طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیدیباگ کرش نیتیو (Native Crash) در اندروید — راهنمای پیشرفته
100 اپلیکیشن برتر در لیست محبوبترین اپلیکیشنهای اندرویدی تا زمان نگارش این مقاله بیش از 54 میلیارد بار نصب شدهاند. 85 درصد از این اپلیکیشنها دارای کد «نیتیو» (native) با استفاده از بیش از 1000 کتابخانه نیتیو هستند. اگر تجربه کار روی چنین اپلیکیشنها یا هر اپلیکیشن بزرگ دیگری را داشته باشید، میدانید که احتمال بروز کرش نیتیو بسیار بالا است.
توسعهدهندگان اندروید میبایست در زمینه دیباگ کردن «رد پشته» (Stack Trace) کرش نیتیو که در زبان اندرویدی «سنگ قبر» (Tombstone) نامیده میشود، تجربه مناسبی داشته باشند. اما کرش اپلیکیشن در بخش نیتیو (یعنی در کدهای سطح پایین C یا ++C) در اغلب موارد پیچیده و درک آن دشوار است. علاوه بر آن امکان از کار افتادن JVM (ماشین مجازی جاوا) پیش از بازگشت کنترل به کد جاوا/کاتلین نیز وجود دارد. این بدان معنی است که شما امکان به دست آوردن «استثنا» (Exception) را در سطح اپلیکیشن نخواهید داشت و تجربه کاربری ناخوشایندی رقم میخورد.
پیش از آغاز
مستندات توسعهدهندگان اندروید اطلاعات مفید زیادی در مورد عیبیابی کرش نیتیو (+) ارائه کرده است، اما جای مثالهای جامع و مفیدی که به تفهیم بهتر موضوع کمک کند، خالی است.
نکته: اگر با کد نیتیو روی پلتفرم اندروید آشنایی ندارید، بهتر است ابتدا راهنمای NDK اندروید (+) را مطالعه کنید.
کتابخانههای نیتیو در بسیاری از اپلیکیشنها مفید هستند؛ اما برخی از کاربردهای آنها به شرح زیر است:
- بهرهگیری از سطوح بالاتری از عملکرد دستگاه برای رسیدن به تأخیر پایین یا اجرای اپلیکیشنهای سنگین از نظر محاسبات مانند بازی یا شبیهسازیهای فیزیکی.
- استفاده مجدد از کتابخانههای C یا ++C که از سوی شما یا توسعهدهندگان دیگر توسعه یافتهاند.
- به علاوه کتابخانههای نیتیو قادرند امنیت اپلیکیشن را افزایش دهند و میتوانند در اپلیکیشنهایی که برای پلتفرمهای مختلف نوشته میشوند، مورد استفاده قرار گیرند.
مثالهایی از دنیای واقعی
تصور کنید در یک تیم Android SDK مشغول به کار هستید که در پروژه خود با کتابخانه شخص ثالثی سر و کار دارید که شامل کدهای نیتیو است. اشیای مشترک (فایلهای so.) نیز به صورت pre-obfuscated هستند که موجب میشود دیباگ کردن هر گونه کرش دشوار باشد.
شاید کتابخانه مشترکی که در اپلیکیشن شما گنجانده شده، از قبل obfuscated باشد و میبایست از obfuscation مجدد جلوگیری کنید. اگر از obfuscation مجدد جلوگیری نکنید، احتمال بالایی وجود دارد که با مشکل مواجه شوید.
در زمان یکپارچهسازی این کتابخانه با اپلیکیشن، اگر با یک کرش در runtime در build-های release مواجه شوید که obfuscation شده است، عملاً با موقعیت بسیار دشواری روبرو شدهاید. Obfuscation کد برای حفظ امنیت اپلیکیشن ضروری است و از این رو باید کرش را به سرعت پیش از انتشار بعدی رفع کنید.
در این موارد باید یک راهحل برای دیباگ کردن اپلیکیشن بیابید. به اپلیکیشن نمونه ساده زیر توجه کنید. مراحل تحلیل و دیباگ کردن برای رفع کرش نیتیو در این اپلیکیشن استفاده شدهاند.
اپلیکیشن نمونه: NativeCrashApp
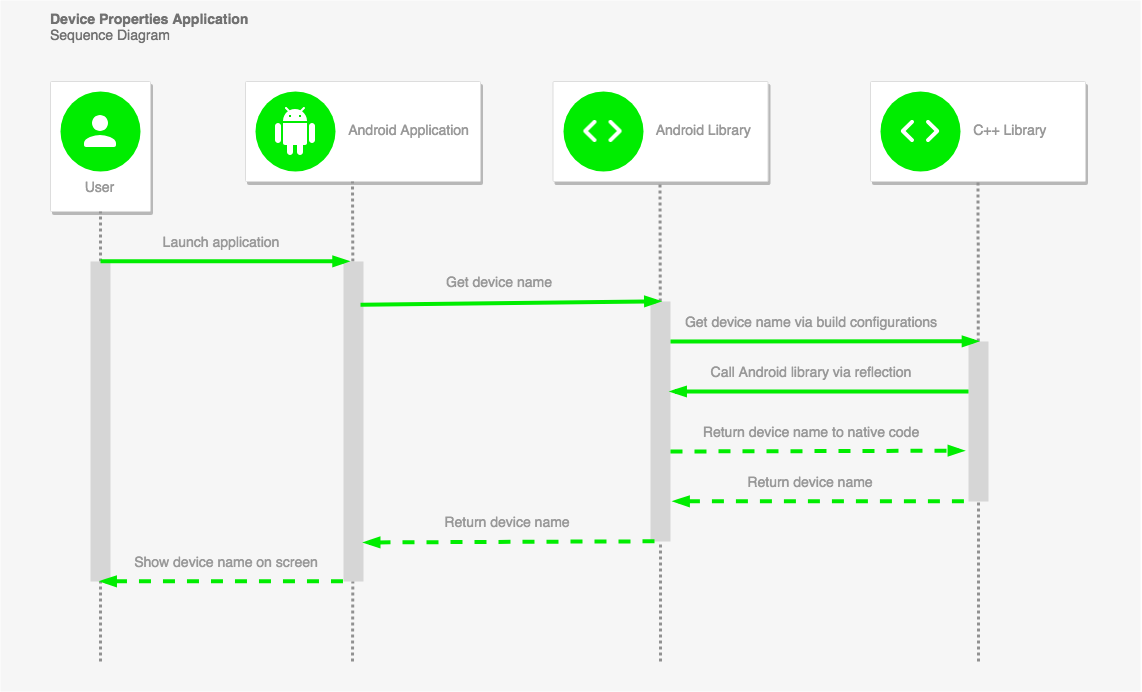
نکته: این اپلیکیشن نمونه به عنوان یک اپلیکیشن نهایی هیچ مناسبتی ندارد و صرفاً با مقاصد آموزشی ارائه شده است.
گردش کار اپلیکیشن ساده (و غیر ضروری) است، اما رفتار جالبی را شامل میشود. تابع ابتدایی و منفرد برای نمایش نام دستگاه در قالبی کاربرپسند به کاربر استفاده میشود و صرفاً یک نام بیمعنی مدل از سوی Build.MODEL بازگشت نمییابد. به این منظور از کتابخانه AndroidDeviceNames (+) استفاده شده است.
1. کاربر اپلیکیشن را اجرا میکند
اپلیکیشن در زمان اجرا شدن با استفاده از کتابخانه سفارشی اندروید به دنبال نام دستگاه میگردد.
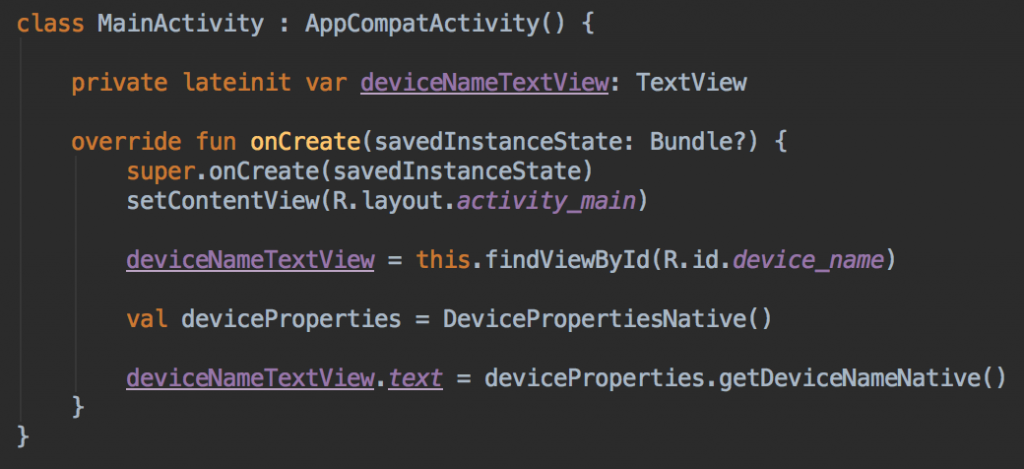
2. فراخوانیهای کتابخانه به سطح نیتیو
سطح نیتیو (کتابخانه ++C) از طریق JNI یا «رابط نیتیو جاوا» (Java Native Interface) فراخوانی میشود.
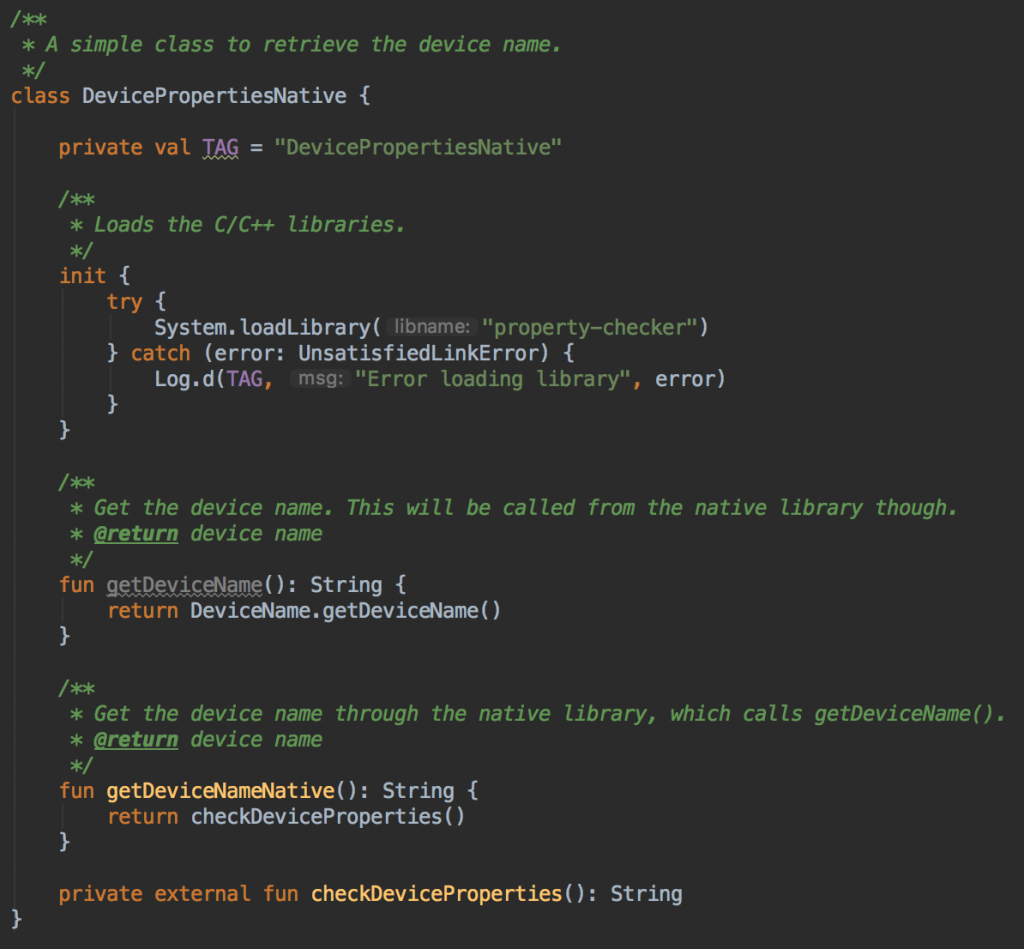
3. فراخوانی بازگشتی به کتابخانه اندروید از طریق بازتاب
در این مرحله یک فراخوانی بازگشتی به کتابخانه اندروید از طریق reflection برای بررسی نام دستگاه (قابل خواندن از سوی انسان) صورت میگیرد.
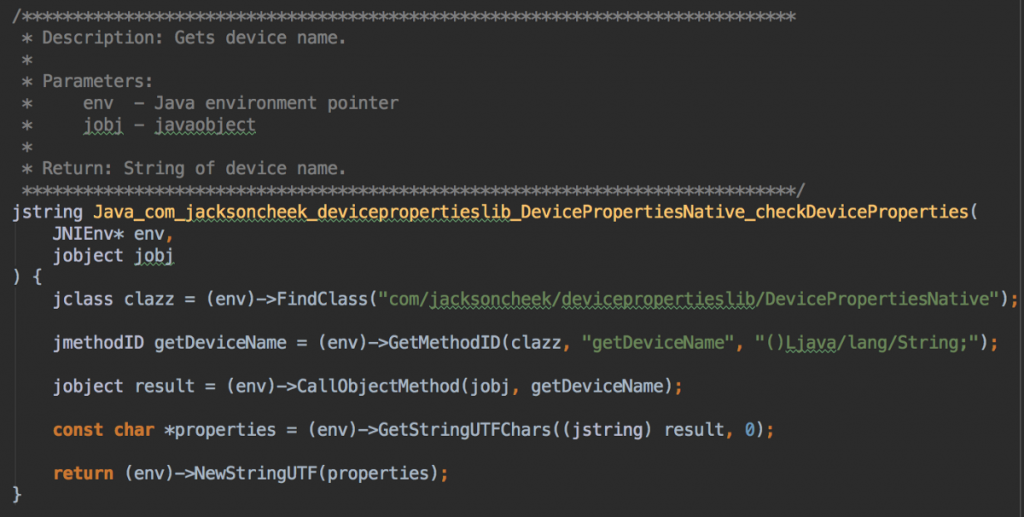
4. بازگشت دادن نام دستگاه به سطوح اولیه
در نهایت نام دستگاه به اپلیکیشن بازگشت و روی صفحه نمایش مییابد.
نکته: بدیهی است که همه این اتفاقات میتوانست در Activity رخ دهد. کتابخانه Android و کتابخانه ++C کاملاً غیر ضروری هستند؛ اما این روش جالبتر است.
باگ کجاست؟
ما به منظور مقاصد آموزشی مقداری باگ در کد فوق اضافه کردهایم. برای مشاهده این باگها به flavor مربوط به نسخه broken این پروژه در این آدرس (+) مراجعه کنید تا باگهایی را که نیازمند دیباگ شدن هستند را ببینید.
Shrinking و Obfuscation کد
تصور کنید ما به عنوان یک توسعهدهنده مسئولیتپذیر اندروید، میخواهیم امنیت اپلیکیشن خود را از طریق ابزارهای Shrinking و Obfuscation کد افزایش دهیم. بدین ترتیب باید ابزار منتخب Obfuscation کد مانند ProGuard (+) را مورد استفاده قرار دهیم. در این فرایند کلاسها، فیلدها، متدها و خصوصیتهای بیاستفاده تشخیص داده شده و از اپلیکیشن بستهبندیشده حذف میشوند.
باگ شماره 1
متأسفانه زمانی که build مربوط به release اپلیکیشن خود را تست میکنیم با یک کرش مواجه میشویم.
هیچ پیادهسازی برای کلاس (com.jacksoncheek.a.a.a(boolean وجود ندارد؛ اما شاید کلاً معنی این را نمیدانید. اگر فایل نگاشت mapping.txt را که ProGuard در خروجی ارائه کرده بررسی کنیم، میبینیم که شامل ترجمهای بین یک کلاس، متد و نام فیلدهای اصلی و obfuscated است.
اینک میدانیم که ProGuard برخی از متدهای ما را به طور نادرستی obfuscate کرده است. این نوع از خطا در زمان obfuscation امری معمول است.
نکته پیشرفته: ProGuard کد نیتیو را بررسی نمیکند و از این رو به طور خودکار کلاسها یا اعضای کلاسهایی را که از طریق reflection در کد نیتیو فراخوانی میشوند، نگهداری نمیکند. اینک زمان آن رسیده است که این متدها را نیز از طریق فلگ keep- در پروژه حفظ کنیم.
- keepclasseswithmembernames – نام کلاس و متدهای نیتیو را حفظ میکند.
- includedescriptorclasses – انواع بازگشتی و پارامترها را حفظ میکند.
باگ شماره 2
بدین ترتیب یک بار دیگر اپلیکیشن را تست میکنیم و با کرش دیگری مواجه میشویم.
به نظر میرسد که یک خطای دیگر obfuscation وجود دارد.
این خطا کمی پیچیدهتر است. چنان که شاهد هستید، نام کلاس DevicePropertiesNative، نام متد getDeviceName؛ نوع پارامتر () یعنی void و نوع بازگشتی Ljava/lang/String پیدا نشده است.
بنابراین باید متدهای کلاس و نیتیو را از obfuscate شدن بازداریم؛ اما انواع بازگشتی و پارامترها چنین حالتی ندارند. این وضعیت تضمین میکند که کد «امضای متد» (method signature) با کتابخانه نیتیو سازگار خواهد بود.
ما باید یک قاعده keep- در پیکربندی ProGuard اضافه کنیم تا از obfuscate شدن متد ()getDeviceName جلوگیری کنیم. راهنمای ProGuard (+) اطلاعات زیادی در مورد گزینههای پیکربندی مختلف ارائه میکند.
باگ شماره 3
در ادامه پروژه را مجدداً تست میکنیم و میبینیم که بار دیگر یک کرش نیتیو داریم!
این یک خطای segmentation به صورت SIGSEGV در آدرس حافظه مجازی 0xff799ffc است؛ اما در عمل اطلاعات مفید چندانی ارائه نمیکند. SEGV_ACCERR زمانی رخ میدهد که یک اشارهگر بخواهد شیئی را که مجوزهای دسترسی نامعتبری دارد بنویسد.
اینک نوبت آن رسیده است که به بررسی log-ها بپردازیم و tombstone را که همان dump کرش برای کرشهای نیتیو است، پیدا کنیم. اگر در log-ها برای یافتن ابتدای tombstone، عبارت *** *** را جستجو کنید، با اطلاعات زیر مواجه میشوید:
- اثر انگشت بیلد: با مشخصه سیستم ro.build.fingerprint مطابقت دارد.
- بازبینی سختافزاری: با مشخصه سیستم ro.revision مطابقت دارد.
- ABI (اینترفیس باینری اپلیکیشن): دستورالعمل پردازنده برای تعیین معماری است که armeabi-v7a برای دستگاههای اندرویدی متداولترین گزینه است.
- نام پردازش از کارافتاده >>> … <<< (و شناسه پردازش) و نام نخ به صورت …:name و شناسه نخ.
- نوع سیگنال خاتمه به صورت SIGSEGV، روش دریافت آن سیگنال در SEGV_ACCER و آدرس خطا در حافظه.
- ثباتهای سیپییو
- محتوای پشته مورد فراخوانی (backtrace).
دیباگ کردن کرشهای نیتیو
در این بخش با روشهای دیباگ کردن کرشهای نیتیو آشنا میشویم.
بررسی Backtrace
مقادیر PC (شمارنده برنامه) آدرسهای متناظر حافظه با موقعیت کتابخانه مشترک هستند. این همان جایی است که بیشترین اطلاعات در مورد کرش نیتیو و مکان آن در کتابخانه را به دست میآوریم.
کرش ما در آدرس حافظه 000008e8 در ابتدای پشته فراخوانی در libproperty-checker.so رخ داده است.
پشته Android NDK دو ابزار ارائه میکند که به دیباگ کردن tombstone-ها کمک میکند و ndk-stack و addr2line نام دارند. ابزارهای NDK را با ابزار مدیریت اندروید استودیو نصب کنید و دایرکتوری NDK را به مسیر bash_profile. اضافه کنید.
ndk-stack
ابزار ndk-stack (+) اقدام به نمادسازی از ردهای پشته برای یک tombstone میکند. در واقع این ابزار آدرسهای حافظه را به فایلهای منبع مرتبط تبدیل میکند و شماره خطوط را از کد منبع کتابخانه نیتیو نمایش میدهد.
addr2line
امکان استفاده از این ابزار addr2line نیز برای دریافت آدرس حافظهای که کد نیتیو موجب کرش شده وجود دارد. بدین ترتیب نام فایل منبع و خط مربوطه به دست میآید. این ابزار بخشی از مجموعه ابزار NDK است. باید مطمئن شوید که از addr2line برای نوع ABI صحیح دستگاه یعنی x86 (نامتداول)، armeabi یا armeabi-v7a (متداول) استفاده میکنید.
در این مورد مسیر addr2line برای انواع ABI به صورت x86 به صورت زیر است:
کاربرد
مثال
اکنون میدانیم که متد نیتیو به نام (accidentallyForceStackOverflow(int در فایل منبع propertyChecker.cpp و شماره خط 64 موجب بروز کرش نیتیو شده است.
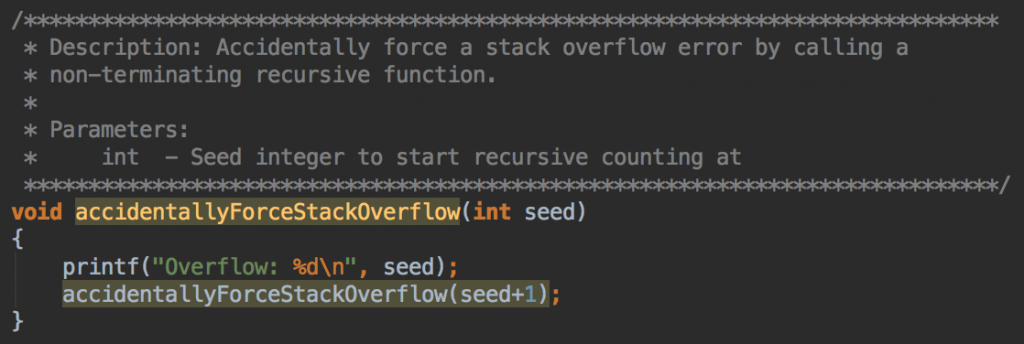
بدین ترتیب باگ نیتیو خود را یافتهایم. این کتابخانه به صورت تصادفی با فراخوانی یک تابع بازگشتی غیر پایانی به صورت نامتناهی موجب یک خطای «سرریز پشته» (stack overflow) شده است. راهحل سریع در این بخش حذف همه کاربردهای این متد است.
در دنیای واقعی ممکن است با نسخههای release از یک ارائهدهنده کتابخانه کار کنید و از این رو دسترسی به کد منبع برای دیباگ کردن نداشته باشید. از طرف دیگر همه فایلهای so. برای دیباگ کردن با ndk-stack مناسب نیستند، زیرا کتابخانههای منتشر شده عموماً از stripped binaries استفاده میکنند که باعث میشود دیباگ کردن آنها دشوارتر شود.
این همان جایی است که ابزار addr2line واقعاً به ابزار مفیدی تبدیل میشود. اگر نام متد نیتیو که کرش در آن رخ داده است در tombstone نمایش نیابد، که برای همه دستگاهها هم چنین تضمینی وجود ندارد، میتوانید از addr2line برای دریافت نام متد نیتیو استفاده کنید.
ابتدا فایل apk. را دیکامپایل بکنید (کافی است آن را unzip بکنید) و فایلهای so. بستهبندیشده در اپلیکیشن را از دایرکتوری lib/ استخراج کنید. سپس کتابخانه مشترک را برای نوع دستگاه ABI مثلاً armeabi-v7a استخراج کنید.
نکته: این فایلها در دایرکتوری /app/src/main/jniLibs نیز قرار دارند.
در این روش شماره خط فایل منبعی که کرش رخ داده است به دست نمیآید، چون APK تنها شامل فایلهای stripped binaries است؛ اما نام متد را به صورت (accidentallyForceStackOverflow(int به دست میآوریم که در نوع خود مفید است.
جمعبندی
در این بخش مراحل مورد نیاز برای دیباگ کردن کرشهای نیتیو را به صوت فهرستوار ارائه میکنیم.
- ابتدا باگ را روی انواع معماریهای مختلف دستگاهها بررسی کنید.
- فایل apk. را دی کامپایل کرده و مطمئن شوید که فایلهای کتابخانه مشترک so. برای هر معماری موجود هستند.
- بررسی کنید که ابزار مدیریت بسته اندروید به درستی کد نیتیو را همراه با اپلیکیشن نصب میکند. به این منظور بررسی کنید که کتابخانه مشترک so. در runtime بارگذاری میشود یا نه. شما باید از ابزار Native Libs Monitor (+) برای بررسی آسان اپلیکیشنهای دارای کتابخانههای نیتیو روی دستگاه خود استفاده کنید؛ اما هیچ تضمینی برای امنیت استفاده از این اپلیکیشن روی دستگاههایی که build-های دیباگ مالکانه دارند وجود ندارد.
- قواعد keep- خاصی را به پیکربندی ProGuard اضافه کنید تا متدهای کلاس و نیتیو را از obfuscate شدن منع کنید. این مورد در خصوص انواع بازگشتی و پارامترها صدق نمیکند.
- Tombstone-های کرش نیتیو را با استفاده از ابزارهای ndk-stack و addr2line بررسی کنید.
- منبع: فرادرس
جستجوی تمام متن در لاراول با Scout — به زبان ساده
جستجوی تمام متن یک قابلیت ضروری جهت فراهم ساختن امکان حرکت در میان صفحههای وبسایتهای با محتوای گسترده است. در این مقاله، شیوه پیادهسازی امکان جستجوی تمام متن را برای یک اپلیکیشن لاراول بررسی میکنیم. در واقع ما از کتابخانه Scout لاراول استفاده میکنیم که پیادهسازی جستجوی تمام متن را به امری ساده و جذاب تبدیل کرده است.
مستندات رسمی، کتابخانه Scout لاراول را به صورت زیر توصیف میکنند:
کتابخانه Scout لاراول یک راهحل ساده و مبتنی بر درایور برای افزودن امکان جستجوی تمام متن به مدلهای Eloquent ارائه میکند. Scout با استفاده از «مشاهدهگرهای مدل» (model observers) به طور خودکار اندیسهای جستجو را در وضعیتی همگامسازی شده با رکوردهای Eloquent حفظ میکند.
کتابخانه Scout لاراول به مدیریت دستکاری اندیسها در زمان بروز تغییراتی در دادههای مدل میپردازد. جایی که دادهها اندیس میشوند به درایوری وابسته است که برای کتابخانه Scout پیکربندیشده است.
در حال حاضر کتابخانه Scout از Algolia پشتیبانی میکند که یک API موتور جستجوی مبتنی بر کلود است و ما نیز در این مقاله از آن برای نمایش پیادهسازی جستجوی تمام متن استفاده خواهیم کرد.
ما کار خود را با نصب کتابخانههای Scout و Algolia server آغاز میکنیم و در ادامه برخی مثالهای واقعی را بررسی میکنیم که شیوه اندیسگذاری و جستجوی دادهها را نمایش میدهد.

پیکربندی سرور
در این بخش ما قصد داریم وابستگیهایی را که برای کار کردن کتابخانه Scout با لاراول لازم هستند نصب کنیم. پس از نصب، باید کمی آن را پیکربندی کنیم تا لاراول بتواند کتابخانه Scout را تشخیص دهد.
در ادامه کتابخانه Scout را با استفاده از Composer نصب میکنیم:
composer require laravel/scout
اگر صرفاً خواسته باشیم کتابخانه Scout را نصب کنیم، کار به همین سادگی است. اینک که کتابخانه Scout نصب شده است، ابتدا باید مطمئن شویم که لاراول در مورد آن اطلاع دارد.
در صورتی که با لاراول کار کرده باشید، احتمالاً با مفهوم «ارائهدهنده سرویس» (service provider) که امکان پیکربندی سرویسها در اپلیکیشن را میدهد، آشنا هستید. بدین ترتیب هر زمان که بخواهید یک سرویس جدید را در اپلیکیشن لاراول پیکربندی کنید، کافی است یک مدخل ارائهدهنده سرویس مرتبط را در config/app.php اضافه کنید.
اگر با مفهوم ارائهدهنده سرویس در لاراول آشنا نیستید؛ قویاً توصیه میکنیم که ابتدا به طور کامل با این مفهوم آشنا شوید.
در مورد اپلیکیشنی که میخواهیم طراحی بکنیم باید یک ارائهدهنده سرویس به نام ScoutServiceProvider را به فهرست ارائهدهندههای سرویس در فایل config/app.php اضافه کنیم. روش کار در قطعه کد زیر نمایش یافته است:
اینک لاراول از وجود ارائهدهنده سرویسی به نام ScoutServiceProvider آگاهی دارد. کتابخانه Scout به همراه یک فایل پیکربندی ارائه میشود که به ما امکان تنظیم نام کاربری و رمز عبور API را میدهد.
در ادامه فایلهای ارائه شده از سوی Scout را با استفاده از دستور زیر منتشر میکنیم:
همان طور که میبینید بدین ترتیب فایل vendor/laravel/scout/config/scout.php به مسیر config/scout.php کپی شده است.
حساب کاربری Algolia
در ادامه یک حساب کاربری در سرویس Algolia (+) ایجاد میکنیم، چون به نام کاربری و رمز عبور API آن نیاز داریم. زمانی که اطلاعات API را به دست آوردید میتوانید اقدام به پیکربندی تنظیمات مورد نیاز در فایل config/scout.php به شیوهای که در قطعه کد زیر نمایش یافته است، بکنید:
دقت داشته باشید که ما مقدار SCOUT_DRIVER را برابر با درایور algolia تعیین کردهایم. از این رو لازم است که تنظیمات لازم برای درایور Algolia را در انتهای فایل پیکربندی کنید. بدین منظور کافی است مقدار id و secret را که از حساب کاربری Algolia دریافت کردهاید تنظیم کنید.
همان طور که شاهد هستید، ما مقادیر را از متغیرهای محیطی واکشی کردهایم، بنابراین باید مطمئن شویم که متغیرهای زیر را در فایل env. به صورت صحیحی تعیین کردهایم:
درنهایت باید SDK مربوط به Algolia PHP را نصب کنیم که برای تعامل با Algolia از طریق API-ها ضروری است. آن را با استفاده از composer و به صورت زیر نصب میکنیم:
بدین ترتیب ما همه وابستگیهای لازم برای ارسال و اندیس کردن دادهها در سرویس algolia را در اختیار داریم.
ایجاد قابلیت اندیسگذاری و جستجو در مدلها
در بخش قبلی ما همه کارهایی را که برای راهاندازی کتابخانههای Scout و Algolia لازم بود انجام دادیم و از این رو اینک میتوانیم دادهها را با استفاده از سرویس جستجوی Algolia اندیسگذاری و جستجو کنیم.
در این بخش مثالی را بررسی میکنیم که شیوه اندیس کردن دادههای موجود و بازیابی نتایج جستجو از Algolia را نمایش میدهد. تصور ما بر این است که شما مدل Post پیشفرض را در اپلیکیشن خود دارید و در مثال خود نیز از آن استفاده خواهیم کرد.
نخستین کاری که باید انجام دهیم، افزودن خصیصه Laravel\Scout\Searchable به مدل Post است. بدین ترتیب مدل Post قابل جستجو میشود و لاراول رکوردهای پست را هر بار که یک رکورد پست، اضافه، بهروزرسانی یا حذف میشود، با اندیس Algolia همگامسازی میکند.
بدین ترتیب مدل Post برای جستجو مناسبسازی میشود. در ادامه و در وهله نخست فیلدهایی را که میبایست اندیسگذاری شوند پیکربندی کنیم. البته لازم نیست همه فیلدهای مدل را در Algolia اندیسگذاری کنید و بهتر است آن را سبک و کارآمد نگه داریم. در واقع در اغلب موارد به چنین کاری نیاز هم نداریم.
میتوان toSearchableArray را در کلاس مدل اضافه کرد تا فیلدهایی که قرار است اندیسگذاری شوند، پیکربندی شوند.
اکنون آماده ایمپورت و اندیسگذاری رکوردهای موجود Post در Algolia هستیم. در واقع کتابخانه Scout این کار را از طریق ارائه دستور artisan زیر سادهتر ساخته است:
این دستور همه رکوردهای مدل Post را در یک حرکت ایمپورت میکند. همه آنها به محض ایمپورت شدن، اندیسگذاری میشوند و از این رو در این لحظه آماده کوئری زدن هستند. در ادامه داشبورد Algolia را بررسی کنید تا رکوردهای ایمپورت شده و دیگر ابزارها را مشاهده کنید.

جمعبندی طرز کار Scout
در این بخش مثالی را ارائه میکنیم که شیوه اجرای عمل جستجو و عملیات CRUD را که به صورت آنی با اندیس Algolia همگامسازی شدهاند نمایش میدهد.
در این بخش فایل app/Http/Controllers/SearchController.php را با محتوای زیر ایجاد میکنیم:
البته ما باید مسیرهای مرتبط را نیز اضافه کنیم:
در ادامه از متد query استفاده می کنیم تا ببینیم شیوه جستجو در Algolia چگونه است:
خصیصه Searchable
به یاد داشته باشید که ما مدل Post را با افزودن خصیصه Searchable قابل جستجو کردهایم. از این رو مدل Post میتواند از متد search برای بازیابی رکوردها از اندیس Algolia استفاده کند. در مثال فوق ما تلاش کردهایم رکوردهایی را که با کلیدواژه title مطابقت دارند بازیابی کنیم.
در ادامه یک متد add وجود دارد که گردش کار افزودن یک رکورد جدید post را تقلید میکند.
در کد فوق هیچ نکته جذابی وجود ندارد و صرفاً یک رکورد post جدید با استفاده از مدل Post ایجاد کرده است. اما مدل Post خصیصه Searchable را پیادهسازی میکند و از این رو لاراول در این مورد به مقداری کار اضافی برای اندیس کردن رکورد جدیداً ایجاد شده در Algolia دارد. بدین ترتیب همان طور که میبینید اندیسگذاری به صورت آنی صورت میگیرد.
درنهایت یک متد delete وجود دارد که آن را نیز بررسی میکنیم:
همان طور که انتظار میرود، این رکورد بیدرنگ پس از حذف شدن از پایگاه داده از اندیس Algolia نیز حذف میشود.
در واقع در صورتی که بخواهید مدلهای موجود را قابل جستجو بکنید، نیاز به هیچ تلاش اضافی از سمت شما وجود ندارد. همه چیز از سوی کتابخانه Scout با استفاده از مشاهدهگرهای مدل مدیریت میشود.
سخن پایانی
بدین ترتیب به پایان این مقاله با موضوع بررسی اجرای جستجوی تمام متن در لاراول با استفاده از کتابخانه Scout و سرویس ابری Algolia رسیدیم. در این مسیر مواردی که لازم بود نصب شوند را توضیح دادیم و با ارائه مثالهای واقعی عملکرد آن را مورد بررسی قرار دادیم.
منبع: فرادرس
مسئله فروشنده دوره گرد در جاوا — به زبان ساده
در این راهنما در مورد الگوریتم «تبرید شبیهسازی شده» (Simulated Annealing) صحبت خواهیم کرد و مثالی از پیادهسازی آن را بر مبنای مسئله فروشنده دوره گرد (TSP) ارائه میکنیم.
تبرید شبیهسازی شده
الگوریتم شبیهسازیشده یک راهحل شهودی برای حل کردن مسائلی با فضای جستجوی بزرگ محسوب میشود. نام و منبع الهام این الگوریتم از موضوع تبرید در متالوژی ناشی میشود. این تکنیکی است که در آن حرارتدهی و خنک کردن کنترلشده یک ماده صورت میگیرد.
به طور کلی تبرید شبیهسازی شده موجب کاهش احتمال پذیرش راهحلهای نادرست در زمان کاوش فضای راهحل و کاهش دمای سیستم میشود. انیمیشن زیر سازوکار یافتن بهترین راهحل را با الگوریتم تبرید شبیهسازی شده نمایش میدهد:
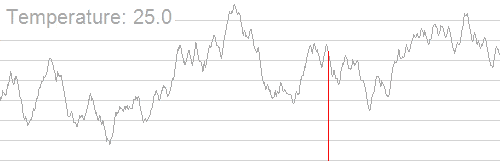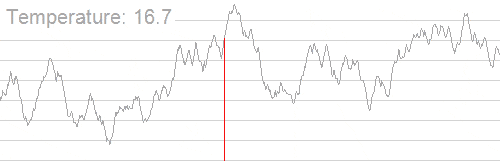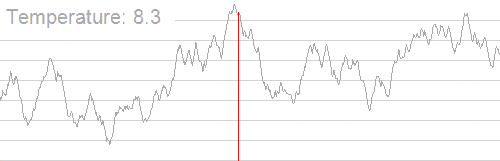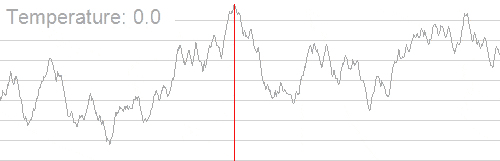
همان طور که مشاهده میکنید؛ الگوریتم از یک بازه وسیعی از راهحل با دمای بالای سیستم استفاده میکند و به دنبال نقطه بهینه سراسری میگردد. زمانی که دما کاهش مییابد، بازه جستجو کوچکتر میشود تا این که به بهینه سراسری میرسد.
این الگوریتم چند پارامتر دارد که با آنها کار میکند:
- تعداد تکرارها: شرط توقف برای شبیهسازی است.
- دمای اولیه: انرژی آغازین سیستم است.
- پارامتر نرخ خنکسازی: درصد کاهش دمای سیستم را تعیین میکند.
- کمینه دما: شرایط اختیاری توقف است.
- زمان شبیهسازی: شرایط اختیاری توقف است.
مقادیر این پارامترها باید به دقت انتخاب شوند، چون ممکن است تأثیر زیادی روی عملکرد فرایند بگذارند.
مسئله فروشنده دورهگرد
مسئله فروشنده دورهگرد (TSP) شناختهشدهترین مسئله بهینهسازی رایانه در دنیای مدرن محسوب میشود. به بیان ساده این مسئله به یافتن مسیر بهینه بین گرههای یک گراف گفته میشود. مسافت کلی سفر میتواند یکی از معیارهای سفر باشد.
مدل جاوا
برای حل مسئله TSP باید کلاسهای مدل را که City و Travel نام دارند در اختیار داشته باشیم. در کلاس اول شرایط گرهها را در گراف ذخیره میکنیم:
متد سازنده کلاس City، امکان ایجاد موقعیتهای تصادفی شهرها را به ما میدهد. منطق (..)distanceToCity مسئول محاسبه مسافت بین شهرها است.
کد زیر مسئول مدلسازی گردش یک فروشنده دورهگرد است. کار خود را با ایجاد ترتیب اولیه شهرها در سفر آغاز میکنیم:
علاوه بر ایجاد مسیر اولیه، باید متدهایی برای تعویض دو شهر تصادفی در ترتیب سفر نیز تهیه کنیم. ما از آن برای جستجوی راهحلهای بهتر درون الگوریتم تبرید شبیهسازی شده استفاده میکنیم:
افزون بر آن باید یک متد برای بازگرداندن تعویض ایجاد شده در مرحله قبلی نیز داشته باشیم که اگر راهحل جدید پذیرفته نشود مورد استفاده قرار میگیرد:
آخرین متد که باید داشته باشیم، محاسبه مسافت کلی سفر است که به عنوان معیار بهینه بودن استفاده میشود:
اینک روی بخش اصلی مسئله یعنی پیادهسازی الگوریتم تبرید شبیهسازی شده متمرکز میشویم.
پیادهسازی الگوریتم تبرید شبیهسازی شده
در پیادهسازی زیر برای الگوریتم تبرید شبیهسازی شده قصد داریم مسئله TSP را حل کنیم. به عنوان یادآوری باید بگوییم که هدف ما یافتن کوتاهترین مسافت برای سفر بین دو شهر است.
برای آغاز فرایند باید سه پارامتر اصلی یعنی startingTemperature ،numberOfIterations و coolingRate را ارائه کنیم:
پیش از آغاز شبیهسازی، ترتیب اولیه (تصادفی) شهرها را ایجاد و مسافت کلی سفر را محاسبه میکنیم. از آنجا که این نخستین محاسبه مسافت است باید آن را درون متغیر bestDistance همراه با currentSolution ذخیره کنیم.
در گام بعدی یک حلقه شبیهسازیهای اصلی را آغاز میکنیم:
این حلقه به تعداد تکرارهایی که تعیینشده اجرا میشود. به علاوه یک شرط نیز برای توقف آن تعیین کردهایم که به صورت کاهش دما به کمتر از 0.1 است. بدین ترتیب میتوانیم در زمان شبیهسازیها صرفهجویی کنیم، زیرا در دماهای پایین، اختلاف بهینهسازیها چندان درخور توجه نیست. در ادامه منطق اصلی الگوریتم تبرید شبیهسازی شده را میبینید:
یافتن کوتاهترین مسافت
در هر گام از شبیهسازی به صورت تصادفی دو شهر را در ترتیب سفر قرار میدهیم. به علاوه currentDistance را محاسبه میکنیم، اگر مسافت جدید پایینتر از bestDistance باشد، آن را به عنوان بهترین نتیجه (bestDistance) ذخیره میکنیم.
در غیر این صورت بررسی میکنیم که آیا تابع بولتزمان احتمال توزیع پایینتر از مقدار انتخاب شده تصادفی در بازه 0 تا 1 است یا نه. اگر چنین بود شهرها را عوض میکنیم؛ در غیر این صورت ترتیب جدید شهرها را نگه میداریم، چون به ما کمک میکند که از کمینههای موضعی احتراز کنیم. در نهایت در هر گام از شبیهسازی دما را به میزان coolingRate کاهش میدهیم:
پس از این که شبیهسازی پایان یافت، بهترین راهحل را که با استفاده از الگوریتم تبرید شبیهسازی شده به دست آمده است، بازگشت میدهیم. در ادامه چند نکته در مورد انتخاب پارامترهای بهترین شبیهسازی ارائه شده که باید مورد توجه قرار دهید:
- در فضاهای راهحل کوچک بهتر است دمای آغازین پایین باشد و نرخ خنکسازی کاهش یابد تا زمان شبیهسازی بدون تأثیر منفی روی کیفیت، پایین بماند.
- برای فضاهای راهحل بزرگتر بهتر است نرخ آغازین دما بالا باشد و نرخ خنکسازی کم انتخاب شود، چون ممکن است کمینههای موضعی زیادی وجود داشته باشند.
- همواره زمان کافی برای شبیهسازی از دماهای بالا تا پایین در اختیار سیستم قرار دهید.
فراموش نکنید که پیش از آغاز شبیهسازیهای اصلی، زمان بیشتری را صرف تنظیم الگوریتم با وهلههای کوچکتر مسئله بکنید، چون موجب بهبود نتیجه نهایی میشود.
سخن پایانی
در این راهنمای کوتاه با الگوریتم تبرید شبیهسازی شده آشنا شدیم و مسئله فروشنده دورهگرد را حل کردیم. امیدواریم این مطلب میزان کارآمد بودن این الگوریتم ساده را در زمان استفاده برای انواع خاصی از مسائل بهینهسازی به شما نشان داده باشد. برای مشاهده کد کامل این پیادهسازی به این آدرس گیتهاب (+) مراجعه کنید.
منبع: فرادرس
ساخت نوع های فرعی مبتنی بر شرط در تایپ اسکریپت — به زبان ساده
در این مقاله قصد داریم نوع های فرعی مبتنی بر شرط در تایپ اسکریپت و همچنین انواع «نگاشت» (Mapping) را مورد بررسی قرار دهیم. هدف ما این است که نوعی ایجاد کنیم که همه کلیدهایی را که با شرط خاصی مطابقت ندارند را از اینترفیس فیلتر کند.
به این منظور نیازی به آشنایی با جزییات نوعهای نگاشتی وجود ندارد. کافی است بدانید که تایپاسکریپت امکان انتخاب یک نوع موجود و ایجاد تغییر اندک در آن برای ایجاد نوع جدید را به ما میدهد. این بخشی از «کامل بودن تورینگ» (Turing Completeness) آن است.
نوع را میتوان به صورت تابع در نظر گرفت. هر نوع یک نوع دیگر را به عنوان ورودی میگیرد، روی آن نوعی محاسبات اجرا میکند و نوع جدیدی به عنوان خروجی تولید میکند. اگر با <Partial<Type یا <Pick<Type, Keys آشنا هستید، این فرایند نیز کاملاً شبیه آن است.
بیان مسئله
فرض کنید یک شیء پیکربندی دارید. این شیء شامل گروههای مختلفی از کلیدها مانند Ids ،Dates و functions است. این شیء میتواند ناشی از یک API باشد و یا از سوی افراد مختلف سالها نگهداری شود تا این که کاملاً بزرگ شده باشد.
ما میخواهیم تنها کلیدهایی را از نوع خاص استخراج کنیم. این فرایند شبیه به این است که تنها تابعهایی که Promise بازگشت میدهند را انتخاب کنیم یا چیزی سادهتر مانند کلید از نوع number داشته باشیم.
ما به یک نام و تعریف نیاز داریم و از این رو از <SubType<Base, Condition استفاده میکنیم.
بدین ترتیب دو ژنریک تعریف کردهایم که به وسیله آن SubType را پیکربندی خواهیم کرد:
- Base – اینترفیسی است که قرار است آن را تغییر دهیم.
- Condition – نوع دیگری است که به ما اعلام میکند کدام مشخصهها باید در شیء جدید حفظ شوند.
ورودی
به منظور تست کردن یک شیء Person داریم که از نوعهای متفاوتی به صورت string ،number ،Function تشکیل یافته است. این همان «شیء عظیم» ما است که میخواهیم فیلتر کنیم.
خروجی مورد انتظار
برای مثال SubType به نام Person بر اساس نوع رشته میتواند تنها کلیدهایی از نوع رشته را بازگشت دهد:
گام به گام به سوی راهحل
در این بخش برای مسئلهای که در بخش قبل مطرح شد، یک راهحل را به صورت گام به گام مطرح میکنیم.
گام 1: Baseline
بزرگترین مشکل، یافتن و حذف کلیدهایی است که با شرط ما مطابقت ندارند. خوشبختانه تایپاسکریپت 2.8 دارای امکانی به نام نوعهای شرطی است. ما به عنوان یک ترفند کوچک قصد داریم نوع پشتیبانی برای یک محاسبه آتی بسازیم.
برای هر کلید یک شرط استفاده شده است. بسته به نتیجه نام را به صورت نوع تعیین میکنیم یا از مقدار never استفاده میکنیم که فلگی برای کلیدهایی است که نمیخواهیم در نوع جدید ظاهر شوند. این یک نوع خاص و متضاد any است. به این نوع هیچ چیز نمیتوان انتساب داد.
در ادامه به روش ارزیابی کد میپردازیم:
توجه کنید که ‘id’ یک مقدار نیست، اما نسخه دقیقتری از نوع string محسوب میشود. ما قصد داریم از آن در ادامه استفاده کنیم. تفاوت بین نوع string و ‘id’ به صورت زیر است:
گام 2: فهرستبندی کلیدهایی که با شرط نوع مطابقت دارند
در این مرحله کار اصلی انجام یافته است. اکنون هدف جدیدی داریم و آن گردآوری نامهای کلیدهایی است که از اعتبارسنجی ما عبور کردهاند. در مورد <SubType<Person, string این مقدار برابر با ‘name’ | ‘lastName’ خواهد بود:
ما از کد مرحله قبلی استفاده کرده و تنها یک بخش دیگر به نام [keyof Base] به آن اضافه میکنیم.
کار این بخش آن است که رایجترین انواع مشخصههای مفروض را گردآوری کرده و never را نادیده بگیرد چون هیچ راهی برای استفاده از آنها وجود ندارد.
در کد فوق مثالی از بازگشت string | number داریم. چنان که میبینید در نخستین گام نوع کلید را با نام آن عوض کردهایم.
اینک به راهحل نهایی نزدیک شدهایم.
ما اکنون آماده ساخت شیء نهایی خود هستیم. صرفاً از Pick استفاده میکنیم که روی نامهای کلید ارائه شده میچرخد و نوع متناظر با شیء جدید را استخراج میکند.
در کد فوق Pick یک نوع نگاشت درونی است که از تایپاسکریپت 2.1 به بعد ارائه شده است:
راهحل نهایی
اگر بخواهیم همه گامهای فوق را جمعبندی کنیم باید بگوییم که ما دو نوع ایجاد کردهایم که از پیادهسازی SubType ما پشتیبانی میکنند:
نکته: این صرفاً یک سیستم نوعبندی است. میتوان در آن از حلقه و حتی اعمال گزارههای شرطی نیز استفاده کرد. برخی افراد ترجیح میدهند که درون یک عبارت نوعهایی داشته باشند:
کاربرد
کاربردهای مختلفی که این نوعهای شرطی دارند به شرح زیر هستند:
۱. استخراج صرف انواع کلید primitive از JSON:
2. فیلتر کردن همه چیز به جز تابعها:
شما میتوانید به کاربردهای دیگر این امکان نیز فکر کنید.
این راهحل چه مسائلی را حل نمیکند؟
۱. یک سناریوی جالب این است که یک زیرنوع Nullable بسازیم
اما از آنجا که string | null نمیتواند به null انتساب پیدا کند کار نخواهد کرد. البته ممکن است شما ایدهای برای حل این مشکل داشته باشید!
2. فیلترینگ زمان اجرا
چنان که میدانید نوعها در زمان کامپایل پاک میشوند. بدین ترتیب هیچ نقشی در شیء واقعی ندارند. اگر بخواهید یک شیء را به نوعی فیلتر کنید، باید کد جاوا اسکریپت برای آن بنویسید.
ضمناً استفاده از ()Object.keys روی چنین ساختارهایی توصیه نمیشود، زیرا نتیجه «زمان اجرا» ممکن است از نوع مفروض متفاوت باشد.
منبع: فرادرس