طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیساخت ابر برچسب در پایتون — به زبان ساده
در این مطلب، چگونگی انجام تحلیل اکتشافی دادهها برای «پردازش زبان طبیعی» (Natural Language Processing) با استفاده از «ابر برچسب» (Word Cloud) در «زبان برنامهنویسی پایتون» آموزش داده شده است. اما پیش از ارائه آموزش ساخت ابر برچسب در پایتون، باید دانست که ابر بچسب (با عنوان تگکلود یا کلودتگ هم از آن یاد میشود) چیست.
ابر برچسب چیست؟

بسیاری از مواقع، افراد با ابری که با کلمات متعدد در ابعاد گوناگون ترسیم شده، مواجه شدهاند. این ابر کلمات، تعداد تکرار یا اهمیت هر کلمه را نشان میدهد. به ابر کلمات مذکور، ابر برچسب یا «تگ کلود» (Tag Cloud) نیز میگویند. ابر برچسب ابزاری قدرتمند برای بصریسازی متن محسوب میشود که خواندن آنها آسان و درک آنها ساده است. ساخت ابر برچسب به شکل خاصی که مد نظر کاربر است، میتواند بصریسازی را حتی جذابتر هم بکند. در این راهنما، روش ساخت ابر برچسب در پایتون و چگونگی سفارشیسازی آن بیان شده است. ابر برچسب، ابزاری مفید برای اکتشاف دادهها و ساخت گزارشهای زندهتر است.
ساخت ابر برچسب در پایتون
ساخت ابر برچسب در پایتون طی چندین مرحله انجام میشود که در ادامه شرح داده شدهاند.
گام ۱
ابتدا، کتابخانههای پایتون مورد نیاز را باید «وارد» (ایمپورت) کرد.
نکته ۱: اگر پس از اجرای قطعه کد بالا، پیغام خطای «No module named ‘wordcloud» صادر شد، نیاز است که از دستور زیر، برای نصب wordcloud استفاده شود.
نکته ۲: اگر پیغام خطایی مربوط به کتابخانه تصویر پایتون (Python Imaging Library | PIL) صادر شد، باید به فایل زیر مراجعه کرد.
سپس، باید فایل Image.py را باز کرد و کد آن را که به صورت زیر است، به شکلی که در ادامه خواهد آمد تغییر داد.
کد بالا، باید به صورت کد زیر تغییر کند.
گام ۲
اکنون، وقت آن رسیده تا کاربر متنی که تمایل دارد برای رسم ابر برچسب خود استفاده کند را اضافه کند. در اینجا، از متنی که در زیر آمده و ارتباط به خانه و موضوعات مربوط به آن دارد، استفاده شده است.
گام ۳
برای آنکه ابر برچسب به شکل سفارشی و مورد نظر کاربر ساخته شود، باید تصویری که مد نظر دارد را مشخص کند تا به عنوان ماسک از آن استفاده شود. در این مطلب، از تصویری که در زیر آمده برای این کار استفاده شده و کدی که در ادامه میآید برای تعیین همین موضوع است.

گام ۴
تابع زیر، متن و ماسک (تصویر خانه) را دریافت میکند تا یه ابر برچسب سفارشیسازی شده بسازد.
از کد زیر میتوان برای فراخوانی تابع generate_wordcloud که در بالا ساخته شده، استفاده کرد.
کد نهایی باید به شکل زیر باشد.
کلون (Clone) کردن آرایه در جاوا اسکریپت — راهنمای مقدماتی
در جاوا اسکریپت برای انجام کارهای مختلف، روشهای گوناگونی وجود دارند. در این نوشته به روشهای متفاوتی میپردازیم که میتوان یک آرایه را در جاوا اسکریپت Clone کرد.
1. عملگر Spread (کپی سطحی)
از زمانی که استاندارد ES6 معرفی شده است؛ عملگر Spread پراستفادهترین گزینه محسوب میشود. این روش ساختار خلاصهای دارد و در مواردی که از کتابخانهای مانند React و Redux استفاده میکنید بسیار مفید خواهد بود:
نکته: در این روش امکان کپی آرایههای چندبعدی وجود ندارد و مقادیر آرایه/شیء به جای کپی «با مقدار» (By Value) با روش «با ارجاع» (by Reference) کپی میشود. بنابراین کد زیر صحیح است:
اما کد زیر درست نیست:
2. روش قدیمی حلقه ()for (کپی سطحی)
با توجه به رواج برنامهنویسی تابعی در این روزها، این روش احتمالاً از کمترین اقبال برخوردار است. در هر صورت این روش چه به صورت محض یا غیر محض، و چه به صورت اعلانی یا دستوری کار خود را به انجام میرساند.
نکته: این روش آرایههای چندبعدی را به طور امنی کپی نمیکند. از آنجا که در این روش از عملگر = استفاده میشود، اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب خواهند یافت.
کد زیر صحیح است:
اما کد زیر نادرست است:
3. روش حلقه ()While (کپی سطحی)
همان مطالبی که در مورد قبل در خصوص حلقه ()for گفتیم، در مورد این روش نیز صدق میکند:
نکته: در این روش نیز اشیا/آرایهها به جای «با مقدار» به صورت «با ارجاع» انتساب مییابند.
کد زیر صحیح است:
کد زیر صحیح نیست:
4. روش Array.map (کپی سطحی)
امروزه و در روزگار مدرن با تابع map سر و کار داریم. ریشههای این تابع به ریاضیات بازمیگردد، چون «نگاشت» (map) به مفهوم تبدیل یک مجموعه به نوع دیگری از مجموعه، در عین حفظ ساختار گفته میشود. به زبان ساده Array.map هر بار یک آرایه با طول یکسان بازگشت میدهد.
برای دوبل کردن یک فهرست اعداد میتوان از map به همراه double استفاده کرد:
چه ربطی به Clone کردن دارد؟
از آنجا که مقاله ما در مورد کلون کردن است، برای ایجاد کپی تکراری از یک آرایه کافی است آن عنصر را در یک فراخوانی map بازگشت دهیم.
اگر دوست دارید این توضیح را به زبان ریاضیاتی بشنوید، باید بگوییم که تابع زیر:
(x) => x
یک تابع همانی است که هر پارامتری به آن داده شود آن را بازگشت میدهد. بنابراین (map(identity موجب کلون شدن یک آرایه میشود.
نکته: در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب خواهند یافت.

5. روش Array.filter (کپی سطحی)
این تابع دقیقاً مانند map یک آرایه بازگشت میدهد؛ اما تضمینی وجود ندارد که آرایه بازگشتی طول مشابهی داشته باشد. برای نمونه در کد زیر اگر اعداد زوج را فیلتر کنیم چه اتفاقی میافتد؟
آرایه ورودی طولی برابر با 3 دارد؛ اما طول آرایه حاصل 1 است. اگر گزاره فیلتر شما همواره مقدار true بازگشت دهد، همیشه یک کپی تکراری از آرایه اصلی به دست میآورید:
هر عنصر که تست را بگذراند، در خروجی آرایه بازگشت مییابد.
نکته: در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب مییابند.
6. روش Array.reduce (کپی سطحی)
با این که این روش برای کلون کردن یک آرایه چندان مناسب نیست؛ اما برای این که فهرستمان کامل باشد این گزینه را معرفی میکنیم. واقعیت این است که reduce قویتر از آن است که صرفاً برای کلون کردن یک آرایه استفاده شود:
Reduce همچنان که روی یک لیست حلقهای تعریف میکند، یک مقدار اولیه را تبدیل میکند. در این روش مقدار اولیه یک آرایه خالی است که آن را با به تدریج با عناصر لیست پر میکنیم. این آرایه باید از تابع بازگشت پیدا کند تا در تکرار بعدی استفاده شود.
نکته: در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب مییابند.
7. روش Array.slice (کپی سطحی)
Slice یک کپی سطحی از یک آرایه بر مبنای اندیس آغازین/انتهایی ارائه شده بازمیگرداند. اگر 3 عنصر نخست را بخواهیم به صورت زیر عمل میکنیم:
اگر بخواهیم همه عناصر را داشته باشیم، باید هیچ پارامتری ندهیم:
نکته: این روش یک کپی سطحی ایجاد میکند و از این رو در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب مییابند.
8. JSON.parse و JSON.stringify (کپی عمیق)
JSON.stringify یک شیء را به صورت یک رشته درمیآورد. JSON.parse یک رشته را به صورت یک شیء درمیآورد. ترکیب کردن آنها باعث میشود که یک شیء به یک رشته تبدیل شود. سپس این فرایند معکوس شود تا یک ساختار داده کاملاً جدید ایجاد شود.
نکته: این روش برای کپی کردن عمیق اشیا/آرایههای تودرتو به روش امن مناسب است.
9. روش Array.concat (کپی سطحی)
concat آرایهها را با مقادیر و یا دیگر آرایهها ترکیب میکند.
اگر هیچ چیز ارائه نشود یا یک آرایه خالی داده شود، یک کپی سطحی بازگشت مییابد:
نکته: در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب مییابند.
10. روش Array.from (کپی سطحی)
این روش موجب میشود که هر شیء تکرارپذیر به یک آرایه تبدیل شود. با ارائه یک آرایه، یک کپی سطحی از آن بازگشت مییابد.
نکته: در این روش نیز اشیا/آرایهها به جای روش «با مقدار» به صورت «با ارجاع» انتساب مییابند.
سخن پایانی
امیدواریم از مطالعه این مطلب لذت برده باشید. در این مقاله تلاش کردیم روشهای مختلف کلون کردن آرایه را در یک گام توضیح دهیم. با این وجود، اگر بخواهید از ترکیب متدها و تکنیکهای مختلف استفاده کنید، بدیهی است که روشهای بسیار بیشتری وجود دارد.
https://blog.faradars.org/how-to-clone-an-array-in-javascript/
بررسی وجود چند کلیدواژه در یک رشته با جاوا — به زبان ساده
در این راهنمای مقدماتی با روش تشخیص وجود چند کلمه درون یک رشته متنی (String) آشنا میشویم. بدین منظور الگوریتمهای یافتن کلیدواژه در یک رشته را در زبان جاوا طراحی و بررسی خواهیم کرد.
فرض کنید رشته زیر را داریم:
وظیفه ما این است که ببینیم آیا inputString شامل کلمات hello و Baeldung است یا خیر؛ بنابراین کلیدواژههای خود را در یک آرایه قرار میدهیم:
به علاوه، ترتیب کلمات نیز مهم نیست و نوع مطابقت با در نظر گرفتن حروف کوچک/بزرگ است.
استفاده از متد ()String.contains
در آغاز، روش استفاده از متد ()String.contains برای رسیدن به هدف خود را بررسی میکنیم. به این منظور باید حلقهای روی آرایه کلیدواژهها تعریف کنیم و رخداد هر آیتم را درون inputString بررسی کنیم:
متد ()contains در صورتی مقدار true بازگشت میدهد که رشته inputString شامل آیتم مفروض باشد. هنگامی که هیچ کدام از کلیدواژهها درون رشته نباشد، میتوانیم فرایند کار را متوقف کرده و بیدرنگ مقدار false بازگشت دهیم. علیرغم این واقعیت که نیاز به نوشتن کد بیشتر وجود دارد، این راهحل برای کاربردهای ساده سریع است.
استفاده از متد ()String.indexOf
همانند راهحل مطرح شده در بخش قبلی میتوان اندیسهای کلیدواژهها را با استفاده از متد ()String.indexOf نیز بررسی کرد. به این منظور باید یک متد داشته باشیم که inputString و فهرستی از کلیدواژهها را بپذیرد.
متد ()indexOf اندیس هر واژه را درون inputString بازگشت میدهد. هنگامی که کلمه مورد نظر در متن نباشد، اندیس برابر با 1- خواهد بود.
استفاده از عبارتهای منظم
روش دیگری که برای نیل به مقصود مطرح شده در ابتدای این مطلب میتوان به خدمت گرفت، استفاده از «عبارتهای منظم» (Regular Expressions) برای تطبیق کلمهها است. به این منظور از کلاس Pattern استفاده میکنیم.
ابتدا عبارت رشتهای را تعریف میکنیم. از آنجا که باید دو کلیدواژه را تطبیق دهم، ابتدا باید قاعده regex را با دو چشمانداز بسازیم:
در مورد کاربرد عمومی میتوان از کد زیر استفاده کرد:
سپس از متد ()matcher برای پیدا کردن رخدادهای کلیدواژه استفاده میکنیم:
اما عبارتهای منظم هزینه عملیاتی بالایی دارند اگر بخواهیم به دنبال چند واژه بگردیم، عملکرد این راهحل ممکن است بهینه نباشد.
استفاده از جاوا 8 و List
روش دیگری که بررسی میکنیم API مربوط به Stream در جاوا 8 است. اما قبل از آن باید مقداری تبدیل جزئی روی دادههای اولیه خود اجرا کنیم:
اینک نوبت آن رسیده است که از Stream API استفاده کنیم:
عملیات فوق در صورتی مقدار true بازگشت میدهد که رشته ورودی شامل همه کلیدواژهها باشد. به طور جایگزین میتوان از متد ()containsAll فریمورک Collections برای رسیدن به نتیجه مطلوب نیز استفاده کرد:
با این وجود، این متد صرفاً در مورد کلمات کامل عمل میکند. بنابراین تنها در صورتی میتواند کلیدواژههای مورد نظر را پیدا کند که در متن مربوطه با فاصله از کلمات دیگر جدا شده باشند.
استفاده از الگوریتم Aho-Corasick
الگوریتم Aho-Corasick به بیان ساده برای جستجوی متن با چند کلیدواژه طراحی شده است. پیچیدگی زمانی این الگوریتم (O(n ارتباطی با تعداد کلیدواژههایی که جستجو میشوند و یا طول متنی که قرار است جستجو شود ندارد.
ابتدا باید وابستگی الگوریتم Aho-Corasick را در فایل pom.xml خود ذکر کنیم:
سپس درخت پیشوندی (Trie) را با آرایهای از کلمات کلیدواژهها میسازیم. به این منظور از ساختار داده Trie استفاده میکنیم:
پس از آن متد parser را با متن inputString فراخوانی میکنیم که میخواهیم کلیدواژهها را در آن بیابیم و نتایج را در مجموعه emits ذخیره میکنیم:
در نهایت اگر نتایج خود را پرینت کنیم:
در مورد هر کلیدواژه موقعیت آغازین کلیدواژه در متن، موقعیت انتهایی و خود کلیدواژه را خواهیم دید:
در نهایت پیادهسازی کامل به صورت زیر خواهد بود:
در این مثال، ما تنها به دنبال کلمات کامل هستیم. اما اگر بخواهیم نه تنها inputString بلکه helloBaeldung را نیز تطبیق بدهیم، باید خصوصیت ()onlyWholeWords را از محاسبات سازنده Trie حذف کنیم.
به علاوه به خاطر داشته باشید که ما عناصر تکراری را نیز از مجموعه emits حذف کردهایم، چون ممکن است چند مورد مطابقت از کلیدواژه یکسان وجود داشته باشند.
سخن پایانی
در این مقاله با روشهای مختلف یافتن چند کلیدواژه در یک رشته در زبان برنامهنویسی آشنا شدیم. به علاوه مثالهایی را با استفاده از JDK مرکزی و همچنین کتابخانه Aho-Corasick ارائه کردیم. برای مشاهده کدهای کامل این مقاله میتوانید به این ریپوی گیتهاب (+) مراجعه کنید.
https://blog.faradars.org/check-if-a-string-contains-multiple-keywords-in-java/
حلقه for در زبان برنامه نویسی ++C — به زبان ساده
در زبانهای برنامهنویسی مختلف از حلقهها برای تکرار یک بلوک خاصی از کد استفاده میشود. در این راهنما با روش ایجاد حلقه for در زبان برنامه نویسی ++C با ارائه مثال آشنا میشویم. اجرای حلقهها تا زمانی که شرط خاصی برقرار بشود ادامه مییابد. سه نوع حلقه در زبان برنامهنویسی ++C وجود دارند:
- حلقه for
- حلقه while
- حلقه do…while
برای مطالعه قسمت قبلی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
ساختار حلقه for در زبان برنامه نویسی ++C
در قطعه کد زیر ساختار کلی یک حلقه for در ++C ارائه شده است:
در کد فوق تنها جزء testExpression اجباری است.
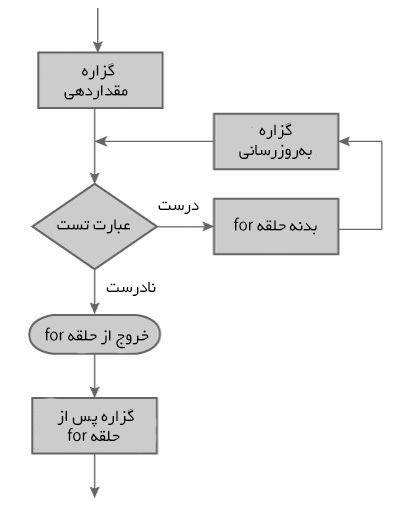
طرز کار حلقه for
- گزاره مقداردهی تنها یک بار و در ابتدای کار اجرا میشود.
- سپس عبارت تست ارزیابی میشود.
- اگر عبارت تست نادرست باشد، حلقه for خاتمه مییابد؛ اما اگر عبارت تست true باشد، کدهای درون بدنه حلقه for اجرا میشوند و عبارت update بهروزرسانی میشود.
- یک بار دیگر عبارت تست ارزیابی میشود و این فرایند تا زمانی که عبارت تست false شود، تکرار میشود.
فلوچارت حلقه for در ++C
مثال اول: حلقه for در ++C
خروجی
Enter a positive integer: 5 Factorial of 5 = 120
در این برنامه از کاربر خواسته میشود که یک عدد صحیح مثبت وارد کند که در متغیر n ذخیره میشود. فرض کنید کاربر مقدار 5 را وارد میکند. طرز کار عملی حلقه for چنین خواهد بود:
- در ابتدا i برابر با 1 است، عبارت تست true است، فاکتوریل برابر با 1 خواهد بود.
- i به مقدار 2 بهروزرسانی میشود، عبارت تست true است، فاکتوریل 2 میشود.
- i به مقدار 3 بهروزرسانی میشود، عبارت تست true است، فاکتوریل 6 میشود.
- i به مقدار 4 بهروزرسانی میشود، عبارت تست true است، فاکتوریل 24 میشود.
- i به مقدار 5 بهروزرسانی میشود، عبارت تست true است، فاکتوریل 120 میشود.
- i به مقدار 6 بهروزرسانی میشود، عبارت تست false است، حلقه for خاتمه مییابد.
در برنامه فوق متغیر i در خارج از حلقه for استفاده نمیشود. در چنین مواردی بهتراست این متغیر را درون حلقه for (در گزاره مقداردهی) اعلان کنیم.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
آدرس دهی در شبکه های کامپیوتری — به زبان ساده
آدرس دهی لایه ۳ شبکه، یکی از وظایف اصلی لایه شبکه محسوب میشود. آدرسهای این شبکه همواره منطقی هستند، یعنی آدرسهایی بر مبنای نرمافزار هستند و میتوان با پیکربندی مناسب آنها را تغییر داد.
آدرس شبکه معمولاً به یک میزبان یا گره و یا سرور اشاره میکند. همچنین آدرس میتواند نشان دهنده کل یک شبکه باشد. آدرس شبکه همواره روی کارت اینترفیس آن پیکربندی میشود و عموماً روی آدرسهای MAC سیستم مورد نگاشت قرار میگیرد. آدرسهای MAC در واقع آدرسهای سختافزاری یا آدرسهای لایه 2 ماشین هستند که برای ارتباط در لایه 2 استفاده میشوند.
انواع مختلفی از آدرسهای شبکه با عناوین IP ،IPX و AppleTalk وجود دارند که البته در این نوشته صرفاً IP را برسی میکنیم، چون تنها گزینهای است که عملاً امروزه استفاده میشود.

آدرسدهی IP سازوکاری برای ایجاد تمایز بین میزبانها و شبکه فراهم میسازد. از آنجا که آدرسهای IP به روش سلسله مراتبی تخصیص مییابند، میزبان همواره تحت شبکه خاصی قرار میگیرد. میزبانی که نیاز به ارتباط با خارج از subnet خود دارد، میبایست آدرس شبکه مقصد را که بسته یا دادهها به آنجا ارسال میشوند بداند.
میزبانها در subnet-های مختلف به سازوکاری برای یافتن موقعیت همدیگر نیاز دارند. این کار از طریق DNS صورت میگیرد. DNS سروری است که آدرس لایه 3 میزبان ریموت را که روی نام دامنه یا FQDN تنظیم شده است ارائه میکند. هنگامی که یک میزبان آدرس لایه 3 (یعنی آدرس IP) را از میزبان ریموت اخذ میکند، همه بستههایش را به «گیتوی» (Gateway) آن ارسال میکند. گیتوی روتری است که اطلاعات موردنیاز برای مسیریابی بستهها به سمت میزبان مقصد را در اختیار دارد.
روترها از جدولهای مسیریابی بهره میگیرند که حاوی اطلاعاتی در مورد روش رسیدن به شبکه هستند. روترها به محض دریافت یک درخواست فوروارد کردن، بستهها را به hop (روتر مجاور) در مسیر مقصد فوروارد میکنند. روتر بعدی در طول مسیر نیز همین کار را تکرار میکند تا این که بستههای داده به مقصد خود برسند.
آدرس شبکه میتواند یکی از حالتهای زیر را داشته باشد:
- Unicast (با مقصد یک میزبان)
- Multicast (با مقصد گروهی)
- Broadcast (با مقصد همه)
- Anycast (با مقصد نزدیکترین مورد)
روتر هرگز به صورت پیشفرض ترافیک را به روش Broadcast فوروارد نمیکند. ترافیک Multicast از تدابیر خاصی استفاده میکند، چون غالباً یک جریان ویدئویی یا صورتی با اولویتبندی بالا است. Anycast حالتی شبیه به Unicast دارد؛ به جز این در صورت وجود چند مقصد، بستهها به نزدیکترین مقصد تحویل میشوند.
منبع: فرادرس