طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیکمبود حافظه هنگام اجرای برنامه در متلب — پادکست پرسش و پاسخ
امروزه، حجم دادههایی که افراد برای تحلیل مورد استفاده قرار میدهند افزایش قابل توجهی داشته است. همین امر، منجر به مشکلات و چالشهایی ضمن نوشتن و اجرای برنامههایی شده است که با حجم انبوهی از دادهها کار میکنند. یکی از این مشکلات، مساله اجرا نشدن برنامه در نرمافزار «متلب» (MATLAB) و نمایش خطای Out of Memory است. کاربران زیادی با این پرسش مواجه هستند که چگونه میتوان مشکل کمبود حافظه هنگام اجرای برنامه در متلب را حل کرد. دکتر «سید مصطفی کلامی هریس»، در پادکستی که در ادامه آمده، به این پرسش به طور مشروح پاسخ داده است. نسخه متنی این پادکست نیز در همین مطلب قرار دارد. البته، منبع اصلی همچنان فایل صوتی محسوب میشود.
پادکست پیرامون کمبود حافظه هنگام اجرای برنامه در متلب
ذخیره کردن این فایل صوتی: لینک دانلود
نسخه نوشتاری
یکی از مشکلات رایجی که که افراد گزارش میکنند، پیرامون مسالهای است که در اجرای برنامههای خود در «متلب» (MATLAB) دارند. وقتی حجم دادههای مساله و در واقع، حجم مساله از یک اندازه بزرگتر میشود، دیگر برنامه اجرا نمیشود و پیام خطای «کمبود حافظه» (Out of Memory) به کاربر نمایش داده میشود. یعنی حافظه تمام شده است و به اندازه کافی جا ندارد. در اینجا، منظور از «حافظه» (Memory)، «رم» (RAM) است. یعنی، حافظهای که برنامهها در آن اجرا میشوند. بنابراین، اگر رم به اندازه کافی وجود نداشته باشد، طبیعتا گنجایش لازم وجود ندارد و برنامهها نمیتوانند اجرا شوند.
چند راهکار برای حل این مساله وجود دارد. البته ابتدا باید بررسی شود که واقعا به میزان خاصی از رم نیاز باشد. گاهی، برنامه درست نوشته نشده و محاسبات و دادههای اضافی ضمن اجرای آن لود میشوند. بعضا در این شرایط میتوان موضوع را در همین مرحله حل کرد. اما گاهی چنین موضوعی حل شده است؛ اما، مثلا یک کامپیوتر با هشت گیک رم موجود است ولی برنامه کاربر به بیست گیگ رم احتیاج دارد.
به دو روش میتوان این مساله را حل کرد. یکی اینکه از کامپیوتر دیگری استفاده شود که خب فرض میشود امکان تغییر و ارتقا سختافزار وجود ندارد. روش دیگر این است که «حافظه مجازی» (Virtual Memory) به سیستم اضافه شود. یعنی، بخشی از «درایو دیسک سخت» (Hard Disk Drive) به عنوان رم تعریف شود. این امکان، در بخش «System Properties» در کنترل پنل تعبیه شده است. در نسخههای متفاوت ویندوز، امکان دارد جای آن متفاوت باشد. معمولا میتوان آن را با کلیک راست روی «My Computer» و از System Properties، بخش Advance، در قسمت Performance پیدا کرد. با جستجوی عبارتهایی مانند «Add Virtual Memory» در گوگل نیز میتوان روش آن را پیدا کرد.
با این قابلیت، به عنوان مثال اگر پارتیشن هارد ۳۰ گیگ فضا خالی دارد، ۳۰ گیگ به رم میتوان اضافه کرد تا در واقع از بخشی از این هارد دیسک نیز به عنوان RAM استفاده کند. البته اگر هارد کامپیوتر فرد از نسخههای قدیمی باشد، سرعت آن پایین است و این موجب افت کیفیت اجرای برنامه میشود. اما اگر هارد از مدلهای جدید و SSD باشد، به خوبی میتواند اثرگذار باشد و سرعت همچون وقتی که از هاردهای کلاسیک استفاده میشود، خیلی کاهش پیدا نمیکند. البته، به هر حال استفاده از هارد دیسک به عنوان حافظه مجازی نمیتواند به خوبی رم باشد. این مورد را حتما باید در نظر داشت، ولی به هر حال مشکل را حل میکند. البته در شرایط بیان شده، کمی کارایی کاهش پیدا میکند ولی به هر حال میتوان با استفاده از کامپیوتر موجود، کار را انجام داد و برنامه را اجرا کرد. یعنی در واقع، گاهی ناگزیر باید این کار را انجام داد. یعنی، بخشی از هارد، یا یک یا چند پارتیشن را، به عنوان یک رم ثانویه و در واقع، یک رم مجازی (Virtual Memory) تخصیص داده و سایر کارها را خود سیستم عامل جلو میبرد.
البته این را نیز باید مد نظر داشت که بعد از انجام این تنظیمات، باید متلب را بست و دوباره باز کرد و گاهی حتی نیاز میشود کامپیوتر را Reset کرد. این موضوع، بستگی به «پیکربندی» (Configuration) سیستم کاربر دارد. برای حصول اطمینان از اینکه این تغییرات اعمال شده است، میتوان در Task Manager و با استفاده از کلیدهای ترکیبی Ctrl+Shift+Escape، میتوان آمارهای مربوط به سیستم را مشاهده کرد. در این بخش، میتوان میزان حافظه در دسترس (Available)، میزان حافظه مجازی (Virtual Memory) و حافظه فیزیکی (Physical Memory) را مشاهده کرد.
به هر حال، مساله Out of Memory نه تنها در متلب که در بقیه نرمافزارها نیز ممکن است به وقوع بپیوندد و آن را میتوان بدین شکل حل کرد. از آنجا که بسیاری از دانشجویان از متلب استفاده میکنند و این موضوع، مشکل شایعی در این نرمافزار است، راه حل آن را بیان کردم.
برای دانلود کردن و شنیدن دیگر پادکستهای دکتر سید مصطفی کلامی هریس در مجله فرادرس، روی این لینک [+] کلیک کنید.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
ساخت خزنده وب (Web Crawler) با فریمورک Scrapy — از صفر تا صد
در این نوشته میخواهیم یک ربات خزنده وب بسازیم تا روی صفحههای مختلف جستجو کرده و اطلاعاتی برای ما گردآوری کند. بدین منظور از یک فریمورک پایتون به نام Scrapy استفاده خواهیم کرد.
Scrapy چیست؟
بر اساس تعریف ویکیپدیا، Scrapy که skray-pee تلفظ میشود یک فریمورک خزش وب اوپنسورس و رایگان است که به زبان پایتون نوشته شده است. این فریمورک در ابتدا برای وب اسکرپینگ طراحی شده بود و اکنون میتوان از آن برای استخراج دادهها با استفاده از API-ها و یا به عنوان یک خزنده وب عمومی استفاده کرد. این فریمورک در حال حاضر از سوی شرکت Scrapinghub نگهداری میشود که ارائهدهنده خدمات برنامهنویسی وب اسکرپینگ است.
ایجاد یک پروژه
Scrapy ایده پروژهای را مطرح کرد که چندین خزنده یا عنکبوت در یک پروژه منفرد داشته باشد. این مفهوم به طور خاص در مواردی مفید است که مشغول نوشتن چندین خزنده برای بخشهای مختلف یا زیردامنههای متفاوت یک سایت باشیم. بنابراین در ابتدا یک پروژه میسازیم:
ایجاد خزنده
با اجرای دستور زیر یک پروژه با نام olx ایجاد و اطلاعاتی را که برای مراحل بعدی کار مفید هستند ارائه میشوند.
ابتدا به پوشه جدیداً ایجاد شده میرویم و سپس دستوری برای تولید نخستین عنکبوت با نام دامنه و سایتی که باید خزیده شود، وارد میکنیم:
ما کد عنکبوت نخست خود را با نام electronics ساختیم، زیرا قصد داریم به بخش electronics در سایت OLX دسترسی پیدا کنیم. شما میتوانید نام عنکبوت خود را بر اساس نیازهای خود تعیین کنید.
ساختار پروژه نهایی چیزی مانند تصویر زیر خواهد بود:
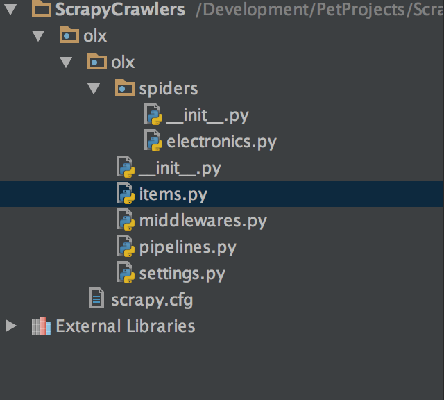
همان طور که میبینید یک پوشه مستقل برای هر عنکبوت وجود دارد. شما میتوانید چند عنکبوت را به یک پروژه منفرد اضافه کنید. اگر فایل عنکبوت electronics.py را باز کنیم با چیزی مانند زیر مواجه میشویم:
چنان که مشاهده میکنید، ElectronicsSpider یک زیرکلاس از scrapy.Spider است. مشخصه name در واقع نام عنکبوت است که در دستور تولید عنکبوت تعیین شده است. این نام در زمانی که خزنده، خود را اجرا میکند به کار میآید. مشخصه allowed_domains تعیین میکند که کدام دامنهها در دسترس این خزنده هستند و start_urls جایی است که URL-های ابتدایی در آنجا نگهداری میشوند. این URL-های ابتدایی در زمان آغاز به کار عنکبوت مورد نیاز هستند. علاوه بر ساختار فایل، این یک قابلیت خوب برای ایجاد کرانهایی برای خزنده است.
متد parse چنان که از نامش برمیآید، محتوای صفحهای را که مورد دسترسی قرار داده است تحلیل خواهد کرد. ما میخواهیم خزندهای بنویسیم که به چندین صفحه برود و به این منظور باید برخی تغییرات ایجاد کنیم.
برای این که خزنده به چندین صفحه سر بزند، به جای scrapy.Spider یک زیرکلاس از آن ایجاد میکنیم. این کلاس موجب میشود که خزش روی صفحههای چندگانه آسانتر باشد. شما میتوانید با کد تولید شده هر کاری که دوست دارید انجام دهید، اما باید مواظب باشید که دوباره به صفحههای قبلی بازنگردید.
گام بعدی این است که متغیرهای قاعده خود را تنظیم کنید. در اینجا قواعد ناوبری وبسایت را بررسی میکنیم. LinkExtractor در واقع پارامترهایی برای رسم کرانها میگیرد. ما در این مثال از پارامتر restrict_css برای تعیین کلاسی جهت صفحه بعدی استفاده میکنیم. اگر به این صفحه (+) مراجعه کنید، چیزی مانند تصویر زیر را مشاهده خواهید کرد:
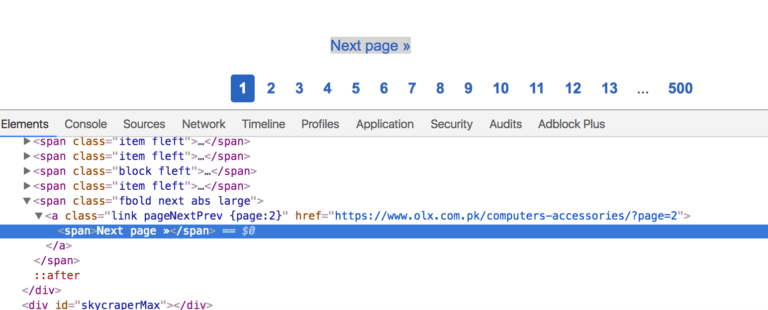
pageNextPrev کلاسی است که برای واکشی لینکها صفحههای بعدی استفاده میشود. پارامتر call_back مشخصی میکند که کدام متد برای دسترسی به عناصر استفاده میشود. این متد را در ادامه بررسی میکنیم.
به خاطر داشته باشید که باید نام متد را از ()parse به ()parse_item با هر چیزی که دوست دارید تغییر دهید تا از override شدن کلاس مبنا جلوگیری شود. در غیر این صورت قاعده شما کار نخواهد کرد حتی اگر مقدار follow=True تنظیم کنید.
تا به اینجا همه چیز به خوبی پیش رفته است. در ادامه خزندهای را که تا به اینجا ساختهایم تست میکنیم. در دایرکتوری پروژه به ترمینال بروید و دستور زیر را وارد کنید:
پارامتر سوم در واقع نام عنکبوتی است که قبلاً در مشخصه name کلاس ElectronicsSpiders تعیین کردهایم. در ترمینال اطلاعات مفید زیادی مییابید که برای دیباگ کردن خزنده مفید هستند. در صورتی که نخواهید اطلاعات دیباگ کردن را ببینید، میتوانید گزینه debugger را غیرفعال کنید. دستور مشابهی با سوئیچ –nolog وجود دارد:
اگر این دستور را در حال حاضر اجرا کنید، خروجی چیزی مانند زیر خواهد بود:
از آنجا که مقدار follow=True را تنظیم کردهایم، خزنده قاعده صفحه بعد را بررسی میکند و به ناوبری خود ادامه میدهد، مگر این که به صفحهای برخورد کند که قاعده در مورد آن صدق نمیکند که معمولاً صفحه آخر لیست است.
اینک تصور کنید بخواهیم منطق مشابهی را با چیزهایی که در این صفحه (+) اشاره شدهاند بنویسیم، ابتدا باید کدی بنویسیم که روی چندین پردازنده کار کند. همچنین باید کدی بنویسیم که نه تنها به صفحه بعد برود، بلکه اسکریپت را از طریق عدم دسترسی به URL های ناخواسته، در داخل کرانهای تعریف شده نگه دارد. Scrapy همه این وظایف را از دوش ما بر میدارد و کاری میکند که صرفاً روی منطق متمرکز شویم، یعنی خزندهای برای استخراج اطلاعات بنویسیم. اینک قصد داریم کدی بنویسیم که لینکهای آیتم منفرد مانند صفحههای فهرستبندی را واکشی کند بدین ترتیب کدی را که در متد parse_item داشتیم تغییر میدهیم:
در این کد ما لینکها را با استفاده از متد css. پاسخ واکشی میکنیم. چنان که گفتیم میتوان از xpath نیز استفاده کرد و بستگی به نظر شما دارد.. در این حالت همه چیز کاملاً ساده خواهد بود:

لینک دیگر کلاسی به نام detailsLink دارد. اگر تنها از (‘response.css(‘.detailsLink استفاده کنیم، در این صورت لینکهای تکراری از یک مدخل منفرد گردآوری میشوند، زیرا لینکها در تگهای img و h3 تکرار شدهاند. همچنین به کلاس والد large اشاره کردهایم تا لینکهای یکتا دریافت کنیم. ما از (attr(href:: برای استخراج بخش href خود لینک استفاده میکنیم. سپس از متد ()extract استفاده میکنیم.
دلیل استفاده از این متد آن است که css. و xpath. شیء SelectorList را بازگشت میدهند و ()extract به بازگرداندن DOM واقعی برای پردازش بیشتر کمک میکند. در نهایت لینکها را در scrapy.Request با یک callback به صورت کامل yield میکنیم. ما کد داخلی Scrapy را بررسی نکردهایم، اما احتمالاً از yield به جای return استفاده میکند، زیرا میتوانید چندین آیتم را return کنید. از آنجا که خزنده باید مراقب لینکهای چندگانه همراه با هم نیز باشد، در این صورت yield بهترین انتخاب خواهد بود.
متد parse_detail_page چنان که از نامش هویدا است، اطلاعات منفرد را از صفحه جزییات تحلیل میکند. بنابراین اتفاقی که در عمل میافتد این است که:
- یک لیست از مدخلها در parse_item به دست میآورید.
- میتوانید آنها را در یک متد callback برای پردازش بیشتر ارسال کنید.
از آنجا که تنها پیمایش دوسطحی وجود دارد، قادر شدیم به کمک دو متد به پایینترین سطح برسیم. اگر قصد داشتیم شروع به خزش از صفحه اصلی وبسایت OLX بکنیم، باید سه متد مینوشتیم که دو مورد برای واکشی دستهبندیهای فرعی و مداخل آنها و متد آخر برای تحلیل اطلاعات واقعی بود.
در نهایت قصد داریم اطلاعات واقعی را تحلیل کنیم که روی یکی از مدخلها مانند این (+) در دسترس است.
تحلیل اطلاعات این صفحه کار دشواری نیست، اما این کاری است که باید روی اطلاعات ذخیرهشده صورت بگیرد. ما باید model را برای دادههای خود تعریف کنیم. این بدان معنی است باید به Scrapy بگوییم چه اطلاعاتی را میخواهیم برای استفادههای بعدی ذخیره کنیم. در ادامه فایل item.py را ویرایش میکنیم که قبلاً از سوی Scrapy ایجاد شده است:
OlxItem کلاسی است که در آن فیلدهای مورد نیاز برای نگهداری اطلاعات را تنظیم خواهیم کرد. ما قصد داریم سه فیلد برای کلاس مدل خود تعریف کنیم.
در این فیلدها عنوان مطلب، قیمت و خود URL را ذخیره میکنیم. در این مرحله به فایل کلاس خزنده بازمیگردیم و parse_detail_page را ویرایش میکنیم. اکنون یک متد برای آغاز نوشتن کد، یکی برای تست از طریق اجرای کل خزنده و دیگری برای مشاهده درست بودن مسیر است، اما ابزار جالب دیگری نیز وجود دارد که از سوی Scrapy عرضه شده است.
شل Scrapy
Shell یا پوسته Scrapy (+) یک ابزار خط فرمان است که فرصت تست کد تحلیلشده را بدون اجرای کلی خزنده در اختیار ما قرار میدهد. برخلاف خزنده که به همه لینکها سر میزند، شل Scrapy اقدام به ذخیرهسازی DOM یک صفحه منفرد برای استخراج دادهها میکند:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/asus-eee-pc-atom-dual-core-4cpus-beautiful-laptops-fresh-stock-IDUVo6B.html#4001329891
اکنون میتوان به سادگی کد را بدون مراجعه چندباره به همان URL تست کرد. بدین ترتیب عنوان صفحه را با کد زیر واکشی کردهایم:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"آن response.css آشنا را اینجا هم میتوانید مشاهده کنید. از آنجا که کل DOM موجود است میتوان هر کاری با آن انجام داد. برای نمونه آن را میتوان به صورت زیر واکشی کرد:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'نیازی به انجام هیچ کاری برای واکشی url نیست، زیرا response.url اقدام به بازگشت دادن URL-ی میکند که هم اینک مورد دسترسی قرار گرفته است.
اکنون که همه کد را بررسی کردیم، نوبت آن رسیده است که parse_detail_page را مورد استفاده قرار دهیم:
وهله OlxItem پس از تحلیل کردن اطلاعات لازم ایجاد میشود و مشخصهها تعیین میشوند. اینک که نوبت اجرای خزنده و ذخیرهسازی اطلاعات رسیده است، کمی تغییر در دستور باید ایجاد کرد:
scrapy crawl electronics -o data.csv -t csv
ما نام فایل و قالببندی فایل را برای ذخیرهسازی دادهها ارسال میکنیم. زمانی که دستور فوق اجرا شود فایل CSV برای شما میسازد. چنان که میبینید روند سادهای است و برخلاف خزندهای که خود میباید مینوشتیم، در اینجا کافی است رویه مورد نیاز برای ذخیرهسازی دادهها را بنویسیم.
اما زیاد عجله نکنید! کار به همین جا ختم نمیشود. شما میتوانید حتی دادهها را در قالب JSON نیز ذخیره کنید، تنها کاری که به این منظور لازم است ارسال مقدار json با سوئیچ t- است.
Scrapy قابلیتهای دیگری نیز در اختیار ما قرار میدهد. برای نمونه میتوان یک نام فایل ثابت ارسال کرد که در سناریوهای دنیای واقعی هیچ معنایی ندارد. چرا باید برنامهای نوشت که نام فایل ثابتی تولید کند؟ یکی از موارد استفاده آن این است که باید فایل settings.py را اصلاح و این دو مدخل را اضافه کنید:
FEED_URI = 'data/%(name)s/%(time)s.json' FEED_FORMAT = 'json'
در ادامه الگوی فایلی که ایجاد کردهایم را ارائه میکنیم. %(name)% نام خود خزنده است، time زمان را نشان میدهد. اکنون زمانی که دستور زیر را اجرا کنیم:
scrapy crawl --nolog electronics
و یا دستور زیر را اجرا کنیم:
scrapy crawl electronics
یک فایل JSON در پوشه data مانند زیر ایجاد میشود:
1 2 3 4 5 6 7 | [ {"url": "https://www.olx.com.pk/item/acer-ultra-slim-gaming-laptop-with-amd-fx-processor-3gb-dedicated-IDUQ1k9.html", "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"}, {"url": "https://www.olx.com.pk/item/saw-machine-IDUYww5.html", "price": "Rs 80,000", "title": "Saw Machine"}, {"url": "https://www.olx.com.pk/item/laptop-hp-probook-6570b-core-i-5-3rd-gen-IDUYejF.html", "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"}, {"url": "https://www.olx.com.pk/item/zong-4g-could-mifi-anlock-all-sim-supported-IDUYedh.html", "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"}, ... ] منبع: فرادرس |
آموزش Node.js: آشنایی با npm و npx — بخش پنجم
در بخش قبلی این سری مقالات آموزش Node.js به توضیح برخی ویژگیهای فایل Package.json پرداختیم. اینک به توضیح npm و npx میپردازیم. برای مطالعه بخش قبلی میتوانید به لینک زیر مراجعه کنید:
برای دیدن آخرین نسخه از پکیج npm نصب شده شامل وابستگیهایش از دستور زیر استفاده کنید:
npm list
مثال:
❯ npm list /Users/flavio/dev/node/cowsay └─┬ cowsay@1.3.1 ├── get-stdin@5.0.1 ├─┬ optimist@0.6.1 │ ├── minimist@0.0.10 │ └── wordwrap@0.0.3 ├─┬ string-width@2.1.1 │ ├── is-fullwidth-code-point@2.0.0 │ └─┬ strip-ansi@4.0.0 │ └── ansi-regex@3.0.0 └── strip-eof@1.0.0
همچنین میتوانید فایل package-lock.json را باز کنید، اما نیازمند کمی کاوش است. دستور npm list –g نیز کار فوق را اما منحصراً در مورد پکیجهای سراسری انجام میدهد.
برای دریافت پکیجهای سطح بالا، یعنی آنها را که به npm گفتهاید نصب کند و در package.json لیست شدهاند، دستور زیر را اجرا کنید:
npm list --depth=0
خروجی:
❯ npm list --depth=0 /Users/flavio/dev/node/cowsay └── cowsay@1.3.1
میتوان نسخه یک پکیج خاص را از طریق تعیین نام آن به دست آورد:
❯ npm list cowsay /Users/flavio/dev/node/cowsay └── cowsay@1.3.1
این دستور در مورد وابستگیهای پکیجهای نصب شده نیز اجرا میشود:
❯ npm list minimist /Users/flavio/dev/node/cowsay └─┬ cowsay@1.3.1 └─┬ optimist@0.6.1 └── minimist@0.0.10
اگر میخواهید ببینید آخرین نسخه پکیج روی یک ریپازیتوری چیست دستور زیر را اجرا کنید:
npm view [package_name] version
خروجی:
❯ npm view cowsay version
نصب یک نسخه قدیمیتر از یک پکیج npm
نصب نسخههای قدیمیتر از یک پکیج npm در برخی موارد میتواند برای حل یک مشکل تطبیقپذیری مناسب باشد. شما می توانید یک نسخه قدیمی از یک پکیج npm را با استفاده از ساختار @ نصب کنید:
npm install <package>@<version>
مثال:
npm install cowsay
دستور فوق نسخه 1.3.1 (که آخرین نسخه در زمان نگارش این مقاله است) را نصب میکند، برای نصب نسخه 1.2.0 میتوانید از دستور زیر استفاده کنید:
npm install cowsay@1.2.0
همین کار را میتوان با استفاده از پکیجهای سراسری نیز اجرا کرد:
npm install -g webpack@4.16.4
همچنین ممکن است بخواهید همه نسخههای قبلی یک پکیج را نصب کنید. این کار با اجرای دستور زیر ممکن است:
npm view <package> versions
خروجی:
❯ npm view cowsay versions [ '1.0.0', '1.0.1', '1.0.2', '1.0.3', '1.1.0', '1.1.1', '1.1.2', '1.1.3', '1.1.4', '1.1.5', '1.1.6', '1.1.7', '1.1.8', '1.1.9', '1.2.0', '1.2.1', '1.3.0', '1.3.1' ]
بهروزرسانی همه وابستگیهای Node به آخرین نسخهها
هنگامی که یک پکیج را با استفاده از دستور <npm install <packagename نصب میکنید، جدیدترین نسخههای ممکن پکیج دانلود میشوند و در پوشه node_modules قرار میگیرند و یک مدخل متناظر به فایل package.json و package-lock.json اضافه میشود که در پوشه جاری حضور دارند.
npm وابستگیها را محاسبه کرده و جدیدترین نسخههای آنها را نیز نصب میکند. فرض کنید میخواهید پکیج cowsay را نصب کنید که یک ابزار جالب خط فرمان است که امکان ایجاد شکل یک «گاو» در حال بیان یک پیام را میدهد. هنگامی که دستور npm install cowsay را اجرا کنید، مدخل زیر به فایل package.json اضافه خواهد شد:
و در ادامه خروجی package-lock.json را مشاهده میکنید که برای وضوح بیشتر در آن وابستگیهای تودرتو حذف شدهاند:
اینک این 2 فایل به ما میگویند که نسخه نصب شده cowsay 1.3.1 است. قاعده ما برای بهروزرسانی به صورت 1.3.1^ است که بر اساس قواعد نسخهبندی npm بدان معنی است که میتواند انتشارهای فرعی و وصلهها یعنی 0.13.1، 0.14.0 و غیره را بهروزرسانی کند.
اگر یک انتشار فرعی یا وصله وجود داشته باشد و دستور npm update را وارد کنیم، نسخه نصبی بهروزرسانی میشود و فایل package-lock.json با نسخه جدید پر میشود، اما فایل package.json بیتغییر باقی میماند. برای یافتن انتشارهای جدید پکیجها میتوانید دستور npm outdated را وارد کنید.
در ادامه فهرستی از پکیجهای تاریخ گذشته را در یک ریپازیتوری که اخیراً بهروزرسانی نشدهاند مشاهده میکنید:
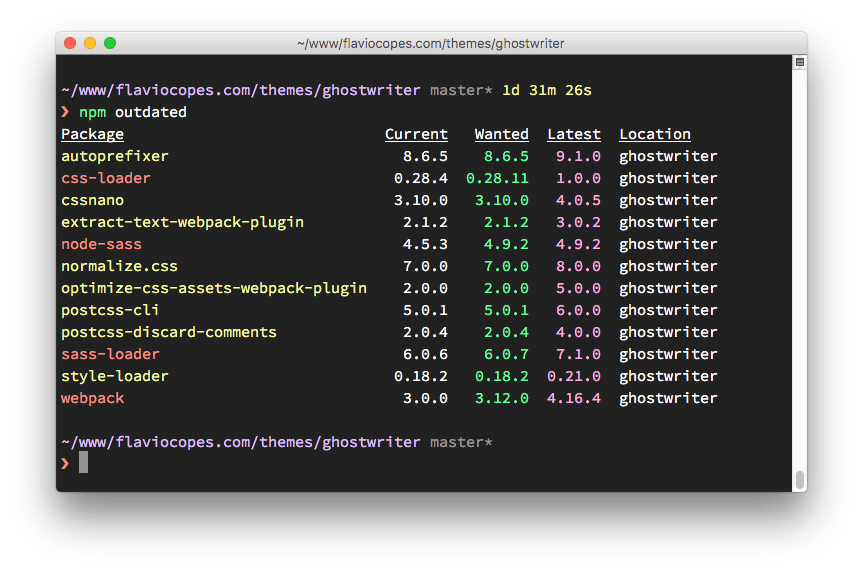
برخی از این بهروزرسانیها انتشار اصلی هستند. اجرای دستور npm update نسخه این موارد را بهروزرسانی نخواهد کرد. انتشارهای اصلی هرگز به این روش بهروزرسانی نمیشوند، چون آنها (برحسب تعریف) تغییرهای گسستهای ایجاد میکنند و npm میخواهید شما را در برابر بروز مشکلات محافظت کند.
برای بهروزرسانی یک نسخه اصلی از همه پکیجها، باید پکیج npm-check-updates را به صورت سراسری نصب کنید:
npm install -g npm-check-updates
و سپس دستور زیر را اجرا کنید:
ncu –u
دستور فوق همه نسخههای موجود در فایل package.json را به dependencies و devDependencies بهروزرسانی میکند به طوری که npm میتواند نسخه جدید اصلی را نصب کند.
اکنون آماده هستید که بهروزرسانی را اجرا کنید:
npm update
اگر پروژه را بدون وابستگیهای node_modules دانلود کردهاند و میخواهید ابتدا نسخههای جدید را نصب کنید، میتوانید دستور زیر را اجرا کنید:
npm install
نسخهبندی معناشناختی با استفاده از npm
نسخهبندی معناشناختی یک قرارداد است که به نسخههای مختلف معنا میبخشد. اگر در مورد پکیجهای Node تنها یک نکته مهم وجود داشته باشد، آن این است که همه افراد روی استفاده از نسخهبندی معناشناختی در تعیین اعداد نسخه توافق دارند.
مفهوم نسخهبندی معناشناختی ساده است. همه نسخهها سه رقم به صورت x.y.z دارند که هرکدام معنی مشخصی دارند:
- رقم نخست نشاندهنده نسخه اصلی است.
- رقم دوم نشاندهنده نسخه فرعی است.
- رقم سوم نشاندهنده نسخه وصله است.
زمانی که یک انتشار جدید انجام مییابد، اعداد به صورت تصادفی انتساب نمییابند، بلکه قواعد خاصی وجود دارند:
- عدد اصلی نسخه زمانی افزایش مییابد که تغییرهای ناسازگاری با نسخههای قبلی در API ایجاد شده باشد.
- نسخههای فرعی زمانی اضافه میشوند که یک کارکرد به روش سازگار با نسخههای قبل اضافه شده باشد.
- نسخه وصله نیز شامل اصلاحیههای باگ مطابق با نسخههای قبلی است.
این قرارداد از سوی همه زبانهای برنامهنویسی پذیرش یافته است و بسیار مهم است که همه پکیجهای npm به آن پایبند باشند، چون کل سیستم به آن وابسته است.
چرا نسخهبندی معنایی مهم است؟
از آنجا که npm برخی قواعد را تعیین کرده است، میتوانیم در زمان اجرای دستور npm update از این قواعد در فایل package.json استفاده کنیم تا نسخهای را که میتواند پکیج را به آن بهروزرسانی کند انتخاب کنیم.
در این قواعد از نمادهای زیر استفاده میشود:
- ~
- >
- >=
- <
- <=
- =
- –
- ||
در ادامه هر یک از نمادهای فوق را توضیح میدهیم:
نماد ^: اگر قاعدهای به صورت 0.13.0^ بنویسیم، وقتی که دستور npm update را اجرا میکنید، میتوانید انتشارهای فرعی و وصله را بهروزرسانی کند. برای مثال 0.13.1، 0.14.0 و غیره.
نماد ~: اگر قاعدهای به صورت 0.13.0~ بنویسید هنگامی که دستور npm update را اجرا میکنید، تنها نسخههای وصله بهروزرسانی میشوند. بین ترتیب 0.13.1 درست است، اما 0.14.0 چنین نیست.
نماد >: بدین ترتیب هر نسخهای بالاتر از عددی که ذکرمی شود قابل قبول خواهد بود.
نماد >=: هر نسخهای برابر یا بالاتر از آن که تعیین کردهاید مورد قبول است.
نماد <=: هر نسخهای برابر با پایینتر از عددی تعیین شده قابل قبول است.
نماد <: هر نسخهای پایینتر از عدد ذکر شده مورد پذیرش است.
نماد =: عدد دقیق نسخه مورد قبول است.
نماد –: بازهای از نسخهها مورد قبول است.
نماد | |: چند بازه با هم ترکیب میشوند برای مثال: < 2.1 || > 2.6
شما میتوانید برخی از این نمادها را با هم ترکیب کنید، برای نمونه از 1.0.0 || >=1.1.0 <1.2.0 استفاده کنید تا از نسخه 1.0.0 یا یکی از انتشارهای 1.1.0 به بالا اما پایینتر از 1.2.0 استفاده کنید.
قواعد دیگری نیز وجود دارند:
- بدون نماد: شما تنها نسخه دقیقی را که تعیین شده (برای نمونه 1.2.1) میپذیرید.
- Latest: در این حالت تنها از آخرین نسخه موجود استفاده میشود.
لغو نصب پکیجهای npm به صورت محلی یا سراسری
برای لغو نصب پکیجهایی که قبلاً به صورت محلی با استفاده از <npm install <package-name در پوشه node_modules نصب شدهاند، باید دستور زیر را اجرا کنید:
npm uninstall <package-name>
با استفاده از فلگ s- یا save— این عملیات نیز موجب حذف ارجاع در فایل package.json میشود.
اگر پکیج یک وابستگی توسعه باشد، در بخش devDependencies در فایل package.json فهرست شده است و باید از فلگ D / –save-dev- برای حذف آن از فایل استفاده کنید:
npm uninstall -S <package-name> npm uninstall -D <package-name>
اگر پکیج به صورت سراسری نصب شده باشد، باید فلگ g / –global- را اضافه کنید:
npm uninstall -g <package-name>
مثال:
npm uninstall -g webpack
و میتوانید این دستور را از هر جایی که میخواهید روی سیستم اجرا کنید، چون پوشهای که اکنون در آن قرار دارید اهمیتی ندارد.
پکیجهای محلی یا سراسری npm
اینک شاید بپرسید نصب محلی پکیجها بهتر است یا نصب سراسری آنها و دلیل آن چیست؟ تفاوت اصلی بین پکیجهای محلی و سراسری به شرح زیر است:
پکیجهای محلی
این پکیجها در همان دایرکتوری که دستور <npm install <package-name اجرا میشود، نصب خواهند شد و در پوشه node_modules زیر این دایرکتوری قرار میگیرند.
پکیجهای سراسری
این پکیجها در یک مکان منفرد در سیستم قرار میگیرند که موقعیت دقیق آن به تنظیمات سیستم وابسته است و مهم نیست که دستور <npm install -g <package-name از کجا اجرا شده باشد.
در کد هر دو پکیج به طرز یکسانی «الزام» (require) میشوند:
require('package-name')اینک شاید بپرسید که پکیجها را باید به چه روشی نصب کنید؟ به طور کلی همه پکیجها باید به صورت محلی نصب شوند. بین ترتیب این اطمینان حاصل میشود که میتوانید اپلیکیشنهای مختلفی روی سیستم خود داشته باشید که در صورت نیاز نسخههای متفاوتی از هر پکیج را اجرا کنند.
بهروزرسانی یک پکیج سراسری موجب میشود که همه پروژهها از انتشارهای جدید استفاده کنند و همان طور که حدس میزنید این وضعیت ازنظر نگهداری اپلیکیشنها یک کابوس محسوب میشود، چون برخی پکیجها ممکن است با وابستگیهای دیگر ناسازگار باشند.
وقتی همه پروژهها نسخههای محلی خود را از یک پکیج دارند، حتی اگر به نظر بیاید که موجب هدررفت منابع میشود، اما این هزینه در برابر عواقب منفی نصب سراسری پکیجها ناچیز است.
یک پکیج زمانی باید به صورت سراسری نصب شود که دستور اجرایی داشته باشد که بتوانید از پوسته (CLI) اجرا کنید و در روی پروژهها قابلیت استفاده مجدد داشته باشد. همچنین میتوانید دستورهای اجرایی را به صورت محلی و با استفاده از npx اجرا کنید، اما برخی پکیجها وقتی که به صورت سراسری نصب میشوند بهتر هستند.
نمونههایی از پکیجهای سراسری که ممکن است بشناسید، به شرح زیر هستند:
- npm
- create-react-app
- vue-cli
- grunt-cli
- mocha
- react-native-cli
- gatsby-cli
- forever
- nodemon
شما ممکن است از قبل برخی پکیجها را روی سیستم خود داشته باشید که به صورت سراسری نصب شده باشند. آنها را میتوان با اجرای دستور زیر در خط فرمان مشاهده کرد:
npm list -g --depth 0
وابستگیهای dependencies و devDependencies
چه زمانی میتوان گفت که یک پکیج، وابستگی (dependency) است و چه هنگام میتوان آن را وابستگی توسعه (DevDependency) نامید؟
زمانی که یک پکیج npm را با استفاده از دستور زیر نصب میکنید، آن را به صورت یک وابستگی نصب کردهاید:
npm install <package-name>
این پکیج به صورت خودکار در فایل package.json و زیر dependencies فهرست میشود. زمانی که فلگ D- را اضافه میکنید یا از فلگ save-dev- استفاده میکنید، پکیج را به صورت یک وابستگی توسعه نصب میکنید و به فهرست devDependencies اضافه میشود.
وابستگیهای توسعه به این منظور ارائه شدهاند که پکیجهایی صرفاً در محیط توسعه اپلیکیشن نصب شوند و قرار نیست در محیط عرضه نهایی (Production) حضور داشته باشند. برای نمونه پکیجهای تست، webpack یا Babel چنین خصوصیتهایی دارند.
زمانی که به محیط Production میرویم، اگر دستور npm install را وارد کنیم و آن پوشه شامل فایل package.json باشد، این پکیجها به صورتی نصب میشوند که npm تصور میکند این یک توزیع توسعه (Development) است.
بدین ترتیب باید فلگ production– را طوری تنظیم کنید (npm install –production) که از نصب این وابستگیهای توسعه جلوگیری کند.
Node Package Runner به نام npx
npx یک روش بسیار جالب برای اجرای کدهای Node.js محسوب میشود و قابلیتهای مفید زیادی ارائه کرده است. در این بخش یک دستور بسیار قدرتمند را معرفی میکنیم که از نسخه 5.2 npm به بعد وجود داشته است. این نسخه که در جولای 2017 انتشار یافته به نام npx شناخته میشود. اگر نمیخواهید npm را نصب کنید، میتوانید آن را به صورت یک پکیج مستقل نصب کنید. npx امکان اجرای کد ساخته شده با Node.js و انتشار یافته از طریق ریپازیتوری npm را فراهم میکند.
اجرای آسان دستورهای محلی
توسعهدهندگان Node.js عادت دارند که اغلب دستورهای اجرایی را به صورت پکیجهای سراسری منتشر کنند تا بیدرنگ در دسترسشان بوده و قابلیت اجرایی داشته باشند. این روش پردردسری است، زیرا عملاً امکان نصب نسخههای مختلفی از یک دستور واحد وجود ندارد. اجرای دستور npx commandname به صورت خودکار باعث میشود که ارجاع صحیحی از دستور در مسیر جاری کاربر، بدون نیاز به دانستن مسیر دقیق و بدون الزام نصب سراسری پکیج، درون پوشه node_modules یک پروژه پیدا شود.
اجرای دستورها بدون نیاز به نصب
npm قابلیت عالی دیگری نیز دارد که امکان اجرای دستورها بدون نصب آنها را فراهم میسازد. این قابلیت بسیار مفید است چون:
- نیاز به نصب هیچ چیزی وجود ندارد.
- میتوان نسخههای مختلفی از یک دستور را با استفاده از ساختار @vrsion اجرا کرد.
یک نمایش نوعی برای استفاده از npx دستور cowsay است. cowsay یک «گفته گاوی» نمایش میدهد که در آن دستوری نوشته شده است. برای نمونه cowsay کاراکترهای زیر را روی صفحه نمایش میدهد:
این وضعیت زمانی است که دستور cowsay را قبلاً به صورت سراسری از npm نصب کرده باشید، در غیر این صورت زمانی که دستور را اجرا کنید، با خطایی مواجه میشوید.
npx امکان اجرای آن دستور npm را بدون الزام به نصب محلی فراهم میسازد:
npx cowsay "Hello"
همان طور که میبینید این یک دستور جالب بیفایده است. سناریوهای دیگر به صورت زیر هستند:
اجرای ابزار CLI مربوط به Vue برای ایجاد اپلیکیشنهای جدید و اجرای آنها با دستور زیر:
npx vue create my-vue-app
ایجاد اپلیکیشن ریاکت جدید با استفاده از :create-react-app:
npx create-react-app my-react-app
و موارد بسیار دیگر؛ زمانی که آن را دانلود کنید، کد دانلود شده پاک میشود.
اجرای برخی کدها با نسخههای مختلف Node.js
با استفاده از @ میتوان اقدام به تعیین نسخه و ترکیب کردن آنها با پکیج npm در node کرد:
npx node@6 -v #v6.14.3 npx node@8 -v #v8.11.3
این وضعیت کمک میکند که دیگر از ابزارهایی مانند nvm یا دیگر ابزارهای مدیریت نسخه Node استفاده نکنیم.
اجرای مستقیم قطعه کدهای دلخواه از یک URL
npx شما را محدود به پکیجهای انتشار یافته روی رجیستری npm نمیکند. بدین ترتیب برای مثال میتوان کدی را که در یک gist گیتهاب قرار دارد اجرا کرد:
npx https://gist.github.com/zkat/4bc19503fe9e9309e2bfaa2c58074d32
البته هنگام اجرای کدی که روی آن کنترل ندارید، باید مراقب باشید چون چنان که میدانید قدرت زیاد نیاز به مسئولیتپذیری زیادی هم دارد. بدین ترتیب به پایان بخش پنجم از سری مقالات آموزش جامع Node.js رسیدیم و توضیحاتی که در مورد npm وجود داشت را به پایان بردیم. در بخش بعدی در مورد حلقهها، و تایمرها در
منبع: فرادرس
احراز هویت کاربر با React Native Navigation — راهنمای کاربردی
در بخش قبلی این مطلب در مورد کتابخانه React Native Navigation صحبت کردیم. در بخش دوم و پایانی این سری مقالات به بررسی روشهای احراز هویت کاربر به کمک این کتابخانه خواهیم پرداخت. برای مطالعه بخش قبلی به لینک زیر مراجعه کنید:
کار خود را از جایی که در بخش اول باقی مانده بود از سر میگیریم و اینک میخواهیم با استفاده از AWS یک بخش واقعی ثبت نام و ورود کاربر به اپلیکیشن بسازیم. بدین منظور از AWS Amplify برای اتصال به AWS و از Amazon Cognito برای مدیریت کاربران استفاده میکنیم. اگر کد بخش قبلی را نوشتهاید، میتوانید شروع به کار روی آن بکنید، اما اگر آن کد را ندارید میتوانید از این ریپو (+) استفاده کنید.
ایجاد سرویس Auth
از root پروژه ریاکت نیتیو آغاز میکنیم و یک پروژه جدید AWS را طوری مقداردهی میکنیم که بتوانیم احراز هویت را اضافه کنیم. به این منظور باید AWS Mobile CLI را نصب و پیکربندی کنیم:
npm i -g awsmobile-cli awsmobile configure
زمانی که CLI را نصب و پیکربندی کردید، یک پروژه جدید AWS را مقداردهی کنید:
awsmobile init
این دستور چند کار به شرح زیر انجام میدهد:
- یک پروژه جدید Mobile Hub در حساب AWS ما ایجاد میکند.
- چند وابستگی را به صورت aws-amplify و aws-amplify-react-native درون پروژه نصب میکند.
- فایلهای پیکربندی محلی با اسامی awsmobile.js و aws-exports.js اضافه میکند که امکان ویرایش محلی پیکربندی از طریق cli و ارسال تغییرات به پروژه Mobile Hub را در کنسول AWS فراهم میسازد.
سپس باید یک وابستگی نیتیو به پروژه React Native خود اضافه کنیم:
react-native link amazon-cognito-identity-js
اینک باید بخش ثبت نام کاربر را به پروژه AWS خود اضافه کنیم:
awsmobile user-signin enable
و آن را به کنسول AWS ارسال کنیم:
awsmobile user-signin enable
اکنون باید کارکرد ثبت نام کاربر ما فعال و آماده استفاده باشد. کل پروژه Mobile Hub را میتوان در حساب AWS با اجرای دستور awsmobile console از خط فرمان مشاهده کرد. همچنین میتوانید از کنسول Amazon Cognito بازدید کنید تا پیکربندی آن را ببینید.
نوشتن اپلیکیشن ریاکت نیتیو
اکنون که سرویس ایجاد شده است، باید اپلیکیشن را بهروزرسانی کنیم تا از آن استفاده کند. ابتدا باید فایل index.js را بهروزرسانی کنیم تا از پیکربندی موجود در فایل aws-exports.js استفاده کرده و با AWS Amplify کار کند.
فایل index.js
در فایل فوق کتابخانه Amplify و همچنین پیکربندی AWS را از aws-exports.js ایمپورت میکنیم و تابع Amplify.configure را فراخوانی کرده و پیکربندی را ارسال میکنیم. بدین ترتیب پروژه ریاکت نیتیو راهاندازی شده و امکان آغاز فراخوانی سرویس AWS را با استفاده از Amplify از هر کجا درون اپلیکیشن فراهم میسازد.
فایل SignUp.js
در فایل SignUp.js تابع signUp را بهروزرسانی میکنیم تا ثبت نام کاربر جدید را مدیریت کرده و یک تابع confirmSignUp جدید برای MFA بسازیم.
در این فایل SignUp.js دو فرم ابتدایی داریم که یکی برای ثبت نام کاربر جدید و دیگری برای تأیید ثبت نام با استفاده از MFA است. فرم تأیید ثبت نام به کاربر امکان میدهد که کد MFA خود را برای شناسایی این که این کد را دریافت کرده است وارد کند. ما این دو فرم را بر اساس مقدار بولی this.state.showConfirmationForm نمایش داده یا پنهان میکنیم که مقدار آن در متدهای کلاس signUp و confirmSignUp تعیین میشود.
متدهایی که برای ثبت نام و تأیید ثبت نام از AWS Amplify استفاده میکنیم، به ترتیب Auth.signUp و Auth.confirmSignUp نام دارند.
فایل SignIn.js
این فایل برای بهروزرسانی تابع signIn جهت مدیریت ثبت نام کاربر و ایجاد تابع جدید confirmSignIn برای MFA استفاده میشود.
فایل SignIn.js
منطق این کامپوننت بسیار مشابه آن چیزی است که در SignUp.js دیدیم و تنها یک تفاوت وجود دارد. زمانی که Auth.signIn را فراخوانی میکنیم، مقدار بازگشتی از فراخوانی متد را در حالت (State) خود ذخیره میکنیم تا بعدتر در Auth.confirmSignIn استفاده کنیم. زمانی که (Auth.confirmSignIn(user, confirmationCode را فراخوانی میکنیم، این شیء کاربر را همراه با کد احراز هویت دریافتی از MFA به آن ارسال میکنیم.
فایل Initializing.js
زمانی که کاربر وارد حساب خود در اپلیکیشن شد، میتوانیم از طریق فراخوانی کردن Auth.currentAuthenticatedUser اطلاعاتی در مورد کاربر بازیابی کنیم. اگر یک کاربر ثبت نام کرده باشد، این تابع موفق خواهد بود و میتوانیم اپلیکیشن اصلی را بارگذاری کنیم. اگر این رویه ناموفق باشد، میتوانیم مسیریابیهای احراز هویت یعنی SignIn و SignUp را بارگذاری کنیم.
برای پیادهسازی این وضعیت باید کامپوننت Auth را از AWS Amplify ایمپورت کرده و متد چرخه عمر componentDidMount را بهروزرسانی کنیم تا کاربر را بررسی کند:
برای مشاهده نسخه نهایی این کامپوننت به این لینک (+) مراجعه کنید.
فایل Home.js
آخرین کاری که باید انجام دهیم، بهروزرسانی دکمه SignOut است تا در زمان کلیک شدن، کاربر را عملاً از اپلیکیشن خارج کند. به این منظور میتوانیم دستگیره onPress را الحاق کنیم تا متد Auth.signOut را از AWS Amplify فراخوانی کند:
برای مشاهده نسخه نهایی این کامپوننت به این صفحه (+) مراجعه کنید.
سخن پایانی
راهاندازی و اجرای احراز هویت کاربر به کمک ترکیبی از Amazon Cognito و AWS Amplify کار واقعاً سرراستی محسوب میشود. تکنیکهایی که در این راهنما استفاده کردیم، به همراه کتابخانه React Native Navigation کار میکنند و البته با ارائهدهندگان خدمات احراز هویت دیگر نیز به خوبی اجرا خواهند شد.
وقتی از ناوبری در ریاکت نیتیو صحبت میکنیم، دو کتابخانه بسیار کارآمد وجود دارند که یکی React Navigation و دیگری React Native Navigation است. کتابخانه React Navigation نگهداری بسیار خوبی دارد و کاملاً به بلوغ رسیده است. این کتابخانه تقریباً هر چیزی را که بخواهید انجام میدهد و تیم نگهداری آن کار فوقالعادهای در رسیدگی به مشکلات و تبدیل کردن به یک کتابخانه درجه یک انجام دادهاند.
React Native Navigation نیز گزینه مناسبی محسوب میشود و از سوی تیم توسعهدهنده به خوبی نگهداری شده است. React Native Navigation نسخه 2 اخیراً وارد فاز آلفا شده و ممکن است برخی قابلیتها هنوز عرضه نشده باشند که در این مورد میتوانید issue بدهید یا درخواست pull کنید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای JavaScript (جاوا اسکریپت)
- آموزش مقدماتی فریمورک React Native
- مجموعه آموزشهای برنامهنویسی
- ساخت یک اپلیکیشن چند پلتفرمی موبایل با React Native (بخش اول) — به زبان ساده
- ساخت اپلیکیشن ساده آب و هوا با React Native و Expo — از صفر تا صد
==
منبع: فرادرس
گزاره switch..case در ++C — راهنمای کاربردی
در بخشهای قبلی (+) این سری مقالات آموزش زبان برنامهنویسی ++C با گزاره if..else..if آشنا شدیم که امکان اجرای یک قطعه کد را در میان گزینههای مختلف فراهم میسازد. با این حال اگر قصد دارید مقدار یک متغیر منفرد را با استفاده از گزارههای متوالی if..else..if بررسی کنید، بهتر است به جای آن از گزاره switch..case استفاده کنید. برای مطالعه بخش قبلی این سری ملاقات آموزشی زبان برنامهنویسی ++C به لینک زیر مراجعه کنید:
گزاره switch اگر نه همیشه، دستکم در اغلب موارد سریعتر از گزاره if…else است. ضمناً ساختار گزاره سوئیچ سادهتر و درک آن آسانتر است.
ساختار گزاره switch…case در زبان ++C
در شبه کد فوق تصور کنید مقدار n برابر با constant2 باشد. کامپایلر بلوک کدی را اجرا خواهد کرد با گزاره case مرتبط هستند تا این که به انتهای بلوک سوئیچ برسد یا با گزاره break مواجه شود. گزاره break برای جلوگیری از اجرای کد در case بعدی استفاده میشود.
فلوچارت گزاره switch
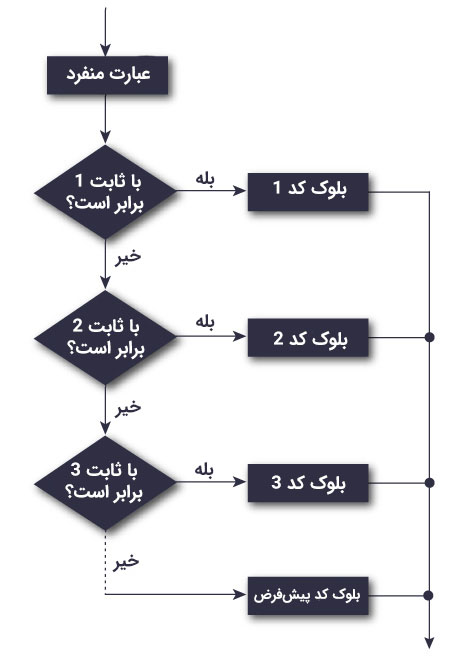
شکل فوق نشان میدهد که گزاره switch چگونه کار میکند و شرایط مختلف چگونه درون بند case سوئیچ بررسی میشوند.
مثالی از گزاره switch در ++C
Enter an operator (+, -, *, /): + - Enter two operands: 2.3 4.5 2.3 - 4.5 = -2.2
عملگر (-) که از سوی کاربر وارد میشود در متغیر 0 ذخیره میشود. دو عملوند 2.3 و 4.5 به ترتیب در متغیرهای num1 و num2 ذخیره میشوند. سپس کنترل برنامه به دستور زیر میرسد:
cout << num1 << " - " << num2 << " = " << num1-num2;
در نهایت گزاره break موجب اتمام گزاره switch میشود. اگر گزاره break استفاده نشود، همه case-های بعد از حالت صحیح نیز اجرا خواهند شد. برای مشاهده بخش بعدی این مطلب به لینک زیر رجوع کنید:
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند: