طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسییادگیری ماشین با پایتون — به زبان ساده
با گسترش استفاده از «یادگیری ماشین» (Machine Learning) در صنایع گوناگون، نیاز به ابزاری که بتواند به فرد برای انجام فرایندهای مختلف کمک کند به امری حیاتی مبدل شده است. «زبان برنامهنویسی پایتون» (Python Programming Language)، یک ستاره درخشان در آسمان فناوری یادگیری ماشین است که اغلب، هم برای پروژههای تحقیقاتی و هم پروژههای عملیاتی، اولین انتخاب بسیاری از افراد محسوب میشود. بنابراین، فراگیری یادگیری ماشین با پایتون، بسیار ساده و البته لذتبخش است. در این مطلب، با یک بررسی موردی، به افرادی که به دنیای یادگیری ماشین علاقمند هستند نشان داده خواهد شد که چگونه میتوانند یک مساله را از صفر تا صد با پایتون حل کنند.
مقدمهای بر یادگیری ماشین با پایتون
دلیل محبوبیت و استفاده زیاد از پایتون برای مسائل یادگیری ماشین در چیست؟ پایتون یکی از سادهترین زبانهای برنامهنویسی برای فراگیری محسوب میشود. در پروژههای یادگیری ماشین، معمولا نیاز به سرعت بخشیدن به فرایند است و با توجه به اینکه کارشناس داده میتواند به سرعت از زبان پایتون برای پروژههای عملی استفاده کند، نیازی به تخصیص زمان زیاد برای یادگیری زبان برنامهنویسی ندارد. برای کسب درک بهتری پیرامون میزان سادگی پایتون، به مثال زیر توجه کنید.
«نحو» (Syntax) زبان برنامهنویسی پایتون، به زبان انگلیسی (و در واقع زبان انسانی، نه زبان ماشین) بسیار نزدیک است؛ از دیگر ویژگیهای این زبان میتوان به عدم نیاز به استفاده از کروشههایی که انسان را هنگام نوشتن برنامه گیج میکنند اشاره کرد. نقطه قوت دیگر پایتون، کتابخانههای متعددی است که برای انجام محاسبات، الگوریتمهای یادگیری ماشین و دیگر فعالیتهای لازم طی یک پروژه، دارد. کتابخانههایی که در ادامه بیان میشوند، از شاهکارهای پایتون هستند که به دانشمندان داده، کارشناسان یادگیری ماشین و دیگر افراد فعال در حوزه علم داده، برای تکمیل وظایف خودشان کمک میکنند. به طور کلی باید گفت که کتابخانههای متعدد و با توانمندیهای قابل توجهی برای پایتون وجود دارند که استفاده از آنها برای پروژههای یادگیری ماشین الزامی است.
۱. نامپای (NumPy)
«نامپای» (Numpy)، یک کتابخانه معروف برای انجام تحلیلهای عددی است. این کتابخانه به کاربر برای انجام کارهای متعدد از محاسبه میانه و توزیع دادهها گرفته تا پردازش آرایههای چندبُعدی کمک میکند.
۲. پانداس (Pandas)
برای پردازش یک فایل CSV، میتوان از کتابخانه «پانداس» (Pandas) استفاده کرد. البته، در این راستا کاربر نیاز به پردازش چندین جدول و مشاهده آمارهای مربوط به آنها دارد.
۳. متپلاتلیب (Matplotlib)
پس از آنکه کاربر دادهها را با بهرهگیری از کتابخانه Pandas به صورت «دیتافریم» (Data Frame) ذخیره کرد، برای درک دادههای موجود به برخی از روشهای بصریسازی نیاز خواهد داشت. تصاویر، معمولا بهتر و گویاتر از خود دادهها هستند (به ویژه برای ذینفعان نهایی که ممکن است دارای تخصصهای گوناگونی باشند و آمارهای عددی و تحلیلهای متنی نمیتوانند گزینههای خوبی برای ارائه خروجی به آنها باشند). «متپلاتلیت» (Matplotlib)، کتابخانهای قدرتمند برای بصریسازی دادهها است که میتوان با بهرهگیری از آن، نمودارهای گوناگون را ترسیم کرد.
۴. سیبورن (Seaborn)
این کتابخانه نیز ابزار دیگری است برای انجام بصریسازیها، با این تفاوت که تمرکز بیشتری روی بصریسازیهای آماری دارد. مواردی مانند «بافتنگار» (هیستوگرام | Histogram)، «نمودار دایرهای» (Pie Chart)، «منحنیها» (Curves) و یا «جداول همبستگی» (Correlation Tables) از جمله مواردی هستند که با بهرهگیری از این کتابخانه میتوان آنها را پیادهسازی کرد.
۵. سایکیتلِرن (Scikit-Learn)
کتابخانه «سایکیتلرن» (Scikit-Learn)، یکی از قدرتمندترین کتابخانههای یادگیری ماشین با پایتون است. این کتابخانه هر آنچه که برای پیادهسازی و بهبود الگوریتمهای یادگیری ماشین مورد نیاز است را فراهم میکند.
۶. تنسورفلو (Tensorflow) و پایتورچ (Pytorch)
تنسورفلو (Tensorflow) و پایتورچ (Pytorch)، کتابخانههای رایگان و متنبازی (Open Source) هستند که کاربردهای گوناگونی را در یادگیری ماشین دارند. از این کتابخانهها برای پیادهسازیهای مربوط به «شبکههای عصبی» (Neural Networks) و به ویژه «یادگیری عمیق» (Deep Learning) و همچنین محاسبات «تانسورها» (Tensors) استفاده میشود.
پروژههای یادگیری ماشین با پایتون
قطعا، مطالعه صرف نمیتواند به فرد کمک کند که در زمینه کاری خود توانمند شود. افراد در هر زمینهای که تمایل به کسب مهارت در آن داشته باشند، باید علاوه بر مطالعه و تحقیق، تمرین و پروژههای عملی داشته باشند و به کسب تجربه در آن حوزه بپردازند. در بحث یادگیری ماشین، مادامی که فرد در میان دادهها شیرجه نزند و با آنها کار نکند، نمیتواند بر این حوزه تسلط کافی پیدا کند و بنابراین، نمیتواند پروژهها یا فرصتهای شغلی خوبی به دست بیاورد.
«کگل» (Kaggle) پلتفرمی است که میتوان با استفاده از آن، مستقیما به سراغ دادهها رفت و با آنها کار کرد. در این سایت میتوان با پروژهها و مسائل گوناگون آشنا شد و به حل آنها پرداخت. چیز دیگری که شاید اغوا کنندهتر به نظر برسد این است که رقابتهایی که در کگل برگزار میشوند جوایز گوناگونی دارند و رقم جایزه برخی از آنها به ۱۰۰,۰۰۰ دلار نیز میرسد. اما، مهمترین مساله در این وهله (و در مرحله یادگیری) پول نیست، زیرا در صورتی که فرد به این حوزه مسلط باشد میتواند پروژههای متعددی با درآمدهای خوب و فرصتهای شغلی با شرایط عالی پیدا کند. آنچه یک فرد تازه وارد در حوزه کار با داده به آن نیاز دارد، یادگیری و کسب تجربه است، البته لذت مسابقه دادن و برنده شدن جایزه را نمیتوان انکار کرد. در ادامه، یک بررسی موردی انجام شده و طی آن یک مساله یادگیری ماشین با پایتون حل شده است.
تشخیص افراد نجات یافته از کشتی تایتانیک
در اینجا صحبت از کشتی تایتانیک معروف و حادثهای است که برای آن رخ داد. در فاجعه تایتانیک که در سال ۱۹۱۲ رخ داد، ۱۵14 نفر از ۲۲۲۴ مسافر و خدمه این کشتی، جان خود را از دست دادند. رقابت کگل تایتانیک (و یا به عبارتی راهنمای آموزشی)، دادههای حقیقی پیرامون این حادثه تلخ را در اختیار عموم قرار میدهد. وظیفه کاربر در این وهله آن است که از این دادهها برای پیشبینی این موضوع استفاده کند که آیا یک شخص خاص در این حادثه جان سالم به در برده است یا خیر.
یادگیری ماشین با پایتون
پیش از عمیق شدن در دادههای تایتانیک، ابتدا باید ابزارهای مورد نیاز برای حل مساله را نصب کرد. در گام اول، نیاز به نصب پایتون است. پایتون را میتوان از وبسایت رسمی آن [+] دانلود و نصب کرد. برای آنکه نسخهای از پایتون که توسط کاربر نصب میشود با نسخه جدید کتابخانههای پایتون سازگار باشد، توصیه میشود پایتون نسخه ۳.۶ به بالا نصب شود. پس از آن، باید کتابخانههای مورد نیاز را با pip نصب کرد. pip باید به طور خودکار، همراه با توزیعی از پایتون که کاربر دانلود کرده است، نصب شود. برای نصب مواردی که کاربر نیاز دارد با استفاده از pip، باید «ترمینال» (Terminal)، «خط فرمان» (Command Line) یا «پاورشل» (Powershell) را باز و دستورات زیر را وارد کرد.
اکنون به نظر میرسد که مقدمات کار به خوبی آماده شدهاند. همانطور که در کد بالا مشهود است، «ژوپیتر» (Jupyter) نیز نصب شده است. ژوپیتر یک نوتبوک محبوب است که میتوان کدهای پایتون را در آن به صورت تعاملی نوشت. برای باز کردن ژوپیتر، تنها کافی است که در ترمینال، jupyter notebook را وارد کرد. پس از آن، یک صفحه مرورگر وب مانند تصویر زیر باز میشود.

کد را میتوان به صورت تعاملی درون مربع سبزرنگ نوشت و ارزیابی کرد. اکنون که همه ابزارها نصب شدهاند، میتوان به ادامه کار پرداخت.
اکتشاف داده
اولین گام برای کاوش، اکتشاف دادهها است. در همین راستا، نیاز به دانلود کردن دادههای مورد استفاده در این مثال، از طریق صفحه مجموعه داده تایتانیک در کگل [+] وجود دارد. سپس، باید دادههای استخراج شده را درون پوشهای قرار داد که نوتبوک ژوپیتر آغاز شده است. در این مرحله، باید کتابخانههای لازم را «وارد» (ایمپورت) کرد.
سپس، باید دادهها را بارگذاری کرد.
خروجی، چیزی شبیه تصویر زیر خواهد بود.

آنچه در تصویر بالا وجود دارد، نمونهای از دادههای مجموعه داده تایتانیک هستند. ستونهای زیر در مجموعه داده وجود دارند.
- PassengerId: شماره شناسایی مسافران
- Survived: وضعیت زنده ماندن یا نماندن فرد
- Pclass: کلاس خدماتی که فرد برای آن بلیط گرفته است. در اینجا، «۱» کلاس اقتصادی، «۲» کلاس تجاری و «۳» درجه یک است.
- Name: نام مسافر
- Gender: جنسیت مسافر
- Age: سن مسافر
- Sibsp یا siblings and spouses: تعداد اعضای خانواده (همسر، خواهران و برادران) مسافر در کشتی
- Parch یا parents and children: تعداد والدین و فرزندان حاضر در کشتی (برای یک شخص حاضر در کشتی) مسافر
- Ticket: جزئیات بلیط مسافر
- Cabin: اطلاعات کابین مسافر، وجود NaN در این قسمت، به معنای ناشناخته است.
- Embarked یا محل مسافرگیری: S برای ساوتهمپتون (Southampton) و Q برای «کویینزتاون» (Queenstown) و C برای «شربورگ» (Cherbourg)
هنگام کاوش دادهها، معمولا «دادههای ناموجود» یا «دادههای گمشده» (Missing Data) پیدا میشوند. برای کشف این دادهها در مجموعه داده تایتانیک، از قطعه کد زیر استفاده شده است.
خروجی، تصویری مانند زیر خواهد بود.
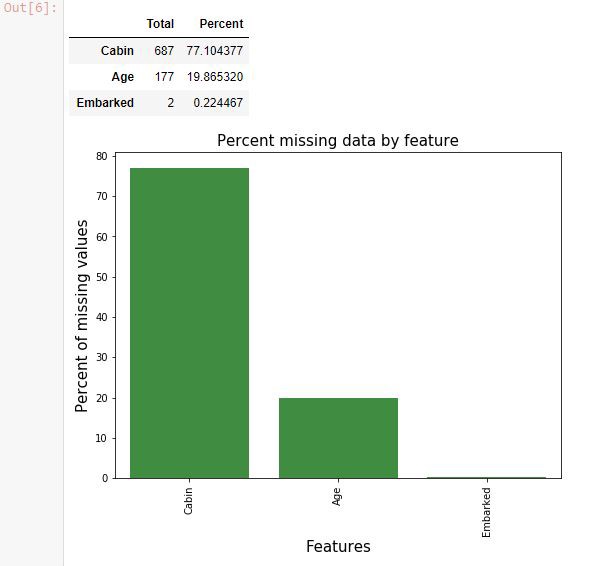
کابین، سن و دادههای محل مسافرگیری (محل سوار شدن مسافرها) دارای مقادیر ناموجود هستند. اطلاعات کابین، دارای مقادیر ناموجود بسیار زیادی است. برای چنین مقادیر ناموجودی (گم شده)، باید فکری کرد. به این فرایند، «پاکسازی دادهها» (Data Cleaning) گفته میشود.
پاکسازی دادهها
پیشپردازش دادهها بخش مهمی از فرایند «دادهکاوی» (Data Cleaning) است. هنگامی که دادهها پاکسازی شد، میتوان بدون نگرانی از هر چیزی، به گام بعدی رفت. یکی از گامهای متداولی که طی فرایند پاکسازی دادهها برداشته میشود، «جایگذاری مقادیر ناموجود» است. هیچ قاعده مشخصی برای انجام این کار وجود ندارد و راهکارهای گوناگونی تاکنون برای آن ارائه شدهاند که هر یک مزایب و معایب خود را دارند. گاه میتوان با آزمودن راهکارهای گوناگون و سنجش کارایی آنها برای یک مساله خاص، بهتری رویکرد را برگزید. به عنوان یک قاعده سرانگشتی، این نکته را نباید فراموش کرد که برای دادههای «طبقهای» (Categorized)، تنها از «مُد» (Mode) و از میانه یا میانگین برای دادههای پیوسته میتوان استفاده کرد. با توجه به اینکه embarkation مقادیر طبقهای دارد، از مد برای پیدا کردن مقادیر ناموجود آن استفاده میشود. همچنین، از میانه برای پر کردن مقادیر ناموجود Age استفاده میشود.
مساله بعدی، حذف دادهها برای مواردی است که مقادیر ناموجود زیادی دارند. برای مثال، در این مجموعه داده، cabin دارای مقادیر ناموجود زیادی است. بنابراین، ستون آن به طور کامل حذف میشود (البته به طور کلی، راهکار حذف نمونهها یا ویژگیهایی که دارای مقادیر از دست رفته هستند توصیه نمیشود. چون بدین شکل ممکن است اطلاعات مهمی از دست بروند. بنابراین، توصیه کلی آن است که از انجام چنین کاری حدالمقدور اجتناب شود).
اکنون، میتوان دادههای پاکسازی شده را بررسی کرد.
مساله مقادیر ناموجود به خوبی حل شده و همانطور که در تصویر بالا نیز میتوان مشاهده کرد هیچ داده ناموجودی پیدا نشده است. این یعنی دادهها پاکسازی شدهاند.
مهندسی ویژگیها
اکنون که دادهها پاکسازی شدند، گام بعدی که باید انجام شود «مهندسی ویژگیها» (Feature Engineering) است. مهندسی ویژگیها، روشی برای پیدا کردن مناسبترین ویژگیها یا دادهها برای حل مساله، از میان دادههای کنونی موجود است. راهکارهای متعددی برای انجام این کار وجود دارند، البته بر فراز همه این روشها، عقل سلیم است. در ادامه، نگاهی به دادههای مسافرگیری انداخته میشود. این بخش با S ،Q یا C پر شدهاند. اغلب کتابخانههای پایتون، تنها قادر به پردازش اعداد و نوع دادههای عددی هستند. بنابراین، برای حل این مشکل و تبدیل کردن دادههای طبقهای به عددی، نیاز به انجام کاری است که به آن روش کدبندی وان هات (One Hot Encoding)گفته میشود. با بهرهگیری از این روش، یک ستون به سه ستون تبدیل میشود. این ستونها Embarked_S ،Embarked_Q و Embarked_C نامیده شدهاند و با مقادیر ۰ و ۱ پر میشوند . مقدار ۱ در یک فیلد بدین معنا است که فرد در آن بندر سوار شده و مقدار صفر یعنی در آن بندر سوار نشده است.
مثالهای دیگر در همین رابطه، SibSp و Parch هستند. شاید هیچ چیز جالبی در این دو ستون وجود نداشته باشد، اما بدین شکل میتوان فهمید خانوادههایی که در کشتی حضور داشتند چقدر بزرگ بودهاند. ممکن است به نظر برسد که اگر خانواده بزرگتر بوده باشد، شانس نجات یافتن اعضای آن نیز بیشتر است. زیرا اعضای خانواده میتوانند به یکدیگر کمک کنند. این در حالی است که افراد تنها، چنین شانسی ندارند. بنابراین، ستون دیگری ساخته میشود با عنوان family size که شامل sibsp + parch + 1 است (خود مسافران).
آخرین مورد، «ستونهای دستهبندی» (bin columns) است. این روش برای ساخت دستههایی از مقادیر، برای گروهبندی چندین چیز در کنار هم است. زیرا به نظر میرسد که متمایز کردن چیزهایی با مقادیر یکسان یا بسیار نزدیک به هم، دشوار باشد. برای مثال، برای کسانی که ۵ و ۶ سال دارند، آیا تفاوت قابل توجهی وجود دارد؟ یا در میان افرادی که ۴۵ و ۴۶ سال دارند، آیا تفاوت خاصی وجود دارد؟ به همین دلیل است که ستونهای دستهها (bin) ساخته میشوند. در اینجا، برای سن چهار دسته ساخت میشود که عبارتند از: بچه (۰ تا ۱۴ سال)، نوجوان (۱۴ تا ۲۰ سال)، بزرگسال (۲۰ تا ۴۰ سال) و کهنسال (بالای ۴۰ سال). کد لازم برای این کار در ادامه آمده است.
اکنون که اقدامات لازم برای همه ویژگیها به پایان رسید، همبستگی ویژگیها به یکدیگر مورد بررسی قرار میگیرد.
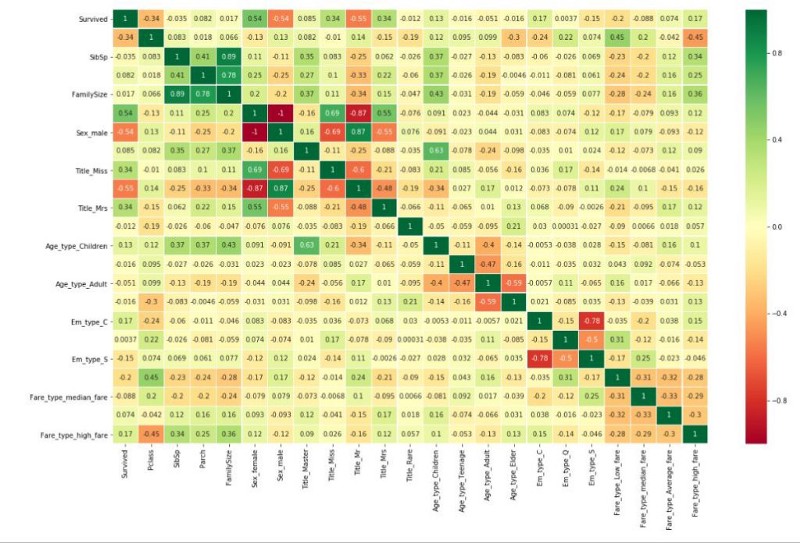
همبستگی با مقدار ۱ بدین معنا است که ویژگیها به شدت با یکدیگر همبسته هستند و با مقدار ۱- بدین معنا است که به شکل منفی با هم همبسته هستند. برای مثال، جنسیت زن و جنسیت مرد به طور منفی با هم همبسته هستند، زیرا مسافران در یکی از این دو دسته قرار میگیرند. به جز ویژگی بیان شده، میتوان مشاهده کرد که هیچ چیزی به شدت مرتبط به دیگری نیست، به جز مواردی که با مهندسی ویژگیها ساخته شده بودند. این یعنی کار مهندسی ویژگیها به درستی انجام شده است. پرسشی که در این وهله مطرح میشود این است که اگر یک ویژگی به شدت مرتبط به دیگری باشد، چه میشود؟ در پاسخ به این پرسش باید گفت که میتوان یکی از آنها را حذف کرد؛ زیرا اطلاعات جدیدی را به سیستم ارائه نمیکند. دلیل این امر، یکی بودن اطلاعات هر دو آنها است.
مدل یادگیری ماشین با پایتون
اکنون، نقطه اوج کار از راه رسیده است. ساخت مدل یادگیری ماشین با پایتون.
برای ساخت مدل یادگیری ماشین با پایتون، میتوان از الگوریتمهای متعدد و متنوعی که در کتابخانه «سایکیتلِرن» وجود دارند، استفاده کرد. برخی از این الگوریتمها در ادامه بیان شدهاند.
- رگرسیون لجستیک (Logistic Regression)
- جنگل تصادفی (Random Forest)
- ماشین بردار پشتیبان (Support Vector Machine | SVM)
- K نزدیکترین همسایگی (K Nearest Neighbor)
- نایو بیز (Naive Bayes)
- درخت تصمیم (Decision Trees)
- آدابوست (AdaBoost)
- تخصیص پنهان دیریکله (Latent Dirichlet Allocation | LDA)
- گرادیان تقویتی (Gradient boosting)
شاید برای افراد تازهوارد گیجکننده باشد که کدام یک از این موارد را باید برگزیند و یا اینکه، در هر یک از این الگوریتمها چه اتفاقی میافتد. در این وهله باید گفت که جای نگرانی نیست، همه این الگوریتمها در کتابخانه سایکیتلرن، مانند یک جعبه سیاه میمانند و الزاما کاربر نیاز به دانستن اتفاقاتی که درون آنها میافتد ندارد و کافی است الگوریتمی با کارایی مناسب برای این مساله را انتخاب کند. در اینجا، از الگوریتم جنگل تصادفی استفاده میشود.
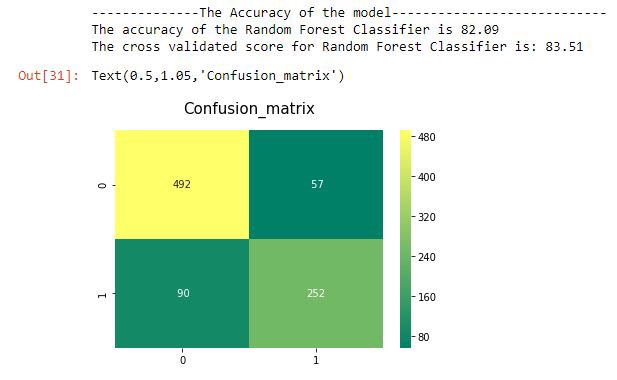
مدل، روی دادهها صحت ٪۸۳ را ارائه میکند. برای اولین بار خوب است. منظور از امتیاز حاصل از «اعتبارسنجی متقابل» (Cross-Validation)، امتیاز اعتبارسنجی متقابل K Fold است. K = 10 به این معنا است که دادهها به ۱۰ بخش تقسیم شدهاند و میانگین همه امتیازهای محاسبه شده برای آنها به عنوان میانگین کل ارائه شده است.
تنظیم دقیق
اکنون، گامهای لازم برای پیادهسازی یک مدل یادگیری ماشین با پایتون، به پایان رسید. اما، یک گام مهمتر وجود دارد که میتواند منجر به بهبود نتایج خروجی شود: تنظیم دقیق. «تنظیم دقیق» (Fine Tuning)، به معنای پیدا کردن بهترین پارامتر برای الگوریتمهای یادگیری ماشین است. در کد مربوط به جنگل تصادفی بالا که در زیر نشان داده شده، میتوان تنظیماتی به منظور بهبود خروجی انجام داد.
پارامترهایی وجود دارد که باید تنظیم شوند. موارد موجود در کد بالا، تنظیمات پیشفرض هستند. کاربر میتواند پارامترها را به هر شکلی که تمایل داشته باشد، تغییر دهد. البته، این کار زمان زیادی میبرد. جای نگرانی وجود ندارد، ابزاری با عنوان Grid Search وجود دارد که پارامترهای بهینه را به صورت خودکار پیدا میکند. جالب به نظر میرسد؟
توصیه میشود افراد پس از مطالعه این مطلب و بررسی کدها، خود کلیه موارد را امتحان کرده و برای دریافت خروجی مناسب تلاش کنند.
منبع: فرادرس
افزودن گرافیک برداری (SVG) به صفحات وب — راهنمای کاربردی
گرافیکهای برداری در شرایط زیادی مفید واقع میشوند. این گرافیکها فایلهایی با اندازه کوچک هستند که به راحتی میتوانند افزایش مقیاس پیدا کنند، به طوری که وقتی روی آنها زوم میکنید به صورت تار یا در اصطلاح «pixelate» (پیکسل پیکسل) در نمیآیند. در این مقاله روش افزودن گرافیک برداری به وب را توضیح میدهیم. پیشنیازهای این مقاله آشنایی با مبانی HTML و روش درج تصاویر در سندهای وب است که در بخشهای قبلی این سری مقالات آموزشی ارائه شدهاند. هدف از این نوشته آشنایی با روش جاسازی یک تصویر (بُرداری) SVG در صفحه وب است.
نکته: در این مقاله با ماهیت SVG آشنا نمیشویم؛ بلکه صرفاً قصد داریم به طور مختصر آن را بشناسیم و روش افزودن آن به صفحات وب را بدانیم. همچنین برای مطالعه قسمت قبلی این مجموعه مقالات آموزشی میتوانید روی لینک زیر کلیک کنید:
گرافیکهای برداری چه هستند؟
در وب ما با دو نوع تصویر سر و کار داریم، تصاویر Raster و تصاویر برداری:
- تصاویر Raster با استفاده از شبکهای از پیکسلها تعریف میشوند. یک تصویر raster شامل اطلاعاتی است که نشان میدهد هر پیکسل دقیقاً باید کجا قرار گیرد و دقیقاً چه رنگی باید داشته باشد. قالبهای متداول raster در وب شامل Bitmap با پسوند bmp، تصاویر PNG با پسوند png، قالب JPEG یا پسوند jpg و قالب GIF با پسوند gif هستند.
- تصاویر بُرداری (Vector) با استفاده از الگوریتمها تعریف میشوند. یک فایل تصویر بُرداری شامل تعاریف شکلها و مسیرهایی است که رایانه میتواند از آن استفاده کرده و تصویر مورد نظر را روی صفحه رندر کند. قالب SVG امکان ایجاد گرافیکهای برداری قوی برای استفاده در وب را در اختیار ما قرار میدهد.
مثال
برای این که ایدهای کلی از تفاوت بین این دو نوع تصویر داشته باشید به دو تصویر زیر توجه کنید:

در این تصویر دو ستاره به ظاهر یکسان را در کنار هم مشاهده میکنید که هر دو رنگ قرمز و سایههای سیاه دارند. تنها تفاوت آنها در این است که یکی از آنها PNG و دیگری SVG است. تفاوت این دو تصویر زمانی مشخص میشود که صفحه را زوم کنیم:

مشکل Pixelate یا «پیکسل پیکسل» شدن
چنان که میبینید تصویر PNG در زمان بزرگنمایی، به صورت Pixelate درمیآید، زیرا شامل اطلاعاتی است که مشخص میسازد هر پیکسل در کجا و به چه رنگی باید باشد. زمانی که این تصویر بزرگنمایی میشود هر پیکسل به سادگی افزایش مییابد تا پیکسلهای بیشتری را روی صفحه اشغال کند و از این رو تصویر ستاره به صورت تار به نظر میرسد. اما تصویر بُرداری سمت راست همچنان تمیز و واضح به نظر میرسد، چون مهم نیست که این تصویر چه اندازهای دارد در هر صوت الگوریتمهایی که برای ساختن آن استفاده شدهاند، با تغییر یافتن مقیاس، آن را در اندازه بزرگتری ترسیم میکنند.
نکته: توجه داشته باشید که همه تصاویر فوق در واقع PNG هستند و ستاره سمت چپ در هر مورد یک تصویر raster و ستاره سمت راست یک تصویربرداری را نمایش میدهد. برای مشاهده مثال واقعی به این صفحه (+) مراجعه کنید و با استفاده از کلیدهای کنترل و به اضافه زوم کنید تا تفاوت دو نوع تصویر را عملاً مشاهده کنید.
به علاوه فایلهای تصاویر بُرداری بسیار سبکتر از نسخههای معادل raster-شان هستند، چون صرفاً چند الگوریتم در آنها ذخیره شده است در حالی که در تصاویر raster اطلاعات تمام پیکسلها یک به یک ذخیره شده است.
SVG چیست؟
SVG یک زبان مبتنی بر XML برای توصیف تصاویر برداری است. در واقع اساس آن یک زبان نشانهگذاری مانند HTML است به جز این که عناصر بسیار مختلفی برای تعریف کردن شکلهایی که میخواهید در تصویر ظاهر شوند و جلوههایی که میخواهید روی شکلها اعمال کنید، در اختیار شما قرار دارد. SVG به منظور نشانهگذاری گرافیکها ابداع شده است و نه برای نشانهگذاری محتوا. SVG در سادهترین شکل خود عناصری مانند <circle> و <rect> برای ایجاد شکل در اختیار شما قرار میدهد. قابلیتهای پیشرفتهتر SVG شامل <feColorMatrix> برای تبدیل رنگها با استفاده از ماتریس تبدیل، <animate> برای متحرکسازی بخشهایی از یک گرافیک برداری و <mask> برای اعمال یک ماسک روی بخشی از تصویر است.
به عنوان یک مثال ساده کد زیر یک دایره و یک مستطیل ایجاد میکند:
خروجی کد فوق به صورت زیر است:
کدنویسی SVG
در مثال فوق، ممکن است این تصور در شما ایجاد شود که کدنویسی SVG به صورت دستی کار آسانی است. البته نوشتن کد یک فایل SVG ساده در یک ویرایشگر متنی کار چندان دشواری محسوب نمیشود؛ اما در مورد تصاویر پیچیدهتر این کار به سرعت دشوار میشود. اغلب افراد برای ایجاد تصاویر SVG از یک ویرایشگر گرافیک برداری مانند Inkscape یا Illustrator استفاده میکنند. این بستههای نرمافزاری امکان ایجاد طیف متنوعی از تصویرسازیها با استفاده از ابزارهای گرافیک برداری و ساخت تخمینی از عکسها (برای نمونه قابلیت Trace Bitmap در Inkscape’s) در اختیار ما قرار میدهند.
SVG علاوه بر مواردی که اشاره شد، مزیتهای دیگری نیز به شرح زیر دارد:
- متن موجود در تصاویر برداری در دسترس ما قرار دارد که از نظر سئو بسیار مناسب است.
- SVG-ها در سبکبندی و اسکریپتنویسی نیز نقش زیادی دارند؛ زیرا هر مؤلفه تصویر یک عنصر است که میتوان از طریق CSS سبکبندی شود و یا به صورت جداگانه به وسیله جاوا اسکریپت برای آن کدنویسی کرد.
اینک سؤال این است که با وجود این همه مزیتها چرا باید کسی همچنان گرافیکهای raster را به گرافیکهای برداری مانند SVG ترجیح بدهد؟ پاسخ این است که SVG برخی معایب نیز دارد:
- SVG به سرعت پیچیده میشود، یعنی اندازه فایل بیش از حد افزایش مییابد؛ از سوی دیگر پردازش SVG-های پیچیده در مرورگر به زمان زیادی نیاز دارد.
- ایجاد SVG بسته به نوع تصویری که میخواهید ایجاد کنید، ممکن است دشوارتر از تصاویر raster باشد.
- SVG در مرورگرهای قدیمی پشتیبانی نمیشود، از این رو اگر میخواهید از نسخههای قدیمیتر اینترنت اکسپلورر نیز پشتیبانی کنید، ممکن است برای شما مناسب نباشد. اولین نسخهای از اینترنت اکسپلورر که از SVG پشتیبانی کرده است نسخه IE9 است.
گرافیکهای Raster معمولاً برای تصاویر با دقت پیچیده مانند عکس به دلایلی در که در بخش فوق توضیح دادیم مناسبتر هستند.
نکته: در نرمافزار Inkscape فایلهای خود را به صورت plain SVG ذخیره کنید تا در فضا صرفهجویی شود.
افزودن SVG به صفحات وب
در این بخش با روشهای مختلفی که میتوان گرافیکهای برداری SVG را به صفحههای وب اضافه کرد آشنا میشویم.
روش سریع: عنصر <img>
برای جای دادن یک SVG از طریق عنصر <img> کافی است در خصوصیت src آن به فایل مربوطه ارجاع بدهید. شما به خصوصیتهای height و یا width هم نیاز دارید. البته در صورتی که نسبت ابعادی ذاتی وجود نداشته باشد، باید هر دو را تعیین کنید. اگر قبلاً چنین کاری انجام ندادهاید پیشنهاد میکنیم به مطلب آموزشی زیر مراجعه کنید:
مزایا
- این روش سریع و دارای ساختار آشنایی است که مشابه گزینه معادل متنی توکار در خصوصیت alt است. میتوان به سادگی با تعریف تودرتوی <img> درون یک عنصر <a> آن را به هایپرلینک تبدیل کرد.
معایب
- امکان دستکاری تصویر با استفاده از جاوا اسکریپت وجود ندارد.
- اگر بخواهید روی محتوای SVG از طریق CSS کنترل داشته باشید، باید از سبکهای CSS «درونخطی» (inline) در کد خود استفاده کنید، چون استایلشیت های خارجی که روی فایل SVG فراخوانی میشوند، تأثیری ندارند.
- نمیتوانید تصاویر SVG را با استفاده از شبه کلاسهای CSS مانند focus: تغییر دهید.
عیبیابی و پشتیبانی روی چند مرورگر
در مورد مرورگرهایی که از SVG پشتیبانی نمیکنند (مانند IE8 و پایینتر، اندروید 2.3 و پایینتر) میتوانید در خصوصیت src به یک PNG یا JPG ارجاع بدهید و از خصوصیت srcset که صرفاً مرورگرهای جدیدتر شناسایی میکنند، برای اشاره به SVG استفاده کنید. در چنین حالتی، تنها مرورگرهایی که از SVG پشتیانی میکنند، این فایلها را بارگذاری میکنند و مرورگرهای قدیمی از نسخه PNG استفاده خواهند کرد:
همچنین میتوانید از SVG-ها به عنوان تصاویر پسزمینه CSS استفاده کنید که شیوه آن در ادامه نمایش یافته است. در کد زیر مرورگرهای قدیمی تنها از PNG (که آن را درک میکنند) استفاده میکنند در حالی که مرورگرهای جدیدتر SVG را نیز بارگذاری خواهند کرد:
درج SVG-ها با استفاده از تصاویر پسزمینه CSS همانند روش <img> توصیف شده در بخش فوق بدین معنی است که SVG نمیتواند از سوی جاوا اسکریپت دستکاری شود و همچنین با برخی محدودیتهای CSS مواجه خواهد بود.
اگر SVG-های شما به طور کلی نمایش پیدا نمیکنند، این مشکل ممکن است از تنظیمات سرور باشد. در این صورت باید تنظیمات سرور را مورد بازنگری قرار دهید.
گنجاندن کد SVG درون HTML
شما میتوانید فایل SVG را در یک ویرایشگر متنی نیز باز کنید، کد SVG را کپی کنید و آن را در سند HTML خود قرار دهید. این کار در برخی موارد به نام SVG inline یا SVG درونخطی نامیده میشود. در این مرحله باید مطمئن شوید که قطعه کد SVG به ترتیب با تگهای <svg> و </svg> باز و بسته میشود. در ادامه مثال کاملاً سادهای از آن چه میتوانید در سند خود جای دهید را مشاهده میکنید:
مزایا
- قرار دادن SVG به صورت inline موجب صرفهجویی در تعداد درخواستهای HTTP میشود و از این رو زمان بارگذاری صفحه را کاهش میدهد.
- شما میتوانید برخی کلاسها و id-ها را به SVG انتساب دهید و آنها را با استفاده از CSS استایل بدهید. این کار چه از طریق درج درون SVG و یا قواعد سبکبندی CSS برای سند HTML ممکن است. در واقع شما میتوانید از خصوصیت ارائه SVG به صورت یک مشخصه CSS استفاده کنید.
- درج درونخطی SVG تنها رویکردی است که در آن امکان استفاده از تعاملهای CSS (مانند focus) و انیمیشنهای CSS روی تصویر SVG وجود دارد.
- میتوان با قرار دادن نشانهگذاری SVG درون یک عنصر <a> آن را به یک هایپرلینک تبدیل کرد.
معایب
این روش تنها در صورتی مناسب است که از SVG صرفاً در یک مکان استفاده کنید. با این وجود، ایجاد نسخههای تکراری (duplication) برای نگهداری پروژههایی که منابع سنگینی دارند ضروری است.
در این روش مرورگر نمیتواند SVG درونخطی را به همان صورتی که فایلهای تصویر معمولی را کَش میکند، ذخیره کند.
شما میتوانید یک fallback در عنصر <foreignObject> تعیین کنید؛ اما مرورگرهایی که از SVG پشتیبانی میکنند، همچنان تصاویر fallback را نیز دانلود خواهند کرد. در این موارد باید بررسی کنید که آیا این سربار اضافی برای پشتیبانی از مرورگرهای منسوخ واقعاً ارزش دارد یا نه.
شیوه جاسازی یک SVG با استفاده از <iframe>
شما میتوانید تصاویر SVG را در مرورگر خود همانند هر صفحه وب دیگری باز کنید. بنابراین جاسازی یک سند SVG با استفاده از عنصر <iframe> دقیقاً به همان روشی که در مطلب زیر توضیح داده شده است، امکانپذیر است:
کد آن به صورت زیر است:
البته بدیهی است که این بهترین گزینه محسوب نمیشود و معایبی دارد.
معایب
iframe-ها همان طور که در کد فوق میبینید دارای ساز و کار fallback هستند؛ اما مرورگرها تنها در صورتی این fallback را نمایش میدهند که به طور کلی از iframe-ها پشتیبانی نکنند.
به علاوه به جز در مواردی که SVG و صفحه وب جاری ریشه یکسانی داشته باشند؛ در موارد دیگر نمیتوانید از جاوا اسکریپت روی صفحه وب اصلی برای دستکاری SVG استفاده کنید.
یادگیری عملی: کار کردن با SVG
در این بخش از یادگیری عملی قصد داریم کمی با SVG-ها کار کنیم تا با آنها بهتر آشنا شویم. در بخش Input زیر میبینید که قبلاً بخشی از نمونهها ارائه شدهاند تا بتوانید سریعتر دست به کار شوید. همچنین میتوانید از صفحه مرجع عنصر SVG (+) در وبسایت موزیلا برای یافتن جزییات بیشتر در مورد SVG ها استفاده کنید و آنها را نیز امتحان کنید. اگر در هر مرحله با کدی مواجه شدید که کار نمیکند، همواره میتوانید با استفاده از دکمه Reset کل کد را ریست کنید.
جمعبندی
در این مقاله یک مرور سریع در مورد گرافیکهای برداری و SVG داشتیم و از دلایل مفید بودن آنها و شیوه درجشان در صفحههای وب صحبت کردیم. البته این مقاله هرگز یک راهنمای جامع در مورد SVG محسوب نمیشود و صرفاً برای آشنایی مقدماتی با SVG مناسب است. بنابراین اگر حس میکنید به قدر کافی در زمینه SVG-ها تجربه کسب نکردهاید، نباید نگران باشید. در بخش بعدی این سری مقالات راهنمای کاربردی به بررسی دقیقتر تصاویر واکنشپذیر پرداخته و ابزارهایی که HTML برای ایجاد شرایط کارکرد بهتر تصاویر روی دستگاههای مختلف ارائه کرده است را معرفی م
منبع: فرادرس
تولید ترکیب ها در جاوا — از صفر تا صد
در این راهنما به بررسی راهحلهای مسئله k-ترکیب در جاوا میپردازیم. ابتدا الگوریتمهای بازگشتی و تکراری را بررسی کرده و پیادهسازی میکنیم تا همه ترکیبهای با اندازه مفروض را بسازیم. سپس راهحلها را با استفاده از کتابخانههای رایج مورد بررسی قرار میدهیم. بدین ترتیب قادر خواهیم بود مسائل مربوط به تولید ترکیب را در جاوا حل کنیم.
مروری بر ترکیبها
یک ترکیب به بیان ساده به زیرمجموعهای از عناصر موجود در یک مجموعه مفروض گفته میشود. در ترکیب برخلاف جایگشت، ترتیب عناصری که در زیر مجموعه انتخاب میشوند اهمیتی ندارند. تنها نکته مهم برای ما این است که آیا عنصر معینی در زیرمجموعه انتخابی وجود دارد یا نه.
برای نمونه در یک بازی کارتی ما باید 5 کارت را از میان دستهای از 52 کارت انتخاب کنیم. هیچ علاقهای به ترتیب انتخاب این 5 کارت نداریم؛ بلکه تنها میخواهیم بدانیم کدام کارتها را در دست خود داریم.
برخی مسائل نیازمند ارزیابی همه ترکیبهای ممکن هستند. به این منظور باید ترکیبهای مختلف را بشماریم. تعداد روشهای متمایز انتخاب r عنصر از میان عناصر مجموعه n عضوی را از نظر ریاضیاتی میتوان با فرمول زیر نمایش داد:
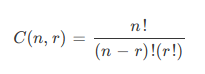
از این رو تعداد روشهای انتخاب عناصر در سناریوی بدترین حالت به صورت نمایی رشد میکند. بدین ترتیب در مورد جمعیتهای بزرگ، امکان احصای راهحلهای مختلف وجود ندارد.
در چنین مواردی ما میتوانیم به صورت تصادفی چند گزیده گویا از جامعه را انتخاب کنیم. در ادامه الگوریتمهای مختلف برای فهرست کردن ترکیبها را بررسی میکنیم.
الگوریتمهای بازگشتی برای تولید ترکیبها
الگوریتمهای بازگشتی عموماً از طریق افراز یک مسئله به مسائل کوچکتر مشابه عمل میکنند. این فرایند تا زمانی ادامه مییابد که به شرط پایانی برسیم که همان حالت مبنا است. سپس مستقیماً حالت مبنا را حل میکنیم.
در ادامه دو روش برای تقسیم وظیفه انتخاب عناصر از یک مجموعه به اجزای کوچکتر را مورد بررسی قرار میدهیم. رویکرد نخست، تقسیم کردن مسئله برحسب عناصر موجود در مجموعه است. رویکرد دوم مسئله را به وسیله ردگیری صرف عناصر منتخب تقسیم میکند.
افراز کردن از طریق عناصر موجود در کل مجموعه
در این بخش وظیفه انتخاب کردن r عنصر از n آیتم را به وسیله بازبینی یک به یک آیتمها انجام میدهیم. در مورد هر آیتم در مجموعه میتوانیم یا آن را در گزینش خود بگنجانیم یا آن را کنار بگذاریم.
ما آیتم اول را در گزینش خود قرار میدهیم، سپس باید r-1 عنصر را از میان n-1 آیتم باقیمانده انتخاب کنیم. از سوی دیگر اگر آیتم نخست را کنار بگذاریم، در این صورت باید r عنصر را از میان n-1 آیتم باقیمانده انتخاب کنیم.
این وضعیت از نظر ریاضیاتی به صورت زیر توصیف میشود:
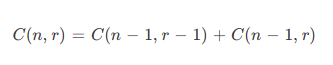
اینک به بررسی پیادهسازی بازگشتی این رویکرد میپردازیم:
متد کمکی دو فراخوانی بازگشتی به خود ارائه میکند. فراخوانی نخست شامل عنصر کنونی است. فراخوانی دوم عنصر کنونی را کنار میگذارد.
سپس تولیدکننده ترکیب را با استفاده از متد کمکی مینویسیم:
در کد فوق متد generate فراخوانی نخست به متد کمکی را تنظیم کرده و پارامترهای مناسب را ارسال میکند.
سپس این متد را برای تولید ترکیبها فراخوانی میکنیم:
در زمان اجرای برنامه، خروجی زیر را به دست میآوریم:
در نهایت حالت تست را مینویسیم:
به سادگی مشاهده میشود که اندازه پشته مورد نیاز برابر با تعداد عناصر مجموعه است. زمانی که تعداد عناصر موجود در مجموعه بزرگ و برای نمونه بالاتر از بیشینه عمق پشته فراخوانی باشد، با سرریز پشته مواجه میشویم و خطای StackOverflowError را دریافت میکنیم. از این رو این رویکرد در صورت بزرگ بودن ورودی عملی نخواهد بود.
افراز کردن به وسیله عناصر موجود در ترکیب
در این روش به جای ردگیری عناصر در مجموعه ورودی، وظیفه مورد نظر را با ردگیری آیتمها در زیرمجموعه انتخابی اجرا میکنیم. ابتدا، آیتمهای موجود در مجموعه ورودی را با استفاده از اندیسهای 1 تا n مرتب میکنیم. سپس میتوانیم آیتم نخست را از میان n-r+1 آیتم موجود انتخاب کنیم.
فرض کنید که آیتم K-اُم را انتخاب کردهایم. سپس باید r-1 آیتم را از میان n-k آیتم که از k+1 تا n اندیسگذاری شدهاند انتخاب کنیم. این فرایند از نظر ریاضیاتی به صورت زیر توصیف میشود:
![]()
سپس متد بازگشتی را برای پیادهسازی این رویکرد مینویسیم:
در کد فوق، حلقه for آیتم بعدی را انتخاب میکند. سپس متد کمکی ()helper را به صورت بازگشتی برای انتخاب از میان آیتمهای باقیمانده فراخوانی میکند. زمانی که تعداد مورد نیاز آیتمها انتخاب شدند حلقه را متوقف میکنیم.
سپس از متد helper برای تولید زیرمجموعهها استفاده میکنیم:
در نهایت حالت تست را مینویسیم:
اندازه پشته فراخوانی مورد استفاده این رویکرد برابر با تعداد عناصر موجود در زیرمجموعه انتخابی است. از این رو این رویکرد میتواند برای ورودیهای بزرگ نیز استفاده شود. تنها شرط این است که تعداد عناصر انتخابی کمتر از بیشینه عمق پشته فراخوانی باشد. توجه داشته باشید که اگر تعداد عناصری که باید انتخاب شوند نیز بزرگ باشد، این متد کار نخواهد کرد.
الگوریتم تکراری
در رویکرد «تکراری» (Iterative) ما کار خود را با یک ترکیب اولیه آغاز میکنیم. سپس به تولید ترکیبهای بعدی از ترکیب کنونی ادامه میدهیم، تا این که همه ترکیبها را تولید کنیم.
اگر ترکیبها را با ترتیب «لغتنامهای» (lexicographic) تولید کنیم، باید کار خود را از کوچکترین ترکیب لغتنامهای آغاز کنیم. برای به دست آوردن ترکیب بعدی از ترکیب کنونی، باید موقعیت عنصری که در انتهای سمت راست ترکیب کنونی قرار دارد و میتواند افزایش یابد را بیابیم. سپس موقعیت را افزایش میدهیم تا کوچکترین ترکیب لغتنامهای ممکن سمت راست آن موقعیت را تولید کنیم. کد این رویکرد را به صورت زیر مینویسیم:
در ادامه حالت تست را مینویسیم:
در بخش بعدی از کتابخانههای جاوا برای حل این مسئله کمک میگیریم.
کتابخانههای جاوا برای پیادهسازی مسئله ترکیبها
باید تا آنجا که ممکن است از پیادهسازیهای کتابخانههای موجود به جای نوشتن کد خود استفاده کنیم. ما کتابخانههای زیر را یافتهایم که به پیادهسازی ترکیبها کمک میکنند:
- Apache Commons
- Guava
- CombinatoricsLib
کتابخانه Apache Commons
کلاس CombinatoricsUtils در کتابخانه Apache Commons تابعهای کاربردی زیادی در ارتباط با ترکیبها ارائه میکند. به طور خاص متد combinationsIterator یک تکرار کننده را بازگشت میدهد که ترکیبها را با ترتیب لغتنامهای بازگشت میدهد.
ابتدا وابستگی Maven با نام commons-math3 را به پروژه اضافه میکنیم:
سپس از متد combinationsIterator برای نمایش ترکیبها استفاده میکنیم:
کتابخانه Google Guava
کلاس Sets در کتابخانه Google Guava متدهای کاربردی برای عملیات مرتبط با مجموعه ارائه میکند. متد combinations همه زیرمجموعههای با اندازه مفروض را بازگشت میدهد.
ابتدا وابستگی Maven با نام Guava library را به پروژه اضافه میکنیم:
سپس از متد combinations برای تولید ترکیبها استفاده میکنیم:
در این کد ما از متد ImmutableSet.of برای ایجاد یک مجموعه از اعداد مفروض استفاده کردهایم.
کتابخانه CombinatoricsLib
CombinatoricsLib یک کتابخانه ساده جاوا برای محاسبه جایگشتها، ترکیبها، زیرمجموعهها، افرازهای صحیح و ضرب دکارتی است. برای استفاده از آن در پروژه باید وابستگی Maven با نام combinatoricslib3 را به پروژه اضافه کنیم:
سپس از این کتابخانه برای نمایش ترکیبها استفاده میکنیم:
اجرای این دستور خروجی زیر را تولید میکند:
برای مشاهده مثالهای بیشتر میتوانید به این آدرس (+) مراجعه کنید.
سخن پایانی
در این مقاله اقدام به پیادهسازی چند الگوریتم برای تولید ترکیبها کردیم. همچنین چند پیادهسازی کتابخانه را مورد بررسی قرار دادیم. به طور معمول بهتر است از این کتابخانهها به جای نوشتن کدهای شخصی استفاده کنیم.
منبع: فرادرس
آموزش Node.js: مفاهیم مقدماتی — بخش اول
در این سری مقالات آموزش جامع Node.js با مفاهیم مقدماتی آشنا میشویم. Node.js یک محیط runtime سمت سرور جاوا اسکریپت است و روی سرور اجرا میشود. این محیط زمان اجرا، اوپنسورس و چند پلتفرمی است و از زمان معرفی در سال 2009 محبوبیت زیادی کسب و نقش مهمی در توسعه وب ایفا کرده است. اگر تعداد ستارههای گیتهاب را معیار محبوبیت بدانیم، Node.js با کسب بیش از 58 هزار ستاره، محبوبیت بالایی دارد.
آموزش جامع Node.js – مفاهیم مقدماتی
Node.js به اجرای موتور V8 جاوا اسکریپت میپردازد که هسته اصلی کروم را تشکیل میدهد و البته خارج از مرورگر قرار دارد. Node.js از توان مهندسانی که runtime جاوا اسکریپت کروم را چنین سریع ساختهاند بهره گرفته است (و میگیرد). این وضعیت به Node.js امکان داده است که بهبود عملکردی زیادی داشته باشد و از کامپایل درجا (Just-in-time) موتور V8 بهره بگیرد. به لطف این موقعیت، کدهای جاوا اسکریپت که روی Nose.js اجرا میشوند، عملکرد بسیار بالایی دارند.
اپلیکیشن Node.js به وسیله یک پردازش منفرد اجرا میشود و برای هر درخواست جدید، نخ مجزایی ایجاد نمیشود. Node مجموعهای از تابعهای ورودی/خروجی ناهمگام در کتابخانه استاندارد خود عرضه کرده است که موجب میشود کد جاوا اسکریپت حالت مسدودکننده نداشته باشد. به طور کلی کتابخانههای Node.js با استفاده از پارادایمهای غیر مسدودکننده نوشته میشوند و رفتار مسدودکننده بیشتر یک حالت استثنا دارد تا این که رویهای معمول محسوب میشود.
هنگامی که Node.js نیاز به اجرای یک عملیات I/O مسدودکننده مانند خواندن مقداری از شبکه، دسترسی به پایگاه داده یا فایلسیستم داشته باشد، به جای مسدود کردن نخ، عملیات را هنگامی که پاسخ بازگشت یابد از سر میگیرد و بدین ترتیب زمان چرخههای CPU را به هدر نمیدهد.
بنابراین Node.js میتواند هزاران اتصال همزمان را روی تنها یک سرور و بدون نیاز به زحمت مدیریت همزمانی نخها اداره کند، چرا که همزمانی نخها میتواند موجب بروز باگهای زیادی شود.
مزیت منحصر به فرد Node.js
Node.js یک مزیت منحصربهفرد دارد و آن این است که میلیونها توسعهدهنده فرانتاند که کدهای جاوا اسکریپت را برای مرورگر مینویسند میتوانند از آن برای اجرای کد سمت سرور و کد سمت فرانتاند بدون نیاز به یادگیری یک زبان کاملاً متفاوت استفاده کنند.
در Node.js میتوان از استانداردهای جدید ECMAScript بدون مشکل استفاده کرد، چون لازم نیست منتظر بمانید که کاربران مرورگرهایشان را بهروزرسانی کنند. شما میتوانید با تغییر دادن نسخه Node.js، به سادگی از نسخههای مختلف ECMAScript استفاده کنید و همچنین با اجرای Node به همراه فلگها میتوانید قابلیتهای آزمایشی مختلفی را فعال کنید.
Node.js کتابخانههای زیادی دارد
ابزار مدیریت پکیج node به نام (npm) با ساختار ساده خود به شکوفایی اکوسیستم Node.js کمک زیادی کرده است. در حال حاضر رجیستری npm تقریباً 500،000 پکیج اوپنسورس را میزبانی میکند که میتوان به صورت رایگان از آنها استفاده کرد.
یک اپلیکیشن ساده Node.js
در ادامه کد برنامه کاملاً رایج Hello World را در Node.js مشاهده میکنید:
برای اجرای این قطعه کد باید آن را به صورت فایلی با نام server.js ذخیره کنید و دستور node server.js را در ترمینال وارد نمایید.
- در ابتدای این کد ماژول http مربوط به Node.js گنجانده شده است.
- Node.js یک کتابخانه استاندارد جالب دارد که شامل پشتیبانی گستردهای از شبکهبندی است.
- متد ()createServer در ماژول http یک سرور HTTP جدید ایجاد کرده و آن را بازگشت میدهد.
- سرور تنظیم شده است که به پورت و hostname خاصی گوش دهد. هنگامی که سرور آماده شود، تابع callback فراخوانی میشود و بدین ترتیب به ما اعلام میکند که سرور در حال اجرا است.
- هر زمان که یک درخواست جدید دریافت شود، رویداد request فراخوانی میشود و دو شیء ارائه میشود که یکی درخواست (شیء http.IncomingMessage) و دیگری پاسخ (شیء http.ServerResponse) است.
- این دو شیء برای مدیریت یک فراخوانی HTTP ضروری هستند.
- شیء نخست جزییات درخواست را شامل میشود. در این مثال ساده از این شیء استفاده نشده است؛ اما میتوانید به هدرهای درخواست و دادههای آن دسترسی داشته باشید.
- شیء دوم برای بازگرداندن دادهها به فراخواننده استفاده میشود. در این مورد:
- ما مقدار مشخصه statusCode را برابر با 200 تعیین میکنیم تا نشان دهیم که پاسخ موفقی بوده است. هدر Content-Type را به صورت زیر تنظیم میکنیم:
- و پاسخ را بسته و محتوا را به صورت یک آرگومان به ()end اضافه میکنیم:

فریمورک و ابزارهای Node.js
Node.js یک پلتفرم سطح پایین است. برای این که امور مختلف برای توسعهدهندهها ساده و جالبتر شوند، هزاران کتابخانه بر اساس Node.js ساخته شده است. بسیاری از این کتابخانهها در طی زمان به گزینههای محبوبی تبدیل شدهاند. در ادامه فهرست مختصری از برخی موارد را که مرتبطتر هستند و ارزش یادگیری دارند ارائه کردهایم:
Express: یکی از سادهترین و با این حال قدرتمندترین روشهای ایجاد وبسرور است. رویکرد مینیمالیستی آن و تمرکز صرف روی قابلیتهای اساسی یک سرور، کلید موفقیتش بوده است.
Meteor: یک فریمورک فولاستک قدرتمند است که یک رویکرد ایزومورفیک برای ساخت اپلیکیشنها با جاوا اسکریپت فراهم میکند و میتوان این کد را در هر دو سمت سرور و کلاینت استفاده کرد. این فریمورک زمانی به عنوان یک ابزار سرهمبندیشده شناخته میشد که همه چیز را عرضه میکرد؛ اما امروز با کتابخانههای فرانتاند مانند React، Vue و Angular ادغام شده است. Meteor میتواند برای ایجاد اپلیکیشنهای موبایل نیز استفاده شود.
Koa: این ابزار از سوی همان تیم سازنده Express ارائه شده است و هدف آن سادهتر و کوچکتر ساختن کارها بر مبنای تجربیات سالیان بوده است. این پروژه جدید بر اساس نیاز به ایجاد تغییراتی که سازگار نیستند و با هدف از دست ندادن جامعه کنونی متولد شده است.
Next.js: یک فریمورک برای اجرای اپلیکیشنهای رندر شده React در سمت سرور است.
Micro: یک سرور بسیار سبک برای ایجاد میکروسرویس های ناهمگام HTTP است.
Socket.io: یک موتور ارتباطی همزمان برای ساخت اپلیکیشنهای شبکه است.
تاریخچه مختصر Node.js
در این بخش به بررسی تاریخچه Node.js از زمان ارائه در سال 2009 تا به اکنون میپردازیم. باور کنید یا نه Node.js امروز 10 ساله است. اگر بخواهیم مقایسه کنیم، جاوا اسکریپت هم اینک 24 ساله است و وب آن چنان که میشناسیم (پس از معرفی مرورگر Mosaic) سنی برابر با 25 سال دارد.
9 سال برای عمر یک فناوری عدد بسیار کوچکی محسوب میشود؛ اما به نظر میرسد که Node.js مدتهای زیادی است که با ما همراه بوده است. در این بخش تلاش میکنیم تصویری بزرگ از Node.js و تاریخچه آن ارائه کنیم و چشمانداز موضوع را روشن سازیم.
اندکی از تاریخچه
جاوا اسکریپت یک زبان برنامهنویسی است که به عنوان ابزار اسکریپتنویسی در Netscape برای دستکاری صفحههای وب درون مرورگر آنها به نام Netscape Navigator ابداع شد.
بخشی از مدل درآمدی Netscape فروش وبسرور بود که محیطی به نام Netscape LiveWire داشت و در آن امکان ایجاد صفحههای دینامیک با استفاده از جاوا اسکریپت سمت سرور وجود داشت. بنابراین ایده جاوا اسکریپت سمت سرور از سوی Node.js معرفی نشده است و قدمتی دستکم به اندازه خود جاوا اسکریپت دارد؛ هر چند در آن زمان موفق نبود.
یکی از عوامل کلیدی که منجر به موفقیت Node.js شد، بحث زمانبندی بود. در زمان عرضه Node.js چند سالی بود که جاوا اسکریپت به لطف اپلیکیشنهای web 2.0 به عنوان یک زبان جدی مطرح شده بود و به دنیا نشان داده بود که تجربه وب مدرن (مانند سرویس نقشه گوگل یا Gmail) به چه شکل میتواند باشد.
عملکرد موتورهای جاوا اسکریپت به لطف نبرد کامپایل مرورگرها که همچنان با شدت در جریان است، به میزان زیادی بهبود یافت. تیمهای توسعهای که دستاندرکار توسعه مرورگرهای اصلی بودند هر روز به شدت تلاش میکردند تا عملکرد بهتری ارائه کنند و بدین ترتیب جاوا اسکریپت به عنوان یک پلتفرم کاملاً تثبیت شد. V8 ، موتوری است که جاوا اسکریپت در پشتصحنه از آن استفاده میکند و یکی از دهها موتور پردازش جاوا اسکریپت است که در مرورگر کروم نیز مورد استفاده قرار میگیرد.
اما البته به این نکته نیز باید اشاره کنیم که Node.js صرفاً به دلیل خوششانسی یا زمانبندی خاص خود موفق نشده است. Node.js یکی از خلاقانهترین روشها برای برنامهنویسی جاوا اسکریپت در سمت سرور را نیز ارائه کرده است.
چگونه Node.js را نصب کنیم؟
در این بخش مراحل مورد نیاز برای نصب Node.js از طریق ابزار مدیریت پکیج، دانلود از وبسایت رسمی یا nvm را معرفی میکنیم.
Node.js میتواند به چند روش نصب شود. در این مبحث رایجترین و راحتترین روشها را معرفی میکنیم. پکیجهای رسمی برای هر چهار پلتفرم عمده از این صفحه (+) قابل دانلود هستند. یک روش بسیار آسان برای نصب Node.js از طریق ابزار مدیریت بسته است. در این حالت هر سیستم عاملی میتواند نسخه خاص خود را داشته باشد.
روی macOS میتوان از Homebrew که یک استاندارد غیررسمی است استفاده کرد و هنگامی که نصب شد امکان نصب Node.js را به روشی کاملاً آسان با اجرای دستور زیر در CLI ارائه میکند:
brew install node
ابزارهای دیگر مدیریت بسته برای لینوکس و ویندوز در این صفحه (+) فهرستبندی شدهاند. nvm یک روش راحت برای اجرای Node.js محسوب میشود که امکان سوئیچ آسان بین نسخههای Node.js و نصب نسخههای جدید برای امتحان کردن و حذف نسخهها در صورت ناموفق بودن را میدهد.
nvm برای تست کد با استفاده از نسخههای قدیمیتر Node.js نیز کاملاً مناسب است. پیشنهاد میکنیم اگر به تازگی کار خود را آغاز کردهاید و قبلاً از Homebrew بهره نگرفتهاید، از نصاب رسمی استفاده کنید. البته در غیر این صورت Homebrew نیز گزینه مناسبی محسوب میشود.
برای استفاده از Node.js چقدر باید جاوا اسکریپت بدانیم؟
اگر به تازگی با جاوا اسکریپت آشنا شدهاید، فکر میکنید تا چه سطحی باید با این زبان آشنا شوید؟ به عنوان یک مبتدی، رسیدن به نقطهای که فرد از مهارتهای برنامهنویسی خود مطمئن باشد، کار دشواری محسوب میشود. همچنین در زمان یادگیری این زبان ممکن است کنجکاو باشید که جاوا اسکریپت کجا خاتمه مییابد و Node از کجا آغاز میشود.
پیشنهاد میکنیم پیش از ورود به Node.js درک نسبتاً خوبی از مفاهیم اصلی جاوا اسکریپت کسب کنید که شامل سرفصلهای زیر میشود:
- ساختار واژگانی
- عبارتها
- نوعها
- متغیرها
- تابعها
- This
- تابعهای Arrow
- حلقهها
- حلقهها و دامنهها
- آرایهها
- قالبهای لفظی (Template Literals)
- نقطهویرگولها
- حالت Strict
- و ECMAScript 6, 2016, 2017
زمانی که این مفاهیم را آموختید، آمادگی تبدیل شدن به یک توسعهدهنده حرفهای جاوا اسکریپت، چه در سمت مرورگر و چه سمت سرور یعنی Node.js را دارید.
مفاهیم زیر نیز برای درک برنامهنویسی ناهمگام که بخشی اساسی از Node.js محسوب میشود، ضروری هستند:
- برنامهنویسی ناهمگام و callback-ها
- تایمرها
- Promise-ها
- Async و Await
- بستارها (Closures)
- حلقه Event
تفاوتهای بین Node.js و مرورگر
روش نوشتن اپلیکیشنهای جاوا اسکریپت در Node.js متفاوت از برنامهنویسی برای وب درون مرورگر است. البته هر دو نسخه مرورگر و Node از جاوا اسکریپت به عنوان زبان برنامهنویسی استفاده میکنند؛ اما ساخت اپلیکیشنهایی که در مرورگر اجرا شوند کاملاً متفاوت از ساخت اپلیکیشنهای Node.js است.
علیرغم این واقعیت که در هر دو مورد از کد جاوا اسکریپت استفاده میشود، برخی تفاوتهای کلیدی وجود دارند که ممکن است باعث شوند تجربه شما از این دو به میزان زیادی متفاوت باشد.
یک توسعهدهنده فرانتاند که اپلیکیشنهای Node.js مینویسد مزیت بسیار زیادی دارد و آن این است که زبان یکسانی در اختیار وی است. این یک مزیت بسیار بزرگ است، زیرا میدانیم که یادگیری عمیق و کامل یک زبان برنامهنویسی تا چه حد دشوار است. با استفاده از جاوا اسکریپت میتوانید با بهرهگیری از یک زبان برنامهنویسی همه کارهای مورد نیاز خود را چه در سمت کلاینت و چه سرور اجرا کنید و این مزیت منحصربهفردی محسوب میشود. این همان چیزی است که کل اکوسیستم را تغییر میدهد.
کد جاوا اسکریپت در مرورگر
در مرورگر اغلب زمان ما به تعامل با DOM یا دیگر API-های پلتفرم وب مانند cookie-ها سپری میشود؛ اما این موارد در Node.js وجود ندارند. در سمت سرور نیازی به کار با document و window یا اشیای دیگری که از سوی مرورگر ارائه میشوند ندارید.
همچنین در مرورگر همه آن API-های زیبایی که Node.js از طریق ماژولهایش ارائه میکند، مانند کارکرد دسترسی به فایل سیستم را در اختیار نداریم.
تفاوت بزرگ دیگر این است که ما در Node.js اقدام به کنترل محیط میکنیم. به جز در مواردی که بخواهید یک اپلیکیشن اوپنسورس بسازید که هر کسی بتواند آن را هر کجا توزیع کند، باید بدانید که اپلیکیشن روی کدام نسخه از Node.js اجرا خواهد شد. این مسئله در مقایسه با محیط مرورگر که امکان انتخاب مرورگر بازدیدکنندگان وجود ندارد، آزادی عمل بیشتری ارائه میکند.
این بدان معنی است که میتوانید هر نوع کدهای جاوا اسکریپت مدرن ES6-8-9 که نسخه Node شما پشتیبانی میکند، بنویسید.
جاوا اسکریپت به سرعت حرکت میکند، اما مرورگرها کندتر رشد میکنند و کاربران نیز با آهنگ کندتری ارتقا مییابند. از این رو در مواردی شاهد هستیم که برخی افراد از نسخههای قدیمیتر JavaScript/ECMAScript استفاده میکنند.
البته میتوان پیش از ارسال کد به مرورگر از Babel برای ترجمه کد به نسخه سازگار با ES5 استفاده کرد؛ اما در Node.js نیازی به این کار وجود ندارد. تفاوت مهم دیگر این است که Node.js از سیستم ماژول CommonJS استفاده میکند؛ در حالی که در مرورگر مدت زیادی از پیادهسازی استاندارد ماژولهای ES نمیگذرد.
این وضعیت در عمل بدان معنی است که وقتی در Node.js از ()require استفاده میکنید در مرورگر همچنان از import استفاده خواهد شد.
موتور V8 جاوا اسکریپت
V8 نام موتور جاوا اسکریپت است که در مرورگر کروم تعبیه شده است. این همان موتوری است که کد جاوا اسکریپت ما را دریافت کرده و آن را در مرورگرهای کروم کاربران اجرا میکند.
V8 محیط runtime-ی را عرضه میکند که کدهای جاوا اسکریپت درون آن اجرا میشوند. DOM و دیگر API-های پلتفرم وب از سوی مرورگر عرضه میشوند.
نکته جالب این است که موتور جاوا اسکریپت مستقل از مرورگری است که آن را میزبانی میکند. این قابلیت کلیدی امکان ظهور Node.js را فراهم ساخته است. V8 در سال 2009 به عنوان موتور Node.js انتخاب شده است و از آنجا که Node.js محبوبیت بسیار بالایی کسب کرده است V8 نیز به موتوری تبدیل شده است که کدهای سمت سرور زیادی را اجرا میکند که به زبان جاوا اسکریپت نوشته شدهاند.
اکوسیستم Node.js بزرگ است و به لطف آن، V8 برای عرضه اپلیکیشنهای دسکتاپ با استفاده از پروژههایی مانند Electron نیز به خدمت گرفته شده است.
موتورهای دیگر جاوا اسکریپت
مرورگرهای دیگر نیز موتورهای خاص خود را برای جاوا اسکریپت دارند که به شرح زیر هستند:
- فایرفاکس از Spidermonkey استفاده میکند.
- سافاری از JavaScriptCore استفاده میکند که Nitro نیز نامیده میشود.
- Edge از Chakra استفاده میکند.
موارد زیاد دیگری نیز وجود دارند. همه این موتورها استاندارد ECMA ES-262 را پیادهسازی میکنند که ECMAScript نیز نامیده میشود و استاندارد مورد استفاده جاوا اسکریپت است.
در جستجوی عملکرد
V8 به زبان ++C نوشته شده است و به طور مکرر بهبود یافته است. این موتور پرتابل است و روی مک، ویندوز، لینوکس و چند سیستم عامل دیگر اجرا میشود. ما در بخش معرفی V8 برخی از جزییات پیادهسازی آن را معرفی نکردیم. این موارد را میتوانید در سایت رسمیV8 (+) مشاهده کنید که در طی زمان تغییر مییابند و تغییراتی غالباً بسیار عمیق هستند.
V8 همانند هر موتور جاوا اسکریپت دیگر، همواره در حال تکامل است تا وب اکوسیستم Node.js را سرعت بیشتری ببخشد. در وب رقابتی برای عملکرد وجود دارد که سالها است در جریان است و ما به عنوان کاربر و توسعهدهنده منافع زیادی از این رقابت بردهایم، زیرا هر سال میتوانیم تجربه مرور وب سریعتر و بهینهتری را شاهد باشیم.
کامپایل
جاوا اسکریپت عموماً به عنوان یک زبان تفسیری نگریسته میشود، اما موتورهای جاوا اسکریپت مدرن دیگر کدهای جاوا اسکریپت را تفسیر نمیکنند، بلکه آن را کامپایل میکنند. این اتفاق از سال 2009 به این سو و با اضافه شدن کامپایلر SpiderMonkey به مرورگر فایرفاکس نسخه 3.5 رخ داد و سپس دیگر رقبا نیز این مسیر را پیگیری کردند.
جاوا اسکریپت به صورت درونی به وسیله V8 و با روش درجا (JIT) کامپایل میشود تا سرعت اجرای کد افزایش یابد.
این وضعیت ممکن است به نظر غیرمنطقی بیاید؛ اما از زمان معرفی Google Maps در سال 2004، جاوا اسکریپت از زبانی که عموماً چند خط کد را اجرا میکرد، به زبانی تبدیل شده است که هزاران و بلکه صدها هزار خط کد را در مرورگر اجرا میکند.
اپلیکیشنهای امروزین ما میتوانند به مدت صدها ساعت درون مرورگرها اجرا شوند و تفاوت زیادی با آن زمانی دارند که تنها چند قاعده اعتبارسنجی فرم یا اسکریپت ساده بودند.
در این دنیای جدید، کامپایل کردن کدهای جاوا اسکریپت کاری کاملاً معنیدار است، زیرا گرچه ممکن است مدت بیشتری طول بکشد که کد جاوا اسکریپت آماده اجرا شود؛ اما وقتی آماده شد، عملکرد بسیار بالاتری نسبت به کد تفسیری ارائه میکند.
چگونه از یک برنامه Node.js خارج شویم؟
روشهای مختلفی برای خاتمه بخشیدن به یک اپلیکیشن Node.js وجود دارد. هنگامی که یک برنامه را در کنسول اجرا میکنید، میتوانید آن را با ctrl-C ببندید؛ اما منظور ما در این بخش خروج برنامهنویسی شده از برنامه است.
برای توضیح این روش ابتدا از بدترین راهحل آغاز میکنیم و دلیل این که نباید از آن استفاده کنید را توضیح میدهیم. ماژول مرکزی process یک روش کارآمد به صورت زیر ارائه کرده است که امکان خروج برنامهنویسی شده از برنامه Node.js را ارائه میکند:
هنگامی که Node.js این خط را اجرا میکند، پردازش مربوطه بیدرنگ مجبور به خروج میشود.
این بدان معنی است که هر callback که در حالت انتظار باشد، هر درخواست شبکه که همچنان در حال ارسال باشد، هر دسترسی به فایل سیستم، یا پردازشهایی که در stdout یا stderr نوشته میشدند، بیدرنگ و بدون هیچ ملاحظهای خاتمه مییابند.
اگر مشکلی در این وضعیت نمیبینید، میتوانید یک عدد صحیح ارسال کنید که کد خروج را به سیستم عامل علامت میدهد:
کد خروج به صورت پیشفرض 0 است که به معنی موفقیت است.
معنی کدهای خروجی مختلف
کدهای خروجی مختلف معناهای متفاوتی دارند که میتوانید در سیستم خود استفاده کنید تا برنامه را وادار به تعامل با برنامههای دیگر بکنید. همچنین میتوانید مشخصه process.exitCode را نیز تعیین کنید:
و زمانی که برنامه در ادامه خاتمه مییابد، Node.js کد خروج را بازگشت میدهد. در این وضعیت یک برنامه حتی زمانی که همه پردازشها خاتمه یافته باشند، با احتیاط بسته میشود.
در اغلب موارد ما در Node.js سرورهایی مانند سرور HTTP زیر را آغاز میکنیم:
این برنامه هرگز به پایان نمیرسد. اگر ()process.exit را فراخوانی کنید؛ هر درخواستی که هم اینک در حالت انتظار یا اجرا باشد، خارج میشود. این وضعیت مناسبی نیست.
در این حالت، باید یک دستور مبنی بر سیگنال SIGTERM ارسال کنید و آن را با استفاده از دستگیره سیگنال پردازش مدیریت کنید.
نکته: process نیازمند require نیست و به صورت خودکار ارائه میشود.
سیگنالها چه هستند؟ سیگنالها سیستم ارتباط داخلی اینترفیس سیستم عامل پرتابل (POSIX) هستند. در واقع سیگنال یک اعلان است که به یک پردازش ارسال میشود تا به آن اطلاع دهد که رویدادی رخ داده است.
- SIGKILL سیگنالی است که به پردازش اعلام میکند تا بیدرنگ خاتمه یابد و معمولاً عملکردی شبیه به ()process.exit دارد.
- SITERM سیگنالی است که به پردازش اعلام میکند تا پردازش را با ملایمت خاتمه ببخشد. این سیگنال از سوی مدیریتهای پردازش مانند upstart یا supervisord و موارد مشابه ارسال میشود.
این سیگنال را میتوان از درون برنامه در تابع دیگری نیز ارسال کرد:
همچنین امکان ارسال این سیگنال از یک برنامه اجرایی دیگر Node.js یا از اپلیکیشن اجرایی دیگری در سیستم وجود دارد. در این مورد آخر آن اپلیکیشن باید PID پردازشی که قرار است خاتمه یابد را بداند.
شیوه خواندن متغیرهای محیطی در Node.js
ماژول مرکزی process در Node مشخصه env را ارائه میکند که میزبان همه متغیرهایی است که در لحظه آغاز به کارِ پردازش تنظیم شده باشند. در ادامه مثالی را مشاهده میکنید که به متغیر محیطی NODE_ENV دسترسی مییابد و به صورت پیشفرض برابر با development تنظیم شده است.
تعیین آن به صورت production پیش از اجرای اسکریپت به Node.js اعلام میکند که این محیط یک محیط «توزیع نهایی» (production) است. به همین ترتیب میتوانید به هر متغیر سفارشی محیطی که تنظیم کردهاید نیز دسترسی داشته باشید.
بدین ترتیب به پایان بخش اول سری مقالات راهنمای جامع Node.js رسیدیم. در بخش بعدی در مورد برخی موضوعات دیگر از جمله شیوه میزبانی از Node، ارتباط با Node از طریق خط فرمان و استفاده از اکسپورتها توضیحاتی ارائه خواهیم کرد. بخش دوم را در لینک زیر مطالعه کنید:
منبع: فرادرس
کار با انواع فرمت ها در پایتون (JSON ،CSV و XML) — به زبان ساده
انعطافپذیری و سهولت استفاده از «زبان برنامهنویسی پایتون» (Python Programming Language)، این زبان را به یکی از محبوبترین زبانها به ویژه برای «دانشمندان داده» (Data Scientist)، مبدل کرده است. یکی از دلایل مهم این امر، سادگی کار بامجموعهدادههای بزرگ در زبان پایتون است. امروزه، همه شرکتهای فناوری، استراتژیهای خاصی را پیرامون «دادهها» برای خود تدوین کردهاند. همه این سازمانها متوجه شدهاند که داشتن دادههای مناسب (معنادار، تمیز و در هر اندازهای که امکان دارد)، به آنها یک مزیت رقابتی کلیدی میدهد. دادهها، اگر به صورت موثر مورد استفاده قرار بگیرند، میتوانند مزیت رقابتی قابل توجهی را برای سازمان به ارمغان بیاورند و بینشی را فراهم کنند که در هیچ کجا و به هیچ شکل دیگر قابل کشف نیست. در طی سالهای اخیر، لیست فرمتهایی که میتوان دادهها را در آنها ذخیره کرد همواره رو به افزایش بوده است. اما در این میان، سه فرمت JSON ،CSV و XML غالب بودهاند. در این مطلب، سادهترین راهکارها برای کار با انواع فرمت ها در پایتون (JSON ،CSV و XML)، بیان شده است.
کار با انواع فرمت ها در پایتون
در ادامه، روش کار با فرمتهای محبوب JSON ،CSV و XML در پایتون بیان و قطعه کدهای لازم برای انجام هر عملیات به طور کامل ارائه شده است.
دادههای CSV
فایلهای CSV (سه حرف CSV، سرنامی برای Comma Separated Values هستند) راهکاری متداول برای ذخیرهسازی دادهها محسوب میشوند. بیشتر دادههایی که در رقابتهای «کگل» (Kaggle) مورد استفاده قرار میگیرند از این نوع هستند. با استفاده از تابع توکار CSV در پایتون، میتوان فایلهای CSV را هم خواند (Read) و هم روی آنها نوشت (Write). به طور متداول، دادهها در یک لیست از لیستها خوانده میشوند. کدی که در ادامه آمده، در این راستا شایان توجه است.
هنگامی که ()csv.reader اجرا شود، همه دادههای CSV در دسترس قرار میگیرند. تابع ()csvreader.next یک خط تنها را از CSV میخواند. هر بار که این تابع فراخوانی شود، به خط بعدی میرود. همچنین، میتواند در هر سطر از فایل CSV با استفاده از حلقه for به صورت for row in csvreader، تکرار داشته باشد (حلقه زدن). باید اطمینان حاصل کرد که تعداد ستونها در کلیه سطرها با هم برابر است. در غیر این صورت، کاربر ممکن است با خطاهایی در حین کار با لیستی از لیستها، مواجه شود.
نوشتن روی فایل CSV در پایتون، به سادگی خواندن دادهها از روی آن است. در این راستا، باید اسامی فیلد را در یک لیست کوتاه تنظیم کرد. این بار، باید یک شی ()writer – توسط کاربر – ساخته شود و از آن برای نوشتن دادهها در یک فایل به شیوهای بسیار مشابه با کاری که برای خواندن دادهها از روی یک فایل انجام شده، استفاده شود.
البته، نصب کتابخانه فوقالعاده عالی «پانداس» (Pandas) کار با دادهها را پس از خواندن آنها در یک متغیر، بسیار سادهتر میکند. خواندن از یک فایل CSV با استفاده از کتاب پانداس نیز همچون نوشتن روی آن، با یک خط کد امکانپذیر است.
حتی میتوان از پانداس برای تبدیل یک فایل CSV به یک لیست از دیکشنریها (Dictionaries) تنها با یک خط کد، استفاده کرد. هنگامی که دادهها به صورت یک لیست از دیکشنریها قالببندی شدند، از کتابخانه dicttoxml برای تبدیل آن به قالب XML استفاده میشود. همچنین، میتوان آن را به صورت فایل JSON نیز ذخیره کرد.
دادههای JSON
«جیسان» (JSON) یک قالب تمیز و به سادگی قابل خواندن را فراهم میکند، زیرا ساختاری با استایل دیکشنری را حفظ میکند. درست مانند CSV، پایتون دارای یک ماژول توکار برای JSON نیز هست که خواندن و نوشتن را فوقالعاده در این فرمت آسان میکند. در پایتون، پس از خوانده شدن یک فایل CSV، به یک دیکشنری مبدل میشود. سپس، دیکشنری مذکور توسط کاربر روی یک فایل نوشته میشود.
همانطور که پیش از این مشاهده شد، میتوان دادهها را به سادگی با استفاده از کتابخانه Pandas یا ماژول پایتون توکار CSV به CSV مبدل کرد. برای تبدیل به XML، کتابخانه dicttoxml به کمک کاربر میآید.
دادههای XML
کار با دادهها در قالب XML، کمی با انواع دادههای CSV و JSON متفاوت است. به طور کلی، CSV و JSON به دلیل سادگی که دارند به طور گسترده مورد استفاده قرار میگیرند. نوشتن، خواندن و تفسیر هر دو نوع فایل بیان شده، برای انسان آسان است. به منظور کار با این دو فرمت داده، نیازی به هیچ کار دیگری (به جز آنچه بیان شد) نیست. تجزیه (Parsing) یک فایل JSON یا CSV بسیار ساده است. اما کار با فایلهای XML اندکی دشوارتر است. این در حالی است که فرمت XML نسبت به JSON و CSV دارای ویژگیهای افزودهای است. کاربر میتواند از فضای نام برای ساخت و به اشتراکگذاری ساختارهای استاندارد، ارائه بهتری برای ارثبری و یک راهکار استانداردشده صنعتی جهت ارائه دادهها با شمای XML و DTD و دیگر موارد استفاده کند. برای خواندن دادههای XML، از ماژول توکار پایتون با زیرماژولی (Sub-Module) با عنوان ElementTree استفاده میشود. از آنجا، میتوان شی ElementTree را با استفاده از کتابخانه xmltodict به یک شی تبدیل کرد. هنگامی که یک دیکشنری وجود دارد، میتوان آن را به JSON ،CSV یا دیتافریم پانداس (مانند آنچه در بالا مشاهده شد) تبدیل کرد.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
منبع: فرادرس