طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیگراف قویا همبند و برنامه تشخیص آن — راهنمای کاربردی
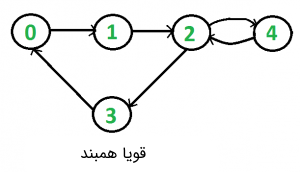
در این مطلب، روش نوشتن برنامهای که تشخیص میدهد یک گراف قویا همبند است یا خیر، مورد بررسی قرار گرفته است. همچنین، پیادهسازی آن در زبانهای برنامهنویسی گوناگون شامل ++C، «جاوا» (Java) و «پایتون» (Python) انجام شده است. فرض میشود یک گراف جهتدار به عنوان ورودی به برنامه داده شده است. هدف آن است که برنامه بررسی و مشخص کند که آیا گراف قویا همبند است یا خیر. یک گراف جهتدار، قویا همبند است اگر مسیری بین هر دو جفت از راسهای آن وجود داشته باشد. برای مثال، گرافی که در تصویر زیر آمده، قویا همبند محسوب میشود.
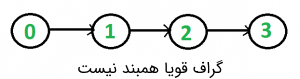
انجام چنین کاری در گراف غیرجهتدار آسان است. در این راستا، کافی است که پیمایش «جستجوی اول سطح» (Breadth-First Search | BFS) و «جستجوی اول عمق» (Depth-First Search | DFS) با آغاز از هر راسی انجام شود. اگر در پیمایش BFS یا DFS، همه راسها مشاهده شدند، گراف غیر جهتدار همبند است. این رویکرد برای گرافهای جهتدار پاسخگو نیست. برای مثال، گراف زیر قویا همبند نیست. اگر پیمایش DFS یا BFS با شروع از راس صفر انجام شود، میتوان به همه راسها رسید، اما اگر از هر راس دیگری آغاز شود، نمیتوان به همه راسها رسید.
یک ایده ساده آن است که از همه الگوریتمهای کوتاهترین مسیرها مانند پیدا کردن «بستار تعدی» (Transitive Closure) گراف یا «الگوریتم فلوید-وارشال» (Floyd Warshall) استفاده شود. پیچیدگی زمانی این روش، از درجه (O(v3 است. همچنین، میتوان DFS را به تعداد V مرتبه با آغاز از هر راسی انجام داد. اگر DFS همه راسها را ملاقات نکرد، گراف قویا همبند نیست. این الگوریتم، ((O(V*(V+E زمان میبرد که مشابه با بستار تعدی برای گراف چگال است.
یک ایده بهتر، استفاده از الگوریتم «اجزای قویاً همبند» (Strongly Connected Components | SCC) است. میتوان همه SCCها را در زمان (O(V+E پیدا کرد. اگر تعداد SCCها برابر با یک باشد، گراف قویا همبند است. الگوریتم SCC پس از پیدا کردن همه SCCها، دیگر کاری انجام نمیدهد. در ادامه، الگوریتم ساده و مبتنی بر DFS «کساراجو» (Kosaraju) ارائه شده است که دو پیمایش در گراف انجام و تشخیص میدهد که گراف قویا همبند است یا خیر. روش کار این الگوریتم، در ادامه بیان شده است.
- همه راسها را با «ملاقات نشده» مقداردهی اولیه کن.
- پیمایش DFS گراف را با شروع از هر راس دلخواه v آغاز کن. اگر در پیمایش DFS همه راسها ملاقات نشدند، false را بازگردان.
- همه یالها را معکوس کن (یا ترانهاده یا معکوس گراف را پیدا کن)
- همه راسها را در گراف معکوس شده با عنوان «ملاقات نشده» علامتگذاری کن.
- پیمایش DFS گراف معکوس را از همان راس v (که در گام ۲ از آن استفاده شد) آغاز کن. اگر پیمایش DFS همه راسها را ملاقات نکرد، مقدار false را بازگردان. در غیر این صورت، مقدار true را بازگردان.
ایده آن است که اگر همه گرهها از راس v دسترسیپذیر باشند، و هر گرهای بتواند به v برسد، گراف قویا همبند است. در گام ۲، بررسی میشود که همه راسها از راس v دسترسیپذیر هستند. در گام ۴، بررسی میشود که آیا میتوان از همه راسها به راس v رسید (در گراف معکوس، اگر همه راسها از راس v دسترسیپذیر باشند، همه راسها میتوانند در گراف اصلی به راس v برسند). پیادهسازی الگوریتم بالا، در ادامه در زبانهای برنامهنویسی گوناگون ارائه شده است.
برنامه تشخیص گراف قویا همبند در ++C
برنامه تشخیص گراف قویا همبند در جاوا
برنامه تشخیص گراف قویا همبند در پایتون
خروجی قطعه کد بالا، به صورت زیر است.
Yes No
پیچیدگی زمانی روش ارائه شده در بالا، برابر با «جستجوی اول عمق» است و اگر گراف با استفاده از ماتریس مجاورت ارائه شده باشد، از درجه (O(V+E خواهد بود. این رویکرد نیازمند دو بار پیمایش گراف است. میتوان با استفاده از «الگوریتم تارژان مؤلفههای قویا همبند» (Tarjan’s Strongly Connected Components Algorithm)، با یک بار پیمایش گراف این کار را انجام داد.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
منبع: فرادرس
تابع بازگشتی در ++C — راهنمای جامع
در این نوشته با روش ایجاد یک تابع بازگشتی در ++C آشنا میشویم. تابع بازگشتی تابعی است که خودش را فرامیخواند. چنین فرایندی به طور کلی «بازگشت» (recursion) نامیده میشود. برای مطالعه بخش قبلی این سری مقالات به لینک زیر رجوع کنید:
طرز کار بازگشت در ++C چگونه است؟
شکل زیر طرز کار بازگشت را از طریق فراخوانی خودش به صورت مکرر نمایش میدهد.

فرایند بازگشت تا زمانی که نوعی شرط برقرار شود تداوم مییابد.
برای جلوگیری از بازگشت نامتناهی از گزارههای if…else یا رویکردی مشابه استفاده میشود که در آن یک شاخه از گزاره مربوطه موجب بازگشت و شاخه دیگر باعث توقف فرایند بازگشتی میشود.
مثال 1
محاسبه فاکتوریل عدد با استفاده از بازگشت
خروجی
Enter a number to find factorial: 4 Factorial of 4 = 24
در شکل زیر طرز کار مثال فوق را توضیح دادهایم:
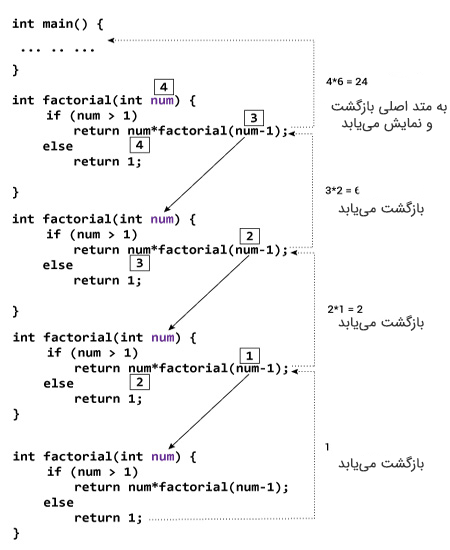
فرض کنید که عدد 4 از سوی کاربر برنامه وارد شده است. این مقدار به تابع ()factorial ارسال میشود.
- در نخستین تابع ()factorial، عبارت تست درون گزاره if صحیح است. گزاره ;(return num*factorial(num-1 اجرا میشود که تابع ()factorial دوم را فرامیخواند و آرگومان ارسالی num-1 است که مقدار 3 را دارد.
- در تابع ()factorial دوم، عبارت تست درون گزاره if صحیح است. گزاره ;(return num*factorial(num-1 اجرا میشود که تابع ()factorial سوم را فرامیخواند و آرگومان ارسالی num-1 است که مقدار 2 دارد.
- در تابع ()factorial سوم، عبارت تست درون گزاره if همچنان صحیح است. بنابراین گزاره ;(return num*factorial(num-1 اجرا میشود که تابع ()factorial چهارم را فرا میخواند و آرگومان ارسالی num-1 و مقدار آن 1 است.
- در تابع ()factorial چهارم، عبارت تست درون گزاره if ناصحیح است. از این رو گزاره ;return 1 اجرا میشود که مقدار 1 را به تابع ()factorial سوم بازمیگرداند.
- تابع ()factorial سوم مقدار 2 را به تابع ()factorial دوم بازگشت میدهد.
- تابع ()factorial دوم مقدار 6 را به تابع ()factorial اول بازگشت میدهد.
- منبع: فرادرس
جستجوی الگو (Pattern Searching) — به زبان ساده
در این مطلب، جستجوی الگو (Pattern Searching) مورد بررسی قرار میگیرد و یک الگوریتم ساده برای این کار ارائه میشود. متن [txt[0..n-1 و الگوی [pat[0..m-1 موجود است؛ هدف نوشتن تابع جستجویی ([]char pat[], char txt) است که همه وقوعهای []pat در []txt را چاپ کند. میتوان فرض کرد که n > m است. مثالهای زیر در این راستا قابل توجه هستند.
Input: txt[] = "THIS IS A TEST TEXT"
pat[] = "TEST"
Output: Pattern found at index 10
Input: txt[] = "AABAACAADAABAABA"
pat[] = "AABA"
Output: Pattern found at index 0
Pattern found at index 9
Pattern found at index 12
جستجوی الگو، یک مسأله مهم در علوم کامپیوتر است. هنگامی که یک رشته در فایل «نوتپد» (Notepad)، «ورد» (Word)، مرورگر و یا «پایگاهداده» (Database) جستجو میشود از جستجوی الگو برای نمایش نتایج جستجو استفاده میشود.
الگوریتم ساده برای جستجوی الگو
الگو در متن به این صورت بررسی میشود که از آغاز متن به صورت اسلایدی (کشویی) با متن مطابقت داده میشود. اگر الگویی مطابق با الگوی جستجو شده در متن پیدا شد، فعالیت مجددا ادامه پیدا میکند تا سایر الگوها نیز یافت شوند.
الگوریتم ساده جستجوی الگو در ++C
الگوریتم ساده جستجوی الگو در C
الگوریتم ساده جستجوی الگو در جاوا
الگوریتم ساده جستجوی الگو در #C
الگوریتم ساده جستجوی الگو در PHP
الگوریتم ساده جستجوی الگو در پایتون ۳
خروجی و پیچیدگی زمانی
خروجی قطعه کدهای بالا، به صورت زیر است.
Pattern found at index 0 Pattern found at index 9 Pattern found at index 13
بهترین حالت
بهترین حالت هنگامی به وقوع میپیوندد که اولین کاراکتر از الگو هرگز در متن ظاهر نشود.
txt[] = “AABCCAADDEE”;
pat[] = “FAA”;
تعداد مقایسه ها در بهترین حالت (O(n است.
بدترین حالت
بدترین حالت الگوریتم جستجوی الگوی ساده در شرایط زیر به وقوع میپیوندد.
۱. هنگامی که همه کاراکترهای متن و الگو مشابه باشد:
txt[] = "AAAAAAAAAAAAAAAAAA"; pat[] = "AAAAA";
۲. همچنین، بدترین حالت هنگامی به وقوع میپیوندد که آخرین کاراکتر متفاوت باشد.
txt[] = "AAAAAAAAAAAAAAAAAB"; pat[] = "AAAAB";
تعداد مقایسهها در بدترین حالت برابر با ((O(m*(n-m+1 است. با وجود اینکه برخی از رشتهها دارای کاراکترهایی هستند که در زبان انگلیسی ظاهر نمیشود، اما این رشتهها ممکن است در دیگر کاربردها به وقوع بپیوندند (برای مثال، در متنهای دودویی). الگوریتم تطبیق KMP، بدترین حالت را به (O(n بهبود میبخشد.
منبع: فرادرس
همگام سازی تنظیمات بین نسخه های مختلف ویژوال استودیو کد — به زبان ساده
اگر یک توسعهدهنده غیر مبتدی هستید و سیستم یا لپتاپی را که استفاده میکنید، چند سال قبل خریداری کردهاید، مسلماً تاکنون ابزارها و نرمافزارهای زیادی را روی آن نصب کردهاید. احتمال دارد از نرمافزار VS Code به عنوان ادیتور کد خود استفاده می کنید و برخی افزونهها را روی آن نصب دارید. ممکن است بتوانید برخی از مواردی که روی آن نصب کردهاید را به خاطر آورید؛ اما بدیهی است که یادآوری بسیاری از آنها ناممکن است. ما این ابزارها را یک بار نصب میکنیم و دیگر کلاً فراموششان میکنیم.
اما این وضعیت خطرناکی است، چون هر چه قدر هم که مراقب باشید، ممکن است اتفاقی برای لپتاپ شما بیافتد، مثلاً فنجان قهوه روی آن بریزد، روی زمین سقوط کند و یا سیستم عامل آن از کار بیفتد.
در چنین حالتی، پس از این که مشکل را رفع کردید یا مجبور شدید یک سیستم جدید بخرید، با یک لپتاپ جدید مواجه خواهید بود که همه تنظیمات شخصی، افزونهها، برنامههای نصبشده مختلف و ابزارهای پیکربندیشده که موجب سهولت کار توسعه میشدند، از دست رفتهاند. این وضعیت به طور خاص در مورد IDE صدق میکند، چون همه تنظیمات و پیکربندیها به یک چشم بر هم زدن از دست میروند.
دقیقاً در این لحظه است که متوجه میشوید برای همه این تنظیمات و پیکربندیها چه مقدار زمان و زحمت صرف شده است. حتی تصور چنین وضعیتی نیز دردناک است. ما در این مقاله قصد نداریم در مورد روشهای بازیابی وضعیت سیستم به حالت اولیه صحبت بکنیم، بلکه میخواهیم نشان دهیم که چگونه میتوانید تنظیمات IDE ویژوال استودیو کد را بدون شروع همه چیز از صفر و صرف ساعتها از وقت خود مجدداً بسازید.
همگامسازی تنظیمات برای مواقع ضروری
اگر تاکنون با VS Code کار نکردهاید و یا کلاً نام آن را نشنیدهاید، پیشنهاد میکنیم ابتدا مطلب معرفی جامع ویژوال استودیو کد را مطالعه کنید. ویژوال استودیو کد، یک IDE جالب و رایگان است و تقریباً از هر لحاظ WebStorm را که رایگان نیست مغلوب میکند.
یکی از جالبترین نکتهها در مورد VS Code بازار اکستنشن (+) آن است که پر از افزونههای مفید است که افراد مختلف برای خودشان نوشتهاند و حس کردهاند که ممکن است برای توسعهدهندگان دیگر نیز مفید باشند و بیشتر آنها نیز رایگان هستند.
این اکستنشنها برخی از ویژگیهایی هستند که موجب میشوند کار توسعه در VS Code چنین دلپذیر باشد و همچنین موجب میشوند که توسعهدهندگان هر کدام نسخه خاصی از این ویرایشگر را داشته باشند. هرکس میتواند theme خاص خود، فهرست افزونههای ضروری و نوار کناری با ابزارهای مفید را در اختیار داشته باشد. همچنین قابلیت مهم LiveShare و فهرست فرایندهای از امکاناتی که تیم توسعه VS Code هر ماه اضافه میکند در این IDE قابل حصول هستند.
زمانی که با احتمال از دست دادن تنظیمات VS Code مواجه میشوید، احتمالاً به دنبال روشی برای انتقال این تنظیمات به سیستم دیگر میگردید. پیش از ما نیز توسعهدهندگان دیگری در نقاط مختلف دنیا با چنین موقعیتهایی مواجه شدهاند و راهی برای همگامسازی تنظیمات VS Code روی سیستمهای مختلف ابداع کردهاند. این کار از طریق اکستنشن Settings Sync (+) میسر است.
Settings Sync

با استفاده از این اکستنشن میتوانید تنظیمات ویژوال استودیو کد را با استفاده از GIST گیتهاب روی چند سیستم همگامسازی کنید.
این افزونه به صورت رایگان در بازار VS CODE ارائه شده است و دقیقاً همان کاری را که در تعریف فوق دیدید، ارائه میکند. با استفاده از این ابزار میتوانید تنظیمات VS Code را روی هر تعداد سیستم مختلف که دوست دارید همگامسازی کنید. همه اینها به لطف بخش GIST در گیتهاب میسر شده است.
این افزونه موارد زیر را همگامسازی میکند:
- فایل Settings
- فایل Keybinding
- فایل Launch
- پوشه Snippets
- افزونههای VS Code و پیکربندی افزونهها
- پوشه Workspaces
همه چیز از نظر تئوری خوب به نظر میرسد، اما آیا در عمل نیز واقعاً به همین سادگی است؟ واقعیت این است که کار به همین سادگی است، چون مستندات بسیار خوبی برای افزونه همگامسازی تنظیمات وجود دارد.
شما میتوانید در طی مدت کوتاهی و با کمی سعی و خطا این افزونه را فعال کنید و در ادامه این موارد و همچنین مشکلاتی که ممکن است با آنها مواجه شوید را توضیح خواهیم داد.
افزونه Settings Sync در عمل
همان طور که قبلاً گفتیم، راهنماییهای ارائه شده از سوی خالق افزونه Settings Sync کاملاً مناسب است؛ اما در این نوشته قصد داریم در طی یک راهنمای گام به گام چند نکته را نیز روشن سازیم که دانستن آنها باعث سهولت هر چه بیشتر کار برای شما خواهد شد.
گام 1: نصب افزونه Settings Sync در VS Code

بدیهی است که گام نخست، نصب افزونه Settings Sync در ترمینال VS Code و از مارکت اکستنشنها است. آیکون این افزونه به صورتی که در تصویر فوق میبینید، در نتایج جستجو ظاهر میشود.
گام 2: ایجاد توکن دسترسی شخصی از گیتهاب
روش کار Settings Sync از طریق گیتهاب است و یک gist شخصی میسازد که اطلاعات VS Code را روی آن ذخیره میکند و سپس این تنظیمات در دسترس هر کسی که کلیدهای دسترسی به gist را داشته باشد، خواهد بود.
بدین ترتیب در گیتهاب به مسیر زیر مراجعه کنید:
Settings / Developer settings / Personal access tokens / Generate New Token**
همان طور که ملاحظه میکنید، ما قبلاً یک توکن vscode-settings-sync به دست آوردهایم؛ اما با توجه به مقاصد این مقاله روی دکمه Generate new token کلیک میکنیم تا گامهای مختلف را همراه با شما بپیماییم.
زمانی که به صفحه تولید توکن رسیدید، نام توکن را چیزی انتخاب کنید که به راحتی در یاد بماند و سپس روی کادر کنار Create gists کلیک کنید. این تنها کاری است که برای تولید توکن لازم است.
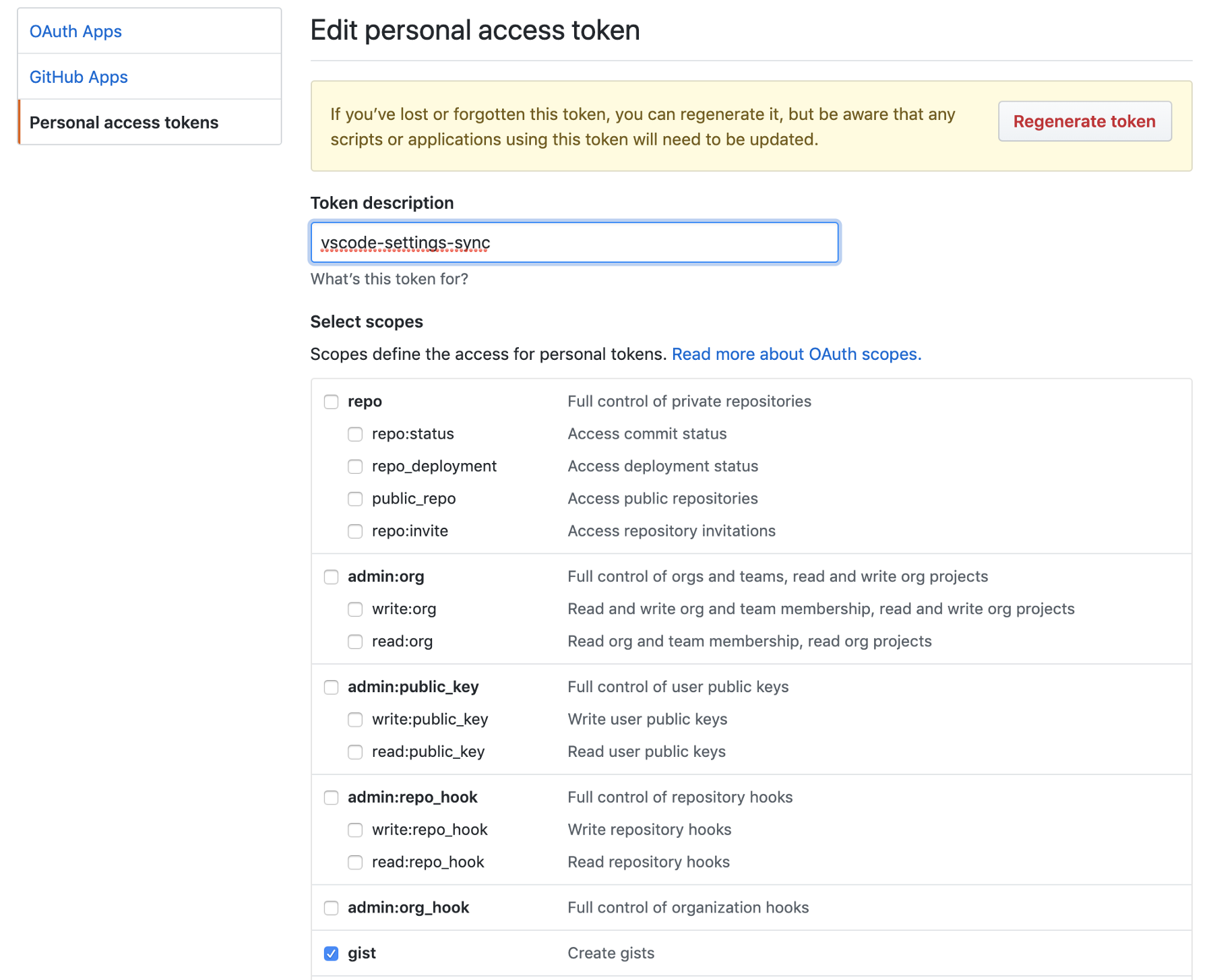
پس از این که توکن جدید ایجاد شد، هش توکن را روی کلیپ بورد کپی کنید (میتوانید آن را در جایی ذخیره کنید)، چون در ادامه هرگز امکان دسترسی به آن نخواهید داشت.
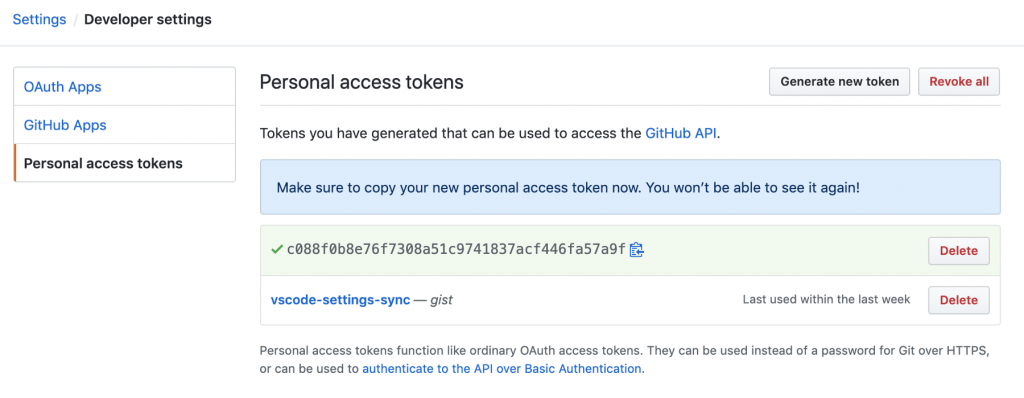
زمانی که این کار را انجام دادید، آماده بازگشتن به VS Code هستید.
گام 3: آپلود تنظیمات VS Code
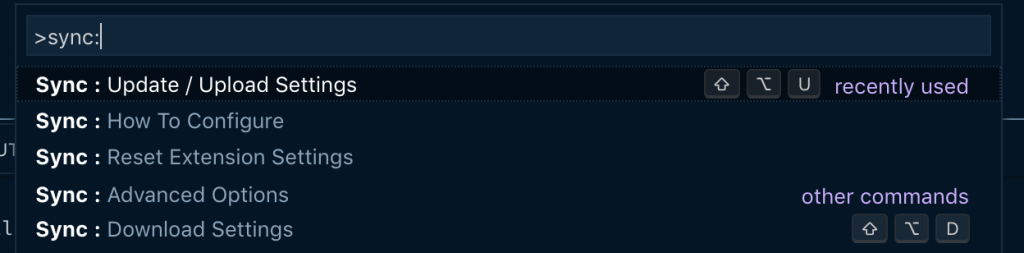
هنگامی که به VS Code بازگشتید، پالت فرمان را با دستور Ctrl + Shift+ P (ویندوز) یا command + shift + p (مک) باز کنید و عبارت :sync را وارد کنید تا فهرستی از گزینهها را مشاهده کنید. روی گزینه اول یعنی Sync: Update/Upload Settings کلیک کنید تا درخواست افزودن توکن گیتهاب را مشاهده کنید. در این مرحله میتوانید توکنی را که اخیراً ایجاد و کپی کردید وارد نمایید.

اکنون که توکن خود را وارد کردهاید، همه تنظیمات جاری شما روی gist آپلود میشود و ترمینال OUTPUT در VS Code پیامی مانند تصویر زیر نشان میدهد:
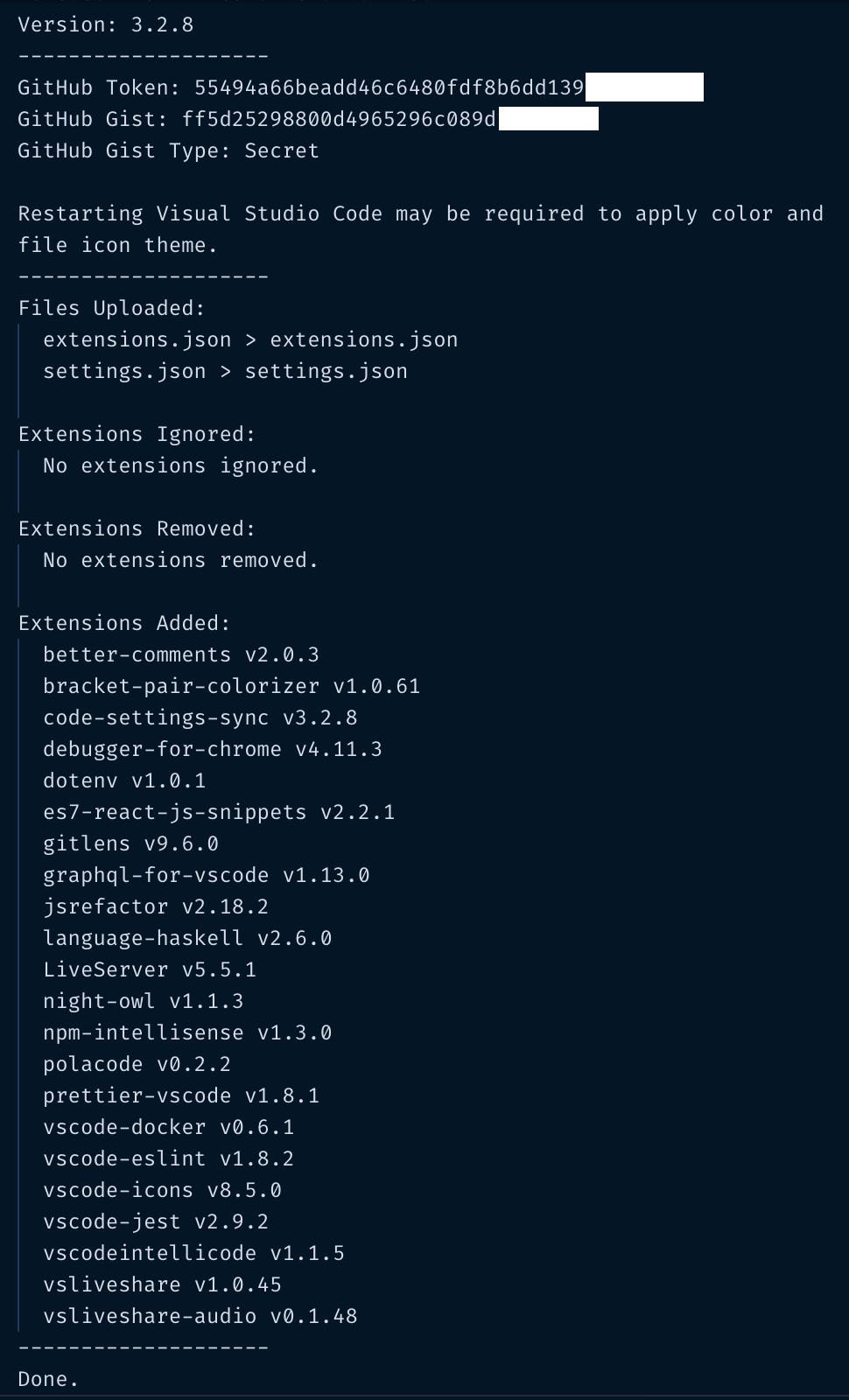
میتوانید ببیند که فایلهای settings و extensions همراه با اکستنشنهایی که هم اینک در تنظیمات VS Code ما استفاده میشوند، آپلود شدهاند. همچنین میتوانید به gist خود در گیتهاب بروید و وجود تنظیمات را در آنجا تأیید کنید. این تنظیمات در gist در فایلی با نام cloudSettings ذخیره شدهاند.
پیش از آن که ترمینال output را ببندید، توکن گیتهاب و ID مربوط به gist تولید شده در این آپلود را کپی کنید. شما در ادامه برای دانلود کردن تنظیمات روی سیستمهای دیگر به این موارد نیاز خواهید داشت. این موارد را جایی قرار دهید که بتوانید از روی سیستم جدید به آنها دسترسی داشته باشید و آنها را دانلود کنید. مثلاً میتوانید آنها را روی اسلک، Google Docs و یا موارد مشابه قرار دهید.

اینک آماده رفتن به IDE جدید VS Code خود هستیم و میتوانیم این تنظیمات را با کمترین زحمت آنجا اعمال کنیم.
گام 4: دانلود تنظیمات روی یک سیستم جدید
برای دانلود تنظیمات VS Code روی سیستم خود، نخستین گام شبیه به بخش قبلی و آپلود تنظیمات است. پالت دستورها را با کلیدهای میانبر Ctrl+Shift+P باز کنید و عبارت :sync را وارد کنید. اما این بار باید گزینه Sync: Download Settings را انتخاب کنید.

پس از این که این گزینه را انتخاب کردید، افزونه Sync Settings از شما میخواهد که توکن دسترسی شخصی گیتهاب خود را وارد کنید. این همان توکن است که از خروجی ترمینال در زمان آپلود تنظیمات VS Code کپی کردهاید.

سپس از شما خواسته میشود که Gist ID را وارد کنید. این مورد را نیز از خروجی ترمینال کپی کردهایم. دقت کنید که اگر در گام نخست این مقدار را کپی نکرده باشید، هیچ کار دیگری میسر نیست و باید کل فرایند را ریست کرده و از نو آغاز کنید که گرچه چندان دشوار نیست، ولی به هر حال دوبارهکاری محسوب میشود

پس از آن تنظیمات اصلی شما روی VS Code جدید بدون هیچ مشکلی دانلود میشود.
گام 5: ریاستارت کردن ادیتور
بدین ترتیب ما به پایان کار رسیدهایم. ممکن است لازم باشد که ادیتور VS Code را کاملاً ببندید و آن را دوباره باز کنید تا همه تغییرات اعمال شوند و این تنها کار موردنیاز است. بدین ترتیب میتوانید به سادگی IDE جدیداً نصب شده خود را به شکلی که دوست دارید دربیاورید.
توجه کنید که اگر میخواهید این تنظیمات و پیکربندیها را میان اعضای مختلف یک تیم و سیستمهای مختلف توزیع کنید، میتوانید یک Gist عمومی ایجاد کنید که همه افراد به آن دسترسی داشته باشند. به این منظور میتوانید از بخش Create Public Gist to Share Settings این راهنما (+) استفاده کنید.
سخن پایانی
هیچ چیزی برای یک توسعهدهنده لذتبخشتر از دیدن یک IDE کاملاً پیکربندیشده مانند VS Code نیست. هیچ چیزی هم به اندازه تلاش برای به خاطر آوردن همه تنظیمات، افزونهها، پیکربندیها و موارد دیگر که روی یک IDE اعمال کردهاید، دردآور نیست.
اینک به کمک افزونه Settings Sync لازم نیست که همه این چیزها را به خاطر بیاورید و یا ساعتها از وقت خود را صرف ایجاد مجدد آنها را یک سیستم جدید بکنید. میتوانید به سادگی آنها را روی کلود گیتهاب آپلود کرده و از روی هر سیستم جدید و از طریق توکن دسترسی شخصی و Gist ID به آنها دسترسی داشته باشید.
منبع: فرادرس
یادگیری ماشین با پایتون — به زبان ساده
با گسترش استفاده از «یادگیری ماشین» (Machine Learning) در صنایع گوناگون، نیاز به ابزاری که بتواند به فرد برای انجام فرایندهای مختلف کمک کند به امری حیاتی مبدل شده است. «زبان برنامهنویسی پایتون» (Python Programming Language)، یک ستاره درخشان در آسمان فناوری یادگیری ماشین است که اغلب، هم برای پروژههای تحقیقاتی و هم پروژههای عملیاتی، اولین انتخاب بسیاری از افراد محسوب میشود. بنابراین، فراگیری یادگیری ماشین با پایتون، بسیار ساده و البته لذتبخش است. در این مطلب، با یک بررسی موردی، به افرادی که به دنیای یادگیری ماشین علاقمند هستند نشان داده خواهد شد که چگونه میتوانند یک مساله را از صفر تا صد با پایتون حل کنند.
مقدمهای بر یادگیری ماشین با پایتون
دلیل محبوبیت و استفاده زیاد از پایتون برای مسائل یادگیری ماشین در چیست؟ پایتون یکی از سادهترین زبانهای برنامهنویسی برای فراگیری محسوب میشود. در پروژههای یادگیری ماشین، معمولا نیاز به سرعت بخشیدن به فرایند است و با توجه به اینکه کارشناس داده میتواند به سرعت از زبان پایتون برای پروژههای عملی استفاده کند، نیازی به تخصیص زمان زیاد برای یادگیری زبان برنامهنویسی ندارد. برای کسب درک بهتری پیرامون میزان سادگی پایتون، به مثال زیر توجه کنید.
«نحو» (Syntax) زبان برنامهنویسی پایتون، به زبان انگلیسی (و در واقع زبان انسانی، نه زبان ماشین) بسیار نزدیک است؛ از دیگر ویژگیهای این زبان میتوان به عدم نیاز به استفاده از کروشههایی که انسان را هنگام نوشتن برنامه گیج میکنند اشاره کرد. نقطه قوت دیگر پایتون، کتابخانههای متعددی است که برای انجام محاسبات، الگوریتمهای یادگیری ماشین و دیگر فعالیتهای لازم طی یک پروژه، دارد. کتابخانههایی که در ادامه بیان میشوند، از شاهکارهای پایتون هستند که به دانشمندان داده، کارشناسان یادگیری ماشین و دیگر افراد فعال در حوزه علم داده، برای تکمیل وظایف خودشان کمک میکنند. به طور کلی باید گفت که کتابخانههای متعدد و با توانمندیهای قابل توجهی برای پایتون وجود دارند که استفاده از آنها برای پروژههای یادگیری ماشین الزامی است.
۱. نامپای (NumPy)
«نامپای» (Numpy)، یک کتابخانه معروف برای انجام تحلیلهای عددی است. این کتابخانه به کاربر برای انجام کارهای متعدد از محاسبه میانه و توزیع دادهها گرفته تا پردازش آرایههای چندبُعدی کمک میکند.
۲. پانداس (Pandas)
برای پردازش یک فایل CSV، میتوان از کتابخانه «پانداس» (Pandas) استفاده کرد. البته، در این راستا کاربر نیاز به پردازش چندین جدول و مشاهده آمارهای مربوط به آنها دارد.
۳. متپلاتلیب (Matplotlib)
پس از آنکه کاربر دادهها را با بهرهگیری از کتابخانه Pandas به صورت «دیتافریم» (Data Frame) ذخیره کرد، برای درک دادههای موجود به برخی از روشهای بصریسازی نیاز خواهد داشت. تصاویر، معمولا بهتر و گویاتر از خود دادهها هستند (به ویژه برای ذینفعان نهایی که ممکن است دارای تخصصهای گوناگونی باشند و آمارهای عددی و تحلیلهای متنی نمیتوانند گزینههای خوبی برای ارائه خروجی به آنها باشند). «متپلاتلیت» (Matplotlib)، کتابخانهای قدرتمند برای بصریسازی دادهها است که میتوان با بهرهگیری از آن، نمودارهای گوناگون را ترسیم کرد.
۴. سیبورن (Seaborn)
این کتابخانه نیز ابزار دیگری است برای انجام بصریسازیها، با این تفاوت که تمرکز بیشتری روی بصریسازیهای آماری دارد. مواردی مانند «بافتنگار» (هیستوگرام | Histogram)، «نمودار دایرهای» (Pie Chart)، «منحنیها» (Curves) و یا «جداول همبستگی» (Correlation Tables) از جمله مواردی هستند که با بهرهگیری از این کتابخانه میتوان آنها را پیادهسازی کرد.
۵. سایکیتلِرن (Scikit-Learn)
کتابخانه «سایکیتلرن» (Scikit-Learn)، یکی از قدرتمندترین کتابخانههای یادگیری ماشین با پایتون است. این کتابخانه هر آنچه که برای پیادهسازی و بهبود الگوریتمهای یادگیری ماشین مورد نیاز است را فراهم میکند.
۶. تنسورفلو (Tensorflow) و پایتورچ (Pytorch)
تنسورفلو (Tensorflow) و پایتورچ (Pytorch)، کتابخانههای رایگان و متنبازی (Open Source) هستند که کاربردهای گوناگونی را در یادگیری ماشین دارند. از این کتابخانهها برای پیادهسازیهای مربوط به «شبکههای عصبی» (Neural Networks) و به ویژه «یادگیری عمیق» (Deep Learning) و همچنین محاسبات «تانسورها» (Tensors) استفاده میشود.
پروژههای یادگیری ماشین با پایتون
قطعا، مطالعه صرف نمیتواند به فرد کمک کند که در زمینه کاری خود توانمند شود. افراد در هر زمینهای که تمایل به کسب مهارت در آن داشته باشند، باید علاوه بر مطالعه و تحقیق، تمرین و پروژههای عملی داشته باشند و به کسب تجربه در آن حوزه بپردازند. در بحث یادگیری ماشین، مادامی که فرد در میان دادهها شیرجه نزند و با آنها کار نکند، نمیتواند بر این حوزه تسلط کافی پیدا کند و بنابراین، نمیتواند پروژهها یا فرصتهای شغلی خوبی به دست بیاورد.
«کگل» (Kaggle) پلتفرمی است که میتوان با استفاده از آن، مستقیما به سراغ دادهها رفت و با آنها کار کرد. در این سایت میتوان با پروژهها و مسائل گوناگون آشنا شد و به حل آنها پرداخت. چیز دیگری که شاید اغوا کنندهتر به نظر برسد این است که رقابتهایی که در کگل برگزار میشوند جوایز گوناگونی دارند و رقم جایزه برخی از آنها به ۱۰۰,۰۰۰ دلار نیز میرسد. اما، مهمترین مساله در این وهله (و در مرحله یادگیری) پول نیست، زیرا در صورتی که فرد به این حوزه مسلط باشد میتواند پروژههای متعددی با درآمدهای خوب و فرصتهای شغلی با شرایط عالی پیدا کند. آنچه یک فرد تازه وارد در حوزه کار با داده به آن نیاز دارد، یادگیری و کسب تجربه است، البته لذت مسابقه دادن و برنده شدن جایزه را نمیتوان انکار کرد. در ادامه، یک بررسی موردی انجام شده و طی آن یک مساله یادگیری ماشین با پایتون حل شده است.
تشخیص افراد نجات یافته از کشتی تایتانیک
در اینجا صحبت از کشتی تایتانیک معروف و حادثهای است که برای آن رخ داد. در فاجعه تایتانیک که در سال ۱۹۱۲ رخ داد، ۱۵14 نفر از ۲۲۲۴ مسافر و خدمه این کشتی، جان خود را از دست دادند. رقابت کگل تایتانیک (و یا به عبارتی راهنمای آموزشی)، دادههای حقیقی پیرامون این حادثه تلخ را در اختیار عموم قرار میدهد. وظیفه کاربر در این وهله آن است که از این دادهها برای پیشبینی این موضوع استفاده کند که آیا یک شخص خاص در این حادثه جان سالم به در برده است یا خیر.
یادگیری ماشین با پایتون
پیش از عمیق شدن در دادههای تایتانیک، ابتدا باید ابزارهای مورد نیاز برای حل مساله را نصب کرد. در گام اول، نیاز به نصب پایتون است. پایتون را میتوان از وبسایت رسمی آن [+] دانلود و نصب کرد. برای آنکه نسخهای از پایتون که توسط کاربر نصب میشود با نسخه جدید کتابخانههای پایتون سازگار باشد، توصیه میشود پایتون نسخه ۳.۶ به بالا نصب شود. پس از آن، باید کتابخانههای مورد نیاز را با pip نصب کرد. pip باید به طور خودکار، همراه با توزیعی از پایتون که کاربر دانلود کرده است، نصب شود. برای نصب مواردی که کاربر نیاز دارد با استفاده از pip، باید «ترمینال» (Terminal)، «خط فرمان» (Command Line) یا «پاورشل» (Powershell) را باز و دستورات زیر را وارد کرد.
اکنون به نظر میرسد که مقدمات کار به خوبی آماده شدهاند. همانطور که در کد بالا مشهود است، «ژوپیتر» (Jupyter) نیز نصب شده است. ژوپیتر یک نوتبوک محبوب است که میتوان کدهای پایتون را در آن به صورت تعاملی نوشت. برای باز کردن ژوپیتر، تنها کافی است که در ترمینال، jupyter notebook را وارد کرد. پس از آن، یک صفحه مرورگر وب مانند تصویر زیر باز میشود.

کد را میتوان به صورت تعاملی درون مربع سبزرنگ نوشت و ارزیابی کرد. اکنون که همه ابزارها نصب شدهاند، میتوان به ادامه کار پرداخت.
اکتشاف داده
اولین گام برای کاوش، اکتشاف دادهها است. در همین راستا، نیاز به دانلود کردن دادههای مورد استفاده در این مثال، از طریق صفحه مجموعه داده تایتانیک در کگل [+] وجود دارد. سپس، باید دادههای استخراج شده را درون پوشهای قرار داد که نوتبوک ژوپیتر آغاز شده است. در این مرحله، باید کتابخانههای لازم را «وارد» (ایمپورت) کرد.
سپس، باید دادهها را بارگذاری کرد.
خروجی، چیزی شبیه تصویر زیر خواهد بود.

آنچه در تصویر بالا وجود دارد، نمونهای از دادههای مجموعه داده تایتانیک هستند. ستونهای زیر در مجموعه داده وجود دارند.
- PassengerId: شماره شناسایی مسافران
- Survived: وضعیت زنده ماندن یا نماندن فرد
- Pclass: کلاس خدماتی که فرد برای آن بلیط گرفته است. در اینجا، «۱» کلاس اقتصادی، «۲» کلاس تجاری و «۳» درجه یک است.
- Name: نام مسافر
- Gender: جنسیت مسافر
- Age: سن مسافر
- Sibsp یا siblings and spouses: تعداد اعضای خانواده (همسر، خواهران و برادران) مسافر در کشتی
- Parch یا parents and children: تعداد والدین و فرزندان حاضر در کشتی (برای یک شخص حاضر در کشتی) مسافر
- Ticket: جزئیات بلیط مسافر
- Cabin: اطلاعات کابین مسافر، وجود NaN در این قسمت، به معنای ناشناخته است.
- Embarked یا محل مسافرگیری: S برای ساوتهمپتون (Southampton) و Q برای «کویینزتاون» (Queenstown) و C برای «شربورگ» (Cherbourg)
هنگام کاوش دادهها، معمولا «دادههای ناموجود» یا «دادههای گمشده» (Missing Data) پیدا میشوند. برای کشف این دادهها در مجموعه داده تایتانیک، از قطعه کد زیر استفاده شده است.
خروجی، تصویری مانند زیر خواهد بود.
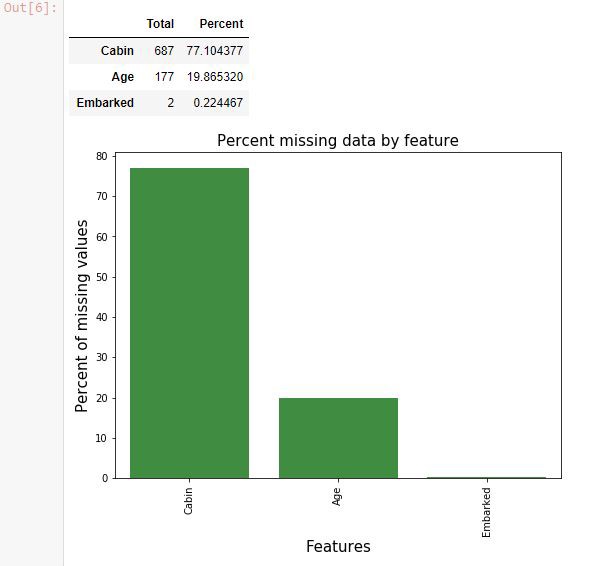
کابین، سن و دادههای محل مسافرگیری (محل سوار شدن مسافرها) دارای مقادیر ناموجود هستند. اطلاعات کابین، دارای مقادیر ناموجود بسیار زیادی است. برای چنین مقادیر ناموجودی (گم شده)، باید فکری کرد. به این فرایند، «پاکسازی دادهها» (Data Cleaning) گفته میشود.
پاکسازی دادهها
پیشپردازش دادهها بخش مهمی از فرایند «دادهکاوی» (Data Cleaning) است. هنگامی که دادهها پاکسازی شد، میتوان بدون نگرانی از هر چیزی، به گام بعدی رفت. یکی از گامهای متداولی که طی فرایند پاکسازی دادهها برداشته میشود، «جایگذاری مقادیر ناموجود» است. هیچ قاعده مشخصی برای انجام این کار وجود ندارد و راهکارهای گوناگونی تاکنون برای آن ارائه شدهاند که هر یک مزایب و معایب خود را دارند. گاه میتوان با آزمودن راهکارهای گوناگون و سنجش کارایی آنها برای یک مساله خاص، بهتری رویکرد را برگزید. به عنوان یک قاعده سرانگشتی، این نکته را نباید فراموش کرد که برای دادههای «طبقهای» (Categorized)، تنها از «مُد» (Mode) و از میانه یا میانگین برای دادههای پیوسته میتوان استفاده کرد. با توجه به اینکه embarkation مقادیر طبقهای دارد، از مد برای پیدا کردن مقادیر ناموجود آن استفاده میشود. همچنین، از میانه برای پر کردن مقادیر ناموجود Age استفاده میشود.
مساله بعدی، حذف دادهها برای مواردی است که مقادیر ناموجود زیادی دارند. برای مثال، در این مجموعه داده، cabin دارای مقادیر ناموجود زیادی است. بنابراین، ستون آن به طور کامل حذف میشود (البته به طور کلی، راهکار حذف نمونهها یا ویژگیهایی که دارای مقادیر از دست رفته هستند توصیه نمیشود. چون بدین شکل ممکن است اطلاعات مهمی از دست بروند. بنابراین، توصیه کلی آن است که از انجام چنین کاری حدالمقدور اجتناب شود).
اکنون، میتوان دادههای پاکسازی شده را بررسی کرد.
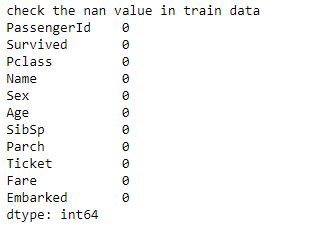
مساله مقادیر ناموجود به خوبی حل شده و همانطور که در تصویر بالا نیز میتوان مشاهده کرد هیچ داده ناموجودی پیدا نشده است. این یعنی دادهها پاکسازی شدهاند.
مهندسی ویژگیها
اکنون که دادهها پاکسازی شدند، گام بعدی که باید انجام شود «مهندسی ویژگیها» (Feature Engineering) است. مهندسی ویژگیها، روشی برای پیدا کردن مناسبترین ویژگیها یا دادهها برای حل مساله، از میان دادههای کنونی موجود است. راهکارهای متعددی برای انجام این کار وجود دارند، البته بر فراز همه این روشها، عقل سلیم است. در ادامه، نگاهی به دادههای مسافرگیری انداخته میشود. این بخش با S ،Q یا C پر شدهاند. اغلب کتابخانههای پایتون، تنها قادر به پردازش اعداد و نوع دادههای عددی هستند. بنابراین، برای حل این مشکل و تبدیل کردن دادههای طبقهای به عددی، نیاز به انجام کاری است که به آن روش کدبندی وان هات (One Hot Encoding)گفته میشود. با بهرهگیری از این روش، یک ستون به سه ستون تبدیل میشود. این ستونها Embarked_S ،Embarked_Q و Embarked_C نامیده شدهاند و با مقادیر ۰ و ۱ پر میشوند . مقدار ۱ در یک فیلد بدین معنا است که فرد در آن بندر سوار شده و مقدار صفر یعنی در آن بندر سوار نشده است.
مثالهای دیگر در همین رابطه، SibSp و Parch هستند. شاید هیچ چیز جالبی در این دو ستون وجود نداشته باشد، اما بدین شکل میتوان فهمید خانوادههایی که در کشتی حضور داشتند چقدر بزرگ بودهاند. ممکن است به نظر برسد که اگر خانواده بزرگتر بوده باشد، شانس نجات یافتن اعضای آن نیز بیشتر است. زیرا اعضای خانواده میتوانند به یکدیگر کمک کنند. این در حالی است که افراد تنها، چنین شانسی ندارند. بنابراین، ستون دیگری ساخته میشود با عنوان family size که شامل sibsp + parch + 1 است (خود مسافران).
آخرین مورد، «ستونهای دستهبندی» (bin columns) است. این روش برای ساخت دستههایی از مقادیر، برای گروهبندی چندین چیز در کنار هم است. زیرا به نظر میرسد که متمایز کردن چیزهایی با مقادیر یکسان یا بسیار نزدیک به هم، دشوار باشد. برای مثال، برای کسانی که ۵ و ۶ سال دارند، آیا تفاوت قابل توجهی وجود دارد؟ یا در میان افرادی که ۴۵ و ۴۶ سال دارند، آیا تفاوت خاصی وجود دارد؟ به همین دلیل است که ستونهای دستهها (bin) ساخته میشوند. در اینجا، برای سن چهار دسته ساخت میشود که عبارتند از: بچه (۰ تا ۱۴ سال)، نوجوان (۱۴ تا ۲۰ سال)، بزرگسال (۲۰ تا ۴۰ سال) و کهنسال (بالای ۴۰ سال). کد لازم برای این کار در ادامه آمده است.
اکنون که اقدامات لازم برای همه ویژگیها به پایان رسید، همبستگی ویژگیها به یکدیگر مورد بررسی قرار میگیرد.
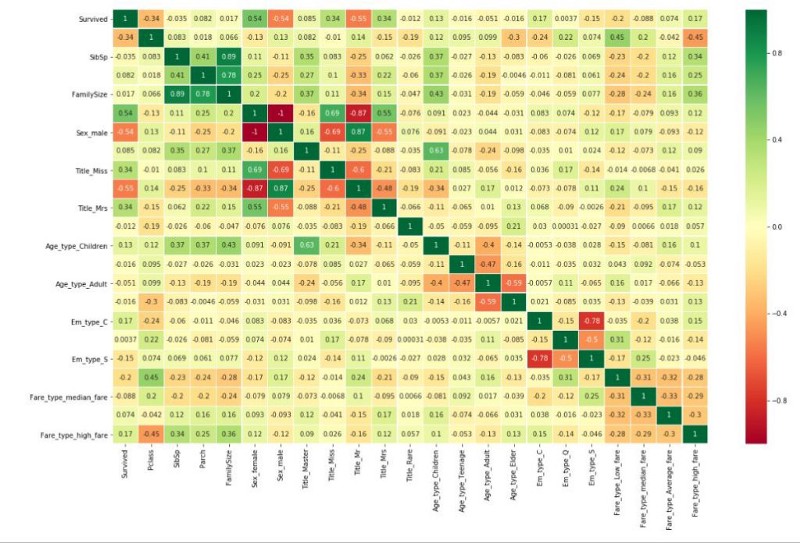
همبستگی با مقدار ۱ بدین معنا است که ویژگیها به شدت با یکدیگر همبسته هستند و با مقدار ۱- بدین معنا است که به شکل منفی با هم همبسته هستند. برای مثال، جنسیت زن و جنسیت مرد به طور منفی با هم همبسته هستند، زیرا مسافران در یکی از این دو دسته قرار میگیرند. به جز ویژگی بیان شده، میتوان مشاهده کرد که هیچ چیزی به شدت مرتبط به دیگری نیست، به جز مواردی که با مهندسی ویژگیها ساخته شده بودند. این یعنی کار مهندسی ویژگیها به درستی انجام شده است. پرسشی که در این وهله مطرح میشود این است که اگر یک ویژگی به شدت مرتبط به دیگری باشد، چه میشود؟ در پاسخ به این پرسش باید گفت که میتوان یکی از آنها را حذف کرد؛ زیرا اطلاعات جدیدی را به سیستم ارائه نمیکند. دلیل این امر، یکی بودن اطلاعات هر دو آنها است.
مدل یادگیری ماشین با پایتون
اکنون، نقطه اوج کار از راه رسیده است. ساخت مدل یادگیری ماشین با پایتون.
برای ساخت مدل یادگیری ماشین با پایتون، میتوان از الگوریتمهای متعدد و متنوعی که در کتابخانه «سایکیتلِرن» وجود دارند، استفاده کرد. برخی از این الگوریتمها در ادامه بیان شدهاند.
- رگرسیون لجستیک (Logistic Regression)
- جنگل تصادفی (Random Forest)
- ماشین بردار پشتیبان (Support Vector Machine | SVM)
- K نزدیکترین همسایگی (K Nearest Neighbor)
- نایو بیز (Naive Bayes)
- درخت تصمیم (Decision Trees)
- آدابوست (AdaBoost)
- تخصیص پنهان دیریکله (Latent Dirichlet Allocation | LDA)
- گرادیان تقویتی (Gradient boosting)
شاید برای افراد تازهوارد گیجکننده باشد که کدام یک از این موارد را باید برگزیند و یا اینکه، در هر یک از این الگوریتمها چه اتفاقی میافتد. در این وهله باید گفت که جای نگرانی نیست، همه این الگوریتمها در کتابخانه سایکیتلرن، مانند یک جعبه سیاه میمانند و الزاما کاربر نیاز به دانستن اتفاقاتی که درون آنها میافتد ندارد و کافی است الگوریتمی با کارایی مناسب برای این مساله را انتخاب کند. در اینجا، از الگوریتم جنگل تصادفی استفاده میشود.
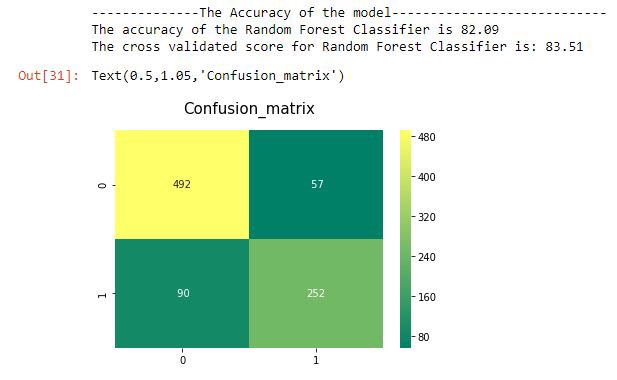
مدل، روی دادهها صحت ٪۸۳ را ارائه میکند. برای اولین بار خوب است. منظور از امتیاز حاصل از «اعتبارسنجی متقابل» (Cross-Validation)، امتیاز اعتبارسنجی متقابل K Fold است. K = 10 به این معنا است که دادهها به ۱۰ بخش تقسیم شدهاند و میانگین همه امتیازهای محاسبه شده برای آنها به عنوان میانگین کل ارائه شده است.
تنظیم دقیق
اکنون، گامهای لازم برای پیادهسازی یک مدل یادگیری ماشین با پایتون، به پایان رسید. اما، یک گام مهمتر وجود دارد که میتواند منجر به بهبود نتایج خروجی شود: تنظیم دقیق. «تنظیم دقیق» (Fine Tuning)، به معنای پیدا کردن بهترین پارامتر برای الگوریتمهای یادگیری ماشین است. در کد مربوط به جنگل تصادفی بالا که در زیر نشان داده شده، میتوان تنظیماتی به منظور بهبود خروجی انجام داد.
پارامترهایی وجود دارد که باید تنظیم شوند. موارد موجود در کد بالا، تنظیمات پیشفرض هستند. کاربر میتواند پارامترها را به هر شکلی که تمایل داشته باشد، تغییر دهد. البته، این کار زمان زیادی میبرد. جای نگرانی وجود ندارد، ابزاری با عنوان Grid Search وجود دارد که پارامترهای بهینه را به صورت خودکار پیدا میکند. جالب به نظر میرسد؟
توصیه میشود افراد پس از مطالعه این مطلب و بررسی کدها، خود کلیه موارد را امتحان کرده و برای دریافت خروجی مناسب تلاش کنند.
منبع: فرادرس