طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیساخت کتابخانه انگولار با Angular CLI — از صفر تا صد
با معرفی انگولار 6 مشخص شد که بسیاری از بهبودهای صورت گرفته مدیون Angular CLI هستند. یکی از بهترین این بهبودها ادغام Angular CLI با ng-packagr برای تولید و ساخت کتابخانههای انگولار بود. ng-packagr یک ابزار عالی است که از سوی «دیوید هرجس» (David Herges) ساخته شده و کتابخانه انگولار را به Angular Package Format تبدیل میکند.
در این مقاله با جزییات مراحل ایجاد یک کتابخانه انگولار آشنا میشویم. ضمناً برخی قواعدی که به شروع به کار صحیح یک کتابخانه کمک و از بروز مشکلات جلوگیری میکنند را با هم مرور خواهیم کرد.
مقدمه
زمانی که از ng new استفاده میکنیم، Angular CLI یک «فضای کاری» (workspace) جدید برای ما میسازد. در این فضای کاری انگولار ما دو پروژه داریم:
پروژه کتابخانه
این همان کتابخانه کامپوننتها و سرویسها است که میخواهیم ارائه کنیم. در واقع این همان کدی است که میتوان به عنوان مثال روی npm منتشر کرد.
پروژه اپلیکیشن
این پروژه برای تست کتابخانه استفاده میشود. برخی اوقات این اپلیکیشن به عنوان مثالی در مستندات و کاربرد نمونه کتابخانه مورد استفاده قرار میگیرد. یک پروژه سوم نیز وجود دارد که تست سر به سر است و Angular CLI به طور پیشفرض برای ما تولید میکند، اما در این راهنما نیازی به آن نداریم. اکنون که درکی کلی از فضای کاری انگولار یافتهایم، برخی اهداف خاصتر این راهنما را مرور میکنیم.
اهداف
- استفاده از Angular CLI برای ایجاد یک فضای کاری با همان نام کتابخانه انگولار مورد نظر یعنی example-ng6-lib
- ما یک اپلیکیشن تست برای کتابخانه example-ng6-lib خود به نام example-ng6-lib-app خواهیم داشت.
- در فضای کاری example-ng6-lib یک کتابخانه انگولار به نام example-ng6-lib ایجاد میکنیم.
- در کتابخانه انگولار یک پیشوند به صورت enl داریم که اختصاری برای حروف ابتدایی عبارت «Example Ng6 Library» است.
- ما کتابخانه example-ng6-lib خودمان را با ایمپورت کردن به صورت یک کتابخانه در اپلیکیشن example-ng6-lib-app تست خواهیم کرد.
انگولار 6
مواردی که در ادامه میآیند در صورت استفاده از انگولار نسخه 6 باید مورد توجه قرار گیرند.
- شماره نسخه Angular CLI با انگولار تطبیق یافته است و از نسخه 1.7 به نسخه 6.0.0 رسیده است.
- فایل پیکربندی Angular CLI یعنی Angular-cli.json با فایلی به نام Angular.json عوض شده است.
- Angular CLI هم اینک یک فضای کاری تولید میکند که مستقیماً از وجود چندین پروژه پشتیبانی میکند.
ایجاد یک فضای کاری انگولار
نخستین هدف ما ایجاد یک فضای کاری انگولار به نام example-ng6-lib است.
برای انگولار 7
در انگولار 7 یک فلگ بسیار مفید به نام –createApplication اضافه شده است. اگر از انگولار 7 استفاده میکنید باید از رویکردی که در این مقاله (+) توصیف شده است پیروی کنید و نه از رویکرد مناسب انگولار 6 که در ادامه آمده و در آن فضای کاری تغییر نام داده میشود.
برای انگولار 6
به دلیل طرز کار پروژهها در انگولار 6 باید فضای کاری انگولار را به روشی نسبتاً نامعمول ایجاد کنیم. ما باید یک فضای کاری به نام example-ng6-lib-app ایجاد کنیم و سپس نام آن را به example-ng6-lib تغییر دهیم:
ng new example-ng6-lib-app rename example-ng6-lib-app example-ng6-lib cd example-ng6-lib ng serve
اگر لازم است از اینترنت اکسپلورر هم پشتیبانی شود، باید این مقاله (+) را نیز مطالعه کنید. زمانی که به این آدرس در مرورگر برویم:
http://localhost:4200/
میبینیم که اپلیکیشن آغازین انگولار مشاهده میشود.

پیکربندی انگولار 6 در فایل angular.json
پیش از آن که اقدام به ایجاد کتابخانه خود بکنیم، نگاهی سریع به فایل پیکربندی انگولار 6 یعنی angular.json خواهیم داشت. در نسخه 6 انگولار فایل قدیمی angular-cli.json با angular.json عوض شده است. ضمناً محتوای آن کمی تغییر یافته است. نکته مهمی که دیده میشود شیء Projects است. این شیء یک مدخل برای هر پروژه دارد.
در حال حاضر ما دو پروژه داریم:
example-ng6-lib-app
این اپلیکیشنی است که از آن برای تست کتابخانه خود استفاده میکنیم.
example-ng6-lib-app-e2e
این پروژه پیشفرض برای تست سر به سر است. در این مقاله میتوان این پروژه را کاملاً نادیده گرفت. به خاطر داشته باشید که گفتیم Angular CLI پروژهای به نام example-ng6-lib-app ایجاد میکند.
سپس اپلیکیشن پیشفرض برای ما به نام example-ng6-lib-app ایجاد میشود. بدین ترتیب میتوانید نام پروژه خود را به صورت example-ng6-lib تعیین کنید. زمانی که کتابخانه ما ایجاد شد میبینیم که پروژه دیگری به شیء پروژه اضافه شده است.
نکته: توجه کنید که در انگولار 6 همواره باید فضای کاری خود را به نام library-app سازید و سپس نام آن را به کتابخانهتان تغییر دهید.
ایجاد یک ماژول کتابخانه
اینک میتوانیم یک کتابخانه جدید به نام example-ng6-lib در فضای کاری خود بسازیم:
ng generate library example-ng6-lib --prefix=enl
توجه کنید که ما از فلگ –prefix استفاده میکنیم، زیرا میخواهیم کامپوننتهای کتابخانه ما متمایز بمانند. اگر چنین کاری نکنیم Angular CLI از نام پیشفرض lib استفاده میکند.
نکته: همواره در زمان ایجاد کتابخانه از یک پیشوند برای نامگذاری استفاده کنید.
یکی از بهترین نکات در مورد دستور generate در Angular CLI این است که همواره به ما اعلام میکند که کدام فایلها از این دستور تأثیر میپذیرند:
ng generate library example-ng6-lib --prefix=enl CREATE projects/example-ng6-lib/karma.conf.js (968 bytes) CREATE projects/example-ng6-lib/ng-package.json (191 bytes) CREATE projects/example-ng6-lib/ng-package.prod.json (164 bytes) CREATE projects/example-ng6-lib/package.json (175 bytes) CREATE projects/example-ng6-lib/src/test.ts (700 bytes) CREATE projects/example-ng6-lib/src/public_api.ts (191 bytes) CREATE projects/example-ng6-lib/tsconfig.lib.json (769 bytes) CREATE projects/example-ng6-lib/tsconfig.spec.json (246 bytes) CREATE projects/example-ng6-lib/tslint.json (317 bytes) CREATE projects/example-ng6-lib/src/lib/example-ng6-lib.module.ts (261 bytes) CREATE projects/example-ng6-lib/src/lib/example-ng6-lib.component.spec.ts (679 bytes) CREATE projects/example-ng6-lib/src/lib/example-ng6-lib.component.ts (281 bytes) CREATE projects/example-ng6-lib/src/lib/example-ng6-lib.service.spec.ts (418 bytes) CREATE projects/example-ng6-lib/src/lib/example-ng6-lib.service.ts (142 bytes) UPDATE angular.json (4818 bytes) UPDATE package.json (1724 bytes) UPDATE tsconfig.json (471 bytes)
در ادامه خلاصهای از کارهایی که دستور تولید کتابخانه انجام داده است را میبینید:
- یک پروژه جدید به نام example-ng6-lib برای کتابخانه ما در angular.json اضافه کرده است.
- وابستگیهای ng-packagr را به فایل ما اضافه کرده است.
- یک ارجاع به مسیر ساخت example-ng6-lib در فایل tsconfig.json اضافه کرده است.
- منابعی برای کتابخانه در projects/example-ng6-lib ایجاد کرده است.
در ادامه به بررسی عمیقتر هر کدام از موارد فوق میپردازیم.
پروژه example-ng6-lib در angular.json
اگر به فایل angular.json نکاه کنیم به طور خاص متوجه میشویم که در شیء projects اینک پروژه جدیدی به نام angular.json داریم.
در کد فوق برخی عناصر کلیدی که باید توجه داشت به صورت زیر هستند:
- Root: این عنصر به پوشه root پروژه ما اشاره میکند.
- sourceRoot: این عنصر به ریشه سورس کد واقعی کتابخانه اشاره دارد.
- projectType: این عنصر تعیین میکند که این یک کتابخانه (library) است در حالی که دو پروژه دیگر از نوع application هستند.
- Prefix: این همان پیشوند مشخصکننده ای است که در سلکتورهای کامپوننت خود استفاده میکنیم. به خاطر داشته باشید که ما هنگام تولید کتابخانه از enl استفاده کردهایم. شما احتمالاً با پیشوند app آشنا هستید که به ما اعلام میکند کدام کامپوننتها به اپلیکیشن اصلی ما تعلق دارند.
- Architect: این شیء بخشهایی دارید که شیوه مدیریت build ،test و lint پروژهها را از سوی Angular CLI تعیین میکنند. توجه کنید که در بخش build، سازنده از ng-packagr استفاده میکند.
وابستگی ng-packagr در package.json
زمانی که کتابخانه خود را میسازیم، Angular CLI متوجه میشود که به ng-packagr نیاز دارد. بنابراین آن را در devDependencies در فضای کاری ما در فایل package.json اضافه میکند:
"ng-packagr": "^3.0.0-rc.2",
مسیر build در tsconfig.json
زمانی که example-ng6-lib را تست میکنیم عموماً میخواهیم آن را مانند یک کتابخانه ایمپورت کنیم و نه این یک مجموعه فایل دیگر را به عنوان بخشی از اپلیکیشن خود داشته باشید. به طور معمول زمانی که از یک کتابخانه شخص ثالث استفاده میکنیم از دستور npm install برای توزیع آن در پوشه node-modules بهره میگیریم.
با این حال example-ng6-lib در پوشه node-modules قرار نمیگیرد، زیرا در یک زیرپوشه در پوشه dist فضای کاری ساخته شده است. Angular CLI این پوشه را به tsconfig.json اضافه میکند تا امکان ایمپورت آن به صورت یک کتابخانه وجود داشته باشد.
مسیری که اضافه میشود به صورت زیر است:
سورسهای example-ng6-lib
پوشه src کتابخانه ما در مسیر projects/example-ng6-lib قرار دارد. در این کتابخانه Angular CLI یک ماژول جدید با یک سرویس و یک کامپوننت میسازد. ضمناً اگر دقت کنیم چند فایل دیگر نیز به شرح زیر وجود دارند:
- package.json: این همان فایل package.json است که به صورت خاص برای کتابخانه ما طراحی شده است. این فایلی است که به همراه کتابخانه ما به صورت یک پکیج npm منتشر میشود. زمانی که افراد کتابخانه ما را با استفاده از npm نصب کنند، این مورد به عنوان وابستگی آن ذکر خواهد شد.
- public_api.ts: این فایل به عنوان فایل مدخل ما است. این فایل بخشهایی از کتابخانه که از دید بیرونی قابل مشاهده هستند را مشخص میسازد. اکنون شاید بپرسید آیا این وظیفه دستور export در ماژولها نیست؟ آری چنین است اما قضیه کمی پیچیدهتر از این است. ما در ادامه این موضوع را بیشتر بررسی میکنیم.
نکته: در Angular CLI 7.3 این فایل به public-api.ts تغییر نام یافته است.
- ng-package.json: این همان فایل پیکربندی برای ng-packagr است. در زمان قدیم ما باید با محتوای آن آشنا میبودیم. اینک به لطف Angular CLI کافی است بدانیم که به ng-packagr اعلام میکند کجا میتواند فالی مدخل را پیدا کند و کجا باید کتابخانه را بسازد.
build کردن کتابخانه
پیش از آن که بتوانیم از کتابخانه جدیداً ایجاد شده خود استفاده کنیم باید آن را build کنیم:
ng build example-ng6-lib
دستور فوق کتابخانه ما را در پوشه زیر میسازد:
example-ng6-lib-app\dist\example-ng6-lib
از نسخه 6.1 به بعد انگولار همواره یک build پروداکشن برای کتابخانه تولید میکند. اگر همچنان از انگولار 6.0 استفاده میکنید، باید در زمان ساخت کتابخانه از فلگ prod– استفاده کنید.
استفاده از کتابخانه در اپلیکیشن
یکی از ایدههای اصلی ساخت یک کتابخانه این است که به صورت معمول اپلیکیشنی داریم که به همراه کتابخانه ساخته میشود و با استفاده از آن میتوانیم کتابخانه را تست کنیم. در مثال مورد بررسی، اپلیکیشن ساخته شده example-ng6-lib-app نام دارد که به همراه کتابخانه مورد استفاده قرار خواهیم داد.
در ادامه یک تست ساده با استفاده از کتابخانه در example-ng6-lib-app اجرا میکنیم. به این منظور ماژول example-ng6-lib را ایمپورت میکنیم. سپس کامپوننت پیشفرض را که Angular CLI برای ما در کتابخانه ساخته است نمایش میدهیم.
ایمپورت کردن ماژول example-ng6-lib
در ادامه AppModule را در مسیر src\app\app.module.ts اصلاح میکنیم. ExampleNg6LibModule را به آرایه impoerts اضافه کنید. IDE شما احتمالاً فکر میکند که این کار به تلاش برای ایمپورت کردن مستقیم فایل کمک میکند. اما شما نباید این کار را انجام دهید، بلکه باید ماژول را در اپلیکیشن با استفاده از نام کتابخانه به صورت زیر ایمپورت کنید:
import { ExampleNg6LibModule } from 'example-ng6-lib';دلیل این که دستور فوق کار میکند این است که وقتی کتابخانه را با نامش ایمپورت میکنیم، Angular CLI ابتدا به مسیرهای tsconfig.json و سپس به مسیرهای node_modules نگاه میکند.
نکته: همواره در اپلیکیشن تست کتابخانه را با نام و نه با فایلهای منفرد ایمپورت کنید.
فایل app.module.ts شما اینک باید چیزی مانند زیر باشد:
نمایش دادن کامپوننت example-ng6-lib
برای این که همه چیز ساده بماند کافی است کامپوننت تولیدشده پیشفرض را از کتابخانه خود به قالب AppComponent در مسیر اضافه کنیم. کافی است نیمه پایینی قالب AppComponent را با کد زیر عوض کنید:
<enl-example-ng6-lib></enl-example-ng6-lib>
اینک فایل src\app\app.component.html باید چیزی مانند زیر باشد:
اجرای اپلیکیشن
همانند همیشه میتوانیم اپلیکیشن خود را با اجرای دستور زیر اجرا کنیم:
ng serve
اینک اگر به مسیر زیر در مرورگر برویم:
http://localhost:4200/
با نتیجه تست کامپوننت خود از کتابخانه مواجه میشویم:

بسط کتابخانه
اکنون که میدانیم چگونه کتابخانههایی برای خودمان بسازیم و اپلیکیشنها را با استفاده از کامپوننتهایی از این کتابخانهها اجرا کنیم، نوبت آن رسیده است که کتابخانه خود را بسط دهیم و ببینیم در کامپوننتهای دیگر چه کارهایی میتوانیم انجام دهیم. مراحل کار به شرح زیر هستند:
- یک کامپوننت جدید در کتابخانه خود ایجاد کنید.
- این کامپوننت را به ماژول exports کتابخانه اضافه کنید.
- کامپوننت را به فایل مدخل اضافه کنید.
- کتابخانه را پس از ایجاد تغییرات فوق مجدداً build کنید.
- از کامپوننت جدید در اپلیکیشن خود استفاده کنید.
ایجاد یک کامپوننت کتابخانه
زمانی که کامپوننتی برای کتابخانه خود میسازیم از فلگ –project برای اعلام این نکته به Angular CLI استفاده میکنیم که میخواهیم این کامپوننت را در پروژه کتابخانه خود ایجاد کنیم. در ادامه یک کامپوننت ساده به نام foo در کتابخانه خود ایجاد میکنیم:
ng generate component foo --project=example-ng6-lib
Angular CLI کارهایی که انجام داده است را دقیقاً به ما گزارش میدهد:
CREATE projects/example-ng6-lib/src/lib/foo/foo.component.html (22 bytes) CREATE projects/example-ng6-lib/src/lib/foo/foo.component.spec.ts (607 bytes) CREATE projects/example-ng6-lib/src/lib/foo/foo.component.ts (257 bytes) CREATE projects/example-ng6-lib/src/lib/foo/foo.component.css (0 bytes) UPDATE projects/example-ng6-lib/src/lib/example-ng6-lib.module.ts (347 bytes)
اکنون یک کامپوننت جدید در کتابخانه خود داریم و Angular CLI نیز آن را به آرایه declarations ماژول کتابخانه در فایل زیر اضافه کرده است:
projects\example-ng6-lib\src\lib\example-ng6-lib.module.ts
اکسپورت کردن کامپوننت از ماژول کتابخانه
ما باید کامپوننت Foo را به اکسپورتهای ماژول کتابخانه اضافه کنیم. اگر این کار را نکنیم با خطای تحلیل قالب مواجه میشویم که در زمان تلاش برای گنجاندن کامپوننت در اپلیکیشن خطایی به صورت زیر اعلام میکند:
"enl-foo" is not a known element
بنابراین در فایل example-ng6-lib.module.ts، اقدام به افزودن FooComponent به آرایه exports میکنیم. اینک ExampleNg6LibModule باید چیزی مانند زیر باشد:
افزودن کامپوننت به فایل مدخل
همچنان که پیشتر اشاره کردیم، پروژه کتابخانه ما یک «فایل مدخل» (entry file) دارد که API عمومی آن را به صورت زیر تعریف میکند:
projects\example-ng6-lib\src\public_api.ts
ما باید خط زیر را به فایل مدخل اضافه کنیم تا به ng-packagr اعلام کنیم که این کلاس کامپوننت باید برای کاربران کتابخانه افشا شود:
export * from './lib/foo/foo.component';
شاید فکر کنید که این کار زائد است، چون ما قبلاً کامپوننت خود را در export های ماژول قرار دادهایم. این گفته صحیح است که عنصر <enl-foo></enl-foo> در قالب اپلیکیشن ما حتی بدون افزودن به فایل مدخل قابل استفاده است. اما کلاس FooComponent خودش نیز نمیتواند اکسپورت شود.
اگر تست زیر را اجرا کنید موضوع را بهتر متوجه میشوید. یک ارجاع به کلاس FooComponent به نام fooComponent: FooComponent; اضافه کنید. در فایل app.component.ts فایل foo.component را به فایل مدخل اضافه نکنید. سپس کتابخانه را مجدداً build کنید. زمانی که دستور ng serve را وارد کنید به سرعت با خطای زیر مواجه میشوید:
Module has no exported member 'FooComponent'
بنابراین قاعده کار چنین است که در مورد کامپوننتها باید از export برای پدیدار ساختن عنصر استفاده کرد و همچنین آن را به فایل مدخل اضافه کرد تا کلاس نمایانی ایجاد شود.
پس از افزودن خط کد لازم برای کامپوننت جدید، فایل مدخل public_api.ts باید مانند زیر باشد:
build مجدد کتابخانه
پس از این که تغییرات لازم داده شد، باید کتابخانه خود را با دستور زیر مجدداً build کنیم:
ng build example-ng6-lib
ما این کار را به صورت دستی اجرا میکنیم. با این حال Angular CLI نسخه 6.2 یک کارکرد build افزایشی ارائه کرده است. هر بار که فایلی تغییر مییابد Angular CLI یک build جزئی اجرا میکند که فایلهای اضافه شده را ملحق میکند. برای استفاده از این کارکرد نظارتی جدید باید از دستور زیر استفاده کنید:
ng build example-ng6-lib –watch
استفاده از کامپوننت کتابخانه جدید
در نهایت عنصر <enl-foo></enl-foo> را به عنوان خط آخر فایل app.component.html اضافه کنید. این فایل باید اینک چیزی مانند زیر باشد:
دستور ng serve را اجرا کنید و به آدرس زیر در مرورگر بروید:
http://localhost:4200/

چنان که میبینید کامپوننت جدید کتابخانه که خودمان ساحتیم نیز کار میکند.
بدین ترتیب به پایان بخش اول این راهنمای ساخت کتابخانههای انگولار میرسیم. در بخش بعدی با روش ساخت، پکیج کردن و استفاده عملی از کتابخانهها در اپلیکیشنهای دیگر آشنا خواهیم شد.
منبع: فرادرس
آموزش داکر (Docker) — مجموعه مقالات مجله فرادرس
کانتینرها برای بهبود امنیت، بازتولیدپذیری، و مقیاسپذیری در توسعه نرمافزار و علم داده بسیار مفید هستند. ظهور آنها به عنوان یکی از روندهای مهم فناوری امروز محسوب میشود. داکر (Docker) یک پلتفرم برای توسعه، توزیع و اجرای اپلیکیشنها درون کانتینرها محسوب میشود، بدین ترتیب داکر اساساً مترادف با کانتینرسازی است. اگر یک توسعهدهنده نرمافزار یا دانشمند داده هستید و یا میل دارید باشید، باید بدانید که داکر در آینده شغلی شما نقشی حیاتی خواهد داشت. بنابراین پیشنهاد میکنیم مجموعه مقالات آموزش داکر را که در ادامه معرفی کردهایم حتماً مطالعه کنید.
این مقاله به شما کمک میکند تا با کلیات مفاهیم داکر آشنا شوید. در این مقاله مفاهیم کانتینر، ماشین مجازی، ایمیج داکر، داکرفایل و رجیستری داکر را توضیح دادهایم. همچنین روش کدنویسی با داکر مورد بررسی قرار گرفته است.
در این نوشته برخی از اصطلاحات تخصصی اکوسیستم داکر در دو بخش اصطلاحهای مقدماتی و اصطلاحهای پیشرفته مورد بررسی قرار گرفتهاند. در بخش مقدماتی با عبارتهای پلتفرم داکر، موتور داکر، Daemon داکر، Volume-های داکر، رجیستری داکر، هاب داکر و ریپازیتوری داکر آشنا میشویم. در بخش پیشرفته نیز مفاهیمی همچون شبکهبندی داکر، داکر کامپوز، داکر سوارم و سرویسهای داکر معرفی شدهاند. همچنین در انتهای این مقاله فناوری Kubernetes توضیح داده شده است.
در این بخش از سری مقالات آموزش داکر به طور کامل در مورد «داکرفایلها» (Dockerfiles) توضیح داده شده است. در این مقاله میتوانید با دهها دستورالعمل داکرفایل که مورد بررسی قرار گرفتهاند، آشنا شوید. لیستی از دستورهای داکرفایل و توضیح آنها که در این مقاله مورد بررسی قرار گرفتهاند به شرح زیر است:
- FROM – یک ایمیج مبنا (والد) تعریف میکند.
- LABEL – متادیتا ارائه میکند و مکان مناسبی برای گنجاندن اطلاعات فراداده است.
- ENV – یک متغیر محیطی دائمی را تعیین میکند.
- RUN – یک دستور را اجرا میکند و یک لایه ایمیج ایجاد میکند. از آن برای نصب بستهها درون کانتینرها استفاده میشود.
- COPY – همه فایلها و دایرکتوریها را به کانتینر کپی میکند.
- ADD – فایلها و دایرکتوریها را به کانتینر کپی میکند و میتواند فایلهای محلی rar. را از حالت فشرده خارج کند.
- CMD – یک دستور و آرگومانهایی برای یک کانتینر اجرایی ارائه میکند. پارامترها میتوانند لغو شوند. تنها یک CMD میتواند وجود داشته باشد.
- WORKDIR – دایرکتوری کاری برای دستورالعملهایی که در ادامه میآید تعیین میشود.
- ARG – یک متغیر تعریف میکند که در زمان ساخت به داکر ارسال میشود.
- ENTRYPOINT – یک دستور و آرگومانهایی برای یک کانتینر اجرایی ارائه میکند. آرگومانها دائمی هستند.
- EXPOSE – یک پورت را باز (افشا) میکند.
- VOLUME – یک نقطه نصب دایرکتوری تعیین میکند که به دادههای دائمی دسترسی دارد و آنها را ذخیره میکند.
شما میتوانید با استفاده از دستورهای فوق تقریباً همه کارهای مورد نظرتان را با کانتینرهای داکر انجام دهید.
در این مقاله با روش افزایش سرعت چرخههای بیلد داکر و ایجاد ایمیجهای سبک آشنا میشویم. در واقع در این مقاله بررسی کردهایم که چگونه میتوانیم داکرفایلهای خود را طراحی کنیم که در زمان توسعه ایمیجها و دریافت کانتینرها در وقت خود صرفهجویی کنیم. از جمله سازوکارهایی که در این مقاله مورد بررسی قرار گرفتهاند شامل کش کردن، کاهش اندازه، بیلد های چندمرحلهای، dockerignore و بازبینی اندازه است.
در این بخش از این سلسله مطالب آموزشی نگاهی خواهیم داشت به 15 مورد از دستورهای داکر که هر توسعهدهندهای باید بداند. داکر دستورهای بسیار زیادی دارد. با این که صفحه مستندات داکر وسیع است؛ اما در نگاه اول سردرگمکننده به نظر میرسد. در این مقاله برخی دستورهای کلیدی که برای اجرای داکر مورد نیاز هستند را معرفی میکنیم. این دستورها در سه دسته دستورهای مرتبط با کانتینر، دستورهای مرتبط با ایمیج و دستورهای متفرقه دستهبندی شدهاند.
آموزش داکر (بخش ششم) — به زبان ساده
در این بخش از سری مقالات آموزش جامع داکر که در واقع بخش نهایی محسوب میشود به بررسی کاربرد دادهها در داکر میپردازیم. در این مطلب به طور خاص روی Volume-ها در داکر متمرکز شدهایم. از جمله مباحث مطرح شده در این مقاله روش کار با دادههای موقت و دادههای دائمی در کانتینرها، معرفی مفهوم «والیوم» (Volume)، روش ایجاد والیوم، دستورهای CLI در ارتباط با والیوم و کار با mount– یا volume– را مورد بررسی قرار دادهایم.
سخن پایانی
بدین ترتیب به پایان این مطلب با عنوان معرفی مجموعه مقالات آموزش جامع داکر در مجله فرادرس رسیدیم. داکر به عنوان نسل جدیدی از مفاهیم مجازیسازی سیستم عامل به روشی سبک و کارآمد، رفته رفته نقش و جایگاه واقعی خود را در صنعت نرمافزار کسب میکند و به طور قطع در آینده شاهد رشدی بهمراتب افزونتر خواهیم بود. البته داکر تنها فناوری کانتینرسازی اپلیکیشنها محسوب نمیشود؛ اما بیشک در ردیف یکم این فهرست قرار دارد و فاصله زیادی با رقبا ایجاد کرده است. دلیل این فاصله علاوه بر قدمت بیشتر داکر در عواملی همچون داشتن جامعه گستردهتر و عملکرد بالاتر آن نهفته است. در هر حال اگر در هر زمینهای از حوزه نرمافزار مشغول به کار هستید، پیشنهاد میکنیم مجموعه مقالات آموزشی فوق را مطالعه کنید.
منبع: فرادرس
زبان برنامه نویسی #C و هفت دلیل مهم برای یادگیری آن — راهنمای کاربردی
انتخاب زبان برنامهنویسی برای یادگیری میتواند امر دشواری باشد. زبانهای مختلف هر کدام برای مقاصد مختلفی طراحی شدهاند و تعیین یک مجموعه اهداف میتواند در این انتخاب کمک شایان توجهی بکند. اگر میخواهید برنامهنویسی را بیاموزید؛ اما در مورد مسیری که باید طی کنید مطمئن نیستید، پیشنهاد میکنیم تا آخر این مقاله با ما همراه باشید. چندین زبان وجود دارند که صرف نظر از این که میخواهید در آینده چه کاری بکنید، حتماً باید آنها را بیاموزید. این احتمال وجود دارد که در مسیر حرفهای خود بخواهید بیش از یک زبان برنامهنویسی را یاد بگیرید؛ اما شروع کار با یادگیری زبان #C ایده خوبی است. سؤال این است که چرا باید #C را نسبت به زبانهای دیگر ترجیح بدهیم؟
#C از کجا میآید؟
![]()
#C یک زبان برنامهنویسی سطح متوسط رو به بالا است که از سوی مایکروسافت توسعه و در سال 2000 انتشار یافته است. مایکروسافت سرمایهگذاری زیادی روی توسعه این زبان در سالهای بعدی کرده است. این زبان بر مبنای زبانهای C و ++C ساخته شده است؛ اما طراحی آن برای سهولت استفاده بوده است و کتابخانههای گستردهای برای اجرای وظایف متفاوت دارد.
مایکروسافت این زبان را به عنوان زبان رسمی فریمورک NET. خود طراحی کرده است. هر چیزی که در فریمورک NET. نوشته شده باشد در ویندوز اجزا میشود و بدین ترتیب #C به یکی از زبانهای رسمی توسعه ویندوز تبدیل شده است. با معرفی NET Core. ،سی شارپ اینک برای ساخت اپلیکیشنهای macOS، لینوکس و حتی «رزبری پای» (Raspberry Pi) نیز استفاده میشود.
1. یادگیری زبان #C آسان است
علیرغم این که سی شارپ مشابه زبانهای با یادگیری دشوار C و ++C نامگذاری شده، اما برای مبتدیها بسیار مناسبتر است. برنامهنویسی #C شیءگرا است و به این ترتیب یادگیری آن برای افراد مبتدی آسانتر است.
با این که خوانایی این زبان برای سهولت کار افراد مبتدی به قدر کافی روان است، اما طرحبندی و کارکردهای #C، آن را به زبانی عالی برای دریافت درک وسیعتری از برنامهنویسی به عنوان یک کلیت تبدیل کرده است.
#C از نظر امنیت نیز زبان مناسبی برای یادگیری محسوب میشود. زبانهای سطح پایین مانند C و ++C تقریباً هر دستورالعملی را تا زمانی که بتوانند کامپایل کنند، اجرا میکنند. این زبانها حتی دستورالعملهایی که موجب آسیب جدی به سیستم عامل میشود را میتوانند اجرا کنند. در نقطه مقابل #C کد را در زمان کامپایل بررسی میکند و در صورت بروز مشکل با صدور هشدارها و خطاها از وقوع این وضعیت جلوگیری میکند.
همچنین #C به جای تخصیص و آزادسازی حافظه برای دادهها، به مدیریت خودکار حافظه میپردازد. بدین ترتیب دیگر لازم نیست نگران باشیم که محاسبات سطح پایین موجب دشواری مسیر یادگیری زبان سی شارپ برای افراد مبتدی خواهد شد.
2. #C جامعه آنلاین بزرگی دارد
یادگیری #C هرگز آسانتر از امروز نبوده است. علاوه بر مستندات عظیم و کاملاً نگهداری شده مایکروسافت، جامعه بزرگی از مدرسان آنلاین نیز برای این زبان وجود دارد. ویدئوهای یوتیوب و بلاگها همه جنبههای برنامهنویسی #C را از مبتدی تا پیشرفته پوشش میدهند.
آکادمی مجازی مایکروسافت (+) نیز دورههای آموزشی رسمی برای زبان #C و توسعه برنامههای ویندوز و برای دستگاههای موبایل ارائه میکند. وبسایت Stack Overflow که مهمترین مرجع کدنویسها محسوب میشود به زبان #C نوشته شده است و از این رو جای شگفتی نیست که جامعه عظیمی از برنامهنویسان این زبان روی این وبسایت وجود دارد.
3. از سوی مایکروسافت پشتیبانی میشود
در زمان نگارش این مقاله #C بر اساس آمار وبسایت مرجع PyPL (+) چهارمین زبان محبوب دنیا بوده است. PyPL اختصاری برای عبارت «شاخص محبوبیت زبانهای برنامهنویسی» (PopularitY of Programming Language Index) است. در وبسایت کاریابی indeed.com (+) نیز این زبان در سال 2018 ششمین زبان پر تقاضا بوده است. بدین ترتیب پیشبینی میشود که سی شارپ با کمک پشتیبانی مایکروسافت تا مدتهای مدیدی با کاهش تقاضا مواجه نخواهد شد.
این زبان به مدت 20 سال است که به طور مداوم در حال توسعه است و هر زمان ویژگیهای جدیدی به آن اضافه میشوند. #C میتواند از کتابخانه قدرتمند LINQ استفاده کند و برای کنترل سطح بالای ساختمان داده و اشیا در کد طراحی شده است. به طور خلاصه، این زبان به منظور کمک به برنامهنویسان جهت انجام کارهای روزمره طراحی شده است.
ویژوال استودیو که محیط توسعه یکپارچه یا IDE مایکروسافت است به زبان #C نوشته شده است. با این که میتوان با استفاده از هر زبانی در ویژوال استودیو برنامهنویسی کرد؛ اما استفاده بهینه آن برای توسعه #C است.
4. توسعه بازی Unity
![]()
برای بسیاری از افراد نقش اصلی #C، زبانی برای استفاده در موتور بازی Unity است. محبوبیت یونیتی مداوماً در حال افزایش است و این موتور به طور مداوم پا به پای موتور Unreal که استاندارد صنعت بازیسازی محسوب میشود حرکت میکند. دلیل این مسئله آن است که یونیتی برای استفاده توسعهدهندگان کوچک رایگان است.
استفاده از #C به عنوان یک زبان برنامهنویسی نیز در مقایسه با زبان سریعتر، اما دشوارتر ++C که از سوی Unreal استفاده میشود، بسیار گسترده است.
یونیتی یادگیری آسانی نیز دارد و جامعه آنلاین بزرگ آن با آموزشهای یوتیوب، مطالب فورومها و وبلاگها غنی شده است. افراد زیادی #C را از طریق Unity و در مسیر ساخت نخستین بازی خود یاد میگیرند. ماهیت مبتنی بر پروژه توسعه بازی همراه با ذات مبتنی بر هدف آن باعث شده که روشی عالی برای ارتقای تجربه افراد مبتدی در زمینه یادگیری #C باشد.
5. ساخت نرمافزارهای چند پلتفرمی

ویندوز همچنان در میان بازار سیستمهای عامل بالاترین سهم را دارد. #C اینک نزدیک به 20 سال است که برای ساخت اپلیکیشنهای ویندوزی روی فریمورک NET. مورد استفاده قرار میگیرد. زبان مایکروسافت و ابزارهای توسعهای مانند ویژوال استودیو بیشک بهترین روش برای طراحی اپلیکیشنها برای ویندوز هستند.
مایکروسافت اخیراً NET Core. را به عنوان نسخه سادهشدهای از فریمورک NET. معرفی کرده است که رایگان بوده و نصب آن آسان است و امکان توسعه چند پلتفرمی را میدهد. این بدان معنی است که توسعهدهندگان اکنون میتوانند با استفاده از آن اپلیکیشنهای کنسول و وب را برای هر سیستم عاملی بنویسند.
6. ASP.NET و ASP.NET Core

ASP.NET دومین فریمورک بزرگ بکاند روی اینترنت محسوب میشود و تنها رقیب آن PHP است. ASP.NET سرویس اپلیکیشن مایکروسافت برای صفحههای وب دینامیک است و #C زبان اصلی مورد استفاده برای برنامهنویسی فریمورک ASP.NET است.
شما به عنوان یک برنامهنویس #C باید با فریمورک ASP.NET برای ایجاد API-های وب جهت ارسال داده به صورت دینامیک به کاربران وبسایت خود کار کنید.
انتشار NET Core. به ASP.NET نیز گسترش یافته است. نسخه Core مربوط به ASP.NET موجب ایجاد انعطافپذیری هر چه بیشتری در توسعه وب شده است، چون روی هر پلتفرمی کار میکند. اکنون به جای این که بکاند خود را روی ویندوز و برای ویندوز سرور بسازید، میتوانید با استفاده از MVC ارائه شده از سوی ASP.NET Core وبسایتهایی را روی macOS یا لینوکس برای هر سروری خلق کنید.
7. توسعه و ساخت اپلیکیشنها برای اندروید و iOS
![]()
توسعه اپلیکیشنهای اندروید معمولاً در جاوا صورت میپذیرد. در مورد توسعه اپلیکیشنهای iOS نیز باید از Swift یا Objective C استفاده کنید. این بدان معنی است که اگر میخواهید اپلیکیشنی برای هر دو پلتفرم بسازید باید دو زبان مجزا را بیاموزید. Xamarin برای مقابله با این مشکل طراحی شده است.
این فریمورک امکان کدنویسی در زبان #C را میدهد و اپلیکیشن نهایی را برای سیستمهای عامل اندروید و iOS کامپایل میکند. این به آن معنی است که شما میتوانید از همان کد روی هر دو پلتفرم استفاده کنید و اپلیکیشنها را از کد پایه یکسانی بهروزرسانی کنید. علاوه بر این که کد شما برای هر دو اپلیکیشن در زبان مشترکی نوشته شده است، Xamarin امکان طراحی GUI برای هر یک از پلتفرمها را نیز میدهد.
بدین ترتیب زمانی که اپلیکیشن مربوطه عملیاتی شد، میتوانید یک رابط کاربری برای آن طراحی کنید تا کاربران هر دو پلتفرم اندروید و iOS از آن بهره بگیرند.
سخن پایانی
#C یک زبان برنامهنویسی قوی و قابل توسعه است که تقاضای زیادی برای آن وجود دارد. از هر مسیری که #C را بیاموزید، در هر حال مهارتهای ضروری زیادی را فرا میگیرید که کاربردهای بسیار متفاوتی برای آنها وجود دارد. در این مقاله به بررسی مزیتهای یادگیری #C پرداختیم؛ اما گزینههای خوب دیگری نیز وجود دارند. جاوا اسکریپت بیشک پادشاه فرانتاند اینترنت است. از سوی دیگر پایتون به دلیل کاربردی که در یادگیری ماشین دارد، میتواند زبان آینده برنامهنویسی به ح
منبع: فرادرس
ساخت یک چت بات (Chatbot) پایتون با NLTK — از صفر تا صد
گارتنر به عنوان بزرگترین شرکت تحقیقات و مشاوره دنیا، پیشبینی کرده است که تا سال 2020، چتباتها 85 درصد از تعاملهای بین مشتری-سرویس را مدیریت خواهند کرد. چتباتها هم اینک در حدود 30 درصد از این تراکنشها را مدیریت میکنند. در این مقاله با روش ساخت یک چتبات پایتون به کمک پکیج NLTK آشنا خواهیم شد.
احتمالاً تاکنون نام Duolingo به گوش شما خورده است. این اپلیکیشن محبوب یک روش یادگیری زبان از طریق تمرین بازیگونه زبان جدید ارائه کرده است. دلیل محبوبیت آن سبکهای نوآورانه تدریس زبان خارجی محسوب میشود. مفهوم کار ساده است: پنج تا ده دقیقه تمرین تعاملی در روز برای یادگیری یک زبان کافی است.
با این وجود علیرغم این که Duolingo به افراد امکان یادگیری یک زبان جدید را داده است؛ اما کاربران آن یک دغدغه دارند. افراد حس میکنند که چیزی را در خصوص یادگیری مهارتهای محاورهای ارزشمند از دست دادهاند، زیرا زبان را به صوت کاملاً مستقل آموختهاند. همچنین این افراد در مورد مکالمه با دیگر یادگیرندگان آن زبان دچار واهمه هستند، زیرا از عدم اعتمادبهنفس رنج میبرند. مشخص شده است که این یک تنگنای بزرگ در نقشههای Duolingo محسوب میشود.
بدین ترتیب تیم آنها این مسئله را از طریق ساخت یک چتبات بومی داخل اپلیکیشن حل کرد. این چتبات به کاربران کمک میکند که مهارتهای محاورهای را بیاموزند و آن چه را که آموختهاند تمرین کنند.
از آنجا که رباتها به صورت محاورهای و دوستانه طراحی شدهاند، یادگیرندگان Duolingo میتوانند هر زمان در طی روز با آنها گفتگو کنند و از شخصیتهایی که خودشان استفاده میکنند بهره بگیرند تا این که آن قدر شجاعت پیدا بکنند که زبان جدیدشان را با گویشوران دیگر نیز تمرین کنند. بدین ترتیب یکی از دغدغههای اصلی مشتریان حل و یادگیری از طریق این اپلیکیشن بسیار جالبتر شد.
چتبات چیست؟
یک «چتبات» (chatbot) در واقع نوعی نرمافزار بهره گرفته از هوش مصنوعی روی یک دستگاه (مانند Siri ،Alexa ،Google Assistant و غیره)، اپلیکیشن، وبسایت یا دیگر شبکهها است که تلاش میکند نیازهای مشتری را سنجیده و سپس به آنها در اجرای وظایف خاص مانند تراکنش تجاری، رزرو هتل، تحویل فرم و غیره کمک کند. امروزه تقریباً همه شرکتها یک چتبات را مورد استفاده قرار میدهند تا به ارزیابی کاربران بپردازند. برخی از روشهایی که شرکتها از چتباتها استفاده میکنند به شرح زیر هستند:
- ارائه اطلاعات پرواز
- اتصال مشتریها و حسابهای مالی
- پشتیبانی از مشتری
- امکانات بهرهگیری از چتباتها (تقریباً) نامحدود است.
تاریخچه چتباتها به سال 1966 بازمیگردد که یک برنامه رایانهای به نام ELIZA از سوی Weizenbaum اختراع شد. این چتبات، زبان یک رواندرمانگر را با تنها 200 خط کد تقلید میکرد. شما میتوانید در این آدرس (+) با الیزا صحبت کنید.
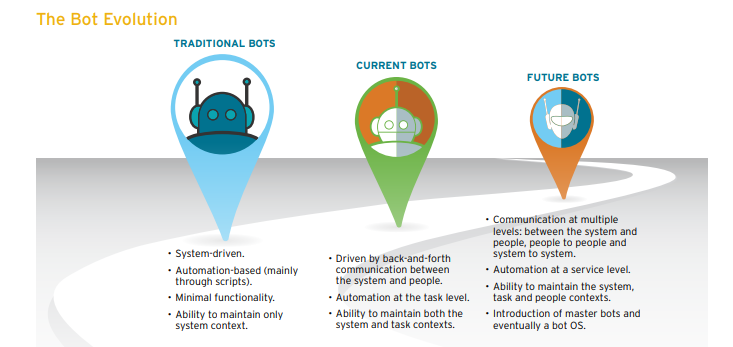
چتبات چگونه کار میکند؟
به طور عمده دو نسخه از چتبات وجود دارد که یکی «مبتنی بر قواعد» (Rule-Based) و دیگری «خودآموز» (Self Learning) است.
- ربات در یک رویکرد مبتنی بر قواعد، به سؤالات بر مبنای برخی قواعد که برای آنها آموزش دیده است پاسخ میدهد. این قواعد ممکن است بسیار ساده و یا بسیار پیچیده تعریف شده باشند. این رباتها میتوانند کوئریهای ساده را مدیریت کنند؛ اما در مدیریت کوئریهای پیچیده ناتوان هستند.
- رباتهای «خودآموز» آنهایی هستند که از برخی رویکردهای مبتنی بر یادگیری ماشین استفاده میکنند و قطعاً بسیار کارآمدتر از رباتهای مبتنی بر قواعد هستند. این رباتها خود میتوانند بر دو نوع باشند: «مبتنی بر بازیابی» (Retrieval Based) و یا «تولیدی» (Generative).
مدلهای مبتنی بر بازیابی
در این مدلها یک چتبات از نوعی شهود برای انتخاب یک پاسخ از کتابخانهای از پاسخهای از پیش تعریفشده اقدام میکند. این چتبات از پیام و زمینه مکالمه برای انتخاب بهترین پاسخ از یک فهرست از پیش تعریف شده از پیامهای ربات استفاده میکند. زمینه گفتگو میتواند شامل موقعیت کنونی در یک درخت گفتگو، همه مکالمههای قبلی در گفتگو، متغیرهای ذخیره شده قبلی (مانند نامهای کاربری) و موارد دیگر باشد. شهود برای انتخاب پاسخها میتواند به روشهای مختلفی مهندسی شود که از منطق شرطی if-else مبتنی بر قواعد تا روشهای طبقهبندی یادگیری ماشین متفاوت است.
مدلهای تولیدی
رباتها میتوانند پاسخها را تولید هم بکنند و لازم نیست که همواره از میان یک مجموعه از پاسخهای از پیش تعریف شده انتخاب کنند. این وضعیت موجب میشود که آنها به موجودات هوشمندی تبدیل شوند و با انتخاب کلمه به کلمه از کوئری، پاسخها را تولید کنند.
در این مقاله ما یک چتبات ساده مبتنی بر بازیابی به وسیله کتابخانه NLTK پایتون میسازیم.
ساخت ربات
در این بخش مراحل مورد نیاز برای ساخت ربات توضیح داده شدهاند.
پیشنیازها
فرض شده است که شما دانش ابتدایی در مورد کتابخانه scikit و NLTK دارید. با این وجود اگر در حوزه NLP مبتدی هستید، همچنان میتوانید از این مقاله بهره بگیرید و سپس به منابع بازگردید.
NLP
این رشته مطالعاتی روی تعاملهای بین زبان انسانی و رایانهها تمرکز دارد و «پردازش زبان طبیعی» (Natural Language Processing) یا به اختصار NLP نامیده میشود. این حوزه از علم در تقاطع بین علوم رایانه، هوش مصنوعی و زبانشناسی رایانشی قرار میگیرد. NLP روشی است که رایانهها استفاده میکنند تا زبان انسانی را به روشی هوشمندانه و مفید، تحلیل، درک و معنایابی کنند. توسعهدهندهها با بهرهگیری از NLP میتوانند دانش اجرای وظایفی مانند خلاصهسازی خودکار، ترجمه، شناسایی موجودیتهای نامدار، استخراج رابطه، تحلیل احساسی، بازشناسی گفتار و دستهبندی موضوعی را به دست آورند.
مقدمه مختصری در خصوص NLTK
NLTK که اختصاری برای عبارت «کیت ابزار زبان طبیعی» (Natural Language Toolkit) است یک پلتفرم پیشرو برای ساخت برنامههای پایتون با دادههای زبان انسانی محسوب میشود. این پلتفرم اینترفیسهای سهلالاستفادهای برای بیش از 50 منبع متنی و واژگانی مانند WordNet ارائه میکند و مجموعهای از کتابخانههای پردازش متن برای طبقهبندی، توکن سازی، «ریشهیابی» (stemming)، تگ گذاری، تجزیه و استدلال احساسی و پوششهایی برای کتابخانههای NLP قدرتمند ارائه میکند.
NLTK به نام «یک ابزار شگفتانگیز برای یادگیری و کار در زمینه زبانشناسی رایانشی در پایتون» و «یک کتابخانه عالی برای کار با زبان طبیعی» توصیف شده است.
کتاب پردازش زبان طبیعی در پایتون (+) یک مقدمه عملی برای برنامهنویسی پردازش زبان ارائه کرده است. مطالعه این کتاب را برای افرادی که قصد آغاز کار با NLP در پایتون را دارند، توصیه میکنیم.
دانلود و نصب NLTK
برای نصب NLTK دستور زیر را اجرا کنید:
pip install nltk
با اجرای دستورهای زیر میتوانید از صحت نصب مطمئن شوید:
python import nltk
نصب پکیجهای NLTK
NLTK را ایمپورت و دستور زیر را اجرا کنید:
nltk.download()
دستور فوق دانلود کننده NLTK را باز میکند و در این بخش میتوانید مجموعه متون و مدلهایی که میخواهید دانلود کنید را انتخاب نمایید. همچنین میتوانید همه پکیجها را به یک باره انتخاب کنید.
پیشپردازش متن با NLTK
مشکل اصلی در دادههای متنی این است که کلاً در قالب متن (String) هستند. با این حال، الگوریتمهای یادگیری ماشین به نوعی بردار ویژگی عددی نیاز دارند تا بتوانند وظایف خود را اجرا کنند. بنابراین پیش از آغاز کار روی هر پروژه NLP باید آن را پیشپردازش کنیم تا برای کار مناسبسازی شود. مراحل مقدماتی پیشپردازش شامل موارد زیر هستند:
- تبدیل کل متن به حالت حروف بزرگ یا حروف کوچک. بدین ترتیب الگوریتم با کلمه یکسان در حالتهای مختلف، به روش متفاوتی برخورد نمیکند.
- توکن سازی: توکن سازی اصطلاحی است که برای توصیف فرایند تبدیل رشتههای متنی معمولی به فهرستی از توکنها یعنی کلماتی که در عمل میخواهیم گفته میشود. توکن ساز جمله میتواند برای یافتن فهرستی از جملهها و توکن ساز کلمه میتواند برای یافتن فهرستی از کلمات در رشته استفاده شود.
پکیجهای داده NLTK شامل توکنسازهای از پیش آموزش دیده Punkt برای زبان انگلیسی هستند.
- حذف Noise: هر چیزی که یک حرف یا عدد استاندارد نباشد از متن حذف میشود.
- حذف Stop Words: در برخی موارد کلمات بسیار متداول که به ظاهر ارزش بسیار کمی در کمک به انتخاب سندها و تطبیق نیازهای کاربر دارند به کلی از واژهنامه حذف میشوند. این کلمهها به نام Stop words نامیده میشوند.
- «ریشهیابی» (Stemming): ریشهیابی فرایندی است که در آن کلمات مشتق شده یا دارای پسوند به شکل بن یا ریشه خود تبدیل میشوند که عموماً شکل نوشتاری کلمه است. برای ارائه مثالی از ریشهیابی باید بگوییم که اگر بخواهیم کلمههای Stems ،Stemming ،Stemmed و Stemtization را ریشهیابی کنیم به کلمه stem میرسیم.
- «بنواژهسازی» (Lemmatization): این روش نسخه کمی متفاوت از ریشهیابی است. تفاوت اصلی بین این دو آن است که در ریشهیابی در اغلب موارد میتوان کلمات ناموجود به دست آورد، در حالی که بنواژهها کلماتی واقعی هستند. بنابراین کلمه ریشهیابی شده که در انتهای فرایند ریشهیابی به دست میآید، ممکن است چیزی نباشد که بتوان آن را در یک فرهنگ لغت پیدا کرد؛ اما بنواژه را حتماً میتوان در واژهنامهها پیدا کرد. نمونههایی از بنواژهسازی کلمه run است که بنواژهای برای کلماتی مانند running یا ran است و همچنین کلماتی مانند better یا good در بنواژه مشترکی قرار دارند و از این رو دارای بنواژه مشترکی محسوب میشوند.
کیسه کلمات (Bag of Words)
پس از مرحله ابتدایی پیشپردازش متن باید آن را به یک بردار (یا آرایهای) معنیدار از اعداد تبدیل کنیم. کیسه کلمات یک بازنمایی از متن محسوب میشود که به توصیف رخداد کلمهها درون یک سند میپردازد. این مدلسازی دو نکته دارد:
- یک واژهنامه از کلمههای شناختهشده
- معیاری از وجود کلمههای شناختهشده
شاید از خود بپرسید چرا آن را «کیسه» کلمات مینامیم؟ دلیل این امر آن است که در این فاز هر اطلاعاتی در مورد ترتیب یا ساختار کلمهها در سند حذف میشود و مدل تنها به بررسی این نکته میپردازد که آیا کلمه شناختهشده مفروض در سند موجود است و محل رخداد آن مهم نیست.
شهودی که در پس کیسه کلمات قرار دارد این است که سندهای متنی در صورت داشتن محتوای مشابه، مشابه نگریسته میشوند. ضمناً این که میتوانیم صرفاً از روی محتوای یک سند در مورد معنای آن نتایجی به دست آوریم.
برای نمونه اگر یک واژهنامه شامل کلمههای {Learning, is, the, not, great} باشد و بخواهیم متن «Learning is great» را بردارسازی بکنیم به بردار زیر میرسیم:
(1, 1, 0, 0, 1)
رویکرد TF-IDF
یک مشکل رویکرد کیسه کلمات این است که کلمههای با فراوانی بالا بر کل سند احاطه مییابند (یعنی امتیاز بالاتری کسب میکنند) اما ممکن است محتوای آگاهیبخش زیادی را شامل نشوند. ضمناً به سندهای طولانیتر وزن بیشتری نسبت به سندهای کوتاهتر میدهد.
یک رویکرد به این مسئله آن است که فراوانی کلمهها را برحسب این که چه مقدار در همه سندها ظاهر میشوند مقیاسبندی مجدد بکنیم و بدین ترتیب امتیازهای کلمههای با فراوانی بالا مانند the در همه سندها بالا خواهد بود و از این رو اثرشان خنثی میشود. این رویکرد به امتیازبندی به نام «فراوانی اصطلاح-معکوس فراوانی سند» (Term Frequency-Inverse Document Frequency) یا به اختصار TF-IDF نامیده میشود که در آن موارد زیر برقرار است.
Term Frequency یک امتیازبندی از فراوانی کلمه مفروض در سند کنونی است:
TF = (Number of times term t appears in a document)/(Number of terms in the document)
و Inverse Document Frequency امتیازبندی میزان نادر بودن کلمه در سندهای دیگر است:
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
وزن TF-IDF وزنی است که غالباً در بازیابی اطلاعات و متنکاوی مورد استفاده قرار میگیرد. این وزن یک معیار آماری است که برای ارزیابی میزان مهم بودن کلمه در یک سند در مجموعه متنی استفاده میشود:
مثال:
سندی را در نظر بگیرید که شامل 100 کلمه است و کلمه phone در آن 5 بار آمده است. فراوانی اصطلاح (یعنی TF) برای phone برابر با 0.05 = 100/5 است. اکنون فرض کنید سندی با 100 میلیون کلمه داریم که کله phone در هزار مورد در آن تکرار شده است. در این صورت معکوس فراوانی سند (IDF) به صورت 4 = 1000000/1000 محاسبه میشود. از این رو وزن TF-IDF نهایی برابر با 0.20 = 4 * 0.05 خواهد بود.
TF-IDF میتواند در یادگیری Scikit به صورت زیر استفاده شود:
from sklearn.feature_extraction.text import TfidfVectorizer
مشابهت کسینوس (Cosine Similarity)
TF-IDF یک تبدیل است که روی متنها اعمال میشود تا دو بردار با ارزش واقعی در فضای برداری به دست آید. سپس میتوانیم مشابهت کسینوسی هر جفت از بردارها را با انتخاب ضرب نقطهای آنها و تقسیم کردن بر حاصل نرمهایشان به دست آوریم. بدین ترتیب کسینوس زاویه بین بردارها به دست میآید. مشابهت کسینوسی معیاری برای مشابهت بین دو بردار غیر صفر محسوب میشود. با استفاده از این فرمول میتوانیم مشابهت بین دو سند d1 و d2 را به صورت زیر پیدا کنیم:
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
که d1 و d2 دو بردار غیر صفر هستند.
اکنون ایده نسبتاً جامعی از پردازش NLP داریم و زمان آن رسیده است که کار واقعی خود یعنی ایجاد یک چتبات را آغاز کنیم. ما چتبات خود را به صورت ROBO نامگذاری میکنیم.
ایمپورت کردن کتابخانههای مورد نیاز
برای ایمپورت کردن کتابخانههای مورد نیاز میتوانید از دستورهای زیر استفاده کنید:
import nltk import numpy as np import random import string # to process standard python strings
مجموعه متون
ما در خصوص مثال مورد بررسیمان از صفحه ویکیپدیا در مورد چتباتها (+) استفاده خواهیم کرد. محتوای صفحه را کپی کرده و آن را در یک فایل متنی به نام chatbot.txt قرار دهید. البته شما میتوانید از هر مجموعه متنی بنا به دلخواه خود استفاده کنید.
خواندن دادهها
ما فایل متنی chatbot.txt را میخوانیم و کل مجموعه متن را برای پیشپردازش به لیستی از جملهها و لیستی از کلمهها تبدیل میکنیم.
در ادامه مثالی از sent_tokens و word_tokens میبینید:
پیشپردازش متن خام
اکنون باید تابعی تعریف کنیم که LemTokens نام دارد و توکنها را به عنوان ورودی میگیرد و توکنهای نرمالسازی شده را بازگشت میدهد:
تطبیق کلیدواژه
سپس تابعی تعریف خواهیم کرد که وظیفه خوشامدگویی از سوی بات را بر عهده دارد، یعنی اگر یک کاربر سلام بکند، ربات در ادامه با سلام و خوشامدگویی پاسخ میدهد. ELIXA از یک تطبیق کلیدواژه ساده برای خوشامدگویی استفاده میکند. ما نیز در اینجا از مفاهیم مشابهی استفاده میکنیم.
تولید پاسخها
برای تولید یک پاسخ از سوی ربات برای سؤالهای ورودی، مفهوم مشابهت سند مورد استفاده قرار گرفته است. بدین ترتیب کار خود را با ایمپورت کردن ماژولهای مورد نیاز آغاز میکنیم.
از کتابخانه scikit learn ماژول TFidf vectorizer (+) را ایمپورت میکنیم تا یک مجموعه از سندهای خام را به ماتریسی از ویژگیهای TF-IDF تبدیل کنیم.
from sklearn.feature_extraction.text import TfidfVectorizer
همچنین ماژول cosine similarity (+) را از کتابخانه scikit learn ایمپورت میکنیم.
from sklearn.metrics.pairwise import cosine_similarity
این ماژول برای یافتن مشابهت بین کلمههای واردشده از سوی کاربر و کلمههای موجود در متن استفاده میشود. این سادهترین پیادهسازی ممکن برای یک چتبات محسوب میشود.
ما یک تابع به نام response تعریف میکنیم که رویکرد کاربر به یک یا چند مورد از کلیدواژههای شناختهشده را جستجو کرده و چند پاسخ ممکن را بازگشت میدهد. اگر مورد مطابقت ورودی برای هیچ کلیدواژهای را پیدا نکند، یک پاسخ به صورت: «متأسفم، سخن شما را درک نکردم» (I am sorry! I don’t understand you) بازگشت میدهد.
در نهایت خطوطی را که میخواهیم ربات در زمان آغاز و خاتمه مکالمه بسته به ورودی کاربر بیان کند را تعریف میکنیم.
بدین ترتیب کار ما تقریباً به پایان رسیده است. ما نخستین چتبات خود را در NLTK کدنویسی کردهایم. شما میتوانید کل کد را به همراه مجموعه متنی در این آدرس گیتهاب (+) مشاهده کنید.
کد منبع کامل چتبات ما به صورت زیر است:
اینک نوبت آن رسیده است که ببینیم ربات ما چگونه با انسانها تعامل میکند:

عملکرد آن چندان هم بد نیست. علی رغم این که چتبات نمیتواند پاسخ رضایتبخشی به برخی سئوالات بدهد، اما در مورد برخی سؤالهای دیگر به خوبی عمل میکند.
سخن پایانی
با این که چتبات ما یک ربات بسیار ساده محسوب میشود و مهارتهای شناختی آن کاملاً محدود است، اما روشی مناسب برای آشنایی با NLP و چتباتها به حساب میآید. اگر چه ROBO به ورودی کاربر پاسخ میدهد، اما نمیتوانید با آن دوستانتان را فریب بدهید و برای یک سیستم production باید به یکی از پلتفرمها یا فریمورکهای موجود مراجعه کنید. این نمونه به شما کمک میکند که در مورد طراحی و چالشهای ایجاد یک چت
منبع: فرادرس