طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیساخت یک چت بات (Chatbot) پایتون با NLTK — از صفر تا صد
گارتنر به عنوان بزرگترین شرکت تحقیقات و مشاوره دنیا، پیشبینی کرده است که تا سال 2020، چتباتها 85 درصد از تعاملهای بین مشتری-سرویس را مدیریت خواهند کرد. چتباتها هم اینک در حدود 30 درصد از این تراکنشها را مدیریت میکنند. در این مقاله با روش ساخت یک چتبات پایتون به کمک پکیج NLTK آشنا خواهیم شد.
احتمالاً تاکنون نام Duolingo به گوش شما خورده است. این اپلیکیشن محبوب یک روش یادگیری زبان از طریق تمرین بازیگونه زبان جدید ارائه کرده است. دلیل محبوبیت آن سبکهای نوآورانه تدریس زبان خارجی محسوب میشود. مفهوم کار ساده است: پنج تا ده دقیقه تمرین تعاملی در روز برای یادگیری یک زبان کافی است.
با این وجود علیرغم این که Duolingo به افراد امکان یادگیری یک زبان جدید را داده است؛ اما کاربران آن یک دغدغه دارند. افراد حس میکنند که چیزی را در خصوص یادگیری مهارتهای محاورهای ارزشمند از دست دادهاند، زیرا زبان را به صوت کاملاً مستقل آموختهاند. همچنین این افراد در مورد مکالمه با دیگر یادگیرندگان آن زبان دچار واهمه هستند، زیرا از عدم اعتمادبهنفس رنج میبرند. مشخص شده است که این یک تنگنای بزرگ در نقشههای Duolingo محسوب میشود.
بدین ترتیب تیم آنها این مسئله را از طریق ساخت یک چتبات بومی داخل اپلیکیشن حل کرد. این چتبات به کاربران کمک میکند که مهارتهای محاورهای را بیاموزند و آن چه را که آموختهاند تمرین کنند.
از آنجا که رباتها به صورت محاورهای و دوستانه طراحی شدهاند، یادگیرندگان Duolingo میتوانند هر زمان در طی روز با آنها گفتگو کنند و از شخصیتهایی که خودشان استفاده میکنند بهره بگیرند تا این که آن قدر شجاعت پیدا بکنند که زبان جدیدشان را با گویشوران دیگر نیز تمرین کنند. بدین ترتیب یکی از دغدغههای اصلی مشتریان حل و یادگیری از طریق این اپلیکیشن بسیار جالبتر شد.
چتبات چیست؟
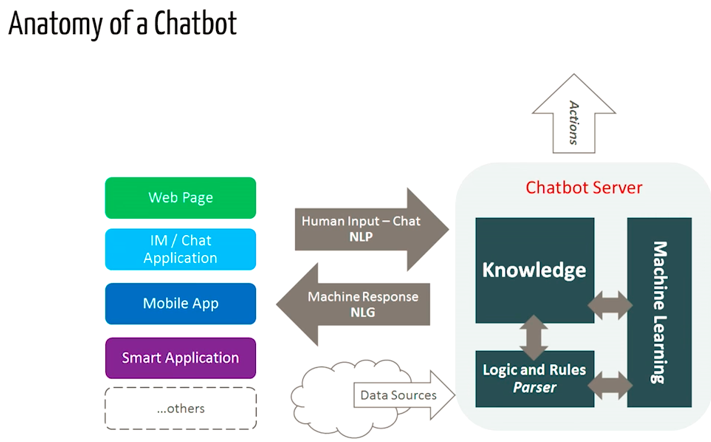
یک «چتبات» (chatbot) در واقع نوعی نرمافزار بهره گرفته از هوش مصنوعی روی یک دستگاه (مانند Siri ،Alexa ،Google Assistant و غیره)، اپلیکیشن، وبسایت یا دیگر شبکهها است که تلاش میکند نیازهای مشتری را سنجیده و سپس به آنها در اجرای وظایف خاص مانند تراکنش تجاری، رزرو هتل، تحویل فرم و غیره کمک کند. امروزه تقریباً همه شرکتها یک چتبات را مورد استفاده قرار میدهند تا به ارزیابی کاربران بپردازند. برخی از روشهایی که شرکتها از چتباتها استفاده میکنند به شرح زیر هستند:
- ارائه اطلاعات پرواز
- اتصال مشتریها و حسابهای مالی
- پشتیبانی از مشتری
- امکانات بهرهگیری از چتباتها (تقریباً) نامحدود است.
تاریخچه چتباتها به سال 1966 بازمیگردد که یک برنامه رایانهای به نام ELIZA از سوی Weizenbaum اختراع شد. این چتبات، زبان یک رواندرمانگر را با تنها 200 خط کد تقلید میکرد. شما میتوانید در این آدرس (+) با الیزا صحبت کنید.
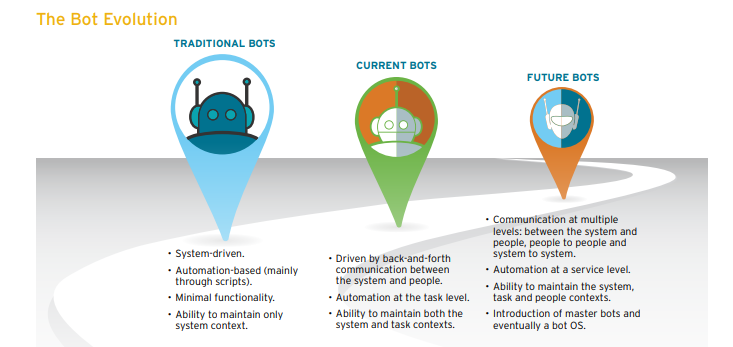
چتبات چگونه کار میکند؟
به طور عمده دو نسخه از چتبات وجود دارد که یکی «مبتنی بر قواعد» (Rule-Based) و دیگری «خودآموز» (Self Learning) است.
- ربات در یک رویکرد مبتنی بر قواعد، به سؤالات بر مبنای برخی قواعد که برای آنها آموزش دیده است پاسخ میدهد. این قواعد ممکن است بسیار ساده و یا بسیار پیچیده تعریف شده باشند. این رباتها میتوانند کوئریهای ساده را مدیریت کنند؛ اما در مدیریت کوئریهای پیچیده ناتوان هستند.
- رباتهای «خودآموز» آنهایی هستند که از برخی رویکردهای مبتنی بر یادگیری ماشین استفاده میکنند و قطعاً بسیار کارآمدتر از رباتهای مبتنی بر قواعد هستند. این رباتها خود میتوانند بر دو نوع باشند: «مبتنی بر بازیابی» (Retrieval Based) و یا «تولیدی» (Generative).
مدلهای مبتنی بر بازیابی
در این مدلها یک چتبات از نوعی شهود برای انتخاب یک پاسخ از کتابخانهای از پاسخهای از پیش تعریفشده اقدام میکند. این چتبات از پیام و زمینه مکالمه برای انتخاب بهترین پاسخ از یک فهرست از پیش تعریف شده از پیامهای ربات استفاده میکند. زمینه گفتگو میتواند شامل موقعیت کنونی در یک درخت گفتگو، همه مکالمههای قبلی در گفتگو، متغیرهای ذخیره شده قبلی (مانند نامهای کاربری) و موارد دیگر باشد. شهود برای انتخاب پاسخها میتواند به روشهای مختلفی مهندسی شود که از منطق شرطی if-else مبتنی بر قواعد تا روشهای طبقهبندی یادگیری ماشین متفاوت است.
مدلهای تولیدی
رباتها میتوانند پاسخها را تولید هم بکنند و لازم نیست که همواره از میان یک مجموعه از پاسخهای از پیش تعریف شده انتخاب کنند. این وضعیت موجب میشود که آنها به موجودات هوشمندی تبدیل شوند و با انتخاب کلمه به کلمه از کوئری، پاسخها را تولید کنند.
در این مقاله ما یک چتبات ساده مبتنی بر بازیابی به وسیله کتابخانه NLTK پایتون میسازیم.
ساخت ربات
در این بخش مراحل مورد نیاز برای ساخت ربات توضیح داده شدهاند.
پیشنیازها
فرض شده است که شما دانش ابتدایی در مورد کتابخانه scikit و NLTK دارید. با این وجود اگر در حوزه NLP مبتدی هستید، همچنان میتوانید از این مقاله بهره بگیرید و سپس به منابع بازگردید.
NLP
این رشته مطالعاتی روی تعاملهای بین زبان انسانی و رایانهها تمرکز دارد و «پردازش زبان طبیعی» (Natural Language Processing) یا به اختصار NLP نامیده میشود. این حوزه از علم در تقاطع بین علوم رایانه، هوش مصنوعی و زبانشناسی رایانشی قرار میگیرد. NLP روشی است که رایانهها استفاده میکنند تا زبان انسانی را به روشی هوشمندانه و مفید، تحلیل، درک و معنایابی کنند. توسعهدهندهها با بهرهگیری از NLP میتوانند دانش اجرای وظایفی مانند خلاصهسازی خودکار، ترجمه، شناسایی موجودیتهای نامدار، استخراج رابطه، تحلیل احساسی، بازشناسی گفتار و دستهبندی موضوعی را به دست آورند.
مقدمه مختصری در خصوص NLTK
NLTK که اختصاری برای عبارت «کیت ابزار زبان طبیعی» (Natural Language Toolkit) است یک پلتفرم پیشرو برای ساخت برنامههای پایتون با دادههای زبان انسانی محسوب میشود. این پلتفرم اینترفیسهای سهلالاستفادهای برای بیش از 50 منبع متنی و واژگانی مانند WordNet ارائه میکند و مجموعهای از کتابخانههای پردازش متن برای طبقهبندی، توکن سازی، «ریشهیابی» (stemming)، تگ گذاری، تجزیه و استدلال احساسی و پوششهایی برای کتابخانههای NLP قدرتمند ارائه میکند.
NLTK به نام «یک ابزار شگفتانگیز برای یادگیری و کار در زمینه زبانشناسی رایانشی در پایتون» و «یک کتابخانه عالی برای کار با زبان طبیعی» توصیف شده است.
کتاب پردازش زبان طبیعی در پایتون (+) یک مقدمه عملی برای برنامهنویسی پردازش زبان ارائه کرده است. مطالعه این کتاب را برای افرادی که قصد آغاز کار با NLP در پایتون را دارند، توصیه میکنیم.
دانلود و نصب NLTK
برای نصب NLTK دستور زیر را اجرا کنید:
pip install nltk
با اجرای دستورهای زیر میتوانید از صحت نصب مطمئن شوید:
python import nltk
نصب پکیجهای NLTK
NLTK را ایمپورت و دستور زیر را اجرا کنید:
nltk.download()
دستور فوق دانلود کننده NLTK را باز میکند و در این بخش میتوانید مجموعه متون و مدلهایی که میخواهید دانلود کنید را انتخاب نمایید. همچنین میتوانید همه پکیجها را به یک باره انتخاب کنید.
پیشپردازش متن با NLTK
مشکل اصلی در دادههای متنی این است که کلاً در قالب متن (String) هستند. با این حال، الگوریتمهای یادگیری ماشین به نوعی بردار ویژگی عددی نیاز دارند تا بتوانند وظایف خود را اجرا کنند. بنابراین پیش از آغاز کار روی هر پروژه NLP باید آن را پیشپردازش کنیم تا برای کار مناسبسازی شود. مراحل مقدماتی پیشپردازش شامل موارد زیر هستند:
- تبدیل کل متن به حالت حروف بزرگ یا حروف کوچک. بدین ترتیب الگوریتم با کلمه یکسان در حالتهای مختلف، به روش متفاوتی برخورد نمیکند.
- توکن سازی: توکن سازی اصطلاحی است که برای توصیف فرایند تبدیل رشتههای متنی معمولی به فهرستی از توکنها یعنی کلماتی که در عمل میخواهیم گفته میشود. توکن ساز جمله میتواند برای یافتن فهرستی از جملهها و توکن ساز کلمه میتواند برای یافتن فهرستی از کلمات در رشته استفاده شود.
پکیجهای داده NLTK شامل توکنسازهای از پیش آموزش دیده Punkt برای زبان انگلیسی هستند.
- حذف Noise: هر چیزی که یک حرف یا عدد استاندارد نباشد از متن حذف میشود.
- حذف Stop Words: در برخی موارد کلمات بسیار متداول که به ظاهر ارزش بسیار کمی در کمک به انتخاب سندها و تطبیق نیازهای کاربر دارند به کلی از واژهنامه حذف میشوند. این کلمهها به نام Stop words نامیده میشوند.
- «ریشهیابی» (Stemming): ریشهیابی فرایندی است که در آن کلمات مشتق شده یا دارای پسوند به شکل بن یا ریشه خود تبدیل میشوند که عموماً شکل نوشتاری کلمه است. برای ارائه مثالی از ریشهیابی باید بگوییم که اگر بخواهیم کلمههای Stems ،Stemming ،Stemmed و Stemtization را ریشهیابی کنیم به کلمه stem میرسیم.
- «بنواژهسازی» (Lemmatization): این روش نسخه کمی متفاوت از ریشهیابی است. تفاوت اصلی بین این دو آن است که در ریشهیابی در اغلب موارد میتوان کلمات ناموجود به دست آورد، در حالی که بنواژهها کلماتی واقعی هستند. بنابراین کلمه ریشهیابی شده که در انتهای فرایند ریشهیابی به دست میآید، ممکن است چیزی نباشد که بتوان آن را در یک فرهنگ لغت پیدا کرد؛ اما بنواژه را حتماً میتوان در واژهنامهها پیدا کرد. نمونههایی از بنواژهسازی کلمه run است که بنواژهای برای کلماتی مانند running یا ran است و همچنین کلماتی مانند better یا good در بنواژه مشترکی قرار دارند و از این رو دارای بنواژه مشترکی محسوب میشوند.
کیسه کلمات (Bag of Words)
پس از مرحله ابتدایی پیشپردازش متن باید آن را به یک بردار (یا آرایهای) معنیدار از اعداد تبدیل کنیم. کیسه کلمات یک بازنمایی از متن محسوب میشود که به توصیف رخداد کلمهها درون یک سند میپردازد. این مدلسازی دو نکته دارد:
- یک واژهنامه از کلمههای شناختهشده
- معیاری از وجود کلمههای شناختهشده
شاید از خود بپرسید چرا آن را «کیسه» کلمات مینامیم؟ دلیل این امر آن است که در این فاز هر اطلاعاتی در مورد ترتیب یا ساختار کلمهها در سند حذف میشود و مدل تنها به بررسی این نکته میپردازد که آیا کلمه شناختهشده مفروض در سند موجود است و محل رخداد آن مهم نیست.
شهودی که در پس کیسه کلمات قرار دارد این است که سندهای متنی در صورت داشتن محتوای مشابه، مشابه نگریسته میشوند. ضمناً این که میتوانیم صرفاً از روی محتوای یک سند در مورد معنای آن نتایجی به دست آوریم.
برای نمونه اگر یک واژهنامه شامل کلمههای {Learning, is, the, not, great} باشد و بخواهیم متن «Learning is great» را بردارسازی بکنیم به بردار زیر میرسیم:
(1, 1, 0, 0, 1)
رویکرد TF-IDF
یک مشکل رویکرد کیسه کلمات این است که کلمههای با فراوانی بالا بر کل سند احاطه مییابند (یعنی امتیاز بالاتری کسب میکنند) اما ممکن است محتوای آگاهیبخش زیادی را شامل نشوند. ضمناً به سندهای طولانیتر وزن بیشتری نسبت به سندهای کوتاهتر میدهد.
یک رویکرد به این مسئله آن است که فراوانی کلمهها را برحسب این که چه مقدار در همه سندها ظاهر میشوند مقیاسبندی مجدد بکنیم و بدین ترتیب امتیازهای کلمههای با فراوانی بالا مانند the در همه سندها بالا خواهد بود و از این رو اثرشان خنثی میشود. این رویکرد به امتیازبندی به نام «فراوانی اصطلاح-معکوس فراوانی سند» (Term Frequency-Inverse Document Frequency) یا به اختصار TF-IDF نامیده میشود که در آن موارد زیر برقرار است.
Term Frequency یک امتیازبندی از فراوانی کلمه مفروض در سند کنونی است:
TF = (Number of times term t appears in a document)/(Number of terms in the document)
و Inverse Document Frequency امتیازبندی میزان نادر بودن کلمه در سندهای دیگر است:
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
وزن TF-IDF وزنی است که غالباً در بازیابی اطلاعات و متنکاوی مورد استفاده قرار میگیرد. این وزن یک معیار آماری است که برای ارزیابی میزان مهم بودن کلمه در یک سند در مجموعه متنی استفاده میشود:
مثال:
سندی را در نظر بگیرید که شامل 100 کلمه است و کلمه phone در آن 5 بار آمده است. فراوانی اصطلاح (یعنی TF) برای phone برابر با 0.05 = 100/5 است. اکنون فرض کنید سندی با 100 میلیون کلمه داریم که کله phone در هزار مورد در آن تکرار شده است. در این صورت معکوس فراوانی سند (IDF) به صورت 4 = 1000000/1000 محاسبه میشود. از این رو وزن TF-IDF نهایی برابر با 0.20 = 4 * 0.05 خواهد بود.
TF-IDF میتواند در یادگیری Scikit به صورت زیر استفاده شود:
from sklearn.feature_extraction.text import TfidfVectorizer
مشابهت کسینوس (Cosine Similarity)
TF-IDF یک تبدیل است که روی متنها اعمال میشود تا دو بردار با ارزش واقعی در فضای برداری به دست آید. سپس میتوانیم مشابهت کسینوسی هر جفت از بردارها را با انتخاب ضرب نقطهای آنها و تقسیم کردن بر حاصل نرمهایشان به دست آوریم. بدین ترتیب کسینوس زاویه بین بردارها به دست میآید. مشابهت کسینوسی معیاری برای مشابهت بین دو بردار غیر صفر محسوب میشود. با استفاده از این فرمول میتوانیم مشابهت بین دو سند d1 و d2 را به صورت زیر پیدا کنیم:
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
که d1 و d2 دو بردار غیر صفر هستند.
اکنون ایده نسبتاً جامعی از پردازش NLP داریم و زمان آن رسیده است که کار واقعی خود یعنی ایجاد یک چتبات را آغاز کنیم. ما چتبات خود را به صورت ROBO نامگذاری میکنیم.
ایمپورت کردن کتابخانههای مورد نیاز
برای ایمپورت کردن کتابخانههای مورد نیاز میتوانید از دستورهای زیر استفاده کنید:
import nltk import numpy as np import random import string # to process standard python strings
مجموعه متون
ما در خصوص مثال مورد بررسیمان از صفحه ویکیپدیا در مورد چتباتها (+) استفاده خواهیم کرد. محتوای صفحه را کپی کرده و آن را در یک فایل متنی به نام chatbot.txt قرار دهید. البته شما میتوانید از هر مجموعه متنی بنا به دلخواه خود استفاده کنید.
خواندن دادهها
ما فایل متنی chatbot.txt را میخوانیم و کل مجموعه متن را برای پیشپردازش به لیستی از جملهها و لیستی از کلمهها تبدیل میکنیم.
در ادامه مثالی از sent_tokens و word_tokens میبینید:
پیشپردازش متن خام
اکنون باید تابعی تعریف کنیم که LemTokens نام دارد و توکنها را به عنوان ورودی میگیرد و توکنهای نرمالسازی شده را بازگشت میدهد:
تطبیق کلیدواژه
سپس تابعی تعریف خواهیم کرد که وظیفه خوشامدگویی از سوی بات را بر عهده دارد، یعنی اگر یک کاربر سلام بکند، ربات در ادامه با سلام و خوشامدگویی پاسخ میدهد. ELIXA از یک تطبیق کلیدواژه ساده برای خوشامدگویی استفاده میکند. ما نیز در اینجا از مفاهیم مشابهی استفاده میکنیم.
تولید پاسخها
برای تولید یک پاسخ از سوی ربات برای سؤالهای ورودی، مفهوم مشابهت سند مورد استفاده قرار گرفته است. بدین ترتیب کار خود را با ایمپورت کردن ماژولهای مورد نیاز آغاز میکنیم.
از کتابخانه scikit learn ماژول TFidf vectorizer (+) را ایمپورت میکنیم تا یک مجموعه از سندهای خام را به ماتریسی از ویژگیهای TF-IDF تبدیل کنیم.
from sklearn.feature_extraction.text import TfidfVectorizer
همچنین ماژول cosine similarity (+) را از کتابخانه scikit learn ایمپورت میکنیم.
from sklearn.metrics.pairwise import cosine_similarity
این ماژول برای یافتن مشابهت بین کلمههای واردشده از سوی کاربر و کلمههای موجود در متن استفاده میشود. این سادهترین پیادهسازی ممکن برای یک چتبات محسوب میشود.
ما یک تابع به نام response تعریف میکنیم که رویکرد کاربر به یک یا چند مورد از کلیدواژههای شناختهشده را جستجو کرده و چند پاسخ ممکن را بازگشت میدهد. اگر مورد مطابقت ورودی برای هیچ کلیدواژهای را پیدا نکند، یک پاسخ به صورت: «متأسفم، سخن شما را درک نکردم» (I am sorry! I don’t understand you) بازگشت میدهد.
در نهایت خطوطی را که میخواهیم ربات در زمان آغاز و خاتمه مکالمه بسته به ورودی کاربر بیان کند را تعریف میکنیم.
بدین ترتیب کار ما تقریباً به پایان رسیده است. ما نخستین چتبات خود را در NLTK کدنویسی کردهایم. شما میتوانید کل کد را به همراه مجموعه متنی در این آدرس گیتهاب (+) مشاهده کنید.
کد منبع کامل چتبات ما به صورت زیر است:
اینک نوبت آن رسیده است که ببینیم ربات ما چگونه با انسانها تعامل میکند:

عملکرد آن چندان هم بد نیست. علی رغم این که چتبات نمیتواند پاسخ رضایتبخشی به برخی سئوالات بدهد، اما در مورد برخی سؤالهای دیگر به خوبی عمل میکند.
سخن پایانی
با این که چتبات ما یک ربات بسیار ساده محسوب میشود و مهارتهای شناختی آن کاملاً محدود است، اما روشی مناسب برای آشنایی با NLP و چتباتها به حساب میآید. اگر چه ROBO به ورودی کاربر پاسخ میدهد، اما نمیتوانید با آن دوستانتان را فریب بدهید و برای یک سیستم production باید به یکی از پلتفرمها یا فریمورکهای موجود مراجعه کنید. این نمونه به شما کمک میکند که در مورد طراحی و چالشهای ایجاد یک چت
منبع: فرادرس
پنج نکته کلیدی برای شروع یادگیری زبان برنامه نویسی C — راهنمای مقدماتی
اگر تاکنون کلمه برنامهنویسی به گوشتان خورده باشد، بیشک نام زبان برنامه نویسی C را نیز شنیدهاید. C یکی از قدیمیترین زبانهای کدنویسی موجود است. برخی از آن میترسند، برخی دیگر نیز عاشقش هستند. زبان C به خاطر دشواری یادگیری برای افراد مبتدی مشهور است. دلایل زیادی برای یادگیری این زبان وجود دارد، اما پیش از شروع به این کار چند نکته مهم وجود دارند که باید به خاطر بسپارید.
زبان برنامهنویسی C چیست؟
برای این که بدانید ماهیت زبان برنامهنویسی C چیست، بهتر است ابتدا با مفهوم کدنویسی آشنا شوید. بدین منظور پیشنهاد میکنیم ابتدا مطلب زیر را مطالعه نمایید:
C یک زبان برنامهنویسی رویهای سطح پایین است که به کد ماشینی که رایانه اجرا میکند، بسیار نزدیک است. این وضعیت موجب میشود که این زبان بسیار سریع باشد؛ اما استفاده از آن چالشبرانگیز است و در صورتی که مراقب نباشید، ممکن است به سیستم خود آسیب بزنید.
چرا باید برنامهنویسی C را بیاموزیم؟
اگر C چنین پیچیده و خطرناک است، پس اصلاً چرا باید آن را آموخت؟ پاسخ این است که:
- C در همه جا حضور دارد.
- تقریباً همه سیستمهای عامل برای رایانهها به زبان C نوشته شدهاند.
- اغلب گوشیهای هوشمند و تبلتها سیستم عامل مبتنی بر زبان C دارند.
- تقریباً همه میکروکنترلرها چه روی نمایشگر درب میکروویو باشند و چه در مسافتیاب داخلی خودرو به کار رفته باشند، به زبان C برنامهنویسی شدهاند.
- C++، Objective C و #C مستقیماً بر مبنای C ساخته شدهاند و زبان برنامهنویسی «پایتون» (Python) نیز به وسیله آن نوشته شده است.
- کسب دانش مناسب از زبان C، در رزومه هر برنامهنویسی نقطهای مثبت تلقی میشود.
برخی افراد فکر میکنند که یادگیری C پیش از هر زبان دیگر برنامهنویسی موجب میشود که فرد درک بهتری از برنامهنویسی به صورت کلی داشته باشد.
یادگیری C در واقع به معنی یادگیری طرز کار رایانهها نیز هست. برنامه نویسان C میتوانند درک عمیقتری از شیوه تأثیر کد روی سیستمها داشته باشند و در نتیجه یادگیری زبانهای برنامهنویسی دیگر برای آنها آسانتر خواهد بود.
1. یادگیری انواع متغیرهای پایه
دادهها در انواع مختلفی هستند. دانستن این که با چه نوع دادهای سر و کار داریم حائز اهمیت است، زیرا در غیر این صورت ممکن است موجب ایجاد سردرگمی شوند. به عنوان مثال باید بدانیم که عدد 5 میتواند یک «عدد صحیح» (Integer) باشد و همچنین میتواند یک کاراکتر متنی باشد.
کد فوق دیگر موجب سردرگمی نمیشود، چون مقدار صحیح 5 به متغیر عددی انتساب یافته است. باید به C اعلام شود که چه نوع دادهای میتواند بپذیرد تا بتواند به طرز بهتری با دادهها کار کند. انواع داده و روشهای انتساب آنها به متغیرها بخشی ضروری از یادگیری C محسوب میشود و درک آنها حائز اهمیت بالایی است. دانستن شیوه انتساب انواع صحیح به دادهها، در همه زبانهای برنامهنویسی یک مهارت مهم محسوب میشود، اما در زبان C کاملاً ضروری است.
2. یادگیری عملگرها
اگر C نخستین زبان برنامهنویسی است که یاد میگیرید، احتمالاً نخستین باری است که با عملگرها آشنا میشوید. عملگرها نمادهایی هستند که به کامپایلر اعلام میکنند یک وظیفه را اجرا کند. شاید سادهترین مثال عملگر + است.
درک این که کد فوق دو متغیر صحیح را با هم جمع میکند کار دشواری محسوب میشود. البته همه عملگرها به این سادگی نیستند. C از عملگرهای زیادی برای عملیات حسابی، انتسابی، منطقی و موارد دیگر استفاده میکند. دانستن این که هر کدام از این عملگرها چه کاری انجام میدهند، به شما کمک میکند که مفاهیم برنامهنویسی را سریعتر درک کنید.
3. استفاده از کتابخانههای استاندارد
C ممکن است یک زبان سطح پایین باشد؛ اما مجموعهای از کتابخانهها برای کمک به ایجاد برنامهها دارد. عملیات حسابی، دادههای خاص locale (مانند نمادهای پولی) و انواع متغیرهای مختلف و ماکروها، همگی مواردی هستند که در این کتابخانهها تعریف شدهاند.
شما میتوانید با گنجاندن این کتابخانهها در کد خود، آنها را مورد استفاده قرار دهید. مثال زیر را در نظر بگیرید:
در C عمل ساده خروجی دادن به کنسول نیازمند گنجاندن فایل هدر stdio.h (کتابخانه استاندارد ورودی/خروجی) است. 15 کتابخانه استاندارد مختلف برای برنامهنویسی در زبان C وجود دارند که هر یک وظایف مختلفی بر عهده دارند.
4. C بخشش ندارد
زبان C دقیقاً همان کاری را انجام میدهد که به آن اعلام شده است و به جای این که در صورت بروز موقعیتهای بیمعنی شکایت کند، به تلاش خود در جهت اجرای وظیفهاش ادامه میدهد. این وضعیت نه تنها میتواند منجر به از کار افتادن برنامه شما بشود؛ بلکه ممکن است کل سیستم را از کار بیندازد.
با این که این وضعیت بغرنج به نظر میرسد؛ اما معمولاً چنین نیست. شما قرار نیست رایانه خود را خراب بکنید؛ اما ممکن است در نهایت چندین باگ در برنامهتان کشف کنید. به مثال زیر توجه کنید:
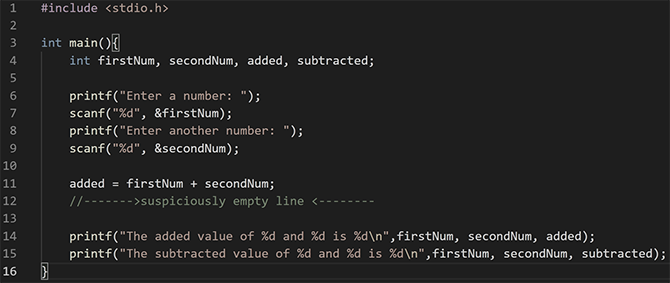
این قطعه کد سؤالهایی را در کنسول نمایش میدهد و سپس ورودیهای کاربر را پیمایش کرده و آنها را در اعداد صحیحی ذخیره میکند. این برنامه برای جمع و تفریق کردن اعداد پیش از نمایش مجدد پاسخ به کاربر طراحی شده است. احتمالاً متوجه شدهاید که اشکالی در این برنامه وجود دارد؛ چون خروجی قطعاً بیمعنی است:
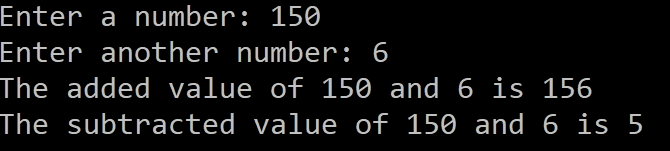
از آنجا که ما هرگز مقادیر را تفریق نکردهایم؛ متغیر تفریق مقدار بیمعنی دارد. زبانهای برنامهنویسی دیگر در مواردی که به متغیر تفریق هیچ مقداری نداده باشید، خطایی به شما نمایش میدهند، اما C چنین نیست.
دیباگ کردن این مثال کار آسانی است، اما برخی کدها از هزاران خط تشکیل یافتهاند و بینهایت پیچیده هستند و C کمکی به یافتن خطاها نمیکند. به جای آن C یک پاسخ بیمعنی ارائه میکند و شما خودتان باید دریابید که چرا چنین اتفاقی افتاده است. البته یک گزینه دیگر نیز وجود دارد که در بخش بعدی توضیح میدهیم.
5. دیباگ کردن بهترین دوست شما است
از آنجا که کدهای C شامل رفتارهای ناخواستهای هستند، ممکن است موجب بروز خطاهایی شوند که ردگیری آنها دشوار باشد و دلیل ظاهری مشخصی نداشته باشند. در این موارد برای این که عقلتان را به طور کامل از دست ندهید، باید در زمینه دیباگ کردن کد مهارت پیدا کنید. یک ابزار دیباگر مانند GDB میتواند در این زمینه کمک کند. GDB در تصویر زیر روی اسکریپت دارای خطا عمل میکند.
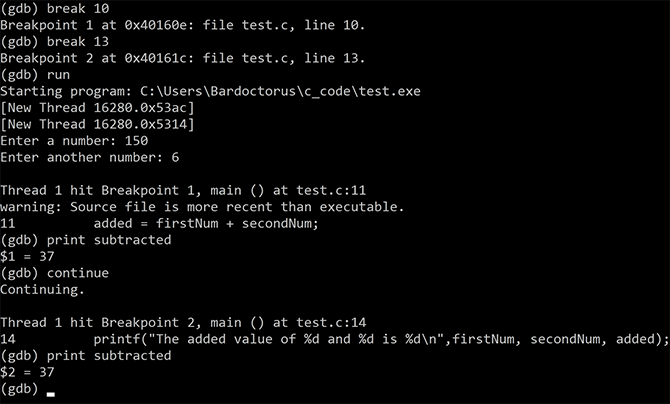
به طور معمول یک برنامه تا زمانی که پایان یابد یا از کار بیفتد، اجرا میشود. ابزار دیباگ امکان توقف کد را به صورت خط به خط میدهند. در کد فوق نقاط توقف روی خطهای 10 و 13 که مشکوک به وجود مشکل هستند، تنظیم شدهاند.
سپس برنامه به صورت نرمال اجرا میشود. اعداد که وارد شدند، در ادامه برنامه پس از خط 10 مکث میکند. ابزار دیباگ از شما میخواهد که مقدار تفریق شده را نمایش دهید که عدد 37 را نمایش میدهد. این وضعیت معنیدار است، چون ما هنوز از آن نخواستهایم که تفریقی انجام دهد و از این رو یک مقدار تصادفی است. در ادامه دیباگر کار خود را به پیش میبرد. این فرایند پس از خط 13 نیز ادامه مییابد و مقدار تفریق شده تنها برای یافتن مقداری که تغییر یافته است نمایش مییابد.

بدین ترتیب مشخص میشود که ما کلاً فراموش کردهایم مقدار را محاسبه کنیم و به جای آن یک خط خالی از کد قرار دادهایم. درک این نکته به لطف دیباگر ممکن شده است. GDB بهترین دوست کدنویسهای C است و هر چه زودتر کار با آن را یاد بگیرید، خوشحالتر خواهید بود.
سخن پایانی
زبان C در واقع یک تجربه یادگیری به درازای عمر است و موارد مهمی مانند اشارهگرها و تخصیص حافظه در آن وجود دارند که در این مقاله اصلاً اشاره نکردهایم. با این که C مشهور به زبان دشوار است؛ اما شما میتوانید با تمرین آن را یاد بگیرید، بنابراین دست به کار شوید و در اولین فرصت شروع به یادگیری آن بکنید
منبع: فرادرس
جستجوی تمام متن در لاراول با Scout — به زبان ساده
جستجوی تمام متن یک قابلیت ضروری جهت فراهم ساختن امکان حرکت در میان صفحههای وبسایتهای با محتوای گسترده است. در این مقاله، شیوه پیادهسازی امکان جستجوی تمام متن را برای یک اپلیکیشن لاراول بررسی میکنیم. در واقع ما از کتابخانه Scout لاراول استفاده میکنیم که پیادهسازی جستجوی تمام متن را به امری ساده و جذاب تبدیل کرده است.
مستندات رسمی، کتابخانه Scout لاراول را به صورت زیر توصیف میکنند:
کتابخانه Scout لاراول یک راهحل ساده و مبتنی بر درایور برای افزودن امکان جستجوی تمام متن به مدلهای Eloquent ارائه میکند. Scout با استفاده از «مشاهدهگرهای مدل» (model observers) به طور خودکار اندیسهای جستجو را در وضعیتی همگامسازی شده با رکوردهای Eloquent حفظ میکند.
کتابخانه Scout لاراول به مدیریت دستکاری اندیسها در زمان بروز تغییراتی در دادههای مدل میپردازد. جایی که دادهها اندیس میشوند به درایوری وابسته است که برای کتابخانه Scout پیکربندیشده است.
در حال حاضر کتابخانه Scout از Algolia پشتیبانی میکند که یک API موتور جستجوی مبتنی بر کلود است و ما نیز در این مقاله از آن برای نمایش پیادهسازی جستجوی تمام متن استفاده خواهیم کرد.
ما کار خود را با نصب کتابخانههای Scout و Algolia server آغاز میکنیم و در ادامه برخی مثالهای واقعی را بررسی میکنیم که شیوه اندیسگذاری و جستجوی دادهها را نمایش میدهد.

پیکربندی سرور
در این بخش ما قصد داریم وابستگیهایی را که برای کار کردن کتابخانه Scout با لاراول لازم هستند نصب کنیم. پس از نصب، باید کمی آن را پیکربندی کنیم تا لاراول بتواند کتابخانه Scout را تشخیص دهد.
در ادامه کتابخانه Scout را با استفاده از Composer نصب میکنیم:
composer require laravel/scout
اگر صرفاً خواسته باشیم کتابخانه Scout را نصب کنیم، کار به همین سادگی است. اینک که کتابخانه Scout نصب شده است، ابتدا باید مطمئن شویم که لاراول در مورد آن اطلاع دارد.
در صورتی که با لاراول کار کرده باشید، احتمالاً با مفهوم «ارائهدهنده سرویس» (service provider) که امکان پیکربندی سرویسها در اپلیکیشن را میدهد، آشنا هستید. بدین ترتیب هر زمان که بخواهید یک سرویس جدید را در اپلیکیشن لاراول پیکربندی کنید، کافی است یک مدخل ارائهدهنده سرویس مرتبط را در config/app.php اضافه کنید.
اگر با مفهوم ارائهدهنده سرویس در لاراول آشنا نیستید؛ قویاً توصیه میکنیم که ابتدا به طور کامل با این مفهوم آشنا شوید.
در مورد اپلیکیشنی که میخواهیم طراحی بکنیم باید یک ارائهدهنده سرویس به نام ScoutServiceProvider را به فهرست ارائهدهندههای سرویس در فایل config/app.php اضافه کنیم. روش کار در قطعه کد زیر نمایش یافته است:
اینک لاراول از وجود ارائهدهنده سرویسی به نام ScoutServiceProvider آگاهی دارد. کتابخانه Scout به همراه یک فایل پیکربندی ارائه میشود که به ما امکان تنظیم نام کاربری و رمز عبور API را میدهد.
در ادامه فایلهای ارائه شده از سوی Scout را با استفاده از دستور زیر منتشر میکنیم:
همان طور که میبینید بدین ترتیب فایل vendor/laravel/scout/config/scout.php به مسیر config/scout.php کپی شده است.
حساب کاربری Algolia
در ادامه یک حساب کاربری در سرویس Algolia (+) ایجاد میکنیم، چون به نام کاربری و رمز عبور API آن نیاز داریم. زمانی که اطلاعات API را به دست آوردید میتوانید اقدام به پیکربندی تنظیمات مورد نیاز در فایل config/scout.php به شیوهای که در قطعه کد زیر نمایش یافته است، بکنید:
دقت داشته باشید که ما مقدار SCOUT_DRIVER را برابر با درایور algolia تعیین کردهایم. از این رو لازم است که تنظیمات لازم برای درایور Algolia را در انتهای فایل پیکربندی کنید. بدین منظور کافی است مقدار id و secret را که از حساب کاربری Algolia دریافت کردهاید تنظیم کنید.
همان طور که شاهد هستید، ما مقادیر را از متغیرهای محیطی واکشی کردهایم، بنابراین باید مطمئن شویم که متغیرهای زیر را در فایل env. به صورت صحیحی تعیین کردهایم:
درنهایت باید SDK مربوط به Algolia PHP را نصب کنیم که برای تعامل با Algolia از طریق API-ها ضروری است. آن را با استفاده از composer و به صورت زیر نصب میکنیم:
بدین ترتیب ما همه وابستگیهای لازم برای ارسال و اندیس کردن دادهها در سرویس algolia را در اختیار داریم.
ایجاد قابلیت اندیسگذاری و جستجو در مدلها
در بخش قبلی ما همه کارهایی را که برای راهاندازی کتابخانههای Scout و Algolia لازم بود انجام دادیم و از این رو اینک میتوانیم دادهها را با استفاده از سرویس جستجوی Algolia اندیسگذاری و جستجو کنیم.
در این بخش مثالی را بررسی میکنیم که شیوه اندیس کردن دادههای موجود و بازیابی نتایج جستجو از Algolia را نمایش میدهد. تصور ما بر این است که شما مدل Post پیشفرض را در اپلیکیشن خود دارید و در مثال خود نیز از آن استفاده خواهیم کرد.
نخستین کاری که باید انجام دهیم، افزودن خصیصه Laravel\Scout\Searchable به مدل Post است. بدین ترتیب مدل Post قابل جستجو میشود و لاراول رکوردهای پست را هر بار که یک رکورد پست، اضافه، بهروزرسانی یا حذف میشود، با اندیس Algolia همگامسازی میکند.
بدین ترتیب مدل Post برای جستجو مناسبسازی میشود. در ادامه و در وهله نخست فیلدهایی را که میبایست اندیسگذاری شوند پیکربندی کنیم. البته لازم نیست همه فیلدهای مدل را در Algolia اندیسگذاری کنید و بهتر است آن را سبک و کارآمد نگه داریم. در واقع در اغلب موارد به چنین کاری نیاز هم نداریم.
میتوان toSearchableArray را در کلاس مدل اضافه کرد تا فیلدهایی که قرار است اندیسگذاری شوند، پیکربندی شوند.
اکنون آماده ایمپورت و اندیسگذاری رکوردهای موجود Post در Algolia هستیم. در واقع کتابخانه Scout این کار را از طریق ارائه دستور artisan زیر سادهتر ساخته است:
این دستور همه رکوردهای مدل Post را در یک حرکت ایمپورت میکند. همه آنها به محض ایمپورت شدن، اندیسگذاری میشوند و از این رو در این لحظه آماده کوئری زدن هستند. در ادامه داشبورد Algolia را بررسی کنید تا رکوردهای ایمپورت شده و دیگر ابزارها را مشاهده کنید.

جمعبندی طرز کار Scout
در این بخش مثالی را ارائه میکنیم که شیوه اجرای عمل جستجو و عملیات CRUD را که به صورت آنی با اندیس Algolia همگامسازی شدهاند نمایش میدهد.
در این بخش فایل app/Http/Controllers/SearchController.php را با محتوای زیر ایجاد میکنیم:
البته ما باید مسیرهای مرتبط را نیز اضافه کنیم:
در ادامه از متد query استفاده می کنیم تا ببینیم شیوه جستجو در Algolia چگونه است:
خصیصه Searchable
به یاد داشته باشید که ما مدل Post را با افزودن خصیصه Searchable قابل جستجو کردهایم. از این رو مدل Post میتواند از متد search برای بازیابی رکوردها از اندیس Algolia استفاده کند. در مثال فوق ما تلاش کردهایم رکوردهایی را که با کلیدواژه title مطابقت دارند بازیابی کنیم.
در ادامه یک متد add وجود دارد که گردش کار افزودن یک رکورد جدید post را تقلید میکند.
در کد فوق هیچ نکته جذابی وجود ندارد و صرفاً یک رکورد post جدید با استفاده از مدل Post ایجاد کرده است. اما مدل Post خصیصه Searchable را پیادهسازی میکند و از این رو لاراول در این مورد به مقداری کار اضافی برای اندیس کردن رکورد جدیداً ایجاد شده در Algolia دارد. بدین ترتیب همان طور که میبینید اندیسگذاری به صورت آنی صورت میگیرد.
درنهایت یک متد delete وجود دارد که آن را نیز بررسی میکنیم:
همان طور که انتظار میرود، این رکورد بیدرنگ پس از حذف شدن از پایگاه داده از اندیس Algolia نیز حذف میشود.
در واقع در صورتی که بخواهید مدلهای موجود را قابل جستجو بکنید، نیاز به هیچ تلاش اضافی از سمت شما وجود ندارد. همه چیز از سوی کتابخانه Scout با استفاده از مشاهدهگرهای مدل مدیریت میشود.
سخن پایانی
بدین ترتیب به پایان این مقاله با موضوع بررسی اجرای جستجوی تمام متن در لاراول با استفاده از کتابخانه Scout و سرویس ابری Algolia رسیدیم. در این مسیر مواردی که لازم بود نصب شوند را توضیح دادیم و با ارائه مثالهای واقعی عملکرد آن را مورد بررسی قرار دادیم.
lمنبع: فرادرس
۷ قابلیت ویژوال استودیو کد برای توسعه دهندگان وب — راهنمای کاربردی
شما میتوانید گردش کار توسعه وب خود را با استفاده از این 7 قابلیت ویژوال استودیو کد و افزونههای آن بهبود ببخشید. چه یک توسعهدهنده حرفهای وب و چه یک فرد مبتدی باشید، در هر صورت مزیتهای یک گردش کار سریعتر بدون شک به کار شما میآید. در این مقاله به بررسی روش تنظیم یک گردش کار بهینه برای استفاده از ویژوال استودیو کد میپردازیم.
ویژوال استودیو کد قابلیتهای داخلی زیادی دارد، اما اگر افزونههای متعدد (و همچنان در حال رشد) آن را نیز در نظر بگیریم، درنهایت هزاران روش برای سفارشیسازی تجربه کاری خود در آن خواهید یافت.
با این که این یکی از نقاط قوت اصلی VS Code محسوب میشود، اما از سوی دیگر میتواند موجب سردرگمی به خصوص برای کاربران تازهکار نیز بشود. در این مقاله قصد داریم این مسائل را روشن بکنیم. همچنین بهترین تکنیکهایی که برای افزایش سرعت و کارایی امور روزمره تا حد امکان مفید هستند معرفی شدهاند.
این مقاله برای دو دسته از افراد به طور خاص مفید است:
- افراد مبتدی که به تازگی شروع به کار با VS Code کردهاند و میخواهند مطمئن شوند که از همان ابزارهایی استفاده میکنند که افراد حرفهای بهره میگیرند.
- کاربران متوسط که VS Code را به خوبی میشناسند؛ اما همچنان حس میکنند میتوانند بهبودهایی در گردش کار خود ایجاد کنند.
چرا باید از VS Code استفاده کنیم؟

VS Code از زمان انتشار در سال 2015 به سرعت جایگاه خود را به عنوان محبوبترین ویرایشگر کد موجود تثبیت کرد. در طی دو سال اخیر، با مراجعه به نتایج روندهای جستجوی گوگل مشاهده میکنیم که علاقه به VS Code (در نمودار زیر به رنگ قرمز) نسبت به همه ویرایشگرهای کد دیگر بیشتر بوده است.

با این که هر ویرایشگر کدی نقاط قوت خاص خود را دارد، اما VS Code به طرز معقولی محبوبترین گزینه است، زیرا قابلیت سفارشیسازی دارد؛ سریعتر بهروزرسانی میشود و نسبت به رقبایش اکوسیستم متنوعتری از افزونهها دارد. در مجموع این قابلیتها به VS Code امکان میدهند که گردش کار بسیار سریعی برای توسعهدهندگان ارائه دهد. در ادامه دلیل این مسئله را به صورت دقیقتری مورد بررسی قرار میدهیم.
اگر تاکنون برخی آموزشهای ویدئویی را در خصوص این IDE تماشا کرده باشید و یا با برخی از همکارانتان کار کرده باشید، احتمالاً با چند مورد از این قابلیتهای VS Code آشنا هستید. در ادامه فهرستی از قابلیتهای اساسی VS Code برای توسعهدهندگان جدی وب ارائه شده است.
اگر میخواهید این نرمافزار را نصب کنید، میتوانید به این آدرس (+) مراجعه کنید.
1. اختصارهای Emmet

این میانبرهای مفید به صورت قابلیتهای درونی VSCode ارائه شدهاند و موجب میشوند که نوشتن کدهای HTML و CSS بسیار سریعتر صورت بگیرد.
آمادهسازی فایل HTML
اگر عبارت html را در هر فایلی تایپ کنید، گزینههای زیادی برای پر کردن دادههای اولیه ضروری در فایل ارائه میشود. با زدن کلیدهای سمت بالا یا پایین میتوانید بین این گزینهها حرکت کنید و سپس با زدن دکمه tab آن میانبر را باز کنید تا چیزی مانند زیر را ببینید:
همچنین میتوانید با زدن کلیدهای Control + SPACE (در ویندوز) یا CMD + SPACE (در macOS) پیش از باز کردن یک گزینه، اطلاعات بیشتری در مورد آن مشاهده کنید.
افزودن تگ
از طریق دانستن چند اختصار که یادگیری آسانی دارند، میتوان امکان ایجاد سریع تگهای HTML، تعریف کردن ID برای آنها، نامهای کلاس، عناصر همنیا و فرزند را به دست آورد.
برای نمونه اگر بخواهید یک لیست نامرتب با سه مدخل ایجاد کنید که هر کدام یک نام کلاس منحصر به فرد داشته باشند، میتوانید عبارت ul>li.item$*3 را وارد کنید تا چیزی مانند زیر را به دست آورید:
در این مثال، ما از نمادهای اختصاری زیر استفاده کردهایم:
- < مشخص میکند که تگ بعدی باید یک فرزند از تگ قبلی باشد.
- . مشخص میکند که متنی که در ادامه آمده است نام کلاس است.
- $ برای نمایش یک عدد منحصر به فرد استفاده میشود (که از 1 رو به بالا شمارش میشود).
- درنهایت * امکان تکثیر سریع یک تگ برای تولید به هر تعداد که میخواهید را فراهم میسازد.
شما میتوانید فهرست کاملی از میانبرهای Emmet را با مراجعه به صفحه مستندات رسمی (+) مشاهده کنید؛ اما سادهترین روش برای شروع به کار استفاده از این تقلب نامه (+) است.
افزودن متن ساختگی
یکی از مفیدترین اختصارهای Emmet برای توسعه وب امکانی برای درج مقدار دلخواهی از متن ساختگی است. برای درج 10 واژه کافی است عبارت lorem100 را وارد کرده و دکمه tab را بزنید. و برای درج 1000 کلمه میتوانید از lorem1000 + tab و همین طور تا آخر استفاده کنید.
Emmet برای JSX
اگر از JSX در React یا هر جایگزین دیگر برای HTML استفاده میکنید، همچنان میتوانید از اختصارهای Emmet کمک بگیرید. تنها تفاوت این است که این بار باید آنها را به صورت دستی فعال کنید.
به این منظور باید کلیدهای ترکیبی , + Ctrl را بزنید تا بخش تنظیمات باز شود و سپس روی نماد آکولاد {} در گوشه راست-بالای آن کلیک کنید تا بخش settings.json باز شود. زمانی که باز شد، کافی است کد زیر را اضافه کنید:
2. CLI یکپارچه (رابط کاربری خط فرمان)

VS Code برای صرفهجویی زمان مورد نیاز جهت سوئیچ کردن بین پنجرهها یک ترمینال یکپارچه یا CLI ارائه کرد است. کافی است دکمههای ‘ + CTRL یا ‘ + CMD را بزنید تا آن را باز کنید. با همین دستور میتوانید این ترمینال داخلی را ببندید. این ترمینال به صورت خودکار در همان دایرکتوری که VS Code باز شده است، باز میشود و بدین ترتیب مراحل ناوبری مورد نیاز برای اجرای عملیات در یک ترمینال استاندارد را کاهش میدهد.
این ترمینال کار نصب وابستگیهای NPM یا YRAN، کامیت فایلها به Git، و ارسال فایلها به گیتهاب را آسانتر ساخته است. همچنین هر کار دیگری که میبایست از طریق خط فرمان اجرا شود در این محیط به آسانی صورت میپذیرد.
نکتهای برای کاربران ویندوز
اگر از سیستم عامل ویندوز استفاده میکنید، به شدت توصیه میشود که Git for Windows (+) را نصب کنید. این ابزار امکان استفاده از برخی دستورها که برای کاربران Mac و Linux آشنا هستند را در اختیار شما قرار میدهد و همچنین با استفاده از آن میتوانید گیت را از خط فرمان اجرا کنید.
زمانی که ابزار فوق نصب شد میتوانید ترمینال پیشفرض را از Powershell به Git Bash تغییر دهید و کد زیر را به فایل settings.json اضافه کنید:
3. ESLint

ESLint یک ابزار قدرتمند و محبوب برای linting محسوب میشود که به یافتن خطاها در کد و اصلاح آنها در زمان نوشتن کد کمک میکند و بدین ترتیب میتوانید از رویههای بهینه رایج کدنویسی پیروی کنید. این یک ابزار خطایابی بسیار عالی نیز محسوب میشود، زیرا با بررسی خطاهای ESLint میتوانید بهترین رویههای کدنویسی را بشناسید و دلیل این که چرا این رویهها، بهترین هستند را درک کنید.
میتوان آن را به صورت یک پکیج Node بر مبنای پروژه اضافه کرد و یا این که میتوان از افزونه ESLint درون VS Code استفاده کرد. گزینه دوم آسان و ساده است و موجب نمیشود که از پیکربندیهای یکتای ESLint برای پروژههای بعدی استفاده نکنید. بنابراین افزونه ESLint را یافته و آن را نصب کنید.
برای این که بیشترین بهره را از این افزونه بگیرید، بهتر است از نسخه سراسری کتابخانه ESLint که روی رایانه نصب میشود استفاده کنید. به این منظور باید مطمئن شوید که Node روی سیستم نصب شده است. سپس ترمینال خود را باز کنید (اگر درون VS Code هستید، دکمههای ‘ + CTRL یا ‘ + CMD را بزنید) و کد زیر را وارد کنید:
npm i -g eslint
زمانی که افزونه و کتابخانه سراسری نصب شد، نیازی به اجرای دستور زیر روی تک تک پروژهها نخواهید داشت.
npm i eslint –s
به جای آن میتوانید فایل eslintrc را به دایرکتوری اصلی پروژه خود اضافه کنید.
به این منظور باید NPM را مقداردهی اولیه کنید. ابتدا مطمئن شوید که در دایرکتوری اصلی پروژه خود هستید و در ترمینال عبارت زیر را وارد کنید:
npm init
در ادامه میتوانید فایل eslintrc را با وارد کردن دستور زیر ایجاد کنید:
eslint –init
و در ادامه مراحل مورد نظر را تعقیب کنید. اگر مطمئن نیستید که از کدام «راهنمای سبک» (Style-guide) باید استفاده کنید، پیشنهاد میکنیم از نوع AirBnB’s پیروی کنید.
زمانی که از تنظیمات ESLint راضی بودید، میتوانید مطمئن باشید که اصلاحهای خودکار در زمان ذخیرهسازی و با افزودن دستور زیر به فایل settings.json اعمال میشوند:
نکتهای دیگر برای کاربران ویندوز: Pesky Linebreaks
به صورت پیشفرض محلهای پایان خطوط در مک و لینوکس از یک فید خط ساده (LF) یعنی n\ استفاده میکنند. اما ویندوز از یک فید (carriage return line (CRLF یعنی r\n\ استفاده میکند.
دو راهحل برای این مسئله وجود دارد. ابتدا میتوانید تنظیمات شکستن خط را از unix به windows تغییر دهید. به این منظور به فایل eslintrc بروید و عبارت “linebreak-style”: “windows” را زیر شیء rules اضافه کنید.
در غیر این صورت اگر فکر میکنید که استفاده از r\n\ ضرورتی ندارد و n\ کفایت میکند و یا به صورت عمده همکارانتان از سیستمهای مک و لینوکس استفاده میکنند، میتوانید رفتار پیشفرض شکستن خط را به LF تغییر دهید و کد زیر را به فایل settings.json اضافه کنید:
4. Prettier

Prettier یک ابزار قالببندی کد است. این ابزار سبکهای قالببندی معینی را به عنوان سبک صحیح توصیف میکند؛ اما محبوبیت آن موجب شده است که قواعد آن به یک استاندارد تثبیتشده برای جاوا اسکریپت، CSS و تعداد فزایندهای از زبانهای دیگر تبدیل شود.
یک همپوشانی بین Prettier و ESLint وجود دارد؛ اما در نهایت Prettier تمرکز بیشتری روی یافتن خطاها دارد و Prettier بیشتر بر اصلاح قالببندی کد متمرکز شده است. این دو با یکدیگر همکاری میکنند و نوعی یکپارچهسازی برای کمک به اجرای روانتر کارها تا حد ممکن دارند.
افزونهای که باید نصب کنیم Prettier — Code formatter نوشته Esben Peterson است. برای فعالسازی یکپارچهسازی ESLint کد زیر را به فایل settings.json اضافه کنید:
قالببندی در زمان ذخیرهسازی
زمانی که این افزونه نصب شد، میتوانید با زدن دکمههای ترکیبی Shift + Alt+ F (در ویندوز) و یا Shift + Option + F (در مک) موجب شوید که Prettier بیدرنگ کدهای جاوا اسکریپت و CSS را قالببندی کند.
یک گزینه مناسب این است که افزونه را طوری تنظیم کنیم که در زمان ذخیرهسازی فایل به صورت خودکار کدها را قالببندی کند. به این منظور باید دستور زیر را به فایل settings.json اضافه کنید:
زبانهای دیگر
از Prettier میتوان برای قالببندی زبانهای دیگر به جز جاوا اسکریپت و CSS نیز استفاده کرد. این افزونه فهرست رو به رشدی از زبانها را پشتیبانی میکند که شامل جاوا، روبی و PHP میشود. البته این موارد به صورت آماده نصب نمیشوند و باید آنها را به صورت مستقل نصب کنید.
5. میانبرهای چند کرسری

قابلیت ویرایش چند کرسری میتواند موجب صرفهجویی زیادی در زمان بشود. برای استفاده از این امکان به روشی کارآمدتر باید چند دستور را به خاطر بسپارید؛ اما جای نگرانی نیست، زیرا آنها به سرعت ملکه ذهن شما میشوند.
دستورهای پایه
برای افزودن دستی کرسرهای جدید، کلید Alt یا Option را نگه دارید و سپس هر جایی که میخواهید کرسر قرار گیرد، کلیک کنید. هر زمان با زدن دکمه Esc میتوانید به حالت تک کرسری بازگردید. صرفاً با استفاده از همین دو دستور میتوانید مقدار زیادی در زمان خود صرفهجویی کنید؛ اما موارد دیگری نیز وجود دارند.
انتخاب ستون
با نگه داشتن کلیدهای Shift + Alt یا Shift + Option در زمان کشیدن ماوس، یک کرسر جدید به انتهای هر خط انتخاب شده اضافه میشود.
درست بالا یا زیر کرسر فعلی
برای افزودن یک کرسر جدید، درست بالای مکان فعلی کرسر میتوانید کلیدهای Ctrl + Alt یا CMD + Option را بزنید و سپس از کلیدهای جهتی بالا یا پایین استفاده کنید.
انتخاب همه کدهای یکسان
با انتخاب یک بخش از کد و سپس زدن کلیدهای Ctrl + Shift + L یا CMD + Shift+ L میتوانید بیدرنگ یک کرسر جدید در انتهای هر بخش کد با همان میزان تورفتگی ایجاد میشود.
انتخاب کد یکسان به صورت یک به یک
در مواردی که نخواهید همه کدهای یکسان انتخاب شوند، می تونید از کلیدهای Ctrl + D یا CMD + D برای هایلایت کردن متن تورفته به صورت یک به یک استفاده کنید.
نکته: اکستنشنهای Keymap
اگر به مجموعه کلیدهای ترکیبی یک ویرایشگر متن دیگر عادت داشته باشید، این امکان وجود دارد که از آن ترکیبها استفاده کنید. در واقع به جای این که وقت خود را صرف یادگیری مجموعه جدیدی از کلیدهای ترکیبی بکنید، میتوانید با مراجعه به مسیر Preferences > Keymaps فهرستی از اکستنشنهای مرتبط را ببینید.
دقت کنید که بسیاری از کلیدهای میانبر توصیفشده در این مقاله در زمان نصب keymap جدید ممکن است به هم بریزند. اگر میخواهید دوباره به حالت پیشفرض بازگردید، کافی است اکستنشنهای مرتبط را یافته و غیرفعال کنید.
6. شکستن خطوط

در اغلب موارد ما تمایل نداریم که متنی که میبینیم از بخش قابل رؤیت صفحه خارج شود تا مجبور نباشیم از اسکرول افقی که چندان هم آسان نیست استفاده کنیم. برای فعال یا غیرفعال کردن امکان شکستن خطوط بر مبنای هر فایل مستقل کافی است کلیدهای Alt + Z را بزنید.
همچنین اگر نمیخواهید هیچ وقت امکان شکستن خطوط غیرفعال شود، میتوانید آن را به صورت رفتار پیشفرض تنظیم کنید. به این منظور درون فایل settings.json کد زیر را اضافه کنید تا همه متون به صورت پیشفرض شکسته شوند:
7. اجرا و دیباگ کد جاوا اسکریپت
چندین گزینه عالی برای اجرا و دیباگ کردن کدهای جاوا اسکریپت درون ویژوال استودیو کد وجود دارد که در ادامه آنها را یک به یک توضیح میدهیم:
Quokka.js

Quokka یک ابزار رایگان است که به ما کمک میکند در هر لحظه از اتفاقهایی که در کد جاوا اسکریپت رخ میدهد اطلاع پیدا کنیم. این ابزار خود را به صورت «چک نویس زنده» توصیف کرده و یک راهنمایی بصری ارائه میکند تا ببینیم آیا کد کاری که قرار بوده انجام دهد را انجام میدهد یا نه.
زمانی که آن را نصب کنید با زدن کلیدهای CTRL + K + Q یا CMD + K + Q میتوانید آن را روی فایل موجود جاوا اسکریپت اجرا یا ریاستارت کنید.
دیباگر برای کروم

بهترین گزینه برای دیباگ کردن کدهای جاوا اسکریپت درون VS Code، اکستنشن خود مایکروسافت به نام «Debugger for Chrome» است. البته طرز کار آن ممکن است کمی پیچیده باشد و از این رو توصیه میکنیم به صفحه مستندات رسمی (+) آن مراجعه کنید تا موارد بیشتری را در خصوص آن بیاموزید. این اکستنشن یک ابزار قدرتمند است و امکاناتی که ارائه میکند بسیار فراتر از ()comsole.log است.
Code Runner

اگر گزینههای فوق برای شما پیچیده هستند و ترجیح میدهید که به روشی ساده قطعه کدها یا فایلهای خود را اجرا کنید، توصیه میکنیم که اکستنشن Code Runner را که تألیف Jun Han است بررسی کنید. این اکستنشن زبانهای زیادی را پوشش میدهد و با یک دستور ساده (Ctrl + Alt + N یا CMD + Option + N) میتوانید خروجی کد خود را در انتهای صفحه ملاحظه کنید. در مورد جاوا اسکریپت رفتار این افزونه شبیه به یک کنسول مرورگر ادغام شده درون VS Code است.
سخن پایانی
قابلیتهایی که در این مقاله معرفی شدند برای هر محیط توسعه وب کاملاً مفید هستند و امیدواریم موجب شوند که گردش کار VS Code شما تا حد امکان سریعتر شود و یا اگر مبتدی هستید بتوانید آغاز قدرتمندی در استفاده از این IDE محبوب داشته باشید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
منبع: فرادرس
فرم های HTML در مرورگرهای قدیمی — راهنمای جامع
همه توسعهدهندگان وب به سرعت این واقعیت دردناک را درمییابند که وب جای خشنی برای آنها محسوب میشود و بدترین مورد هم مرورگرهای قدیمی هستند. باید پذیرفت که وقتی از مرورگرهای قدیمی صحبت میکنیم در عمل نسخههای قدیمی اینترنت اکسپلورر را در نظر داریم، اما تعداد آنها بسیار بیشتر از این است. یک نسخه یک سال پیش فایرفاکس هم مرورگری قدیمی محسوب میشود. همچنین در دنیای موبایل که نه سیستم عامل و نه مرورگر نمیتوانند بهروزرسانی شوند، این مشکل تشدید میشود. بسیاری از گوشیهای اندروید و یا آیفون وجود دارند که مرورگرهای اولیه خودشان را حفظ کردهاند و هرگز بهروزرسانی نشدهاند. اینها نیز مرورگرهای قدیمی محسوب میشوند. در این مقاله به بررسی روش کار با فرمهای HTML در مرورگرهای قدیمی میپردازیم.
برای مطالعه بخش قبلی این سری مطالب آموزشی روی لینک زیر کلیک کنید:
متأسفانه مواجهه با این واقعیتها نیز بخشی از کار برنامهنویسی وب به حساب میآید. اما خوشبختانه چند ترفند وجود دارند که میتوانند به حل حدود 80 درصد از مشکلاتی ناشی از مرورگرهای قدیمی کمک کنند.
بیان مسئله
اساساً مهمترین نکته در زمان مواجهه با این مشکل، خواندن مستندات آن مرورگرهای قدیمی و تلاش برای درک الگوهای رایج است. برای نمونه در اغلب موارد پشتیبانی از CSS بزرگترین مشکل در فرمهای HTML محسوب میشود. بنابراین بهترین نقطه شروع همینجا است. کافی است پشتیبانی از عناصر (یا اینترفیس DOM) که میخواهید استفاده کنید را مورد بررسی قرار دهید. وبسایت MDN جدول سازگاری را برای اغلب عناصر، مشخصهها و API-هایی که میتوان در صفحههای وب مورد استفاده قرار ارائه کرده است. اما منابع دیگری نیز وجود دارند که میتوانند مفید واقع شوند و در ادامه به معرفی آنها میپردازیم.
مستندات ارائهدهنده مرورگر
- موزیلا: به این منظور کافی است به بررسی وبسایت MDN بپردازید.
- مایکروسافت: مستندات پشتیبانی استانداردهای اینترنت اکسپلورر (+)
- WebKit: از آنجا که نسخههای مختلفی برای این موتور وجود دارد، بررسی مستندات آن کمی پیچیدهتر است:
مستندات مستقل
- وبسایت Can I Use (+) اطلاعاتی در مورد فناوریهای کاملاً نوین ارائه میکند.
- وبسایت Quirks Mode (+) یک منبع شگفتانگیز در مورد سازگاری مرورگرها محسوب میشود. بخش موبایل این وبسایت یکی از بهترین منابع حال حاضر است.
- وبسایت Position Is Everything (+) بهترین منبع موجود در مورد رندر کردن باگها در مرورگرهای قدیمی و هر گونه راهحل موجود در این زمینه است.
- وبسایت Mobile HTML5 (+) اطلاعات سازگاری را در مورد طیف وسیعی از مرورگرهای موبایل و نه انواع برندهای مطرح ارائه میکند.
سادهسازی مسائل
از آنجا که فرمهای HTML شامل تعاملهای پیچیدهای هستند، یک قاعده ساده سرانگشتی در مورد آنها وجود دارد: تلاش کنید همه چیز را ساده حفظ کنید. موارد زیادی وجود دارند که میخواهیم فرمها «زیباتر» یا «با کارکردهای پیچیدهتر» باشند، اما ساخت فرمهای HTML کارآمد به طراحی یا کارکرد ربطی ندارد.
«تنزل مطبوع» بهترین دوست توسعهدهنده وب است
«تنزل مطبوع» (Graceful degradation) و «بهبود پیشرونده» (progressive enhancement) دو الگوی توسعه هستند که امکان ساخت محصولاتی عالی و همزمان پشتیبانی از طیف وسیعی از مرورگرها را فراهم میسازند. زمانی که چیزی را برای یک مرورگر مدرن میسازید و میخواهید مطمئن باشید که روی مرورگرهای قدیمی هم به هر حال به طریقی حتماً کار خواهد کرد در واقع از روش تنزل مطبوع استفاده میکنید. در ادامه چند نمونه از این مفهوم را در ارتباط با فرمهای HTML بررسی میکنیم.
انواع ورودی HTML
انواع ورودی جدید ارائه شده از سوی HTML5 بسیار جالب هستند، زیرا روش تنزل آنها کاملاً قابل پیشبینی است. اگر مرورگری مقدار خصوصیت type یک عنصر <input> را نداند، به مقدار text بازمیگردد.
| Chrome 24 | Firefox 18 |
|---|---|
سلکتورهای خصوصیت CSS
سلکتورهای خصوصیت CSS در فرمهای HTML بسیار مفید هستند، اما برخی مرورگرهای قدیمی از آنها پشتیبانی نمیکنند. در این حالت میتوان از یک کلاس معادل برای حل این مشکل استفاده کرد:
توجه کنید که کد زیر بیفایده است (زیرا تکراری است) و ممکن است در برخی مرورگرها کار نکند:
دکمههای فرم
دو روش برای تعریف دکمهها در فرمهای HTML وجود دارد:
- عنصر <input> با خصوصیت type که دارای مقدار button، submit، reset یا image است.
- عنصر <button>.
عنصر <input> در صورتی که بخواهید نوعی CSS را با استفاده از سلکتورهای عنصر روی آن اعمال کند، میتواند موجب دشواریهایی شود.
عنصر <button> از دو مشکل احتمالی رنج میبرد:
- یک باگ در برخی نسخههای قدیمی اینترنت اکسپلورر وجود دارد. وقتی که کاربر روی دکمه کلیک کند، این محتوای خصوصیت value نیست که ارسال میشود، بلکه محتوای HTML بین تگهای آغاز و پایانی عنصر <button> خواهد بود. این مورد تنها در صورتی مشکل محسوب میشود که بخواهید چنین مقداری را ارسال کنید. برای نمونه اگر بخواهید بسته به دکمهای که کاربر کلیک کرده است دادهای را پردازش کنید چنین حالتی متصور خواهد بود.
- برخی مرورگرهای قدیمی از submit به عنوان مقدار پیشفرض خصوصیت type استفاده نمیکنند، از این رو توصیه میشود که همواره خصوصیت type را روی عنصرهای <button> تعیین کنید.
انتخاب هر کدام از راهحلهای فوق بر مبنای محدودیتهای پروژه به عهده شما است.
پشتیبانی از CSS
بزرگترین مشکل فرمهای HTML در مرورگرهای قدیمی، بحث پشتیبانی از CSS است. در چنین مواردی حتی اگر امکان اعمال نوعی تغییر روی عناصر متن (مانند تغییر اندازه یا رنگ) وجود داشته باشد، همواره عوارض ناخواستهای وجود خواهد داشت. در این موارد بهترین رویکرد این است که کلاً از خیر استایلدهی به ویجتهای فرم HTML بگذرید. با این حال همچنان میتوان استایل ها را روی همه آیتمهای پیرامونی اعمال کرد. اگر یک فرد حرفهای باشید و مشتری از شما بخواهد، میتوانید در این حالت برخی تکنیکهای دشوار مانند ساخت مجدد ویجتها با جاوا اسکریپت را انجام دهید.
کشف قابلیت و polyfill-ها
با این که جاوا اسکریپت یک فناوری جالب در مرورگرهای مدرن محسوب میشود، اما مرورگرهای قدیمی مشکلات زیادی با آن دارند.
یکی از بزرگترین مشکلها، دسترسی به API-ها است. به همین دلیل کار با جاوا اسکریپت «غیر مزاحم» (unobtrusive) بهترین رویه در نظر گرفته میشود. این یک الگوی توسعه است که دو الزام را تعریف میکند:
- تمایز کامل بین ساختار و رفتارها.
- اگر کد از کار بیفتد، محتوا و کارکردهای پایه باید در دسترس و قابل استفاده باشند.
مفهوم جاوا اسکریپت «غیر مزاحم» که در ابتدا از سوی پیتر پاول کخ برای Dev.Opera.com عرضه شده است ( و اینک به Docs.WebPlatform.org انتقال یافته است) این ایدهها را به خوبی توضیح میدهد.
کتابخانه Modernizr
موارد زیادی وجود دارند که polyfill مناسب تا حدود زیادی میتواند به ارائه یک API مفقود کمک کند. یک polyfill نوعی کد جاوا اسکریپت است که موارد نقص کارکردهای مرورگرهای قدیمی را جبران میکند. با این که میتوان از آن برای بهبود پشتیبانی هر نوع کارکردی استفاده کرد، استفاده از آنها برای جاوا اسکریپت نسبت به CSS یا HTML ریسک کمتری دارد. موارد زیادی وجود دارند که جاوا اسکریپت ممکن است (به دلیل مشکلات شبکه، تعارض اسکریپت و غیره) از کار بیفتد. اما برای جاوا اسکریپت اگر با ذهنیت جاوا اسکریپت غیر مزاحم کار کنیم، در صورت فقدان polyfill نیز مشکل مهمی به حساب نمیآید.
بهترین روش برای polyfill کردن API مفقود، استفاده از کتابخانه Modernizr و پروژه جانبی آن YepNope است. Modernizr کتابخانهای است که امکان تست وجود کارکرد را میدهد تا بر اساس آن عمل کنید. YepNope یک کتابخانه بارگذاری شرطی است. به مثال زیر توجه کنید:
تیم Modernizr لیستی از polyfill-های عالی را به سادگی نگهداری میکند.
نکته: Modernizr قابلیتهای مدرن دیگری نیز دارد که امکان کار با جاوا اسکریپت غیر مزاحم و تکنیکهای تنزل مطبوع را میدهد. برای کسب اطلاعات بیشتر به مستندات Modernizr (+) مراجعه کنید.
نکاتی در خصوص عملکرد
با این که اسکریپتهایی مانند Modernizr در مورد عملکرد بسیار آگاهانه عمل میکنند، بارگذاری یک پلیفیل 200 کیلوبایتی میتواند بر عملکرد اپلیکیشن تأثیر بگذارد. این وضعیت به طور خاص در مورد مرورگرهای قدیمی صدق میکند، چون بسیاری از آنها موتور جاوا اسکریپت کُندی دارند که میتواند اجرای همه پلیفیل ها را برای کاربر زجرآور کند. عملکرد نیز برای خود موضوع مهمی محسوب میشود، اما مرورگرهای قدیمی بسیار حساس هستند، چون کند هستند و هر چه از پلیفیل های زیادی استفاده کنید، کد جاوا اسکریپت بیشتری باید پردازش شود. بنابراین دشواری آنها نسبت به مرورگرهای مدرنتر دو برابر است. شما باید کد خود را روی مرورگرهای قدیمی تست کنید تا ببینید عملکرد آنها چگونه است. برخی اوقات از دست رفتن برخی کارکردها منجر به تجربه کاربری بهتری نسبت به داشتن دقیق همان کارکرد در همه مرورگرها میشود. به عنوان آخرین یادآوری باید اشاره کنیم که همواره باید کاربر نهایی را در نظر داشته باشید.
سخن پایانی
چنان که در این مقاله دیدیم، سر و کار داشتن با مرورگرهای قدیمی تنها محدود به فرمها نمیشود. با این که مجموعه کاملی از تکنیکها برای کار با مرورگرهای قدیمی وجود دارد، اما یادگیری همه آنها فراتر از حیطه این مقاله است.
منبع: فرادرس