طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیآموزش ری اکت (React) — مجموعه مقالات مجله فرادرس
ریاکت یک کتابخانه جاوا اسکریپت برای ساخت رابط کاربری است که به نام React یا React.js شناخته میشود. این کتابخانه از سوی فیسبوک و جامعهای از توسعهدهندگان و شرکتهای مستقل نگهداری میشود. ریاکت میتواند به عنوان یک مبنا برای توسعه اپلیکیشنهای تکصفحهای یا موبایل استفاده شود زیرا کاربرد اصلی آن ارائه روشی ساده برای واکشی سریع دادههای در حال تغییر و نیازمند ثبت است. با این وجود واکشی دادهها تنها آغاز اتفاقهایی است که در یک صفحه وب رخ میدهند و به همین دلیل اپلیکیشنهای ریاکت به طور معمول از کتابخانههای اضافی برای مدیریت حالت، مسیریابی و تعامل با API استفاده میکنند. در این نوشته به جمعبندی مقالات آموزش ری اکت مجله فرادرس میپردازیم.
فهرست مقالههای آموزشی
در این مطلب به معرفی سری مقالات آموزشی مجله فرادرس در خصوص فریمورک ریاکت میپردازیم. این مطالب در ادامه به دو دسته «نظری» و «عملی» تقسیم شدهاند. دسته نظری پستهایی را شامل میشود که مباحث تئوری را پوشش دادهاند و در دسته عملی، میتوانید از طریق مثال و کدهای نمونه بهتر و بیشتر با فریمورک مورد بحث آشنا شوید و آن را فرا بگیرید.
مقالات نظری
در این مطلب مفاهیم اساسی جاوا اسکریپت مدرن برای استفاده از React معرفی شدهاند که شامل معرفی متغیرها، تابعهای Arrow، همچنین Rest و Spread، تخریب شیء و آرایه، الفاظ قالبی، کلاسها، Callback-ها، Promise-ها، و ماژولهای ES میشود.
در فصل دوم از این سری مقالات آموزش ریاکت در مورد اپلیکیشنهای تکصفحهای، رویکرد اعلانی ریاکت، تغییرناپذیری، محض بودن یا purity، ترکیببندی، DOM مجازی و گردش داده غیر جهتدار صحبت کردیم. اپلیکیشنهای با صفحه منفرد در جاوا اسکریپت ساخته میشوند، یا بهتر است بگوییم در جاوا اسکریپت کامپایل و در مرورگر اجرا میشوند. فناوری مورد استفاده همواره یکسان بوده است، اما فلسفه و برخی اجزای کلیدی طرز کار اپلیکیشنها فرق کرده است. در این مقاله به معرفی جامع این نوع از اپلیکیشنها پرداختهایم.
در این بخش از سری مقالات آموزش ریاکت موضوعات جیاسایکس (JSX)، کامپوننتها، حالت یا State، مشخصهها یا Props، کامپوننتهای ارائهای در برابر کانتینری، State در برابر Props، انواع Prop، فرگمان ریاکت، رویدادها و رویدادهای چرخه عمر صحبت کردیم. JSX یک فناوری معرفی شده از سوی React است. با این که React بدون استفاده از JSX نیز کاملاً به خوبی عمل میکند، اما JSX یک فناوری ایدهآل برای کار با کامپوننتها محسوب میشود و از این رو در ریاکت استفاده زیادی از آن میکنیم. شاید در ابتدا به نظر بیاید که JSX مانند ترکیب کردن HTML و جاوا اسکریپت است، اما این حرف صحیح نیست. چون وقتی از JSX استفاده میکنیم، در واقع از یک ساختار اعلانی برای نوشتن UI یک کامپوننت بهره میگیریم.
در بخش چهارم سری مقالات آموزش ریاکت در خصوص برخی از مفاهیم پیشرفته این فریمورک شامل فرمها در ریاکت، ارجاع به یک عنصر DOM، رندرینگ سمت سرور، «API زمینه» (Context API)، «کامپوننتهای درجه بالا» (Higher order components)، رندر Props، «قلابها» (Hooks) و «افراز کد» (Code splitting) صحبت کردیم. بدین ترتیب مباحث نظری فریمورک ریاکت به پایان میرسد و در بخشهای بعدی بیشتر روی موضوعات عملی تمرکز کردهایم.
مقالات عملی
در این بخش از سری مقالات آموزشی ریاکت با ارائه مثالی از یک اپلیکیشن ساده شمارنده به پیادهسازی موارد نظری آموزش داده شده پرداختیم. در این مثال خلاصه، یک اپلیکیشن بسیار ساده شمارنده در ریاکت ساختیم و بسیاری از مفاهیم و نظریههایی که در بخشهای قبلی معرفی کردهایم را در آن به کار گرفتیم. همچنین مثالی از واکشی و نمایش اطلاعات کاربران گیتهاب از طریق API ارائه کردیم. در این مثال کاملاً ساده یک فرم را نمایش میدهیم که اقدام به پذیرش نام کاربری گیتهاب میکند و زمانی که رویداد submit را دریافت کرد، از API گیتهاب تقاضا میکند که اطلاعات کاربر را ارائه کرده و در ادامه آن را نمایش دهد.
در این بخش از سری مطالب آموزش React، چگونگی استایلدهی و CSS در React را مورد بررسی قرار دادهایم. زمانی که از React استفاده میکنیم، روشهای زیادی برای افزودن استایل به کامپوننتها وجود دارد که در این مقاله همه آنها را بررسی کردهایم. از جمله این روشها استفاده از کلاسها و CSS، استفاده از خصوصیت Style، استفاده از ماژولهای CSS، کامپوننتهای استایلدار و استفاده از props برای سفارشیسازی کامپوننتها است.
در این بخش از سری مقالات آموزش React با Babel و Webpack که به بستهبندی و آمادهسازی کد اپلیکیشنهای ریاکت برای توزیع کمک میکنند آشنا خواهید شد. Babel ابزاری جذاب است که مدتها از زمان معرفی آن میگذرد و امروزه تقریباً همه توسعهدهندگان جاوا اسکریپت از آن بهره میگیرند. این وضعیت در آینده نیز تداوم خواهد داشت، زیرا Babel اینک بخشی جداییناپذیر از جاوا اسکریپت محسوب میشود و مشکل بزرگی را برای افراد زیادی حل کرده است. Webpack نیز ابزاری است که امکان کامپایل کردن ماژولهای جاوا اسکریپت را فراهم میکند و به نام module bundler نیز مشهور است. اگر تعداد بالایی از فایلها داشته باشیم، Webpack میتواند یک فایل منفرد (یا چند فایل معدود) تولید کند که به اجرای اپلیکیشن شما میپردازند.
در این فصل از راهنمای جامع ریاکت با روشهای تست اپلیکیشنهایی که در فریمورک React نوشته میشوند و به طور خاص ابزار Jest آشنا خواهید شد. Jest کتابخانهای برای تست کدهای جاوا اسکریپت است. این کتابخانه اوپنسورس از سوی فیسبوک نگهداری میشود و به طور خاص برای تست کردن کدهای React مناسب است. با این حال Jest محدود به React نیست و میتوان از آن برای تست کردن هر نوع کد جاوا اسکریپت استفاده کرد.
اکوسیستم شکلگرفته پیرامون ریاکت بسیار بزرگ است. در این مقاله که آخرین مقاله از سری مقالات نهگانه آموزش ریاکت محسوب میشود، 4 مورد از محبوبترین پروژهها بر مبنای React یعنی React Router ،Redux ،Next.js و Gatsby را معرفی میکنیم. در این نوشته به جمعبندی مباحث مطرحشده پرداختهایم.
جمعبندی
ریاکت در سال 2011 از سوی یکی از مهندسان فیسبوک به نام «جردن ووک» (Jordan Walke) ایجاد شد. این کتابخانه نخستین بار در سال 2011 در نیوزفید فیسبوک و سپس در سال 2012 در اینستاگرام استفاده شد. کتابخانه مذکور در می 2013 به صورت متن باز عرضه شده است. React Native که امکان توسعه اپلیکیشنهای اندروید و iOS را فراهم ساخته است در سال 2015 از سوی فیسبوک به صوت متن باز عرضه شد. در سال 2017 فیسبوک React Fiber را معرفی کرد که الگوریتم مرکزی جدید کتابخانه فریمورک ریاکت برای ساخت رابطهای کاربری است. ریاکت فیبر به بنیادی برای هر گونه توسعه و بهبود آتی فریمورک ریاکت تبدیل خواهد شد. آخرین نسخه از فریمورک ریاکت با شماره 16.8.4 در 5 مارس 2019 عرضه شده است.
منبع: فرادرس
الگوریتم یافتن اعداد متباین (Coprime) در جاوا — به زبان ساده
دو عدد a و b زمانی اعداد متباین یا نسبت به هم اول نامیده میشوند که تنها عامل یا فاکتور مشترک آنها عدد 1 باشد. این نوع اعداد به نام «متقابلاً اول» (Mutually prime) یا coprime نیز نامیده میشوند. در این راهنما به بررسی اول بودن دو عدد نسبت به هم در زبان برنامهنویسی جاوا میپردازیم.
الگوریتم یافتن بزرگترین عامل مشترک
چنان که اشاره کردیم اگر بزرگترین مقسومعلیه مشترک دو عدد a و b برابر با 1 باشد، در این صورت a و b نسبت به هم اول یا اعداد متباین هستند. در نتیجه برای تعیین این که آیا دو عدد نسبت به هم اول هستند یا نه، کافی است بررسی کنیم که بزرگترین مقسومعلیه مشترک آنها 1 باشد.
پیادهسازی الگوریتم اقلیدس
در این بخش از الگوریتم اقلیدس برای محاسبه بزرگترین مقسومعلیه مشترک اعداد استفاده میکنیم. پیش از آن که این پیادهسازی را ارائه کنیم، اقدام به جمعبندی الگوریتم خود کرده و یک مثال کوچک در مورد شیوه استفاده از آن را بررسی میکنیم تا عملکردش را درک کنیم.
بنابراین تصور کنید دو عدد صحیح به نامهای a و b داریم. با بهرهگیری از یک رویکرد مبتنی بر حلقه تکرار، ابتدا a را بر b تقسیم کرده و باقیمانده را به دست میآوریم. سپس مقدار a را برابر با b میگیریم و مقدار b را نیز برابر با باقیمانده در نظر میگیریم. این فرایند را تا زمانی که b=0 شود ادامه میدهیم. در نهایت زمانی که به این نقطه برسیم، مقدار a را به عنوان بزرگترین مقسومعلیه مشترک بازگشت میدهیم و اگر a = 1 باشد میگوییم که a و b نسبت به هم اول هستند.
این فرایند را با دو عدد a = 81 و b = 35 بررسی میکنیم. در این حالت باقیمانده تقسیم 81 بر 35 برابر با 11 است. بنابراین در گام نخست فرایند تکراری خود، مقادیر a = 35 و b = 11 به دست میآیند. متعاقباً یک مرحله دیگر از تکرار را اجرا میکنیم.
باقیمانده تقسیم 35 بر 11 برابر با 2 است. در نتیجه ما اینک مقدار a = 11 و b = 2 را داریم، چون جای مقادیر را با هم عوض کردهایم. به این کار ادامه میدهیم و در گام بعدی، نتیجه a = 2 و b = 1 به دست میآید. اینک به هدف خود نزدیک شدهایم.
در نهایت پس از یک تکرار دیگر، به مقادیر a = 1 و b = 0 میرسیم. این الگوریتم مقدار 1 را بازگشت میدهد و میتوانیم نتیجه بگیریم که 81 و 5 واقعاً نسبت به هم اول هستند.
پیادهسازی دستوری
ابتدا یک نسخه از برنامه دستوری جاوا را برای الگوریتم اقلیدسی چنان که در بخش قبل توضیح دادیم، پیادهسازی میکنیم.
همان طور که میتوان مشاهده کرد، در حالتی که a کمتر از b باشد، مقادیر را پیش از شمارش جابجا میکنیم. این الگوریتم زمانی که b برابر با 0 باشد متوقف میشود.
پیادهسازی بازگشتی
در ادامه پیادهسازی بازگشتی این الگوریتم را نیز بررسی میکنیم. این نسخه احتمالاً تمیزتر است، زیرا از تعویض صریح مقادیر متغیرها خودداری کردهایم:
استفاده از پیادهسازی BigInteger
شاید برایتان سؤال پیش آمده باشد که آیا الگوریتم یافتن بزرگترین مقسومعلیه مشترک قبلاً در جاوا پیادهسازی شده است یا نه؟ البته که شده است. کلاس BigInteger یک روش برای یافتن بزرگترین مقسومعلیه مشترک ارائه میکند که به پیادهسازی الگوریتم اقلیدسی به این منظور پرداخته است. با استفاده از این روش میتوان الگوریتم یافتن اعداد متباین را به روش سادهتری بازنویسی کرد:
سخن پایانی
در این راهنمای کوتاه به یک راهحل برای مسئله یافتن وضعیت اول بودن دو عدد نسبت به هم پرداختیم و سه پیادهسازی مختلف برای الگوریتم یافتن بزرگترین مقسومعلیه مشترک معرفی کردیم. برای مشاهده کد منبع این مثالها میتوانید به این آدرس گیتهاب (+) مراجعه کنید.
منبع: فرادرس
تنسورفلو (TensorFlow) — از صفر تا صد
«تنسورفلو» (TensorFlow)، یک کتابخانه رایگان و «متنباز» (Open Source) برای «برنامهنویسی جریان داده» ( Dataflow Programming) و «برنامهنویسی متمایزگر» (Differentiable Programming)، جهت انجام طیف وسیعی از وظایف است. تنسورفلو، کتابخانهای برای «ریاضیات نمادین» (Symbolic Math) محسوب میشود و کاربردهای گوناگونی در «یادگیری ماشین» (Machine Learning) دارد که از آن جمله میتوان به پیادهسازی «شبکههای عصبی» (Neural Networks) اشاره کرد. این کتابخانه توسط تیم «گوگل برین» (Google Brain)، برای مصارف داخلی گوگل توسعه داده شده بود؛ ولی در نهم نوامبر سال ۲۰۱۵ با گواهینامه «آپاچی ۲.۰ متنباز» منتشر شد. در حال حاضر، کتابخانه تنسورفلو، در گوگل هم برای پروژههای تحقیقاتی و هم پروژههای عملیاتی مورد استفاده قرار میگیرد.
تنسورفلو
نسخه ۱.۰.۰ تنسورفلو، یازدهم فوریه سال ۲۰۱۷ منتشر شد. با وجود آنکه «پیادهسازی مرجع» (Reference Implementation) این کتابخانه در «دستگاههای مجرد« (Single Devices) اجرا میشد، این نسخه قابل اجرا روی چندین CPU و GPU (با افزونههای اختیاری CUDA و SYCL برای انجام پردازشهای همه منظوره روی واحد پردازنده گرافیکی) بود. کتابخانه تنسورفلو برای سیستمعاملهای ۶۴ بیتی لینوکس، ویندوز، مکاواس و پلتفرمهای موبایل مانند اندروید و iOS موجود است.
این کتابخانه دارای معماری انعطافپذیری است که امکان توسعه آسان آن را برای پلتفرمهای گوناگون (GPU ،CPU و TPU)، و از دسکتاپ گرفته تا خوشهای از سرورها، موبایلها و دستگاههای جدید و لبه علم، فراهم میکند. محاسبات تنسورفلو به صورت «گرافهای جریان داده حالتمند» (Stateful Dataflow Graphs) بیان میشود. نام تنسورفلو از عملیاتی گرفته شده است که شبکههای عصبی روی آرایههای داده چندبعدی که از آنها با عنوان تانسور یاد میشود، انجام میدهند. در کنفرانس گوگل I/O که در ژوئن ۲۰۱۸ برگزار شد، «جف دین» (Jeff Dean) بیان کرد که ۱۵۰۰ مخزن در «گیتهاب» (GitHub)، از تنسورفلو نام بردهاند (آن را منشن کردهاند) که تنها پنج مورد از آنها توسط گوگل بوده است.
واحد پردازش تانسور (TPU)
در می ۲۰۱۶، گوگل از «واحد پردازش تانسور» (Tensor Processing Unit | TPU) خود پردهبرداری کرد که یک «مدار مجتمع با کاربرد خاص» (Application-Specific Integrated Circuit) (یک تراشه کامپیوتری) است. این تراشه، برای کاربردهای یادگیری ماشین و تنسورفلو طراحی شده بود. TPU یک «شتابدهنده هوش مصنوعی» (AI accelerator) قابل برنامهریزی است که برای فراهم کردن «توان عملیاتی» (Throughput) بالا برای «محاسبات دقت پایین» (Low-Precision Arithmetic) (برای مثال ۸ بیتی) طراحی شده است؛ این شتابدهنده، امکان ارائه مرتبه بزرگی بهتر بهینه شده «توان به ازای وات» (Performance Per Watt) را برای یادگیری ماشین میدهد.
در می ۲۰۱۷، گوگل انتشار نسل دوم TPUها را اعلام کرد که برای «موتور محاسبه گوگل» (Google Compute Engine) ارائه شده بودند. TPUهای نسل دوم، کارایی تا ۱۸۰ «ترافلاپس» (Teraflops) را فراهم میکردند و هنگامی که در خوشههای ۶۴ TPUیی قرار میگرفتند، تا ۱۱.۵ «پتافلاپس» (petaflops) کارایی را رقم میزدند. در فوریه ۲۰۱۸، گوگل اعلام کرد که در حال ساخت نسخه TPU برای «پلتفرم گوگل کلود» (Google Cloud Platform) هستند. در جولای ۲۰۱۸، Edge TPU منتشر شد. Edge TPU، یک تراشه «ایسیک» (ASIC) ساخته شده برای هدف خاص است که برای اجرا روی مدلهای یادگیری ماشین TensorFlow Lite در دستگاههای محاسباتی کوچک مانند گوشیهای هوشمند کوچک طراحی شده است؛ این موضوع با عنوان «رایانش لبهای» (Edge Computing) شناخته شده است.
تنسورفلو لایت
در می ۲۰۱۷، گوگل یک «پشته نرمافزاری» (Software Stack) با عنوان «تنسورفلو لایت» (TensorFlow Lite) را به طور ویژه برای توسعه موبایل معرفی کرد. در ژوئن ۲۰۱۹، تیم تنسورفلو یک نسخه ویژه توسعهدهندگان از موتور استنتاج GPU موبایل OpenGL ES 3.1 Compute Shaders را روی دستگاههای اندرویدی و Metal Compute Shaders را روی دستگاههای iOS منتشر کرد.
«پیکسل ویژوال کور» (PVC)
در اکتبر ۲۰۱۷، «گوگل پیکسل ۲» (Google Pixel 2) منتشر شد که دارای ویژگی «پیکسل ویژوال کور» (Pixel Visual Core | PVC) است که یک «واحد پردازش تصویر» (Image Processing Unit | IPU)، «واحد پردازش بینایی» (Vision Processing Unit | VPU) و «پردازنده هوش مصنوعی» (AI Processor) برای دستگاههای موبایل به شمار میآید. PVC از تنسورفلو برای یادگیری ماشین (و «زبان برنامهنویسی» (Halide ) برای پردازش تصویر) پشتیبانی میکند.
کاربردها
گوگل به طور رسمی الگوریتم «رنکبرین» (RankBrain) را ۲۶ اکتبر ۲۰۱۵ منتشر کرد که توسط تنسورفلو حمایت میشد. همچنین، «کلبریتوری» (Colaboratory | Colab) که یک «محیط نوتبوک ژوپیتر تنسورفلو» (TensorFlow Jupyter Notebook Environment) است را معرفی کرد که برای استفاده از آن، نیازی به نصب نیست. این محیط روی «ابر» (Cloud) اجرا میشود و نوتبوکهای خود را روی گوگل درایو ذخیره میکند. با وجود آنکه «کُلَب» (Colaboratory) بخشی از پروژه ژوپیتر است، اما توسعه آن توسط گوگل انجام میشود. از سپتامبر ۲۰۱۸، کلب فقط از کرنلهای پایتون ۲ و پایتون ۳ پشتیبانی میکند و دیگر کرنلهای ژوپیتر، یعنی «جولیا» (Julia) و «R» را پشتیبانی نمیکند.
ویژگیها
کتابخانه تنسورفلو دارای «رابطهای برنامهنویسی کاربردی» (Application programming interface | API) پایدار برای «زبان برنامهنویسی پایتون» (Python Programming Language) و زبان C و همچنین، رابطهای فاقد تضمین «سازگاری عقبرو» (backward compatible) رابط برنامهنویسی کاربردی برای ++C، «گو» (Go)، «جاوا» (Java)، «جاوا اسکریپت» (JavaScript) و«سوئیفت» (Swift) است. همچنین، دارای «بستههای شخص ثالث» (Third Party Packages) برای «سیشارپ» (#C)، «هسکل» (Haskell)، «جولیا» (Julia)، «آر» (R)، «اسکالا» (Scala)، «راست» (Rust)، «اکمل» (OCaml) و «کریستال» (Crystal) است.
برنامههای کاربردی
برنامههای کاربردی متعددی از تنسورفلو قدرت گرفتهاند که از این میان میتوان به نرمافزارهای توضیحات نویسی خوکار برای تصاویر، مانند «دیپدریم» (DeepDream) اشاره کرد. الگوریتم مبتنی بر یادگیری ماشین موتور جستجو با عنوان رنک برین (RankBrain) نیز مثال دیگری است که تعداد قابل توجهی از کوئریهای جستجو، جایگزینی و تکمیل نتایج جستجوی مبتنی بر الگوریتمهای ایستای سنتی را فراهم میکند.
تنسورفلو ۲.۰
«تنسورفلو دِو سامیت» (TensorFlow Dev Summit) گردهمایی است که هر سال فعالان حوزه یادگیری ماشین را از سراسر جهان به مدت دو روز گردهم میآورد. در این رویداد، شرکتکنندگان به گفتگوهای فنی سطح بالا، ارائه دموها و گفتگو با تیم و جامعه تنسورفلو میپردازند. در رویداد سال ۲۰۱۹، گوگل نسخه آلفا از تنسورفلو ۲.۰ را معرفی کرد. نسخه جدید با تمرکز بر افزایش بهرهوری توسعهدهندگان، سادگی و سهولت استفاده طراحی شده است. تغییراتی در تنسورفلو ۲.۰ به وقوع پیوسته که موجب افزایش بهرهوری کاربران آن میشود. همچنین، تغییرات متعددی در API آن انجام شده که از آن جمله میتوان به مرتبسازی مجدد آرگومانها، حذف APIهای زائد، تغییر نام سمبلها و تغییر مقادیر پیشفرض برای پارامترها اشاره کرد. در ادامه برخی از مهمترین تغییرات به وقوع پیوسته در تنسورفلو ۲.۰ بیان میشوند.
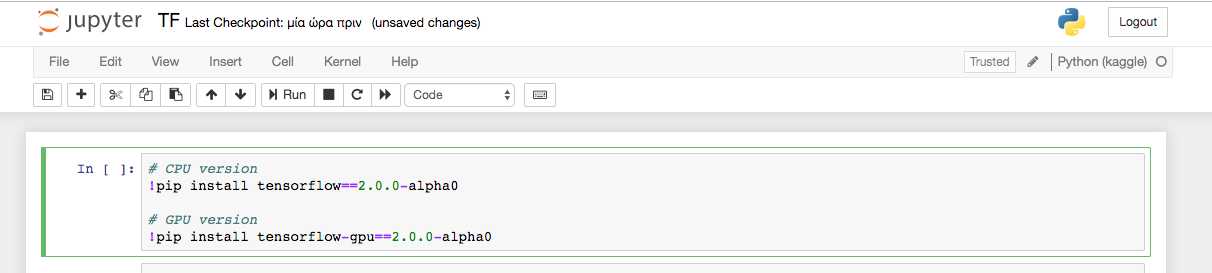
نصب تنسورفلو ۲.۰ آلفا
توصیه میشود که اگر کاربران قصد نصب این نسخه را روی کامپیوتر محلی خود برای ساخت یک محیط جدای پایتون/conda دارند، آن را فعال کرده و با وارد کردن و اجرای دستورات زیر در ترمینال، نصب را انجام دهند.
برای اطمینان حاصل کردن از اینکه تنسورفلو ۲.۰ با استفاده از دستورات بالا به درستی نصب شده است، دستور زیر را میتوان در ترمینال اجرا کرد.
گزینه دیگر برای حصول اطمینان از صحت نصب، باز کردن «ژوپیتر نوتبوک» (Jupyter Notebook) و اجرای دستورات زیر است.
همچنین، میتوان از Google Colaboratory [+] استفاده کرد که امکان راهاندازی نوتبوکهای پایتون را در محیط ابری به راحتی فراهم میکند. همچنین، دسترسی رایگان به GPU را به مدت ۱۲ ساعت برای یک بار ارائه میدهد. Colab به سرعت توانسته جایگاه خوبی را در میان کارشناسان یادگیری ماشین به عنوان یک پلتفرم ابری یادگیری ماشین کسب کند. در صورتی که کاربر تنسورفلو ۲.۰ نسخه GPU را روی Colab نصب کرده، مجددا باید بررسی کند که زمان اجرا «GPU» را به عنوان شتابدهنده زمان اجرا دارد. این کار با رفتن به مسیر Edit>Notebook settings امکانپذیر است.
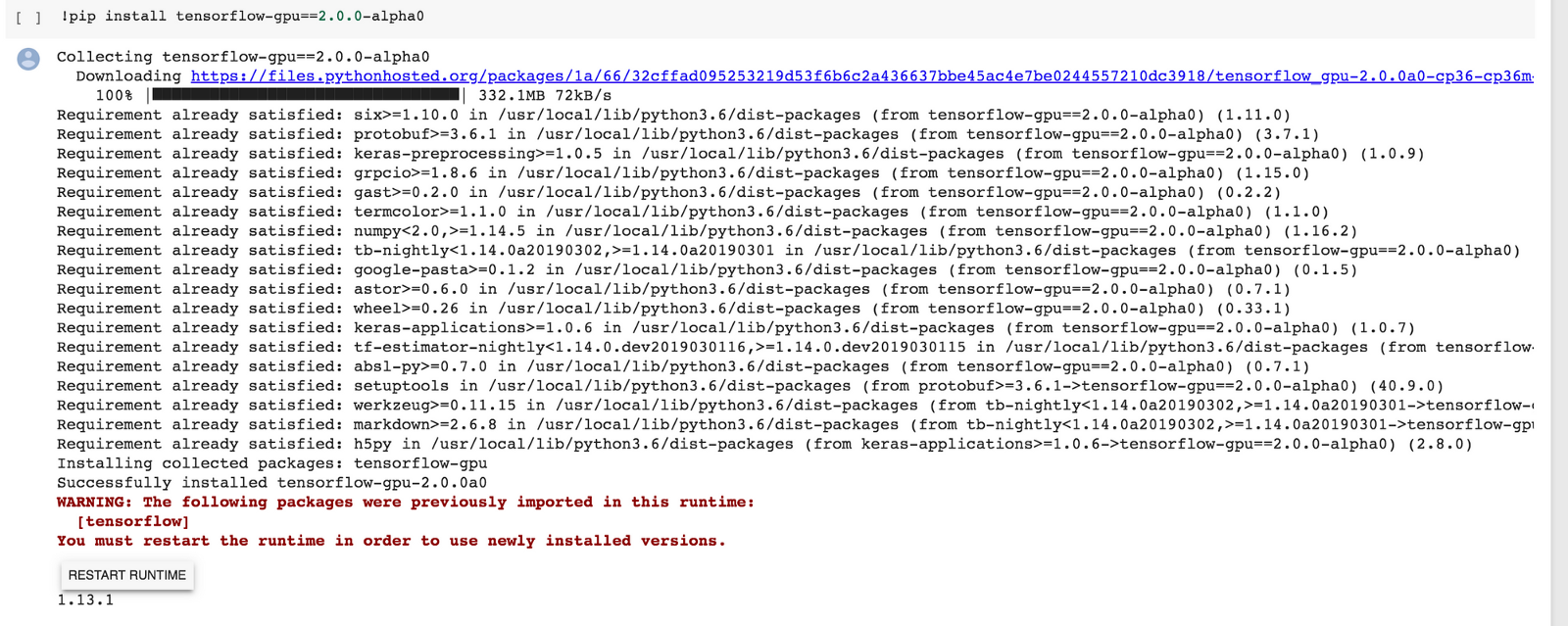
هنگام نصب TF 2.0 روی Colab، این امکان وجود دارد که از کاربر خواسته شود زمان اجرا (runtime) را بازنشانی کند. بنابراین، باید مراحل را ادامه و بازنشانی را حتما انجام دهد.
API تمیزتر
با توجه به آنکه «قوانین نامگذاری» (Naming Convention) خاص متعددی برای تنسورفلو وجود دارد، در بسیاری از موارد، کاربران هنگام استفاده از تنسورفلو نمیدانند که دقیقا از کدام API استفاده کنند. این مساله معمولا به دلایل زیر به وقوع میپیوندد.
- بستههای جدید زیادی اضافه میشوند.
- APIهای منسوخ شده زیادی وجود دارند.
- تغییر نامهای متعدد APIهای موجود

TF 2.0 با توجه به اینکه بسیاری از APIها از آن رفتهاند و یا انتقال داده شدهاند، مشکل بیان شده در بالا را حل میکند. برخی از تغییرات کلیدی که میتوان به آنها اشاره کرد، حذف tf.flags ،tf.app و tf.logging به سود absl-py متنباز، بازخانهدهی (Rehoming) پروژههایی که در tf.contrib قرار داشتند و پاکسازی فضای نام اصلی *.tf با انتقال توابع کمتر استفاده شده در زیربستههایی مانند tf.math است. برخی از APIها با معادل ۲.۰ خود جایگزین شدهاند که از این جمله نیز میتوان به tf.keras.metrics ، tf.summary و tf.keras.optimizers اشاره کرد.
اجرای مشتاقانه
«اجرای مشتاقانه» (Eager Execution) یک رابط ضروری، تعریف شده ضمن اجرا است که در آن، پردازشها بلافاصله پس از آنکه توسط پایتون فراخوانی شدند، اجرا میشوند. به عقیده برخی از توسعهدهندگانی که از تنسورفلو استفاده میکنند، این مهمترین ویژگی تنسورفلو ۲.۰ محسوب میشود. این قابلیت، امکان ساخت سریع نمونه اولیه را با فراخوانی حالت «Eager Execution» به عنوان حالت پیشفرض فراهم میکند. اما پیش از آنکه پیشتر رفته و بیشتر درباره چیستی حالت «Eager Execution» صحبت شود، ابتدا مسالهای که پیرامون «گراف محاسباتی استاتیک» (Static Computation Graph) موجود در TF 1.0 وجود داشت، مورد بررسی قرار میگیرد. هنگام اجرای مثال بالا در TF 1.0، گراف محاسباتی استاتیک زیر، ساخته میشود.
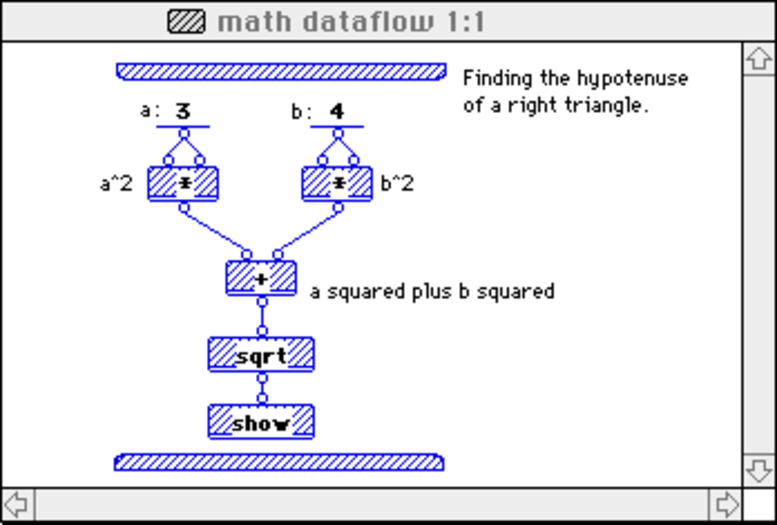
- با یک الگوی برنامهنویسی رایج مدل شده است، که جریان داده (Dataflow) نام دارد.
- در گراف Dataflow، «گرهها» (Nodes) واحدهای محاسباتی را نشان میدهند و «یالها» (Edges)، دادههای مصرف و یا تولید شده در محاسبات را نشان میدهند.
برای مثال، در گراف تنسورفلو، عملیات tf.square مرتبط به یک گره مجرد با دو یال ورودی است (ماتریس مشابهی دو برابر شده است) و یک یال خروجی (نتیجه توان دو). اما پرسشی که در این وهله مطرح میشود این است که چرا TF 1.0 از Dataflow استفاده میکند. در پاسخ به این سوال، میتوان موارد زیر را ذکر کرد.
- موازیسازی (Parallelism ): اجرای آسانتر پردازشها به صورت موازی
- اجرای توزیع شده (Distributed Execution): بخشبندی راحتتر گراف
- همگردانی (Compilation ): کامپایلر XLA کد سریعتری را با استفاده از ساختار گراف ایجاد میکند.
- قابلیت حمل (Portability ): گراف مستقل از زبان
میتوان گفت که روال اجرای TF 1.0 در گامهای زیر خلاصه میشود:
- ساخت روال ورود داده
- ساخت یک مدل؛ TF 1.0 گراف محاسباتی استاتیک را میسازد.
- خوراندن این دادهها از طریق این گراف محاسباتی، محاسبه زیان با استفاده از «تابع زیان» (Loss Function) و به روز رسانی وزنها (متغیرها) با «بازگشت به عقب» (Backpropagating) خطا
- توقف هنگامی که به چند معیار توقف میرسد.
اکنون، میتوان به مزایای افزودن قابلیت «حالت اجرای مشتاقانه» (Eager Execution Mode) به تنسورفلو ۲.۰ پرداخت.

حالت اجرای مشتاقانه چیست؟ در پاسخ به این سوال باید به موارد زیر اشاره کرد.
- یک پارادایم برنامهنویسی ضروری محسوب میشود که پردازشها را فورا ارزیابی میکند.
- عملیاتها، مقادیر گسسته را به جای ساخت یک گراف محاسباتی که بعدا اجرا میشود، باز میگردانند.
- هیچ سشن (Session) یا Placeholder نیست؛ در عوض، دادهها به توابع به عنوان آرگومان پاس داده میشوند.
در واقع، TF 2.0 چیزی را میسازد که از آن با عنوان «گراف محاسبات پویا» (Dynamic Computation Graph) یاد میشود و این روش، حال و هوای پایتونی بیشتری دارد و بیشتر در مسیری قرار دارد که پایتون ساخته شده است. بنابراین، «اشکالزدایی» (Debug | دیباگ) کردن آن نیز آسانتر و خواندن کد نیز کوتاهتر میشود؛ همین یک مورد به تنهایی میتواند ویژگی و تحول بسیار مهمی برای TF 2.0 به شمار بیاید. «پایتورچ» (PyTorch) در حال حاضر این کار را انجام میدهد؛ در حقیقت، Chainer این کار را حدود سه سال پیش انجام میداد، اما حالا این یک مفهوم محلی در تنسورفلو است که درک کارها را سادهتر میکند. اجرایی دقیقا مشابه بالا، خروجی پایین را به همراه دارد که بسیار مفید است.

خروجی دقیقا چیزی است که کاربر نیاز دارد، بدون هرگونه خطایی. در حقیقت اگر کاربر تلاش کند که یک سشن را اجرا کند، با خطا مواجه میشود، چون دیگر سشنی وجود ندارد. بنابراین، مفهوم «اول ساخت گراف و سپس اجرای بخشی از گراف» با استفاده از ()tf.Session.run، در تنسورفلوی ۲.۰ منسوخ شده است.
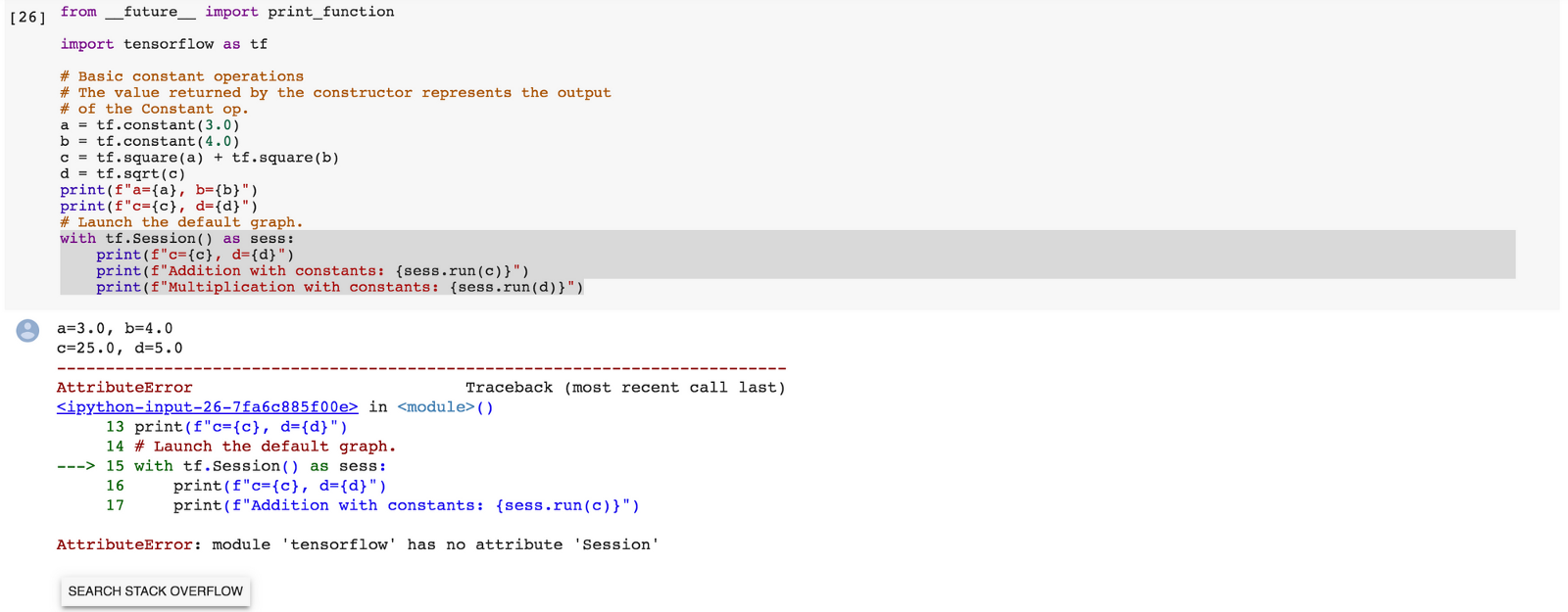
به بیان ساده، تنسورفلوی ۲ دارای توابع است و سشن ندارد. اکنون کاربر میتواند کد گراف را با استفاده از «نحو» (Syntax) طبیعی پایتون بنویسد، در حالیکه قادر به نوشتن کدی با استایل مشتاقانه (Eager Style) به شیوهای مختصر و اجرای آن به عنوان یک گراف تنسورفلو با استفاده از tf.function است.
اشکالزدایی آسانتر
بدون شک، «اشکالزدایی» (Debugging) در تنسورفلو تاکنون خیلی سخت بوده است. ساعتهای زمان زیادی زمان میبرد تا شرایطی مانند آنچه در تصویر زیر آمده، اشکالزدایی شود.

Z به عنوان nan ارزیابی میشود و نمیتوان دید که مساله مربوط به Y بوده است. حتی اگر y پرینت شود، باز هم نمیتوان فهمید که مشکل اینجا است، زیرا Y تاکنون محاسبه نشده؛ در واقع، منتظر ساخت گراف است. بنابراین، این یک ویژگی مهم دیگر به حساب میآید که به تنسورفلوی ۲.۰ اضافه شده است.
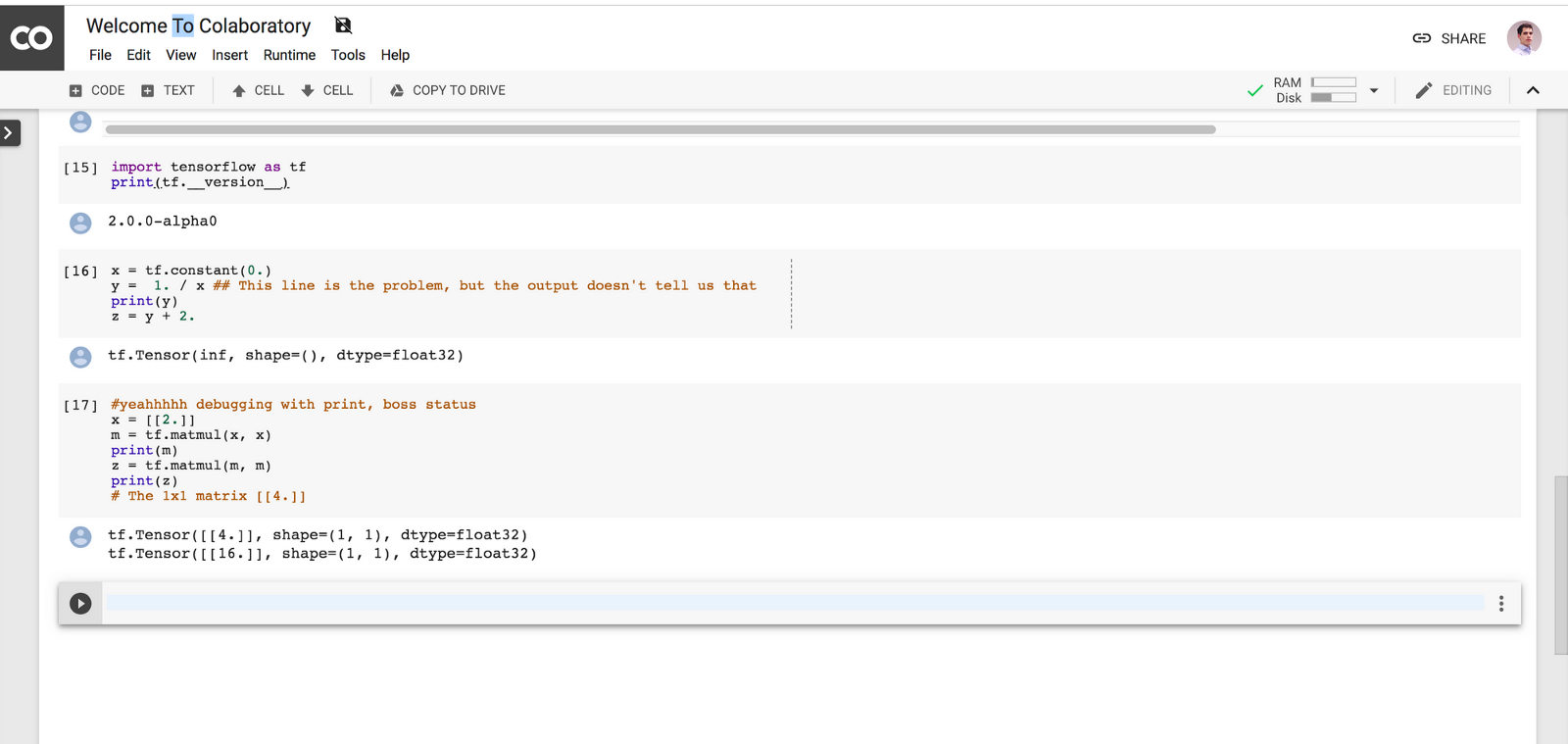
در اینجا میتوان به سرعت Y را چاپ کرد و تشخیص داد مشکل از کجا بوده است؛ این امر فرایند اشکالزدایی را آسانتر میسازد (نیازی به صبر کردن برای اجرای tf.session و سپس، ارزیابی Y نیست).
Verbose کمتر
Verbose مفهومی عمومی در برنامهنویسی است که به تولید حجم زیادی از لوگهای خروجی اشاره دارد. در واقع، می توان از برنامه درخواست کرد که «همه چیز را درباره کاری که در کل مدت زمان انجام میدهد بگوید». TF 1.0 دارای مفاهیم زیادی مانند متغیرها، پلیسهولدرها، servables، «تنسوربورد» (tensorboard)، سشن، گراف محاسباتی، مقادیر هایپرپارامترها (Hyperparameter) و قواعد قالببندی است که کاربر باید باید کلیه آنها را حتی پیش از آغاز صحبت پیرامون نظریه «یادگیری عمیق» (Deep Learning) بیاموزد (منحنی یادگیری بالا). در ادامه، میتوان مثالی از verbosity را مشاهده کرد (مثالی از یک «شبکه مولد تخاصمی پیچشی عمیق» (Deep Convolutional Generative Adversarial Network)).
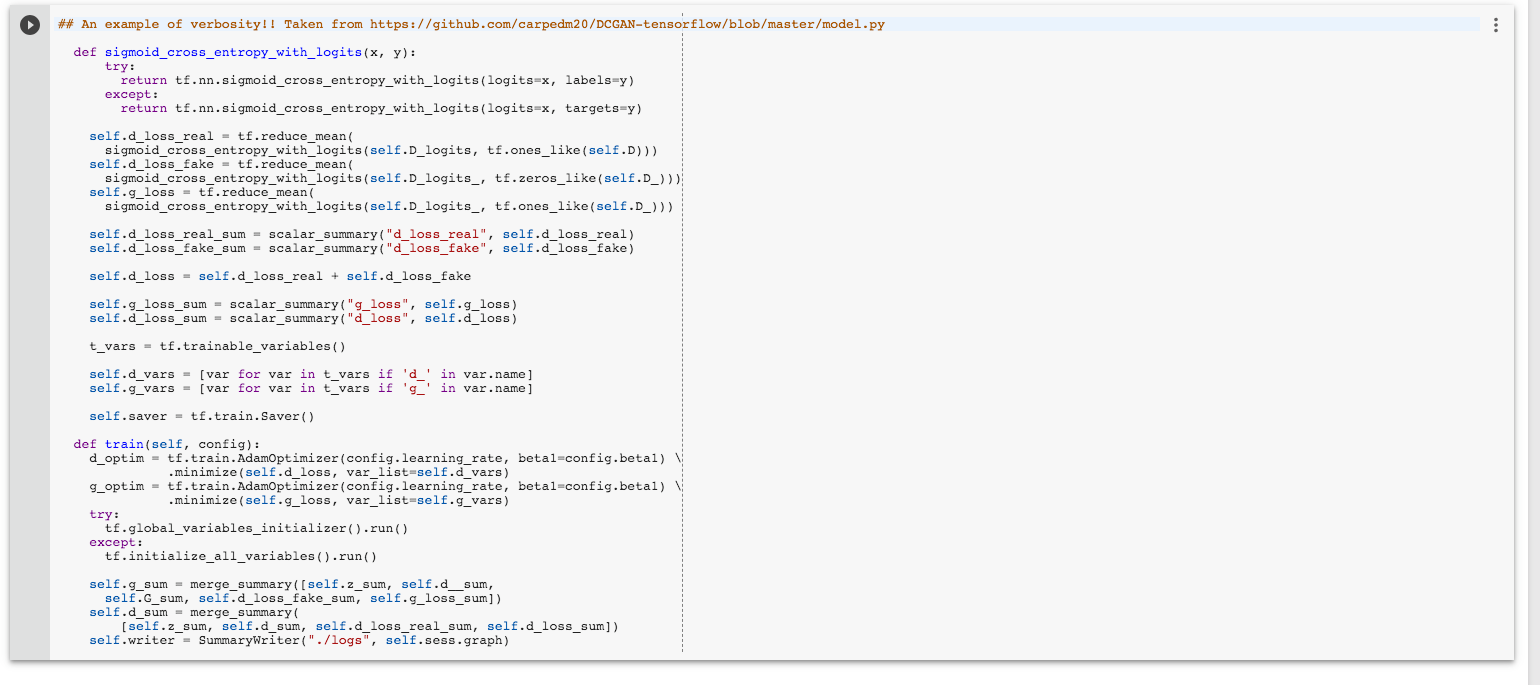
در کد بالا، اتفاقات زیادی میافتد که دنبال کردن آن میتواند برای افراد تازهکار دشوار باشد؛ زیرا قواعد نامگذاری بسیار متنوعی ویژه تنسورفلو وجود دارد که باید پیش از استفاده، آنها را شناخت. هدف Tf 2.o سادهسازی این فرایند با پیادهسازی تغییرات زیر است.
- tf.keras اکنون API سطح بالای رسمی است.
- آموزش توزیع شده آسان است (یک خط کد برای انجام این کار کافی است).
- APIهای منسوخ شده، حذف شدهاند.
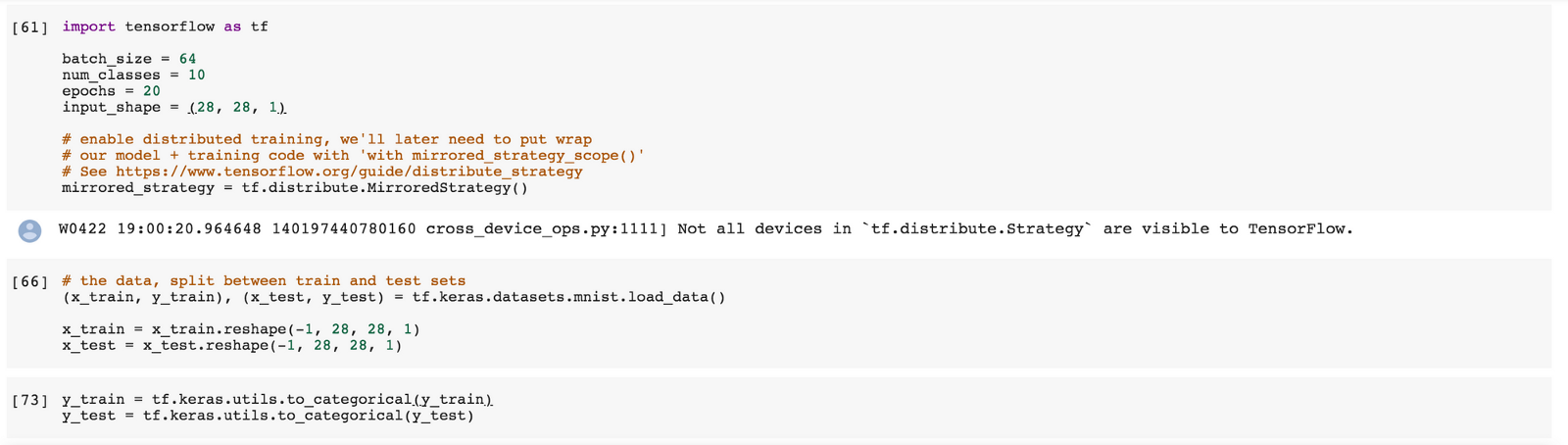

کد بالا، مثالی از آموزش یک مدل در Collab به حساب میآید که فوقالعاده عالی و کوتاه است و تنها چیزی است که باید در تنسورفلو «وارد» (Import) کرد. «کراس» (Keras) به طور جداگانه ایمپورت نشده است، زیرا اکنون به صورت توکار در TF 2.0 وجود دارد. بنابراین، با استفاده از TF 2.0 میتوان یک شبکه عصبی را تنها با چند خط کد با بهرهگیری از API متوالی کراس ساخت.
سازگاری عقبرو با TF 1.0
کد TF 1.0 به سادگی، با اجرای دستور زیر میتواند به 2.۰ تبدیل شود.
بنابراین، با اجرای دستور بالا، TF به طور خودکار کد کاربر را به سادگی به قالبی تبدیل میکند که توسط تنسورفلوی ۲.۰ قابل اجرا باشد.
Serving در تنسورفلو
TF 2.0 بهبودهای قابل توجهی روی TF serving ایجاد کرده است که یکی از قدرتمندترین ابزارها در کل فرایند یادگیری ماشین محسوب میشود. احتمالا نیاز به یک مطلب جامع و جداگانه برای پوشش دادن همه مباحث مربوط به TensorFlow Serving است. ولی، در ادامه برخی از مهمترین ویژگیها در این رابطه به طور خلاصه بیان شدهاند.
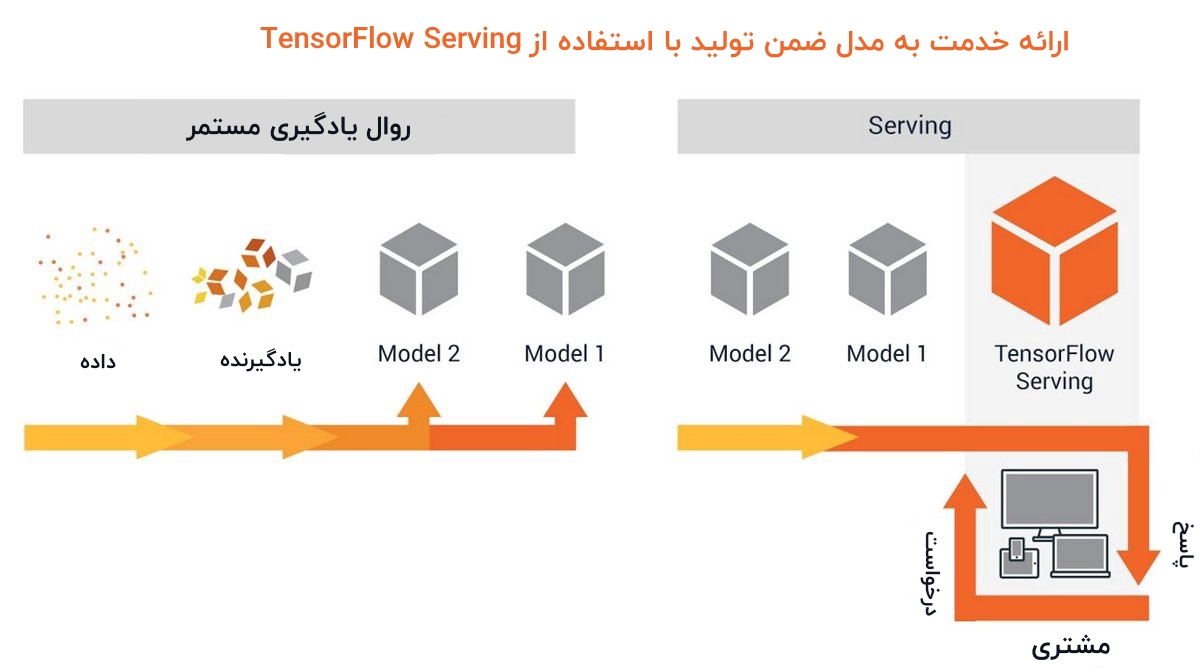
پرسشی که در این وهله مطرح میشود این است که TensorFlow Serving چیست؟ در پاسخ به این پرسش باید موارد زیر را بیان کرد.
- TensorFlow Serving یک سیستم انعطافپذیر و سطح بالا برای یادگیری ماشین است که برای محیطهای تولیدی طراحی شده است.
- TensorFlow Serving توسعه الگوریتمها و آزمایشهای جدید را با حفظ همان معماری سرور و API، آسانتر ساخته است.
- TensorFlow Serving یکپارچگی فوری را با مدلهای تنسورفلو فراهم میکند، اما به سادگی قابل توسعه یافتن برای خدمترسانی به دیگر انواع مدلها است.
به عنوان یک دانشمند داده، کاربر همواره مدلی را میخواهد که به طور پیوسته از مشاهدات جدید یاد بگیرد و یک مدل ایستا که فقط یک بار آموزش ببیند و سپس به کاربر خدمت بدهد، تقریبا در هیچ شرایطی مد نظر دانشمند داده نیست. TensorFlow serving این فرایند را ساده میسازد، چون در صورت وجود پیچیدگی، خیلی از موارد میتوانند اشتباه پیش بروند. TF 2.0 ایده سیستم کنترل نسخه برای مدل را معرفی میکند. در واقع، یک ورژن از مدل وجود دارد که «مدل یک» (model one) نامیده میشود و بر اساس مقادیری داده آموزش داده شده است و دانشمند داده آن را توسعه داده تا به کاربران از طریق یک برنامه کاربردی وب، خدماترسانی کند. بنابراین، کاربران درخواستها را به post requests انجام میدهند و پیشبینیها را دریافت میکنند.
با توجه به اینکه این اتفاق در پشت صحنه میافتد، نسخه دیگری از این مدل (که برای مثال آن را مدل دو (Model two) میتوان نامید) با دادههای جدید آموزش میبینید و وقتی این مدل به طور کامل روی دادههای جدید آموزش دید، مدل اصلی را به خوبی از رده خارج می کند (مدل یک) و مدل آموزش دیده جدید جایگزین آن میشود (مدل دو). هنگامی که این فرایند به پایان رسید، این مدل (مدل ۲) میتواند مدل دیگری را آموزش بدهد و به همین ترتیب این ماجرا تکرار میشود.
مهمترین مساله آن است که این کار در محیط تولید به وقوع میپیوندد، در حالیکه کاربر به طور طبیعی و مانند همیشه خدمات دریافت میکند. در حقیقت، دانشمند داده میتوان این کار را به چندین شکل انجام دهد؛ او میتواند چندین مدل داشته باشد و یا دادهها را از خروجیهای گوناگون برای ساخت یک مجموعه فنی ترکیب کند. به بیان ساده، TensorFlow serving این امکان را برای دانشمند داده فراهم میکند که مدلهایی را بسازد که به کاربران در محیط تولید خدماترسانی میکنند و این موضوع، موجب میشود که کارها سرعت بگیرند.
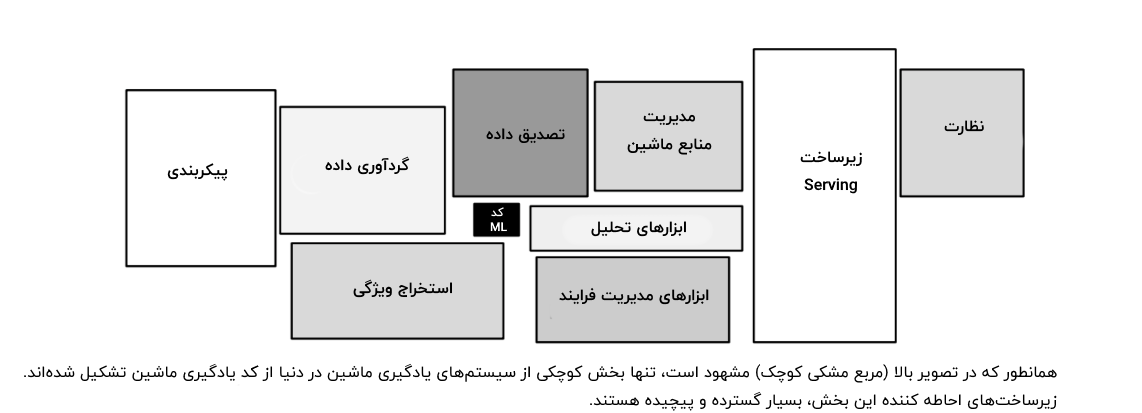
اگر به روال انجام پروژههای علم داده نگاه شود، می توان به سادگی فهمید که کد یادگیری ماشین بخش کوچکی از کل روال علم داده است. مولفههای دیگری همچون موارد زیر نیز وجود دارند؛
- پیکربندی
- نظارت
- گردآوری داده
و بسیاری از دیگر موارد.
خلاصه
در این مطلب، کتابخانه یادگیری ماشین «تنسورفلو» که توسط گوگل توسعه داده شده است مورد بررسی قرار گرفت. سپس، نسخه ۲.۰ از این کتابخانه که اخیرا منتشر شده و تغییرات قابل توجهی نسبت به نسخههای پیشین داشته است به صورت جامع بررسی شد و تغییراتی که در آن نسبت به نسخه ۱.۰ اتفاق افتادهاند، به طور کامل و همراه با ذکر مثالهایی بیان شدند. به طور کلی میتوان گفت که در TensorFlow 2.0، کارایی، شفافیت و انعطافپذیری به طور قابل توجهی افزایش یافته است. همچنین، قابلیت «اجرای مشتاقانه» (Eager Execution) به آن افزوده شده و APIهای سطح بالای آن بهبود یافتهاند که در نهایت منجر به ساده شدن پیادهسازی و اجرای سریع مدلهای یادگیری ماشین شده است.
منبع: فرادرس
الگوریتم بهینه سازی کلونی مورچگان در جاوا — راهنمای کاربردی
در این مقاله به توضیح مفهوم «بهینهسازی کلونی مورچگان» (ant colony optimization) یا به اختصار ACO میپردازیم و کدهای نمونه آن را نیز ارائه میکنیم.
طرز کار الگوریتم کلونی مورچگان چگونه است؟
ACO یک الگوریتم ژنتیک است که از رفتار طبیعی مورچهها الهام گرفته است. برای درک کامل الگوریتم ACO باید با مفاهیم مقدماتی آن آشنا باشیم.
- مورچهها از «فرمیون» (pheromone) برای یافتن کوتاهترین مسیر بین خانه و منبع غذایی استفاده میکنند.
- فرمیونها به سرعت تبخیر میشوند.
- مورچهها مسیرهای کوتاهتر با فرمیونهای چگالتر را ترجیح میدهند.
در ادامه مثال سادهای از الگوریتم کلونی مورچگان را که به صورت مسئله فروشنده دورهگرد مطرح شده، مورد بررسی قرار میدهیم. در مثال زیر باید کوتاهترین مسیر بین همه گرههای گراف را بیابیم.
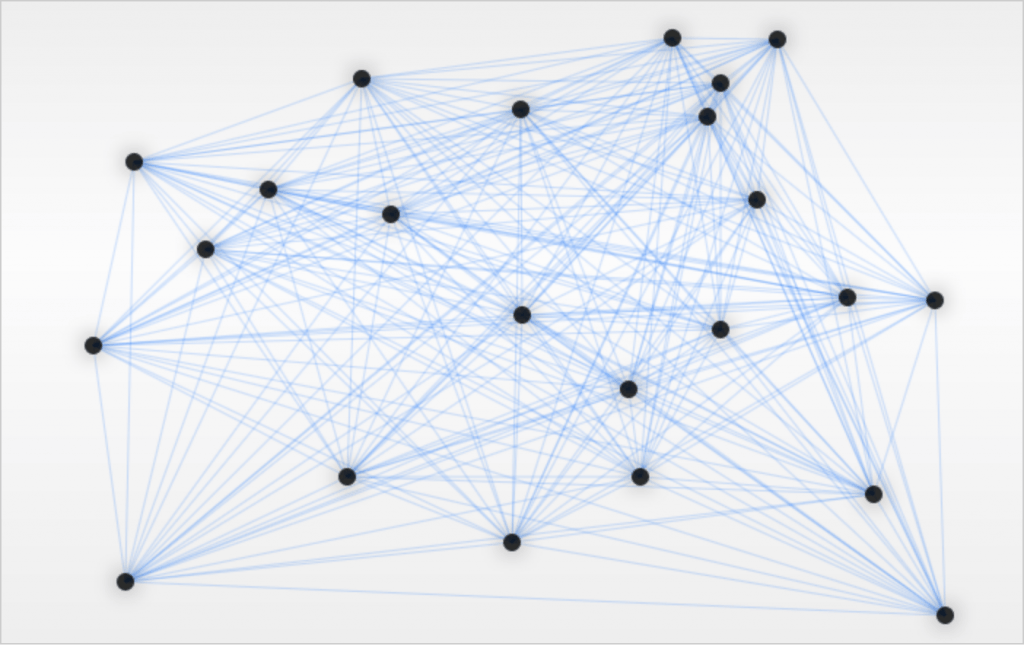
مورچهها با پیروی از رفتار طبیعیشان شروع به جستجوی مسیرهای جدید در مرحله کاوش میکنند. مسیرهای آبی پررنگ نشاندهنده مواردی هستند که نسبت به بقیه بیشتر استفاده شدهاند؛ در حالی که مسیرهای سبزرنگ نماینده کوتاهترین مسیر کنونی پیدا شده است:
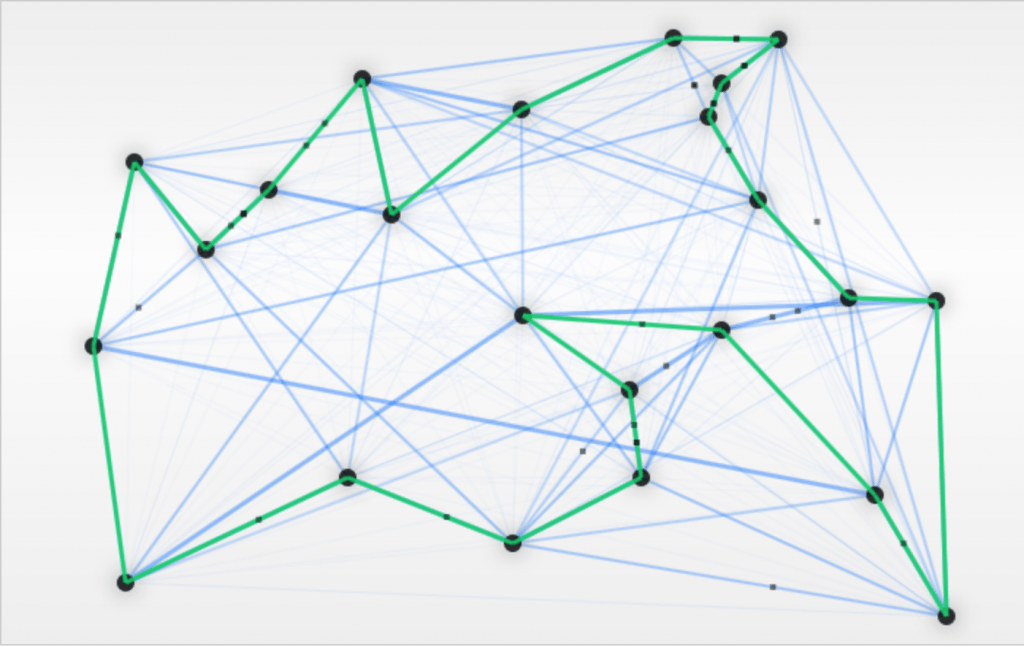
در نتیجه به کوتاهترین مسیر بین همه گرهها دست پیدا کردهایم:

برای مشاهده یک ابزار زیبای مبتنی بر GUI برای آزمودن ACO میتوانید به این آدرس (+) مراجعه کنید.
پیادهسازی جاوا
در این بخش به بررسی روش موردنیاز برای پیادهسازی بهینهسازی کلونی مورچگان در زبان برنامهنویسی جاوا میپردازیم.
پارامترهای ACO
ابتدا پارامترهای الگوریتم ACO را که در کلاس AntColonyOptimization اعلان شدهاند، بررسی میکنیم:
پارامتر c نشاندهنده عدد اولیه «مسیرها» (trails) در ابتدای شبیهسازی است. به علاوه، alpha به کنترل اهمیت فرمیون میپردازد؛ در حالی که beta اولویت مسافت را کنترل میکند. به طور کلی در بهترین نتایج پارامتر بتا باید بزرگتر از آلفا باشد.
سپس متغیر «تبخیر» (evaporation) نشان میدهد که چه درصدی از فرمیون در هر تکرار تبخیر میشود؛ در حالی که Q اطلاعاتی در مورد مقدار کلی فرمیون باقیمانده روی مسیر از سوی هر مورچه و antFactor نیز تعداد مورچههای هر شهر را نشان میدهد. در نهایت باید مقداری تصادفی بودن به شبیهسازیهای خود اضافه کنیم که این وظیفه نیز به پارامتر ranfomFactor محول شده است.
ایجاد مورچهها
هر مورچه امکان بازدید از یک شهر خاص را دارد، همه شهرهای بازدید شده را به خاطر میسپارد و رد طول مسیر را نگه میدارد:
تنظیم مورچهها
در ابتدای کار، باید پیادهسازی کد ACO خود را از طریق ارائه ماتریسهای مسیرها و مورچهها، مقداردهی اولیه بکنیم:
سپس باید ماتریس مورچگان را با یک شهر تصادفی مقداردهی بکنیم:
در هر تکرار این حلقه، عملیات زیر اجرا میشوند:
جابجایی مورچهها
کار خود را با متد ()moveAnts آغاز میکنیم. به این منظور باید شهر بعدی را برای همه مورچهها تنظیم کنیم و مسیر هر مورچه را برای پیمودن از سوی مورچههای دیگر به خاطر بسپاریم:
مهمترین بخش، انتخاب مناسب شهر بعدی برای بازدید است. ما باید شهر بعدی را بر مبنای منطق احتمال انتخاب کنیم. ابتدا بررسی میکنیم که آیا مورچه باید از یک شهر تصادفی بازدید کند یا نه:
اگر هیچ شهر تصادفی را انتخاب نکرده باشیم، باید احتمالهای انتخاب شهر بعدی را نیز محاسبه کنیم و به خاطر داشته باشیم که مورچه ترجیح میدهد، مسیر قویتر و کوتاهتر را بپیماید. این کار از طریق مرتبسازی احتمال رسیدن به هر شهر در آرایه ممکن است:
پس از آن که احتمالها را محاسبه کردیم، میتوانیم با کد زیر در مورد این که به کدام شهر باید برویم تصمیمگیری کنیم:
بهروزرسانی مسیرها
در این مرحله، باید مسیرها و میزان فرمیون باقیمانده را بهروزرسانی کنیم:
بهروزرسانی بهترین انتخاب
این آخرین مرحله برای هر تکرار است. ما باید بهترین انتخاب را بهروزرسانی کنیم تا ارجاع آن را حفظ کنیم:
پس از اجرای همه تکرارها، نتیجه نهایی بهترین مسیر مشخص شده از سوی ACO را نشان خواهد داد. توجه داشته باشید که با افزایش تعداد شهرها، احتمال یافتن کوتاهترین مسیر کاهش مییابد.
نتیجهگیری
در این راهنما به معرفی الگوریتم بهینهسازی کلونی مورچگان پرداختیم. شما میتوانید با مطالعه این مقاله بدون هیچ دانش قبلی و صرفاً به کمک مهارتهای ابتدایی برنامهنویسی رایانه، با الگوریتمهای ژنتیک آشنا شوید.
کد کامل این راهنما را میتوانید در این ریپوی گیتهاب (+) ملاحظه کنید.
منبع: فرادرس