را دارد و تعداد تکرار آن را بالاتر از یک حد آستانه مشخص میسازد.
- امکان کنترل داشته باشد: هر توالی DNA که کاربر انتخاب میکند را جستجو کند.
- بخشنده باشد: برنامه میبایست اشتباههای معمول کاربران را در نظر بگیرد. برای مثال تایپ کردن نام بازهای DNA بدون استفاده از کاراکترهای ambiguity در یک توالی DNA یا استفاده از حروف کوچک برای بازهای DNA.
- «بسیار» بخشنده باشد: برنامه باید همه تلاش خود را در راستای کمک به کاربر در جهت وارد کردن یک توالی معتبر DNA ارائه کند.
ورودی تعاملی کاربر
برای دریافت ورودی کاربر در یک برنامه باید از تابع ()input استفاده کنیم. تابع ()input یک آرگومان منفرد رشتهای میگیرد که از طریق اعلان نمایش یافته برای کاربر دریافت میشود و مقدار وارد شده را به صورت یک رشته بازمیگرداند. در این حالت بهتر است پیامی به کاربر نمایش داده شود که به صورت روشنی از وی بخواهد مقدار مورد نظر خود را وارد نماید. در مثال زیر از کاربر میخواهیم که یک توالی DNA را وارد کند:
با این وجود، بروز خطا ناگزیر است و یک ضربه نادرست روی کیبورد و یا غلط املایی هر زمان محتمل است. در چنین وضعیتی دو گزینه در اختیار داریم؛ میتوانیم به سادگی از برنامه خارج شویم و همه کارها را از نو آغاز کنیم. برای خروج بیدرنگ میتوانیم کد زیر را اجرا کنیم:
با این حال، این کار به صورت شهودی نادرست به نظر میرسد. به طور جایگزین میتوانیم امکان وارد کردن مقدار دیگری را در اختیار کاربر قرار دهیم و یا این کار را تا هر تعداد دفعاتی که کاربر یک توالی DNA قابل قبول وارد نکرده است، تکرار کنیم. این کار به نام اعتبارسنجی ورودی کاربر شناخته میشود و اساساً به معنی بررسی معنیدار بودن ورودی ارائه شده از سوی کاربر است. در این مثال، ما میخواهیم که کاربر یک توالی را بدون بازهای مبهم وارد کند. ما میتوانیم از یک گروه کاراکتر منفی شده و تابع ()re.search برای اطمینان یافتن از این که کاربر یک توالی معتبر DNA وارد کرده است استفاده کنیم. همچنین از متد ()upper. استفاده میکنیم تا مطمئن شویم که همه حروف توالی به صورت حروف بزرگ لاتین هستند. این مباحث همگی در حوزه «عبارتهای منظم» (Regular Expressions) قرار میگیرند.
زمانی که برنامه ورودی کاربر را دریافت کند، باید به دقت در مورد طراحی آن تأمل کنیم. در برخی موارد کاربر یک برنامه را اجرا میکند و این برنامه نیازمند نوعی ورودی کاربر است که این مسئله به طور روشنی مشخص نشده است. ما باید از چنین موقعیتهایی اجتناب کنیم. در چنین وضعیتی کاربر ممکن است توجه خود را به چیز دیگری معطوف کند و برنامه در اعلان خود منتظر ورودی کاربر باشد و بدین ترتیب هیچ پیشرفتی در روند کار صورت نگیرد.
گرچه ورودی کاربر میتواند موجب تعاملی و انعطافپذیر شدن برنامه بشود؛ اما اجرای برنامههایی که بخشی از گردش کار آن به صورت نظارتنشده است کار دشوارتری محسوب میشود. به طور ایدهآل بهتر است موقعیتهایی را طراحی کنیم که برنامه ما همه آرگومانهای تعیینشده را در آغاز از کاربر دریافت کند. برای نیل به این مقصود؛ آرگومانهای خط فرمان یک راهحل ایدهآل محسوب میشوند.
آرگومانهای خط فرمان
آرگومانهای خط فرمان رشتههایی هستند که پس از نام برنامهای که میخواهیم اجرا شود، در خط فرمان تایپ میکنیم. برای استفاده از آرگومانهای خط فرمان در اسکریپتهای پایتون لازم است که ماژول sys ایمپورت شود. سپس میتوانیم با استفاده از لیست خاص بازگشتی از سوی sys.argv به آرگومانهای خط فرمان دسترسی داشته باشیم. عنصر نخست sys.argv، نام برنامه است که در این مورد به صورت Command_line_arguments.py و در اندیس 0 لیست قرار دارد. مثال زیر، اندیسها آرگومانهای متناظر خط فرمان آن را نمایش میدهد.
ما میتوانیم با ایجاد امکان وارد کردن توالی به صورت حروف کوچک یا بزرگ در خط فرمان، کد خود را بیش از این پایدار بسازیم. همچنین میتوان از متد رشته ()upper. به منظور مدیریت این وضعیت بهره جست. با این وجود، یک نکته مهم که باید توجه داشت این است که گزینههای خط فرمان همواره به صورت رشته بازگشت مییابند و از این رو باید count_no را به شکل زیر صریحاً به صورت عدد صحیح تبدیل کنیم:

در خط فرمان زیر، به نکاتی که در ادامه آمده است میتوان اشاره کرد:
- GA نخستین آرگومان خط فرمان در اندیس 1 است که به الگو اشاره میکند.
- TC دومین آرگومان خط فرمان در اندیس 2 است که به الگوی 2 اشاره میکند.
- 2 سومین آرگومان خط فرمان است که در اندیس 3 قرار دارد و به count_no اشاره میکند.

اسکریپت پایتون ما یک تابع برای جستجوی دو آنزیم محدودکننده درون توالی DNA تعیین شده تعریف میکند. سپس یک دیکشنری میسازیم و در آن به ذخیرهسازی توالی آنزیم محدودکننده به صورت کلید میپردازیم و مقادیر آن نیز شمار آنها خواهد بود. در ادامه روی این دیکشنری یک حلقه تعریف و بررسی میکنیم که آیا توالی بزرگتر از تعداد تعیینشده از سوی کاربر است یا نه. کد کامل اسکریپت به صورت زیر است:
اکنون میتوانیم اسکریپت را با استفاده از آرگومانهای خط فرمان اجرا کنیم. در این مرحله برای تست کارکرد برنامه از یک توالی کوچک تعیینشده از سوی کاربر استفاده کرده و تلاش میکنیم تعیین کنیم آیا tri-nucleotide-های TGC و ATG بیش از 3 بار وجود دارند یا نه.
در این مثال، میتوانیم به وضوح مشاهده کنیم که کاربر یک نوکلئوتید DNA نامعتبر به صورت F (با رنگ زرد مشخص شده) وارد کرده است. برنامه ما در ادامه از کاربر میخواهد که یک توالی معتبر DNA وارد کند و زمانی که این کار صورت گرفت، نتیجه را بازگشت میدهد.

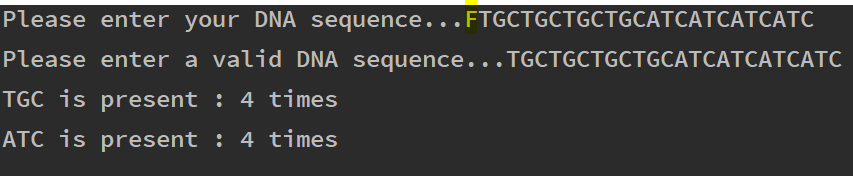
با این حال در اغلب موارد میخواهیم کل ژنوم را مورد جستجو قرار دهیم و از این رو تقاضا برای وارد کردن مقدار از سوی کاربر بهسادگی میسر نیست. برای نمایش بهتر این که این برنامه تا چه حد میتواند مفید باشد ما کل ژنوم E.coli را از NCBI با شماره دسترسی Genbank CU928161.2 دانلود کردیم. این ژنوم نسبتاً بزرگ است و دقیقاً شامل 5،032،268 جفت باز است. با این وجود، اسکریپت ما به طرز کارآمدی آن را مدیریت میکند و نتیجه را تقریباً به صورت آنی بازگشت میدهد. در مثال زیر جستجو کردهایم که جایگاههای آنزیمهای محدودکننده EcoR1 GTTACC, و HindIII AAGCCT در ژنوم بالاتر از 50 بار حضور دارند یا نه. اگر چنین باشد برنامه اعلام میکند که چندین بار این جایگاهها وجود داشتهاند.

علاوه بر این میتوانیم خروجی بسیار واضحتری از ترمینال بگیریم و بدین ترتیب همه افرادی که نتایج را روی ترمینال میخوانند، میتوانند دادهها را تفسیر کنند.

نتیجهگیری
آرگومانهای خط فرمان روشی مناسب برای دریافت ورودی در برنامههای پایتون محسوب میشود. در این روش همه دادههای متناظر که برنامه نیاز دارد در آغاز ارائه میشوند. در این راهنما مقدمه کوتاهی در مورد روش طراحی اسکریپتهای پایتون با ذهنیت کاربر محور ارائه کردیم. اگر میخواهید کاربر بتواند با برنامه شما تعامل داشته باشد، باید انتظار بروز خطا را نیز داشته باشید و بر همین اساس باید رویههای اصلاح خطا را در اسکریپت خود در نظر بگیرید.
منبع: فرادرس
ساخت ربات تلگرام برای دریافت اعلان های سفارشی — به زبان ساده
در این مقاله روش استفاده از ربات تلگرام برای دریافت اعلان های سفارشی در موضوعات خاص را بررسی میکنیم. فرض کنید یک اپلیکیشن را روی یک سرور توزیع کردهاید. همواره برخی کارها وجود دارند که لازم است در پسزمینه اجرا شوند. اما برای این که متوجه شویم این کارها پایان یافتهاند یا نه، باید به صورت دستی آنها را بررسی کنیم.
این همان نقطهای است که رباتهای تلگرام به کار میآیند. البته روشهای مختلفی برای ارسال چنین اعلانهایی از طریق ابزارهای شخص ثالث وجود دارند. برای مثال میتوان یک ایمیل، پیامک و یا حتی پیام slack ارسال کرد.
اما استفاده از پیامرسان تلگرام به این منظور بسیار کارآمد است، زیرا پلتفرم ربات آن امکانات بسیار زیادی دارد و خود این سرویس نیز به عنوان یک سرویس پایدار و رایگان برای این منظور کاملاً مناسب است.
ایجاد یک ربات تلگرام
برای ایجاد یک ربات تلگرام ابتدا باید به ربات botfather (+) مراجعه کنید و یک پیام به صورت newbot/ به آن ارسال کنید. ارسال این پیام بهسادگی به صورت زیر ممکن است:
مطمئن باشید که توکن API خود را به جای TELEGRAM_TOKEN$ جایگزین کردهاید.
برای به دست آوردن chat_id میتوانید ربات خود را به یک گروه یا گفتگویی که میخواهید اعلانها به آن ارسال شوند اضافه کنید. سپس یک پیام ارسال کرده و آن را اجرا کنید:
در این مرحله یک پاسخ JSON دریافت میکنید و درون این پیام میتوانید chat_id خود را به دست آورید.
استفاده از کلاینت Bash تلگرام
مرحله بعدی این است که این کلاینت Bash تلگرام (+) را فورک کنید تا از طریق دستور زیر یک پیام را ارسال کنید:
همچنین میتوانید متغیرهای محیطی را طوری تنظیم کنید که دیگر نیازی به وارد کردن مکرر TELEGRAM_TOKEN و TELEGRAM_CHAT نباشد. بدین ترتیب دستور موردنیاز برای ارسال پیام Hello World! به صورت زیر درمیآید:
همان طور که میبینید، قابلیت بسیار جالبی است. بدین ترتیب به محض این که کار مورد نظر شما به پایان برسد، میتوانید از دستورهای فوق برای ارسال یک پیام و همچنین خلاصهای از نتیجه اجرای آن کار برای خودتان استفاده کنید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
منبع: فرادرس
جستجوی الگو (Pattern Searching) — به زبان ساده
در این مطلب، جستجوی الگو (Pattern Searching) مورد بررسی قرار میگیرد و یک الگوریتم ساده برای این کار ارائه میشود. متن [txt[0..n-1 و الگوی [pat[0..m-1 موجود است؛ هدف نوشتن تابع جستجویی ([]char pat[], char txt) است که همه وقوعهای []pat در []txt را چاپ کند. میتوان فرض کرد که n > m است. مثالهای زیر در این راستا قابل توجه هستند.
Input: txt[] = "THIS IS A TEST TEXT"
pat[] = "TEST"
Output: Pattern found at index 10
Input: txt[] = "AABAACAADAABAABA"
pat[] = "AABA"
Output: Pattern found at index 0
Pattern found at index 9
Pattern found at index 12
جستجوی الگو، یک مسأله مهم در علوم کامپیوتر است. هنگامی که یک رشته در فایل «نوتپد» (Notepad)، «ورد» (Word)، مرورگر و یا «پایگاهداده» (Database) جستجو میشود از جستجوی الگو برای نمایش نتایج جستجو استفاده میشود.
الگوریتم ساده برای جستجوی الگو
الگو در متن به این صورت بررسی میشود که از آغاز متن به صورت اسلایدی (کشویی) با متن مطابقت داده میشود. اگر الگویی مطابق با الگوی جستجو شده در متن پیدا شد، فعالیت مجددا ادامه پیدا میکند تا سایر الگوها نیز یافت شوند.
الگوریتم ساده جستجوی الگو در ++C
الگوریتم ساده جستجوی الگو در C
الگوریتم ساده جستجوی الگو در جاوا
الگوریتم ساده جستجوی الگو در #C
الگوریتم ساده جستجوی الگو در PHP
الگوریتم ساده جستجوی الگو در پایتون ۳
خروجی و پیچیدگی زمانی
خروجی قطعه کدهای بالا، به صورت زیر است.
Pattern found at index 0 Pattern found at index 9 Pattern found at index 13
بهترین حالت
بهترین حالت هنگامی به وقوع میپیوندد که اولین کاراکتر از الگو هرگز در متن ظاهر نشود.
txt[] = “AABCCAADDEE”;
pat[] = “FAA”;
تعداد مقایسه ها در بهترین حالت (O(n است.
بدترین حالت
بدترین حالت الگوریتم جستجوی الگوی ساده در شرایط زیر به وقوع میپیوندد.
۱. هنگامی که همه کاراکترهای متن و الگو مشابه باشد:
txt[] = "AAAAAAAAAAAAAAAAAA"; pat[] = "AAAAA";
۲. همچنین، بدترین حالت هنگامی به وقوع میپیوندد که آخرین کاراکتر متفاوت باشد.
txt[] = "AAAAAAAAAAAAAAAAAB"; pat[] = "AAAAB";
تعداد مقایسهها در بدترین حالت برابر با ((O(m*(n-m+1 است. با وجود اینکه برخی از رشتهها دارای کاراکترهایی هستند که در زبان انگلیسی ظاهر نمیشود، اما این رشتهها ممکن است در دیگر کاربردها به وقوع بپیوندند (برای مثال، در متنهای دودویی). الگوریتم تطبیق KMP، بدترین حالت را به (O(n بهبود میبخشد.
منبع: فرادرس