طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسی۹ افزونه ویژوال استودیو کد برای برنامه نویسی آسان تر — راهنمای کاربردی
ویژوال استودیو کد یک IDE از محصولات مایکروسافت و همزمان یکی از بهترین ویرایشگرهای رایگان متن حال حاضر است. این IDE مجموعه کاملی از سهولت نسبی استفاده و عملکرد را ترکیب کرده است که به عنوان یک اپلیکیشن Electron کاملاً شگفتانگیز است. به جز مواردی که ذکر کردیم، یکی از دلایلی که افراد عاشق VS Code میشوند، قابلیت توسعهپذیری آن است. ویژوال استودیو کد نیز مانند اغلب ویرایشگرهای متنی دیگر تعداد بالایی افزونه دارد که به سفارشیسازی رفتار آن کمک میکنند. بدین ترتیب میتوان طرز کار و ظاهر VS Code را تا حدود زیادی تغییر داد. برای نمونه میتوان Vim یا key binding-های به سبک Emcas را به آن اضافه کرد. ما در ادامه چند مورد معدود از فهرست پرشمار افزونههای ویژوال استودیو کد را معرفی میکنیم. اما قبل از آن باید با روش نصب افزونههای VS Code آشنا شویم.
آموزش نصب افزونه ویژوال استودیو کد
در صورتی که با روش نصب افزونههای ویژوال استودیو کد آشنا نیستید، نگران نباشید چون فرایند بسیار آسانی دارد. روی آیکون Extensions در سمت چپ صفحه کلیک کنید. این پنجمین آیکون است که درست زیر آیکون Debug قرار دارد.
در ادامه نام کامل یا بخشی از نام آن اکستنشن که میخواهید نصب کنید را وارد کنید. روی نامی که میبینید کلیک کنید تا خلاصهای راجع به افزونه بخوانید و سپس روی آیکون Install کلیک کنید تا نصب شود.
1. Visual Studio IntelliCode
Visual Studio IntelliCode (+) که از سوی بخش DevLabs مایکروسافت توسعه یافته، اکستنشنی است که هوش مصنوعی را در جهت کمک به کدنویسی به VS Code آورده است. این افزونه در حال حاضر از زبانهای پایتون، جاوا اسکریپت/تایپاسکریپت و جاوا پشتیبانی میکند.
اگر IntelliCode را قبلاً در ویژوال استودیو یا ویژوال استودیو کد نصب کرده باشید، احتمالاً میدانید که عملکرد آن به چه صورت است. تنها تفاوت در اینجا آن است که این افزونه اساساً هوشمندتر از حالتی است که تصور میکنید. اکستنشن مورد بحث همچنان در مراحل ابتدایی توسعه خود قرار دارد و با این حال عملکرد کاملاً جالبی دارد. در مراحل بعدی توسعه ممکن است شاهد این باشیم که این افزونه به صورت یک قابلیت داخلی VS Code عرضه شود.
2. Settings Sync
اغلب افرادی که از یک ویرایشگر متنی استفاده میکنند، به طور مرتب تغییراتی در تنظیمات آن ایجاد میکنند. برخی دیگر نیز پا را فراتر میگذارند و ویرایشگر خود را طوری سفارشیسازی میکنند که با سبک نگارش شخصیشان متناسب باشد. اگر به طور مکرر کارهایتان را روی بیش از یک سیستم انجام میدهید، اعمال این اصلاحها به صورت مداوم کار خستهکنندهای خواهد بود.
اکستنشن Settings Sync (+) به حل این مشکل کمک میکند. این افزونه با کمک گرفتن از یک GitHub Gist ساده، تنظیمات VS Code شما را روی سیستمهای مختلف همگامسازی میکند. این موارد شامل انواع اکستنشنهای نصب شده و پیکربندی آنها نیز میشود و از این رو با استفاده از این افزونه، همه پیکربندیهای شما به صورت پرتابل درمیآیند. در صورتی که تغییراتی روی یک سیستم ایجاد کنید، میتوانید با همگامسازی تنظیمات، آنها را روی سیستمهای دیگر نیز مشاهده کنید.
البته همگامسازی تنظیمات ممکن است چند دقیقه طول بکشد؛ اما پس از طی این مدت دیگر لازم نیست در مورد ایجاد تغییرات و اصلاحهای مختلف نگران نباشید. دستورالعملهای راهاندازی این افزونه در بخش معرفی اکستنشن در VS Code ارائه شده است. همچنین اگر به راهنمایی بیشتری نیاز دارید، میتوانید از مطلب زیر استفاده کنید:
3. Path Intellisense
اگر از ویژوال استودیو کد برای ویرایش فایلهای شخصی یا سیستمی استفاده میکنید، اکستنشن Path Intellisense (+) میتواند کمک زیادی به شما بکند. این افزونه به طور خلاصه امکان تکمیل کردن با سبک Intellisense را برای نام فایلها میسر میسازد و بدین ترتیب میتوانید به سادگی نام مسیرهای طولانی فایل را بدون نیاز به کامیت کردن در حافظه وارد کنید.
این افزونه کارکرد نسبتاً سادهای دارد؛ اما چند گزینه پیکربندی نیز وجود دارند. برای نمونه میتوان انتخاب کرد که علامت / پس از نامهای دایرکتوری اضافه شود یا نشود. گزینههای دیگر شامل این هستند که آیا نام فایل در گزارههای ایمپورت ذکر شود یا نه و یا این که میتوانید انواع خاصی از فایلها را نادیده بگیرید.
4. Task Explorer
اکستنشن Task Explorer (+) کارکردهای اجرای وظیفه به سبک IDE را به ویژوال استودیو کد اضافه میکند. این وضعیت به طور عمده شامل ساخت وظایفی برای پروژه کنونی است، اما شامل Bash، پایتون و دیگر اسکریپتها نیز میشود.
Task Explorer از تعداد نسبتاً زیادی از ابزارهای استاندارد Build پشتیبانی میکند. این موارد شامل NPM ،Grunt ،Gulp ،Ant ،Make و خود ویژوال استودیو کد میشود. این افزونه قابلیت سفارشیسازی دارد و امکان سفارشی ساختن مسیر هر اجراکننده وظیفه و زبان اسکریپتنویسی را میدهد. این موارد در صورتی که چند نسخه از هر کدام از این موارد نصب شده باشد و شما بخواهید از یک نسخه خاص استفاده کنید، مفید خواهد بود.
5. GitLens
ویژوال استودیو کد به صورت پیشفرض پس از نصب، به قابلیت یکپارچهسازی Git مجهز است و از این رو ممکن است نیاز مطلقی به این افزونه نداشته باشید. با این وجود، GitLens (+) چندین قابلیت اضافه کرده است که به بصریسازی، ناوبری و درک تاریخچه گیت پروژه کمک میکند.
GitLens علاوه بر ویژگیهای دیگری که دارد یک قابلیت قدرتمند برای نمایش تفاوتها در پنجره جداگانه (split diff) ارائه میکند که به بصریسازی تفاوتهای بیت کامیت ها و شاخهها (Branches) کمک میکند. این افزونه امکان جستجو تاریخچه کامیت پروژهها، جستجوی نویسندگان، فایلها، پیامهای کامیت و موارد دیگر را نیز ارائه میکند.
ویژگیهای دیگر شامل «هیتمپ» (Heat Map) در حاشیه پنجره ویژوال استودیو کد است که به ما امکان میدهد به آسانی ببینیم که در یک فایل مفروض بخش عمده کار در کجا صورت گرفته است. برای جمعبندی در مورد این اکستنشن باید اضافه کرد که اگر در پروژه خود تمرکز زیادی روی Git دارید، حتماً باید آن را دست کم یک بار امتحان کنید.
6. Prettier
اگر یک توسعهدهنده فرانتاند هستید و به خصوص اگر دوست دارید از یک سبک نگارشی خاص پیروی کنید، افزونه Prettier (+) این نیاز شما را به بهترین وجه تأمین میکند. این افزونه به صورت خودکار کدهای جاوا اسکریپت، تایپاسکریپت و CSS را با استفاده از ابزارهای مرتبط قالببندی کد برای هر زبان قالببندی میکند.
Prettier کدی را که نوشتهاید میگیرد و آن را با پیروی از یک سری راهنماهای قالببندی برای شما بازنویسی میکند. این اکستنشن دارای گزینههای مختلفی است و میتوانید بسته به نیازهای خود آن را پیکربندی کنید، اما میتوانید از آن به همراه ابزارهای eslint یا tslint نیز استفاده کنید تا مطمئن شوید که از پیکربندی بندی linting خود پیروی میکند.
7. Bracket Pair Colorizer
Bracket Pair Colorizer (+) افزونهای است که نامش آن را به خوبی توصیف میکند. این افزونه به صورت خودکار کاراکترهای خاصی را در کد رنگی میکند تا مشخص شود که یک بخش خاص از کد در سلسلهمراتب خود در چه سطحی قرار دارد. این اکستنشن به صورت پیشفرض از چند زبان پشتیبانی میکند و این فهرست آن قدر بزرگ هست که مطمئن باشید زبان مورد نظر شما نیز در آن جای دارد.
به صورت پیشفرض کاراکترهای ()، []، و {}با همدیگر تطبیق پیدا میکنند؛ اما میتوانید کاراکترهای براکت دیگر را نیز بر حسب نیاز اضافه کنید. این نوع از افزونهها معمولاً مورد تنفر یا عشق شدید کاربران قرار دارند، اما گر مطمئن نیستید که آن را دوست دارید یا نه، بهتر است دست کم یک بار امتحانش کنید.
8. Code Time
آیا تاکنون کنجکاو بودهاید که چه مقدار زمان برای کار روی یک قطعه کد صرف کردهاید؟ آیا تاکنون خواستهاید بدانید که بهترین زمان برنامهنویسی بهینه شما چه زمان از روز یا کدام روز هفته بوده است؟ اگر تا به حال مشتاق بودهاید که پاسخ این سؤالها یا هر معیار زمانی دیگر را بدانید، بهتر است از اکستنشن Code Time (+) استفاده کنید.
افزونه Code Time فعالیت شما در ویژوال استودیو کد را اندازهگیری میکند و در مورد این فعالیتها و همچنین معیارهای دیگر به شما گزارش میکند. شما میتوانید معیارهای آنی را در نوار وضعیت ببینید و برای مشاهده موارد بیشتر، یک داشبورد نیز درون ویرایشگر ارائه شده است.
میتوان Code Time را طوری تنظیم کرد که در مورد فعالیتهای فوق گزارشهای هفتگی به شما ارائه کند. همچنین یکپارچهسازی آن با تقویم گوگل باعث میشود که به صورت خودکار بهترین زمانهای برنامهنویسی خود را بدانید و در آن زمانها به کار بپردازید و دیگر اجازه ندهید که این زمانها در جلسههای کاری به هدر بروند.
9. REST Client
شما چه یک توسعهدهنده فرانتاند وب باشید و یا فردی باشید که به صورت عمده روی سرور کار میکنید، احتمالاً با مواردی مواجه شدهاید که باید یک REST API را تست میکردید. برخی افزونههای مرورگر و کلی ابزار دیگر برای این منظور وجود دارند، اما اگر اغلب زمان خود را در یک ویرایشگر متنی صرف میکنید، آیا بهتر نیست که کلاینت را نیز در همین جا داشته باشید؟
افزونه REST Client (+) افزونه نسبتاً سادهای است که کار خود را به نحو احسن انجام میدهد. با استفاده از این افزونه میتوان یک درخواست HTTP و همچنین دستورهای cURL ارسال کرد. برای احراز هویت، این افزونه از روشهای احراز هویت مقدماتی، احراز هویت digest، گواهی کلاینت SSL و موارد مشابه پشتیبانی میکند.
سخن پایانی در مورد افزونه های ویژوال استودیو کد
اکستنشنهایی که در این مطلب معرفی کردیم، تنها گوشه کوچکی از دنیای گسترده افزونههای VS Code را تشکیل میدهند. به خصوص اگر به تازگی با ویژوال استودیو کد آشنا شدهاید، افزونههای زیادی وجود دارند که میتوانید امتحان کنید. البته ما در این نوشته از اکستنشنهایی که اختصاص به یک زبان خاص داشتند اجتناب کردیم که میتوانید با کمی جستجو آنها را پیدا کنید. شما چه در زبان جاوا اسکریپت و چه در ++C یا Go یا زبانهای دیگر کدنویسی کنید، افزونههایی وجود دارند که به تسهیل کارهای شما کمک میکنند.
آموزش پایتون: ساخت نمودارهای مالی با Bokeh — از صفر تا صد
دنیا به سرعت در حال رشد است. از زمانی که اینترنت و گوشیهای هوشمند تکامل یافتهاند، فناوریهای مالی به طور انفجاری رشد کردهاند. بر اساس گزارشها، از هر 781 نفر روی کره زمین یک نفر به صورت آنلاین تجارت میکند. این عدد وقتی با دیگر کارهایی که انسانها انجام میدهند مقایسه شود، عدد بزرگی به نظر خواهد رسید. در این مطلب در مورد دادههای بازار سهام، روش دانلود کردن آنها از ترمینال و پرکاربردترین نمودار در حوزههای تجاری که به نام نمودار «شعدانی» یا «کندلاستیک» (Candlestick) شناخته میشود بیشتر خواهیم آموخت. همچنین، روش رسم نمودارهای کندلاستیک را با استفاده از پایتون و Bokeh از صفر فرا خواهیم گرفت. در ادامه این مطلب راجع به ساخت نمودارهای مالی با Bokeh با مجله فرادرس همراه باشید.
برای مطالعه قسمت قبلی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
دانلود کردن دادههای بازار سهام
در این مرحله به صورت گام به گام کارهایی که باید انجام یابند را توضیح میدهیم. ابتدا باید با نوشتن دستور زیر پکیج pandas_datareader را نصب کنیم:
pip3 install pandas_datareader --user
این بسته به ما کمک میکند که دادههای بازار سهام را دانلود کنیم. نکته جالب این است که این کار از ترمینال نیز امکانپذیر است. کار دوم این است که کتابخانه datetime را نصب میکنیم تا قاب زمانی را برای بازهای که دادههایش را لازم داریم ثبت شود.
در این مرحله دادهها را از نهم اکتبر 2018 دریافت میکنیم. اینک برای واکشی دادهها باید در پارامتر نخست نام شرکت یا سهام را وارد کنیم. برای مثال عبارت TSLA برای اشاره به شرکت Tesla استفاده میشود. هر شرکت یک نام اختصاری یا ticker برای خود دارد. شرکت Yahoo نیز منبع خوبی برای بررسی دادههای مالی محسوب میشود. از این رو از Yahoo به عنوان منبع دادهها استفاده میکنیم. موارد دیگر که میتوانید استفاده کنید، Google ،FRED ،Robinhood و موارد بسیار دیگر است. دو پارامتر آخر نیز قاب زمانی هستند که قبلاً اشاره کردیم.
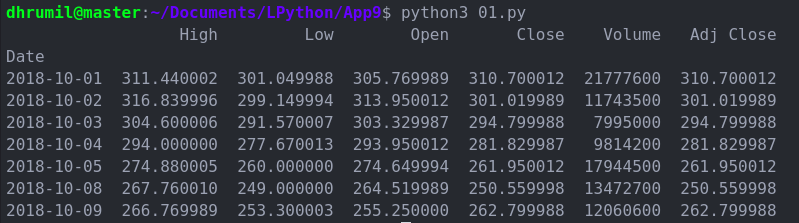
درک دادههای بازار سهام
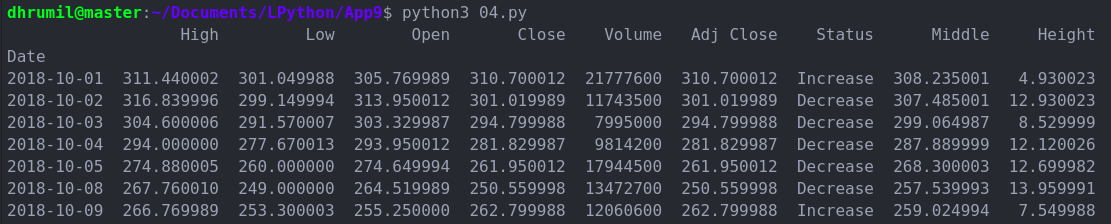
اگر قبلاً با بازار سهام آشنایی داشته باشید، میتوانید این مرحله را کلاً رد کنید و به مرحله بعد بروید. اگر چنین نیست مطمئن باشید که بالاخره یک روز سر و کارتان به آنجا خواهد افتاد. اما در حال حاضر، اجازه دهید توضیح دهیم که معنی این دادهها چیست. ما در تصویر فوق پنج ستون داریم که تقریباً شامل همهچیز میشود. شما میتوانید ستون Adj close را فعلاً نادیده بگیرید.
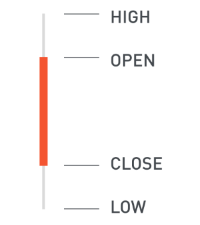
- High: بالاترین قیمتی است که سهام معامله شده است.
- Low: پایینترین قیمتی است که سهام معامله شده است.
- Open: قیمت سهام در نخستین لحظه باز شدن بازار است.
- Close: قیمت سهام در زمان بسته شدن بازار سهام است.
- Volume: تعداد سهمهای معامله شده در روز مفروض است.
تنها به کمک این پنج ستون میتوانیم گراف مالی خود را بسازیم تا دادهها به حالت بصری درآیند و بتوانیم از آن نتیجهگیریهایی بکنیم. بنابراین منتظر چه هستیم؟ در ادامه این کار را انجام میدهیم. همواره نهایت تلاش خود را بکنید که پول دربیاورید، اما هیچ گاه این سخن بنجامین فرانکلین را فراموش نکنید که: «سرمایهگذاری روی دانش، بالاترین بهره را میدهد.»
درک نمودار کندلاستیک

نمودار کندلاستیک روشی بسیار کارآمد برای نگاه کردن همزمان به همه ستونهایی است که در بخش قبل اشاره کردیم. همان طور که در تصویر فوق میبینید، کندل سبز نشان میدهد که قیمت امروز افزایش یافته است، در حالی که کندل قرمز نشانگر کاهش است. قیمتهای high و low نیز روی آن کندل نمایش مییابند.
ساخت بدنه کندلاستیک
اینک ما میدانیم که نمودارهای کندلاستیک چیست و همچنین با روش دانلود دادههای بازار سهام آشنا شدیم. بنابراین اکنون نوبت آن رسیده است که بدنه نمودارهای کندلاستیک خود را با استفاده از متد rect در کتابخانه Bokeh بسازیم. اما قبل از این کار باید یک تصویر (figure) بسازیم که نمودار درون آن نمایش پیدا میکند. در واقع این یک زمینه بیرونی است. به این منظور از متد figure کتابخانه Bokeh استفاده میکنیم.
کد فوق یک کادر خالی ایجاد میکند که نمودار ما در ادامه روی آن نمایش پیدا خواهد کرد. اگر از متد rect استفاده کنیم باید چهار پارامتر اجباری به آن ارسال کنیم که باعث ساخت یک مستطیل کامل میشوید. دو پارامتر نخست یعنی X-coordinate and و Y-coordinate نقاط مرکزی مستطیل هستند (این وضعیت پیشفرض، گرچه روش عجیبی است؛ اما به هر حال مهم است). دو پارامتر دیگر Width و Height یعنی عرض و ارتفاع تصویر هستند. ابتدا نگاهی به کد میاندازیم:
پارامترهای نمودار
اینک نوبت آن رسیده است که همه پارامترهای مورد استفاده در متد rect را توضیح دهیم، به طوری که بدانیم نخستین نمودار کندلاستیک چگونه آمادهسازی میشود.
- X-axis: همان طور که اشاره کردیم، به یک نقطه مرکزی برای رسم مستطیل خود نیاز داریم و به این منظور باید مختصات افقی یا x نقطه مرکزی را ارسال کنیم. برای محور x از مقدار df.index استفاده میکنیم، چون شامل مقادیر زمانی است.
- Y-axis: در مورد محور y یا عمودی از مقدار 2/(open+close) برای همان تاریخ استفاده میکنیم و بدین ترتیب نقطه مرکزی مستطیل خود را در اختیار داریم.
- Width: ما برای عرض کندلاستیک از پارامتر hours استفاده میکنیم. هر روز 24 ساعت است. در هر طرف 6 ساعت داریم و از این رو بدنه مستطیل 12 ساعت خواهد بود و سپس یک فاصله 12 ساعتی و کندل بعدی قرار دارند. اساساً ما بر اساس زمان فاصلهبندی میکنیم و نه بر حسب فضا؛ گرچه روش چندان مناسبی به نظر نمیرسد.
- Height: تفاضل مطلق بین مقادیر قیمت باز و بسته شدن بازار، ارتفاع بدنه کندل را تشکیل میدهد.
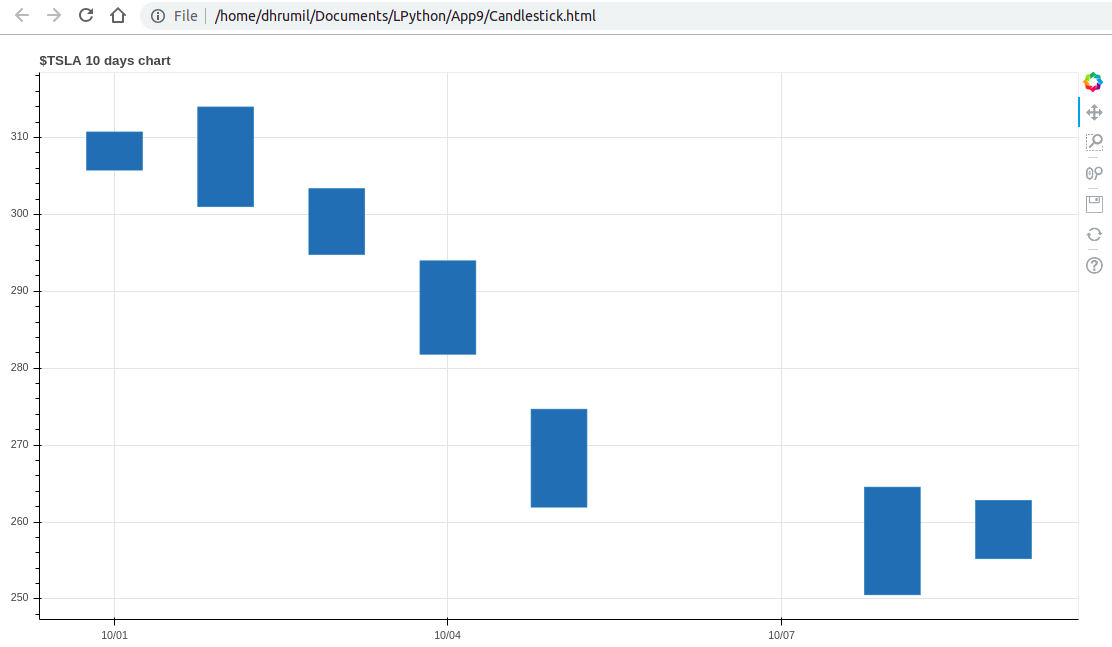
اینک موفق شدهایم بخش اصلی کار را به پایان ببریم. حال میدانیم که همه چیزهای لازم برای ساخت نمودار کندلاستیک بر اساس دادههای شرکت مورد نظر در اختیارمان قرار دارند. نمودار ما برای TESLA چیزی مانند تصویر زیر است:
زیباتر ساختن ظاهر نمودار
هیچ کس دوست ندارد همیشه میلههای آبی را تماشا کند که هیچ معنایی ندارند. به همین دلیل باید تغییراتی در آنها ایجاد کنیم. ما از میلههای سبز و قرمز به ترتیب برای بالا رفتن و پایین آمدن قیمت استفاده میکنیم. ضمناً تابعهای مستقلی برای همه پارامترها در متد rect ایجاد میکنیم. در ادامه یک ستون جدید برای هر کدام ایجاد کردهایم و دادهها را در آن ذخیره میکنیم تا درک طرز کار همه موارد آسانتر باشد. میتوانید قاب داده بهروزرسانی شده را زیر قطعه کدی که در ادامه آمده است ببینید و پس از آن نمودار بهروزرسانی شده ارائه شده است:
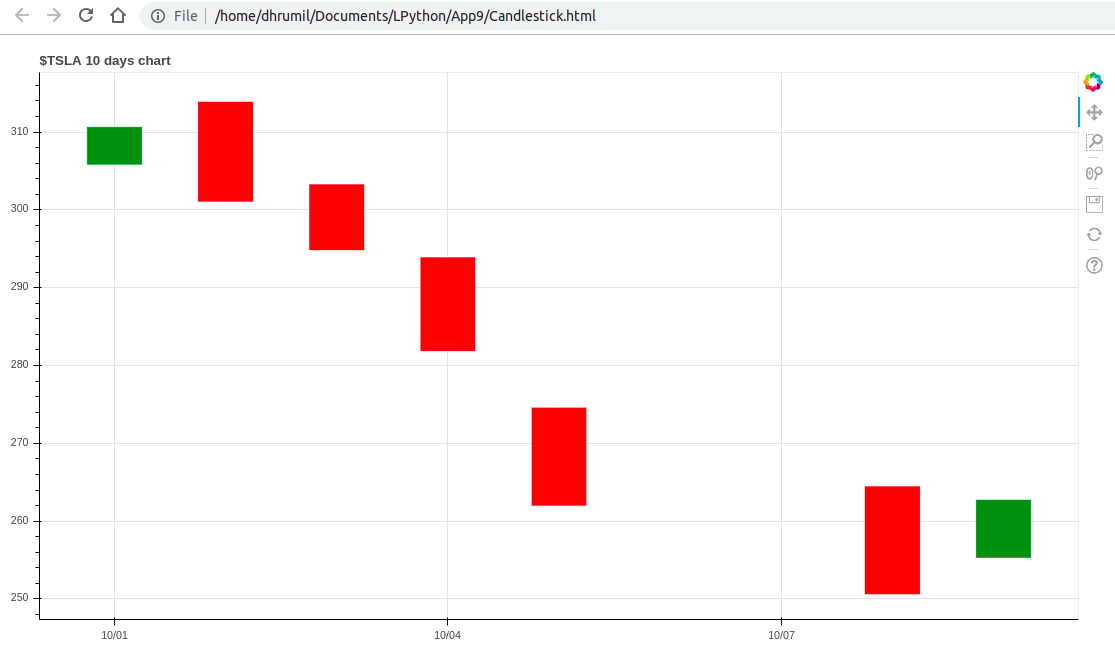
ساخت قطعههای کندلاستیک
اینک ما یک نمودار زیبا داریم و بدنه میلهها را نیز ایجاد کردهایم، اما همچنان مقادیر high و low نمایش پیدا نمیکنند. این میلهها نیز همانند عمر همه ما کوتاه و بلند دارند. اگر به خط 41 کد زیر نگاه کنید، میبینید که این وضعیت را چگونه باید مدیریت کنید، فرایند سادهای دارد.
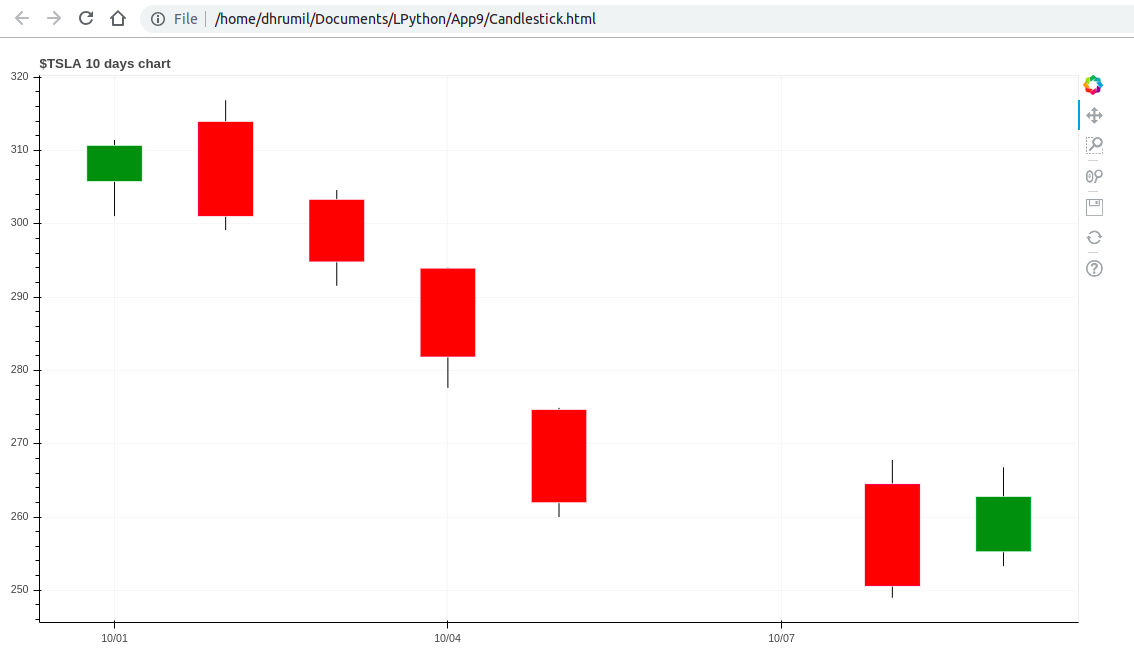
بدین ترتیب موفق شدهایم یک نمودار عالی کندلاستیک را برای 10 روز بسازیم. همین کار را میتوان برای بازه 3 ماهه و یا بیشتر نیز ایجاد کرد. نموداری که در ادامه مشاهده میکنید، با استفاده از همان 60 خط کد فوق ساخته شده و مربوط به دادههای سه ماه است.
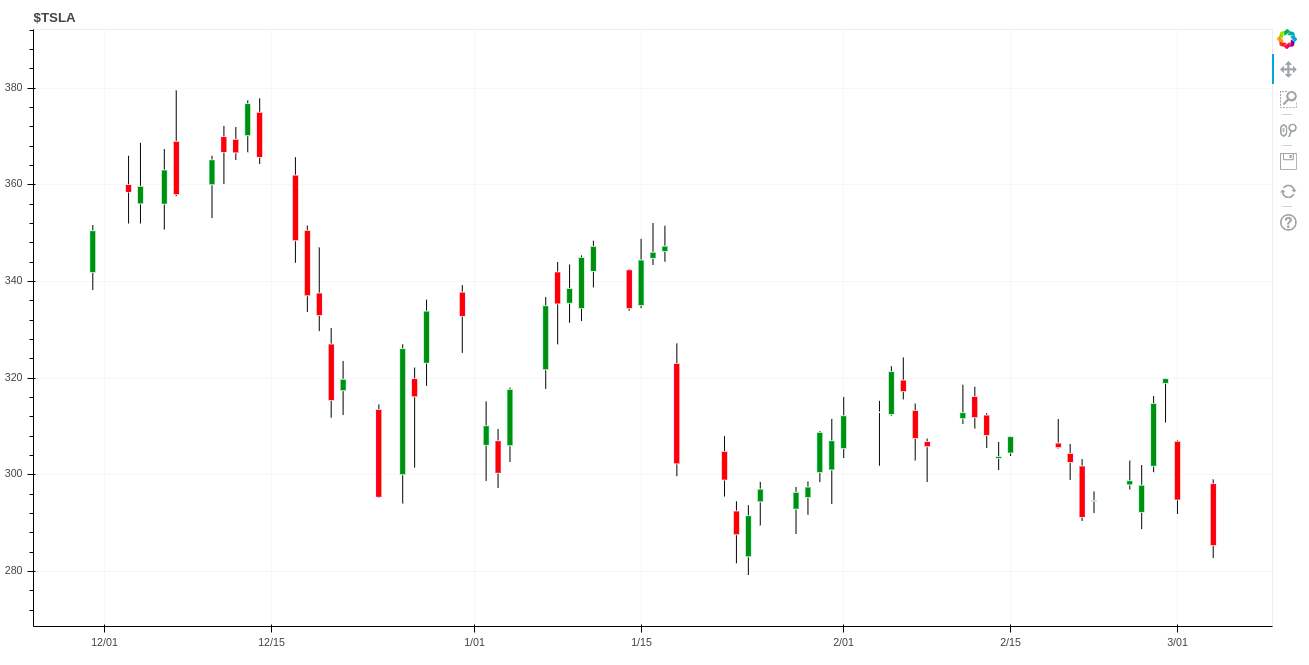
سخن پایانی درباره ساخت نمودارهای مالی با Bokeh
همانطور که همه ما میدانیم، بصریسازی به درک بهتر دادههای خام کمک زیادی میکند. ایجاد نمودارهای بصری از دادهها مزیتهای بسیاری دارد و به کمک کتابخانههای خارجی مانند Bokeh و همچنین فرایند بصریسازی پایتون این کار قدرتمندتر از هر زمان دیگری انجام میپذیرد. در این مطلب مواردی را در خصوص دادههای بازار سهام، روش دانلود کردن آنها، مفهوم نمودارهای کندلاستیک، و روش ایجاد آنها به کمک کتابخانه Bokeh آموختید.
منبع: فرادرس
تشخیص چهره در پایتون با OpenCV و Dlib — از صفر تا صد
در این راهنما با روش ایجاد و اجرای یک الگوریتم تشخیص چهره در پایتون با استفاده از OpenCV و Dlib آشنا میشویم. همچنین برخی قابلیتهای آنها را برای شناسایی همزمان چشمها و دهان روی چهرههای مختلف معرفی خواهیم کرد. در این مقاله روش پیادهسازی مقدماتی تشخیص چهره را به طور کامل توضیح میدهیم که شامل ابزارهای طبقهبندی آبشاری، پنجرههای HOG، و CNN-های یادگیری عمیق میشود.
برای مشاهده مخزن گیتهاب این مقاله به این لینک (+) مراجعه کنید.
مقدمه
ما در این مطلب از OpenCV استفاده خواهیم کرد که یک کتابخانه متنباز برای بینایی ماشین است و به زبان ++C/C نوشته شده است. این کتابخانه اینترفیسهایی در زبانهای ++C، پایتون و جاوا دارد. OpenCV از پلتفرمهای ویندوز، لینوکس، macOS ،iOS و اندروید پشتیبانی میکند. برخی از بخشهای کار نیازمند Dlib هستند که یک کیت ابزار ++C شامل الگوریتمهای یادگیری ماشین و ابزارهایی برای خلق نرمافزارهای پیچیده است.
پیشنیازهای تشخیص چهره در پایتون
نخستین مرحله برای شروع کار، نصب OpenCV و Dlib است. به این منظور دستور زیر را وارد کنید:
pip install opencv-python pip install dlib
بسته به این که از کدام نسخه از پایتون استفاده میکنید، فایل در مسیرهای مختلفی نصب میشود. در مورد نسخهای که ما استفاده میکنیم، وضعیت به صورت زیر بوده است:
/usr/local/lib/python3.7/site-packages/cv2
اگر در نصب Dlib با مشکلاتی مواجه شدید به این مقاله (+) مراجعه کنید.
ایمپورت و مسیر مدلها
ما یک نتبوک ژوپیتر/فایل پایتون میسازیم و کار خود را با آن آغاز میکنیم:
import cv2 import matplotlib.pyplot as plt import dlib from imutils import face_utils font = cv2.FONT_HERSHEY_SIMPLEX
طبقهبندی آبشاری
ابتدا به بررسی طبقهبندی آبشاری میپردازیم.
نظریه
طبقهبندی آبشاری یا آبشارهای مشهور طبقهبندی ارتقا یافته به همراه ویژگیهای شِبه Haar (یا Haar-like feature) عمل میکنند و یک کاربرد خاص از «یادگیری گروهی» (ensemble learning) محسوب میشوند که boosting نام دارند. این ابزارها به طور عمده روی طبقهبندیهای Adaboost و دیگر مدلها مانند Real Adaboost ،Gentle Adaboost یا Logitboost تکیه دارند.
ابزارهای طبقهبندی آبشاری روی چند تصویر نمونه از یک موضوع آموزش میبینند. این تصاویر شامل سوژهای است که میخواهیم شناسایی کنیم. همچنین از تصاویر دیگر که شامل آن موضوع نیستند نیز استفاده میشود.
چگونه میتوان تشخیص داد که در تصویری چهره انسان وجود دارد یا نه؟ یک الگوریتم به نام فریمورک شناسایی شیء Viola–Jones وجود دارد که شامل همه مراحل مورد نیاز برای شناسایی زنده چهره است. این موارد شامل فهرست زیر میشوند:
- گزینش ویژگی Haar: ویژگیهایی هستند که از موجکهای Haar مشتق شدهاند.
- ایجاد تصویر یکپارچه
- آموزش Adaboost
- ابزارهای طبقهبندی آبشاری
اگر میخواهید مقاله اصلی Viola-Jones را ببینید، به این لینک (+) مراجعه کنید.
گزینش ویژگی Haar
برخی ویژگیهای مشترک وجود دارند که در همه چهرههای انسانی میتوان مشاهده کرد:
- یک منطقه شامل ناحیه چشمی که در مقایسه با گونهها تیرهتر است.
- رنگ روشنتر بینی در مقایسه با چشمها
- موقعیت خاص چشمها، دهان و بینی و …
این خصوصیات به نام ویژگیهای Haar نامیده میشوند. فرایند استخراج ویژگی مانند زیر است:

در این مثال، نخستین ویژگی تفاوت بین شدت روشنایی بین ناحیه چشمها و منطقه گونههای فوقانی را اندازهگیری میکند. مقدار این ویژگی به وسیله جمع زدن پیکسلها در ناحیه سیاه فوقانی و تفریق آن از مقادیر پیکسلهای ناحیه سفید به دست میآید.
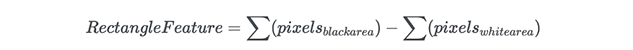
سپس این مستطیل را به عنوان یک کرنل کانولوشنی روی کل تصویر اعمال میکنیم. برای این که رویکرد جامعی داشته باشیم، باید همه ابعاد و موقعیتهای ممکن برای هر کرنل را اعمال کنیم. یک تصویر ساده 24 در 24 پیکسل، معمولاً منتهی به 160،000 ویژگی میشود که هر یک از جمع/تفریق کردن مقادیر پیکسلها به دست آمدهاند. بدین ترتیب امکان تشخیص چهره زنده از دست میرود. بنابراین سؤال این است که این فرایند چگونه عملیاتی میشود؟
زمانی که ناحیه مناسبی به وسیله یک مستطیل شناسایی میشود، اجرای پنجره روی نواحی مختلف چهره بیفایده خواهد بود. این کار به وسیله Adaboost صوت میگیرد.
ویژگیهای مستطیل با استفاده از مفهوم تصویر یکپارچه محاسبه میشوند که روشی بسیار سریعتر است. در مورد این روش در بخش بعدی بیشتر توضیح خواهیم داد.

چند نوع از مستطیلها وجود دارند که میتوان برای استخراج ویژگیهای Haar مورد استفاده قرار داد. این موارد شامل فهرست زیر هستند:
- ویژگی دو مستطیلی به تفاضل بین مجموع مقادیر پیکسلها درون نواحی مستطیلی میپردازد و به طور عمده برای تشخیص لبهها (در تصویر زیر a و b) استفاده میشود.
- ویژگی سه مستطیلی مجموع ناحیه درون محدوده مستطیلهای کناری را محاسبه میکند که از مجموع مستطیل میانی کسر میشوند و به طور عمده برای شناسایی خطوط (c و d) استفاده میشود.
- ویژگی چهار مستطیلی تفاضل بین جفتهای قطری مستطیلها (e) را محاسبه میکند.
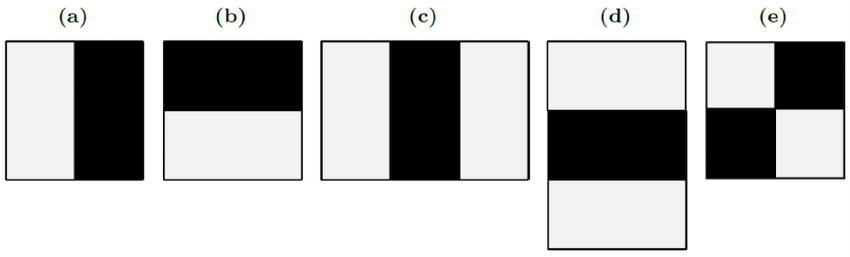
اینک که ویژگیها گزینش شدهاند، آنها را با استفاده از طبقهبندی Adaboost روی مجموعهای از تصاویر آموزشی اعمال میکنیم. بدین ترتیب مجموعهای از طبقهبندیهای ضعیف با هم ترکیب میشود تا یک مدل گروهی دقیق را تشکیل دهند. با استفاده از 200 ویژگی (به جای 160،000 ویژگی اولیه) میزان دقتی برابر با 95% به دست میآید. ما در این نوشته از 6000 ویژگی استفاده کردهایم.
تصویر یکپارچه
محاسبه ویژگیهای مستطیلی به سبک کرنل کانولوشنی، ممکن است مدت زمان بسیار زیادی طول بکشد. به همین دلیل طراحان اولیه این روش Viola و Jones یک بازنمایی میانجی از تصویر را پیشنهاد کردهاند که آن را تصویر یکپارچه مینامند. نقش تصویر یکپارچه این است که امکان محاسبه مجموع هر مستطیلی را به سادگی با استفاده از تنها چهار ویژگی فراهم میکند.
فرض کنید میخواهیم ویژگیهای مستطیلی را در یک پیکسل مفروض با مختصات x و y محاسبه کنیم. سپس تصویر یکپارچه پیکسل را در مجموع پیکسلهای سمت بالا و سمت چپ پیکسل محاسبه میکنیم:
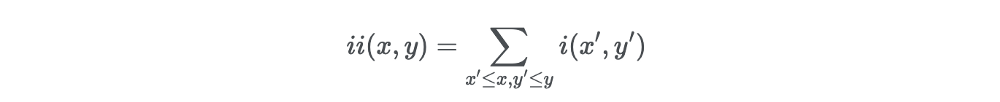
در فرمول فوق (ii(x،y تصویر یکپارچه و (i(x،y تصویر اصلی است.
زمانی که تصویر یکپارچه به صورت کامل محاسبه شد، یک رابطه بازگشتی وجود دارد که یک بار روی تصویر اصلی اعمال میشود. در واقع میتوانیم جفت روابط بازگشتی زیر را تعریف کنیم:
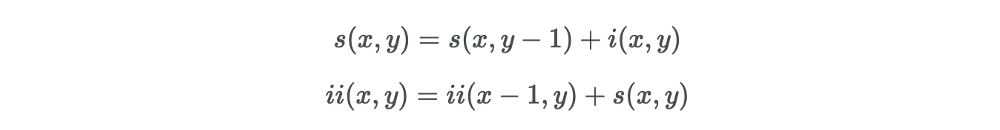
که (s(x،y مجموع ردیف تجمعی و s(x−1)=0، ii(−1،y)=0 است.
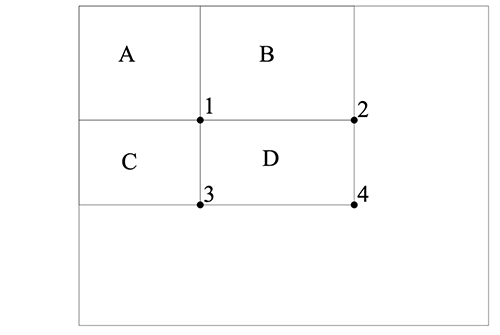
این رابطه چه فایدهای دارد؟ تصور کنید ناحیه D وجود دارد که در آن میخواهیم مجموع پیکسلها را محاسبه کنیم. ما سه ناحیه دیگر را نیز به صورت A ،B و C تعریف کردهایم.
- مقدار تصویر اصلی در نقطه 1 برابر با مجموعه پیکسلها در مستطیل A است.
- مقدار مربوطه در نقطه 2 برابر با A + B است.
- مقدار مربوطه در نقطه 3 برابر با A + C است.
- مقدار مربوطه در نقطه 4 برابر با A + B + C + D است.
از این رو مجموع پیکسلها در ناحیه D را میتوان با استفاده از فرمول زیر محاسبه کرد:
4+1−(2+3)
با استفاده از یک گذر میتوان مقدار درون یک مستطیل را با استفاده از تنها 4 ارجاع آرایهای محاسبه کرد:
باید بدانید که مستطیلها عملاً ویژگیهای کاملاً سادهای هستند، اما اهمیت زیادی در تشخیص چهره دارند. فیلترهای Steerable هنگامی که با مسائل پیچیده سر و کار داریم، انعطافپذیری بیشتری دارند.
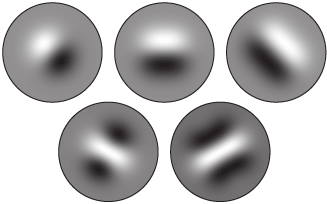
یادگیری تابع طبقهبندی با استفاده از Adaboost
با فرض وجود یک مجموعه برچسب خورده از تصاویر آموزشی (مثبت یا منفی) Adaboost به صورت زیر مورد استفاده قرار میگیرد:
- یک مجموعه کوچک از ویژگیها را انتخاب کنید.
- الگوریتم طبقهبندی را آموزش دهید.
از آنجا که اغلب ویژگیها در میان 160،000 ویژگی نامرتبط تصور شدهاند؛ الگوریتم یادگیری ضعیف که با استفاده از مدل boosting ساختیم طوری طراحی شده است که ویژگی مستطیلی منفردی را انتخاب کند که مثالهای مثبت و منفی را به بهترین روش از هم جدا میکند.
طبقهبندی آبشاری
با این که فرایند توصیف شده فوق کاملاً کارآمد است، اما هنوز یک مشکل عمده بر سر راه آن پابرجا است. در یک تصویر اغلب بخشها را قسمتهای غیر از چهره تشکیل میدهند. دادن اهمیت یکسان به همه بخشهای چنین تصویری بیمعنی است، چون باید تمرکز عمده روی ناحیهای باشد که احتمال وجود چهره بیشتر است. Viola و Jones در روش خود به نرخ شناسایی بالایی دست یافتند و در عین حال زمان محاسبه را با استفاده از طبقهبندیهای آبشاری کاهش دادند.
ایده اصلی این بوده است که آن پنجرههای فرعی را که شامل چهره نیستند رد کنند و در عین حال مناطقی که چنین خصوصیتی را دارند حفظ نمایند. از آنجا که وظیفه ما شناسایی مناسب چهره بوده است، میخواهیم نرخ تشخیص منفی نادرست، یعنی موادی که شامل چهره بودهاند، اما چنین شناسایی نشدهاند را کاهش دهیم.
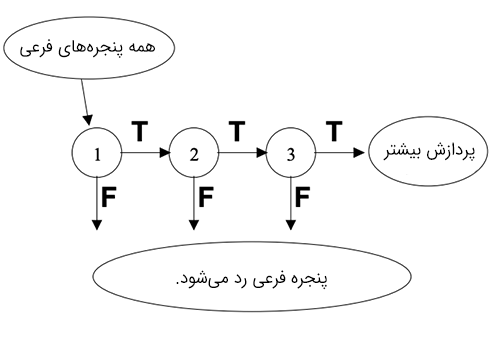
یک سری از طبقهبندیها روی هر پنجره فرعی اعمال میشوند. این طبقهبندیها درختهای تصمیم سادهای هستند:
- اگر طبقهبندی نخست مثبت باشد، به طبقهبندی دوم میرویم.
- اگر طبقهبندی دوم مثبت باشد، به طبقهبندی سوم میرویم.
- و همین طور تا آخر.
هر نتیجه منفی در یک نقطه، منتهی به رد پنجره فرعی میشود که احتمالاً شامل یک چهره است. طبقهبندی اول اغلب مثالهای منفی را با هزینه محاسباتی پایین کاهش میدهد و طبقهبندیهای بعدی مثالهای منفی بعدی را که هزینه بالاتری دارند با استفاده از توان محاسباتی بالاتر حذف میکنند.
طبقهبندیها با استفاده از Adaboost آموزش داده میشوند و حد آستانه طوری تعیین میشود که نرخ تشخیص نادرست کمینه شود. زمانی که چنین مدلی را آموزش میدهیم، متغیرها به صورت زیر هستند:
- تعداد مراحل طبقهبندی
- تعداد ویژگیها در هر مرحله
- حد آستانه در هر مرحله
خوشبختانه در OpenCV، کل مدل از قبل برای تشخیص چهره تعلیم یافته است.
ایمپورتها
مرحله بعدی این است که وزنهای از قبل آموزشیافته را مکانیابی کنیم. ما از مدلهای از پیش آموزشدیده برای تشخیص چهره، چشمها و دهان استفاده خواهیم کرد. بسته به این که از چه نسخهای از پایتون استفاده میکنید فایلهای مربوطه باید در چنین مکانهایی باشند:
/usr/local/lib/python3.7/site-packages/cv2/data
الگوریتمهای طبقهبندی آبشاری را به روش زیر اعلان میکنیم:
cascPath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml" eyePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_eye.xml" smilePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_smile.xml" faceCascade = cv2.CascadeClassifier(cascPath) eyeCascade = cv2.CascadeClassifier(eyePath) smileCascade = cv2.CascadeClassifier(smilePath)
تشخیص چهره روی یک تصویر
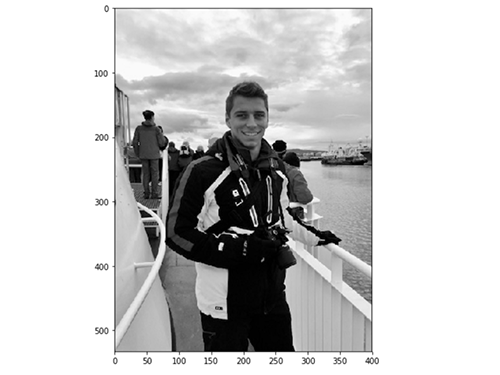
پیش از پیادهسازی یک الگوریتم تشخیص چهره واقعی، نسخه سادهای از آن را روی یک تصویر ساده به کار میگیریم. کار خود را با بارگذاری یک تصویر تست آغاز میکنیم:
سپس چهره را تشخیص داده و یک مستطیل پیرامون آن اضافه میکنیم:
در ادامه فهرستی از پارامترهای مشترک را برای تابع detectMultiScale مشاهده میکنید:
- scaleFactor: پارامتری است که میزان کاهش اندازه تصویر را در هر مقیاسبندی تصویر تعیین میکند.
- minNeighbors: این پارامتر تعداد همسایگیهای هر مستطیل نامزد که باید حفظ شوند را تعیین میکند.
- minSize: کمینه اندازه ممکن برای شیء است. شیءهای کوچکتر از آن نادیده گرفته میشوند.
- maxSize: بیشینه ممکن برای اندازه شیء است. شیءهای بزرگتر از آن نادیده گرفته میشوند.
در نهایت نتیجه نمایش پیدا میکند:
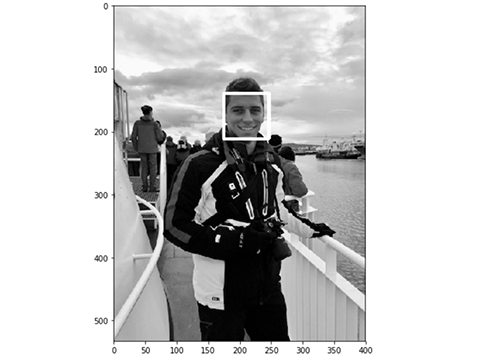
چنان که مشاهده میکنید، تشخیص چهره روی تصویر تست ما به خوبی عمل کرده است. در ادامه آن را به صورت عملکرد همزمان (آنی) تست میکنیم.
تشخیص چهره آنی
در این بخش پیادهسازی تشخیص چهره زنده را در پایتون بررسی خواهیم کرد. نخستین گام باز کردن دوربین و دریافت ویدئو است. سپس تصویر را به یک تصویر خاکستری تبدیل میکنیم. این کار برای کاهش ابعاد تصویر ورودی صورت میگیرد. در واقع به جای 2 نقطه برای هر پیکسل که با رنگهای قرمز، سبز و آبی توصیف میشوند، یک تبدیل خطی ساده استفاده میشود:

این وضعیت به صورت پیشفرض در OpenCV پیادهسازی شده است:
اینک از متغیر faceCascade که در بخش قبلی تعریف کردیم استفاده میکنیم. این متغیر شامل یک الگوریتم از پیش آموزشدیده است و آن را روی یک تصویر خاکستری اعمال میکنیم.
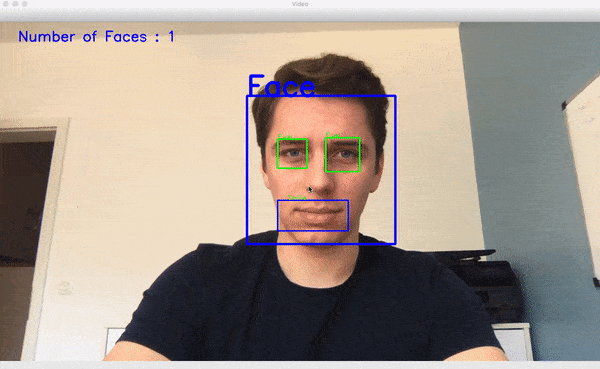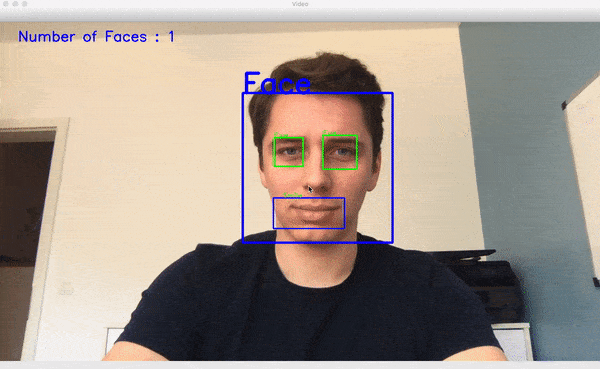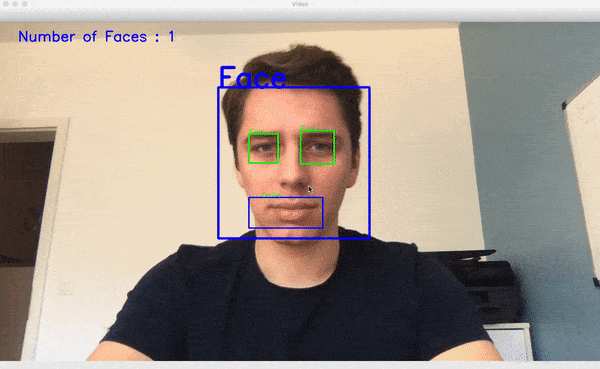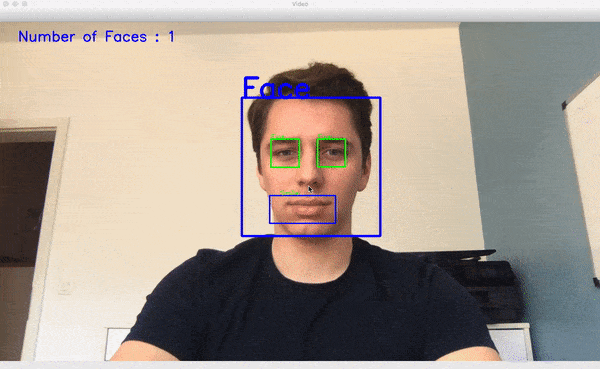
برای هر چهرهای که تشخیص داده شود، یک مستطیل پیرامون چهره ترسیم میشود:
در مورد هر دهان که تشخیص داده میشود نیز یک مستطیل پیرامون آن رسم میشود:
همچنین برای هر چشم شناسایی شده یک مستطیل در پیرامونش ترسیم میشود:
سپس تعداد کل چهرهها شمارش شده و تصویر نهایی نمایش پیدا میکند:
زمانی که میخواهیم از دوربین خارج شویم یک گزینه خروج نیز پیادهسازی میکنیم تا با ارسال حرف q فعال شود:
در نهایت هنگامی که همه کارها انجام یافت، دریافت ویدئو قطع میشود و همه پنجرهها بسته میشوند. البته بستن پنجرهها در سیستم Mac با برخی مشکلات مواجه میشود که ممکن است نیازمند توقف پردازش پایتون در Activity Manager باشد:
جمعبندی
کد کامل ما اینک به صورت زیر است:
نتایج
در ویدئوی کوتاه زیر عملکرد پیادهسازی تشخیص چهره ما را مشاهده میکنید:
هیستوگرام گرادیانهای جهتدار (HOG) در Dlib
دومین پیادهسازی محبوب برای تشخیص چهره از سوی Dlib ارائه شده و از مفهومی به نام هیستوگرام گرادیانهای جهتدار (HOG) بهره میگیرد. در این بخش به پیادهسازی روش اصلی پیشنهاد شده در مقاله Dalal و Triggs (+) میپردازیم.
نظریه
ایدهای که در پشت HOG قرار دارد این است که میتوان ویژگیها را به صورت یک بردار استخراج کرد و آن را به یک الگوریتم طبقهبندی، برای مثال ماشین بردار پشتیبانی داد که ارزیابی کند آیا یک چهره (یا هر چیز دیگر که برای شناساییاش تعلیم دیده است) در آن ناحیه وجود دارد یا نه.
ویژگیهای استخراج شده، توزیعها (هیستوگرامها)-ی جهتگیری گرادیانها (یا گرادیانهای جهتدار) از تصویر هستند. گرادیانها عموماً در بخشهای لبه و گوشه، مقادیر بالایی دارند و بدین ترتیب به ما امکان میدهند که آن نواحی را تشخیص دهیم.
در مقاله اصلی، فرایند کار برای تشخیص بدن انسان به صورت زیر پیادهسازی شده است و زنجیره تشخیص به شرح زیر است:

پیشپردازش
قبل از هر چیز، تصاویر ورودی باید هماندازه باشند. از این رو برش و تغییر مقیاس لازم است. وصلههایی که ما در این مقاله استفاده میکنیم، دارای نسبت 1:2 هستند و از این رو ابعاد تصاویر ورودی باید برای نمونه 64 در 128 یا 100 در 200 باشد.
محاسبه تصاویر گرادیان
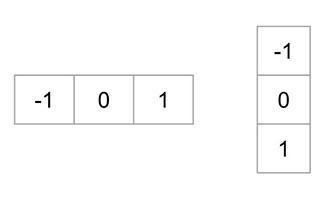
نخستین گام، محاسبه گرادیانهای افقی و عمودی تصویر از طریق بهکارگیری کرنلهای زیر است:
گرادیان یک تصویر عموماً اطلاعات غیرضروری را حذف میکند. گرادیان تصویری که در بخش فوق در نظر گرفتیم را میتوان در پایتون به صورت زیر به دست آورد:
شکل را به صورت زیر رسم میکنیم:

با این حال ما تصویر را پیشپردازش نکردهایم.
محاسبه HOG
در ادامه تصویر به سلولهای 8 در 8 تقسیم میشود تا یک بازنمایی فشرده ایجاد شود و HOG در برابر نویز مقاومت بیشتری بیابد. سپس HOG را برای هریک از این سلولها محاسبه میکنیم.
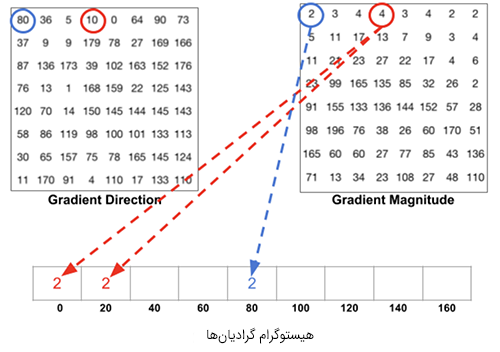
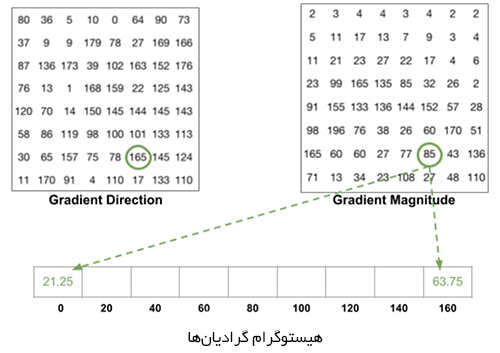
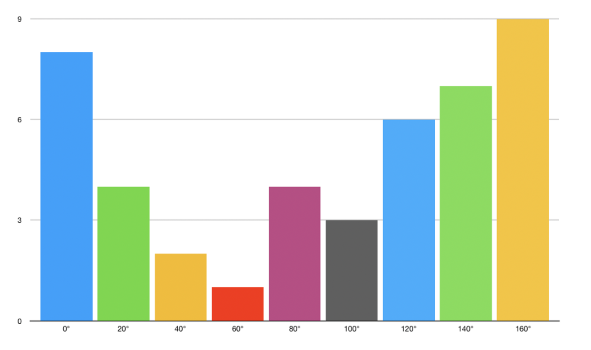
برای تخمین جهت گرادیان درون ناحیه، یک هیستوگرام میان 64 مقدار از جهتگیریهای گرادیان (8 در 8) میسازیم و بزرگی آنها (64 مقدار دیگر) درون هر ناحیه را نیز محاسبه میکنیم. دستههای هیستوگرام با زوایای گرادیان از 0 تا 180 درجه مرتبط هستند. در مجموع 9 دسته به صورت 0، 20، 40،… و 160 درجه وجود دارند.
کد فوق دو نوع اطلاعات را در اختیار ما قرار میدهد:
- جهت گرادیان
- بزرگی گرادیان
زمانی که HOG را میسازیم، 3 حالت فرعی وجود دارد:
- زاویه کمتر از 160 درجه باشد و در نیمه بین 2 طبقه قرار نگرفته باشد. در چنین مواردی، این زاویه در دسته مناسب HOG اضافه میشود.
- زاویه کمتر از 60 درجه باشد و دقیقاً بین دو طبقه قرار بگیرد. در چنین حالتی یک مشارکت برابر بین دو طبقه مجاور تصور کرده و بزرگی را به 2 بخش تقسیم میکنیم.
- زاویه بزرگتر از 160 درجه باشد. در چنین حالتهایی تصور میکنیم که آن پیکسل به صورت قائم بر 160 و تا 0 درجه مشارکت دارد.
HOG برای هر سلول 8 در 8 به صورت زیر به دست میآید:
نرمالسازی بلوک
در نهایت، یک بلوک 16 در 16 را میتوان برای نرمالسازی تصویر و برای مثال حذف تأثیر نوردهی اعمال کرد. این نتیجه به سادگی با تقسیم کردن هر مقدار HOG با اندازه 8 در 8 بر L2-norm مربوط به بلوک HOG 16 در 16 که شامل آن است صورت میگیرد. در واقع این یک بردار ساده با طول 9*4 = 36 است.
در نهایت همه بردارهای 36 در 1 در یک بردار بزرگ تجمیع میشوند و کار به پایان میرسد. بدین ترتیب بردار ویژگی به دست میآید و با استفاده از آن میتوان یک الگوریتم طبقهبندی SVM نرم (C=0.01) را آموزش داد.
تشخیص چهره روی یک تصویر
پیادهسازی این روش کاملاً سر راست است:
تشخیص چهره آنی
همانند روش قبلی، پیادهسازی آنی این الگوریتم نیز آسان است. ما یک نسخه سبکتر از آن را که تنها چهره را تشخیص میدهد را پیادهسازی کردهایم. Dlib شناسایی نقاط کلیدی چهره را نیز به صورت کاملاً ساده اجرا میکند که البته بررسی آن خارج از حیطه این مقاله است:
شبکه عصبی کانولوشنی در Dlib
آخرین روش که در این مقاله برای تشخیص چهره بررسی میکنیم مبتنی بر شبکههای عصبی کانولوشنی (CNN) است. برای پیادهسازی این روش از نتایج این مقاله (+) در مورد شناسایی شیء (Max-Margin (MMOD بهره جستهایم.
اندکی از نظریه روش
شبکههای عصبی کانولوشنی (CNN) شبکههای عصبی پیشخور (feed-forward) هستند که به طور عمده برای بینایی ماشین استفاده میشوند. این شبکهها یک پیش-آموزش خودکار را نیز همراه با بخش شبکه عصبی فشرده ارائه میکنند. CNN-ها انواع خاصی از شبکههای عصبی برای پردازش دادهها با فناوری شبه grid هستند. معماری CNN از کورتکس بینایی جانداران الهام گرفته است.
در رویکردهای قبلی، بخش عمدهای از کار مربوط به انتخاب فیلترها برای ایجاد ویژگیهایی جهت استخراج بیشینه ممکن اطلاعات از تصاویر بوده است. با ظهور یادگیری عمیق و ظرفیتهای محاسباتی بالاتر این کار اکنون به صورت خودکار صورت میگیرد. نام CNN از این واقعیت ناشی میشود که ورودی تصویر اولیه با یک مجموعه از فیلترها پیچش (convolve) مییابد. پارامتری که باید انتخاب کرد، تعداد فیلترهایی که باید اعمال شوند و ابعاد فیلترها است. بُعد فیلتر به نام طول stride نامیده میشود. مقادیر معمول برای این stride بین 2 و 5 هستند:
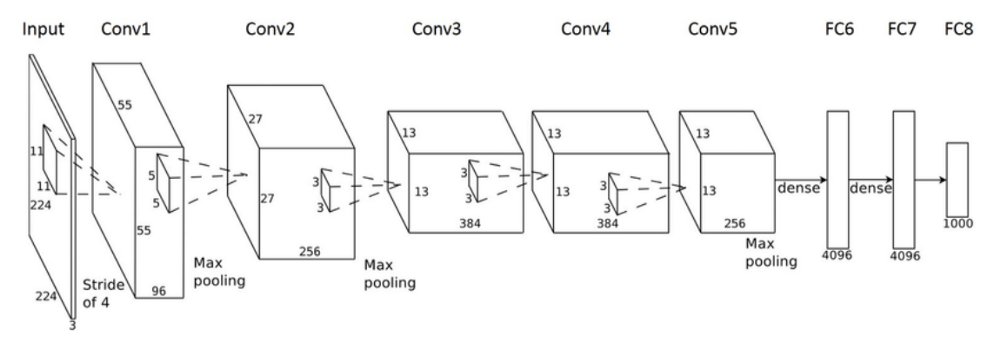
خروجی CNN در این مورد خاص یک طبقهبندی باینری است که در صورت وجود چهره مقدار 1 و در غیر این صورت مقدار 0 میگیرد.
تشخیص چهره روی یک تصویر
برخی اجزای این رویکرد در پیادهسازی تغییر مییابند. نخستین گام، دانلود کردن مدل از پیش آموزشدیده (+) است. وزنها را به پوشه خود منتقل و dnnDaceDetector را تعریف کنید:
dnnFaceDetector = dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat")سپس مشابه روشی که تا به اینجا عمل کردیم پیش میرویم:

تشخیص چهره آنی
در نهایت نسخه آنی تشخیص چهره CNN را پیادهسازی خواهیم کرد:
کدام روش را باید انتخاب کرد؟
سؤال دشواری است و برای پاسخ به آن باید دو معیار مهم زیر را در نظر گرفت:
- زمان محاسبات
- دقت
اگر سرعت را معیار قرار دهیم، HoG سریعترین الگوریتم به نظر میرسد و سپس طبقهبندی آبشار Haar و CNN قرار دارند.
با این حال، CNN-ها و Dlib دقیقترین الگوریتمها هستند. HoG نیز عملکرد خوبی دارد، اما مشکلاتی در شناسایی چهرههای کوچک دارد. طبقهبندی HaarCascade نیز به خوبی HoG عمل میکند. اگر میخواهید تشخیص سریعی در ویدئوهای زنده خود داشته باشید پیشنهاد میکنیم از روش HoG استفاده کنید.
منبع: فرادرس
تحلیل شبکه های اجتماعی با R — به زبان ساده
تحلیل شبکه های اجتماعی یکی از مباحث داغ روز است که در این مطلب به طور کامل به آن پرداخته خواهد شد. از زمان پیداش «شبکههای اجتماعی برخط» (Online Social Networks | OSN) تاکنون، جمعیت کاربران این شبکهها روز به روز افزایش مییابد. بر اساس آخرین گزارش «دیجیتال ۲۰۱۹» (Digital 2019) که توسط «هوتسوئیت» (Hootsuite) ارائه شده است (این گزارش ۲۲۱ صفحهای، چشماندازی دقیق از وضعیت استفاده از وب و به طور خاص شبکههای اجتماعی ارائه میکند)، در سال ۲۰۱۹، اینترنت از سراسر جهان ۴.۳۸۸ میلیارد کاربر (نفوذ ٪۵۷) دارد و نسبت به سال گذشته، رشد ٪۹.۱ داشته است. شایان توجه است که جمعیت کل جهان، ۷.۶۷۶ میلیارد نفر است.
همچنین، تعداد کاربران شبکههای اجتماعی در سال ۲۰۱۹ برابر با ۳.۴۸۴ میلیارد (نفوذ ٪۴۵) گزارش شده که نسبت به سال گذشته ٪۹ رشد داشته است. تعداد کاربران تلفن همراه در سال ۲۰۱۹، برابر با ۵.۱۱۲ میلیارد است که رشد ٪۲ نسبت به سال گذشته از خود نشان میدهد. در این میان، تعداد کاربران شبکههای اجتماعی موبایل، ۳.۲۵۶ میلیارد نفر (نفوذ ٪۴۲) است.

از سوی دیگر، مدت زمانی که افراد برای حضور در شبکههای اجتماعی صرف میکنند رشد قابل توجهی داشته و به نوعی میتوان گفت این روزها، شبکههای اجتماعی همیشه و همه جا همراه افراد هستند و بخش قابل توجهی از زندگی آنها را شامل میشوند. با توجه به همین آمار و ارقام و حجم محتوایی که هر روز افراد در شبکههای اجتماعی برخط تولید کرده و به اشتراک میگذارند، مبحثی جدید با عنوان تحلیل شبکه های اجتماعی شکل گرفته است.
در این مطلب، آموزش تحلیل شبکه های اجتماعی با R ارائه شده است. البته به منظور درک هر چه بهتر مطلب، ابتدا مفهوم شبکه اجتماعی و دلایل نیاز به تحلیل شبکه های اجتماعی بیان شده، فرصتهای شغلی این حوزه مورد بررسی قرار گرفته و سپس، به چگونگی انجام تحلیل شبکه های اجتماعی با R پرداخته شده است. در نهایت، منابع آموزشی مفید برای فراگیری کامل و تسلط بر این مبحث، ارائه شدهاند.
شبکه اجتماعی چیست؟
یک تعریف ساده و کوتاه قابل ارائه از شبکههای اجتماعی این است: «شبکه اجتماعی، ساختاری متشکل از افراد (یا سازمانها) است». به بیان جامعتر، شبکه اجتماعی ساختاری متشکل از بازیگران شبکه (افراد یا سازمانها) و روابط میان آنها است.
در واقع، یک شبکه اجتماعی را میتوان به صورت یک «گراف» (Graph) در نظر گرفت که در آن، بازیگران شبکه همان «گرههای» (Nodes) گراف و روابط میان آنها «یالهای» (Edges) گراف است. قدمت شبکههای اجتماعی به تشکیل اولین اجتماعات انسانی باز میگردد. یک خانواده، فامیل، سازمان و حتی مدرسه، به دید سنتی یک شبکه اجتماعی محسوب میشود. در واقع، انواع گوناگونی از روابط میتواند میان بازیگران یک شبکه اجتماعی برقرار باشد.

جنس جدیدی از شبکههای اجتماعی با ظهور وب ۲.۰ ایجاد شدند. «شبکههای اجتماعی برخط» (Online Social Networks)، نوعی از شبکههای اجتماعی مبتنی بر وب هستند. این شبکههای اجتماعی انواع گوناگونی دارند که میتوان به شبکههای اجتماعی به اشتراکگذاری ویدئو، صوت، متن و شبکههای اجتماعی ترکیبی که انواع محتوا را میتوان در آن به اشتراک گذاشت اشاره کرد.
هرچند، در حال حاضر اغلب شبکههای اجتماعی با وجود آنکه برای هدف خاصی طراحی شدهاند، معمولا امکان به اشتراکگذاری چند نوع محتوا را به طور همزمان به کاربر میدهند و هر بار در گذر زمان، از قابلیتهای جدیدی در این راستا، بهرهبرداری میکنند. از جمله معروفترین و محبوبترین شبکههای اجتماعی برخط، میتوان به «فیسبوک» (Facebook)، «یوتیوب» (YouTube)، واتساپ (WhatsApp)، «ویچت» (WeChat)، «اینستاگرام» (Instagram)، «توییتر» (Twitter) و «لینکدین» (Linkedin) اشاره کرد. نکته شایان توجه این است که در حال حاضر از عبارت شبکههای اجتماعی معمولا برای اشاره به شبکههای اجتماعی برخط استفاده میشود و کمتر پیش میآید که با بیان شبکه اجتماعی شکل سنتی آن مد نظر باشد.
تحلیل شبکه های اجتماعی چیست و چرا به آن نیاز است؟
همانطور که پیش از این اشاره شد، مفهوم شبکههای اجتماعی به اولین اجتماعات انسانی شکل گرفته توسط بشر باز میگردد و مفهوم کنونی شبکه اجتماعی که در واقع منظور از آن، شبکه اجتماعی برخط است، با ظهور وب ۲.۰ ایجاد شد. اولین رشتههای تحلیل اجتماعات انسانی نیز به تلاشهای جامعهشناسان اولیه مانند «گئورگ زیمل» (Georg Simmel) و «امیل دورکیم» (Émile Durkheim) مربوط میشود که مطالعات و آثار مکتوبی را پیرامون الگوهای روابطی که بازیگران شبکههای اجتماعی را به یکدیگر متصل میکند دارند. در سال ۱۹۳۰ بود که «جاکوب مورنو» (Jacob L. Moreno) و «هلن جنگینز» (Helen Jennings) روشهای تحلیلی پایهای را برای شبکههای اجتماعی معرفی کردند.
در ابتدای قرن بیستم، برخی از جامعهشناسان، از عبارت «شبکه اجتماعی» برای اشاره به روابط پیچیده بین اعضای اجتماعات انسانی در ابعاد شخصی و بین فردی گرفته تا بینالمللی استفاده کردند. در واقع میتوان گفت، «تحلیل شبکه های اجتماعی» (Online Social Network Analysis | OSNA | SNA)، استراتژی برای بررسی شبکههای اجتماعی است. تحلیل شبکههای اجتماعی به دو صورت «ساختاری» (Structural) و «رفتاری» (Behavioral) انجام میشود. در تحلیل ساختاری، گراف ساختاری یک شبکه اجتماعی (شامل گرهها و یالها) مورد بررسی قرار میگیرد.

در تحلیل رفتاری، رفتار کاربر در یک شبکه اجتماعی، شامل محتوایی که به اشتراک میگذارد، زمانهای فعالیت و برخی از دیگر موارد، مورد بررسی قرار میگیرد. یکی از وظایف اصلی که در تحلیل رفتاری شبکههای اجتماعی معمولا انجام میشود، «متنکاوی» (Text Mining)است. برای مثال، توییتهای ارسالی کاربران فارسی زبان در یک شبکه اجتماعی مانند توییتر، در یک بازه زمانی مشخص گردآوری میشوند و با استفاده از روشهای متنکاوی، «تحلیل احساسات» (Sentimental Analysis) که به آن عقیدهکاوی (Opinion Mining) یا تحلیل عواطف نیز گفته میشود، تحلیل عواطف کاربران در جهت تشخیص حسابهای کاربری که به «نفرت پراکنی» (Hate Speech)میپردازند انجام میشود (البته برخی از دانشمندان، تفاوتهای ظریفی بین تحلیل احساست و عقیدهکاوی بر میشمارند).
با توجه به آمارهای ارائه شده در ابتدای این مطلب، به خوبی مشهود است که جهان کنونی، جهانی متشکل از ساختارهای اجتماعی شکل گرفته در وب و در واقع دنیای شبکههای اجتماعی برخط است. افراد حاضر در شبکه، احساسات، عقاید، خواستهها، اخبار و مسائل گوناگون را به صورت آنی با یکدیگر به اشتراک میگذارند. این یعنی، یک بایگانی عظیم و به وسعت جهان از دادههای افراد گوناگون که با تحلیل آنها میتوان به دانشی فوقالعاده در راستای شناخت بشر و دنیای انسانی دست یافت. چنین شناختی میتواند در راستای اهداف گوناگون، از جمله موارد زیر مفید واقع شود.
- شناسایی فعالیتهای مجرمانه در شبکههای اجتماعی (شامل گروهکها و ترولها)
- انجام بازاریابی دیجیتال هدفمند و قدرتمند با شناخت دقیق مشتریان
- بهبود فرایند ارتباط با مشتریان از طریق شبکههای اجتماعی
- ساخت سیستمهای توصیهگر (برای کالا و خدمات و یا دیگر انواع سیستمهای توصیهگر)
- ساخت موتورهای جستجوی مبتنی بر نظرات کاربران
- استفاده از دانش حاصل شده از تحلیل شبکه های اجتماعی در راستای اهداف «هوش تجاری» (Business Intelligence)
- کمک به بهبود تصمیمسازی در کسب و کارها و یا سازمانهای گوناگون دولتی و نهادهای نظارتی و امنیتی
- پیشبینی نتایج به ویژه در انتخاباتها
- کشف موضوعات نوظهور و گرایشهای موضوعی
نمونهای از قدرت تحلیل شبکههای اجتماعی و استفاده از دانش حاصل شده از آن جهت دستیابی به اهداف گوناگون را میتوان در ماجرای «کمبریج آنالیتیکا» (Cambridge Analytica) و فیس بوک و تاثیر به سزایی که گفته میشود در انتخابات آمریکا داشته است مشاهده کرد.
فرصتهای شغلی در زمینه تحلیل شبکه های اجتماعی
با توجه به نقش مهمی که شبکههای اجتماعی در تدوین استراتژیهای کسب و کارها در حال حاضر دارند، و تاثیر به سزایی که دانش حاصل از تحلیل شبکه های اجتماعی در حوزههای گوناگون داشته است، فرصتهای شغلی متعدد با درآمد خوب برای کارشناسان این حوزه وجود دارد. تحلیلگران شبکههای اجتماعی میتوانند تا حتی ۱۱۰,۰۰۰ دلار در سال حقوق دریافت کنند. انتظار میرود تعداد فرصتهای شغلی این حوزه با توجه به رشد روزافزون ضریب نفوذ شبکههای اجتماعی، افزایش پیدا کند.

تحلیل شبکه های اجتماعی چگونه انجام میشود؟
همانطور که پیش تر بیان شد، تحلیل شبکه های اجتماعی به دو شکل ساختاری (بر اساس گراف شبکه) و رفتاری (محتوای به اشتراک گذاشته شده توسط کاربر و رفتار کاربر در شبکه مانند ساعات حضور و به اشتراکگذاری محتوا) انجام میشود. هر یک از این دو نوع تحلیل، اصول و روشهای خاص خود را دارند. برای مثال، در تحلیل ساختاری، نیاز به تسلط بر مباحث زیر وجود دارد:
- مفاهیم نظریه گرافها
- مفاهیم بنیادین پیرامون ساختار شبکههای اجتماعی مانند «شبکههای اگو» (Ego Networks) و «شبکههای سراسری» (Global Networks)
- سنجههای اختصاصی ساختارهای شبکههای اجتماعی ( که سه دسته اصلی آن عبارتند از «ارتباطات» (Connections)، «توزیعها» (Distributions) و «بخشبندی» (Segmentation))
- دیگر مباحث این حوزه مانند انواع ساختارهای ناهنجار در شبکه (ستارهای، گروهک و شبه گروهک)
در تحلیل رفتاری، یکی از مرسومترین راهکارها استفاده از محتوای متنی به اشتراک گذاشته شده توسط کاربر است. بدین معنا که برای مثال متن توییتها، پستهای فیسبوک و یا کپشنهای پستهای اینستاگرام را گردآوری و تحلیل میکنند. بدین منظور، کاربر نیاز به آشنایی با مفاهیم متنکاوی و ابزارهای آن دارد.
تحلیل شبکه های اجتماعی با زبان برنامه نویسی R
برای پیادهسازی تحلیل شبکه های اجتماعی میتوان از ابزارهای ویژه این حوزه استفاده کرد. از جمله این ابزارها، زبانهای برنامهنویسی R و «پایتون» (Python) هستند. R یک زبان محاسباتی قدرتمند است که در ابتدا به طور ویژه برای محاسبات آماری به کار میرفت. اما در گذر زمان و با توسعه «بستههای» (Packages) این زبان برای «علم داده» (Data Science)، «یادگیری ماشین» (Machine Learning) و به طور خاص «متنکاوی» (Text Mining) استفاده از این زبان برای انجام تحلیل شبکههای اجتماعی نیز رواج یافت. نمونهای از پروژههای تحلیل شبکه های اجتماعی با R را میتوان در مطلب «تحلیل احساسات در توییتر با زبان R — راهنمای کاربردی» و «تحلیل ترافیک شهری با استفاده از شبکههای اجتماعی و R — راهنمای کاربردی» مشاهده کرد.

جمعبندی
تحلیل شبکههای اجتماعی به اشکال گوناگون و با اهداف متنوعی صورت میپذیرد. به منظور انجام تحلیل شبکه های اجتماعی، کاربر نیاز به آشنایی با مفاهیم این حوزه، مباحث دادهکاوی و متنکاوی و همچنین یک ابزار مانند زبان برنامهنویسی R دارد. به علاقهمندان یادگیری تحلیل شبکه های اجتماعی، مشاهده دوره آموزش ویدئویی آموزش تحلیل شبکه های اجتماعی با زبان R و متن کاوی که به زبان فارسی تهیه شده و مدت زمان آن ۷ ساعت و ۲۵ دقیقه است، توصیه میشود.
منبع: فرادرس
حلقه while و do…while در ++C — راهنمای کاربردی
حلقهها در برنامهنویسی برای تکرار یک بلوک خاص از کد استفاده میشوند. در این مقاله با روش ایجاد حلقه while و do…while در ++C آشنا خواهیم شد. در برنامهنویسی رایانه، حلقه برای تکرار یک بلوک کد تا زمانی که شرط خاصی برقرار شود، مورد استفاده قرار میگیرد. در زبان برنامهنویسی ++C، سه نوع حلقه وجود دارند:
- حلقه for
- حلقه while
- حلقه do…while
برای مطالعه قسمت قبلی این مجموعه مطلب آموزشی میتوانید به پست حلقه for در زبان برنامه نویسی ++C — به زبان ساده مراجعه کنید.
حلقه while در ++C
ساختار این حلقه به صورت زیر است:
که در آن testExpression روی هر مدخل حلقه while بررسی میشود.
حلقه while چگونه کار میکند؟
- حلقه while عبارت تست را ارزیابی میکند.
- اگر عبارت تست درست باشد، کد درون بدنه حلقه while مورد ارزیابی قرار میگیرد.
- سپس عبارت تست مجدداً ارزیابی میشود. این فرایند تا زمانی که عبارت تست نادرست شود ادامه مییابد.
- هنگامی که عبارت تست نادرست شود، حلقه while خاتمه مییابد.
فلوچارت حلقه while

مثال 1: حلقه while در ++C
خروجی
Enter a positive integer: 4 Factorial of 4 = 24
در این برنامه از کاربر تقاضا میشود که یک عدد صحیح مثبت وارد کند که در متغیر number ذخیره میشود. فرض کنید کاربر مقدار 4 را وارد کند.
سپس حلقه while شروع به اجرای کد میکند. طرز کار حلقه while به صورت زیر است:
- در ابتدا i=1 است و عبارت تست یعنی i <= number درست است، از این رو مقدار فاکتوریل برابر با 1 خواهد بود.
- عبارت i به مقدار 2 بهروزرسانی میشود، عبارت تست true است، مقدار فاکتوریل برابر با 2 میشود.
- عبارت i به مقدار 3 بهروزرسانی میشود، عبارت تست true است، مقدار فاکتوریل برابر با 6 میشود.
- عبارت i به مقدار 4 بهروزرسانی میشود، عبارت تست true است، مقدار فاکتوریل برابر با 24 میشود.
- عبارت i به مقدار 5 بهروزرسانی میشود، عبارت تست false میشود و حلقه خاتمه مییابد.
حلقه do…while در ++C
حلقه do…while نوع دیگری از حلقه while است که یک تفاوت مهم با آن دارد. بدنه حلقه do…while پیش از بررسی عبارت تست، یک بار اجرا خواهد شد.
ساختار حلقه do…while به صورت زیر است:
طرز کار حلقه do…while چگونه است؟
- کدهای درون بدنه حلقه دستکم یک بار اجرا میشوند. سپس تنها عبارت تست بررسی میشود.
- اگر عبارت تست درست باشد، بدنه حلقه اجرا میشود. این فرایند تا زمانی ادامه مییابد که عبارت نادرست شود.
- هنگامی که عبارت تست نادرست باشد، حلقه do…while خاتمه مییابد.
فلوچارت حلقه do…while

مثال 2: حلقه do…while در ++C
خروجی
Enter a number: 2 Enter a number: 3 Enter a number: 4 Enter a number: -4 Enter a number: 2 Enter a number: 4.4 Enter a number: 2 Enter a number: 0
بدین ترتیب به پایان این بخش از آموزش مفاهیم زبان برنامهنویسی ++C میرسیم.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید: