طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیساخت ویجت گفتگوی زنده با پشتیبانی در ری اکت (React) — از صفر تا صد
فتگوی زنده یک روش پشتیبانی از مشتری است که سابقهای طولانی دارد. این روش سریع و کارآمد است چون در آن هر کارمند میتواند همزمان به مشتریان زیادی کمک بکند. بهترین نکته این است که میتوان در طی فرایند خرید به سریعترین روش ممکن به سؤالهای مشتری پاسخ داد و بدین ترتیب احتمال خرید مشتری بالاتر میرود.
در این مقاله به روش یکپارچهسازی یک گفتگوی زنده در اپلیکیشنهای React میپردازیم. قصد ما این است که شیوه یکپارچه قابلیت گفتگوی زنده در اپلیکیشن ریاکت را بدون نگرانی از نگهداری سرور گفتگو و معماری آن پیادهسازی کنیم. در ادامه تصویری از آن چه قصد داریم بسازیم را مشاهده میکنید.
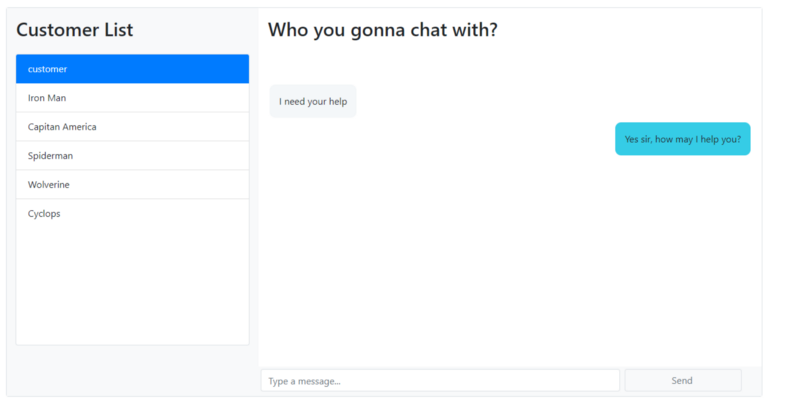
ما برای راهاندازی بخش گفتگوی اپلیکیشن خود از خدمات CometChat Pro استفاده میکنیم. CometChat Pro یک API ارتباطی قدرتمند است که امکان افزودن قابلیتهای گفتگو را به اپلیکیشن فراهم میسازد. این API با قابلیت یکپارچهسازی آسان و مستندات منظم به شما کمک میکند تا ویژگی گفتگوی زنده را با نوشتن چند خط کد به اپلیکیشن خود اضافه کنید. به این منظور ابتدا باید یک حساب رایگان در این وبسایت (+) بسازید.
ما در این راهنما علاوه بر CometChat از فناوریهای زیر نیز استفاده خواهیم کرد:
- Create React App
- react-chat-widget
- Express
- Bootstrap
- Axios
- react-md (spinner component only)
پیشنهاد ما این است که تا انتهای این راهنما همراه باشید تا گامبهگام اپلیکیشن مورد نظر خود را بسازیم، اما اگر بیش از این شتاب دارید، میتوانید کد کامل این مقاله را در این صفحه گیتهاب (+) ملاحظه کنید.
ایجاد اپلیکیشن CometChat
چنان که پیشتر گفتیم برای گنجاندن قابلیت گفتگوی زنده در اپلیکیشن از CometChat استفاده میکنیم. با این وجود، پیش از یکپارچهسازی باید ابتدا اپلیکیشن CometChat را بسازیم.
برای ایجاد یک اپلیکیشن CometChat باید به داشبورد CometChat بروید و روی آیکون + کلیک کنید. ما اپلیکیشن خود را react-chat-widget مینامیم، اما شما میتوانید اپلیکیشن خود را با هر نامی که دوست دارید ایجاد کنید.
ما دو نوع کاربر داریم که به گفتگوی ما اتصال مییابند. یک دسته مشتریهایی هستند که ویجت گفتگو را باز میکنند و دیگری کارمندان بخش پشتیبانی هستند که به گفتگو دسترسی مییابند و از طریق داشبورد به پرسوجوها پاسخ میدهند. به طور کلی «کاربر» مفهومی بنیادی در CometChat محسوب میشود.
از آنجا که ما احتمالاً مشتریان زیادی خواهیم داشت، برای هر مشتری که به گفتگو وصل میشود، باید به صورت دینامیک یک کاربر CometChat ایجاد کنیم. با این وجود از آنجا که تنها یک کارمند وجود خواهد داشت، میتوانیم یک Agent را از پیش در داشبورد ایجاد کنیم.
به این منظور در داشبورد به برگه Users بروید و روی Create User کلیک کنید:
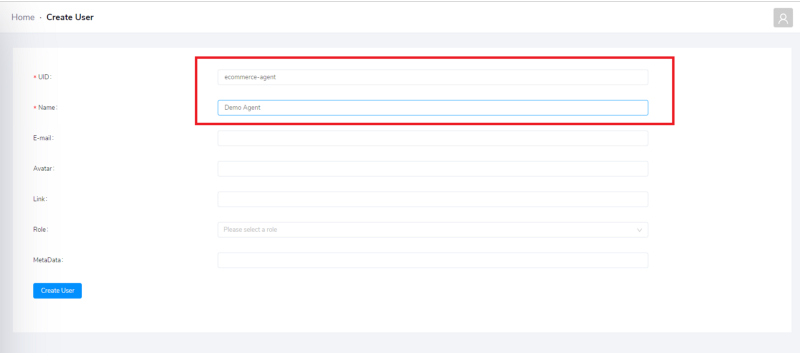
برای ID کاربر مقدار ecommerce-agent را وارد کنید و برای نام کارمند نیز مقدار Demo Agent را وارد کنید. اگر قصد دارید از مراحل این راهنما پیروی کنید، از همین نامها استفاده کنید، چون در غیر این صورت در ادامه با مشکل مواجه خواهید شد. ID کاربر را یادداشت کنید، زیرا در ادامه به آن ارجاع خواهیم داد.
پیش از آن که از داشبورد خارج شوید و به کدنویسی بپردازید، باید یک کلید دسترسی کامل CometChat نیز بسازید. در همین صفحه روی برگه API Keys و سپس روی Create API Key کلیک کنید:
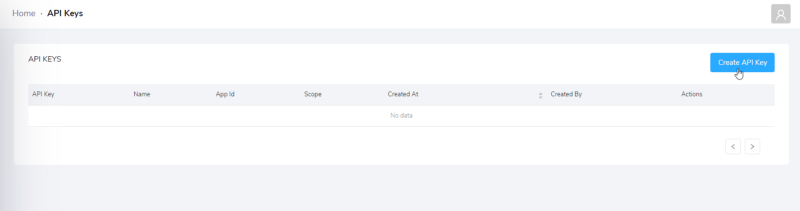
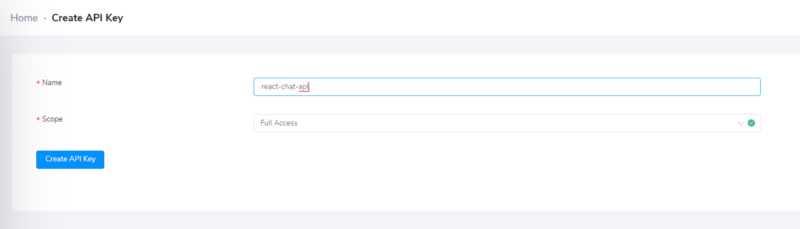
ما کلید خود را react-chat-api نامیدهایم، اما نام آن اهمیت چندانی ندارد. کلید API و ID اپلیکیشن خود را نیز مانند ID کاربر در جایی یادداشت کنید، چون در ادامه لازم خواهد شد.
راهاندازی اکسپرس
در گام قبلی یک کلید دسترسی کامل ساختیم که میتوانیم از آن برای ایجاد دینامیک CometChat استفاده کنیم. با این که میتوانیم این کار را در سمت کلاینت نیز اجرا کنیم، اما معنی آن این خواهد بود که کلید دسترسی کامل خصوصی خود را در معرض دسترس عموم قرار میدهیم که کار نادرستی است. برای جلوگیری از این مشکل یک سرور اکسپرس میسازیم که شرایط زیر را داشته باشد:
- کاربر CometChat را با استفاده از کلید دسترسی کامل بسازد.
- توکنهای احراز هویت را بازگشت دهد (در ادامه بیشتر توضیح خواهیم داد)
- لیستی از کاربران CometChat برای استفاده بعدی در داشبورد بازگشت دهد.
اینک نوبت آغاز کار است. ابتدا یک دایرکتوری خالی جدید برای اپلیکیشن اکسپرس خود ایجاد میکنیم و دستور npm init -y را اجرا میکنیم:
mkdir react-express-chat-widgetcd react-express-chat-widgetnpm init –y
سپس اکسپرس و axios را نصب میکنیم:
npm install express axios
سپس در فایلی به نام server.js کد زیر را وارد میکنیم:
در فایل فوق موارد زیر وجود دارند:
- اطلاعات هویتی اپلیکیشن و ID کاربر پاسخگو که قبلاً ایجاد کردیم ذخیره میشوند.
- UIRL مربوط به API-ی CometChat برای دسترسی راحتتر تعریف میشود.
- یک شیء headers که با استفاده از appID و apiKey ایجاد میشود. ما این هدر را به همراه هر درخواست CometChat ارسال میکنیم.
در همین فایل اکنون یک مسیر تعریف میکنیم تا ایجاد کاربران جدید CometChat را مدیریت کنیم. برای ایجاد یک کاربر جدید باید یک درخواست POST را با UID و نام کاربر ارسال کنیم.
در این راهنما، نام یکسانی را برای همه مشتریان به صورت hard-code مینویسیم، یعنی همه مشتریها را «customer» مینامیم، اما UID آنها باید یکتا باشد. برای UID میتوانیم از تابع POST برای ایجاد ID-های یکتا استفاده کنیم.
کد زیر را به فایل server.js اضافه کنید:
زمانی که این مسیر فراخوانی شود، اکسپرس کارهای زیر را انجام میدهد:
- یک درخواست POST به آدرس https://api.cometchat.com/v1/users با headers صحیح و اطلاعاتی در مورد کاربر جدید ارسال میکند.
- توکن احراز هویت را برای کاربر جدید واکشی میکند.
- و در نهایت آن را به فراخواننده بازمیگرداند.
ما همچنین یک تابع به نام requestAuthToken میسازیم تا به واکشی کردن توکن احراز هویت کمک کند. سپس در همان فایل یک مسیر احراز هویت میسازیم که آن را برای ایجاد توکن جهت کاربران بازگشتی فراخوانی خواهیم کرد:
در نهایت یک تابع برای بازگشت لیستی از کاربران ایجاد کرده و agent یا همان کارمند پشتیبانی را از آن حذف میکنیم. ما این endpoint را متعاقباً از داشبورد فراخوانی میکنیم تا لیستی از کاربران را که agent میتواند با آنها صحبت کند نمایش دهیم. البته کارمند ما نمیتواند با خودش صحبت کند و از این رو خودش را از لیست فیلتر میکنیم:
در انتهای فایل server.js، سرور را اجرا میکنیم:
اگر از ابتدای این مقاله با ما همگام بوده باشید، اینک فایل Server.js باید به صورت زیر در آمده باشد:
در یک پنجره ترمینال دستور node server.js را اجرا کنید و منتظر باشید تا پیامی به صورت زیر نمایش یابد:
Listening on port 5000
اکنون باید زمان مناسبی برای تست endpoint-ها به همراه curl یا Postman باشد تا مطمئن شویم که کار میکنند و سپس به بخش کدنویسی کلاینت بپردازیم.
راهاندازی اپلیکیشن React
درون دایرکتوری خود دستور npx create-react-app را اجرا کنید تا ساختار اولیه یک اپلیکیشن ریاکت ایجاد شود:
npx create-react-app client
ساختار پوشه شما اینک باید مانند زیر باشد:
|-- express-react-chat-widget |-- package-lock.json |-- package.json |-- server.js |-- client |--.gitignore |-- package-lock.json |-- package.json |-- public |-- src
زمانی که اپلیکیشن ریاکت آماده شد، به دایرکتوری client بروید و ماژولهای زیر را نصب کنید:
cd clientnpm install @cometchat-pro/chat react-chat-widget react-router-dom bootstrap react-md-spinner
اپلیکیشن Create React برای bootstrap کردن یک اپلیکیشن ریاکت کاملاً مفید است، اما فایلهای زیادی تولید میکند که مورد نیاز ما نیستند و اینها شامل فایلهای تست و از این دست هستند. پیش از اقدام به کدنویسی، همه چیز را از دایرکتوری client/src حذف کنید تا از صفر کار خود را شروع کنیم. برای شروع یک فایل config.js با ID اپلیکیشن و UID کارمند در مسیر client/src/config.js با محتوای زیر بسازید:
این کد مبنایی است که میتوان برای ارجاع به اطلاعات احراز هویت CometChat از هر کجا مورد استفاده قرار داد. با این که ما آن را کد مبنا مینامیم، اما این فرصت را نیز داریم که یک فایل index.css بسازیم:
ما این فایل را در ادامه از داشبورد مورد ارجاع قرار میدهیم. اکنون در فایل با نام index.js کد زیر را درج کنید:
در این کد ما Bootstrap ،CometChat و فایل پیکربندی را که پیش از مقداردهی اولیه CometChat و رندر کردن App ساختهایم ایمپورت میکنیم. اگر در این راهنما با ما همگام بوده باشید، متوجه شدهاید که ما هنوز App را تعریف نکردهایم. بنابراین در این مرحله این کار را انجام میدهیم. در فایل به نام App.js کد زیر را درج کنید:
در این کد ما دو مسیر را تعریف کردیم:
- مسیر / یا Customer home جهت برقراری اتصال با کارمند پشتیبانی است.
- و مسیر agent/ یا Agent Dashboard برای دسترسی سریع و راحت به داشبورد تعریف شده است.
در ادامه ابتدا کامپوننت در دید مشتری را بررسی میکنیم. ما آن را کامپوننت کلاینت مینامیم.
ایجاد کامپوننت کلاینت
کامپوننت کلاینت ما دو مسئولیت عمده خواهد داشت:
- ایجاد یک کاربر CometChat جدید از طریق سرور Express در زمانی که نخستین مشتری وصل میشود.
- ارسال و دریافت پیامها به صورت آنی.
یک فایل به نام Client.js بسازید و کد زیر را در آن درج کنید:
اگر فکر میکنید این کد حجم بالایی دارد جای نگرانی نیست چون در ادامه آن را جزء به جزء توضیح میدهیم.
تابع render به قدر کافی ساده است، در واقع وظیفه اصلی آن رندر کردن react-chat-widget است. بخش زیادی از کد اختصاص به مدیریت پیام جدید ارسالی از سوی مشتری در تابعی به نام handleNewUserMessage دارد.
به طور خلاصه، ابتدا باید بررسی کنیم که آیا UID مشتری در localStorage وجود دارد یا نه. اگر چنین باشد، از این UID برای لاگین کردن کاربر و ارسال پیام استفاده میکنیم. در غیر این صورت تابع ()createUser را فراخوانی میکنیم و از مقدار بازگشتی برای لاگین کردن کاربر استفاده میکنیم. این تابع createUser یک endpoint را فراخوانی میکند که قبلاً در همین راهنما تعریف کردیم.
در نهایت در یک تابع چرخه عمر ریاکت componentWillUnmount را فرا میخوانیم و به خاطر میسپاریم که شنونده پیام را حذف کنیم. پیش از ادامه باید به یک نکته کوچک اشاره کنیم. در کد فوق، به جای وارد کردن URL سرور و پورت آن (localhost:5000/users) یا چیزی مانند آن در فرانتاند، میتوانیم یک گزینه proxy به فایل package.json اضافه کنیم. بدین ترتیب میتوانیم به جای localhost:5000/users// صرفاً از /users استفاده کنیم:
"browserslist": [">0.2%"، "not dead"، "not ie <= 11"، "not op_mini all"]،"proxy": http://localhost:5000
در این مرحله اپلیکیشن مانند زیر خواهد بود:
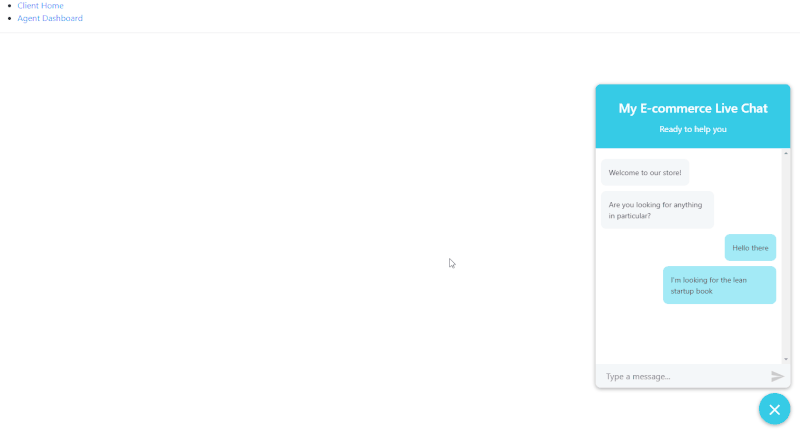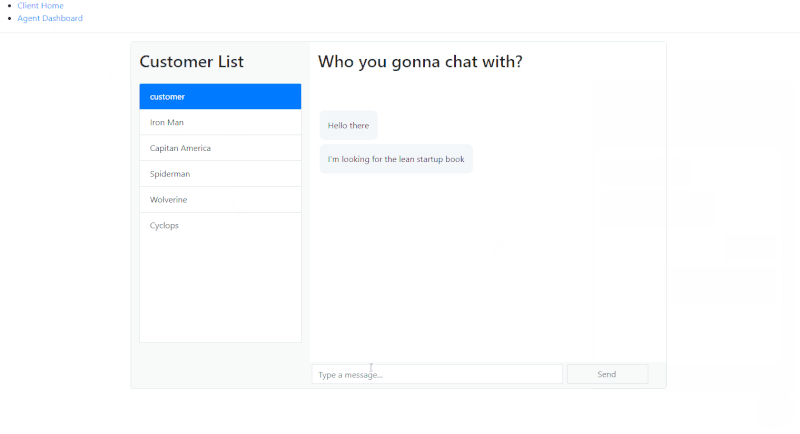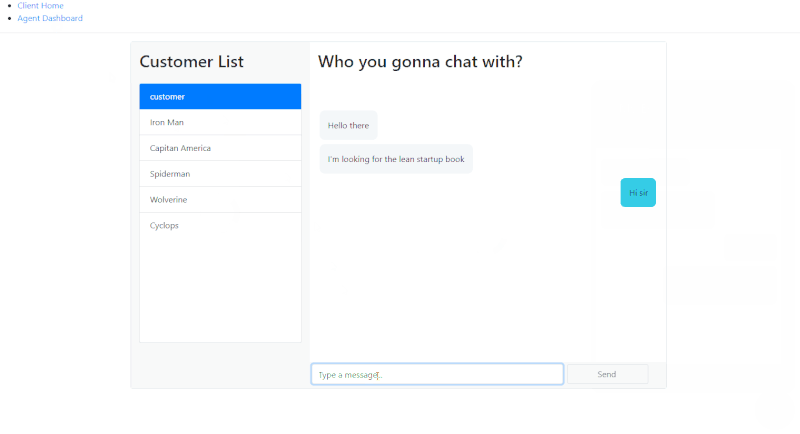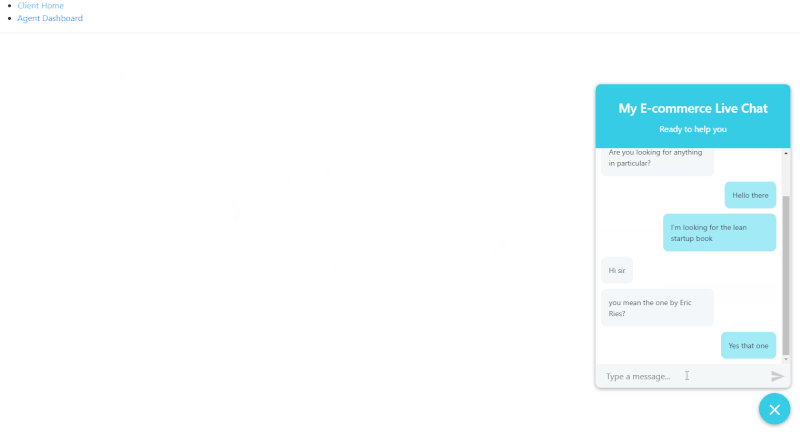
چنان که مشاهده میکنید، میتوان پیامها را ارسال یا دریافت کرد، اما اگر صفحه را رفرش کنیم، پیامهای گفتگو ناپدید میشوند و این خوب نیست.
برای حل این مشکل یک متد componentDidMount تنظیم میکنیم که به دنبال UID مشتری در localStorage میگردد، به طوری که وقتی مشتریان صفحه را رفرش بکنند، میتوانند گفتگو را از همان جایی که مانده بود ادامه دهند.
زمانی که UID را پیدا کردیم، میتوانیم از آن برای مقداردهی اولیه یک زنجیره از متدها جهت login ،fetch کردن پیامهای قبلی و ایجاد listener برای پیامهای ورودی استفاده کنیم.
اکنون اگر صفحه را رفرش کنیم، اپلیکیشن تلاش خواهد کرد در CometChat لاگین کند و پیامهای قبلی را به صورت خودکار با گشتن به دنبال UID مشتری در localStorage بارگذاری کند و این وضعیت مناسبی محسوب میشود.
اما همچنان مشکل کوچکی وجود دارد. چنان که مشخص شد، هنوز راهی برای کارمند پشتیبانی وجود ندارد که به پیام مشتری پاسخ دهد. ما این مشکل را از طریق ساختن داشبورد کارمند حل میکنیم. در این حالت کارمند میتواند به پیامهای گفتگو که از سوی مشتریان میرسند پاسخ دهد. بدن ترتیب کار ما در فایل Client.js به پایان میرسد و در ادامه به ساخت فایل Agent.js میپردازیم.
ایجاد کامپوننت agent
منبع: فرادرس
۱۱ ترفند بسیار کاربردی جاوا اسکریپت — به زبان ساده
زمانی که شروع به یادگیری جاوا اسکریپت میکنید، باید یک فهرست از همه ترفندهایی که موجب صرفهجویی در زمان میشوند تهیه کنید. این فهرست از ترفندهای جاوا اسکریپت میتواند از مواردی که در کد افراد دیگر مشاهده میشود، از چالشهای کدنویسی در وبسایتها و از هر جای دیگر به دست آید.
در این نوشته فهرستی از 11 نکته این چنین را ارائه میکنیم که همگی به خاطر وجود یک جنبه ذکاوت یا مفید بودن جمعآوری شدهاند. این مطلب برای افراد مبتدی بسیار مفید است؛ اما امید میرود که حتی توسعهدهندگان در سطح متوسط جاوا اسکریپت نیز در این فهرست، نکات جدیدی را مشاهده کنند.
با این که بسیاری از این ترفندها در هر زمینهای مفید هستند؛ اما چند مورد از آنها بیشتر برای نوشتن با حداکثر خلاصهسازی مفید هستند تا کدی که برای محیط توزیع نهایی مناسب است، چون در محیط production وضوح و خوانایی کد بسیار مهمتر از فشردگی آن است. قضاوت در مورد این خصوصیتها را بر عهده شما میگذاریم.
بنابراین فهرست زیر بدون هیچ ترتیب خاصی، 11 روش نوشتن کدهای فشردهتر و با عملکرد بالاتر را در اختیار شما قرار میدهد.
1. فیلتر کردن مقادیر یکتا (Arrays)
نوع شیء set در ES6 معرفی شده است و میتوان از آن به همراه عملگر spread (…) برای ایجاد یک آرایه جدید با استفاده صرف از مقادیر یکتا بهره گرفت.
تا پیش از ES6 جداسازی مقادیر یکتا نیاز به کد بسیار بیشتر از این داشت.
این ترفند برای آرایههایی که شامل انواع ابتدایی یعنی undefined ،null ،boolean ،string و number هستند مناسب است. اگر آرایهای دارید که شامل اشیا، تابعها یا آرایههای دیگر است به رویکرد متفاوتی نیاز دارد.
2. ارزیابی اتصال کوتاه (CONDITIONALS)
عملگر سهتایی روشی سریع برای نوشتن گزارههای شرطی ساده (و گاهی اوقات نه چندان ساده) به صورت زیر است:
اما در پارهای موارد حتی عملگر سهتایی نیز بیش از حد ضرورت پیچیده است. به جای آن میتوان از عملگرهای منطقی and (&&) و or (||) برای ارزیابی عبارتهای خاص به روشی فشردهتر استفاده کرد. این وضعیت غالباً به نام «اتصال کوتاه» یا «ارزیابی اتصال کوتاه» نامیده میشود.
ارزیابی اتصال کوتاه چگونه کار میکند؟
فرض کنید میخواهیم تنها یک یا دو گزینه را بازگشت دهیم. با استفاده از && نخستین مقدار false یا کاذب بازگشت مییابد. اگر همه عملوندها به صورت true ارزیابی شوند، آخرین عبارت ارزیابیشده بازگشت مییابد.
استفاده از عملگر || نخستین مقدار true یا صادق را بازگشت میدهد. اگر همه عملوندها false ارزیابی شوند، آخرین عبارت ارزیابیشده بازگشت مییابد.
مثال اول
تصور کنید میخواهیم length یک متغیر را پیدا کنیم؛ اما نوع متغیر را نمیدانیم. در این شرایط میتوان از گزاره if/else برای بررسی این که متغیر foo از نوع قابل قبول باشد استفاده کرد؛ اما این رویکرد بسیار طولانی است. «ارزیابی اتصال کوتاه»، امکان این کار را به صورت زیر فراهم میسازد:
اگر متغیر foo صادق باشد، این عبارت مقدار بازگشتی خواهد داشت، در غیر این صورت length آرایه خالی به صورت 0 بازگشت مییابد.
مثال دوم
آیا کنون با مسائلی سر و کار داشتهاید که بخواهید به مشخصه یک شیء تودرتو دسترسی پیدا کنید؟ ممکن است ندانید که آن شیء یا یکی از مشخصههای فرعی آن وجود دارند یا نه و این وضعیت منجر به خطاهای ناگواری میشود.
تصور کنید میخواهیم به یک مشخصه به نام data درون this.state دسترسی پیدا کنیم؛ اما data تا زمانی که برنامه ما یک درخواست واکشی را با موفقیت بازگشت نداده است، تعریف نشده است.
فراخوانی this.data.state بسته به این که در کجا از آن استفاده کنیم، میتواند از اجرای اپلیکیشن ما جلوگیری کند. برای حل این مشکل میتوانیم آن را درون یک گزاره شرطی قرار دهیم:
اما این وضعیت کاملاً مفصل به نظر میرسد. عملگر or یک راهحل بسیار فشردهتر ارائه میکند:
نمیتوان کد فوق را برای استفاده از && «بازسازی» (refactor) کرد. گزاره زیر:
'Fetching Data' && this.state.data
مقدار this.data.state را چه تعریف شده باشد و یا نباشد، بازگشت میدهد. دلیل این امر آن است که ‘Fetching Data’ صادق است و از این رو && زمانی که در ابتدا قرار گیرد همواره از آن رد میشود.
پیشنهاد یک ویژگی جدید: زنجیرهسازی اختیاری
در حال حاضر پیشنهاد شده است که «زنجیرهسازی اختیاری» (Optional Chaining) در زمان تلاش برای بازگشت یک مشخصه از اعماق ساختارهای شبه درختی مورد استفاده قرار گیرد. در این پیشنهاد علامت سؤال (?) میتواند برای استخراج مشخصه تنها در صورتی قابل استفاده است که null نباشد.
برای نمونه، میتوانیم مثال فوق را طوری به صورت this.state.data?. () بازسازی کنیم که data تنها در صورتی بازگشت یابد که null نباشد.
همچنین اگر دغدغه اصلی ما در مورد این باشد که آیا state تعریف شده یا نه، میتوانیم this.state?.data را بازگشت دهیم. این پیشنهاد هنوز در مرحله 1 و به عنوان یک ویژگی آزمایشی است. البته شما میتوانید از طریق Babel و از طریق افزودن babel/plugin-proposal-optional-chaining@ به فایل babelrc. از آن استفاده کنید.
3. تبدیل به بولی (TYPE CONVERSION)
جاوا اسکریپت علاوه بر مقادیر معمول بولی true و false با همه مقادیر دیگر به صورت «صادق» (truthy) یا «کاذب» (falsy) برخورد میکند. همه مقادیر در جاوا اسکریپت به جز 0، “” ،null ،undefined ، NaN و البته false صادق هستند.
میتوان به سادگی بین مقادیر true و false با استفاده از عملگر منفی (!) سوئیچ کرد. این عملگر نوع متغیر را نیز به Boolean تغییر میدهد.
این نوع از تبدیل نوع در گزارههای شرطی بسیار کارآمد است؛ اما شاید تنها هدف از این که بخواهیم false را به صورت 1! تعریف کنیم، این است که میخواهیم کدمان تا حد امکان فشرده باشد.
4. تبدیل به رشته (TYPE CONVERSION)
برای تبدیل سریع یک عدد به رشته، میتوان از عملگر الحاق + و سپس یک مجموعه تهی از علامت نقل قول “” استفاده کرد.
5. تبدیل به عدد (TYPE CONVERSION)
متضاد حالت قبل زمانی است که بخواهیم یک متغیر رشته را به عدد تبدیل کنیم و در این مورد میتوانیم از یک عملگر جمع + استفاده کنیم.
این وضعیت برای تبدیل مقادیر بولی به اعداد به صورت زیر نیز قابل استفاده است:
ممکن است برخی زمینهها باشند که + به جای عملگر جمع به عنوان عملگر الحاق تفسیر شود. زمانی که این اتفاق میافتد (و میخواهید یک عدد صحیح و نه اعشاری بازگشت یابد) میتوانید از دو کاراکتر مد ~~ استفاده کنید.
یک کاراکتر مد که به نام «عملگر NOT بیتی» نیز شناخته میشود؛ عملگر معادل n — 1- است. از این رو برای مثال، 15~ معادل 16- است.
استفاده از دو کاراکتر مد ~~ پشت سر هم موجب منفی شدن عملیات میشود و از این رو محاسبه زیر صورت میگیرد:
به بیان دیگر 16-~ برابر با 15 است.
گرچه این عملیات کاربردهای زیادی ندارد؛ اما عملگر NOT بیتی روی مقادیر بولی به صورتهای زیر نیز قابل استفاده است:
true = -2~ false = -1~
6. توان سریع (OPERATIONS)
از ES7 به بعد امکان استفاده از عملگر نمایی ** به عنوان یک میانبر برای توان فراهم شده است که روش سریعتری برای نوشتن (Math.pow(2, 3 است. این دستور سرراستی محسوب میشود؛ اما موجب سردرگمی میشود، زیرا اغلب راهنماها برای معرفی این عملگر بهروزرسانی نشدهاند!
این عملگر نباید با عملگر ^ اشتباه گرفته شود که به طور معمول برای نمایش نماها استفاده میشود؛ چون در جاوا اسکریپت عملگر ^ برای نمایش عملگر XOR بیتی استفاده میشود.
تا پیش از ES7 این میانبر تنها برای توانهای در پایه 2 وجود داشت که با استفاده از عملگر شیفت چپ بیتی >> عمل میکرد:
برای نمونه
2 << 3 = 16
معادل عبارت زیر است:
2 ** 4 = 16
7. تبدیل سریع Float به Integer
اگر بخواهید یک مقدار Float را به Integer تبدیل کنید، میتوانید از ()Math.floor() ،Math.ceil یا ()Math.round استفاده کنید. اما روش سریعتری نیز برای کاهش یک مقدار اعشاری به صحیح با استفاده از | وجود دارد که عملگر OR بیتی است.
رفتار | بسته به این که با مقادیر مثبت یا منفی سروکار داشته باشد متفاوت خواهد بود، بنابراین بهتر است تنها در صورتی که مطمئن هستید از آن استفاده کنید.
اگر n مثبت باشد، n | 0 موجب گرد شدن مطمئن عدد n میشود. اگر n منفی باشد، باز به طرز مؤثری گرد میشود. برای این که موضوع روشنتر شود، باید گفت که این عملیات هر آن چه را که پس از ممیز اعشاری میآید حذف میکند و بدین ترتیب عدد اعشاری به یک عدد صحیح تبدیل میشود.
همان تأثیر گرد کردن از طریق استفاده از ~~ فوق نیز میسر است و در واقع هر عملگر بیتی میتواند یک مقدار اعشاری را به مقدار صحیح تبدیل کند. دلایل عملکرد صحیح این عملیات خاص آن است که زمانی روی یک عدد صحیح اعمال میشود، مقدار آن بدون تغییر باقی میماند.
حذف ارقام نهایی
عملگر OR بیتی میتواند برای حذف هر تعداد از ارقام از انتهای یک عدد صحیح نیز استفاده شود. این بدان معنی است که لازم نیست از کدی مانند زیر برای تبدیل بین نوعها استفاده کنیم:
به جای آن عملگر OR بیتی امکان نوشتن کدی به صورت زیر را به ما میدهد:
8. اتصال خودکار در کلاسها (CALSSES)
میتوان از نماد Arrow در ES6 برای متدهای کلاس استفاده کرد و بدین ترتیب binding اعمال میشود. این حالت در اغلب موارد موجب صرفهجویی چندین خط از کد در سازنده کلاس میشود و میتواند پایانی بر عبارتهای تکراری مانند گزاره زیر باشد:
this.myMethod = this.myMethod.bind(this)
9. کوتاه کردن یک آرایه (ARRAYS)
اگر میخواهید مقادیری را از انتهای یک آرایه به روش مخربی حذف کنید، جایگزینهای سریعتر از ()splice نیز وجود دارند. برای نمونه اگر اندازه آرایه اصلی را میدانید، میتوانید مشخصه طول آن را به صورت زیر بازتعریف کنید:
این یک راهحل فشرده است. با این وجود، زمان اجرای متد ()slice میتواند از این هم سریعتر باشد. اگر سرعت هدف اصلی شما است، میتوانید از چیزی مانند زیر استفاده کنید:
10. دریافت آخرین آیتمها در یک آرایه (ARRAYS)
متد ()slice آرایه میتواند اعداد صحیح منفی نیز بپذیرد و در این حالت مقادیر را به جای ابتدا از انتهای آرایه میگیرد.
11. قالببندی کد JSON
در نهایت احتمالاً تاکنون از JSON.stringify استفاده کردهاید؛ اما آیا متوجه شدهاید که این متد میتواند به ایجاد تورفتگی در JSON نیز کمک کند؟ متد ()stringify دو پارامتر اختیاری میگیرد، یکی تابع replacer است که برای فیلتر کردن JSON نمایش یافته استفاده میشود و دیگری مقدار space است.
مقدار space یک عدد صحیح میگیرد که تعداد فاصلهها یا رشتهای (مانند ‘t\’ برای درج tab) هست که قرار میگیرد و موجب میشود که خواندن دادههای JSON واکشی شده بسیار آسانتر شود.
1 2 3 4 5 6 | console.log(JSON.stringify({ alpha: 'A', beta: 'B' }, null, '\t')); // Result: // '{ // "alpha": A, // "beta": B // }' منبع: فرادرس |
ریاضیات لازم برای برنامه نویسی — پادکست پرسش و پاسخ
پرسشی که برای بسیاری از افراد علاقهمند به یادگیری برنامهنویسی مطرح میشود، آن است که آیا نیازی به یادگیری ریاضیات دارند؟ و یا اینکه، اگر برای یادگیری برنامهنویسی به ریاضیات نیاز دارند، کدام مباحث را باید بیاموزند و از کجا باید شروع کنند. دکتر «سید مصطفی کلامی هریس»، در پادکستی که در ادامه آمده، به این پرسش به طور مشروح پاسخ داده و به مبحث ریاضیات لازم برای برنامه نویسی پرداخته است. نسخه متنی این پادکست نیز در همین مطلب قرار دارد. البته، منبع اصلی همچنان فایل صوتی محسوب میشود.
پادکست پیرامون ریاضیات لازم برای برنامه نویسی
ذخیره کردن این فایل صوتی: لینک دانلود
نسخه نوشتاری
یکی از دوستان سوالاتی را با توجه به این موضوع پرسیدهاند که من همواره تاکید میکنم، برنامهنویسی بدون ریاضیات نمیشود. ایشان پرسیدهاند که از کجا باید یادگیری را شروع کنیم؟ افرادی که ریاضیات آنها ضعیف است چه کاری باید انجام دهند و در نهایت اینکه، کدام مباحث ریاضی برای برنامهنویسی از اهمیت بیشتری برخوردار هستند. باید توجه داشت که اصلا در برنامهنویسی و به طور کلی در این فضا، مهمتر از چیزی که فرد هست، چیزی است که میتواند باشد. در بحث ریاضیات نیز، مهمتر از چیزی که فرد در حال حاضر بلد است، چیزی است که میتواند بیاموزد و ذهن ایشان پذیرش آن را دارد. فردی که فضای «الگوریتمیک» (algorithmic) را توانسته درک بکند، فکر نرمافزاری دارد.
چنین فردی اگر مشکلی در ریاضیات دارد، مشکل او در واقع از نحوه آموزش است. یعنی اگر فرد واقعا درک کاملی از مثلا یک زبان برنامهنویسی دارد، با مفاهیم برنامهنویسی خوب ارتباط برقرار کرده است و با این وجود، همچنان ریاضیات ضعیفی دارد، باید گفت که اینجا اشکال از سیستم آموزشی و یک بخشی از اشکال شاید از خود فرد باشد که به اندازه کافی روی این موضوع وقت نگذاشته است. پس در واقع، «من نمی توانم» نداریم.
مطمئنا اگر فرد در حال حاضر برنامهنویسی میکند، در ریاضیات هم میتواند مشکلات خود را حل کند. اما در پاسخ به این سوال که چطور و از کجا باید شروع کنیم، حقیقتا باید گفت که این امر برای افراد مختلف متفاوت است. نمیشود یک نسخه واحد را برای همه پیچید؛ اما، یکی از راهکارها میتواند حل مساله باشد. ولی حل مسائلی که اغلب شما در یک کلاس و دوره برنامهنویسی با آنها مواجه نمیشوید. سعی کنید دید ریاضی را کسب کنید، ولی بلافاصله در محیط یک برنامه آنها را پروش دهید و یک برنامه بنویسید که آن مساله را حل کند. حالا یک روش این است که فرد این مساله را روی کاغذ حل کند؛ خب این یک دانش ریاضی است و فرد این را باید در نهایت یاد بگیرد و اجتناب ناپذیر هم محسوب میشود.
حالا میتوان حل این مساله را روی کاغذ انجام داد و یا انجام آن را با برنامهنویسی به کامپیوتر سپرد. این، همان دانشی است که فرد به آن نیاز دارد؛ یعنی چیزی فراتر از بلد بودن یک مساله ریاضی است. میتوان از مسائل خیلی ساده هم شروع کرد. مثلا من در «دوره آموزشی جاوا»، محاسبه «شاخص توده بدنی» (Body mass index | BMI) را انجام دادم که نرخ سلامتی یک نفر را با توجه به قد و وزن او، نشان میدهد. خب BMI فرمول سادهای دارد؛ اما این دید ریاضی را شما باید داشته باشید. به عنوان مثالی دیگر، میتوان به مساله محاسبه اقساط یک وام اشاره کرد که میتوان با زبانهای برنامهنویسی گوناگون آن را حل کرد و پیادهسازی مربوط به آن را انجام داد. با بهرهگیری از برنامهنویسی، از این محاسبات ساده ریاضی گرفته تا یک بحث پیچیده را میتوان انجام داد.
مثلا فرض کنید که از گوشه یک کاغذ، عکسی را گرفتهاند. عمود که نیست؛ این امر موجب میشود که زاویه قائمه کاغذ، در عکس قائمه دیده نشود. زاویه قائمه است، ولی به خاطر زاویه دوربین، قائمه بودن دیده نمیشود یا بعضی چیزها دوران پیدا میکنند. این را چطور میتوان اصلاح کرد؟ این یک مساله هندسی و در واقع یک مساله ریاضی است که ریشه آن برای مثال به ماتریسها باز میگردد. شما باید کار با ماتریسها و محاسبات ماتریسی را بلد باشید تا بتوانید این مساله را حل کنید و این موضوع نیاز به مطالعاتی دارد. گاهی هم خیلی از مسائل تبدیل میشوند به یک گراف، یعنی شما باید مساله را به شکل یک مساله ریاضی توصیف کنید و بعد، پیدا کردن یک مسیر روی گراف یک پاسخ برای مساله فرد میشود که نمونه آن را میتوان در بسیاری از «موتورهای جستجو» (Search Engines) و «سیستمهای توصیهگر» (Recommender system) مشاهده کرد.
منبع: فرادرس
آموزش برنامه نویسی سوئیفت (Swift): مفهوم ژنریک ها (Generics) – بخش سیزدهم
در بخش قبلی این سری مقالات آموزش سوئیفت در مورد اسامی مستعار نام، مشاهدهگرهای مشخصه و تفاوت self با Self صحبت کردیم. اما زمانی که به توضیح Self رسیدیم، مشاهده کردیم که ابتدا باید مفهوم ژنریک را در زبان سوئیفت روشنتر بکنیم. برای مطالعه بخش قبلی به لینک زیر مراجعه کنید:
از سوی دیگر صحبت کردن در مورد ژنریکها بدون اشاره به Self کار دشواری است. پروتکلها نیز میتوانند از Self جهت گسترش کارکردهای خود بهره بگیرند. با این حال در اغلب مقالات میبینیم که یکراست به موضوع ژنریکها یا پروتکلها پرداخته شده و بهیکباره هر سه موضوع موردبررسی قرار گرفته است.
البته درک این مفاهیم برای نویسندهای که قبلاً با آنها به خوبی آشنا بوده آسان است؛ اما خوانندهای که میخواهد صرفاً یکی از قابلیتهای زبان سوئیفت را بشناسد در این زمینه با مشکل مواجه خواهد شد. این مشکل در زمینههای دیگر فناوری نیز رخ میدهد. برخی موارد برای توسعهدهنده یا مدیر آسان هستند و کاربر در آنها دچار مشکل میشود و یا برعکس.
ژنریک
احتمالاً تاکنون زمانی که مشغول کدنویسی سوئیفت بودهاید به این نکته فکر کردهاید که چه خوب میشد اگر مجبور نبودید برای اجرای کارهای تکراری، متدهای تکراری بنویسید. این همان جایی است که ژنریکها به کار میآیند.
ژنریکها امکان ایجاد تابعهایی را با قابلیت استفاده مجدد میدهند که میتوانند در انواع متفاوتی استفاده شوند. تنها نکته این است که این نوع باید با کاری که قرار است اجرا شود متناسب باشد.
این بدان معنی است که میتوان یک تابع منفرد نوشت که مقدار مجموع را محاسبه میکند و مهم نیست که مقادیر ارسالی به آن از نوع int ،double، یا float باشند. این تابع برای هر نوع Binarty Integr نیز کار میکند، اما در مورد انواع String کارکردی نخواهد داشت. در ادامه این تابع ژنریک را مورد بررسی بیشتری قرار میدهیم:
در این بخش نوعی ساختار جدید را شاهد هستیم. ابتدا <T> را میبینید. البته هر چیزی میتواند درون براکتها باشد و عموماً از T برای نمایش نوع T استفاده میشود. همچنین در برخی موارد به صورت <Elements> میبینیم.
نکته دیگری که مشاهده میشود تغییر اعلان تابع است که عنوان آن به صورت زیر است:
در واقع این یک mutating func جدید است که add را فراخوانی میکند و از یک نوع ژنریک با نام <T> استفاده میکند و یک آرگومان منفرد newItem از نوع T میگیرد. Mutating به این معنی است که این تابع میتواند ساختار آرایه items را تغییر دهد.
این نوع از روی نوع لیستی که در ابتدا مقداردهی شده استنباط میشود. به محض این که کامپایلر این خط را ببیند:
همه رخدادهای <T> درون دامنه ساختار List ژنریک را به <Int> تغییر میدهد. از این رو آرایه Items و همه تابعها انتظار نوع Int را خواهند داشت.
اگر یک List جدید با استفاده از <String> ساخته شود و در stringList ذخیره شود، این آرایه و تابع میتواند انتظار استفاده از یک نوع String را داشته باشد.
شما احتمالاً قبلاً این ساختار را دیدهاید مثلاً وقتی که دیکشنریها و آرایهها را میساختید از آن استفاده کردهاید. ما موارد زیادی از این اختصارها را ساختهایم که به طور عمده روی استنباط نوع تکیه دارند؛ اما سوئیفت در پشت صحنه از ما پشتیبانی میکند و به صورت خودکار این نوعها را برای ما گسترش میدهد.
آرایههای اعداد صحیح با استفاده از ساختار ()[Int] اعلان میشوند؛ اما سوئیفت آن را به صورت ()<Array<Int بسط میدهد.
دیکشنریهای رشتهها با استفاده از ()[String: String] اعلان میشوند؛ اما همانند آرایهها، سوئیفت آن را به صورت دیکشنریهای ()<Dictionary<String: String درک میکند.
با این ساختار، میتوانیم تعیین کنیم که دیکشنریها و آرایهها هر دو از نوع ژنریک هستند و مهم نیست که چگونه تنظیم شوند، چون تنها نکته مهم برای آنها این است که هر مقداری که درونشان استفاده میشود با نوع اعلان شده مطابقت داشته باشد.
در ادامه متد دوم کد فوق را نیز بررسی میکنیم:
طرز کار این متد مانند متد add است و به جای T هر نوعی که برای ایجاد List استفاده شده باشد جایگزین میشود؛ اما این متد از Int به عنوان مقدار پارامتر استفاده میکند. دلیل این کار آن است که باید اندیس مبتنی بر Integer آرایه را داشته باشیم. علی غم این که محتوای آرایه ژنریک است؛ اما اندیسها همچنان عدد صحیح هستند.
البته عنصری که در آن اندیس قرار دارد از نوع ژنریک تعریفشده ما خواهد بود؛ اما اگر کاربر هیچ چیزی به آرایه اضافه نکرده باشد چطور؟ ما باید این موقعیت که هیچ عنصری در آرایه نباشد را نیز مدیریت کنیم. بنابراین ابتدا مطمئن میشویم که یک آیتم را در لیست خود داریم. در ادامه میتوانیم تلاش کنیم عنصر را دریافت کنیم. اما اگر نتوانیم آن عنصر را پیدا کنیم مقدار nil بازگشت میدهیم.
دقت کنید که در پاراگراف قبلی گفتیم «تلاش» میکنیم. این یک نکته منطقی است که اگر تمرینهای قبلی را انجام داده باشید، متوجه سرنخ آن میشوید. تصور کنید ما سه آیتم به آرایه اضافه کردهایم؛ اما گزاره زیر را اجرا میکنیم:
به نظر میرسد باید چیز دیگری را نیز بررسی کنیم تا از کرش کردن برنامه جلوگیری کنیم. کشف این نکته را بر عهده شما میگذاریم.
در این بخش یک سؤال دیگر را مطرح میکنیم. اگر یک لیست جدید با استفاده از دستور زیر ایجاد کنیم و مقادیر 3، 4 و 5 را به آن اضافه کنیم:
در این صورت اگر از دستور زیر استفاده کنیم، در زمان استفاده از print(value) دقیقاً چه متنی در کنسول نمایش مییابد؟

سازگاری
شما میتواند کاری کنید که ژنریکها با پروتکلهای خاصی سازگاری داشته باشد. بدین ترتب آنها تنها میتوانند با نوعهای خاصی وهلهسازی شوند. برای نمونه زمانی که از پروتکل BinaryInteger استفاده میکنید، در واقع تعیین کردهاید که صرفاً اعداد صحیح با علامت (+/-) و بی علامت (+) میتوانند در این متد ژنریک استفاده شوند.
امکان تعریف سازگاری با هر نوع وجود دارد؛ اما بهترین استفاده از آن با بهرهگیری از رفتارهای پایه و پروتکلهای پایهای مانند Numeric ،Stridable ،Sequence و/یا Collection است.
اینها رفتارهای پایهای هستند که میتوان سازگاری با آنها را تعریف کرد. در این صفحه (+) میتوانید فهرست کامل را مشاهده کنید؛ اما در ادامه برخی از مواردی که استفاده متداولی دارند را نیز بررسی کردهایم:
- Equatable – امکان بررسی این مسئله را میدهد که مقدار یک متغیر مقدار دیگر برابر است یا نه.
- Comparable – امکان مقایسه مقدار یک متغیر با متغیر دیگر را با استفاده از عملگرهای رابطه (بولی) مانند «بزرگتر از»، «کمتر از»، «برابر» میدهد.
- Hashable – یک هش Integer ایجاد میکند که امکان استفاده از نوع، در یک مجموعه یا یک کلید دیکشنری را میدهد.
برخی اوقات یکی از این موارد برای نیازهای شما کافی است؛ اما در موقعیتهای دیگری نیز ممکن است به بیش از یک مورد نیاز داشته باشید.
برای این که بهترین استفاده را از ژنریکها داشته باشید باید پروتکلهای مختلف توصیفشده در مستندات اپل را بررسی کنید. هر پروتکلی که استفاده میشود، صرفاً باید مطمئن شوید که با آن چه برایش استفاده میکنید سازگار است. این بدان معنی است که نباید فهرستی از سن افراد بسازید که از پروتکل FloatingPoint استفاده کند؛ مگر این که بخواهید از این تابع با اعداد اعشاری (float, double) استفاده کنید.
در ادامه به بررسی روش محدودسازی یک تابع ژنریک برای محدودسازی انواعی که میتوانند استفاده شوند میپردازیم.
ما با استفاده از پروتکل Numeric به کامپایلر اعلام میکنیم، هر نوعی که عدد است را میتواند به جای T قبول کند. این امر به ما اجازه میدهد که از همان تابع برای انواع مختلفی استفاده کنیم.
گرچه افزودن دو عدد به هم دیگر کار چندان بزرگی به نظر نمیرسد؛ اما این روش زمانی که شروع به استفاده از تکنیکهای پیشرفتهتر بکنید، قدرتش را نشان میدهد. استفاده از ژنریکها در قالب یک تابع مانند این، یکی از ویژگیهای سوئیفت است که اغلب توسعهدهندههای مبتدی در پروژههای خود استفاده نمیکنند. حتی میتوان کل یک اپلیکیشن را بدون استفاده از ژنریک نیز نوشت؛ اما بالاخره روزی فرا میرسد و با موقعیتی مواجه شوید که باید از یک تابع برای دو نوع داده متفاوت استفاده کنید. در این حالت باید پروتکلی پیدا کنید که سازگاری داشته باشد و بتوانید آن تابع با نوعبندی قوی را به یک تابع ژنریک تبدیل کرده و به صورت مکرر در هر کجا که لازم است از آن استفاده کنید.
ژنریکها در پروتکلها
این همان نقطهای است که قبلاً به آن رسیدیم و به جای صحبت کردن در ژنریکها در پروتکلها؛ از آن عبور کرده و در مورد سازگاری و مثالهایی از شیوه تفکر لازم برای استفاده از ژنریکها در پروتکلها صحبت کردیم.
ژنریکها در پروتکلها چنان که انتظار میرود عمل میکنند؛ اما سازگاری فاصله زیادی با این وضعیت دارد. بدین ترتیب امکان صحبت بیشتر در مورد Self و همچنین خویشاوند نزدیک آن typealiase که associatedtype نامیده میشود فراهم میآید. ابتدا به توضیح دقیقتر Self میپردازیم.
Self یک الگوریتم جستجوی باینری است که شباهت زیادی به روش جستجو در یک دفترچه شماره تلفن یا دیکشنری دارد. فرض کنید به دنبال کلمه Swift در دیکشنری میگردید.
- ابتدا کتاب را باز میکنید و مثلاً به جایی روی حروف M میرسید.
- S بزرگتر از M است و بنابراین نیمی از صفحهها را به عقب بازمیگردیم تا به جایی مانند T میرسیم.
- S کوچکتر از T است و از این رو دوباره نیمی از صفحههای قبلی را به جلو ورق میزنیم تا به جایی بین حرف M و T برسیم.
- این کار را تا جایی ادامه میدهیم که به صفحهای حاوی کلمه Swift برسیم.
در این مثال، یک پروتکل ارائه میکنیم که میتواند با هر نوعی کار کند به شرط این که آن نوع معادل Self باشد. Self در این چارچوب به این معنی است که میخواهیم مطمئن شویم مقداری که ارسال شده است نیز امکان سازگاری با پروتکل Ordered را دارد. ما یک سازه عددی داریم که از آن برای مقایسه با مقداری از همان نوع بهره میگیریم.
سپس اندیس بالا و پایین آرایه را به دست میآوریم (چون مرتب است) و در ادامه مقداری که به دنبالش هستیم را پیدا میکنیم. به این منظور ابتدا میانه آرایه را مییابیم. الگوریتم زیر این کار را انجام میدهد:
چون که:
0 + (10 - 0) / 2 = 5
در ادامه اگر به نقطه بالا برویم، به دلیل رند کردن به نتیجه زیر میرسیم:
5 + (10–5) / 2 = 8
سپس [if sortedKeys[mid را بررسی کنیم، که مقدار 5 را به دست میدهد، (precedes(k قبل از مقداری است که به دنبالش میگردیم و از این رو مقدار زیر یا مقداری بالاتر از میانه را تنظیم میکنیم:
اگر مقدار مورد نظر در این بازه نباشد، مقدار hi = mid را تنظیم میکنیم، چون میخواهیم هر چیزی پایین تراز mid را بگردد. بدین ترتیب ادامه میدهیم تا زمانی که یک مقدار باقی بماند که lo است.
انواع Associated به منظور placeholder-هایی مشابه <T>؛ اما در اعلان پروتکل استفاده میشوند. مثال لیست فوق را با استفاده از پروتکل با یک نوع Associated بازنویسی میکنیم:
ابتدا associatedtype را داریم که آن را Item مینامیم، زیرا قرار است آیتمهایی را در یک آرایه ذخیره کنیم.
سپس آرایه items را با استفاده از یک getter که با { get } نمایش مییابد ایجاد میکنیم. این دستور به کامپایلر اعلام میکند که این آرایه باید فقط-خواندنی باشد. اگر بخواهیم این آرایه قابل خواندن و قابل نوشتن باشد میتوانیم از { get set } استفاده کنیم. در این حالت تنها میخواهیم که کاربر متغیر را با استفاده از تابع add تعیین کند. در مقالات آینده در مورد getrer-ها و setter-ها بیشتر صحبت خواهیم کرد.
در این مورد نیز یک mutating func داریم، زیرا تابع خودش، یعنی آن struct که مالک متد را تغییر میدهد همچنین متدی برای دریافت آیتمها ایجاد میکنیم که نکته جدیدی ندارد.
Struct با نام <List<T خارج از چارچوب پروتکل و تا حدود زیادی شبیه به وضعیت پیشین است. البته ما هیچ اکستنشنی برای پروتکل ایجاد نکردهایم که بتواند در صورت نیاز کارکردهای پیشفرض را شامل شود. در برخی موارد زمانی که بین انواع مختلف سوئیچ میکنیم، ممکن است به کارکردهای متفاوتی نیاز داشته باشیم. برای نمونه زمانی که از یک <List<String استفاده میکنیم، ممکن است بخواهیم یک آرایه از کاراکترها و یا آرایهای از رشتهها را الحاق کنیم. همین موضوع در مورد <List<Character نیز صدق میکند.
اینک با کسب این دانش جدید میدانیم که پروتکلهای دیگری نیز وجود دارند که انواع رایجی مانند String ،Int ،Double و غیره از چیزی مانند Numeric ارث میبرند و میتوانیم یک اکستنشن از Numeric بسازیم که پروتکل را به خدمت بگیرد و کارکرد پیشفرضی که همه انواع Numeric را در برمیگیرد برای آن تعریف کنیم. در این حالت میتوانیم یک چنین موردی را برای نوعهای StringProtocol برای رشتهها بسازیم.
نکته آخری که باید در مورد ژنریکها بگوییم در خصوص بند where است. بند where یک متمم برای پروتکل یا associatedtypes است.
بدین ترتیب myProtocol یک الزام روی هر چیزی که از این پروتکل استفاده کند، قرار میدهد و همچنین از Hashable استفاده میکند. به طور معمول سازگاری با پروتکلهای کتابخانه استاندارد سوئیفت نیازمند پیادهسازی چند نوع، متغیر و/یا متد associated است که کمی اضافهکاری به نظر میرسد. در مورد Hashable باید کد زیر را به struct یا class خود اضافه کنید.
hashvalue کاملاً سرراست است؛ اما static func ==(lhs:rhs:) -> Bool برای ما کاملاً جدید است.
static به این معنی است که میتوان آن را در هر کجا صرفاً با استفاده از ListA == ListB فراخوانی کرد و دو لیست را برای برابری فشرده میسازد. علامت == جایی است که برابرسازی اجرا میشود و یک روش استفاده از این عملگر محسوب میشود. lhs و rhs به معنی سمت چپ و سمت راست عملگر برابری هستند. ما یک مقدار بولی بازگشت میدهیم اما پیادهسازی این تابع خالی است. بنابراین باید پرسید چه اتفاقی در آن میافتد؟ منطقی که قصد داریم استفاده کنیم استفاده از بررسی برابری است. ما صرفاً یک پیادهسازی پیشفرض میسازیم که چارچوبی مانند زیر دارد:
اگر lhs برابر با rhs باشد، مقدار true و در غیر این صورت مقدار false بازگشت مییابد.
در بخش دوم که بند where با یک نوع associated استفاده شده است، در واقع قصد داریم کارکرد خود را در صورتی ارائه کنیم که شیئی که پروتکل را اختیار کرده است، الزام نوع مرتبط آن را نیز مورد استفاده قرار دهد. اگر شیء این کار را بکند، همه متدهایی که از نوع associated استفاده میکنند را به دست میآورد و در غیر این صورت چنین اتفاقی نخواهد افتاد. پیادهسازی آن به صورت زیر است:
به طور خلاصه تفاوتهای بند where بین سطح پروتکل و سطح نوع associated چنین است که وقتی در سطح پروتکل استفاده میشود، به خدمت گرفتن شیء برای استفاده از پروتکل ارجاع یافته در بند where ضروری است. زمانی که بند where در سطح نوع associated استفاده میشود، شیء برای استفاده از پروتکل تعریفشده در بند where ضروری نیست؛ اما به همه متدهایی که در اختیار پروتکل هستند نیز دسترسی نخواهد داشت.
سخن پایانی
بدین ترتیب به پایان این مقاله با موضوع ژنریکها میرسیم. ژنریکها کارکردهای زیادی را با چند تغییر کوچک در کد در اختیار ما قرار میدهند. این موردی است که در زمان ایجاد پروتکلها قطعاً باید در خاطر داشته باشیم و از خود بپرسیم آیا این پروتکل برای انواع مختلفی استفاده خواهد شد؟ یا این انواع چندان متفاوت هستند که باید به دنبال استفاده از بند where برای محدودسازی کارکردهای ارائه شده باشیم.
اغلب افراد تصور میکنند که در برنامهنویسی مهمترین نکته دست یافتن به منطق طرز کار اپلیکیشنها است. با این که این منطق مهم است؛ اما نکته مهمتر از آن مسائلی مانند کامنت های کد، حفظ خوانایی کد، سازگاری در چینش فایلها و ساختار کد و در نهایت روش مدیریت خطا در کد است.
همه افراد میتوانند اپلیکیشنی بسازند که کار مفیدی انجام دهد؛ اما ممکن است همین اپلیکیشن زمانی که API سرور تغییر پیدا میکند و دادههایی خارج از آن چه مورد انتظار است دریافت میکند از کار بیفتد چون خطاها به درستی مدیریت نشدهاند. به دلیل اهمیت موضوع مدیریت خطا در بخش بعدی قصد داریم به بررسی روش مدیریت خطا در iOS و macOS بپردازیم. تا آن زمان به تمرین کد کدنویسی ادامه بدهید و هر کجا که به مشکلی برخورد کردید به مستندات مراجعه کنید. اگر در اولین بار کدتان کار نکرد نباید نگران شوید زیرا یادگیری ژنریک ها به زمان نیاز دارد. در بخش بعدی این سری مقالات آموزشی، در مورد مدیریت خطا در سوئیفت صحبت خواهیم کرد.
دیباگ کرش نیتیو (Native Crash) در اندروید — راهنمای پیشرفته
100 اپلیکیشن برتر در لیست محبوبترین اپلیکیشنهای اندرویدی تا زمان نگارش این مقاله بیش از 54 میلیارد بار نصب شدهاند. 85 درصد از این اپلیکیشنها دارای کد «نیتیو» (native) با استفاده از بیش از 1000 کتابخانه نیتیو هستند. اگر تجربه کار روی چنین اپلیکیشنها یا هر اپلیکیشن بزرگ دیگری را داشته باشید، میدانید که احتمال بروز کرش نیتیو بسیار بالا است.
توسعهدهندگان اندروید میبایست در زمینه دیباگ کردن «رد پشته» (Stack Trace) کرش نیتیو که در زبان اندرویدی «سنگ قبر» (Tombstone) نامیده میشود، تجربه مناسبی داشته باشند. اما کرش اپلیکیشن در بخش نیتیو (یعنی در کدهای سطح پایین C یا ++C) در اغلب موارد پیچیده و درک آن دشوار است. علاوه بر آن امکان از کار افتادن JVM (ماشین مجازی جاوا) پیش از بازگشت کنترل به کد جاوا/کاتلین نیز وجود دارد. این بدان معنی است که شما امکان به دست آوردن «استثنا» (Exception) را در سطح اپلیکیشن نخواهید داشت و تجربه کاربری ناخوشایندی رقم میخورد.
پیش از آغاز
مستندات توسعهدهندگان اندروید اطلاعات مفید زیادی در مورد عیبیابی کرش نیتیو (+) ارائه کرده است، اما جای مثالهای جامع و مفیدی که به تفهیم بهتر موضوع کمک کند، خالی است.
نکته: اگر با کد نیتیو روی پلتفرم اندروید آشنایی ندارید، بهتر است ابتدا راهنمای NDK اندروید (+) را مطالعه کنید.
کتابخانههای نیتیو در بسیاری از اپلیکیشنها مفید هستند؛ اما برخی از کاربردهای آنها به شرح زیر است:
- بهرهگیری از سطوح بالاتری از عملکرد دستگاه برای رسیدن به تأخیر پایین یا اجرای اپلیکیشنهای سنگین از نظر محاسبات مانند بازی یا شبیهسازیهای فیزیکی.
- استفاده مجدد از کتابخانههای C یا ++C که از سوی شما یا توسعهدهندگان دیگر توسعه یافتهاند.
- به علاوه کتابخانههای نیتیو قادرند امنیت اپلیکیشن را افزایش دهند و میتوانند در اپلیکیشنهایی که برای پلتفرمهای مختلف نوشته میشوند، مورد استفاده قرار گیرند.
مثالهایی از دنیای واقعی
تصور کنید در یک تیم Android SDK مشغول به کار هستید که در پروژه خود با کتابخانه شخص ثالثی سر و کار دارید که شامل کدهای نیتیو است. اشیای مشترک (فایلهای so.) نیز به صورت pre-obfuscated هستند که موجب میشود دیباگ کردن هر گونه کرش دشوار باشد.
شاید کتابخانه مشترکی که در اپلیکیشن شما گنجانده شده، از قبل obfuscated باشد و میبایست از obfuscation مجدد جلوگیری کنید. اگر از obfuscation مجدد جلوگیری نکنید، احتمال بالایی وجود دارد که با مشکل مواجه شوید.
در زمان یکپارچهسازی این کتابخانه با اپلیکیشن، اگر با یک کرش در runtime در build-های release مواجه شوید که obfuscation شده است، عملاً با موقعیت بسیار دشواری روبرو شدهاید. Obfuscation کد برای حفظ امنیت اپلیکیشن ضروری است و از این رو باید کرش را به سرعت پیش از انتشار بعدی رفع کنید.
در این موارد باید یک راهحل برای دیباگ کردن اپلیکیشن بیابید. به اپلیکیشن نمونه ساده زیر توجه کنید. مراحل تحلیل و دیباگ کردن برای رفع کرش نیتیو در این اپلیکیشن استفاده شدهاند.
اپلیکیشن نمونه: NativeCrashApp
نکته: این اپلیکیشن نمونه به عنوان یک اپلیکیشن نهایی هیچ مناسبتی ندارد و صرفاً با مقاصد آموزشی ارائه شده است.
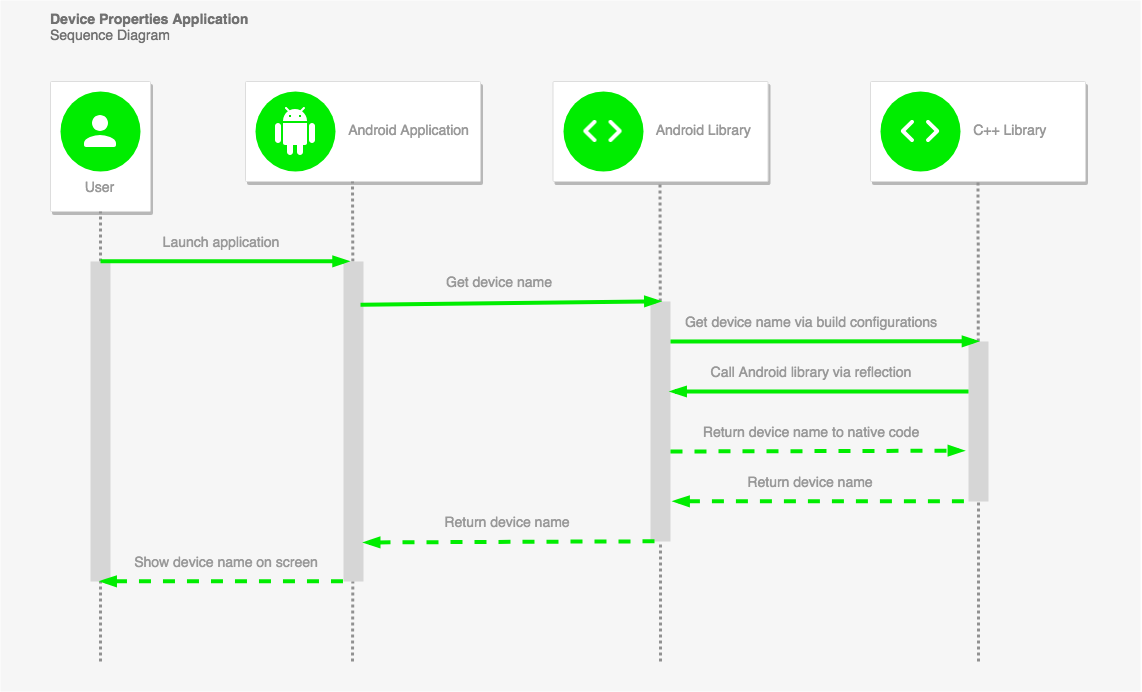
گردش کار اپلیکیشن ساده (و غیر ضروری) است، اما رفتار جالبی را شامل میشود. تابع ابتدایی و منفرد برای نمایش نام دستگاه در قالبی کاربرپسند به کاربر استفاده میشود و صرفاً یک نام بیمعنی مدل از سوی Build.MODEL بازگشت نمییابد. به این منظور از کتابخانه AndroidDeviceNames (+) استفاده شده است.
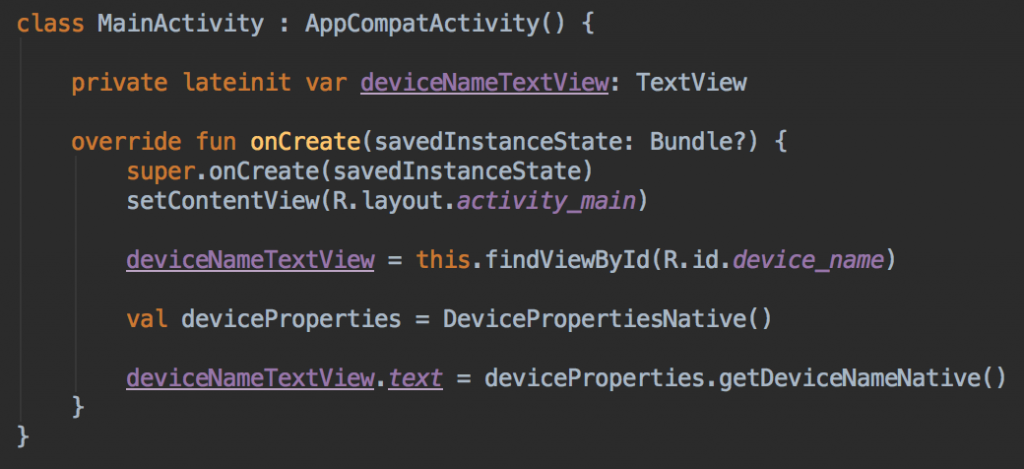
1. کاربر اپلیکیشن را اجرا میکند
اپلیکیشن در زمان اجرا شدن با استفاده از کتابخانه سفارشی اندروید به دنبال نام دستگاه میگردد.
2. فراخوانیهای کتابخانه به سطح نیتیو
سطح نیتیو (کتابخانه ++C) از طریق JNI یا «رابط نیتیو جاوا» (Java Native Interface) فراخوانی میشود.
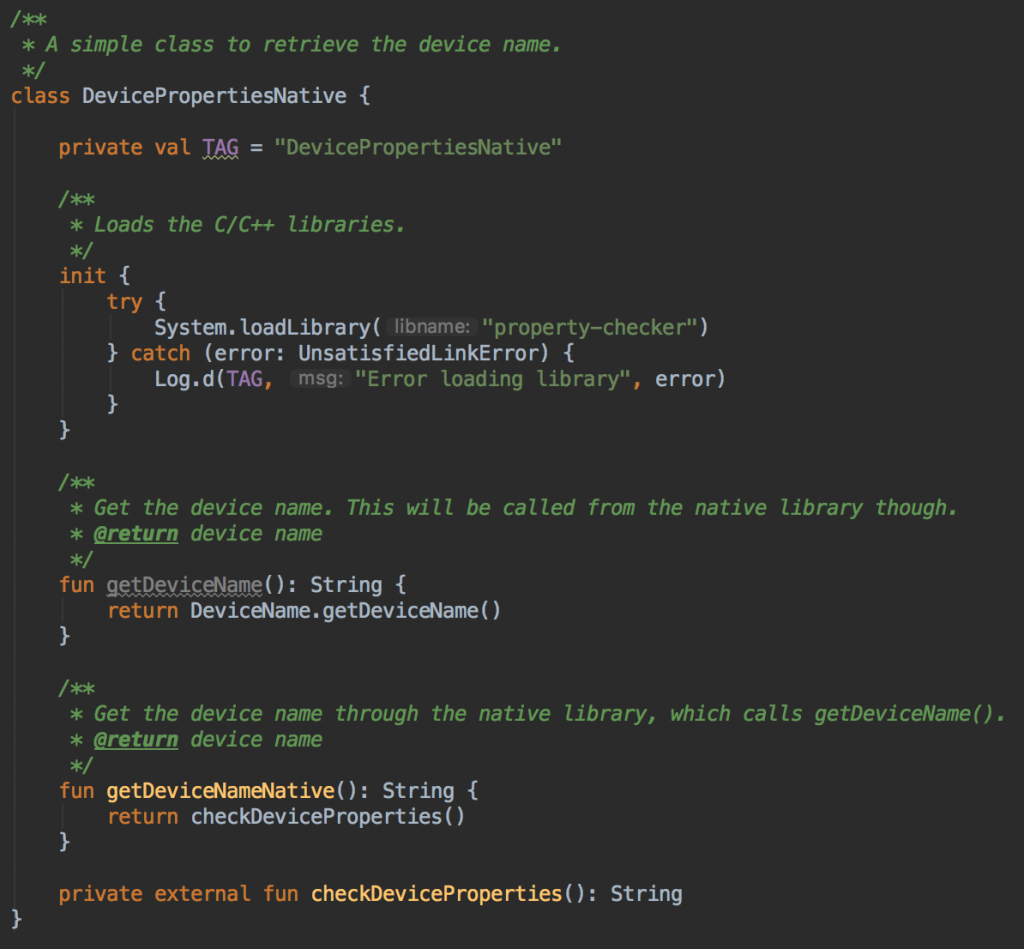
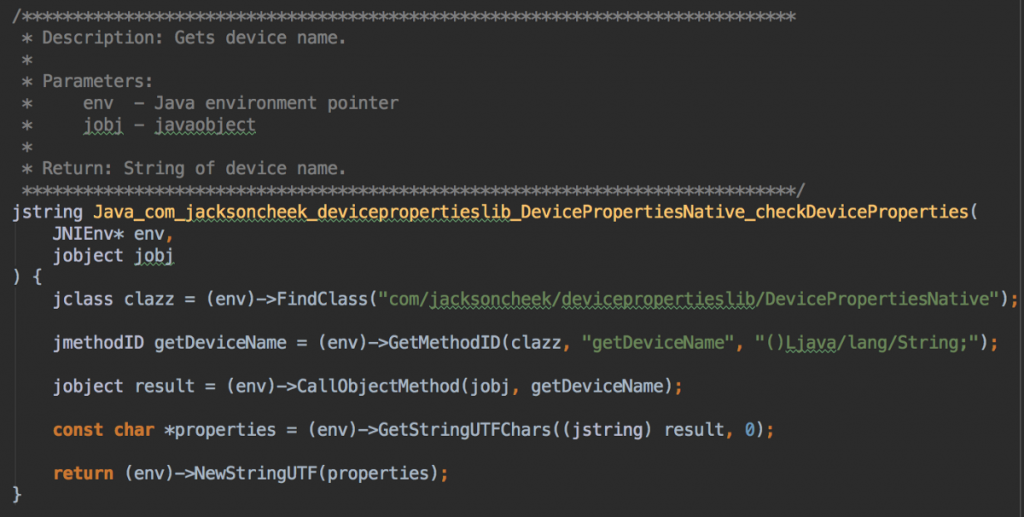
3. فراخوانی بازگشتی به کتابخانه اندروید از طریق بازتاب
در این مرحله یک فراخوانی بازگشتی به کتابخانه اندروید از طریق reflection برای بررسی نام دستگاه (قابل خواندن از سوی انسان) صورت میگیرد.
4. بازگشت دادن نام دستگاه به سطوح اولیه
در نهایت نام دستگاه به اپلیکیشن بازگشت و روی صفحه نمایش مییابد.
نکته: بدیهی است که همه این اتفاقات میتوانست در Activity رخ دهد. کتابخانه Android و کتابخانه ++C کاملاً غیر ضروری هستند؛ اما این روش جالبتر است.
باگ کجاست؟
ما به منظور مقاصد آموزشی مقداری باگ در کد فوق اضافه کردهایم. برای مشاهده این باگها به flavor مربوط به نسخه broken این پروژه در این آدرس (+) مراجعه کنید تا باگهایی را که نیازمند دیباگ شدن هستند را ببینید.
Shrinking و Obfuscation کد
تصور کنید ما به عنوان یک توسعهدهنده مسئولیتپذیر اندروید، میخواهیم امنیت اپلیکیشن خود را از طریق ابزارهای Shrinking و Obfuscation کد افزایش دهیم. بدین ترتیب باید ابزار منتخب Obfuscation کد مانند ProGuard (+) را مورد استفاده قرار دهیم. در این فرایند کلاسها، فیلدها، متدها و خصوصیتهای بیاستفاده تشخیص داده شده و از اپلیکیشن بستهبندیشده حذف میشوند.
باگ شماره 1
متأسفانه زمانی که build مربوط به release اپلیکیشن خود را تست میکنیم با یک کرش مواجه میشویم.
هیچ پیادهسازی برای کلاس (com.jacksoncheek.a.a.a(boolean وجود ندارد؛ اما شاید کلاً معنی این را نمیدانید. اگر فایل نگاشت mapping.txt را که ProGuard در خروجی ارائه کرده بررسی کنیم، میبینیم که شامل ترجمهای بین یک کلاس، متد و نام فیلدهای اصلی و obfuscated است.
اینک میدانیم که ProGuard برخی از متدهای ما را به طور نادرستی obfuscate کرده است. این نوع از خطا در زمان obfuscation امری معمول است.
نکته پیشرفته: ProGuard کد نیتیو را بررسی نمیکند و از این رو به طور خودکار کلاسها یا اعضای کلاسهایی را که از طریق reflection در کد نیتیو فراخوانی میشوند، نگهداری نمیکند. اینک زمان آن رسیده است که این متدها را نیز از طریق فلگ keep- در پروژه حفظ کنیم.
- keepclasseswithmembernames – نام کلاس و متدهای نیتیو را حفظ میکند.
- includedescriptorclasses – انواع بازگشتی و پارامترها را حفظ میکند.
باگ شماره 2
بدین ترتیب یک بار دیگر اپلیکیشن را تست میکنیم و با کرش دیگری مواجه میشویم.
به نظر میرسد که یک خطای دیگر obfuscation وجود دارد.
این خطا کمی پیچیدهتر است. چنان که شاهد هستید، نام کلاس DevicePropertiesNative، نام متد getDeviceName؛ نوع پارامتر () یعنی void و نوع بازگشتی Ljava/lang/String پیدا نشده است.
بنابراین باید متدهای کلاس و نیتیو را از obfuscate شدن بازداریم؛ اما انواع بازگشتی و پارامترها چنین حالتی ندارند. این وضعیت تضمین میکند که کد «امضای متد» (method signature) با کتابخانه نیتیو سازگار خواهد بود.
ما باید یک قاعده keep- در پیکربندی ProGuard اضافه کنیم تا از obfuscate شدن متد ()getDeviceName جلوگیری کنیم. راهنمای ProGuard (+) اطلاعات زیادی در مورد گزینههای پیکربندی مختلف ارائه میکند.
باگ شماره 3
در ادامه پروژه را مجدداً تست میکنیم و میبینیم که بار دیگر یک کرش نیتیو داریم!
این یک خطای segmentation به صورت SIGSEGV در آدرس حافظه مجازی 0xff799ffc است؛ اما در عمل اطلاعات مفید چندانی ارائه نمیکند. SEGV_ACCERR زمانی رخ میدهد که یک اشارهگر بخواهد شیئی را که مجوزهای دسترسی نامعتبری دارد بنویسد.
اینک نوبت آن رسیده است که به بررسی log-ها بپردازیم و tombstone را که همان dump کرش برای کرشهای نیتیو است، پیدا کنیم. اگر در log-ها برای یافتن ابتدای tombstone، عبارت *** *** را جستجو کنید، با اطلاعات زیر مواجه میشوید:
- اثر انگشت بیلد: با مشخصه سیستم ro.build.fingerprint مطابقت دارد.
- بازبینی سختافزاری: با مشخصه سیستم ro.revision مطابقت دارد.
- ABI (اینترفیس باینری اپلیکیشن): دستورالعمل پردازنده برای تعیین معماری است که armeabi-v7a برای دستگاههای اندرویدی متداولترین گزینه است.
- نام پردازش از کارافتاده >>> … <<< (و شناسه پردازش) و نام نخ به صورت …:name و شناسه نخ.
- نوع سیگنال خاتمه به صورت SIGSEGV، روش دریافت آن سیگنال در SEGV_ACCER و آدرس خطا در حافظه.
- ثباتهای سیپییو
- محتوای پشته مورد فراخوانی (backtrace).
دیباگ کردن کرشهای نیتیو
در این بخش با روشهای دیباگ کردن کرشهای نیتیو آشنا میشویم.
بررسی Backtrace
مقادیر PC (شمارنده برنامه) آدرسهای متناظر حافظه با موقعیت کتابخانه مشترک هستند. این همان جایی است که بیشترین اطلاعات در مورد کرش نیتیو و مکان آن در کتابخانه را به دست میآوریم.
کرش ما در آدرس حافظه 000008e8 در ابتدای پشته فراخوانی در libproperty-checker.so رخ داده است.
پشته Android NDK دو ابزار ارائه میکند که به دیباگ کردن tombstone-ها کمک میکند و ndk-stack و addr2line نام دارند. ابزارهای NDK را با ابزار مدیریت اندروید استودیو نصب کنید و دایرکتوری NDK را به مسیر bash_profile. اضافه کنید.
ndk-stack
ابزار ndk-stack (+) اقدام به نمادسازی از ردهای پشته برای یک tombstone میکند. در واقع این ابزار آدرسهای حافظه را به فایلهای منبع مرتبط تبدیل میکند و شماره خطوط را از کد منبع کتابخانه نیتیو نمایش میدهد.
addr2line
امکان استفاده از این ابزار addr2line نیز برای دریافت آدرس حافظهای که کد نیتیو موجب کرش شده وجود دارد. بدین ترتیب نام فایل منبع و خط مربوطه به دست میآید. این ابزار بخشی از مجموعه ابزار NDK است. باید مطمئن شوید که از addr2line برای نوع ABI صحیح دستگاه یعنی x86 (نامتداول)، armeabi یا armeabi-v7a (متداول) استفاده میکنید.
در این مورد مسیر addr2line برای انواع ABI به صورت x86 به صورت زیر است:
کاربرد
مثال
اکنون میدانیم که متد نیتیو به نام (accidentallyForceStackOverflow(int در فایل منبع propertyChecker.cpp و شماره خط 64 موجب بروز کرش نیتیو شده است.
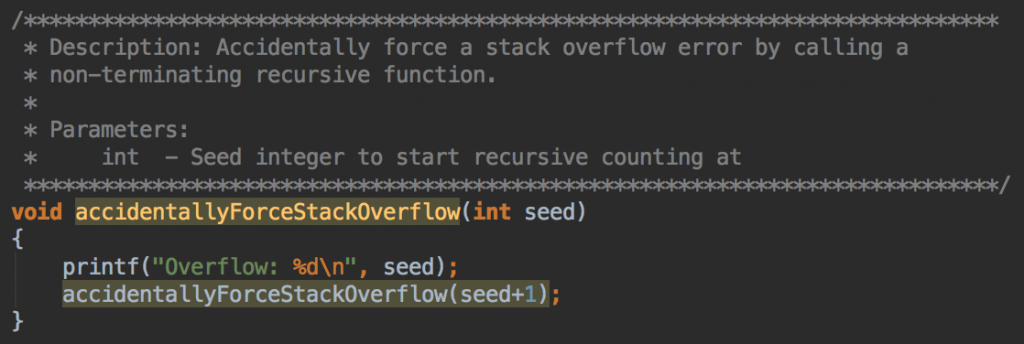
بدین ترتیب باگ نیتیو خود را یافتهایم. این کتابخانه به صورت تصادفی با فراخوانی یک تابع بازگشتی غیر پایانی به صورت نامتناهی موجب یک خطای «سرریز پشته» (stack overflow) شده است. راهحل سریع در این بخش حذف همه کاربردهای این متد است.
در دنیای واقعی ممکن است با نسخههای release از یک ارائهدهنده کتابخانه کار کنید و از این رو دسترسی به کد منبع برای دیباگ کردن نداشته باشید. از طرف دیگر همه فایلهای so. برای دیباگ کردن با ndk-stack مناسب نیستند، زیرا کتابخانههای منتشر شده عموماً از stripped binaries استفاده میکنند که باعث میشود دیباگ کردن آنها دشوارتر شود.
این همان جایی است که ابزار addr2line واقعاً به ابزار مفیدی تبدیل میشود. اگر نام متد نیتیو که کرش در آن رخ داده است در tombstone نمایش نیابد، که برای همه دستگاهها هم چنین تضمینی وجود ندارد، میتوانید از addr2line برای دریافت نام متد نیتیو استفاده کنید.
ابتدا فایل apk. را دیکامپایل بکنید (کافی است آن را unzip بکنید) و فایلهای so. بستهبندیشده در اپلیکیشن را از دایرکتوری lib/ استخراج کنید. سپس کتابخانه مشترک را برای نوع دستگاه ABI مثلاً armeabi-v7a استخراج کنید.
نکته: این فایلها در دایرکتوری /app/src/main/jniLibs نیز قرار دارند.
در این روش شماره خط فایل منبعی که کرش رخ داده است به دست نمیآید، چون APK تنها شامل فایلهای stripped binaries است؛ اما نام متد را به صورت (accidentallyForceStackOverflow(int به دست میآوریم که در نوع خود مفید است.
جمعبندی
در این بخش مراحل مورد نیاز برای دیباگ کردن کرشهای نیتیو را به صوت فهرستوار ارائه میکنیم.
- ابتدا باگ را روی انواع معماریهای مختلف دستگاهها بررسی کنید.
- فایل apk. را دی کامپایل کرده و مطمئن شوید که فایلهای کتابخانه مشترک so. برای هر معماری موجود هستند.
- بررسی کنید که ابزار مدیریت بسته اندروید به درستی کد نیتیو را همراه با اپلیکیشن نصب میکند. به این منظور بررسی کنید که کتابخانه مشترک so. در runtime بارگذاری میشود یا نه. شما باید از ابزار Native Libs Monitor (+) برای بررسی آسان اپلیکیشنهای دارای کتابخانههای نیتیو روی دستگاه خود استفاده کنید؛ اما هیچ تضمینی برای امنیت استفاده از این اپلیکیشن روی دستگاههایی که build-های دیباگ مالکانه دارند وجود ندارد.
- قواعد keep- خاصی را به پیکربندی ProGuard اضافه کنید تا متدهای کلاس و نیتیو را از obfuscate شدن منع کنید. این مورد در خصوص انواع بازگشتی و پارامترها صدق نمیکند.
- Tombstone-های کرش نیتیو را با استفاده از ابزارهای ndk-stack و addr2line بررسی کنید.
- منبع: فرادرس