طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیشبکه بندی و ارتباط ها در اکوسیستم داکر — راهنمای جامع
زمانی که مشغول ساخت سیستمهای توزیع یافته برای عرضه کانتینرهای داکر هستیم، ارتباط و شبکهبندی بسیار حائز اهمیت است. معماری مبتنی بر سرویس به طرز غیر قابل انکاری روی ارتباط بین کامپوننتها برای کارکرد صحیح تکیه دارد.
در این راهنما به بررسی راهبردهای مختلف شبکهبندی و ابزارهای مورد استفاده برای قالببندی شبکههای مورد استفاده کانتینرها در حالتهای مطلوب میپردازیم. در برخی موقعیتها میتوان از مزیت راهحلهای بومی داکر استفاده کرد؛ در حالی که در برخی موقعیتهای دیگر باید از پروژههای جایگزین بهره جست.

پیادهسازی شبکهبندی بومی داکر
داکر، خود بسیاری از موارد ضروری برای ارتباط بین کانتینرها و ارتباط کانتینر با میزبان را ارائه کرده است.
زمانی که پروسس داکر اجرا میشود، یک رابط bridge مجازی جدید به نام docker0 روی سیستم میزبان، پیکربندی میکند. این رابط به داکر امکان تخصیص یک subnet مجازی برای استفاده میان کانتینرهای اجرا شونده میدهد. این بریج به عنوان نقطه اصلی رابط بین شبکهبندی درون کانتینر و شبکهبندی روی میزبان عمل میکند.
زمانی که یک کانتینر از سوی داکر آغاز میشود، یک رابط مجازی جدید ایجاد میشود و یک آدرس در محدوده subnet بریج به آن داده میشود. این آدرس IP به شبکهبندی داخلی کانتینر قلاب میشود و مسیری از شبکه کانتینر به بریج docker0 روی سیستم میزبان ارائه میدهد. داکر به طور خودکار قواعد iptables را طوری پیکربندی میکند که امکان فوروارد کردن و پیکربندی NAT masquerading برای ترافیک با مبدأ docekr0 و مقصد دنیای خارج را فراهم میسازد.
کانتینرها چگونه سرویسها را در دسترس مصرفکنندهها قرار میدهند؟
کانتینرهای مختلف روی یک میزبان، توانایی دسترسی به سرویسهای کانتینرهای همسایه را بدون هیچ گونه پیکربندی اضافی دارند. سیستم میزبان به سادگی درخواستهای با مبدأ و مقصد رابط docker0 را به موقعیت مناسب مسیریابی میکند.
کانتینرها میتوانند پورتهای خود را در معرض دسترسی میزبان قرار دهند و بدین ترتیب ترافیک فوروارد شده از دنیای بیرون را دریافت کنند. پورتهای باز را میتوان از طریق انتخاب کردن یک پورت خاص یا دادن حق انتخاب پورت با عدد بزرگ و استفاده نشده تصادفی، به داکر در عمل به سیستم میزبان نگاشت کرد. داکر مسائل مربوط به هر گونه قواعد فوروارد و پیکربندی iptables برای مسیریابی صحیح بستهها در چنین موقعیتهایی را بر عهده میگیرد.

تفاوت بین باز کردن (Exposing) و انتشار (Exposing) یک پورت چیست؟
زمانی که تصویرهای کانتینر ایجاد میشوند یا کانتینری اجرا میشود، این گزینه وجود دارد که پورتها باز شوند یا انتشار یابند. تفاوت این دو وضعیت حائز اهمیت است؛ اما ممکن است در نگاه اول قابل تشخیص نباشد.
باز کردن یک پورت صرفاً به این معنی است که داکر متوجه خواهد شد پورت مورد نظر از سوی کانتینر استفاده میشود. این پورت در موارد آتی میتواند به منظور کشف سرویس یا لینک کردن استفاده شود. برای نمونه بررسی یک کانتینر اطلاعاتی در مورد پورتهای باز شده آن میدهد. وقتی کانتینرها لینک میشوند، متغیرهای محیطی در کانتینر جدید طوری تنظیم میشوند که پورتهای باز شده در کانتینر دیگر را نشان دهند.
کانتینرها به طور پیشفرض از سوی سیستم میزبان و همچنین هر کانتینر دیگر روی میزبان، صرفنظر از این که پورتهای آن باز است یا نه، قابل دسترسی هستند. باز کردن پورت صرفاً ثبت استفاده از پورت است و اطلاعاتی را در مورد نگاشتهای خودکار و لینک شدنها ارائه میکند.
برخلاف باز کردن پورت، انتشار یک پورت باعث میشود که آن پورت به رابط سیستم میزبان نگاشت شود و از سوی دنیای خارج مورد دسترسی قرار گیرد. پورتهای کانتینرها را میتوان به یک پورت خاص روی میزبان نگاشت کرد یا این که داکر میتواند به طور خودکار یک عدد بزرگ تصادفی از میان پورتهای استفاده نشده انتخاب کند.

منظور از لینک داکر چیست؟
داکر سازوکاری به نام «لینکهای داکر» (Docker links) ارائه کرده است که برای پیکربندی ارتباط بین کانتینرها استفاده میشود. اگر یک کانتینر جدید به کانتینر موجود لینک شود، کانتینر جدید اطلاعات اتصال کانتینر موجود را از طریق متغیرهای محیطی دریافت میکند.
این یک روش آسان برای ایجاد ارتباط بین دو کانتینر است که از طریق ارائه اطلاعات کامل به کانتینر جدید در مورد شیوه دسترسی به همتای خود عمل میکند. متغیرهای محیطی بر اساس پورتهای باز شده از سوی کانتینر دیگر ثبت میشوند. آدرس IP و دیگر اطلاعات در خود داکر ثبت میشوند.
پروژههایی برای بسط قابلیتهای شبکهبندی داکر
مدل شبکهبندی مورد بررسی فوق، نقطه شروع خوبی برای ساخت شبکهبندی بین کانتینری محسوب میشود. ارتباط بین کانتینرها روی یک میزبان تقریباً سرراست است و ارتباط بین میزبانها نیز از طریق شبکهبندی معمولی صورت میگیرد و تا وقتی که نگاشت پورتها به طرز صحیحی اجرا میشود و اطلاعات اتصال نیز به طرف دیگر ارائه میشود، همه چیز سرراست است.
با این وجود، بسیاری از اپلیکیشنها نیازمند شرایط شبکهبندی خاصی به منظور تأمین امنیت یا کارکردهای خاص خود هستند. کارکردهای شبکهبندی بومی داکر تا حدودی در این زمینهها محدود هستند. به همین دلیل پروژههای زیادی برای بسط اکوسیستم شبکهبندی داکر ایجاد شدهاند.
ایجاد شبکههای Overlay برای انتزاع توپولوژی زیرساختی
یک بهبود کارکردی که چند پروژه بر روی آن متمرکز شدهاند، ایجاد شبکههای overlay است. یک شبکه overlay در واقع شبکهای مجازی است که روی اتصالهای شبکه موجود ساخته میشود.
ایجاد شبکههای overlay، امکان ساخت محیطهای شبکهبندی با پیشبینی پذیری بالاتر و منسجمتر را روی میزبانهای مختلف فراهم میسازد. بدین ترتیب شبکهبندی بین کانتینرها صرفنظر از این که کجا اجرا میشوند سادهتر میشود. یک شبکه مجازی میتواند روی چندین میزبان گسترش یابد یا sunbet های خاصی به هر میزبان درون یک شبکه منسجم اختصاص یابد.
کاربرد دیگر شبکه overlay در ساخت کلاسترهای محاسباتی Fabric است. در محاسبات Fabric چند میزبان انتزاع مییابند و به صورت یک واحد منفرد و قویتر مدیریت میشوند. پیادهسازی لایه محاسبات Fabric به کاربر نهایی امکان میدهد که کلاستر را به جای میزبانهای منفرد، به صورت یک کل واحد مدیریت کند. شبکهبندی بخش عمدهای از این کلاسترینگ را تشکیل میدهد.
پیکربندی پیشرفته شبکهبندی
پروژههای دیگری نیز برای بسط قابلیتهای شبکهبندی داکر و ایجاد انعطافپذیری بیشتر ایجاد شدهاند.
پیکربندی پیشفرض برای شبکهبندی داکر کاملاً کاربردی است؛ اما تا حدود زیادی ساده محسوب میشود. این محدودیتها زمانی که با شبکهبندی چند پلتفرمی سروکار داریم خود را به طور کامل نشان میدهند؛ اما با این حال میتوانند با اغلب الزامات شبکهبندی سفارشی روی یک میزبان منفرد سازگار باشند.
کارکردهای بیشتر از طریق قابلیتهای «لولهکشی» (plumbing) اضافی ارائه میشوند. این پروژهها پیکربندیهای کاملاً آماده استفادهای ارائه نمیدهند؛ بلکه امکان اتصال بخشهای منفرد به هم و ایجاد سناریوهای مورد نیاز برای شبکههای پیچیده را فراهم میسازند. قابلیتهایی که به این ترتیب میتوان به دست آورد، از ایجاد شبکهبندی خصوصی بین میزبانهای خاص تا پیکربندی bridge ها، vlan ها و subnet ها و گیتویها متفاوت هستند.
ابزارها و پروژههای دیگری نیز وجود دارند که از ابتدا برای داکر توسعه نیافتهاند؛ اما غالباً در محیط داکر برای تأمین کارکردهای مورد نیاز استفاده میشوند. به طور خاص ارتباط شبکهبندی خصوصی کامل و فناوریهای تونلبندی غالباً برای ایجاد ارتباط امن بین میزبانها و میان کانتینرها استفاده میشود.

پروژههای رایج برای بهبود شبکهبندی داکر
چند پروژه هستند که روی شبکهبندی overlay برای میزبانهای داکر متمرکز شدهاند. انواع رایجتر به شرح زیر هستند:
- Flannel – از سوی تیم CoreOS توسعه یافته است. این پروژه در ابتدا برای ارائه subnet اختصاصی به هر میزبان از یک شبکه مشترک طراحی شده است. این شرایطی است که برای کارکرد ابزار هماهنگی kubernetes گوگل ضروری محسوب میشود؛ اما در موقعیتهای دیگر نیز مفید است.
- Weave – یک شبکه مجازی ایجاد میکند که هر یک از سرورهای میزبان را به همدیگر اتصال میدهد. این امر موجب سادهتر شدن مسیریابی میشود، زیرا در ظاهر هر کانتینر به یک سوئیچ شبکه منفرد اتصال یافته است.
- پروژههای زیر برحسب شبکهبندی پیشرفته با هدف پر کردن موارد ناقص با استفاده از اتصالهای اضافی ارائه شدهاند:
- pipework – به عنوان یک پروژه موقت تا زمانی که شبکهبندی بومی داکر پیشرفتهتر شود، ارائه شده است و امکان پیکربندی ساده پیکربندیهای سفارشی و پیشرفته شبکهبندی داکر را فراهم میسازد.
- یک نمونه مرتبط از نرمافزارهای از قبل موجود که برای بهبود کارکردهای داکر نیز استفاده میشود tinc است:
- tinc – یک نرمافزار VPN سبک است که با استفاده از تونلها و رمزنگاری پیادهسازی شده است. tinc راهحلی پایدار است که شبکه خصوصی را در معرض دید همه اپلیکیشنها قرار میدهد.
سخن پایانی
ارائه سرویسهای داخلی و خارجی از طریق کامپوننتهای کانتینرشده مدلی بسیار قدرتمند است؛ اما پیکربندیهای چنین شبکههایی یک اولویت محسوب میشود. با این که داکر برخی از این کارکردها را به طور بومی از طریق پیکربندی رابطهای مجازی، ایجاد subnet ها، iptables و مدیریت جدول NAT ارائه میکند؛ اما پروژههای دیگری نیز برای ارائه پیکربندیهای پیشرفتهتر طراحی شدهاند.
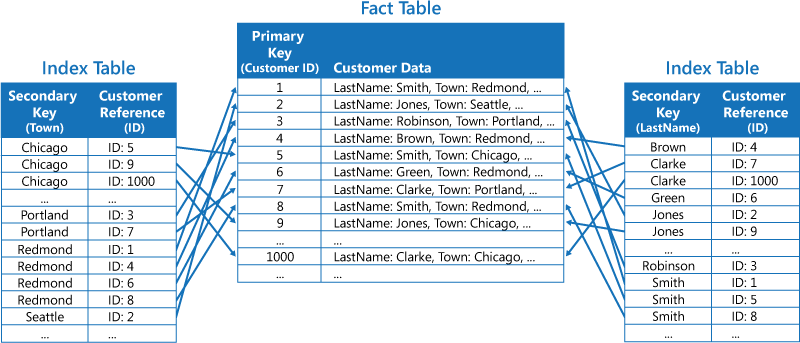
اندیس ها در MySQL — راهنمای جامع
منظور از اندیس در پایگاه داده ساختاری است که باعث بهبود سرعت عملیاتها در یک جدول میشود. اندیسها را میتوان با استفاده از یک یا چند ستون ایجاد کرد و مبنایی برای جستجوی تصادفی سریع و مرتبسازی بهینه دسترسی به رکوردها تشکیل داد.
هنگام ایجاد اندیس باید این نکته را در نظر داشت که کدام ستونها برای ایجاد کوئریهای SQL بیشتر مورد استفاده قرار میگیرند و یک یا چند اندیس روی این ستونها تشکیل داد.
از لحاظ عملی اندیسها نیز نوعی جدول محسوب میشوند که کلید ابتدایی (primary key) یا فیلد اندیس را در خود جای دادهاند و به هر یک از رکوردهای داخل جدول واقعی اشاره میکنند.
کاربران نمیتوانند اندیسها را ببینند. اندیسها از سوی موتور جستجوی پایگاه داده صرفاً برای افزایش سرعت اجرای کوئریها و یافتن بسیار سریعتر رکوردها استفاده میشوند.
عبارتهای INSERT و UPDATE روی جدولهایی که حاوی اندیس هستند، زمان بیشتری طول میکشند؛ در حالی که عبارت SELECT روی این جدولها سریعتر اجرا میشود. دلیل این مسئله آن است که هنگام درج یا بهروزرسانی فیلدها، پایگاه داده باید مقادیر اندیس را نیز درج یا بهروزرسانی کند.

اندیس ساده و یکتا
شما میتوانید یک اندیس یکتا روی یک جدول ایجاد کنید. منظور از اندیس یکتا این است که دو ردیف نمیتوانند مقدار اندیس مشابهی داشته باشند. در ادامه طرز ایجاد یک اندیس روی جدول را میبینید:
CREATE UNIQUE INDEX index_name ON table_name (column1, column2,...);
شما میتوانید از یک یا چند ستون برای ایجاد یک اندیس استفاده کنید.
برای مثال ما یک اندیس را روی tutorials_tbl با استفاده از tutorial_author ایجاد میکنیم:
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author)
شما میتوانید یک اندیس ساده را روی یک جدول ایجاد کنید. کافی است کلیدواژه UNIQUE را از کوئری حذف کنید تا یک اندیس ساده ایجاد شود. یک اندی ساده امکان کپی کردن مقادیر یک جدول را ایجاد میکند.
اگر بخواهید مقادیر موجود در یک ستون را به ترتیب نزولی اندیسگذاری کنید، میتوانید از کلیدواژه DESC پس از نام ستون استفاده کنید.
mysql> CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author DESC)
دستور ALTER برای افزودن یا حذف یک اندیس
چهار نوع عبارت برای افزودن اندیس به یک جدول وجود دارد:
- (ALTER TABLE tbl_name ADD PRIMARY KEY (column_list – این عبارت یک PRIMARY KEY اضافه میکند که به این معنی است که مقادیر اندیس شده باید یکتا و غیر NULL باشند.
- (ALTER TABLE tbl_name ADD UNIQUE index_name (column_list – این عبارت یک اندیس ایجاد میکند که مقادیر آن باید یکتا باشند (به استثنای مقادیر NULL که میتوانند تکرار شده باشند)
- (ALTER TABLE tbl_name ADD INDEX index_name (column_list – این عبارت یک اندیس معمولی اضافه میکند که در آن مقادیر مختلف میتوانند بیش از یک بار وجود داشته باشند.
- (ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list – این عبارت یک اندیس FULLTEXT خاص ایجاد میکند که به منظور جستجوهای متنی مورد استفاده قرار میگیرد.
در ادامه قطعه کدی ارائه شده است که مثالی برای افزودن اندیس به یک جدول موجود است:
mysql> ALTER TABLE testalter_tbl ADD INDEX (c);
شما میتوانید هر اندیس را با استفاده از بند DROP به همراه دستور ALTER حذف کنید. مثال زیر برای حذف اندیسی استفاده میشود که در بخش قبل ایجاد کردیم.
mysql> ALTER TABLE testalter_tbl DROP INDEX (c);
شما میتوانید هر اندیس را با استفاده از بند DROP به همراه دستور ALTER حذف نمایید
دستور ALTER برای افزودن یا حذف PRIMARY KEY
شما میتوانید کلید ابتدایی را نیز به همین ترتیب به جدول اضافه کنید؛ اما ابتدا باید اطمینان حاصل کنید که کلید ابتدایی روی ستونها که NULL نیستند نیز کار میکند.
در قطعه کد زیر مثالی از روش افزودن کلید ابتدایی به یک جدول موجود نمایش یافته است. در این مثال ابتدا یک ستون غیر NULL ایجاد میشود و سپس یک کلید ابتدایی به آن اضافه میگردد.
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);
شما میتوانید از دستور ALTER برای حذف کلید ابتدایی به صورت زیر استفاده کنید:
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;
برای حذف اندیسی که کلید ابتدایی نیست، باید نام اندیس را ذکر کنید.
نمایش اطلاعات اندیس
از دستور SHOW INDEX میتوان برای نمایش فهرستی از همه اندیسهای مرتبط با یک جدول استفاده کرد. خروجی با قالببندی عمودی (که با G تعیین میشود) غالباً در این عبارت مفید است، چون از چندپاره شدن خطوط جلوگیری میکند. مثال زیر را بررسی کنید:
mysql> SHOW INDEX FROM table_name\G ........
منبع: فرادرس
مشخصات سیستم عامل — راهنمای جامع
هر سیستم عاملی صرف نظر از نوع آن، به طور کلی برخی مشخصات کلی دارد که در این نوشته به بررسی تک تک این مشخصات سیستم عامل میپردازیم.
پردازش دستهای
پردازش دستهای تکنیکی است که سیستم عامل به وسیله آن برنامهها و دادهها را پیش از پردازش در یک دسته گردآوری میکند. یک سیستم عامل فعالیتهای زیر را در ارتباط با پردازش دستهای انجام میدهد:
- سیستم عامل یک وظیفه تعریف میکند که توالی از پیش تعریفشدهای از دستورها، برنامهها و دادهها را به عنوان یک واحد منفرد دارد.
- سیستم عامل تعدادی از وظایف را در حافظه نگهداری میکند و آنها را بدون ورود هر گونه اطلاعات دستی اجرا میکند.
- این وظیفهها به ترتیب تحویل پردازش میشوند، یعنی اول وظیفهای که در ابتدای صف قرار دارد پردازش میشود.
- زمانی که یک وظیفه خاتمه یافت، حافظه مربوط به آن آزاد میشود و خروجی وظیفه در یک spool خروجی قرار میگیرد تا بعداً پرینت شده یا پردازش شود.

مزایا
- پردازشهای دستهای بسیاری از وظایفت اپراتور رایانه را به خود رایانه انتقال میدهند.
- عملکرد کاری افزایش مییابد، زیرا یک وظیفه جدید به محض این که وظیفه قبلی پایان یافت اجرا میشود و هیچ مداخله دستی لازم نیست.
معایب
- دیباگ کردن برنامهها دشوار است
- یک وظیفه میتواند وارد حلقه بیانتها شود.
- به دلیل فقدان طرح حفاظتی، یک وظیفه دستهای میتواند بر روی وظایف در صف انتظار، تأثیر بگذارد.
چند وظیفگی
چند وظیفگی (Multitasking) به حالتی گفته میشود که چند وظیفه به طور همزمان از سوی CPU اجرا شوند. سوئیچ بین این وظیفهها ممکن است آن قدر سریع رخ دهد که کاربر متوجه نشود و همزمان با برنامه در حال اجرا ارتباط داشته باشد. سیستم عامل فعالیتهای زیر را در خصوص چندوظیفگی انجام میدهد:
- کاربر دستورالعملها را به سیستم عامل یا مستقیماً به یک برنامه میدهد و پاسخی بیدرنگ دریافت میکند.
- سیستم عامل چندوظیفگی را به روشی اجرا میکند که میتواند چندین برنامه را همزمان عملیاتی/اجرایی کند.
- سیستمهای عامل با خصوصیت چندوظیفگی به نام سیستمهای اشتراک زمانی نیز شناخته میشوند.
- این سیستمهای چندوظیفگی به منظور ایجاد امکان استفاده تعاملی از یک رایانه با هزینهای معقول طراحی شدهاند.
- سیستمهای عامل اشتراک زمانی از مفهوم زمانبندی CPU و چند برنامگی برای ارائه بخش کوچکی از زمان اشتراکی CPU به هر کاربر استفاده میکنند.
- هر کاربر دست کم یک برنامه مستقل در حافظه دارد.
- برنامهای که در حافظه بارگذاری شده و در حال اجرا است، معمولاً به نام process نامیده میشود.
- زمانی که یک پروسس اجرا میشود، به طور معمول در طی زمان کوتاهی یا باید پایان یابد و یا یک عملیات I/O اجرا کند.
- از آنجا که عملیات I/O معمولاً با سرعتهای پایینتری اجرا میشود، زمانی طول میکشد تا پایان یابد. در طی این زمان CPU میتواند به پروسسهای دیگر برسد.
- سیستم عامل به کاربران اجازه میدهد که از رایانه به طور همزمان و مشترک استفاده کنند. از آنجا که هر اقدام یا دستور در سیستم اشتراک زمانی باید کوتاه باشد، تنها زمان اندکی از CPU برای هر کاربر مورد نیاز است.
- به دلیل این که سیستم به سرعت CPU را از یک برنامه یا کاربر به برنامه یا کاربر بعدی سوئیچ میکند، هر کاربر تصور میکند که یک CPU اختصاصی برای خود دارد؛ در حالی که در عمل یک CPU در میان کاربران و برنامههای مختلف به اشتراک گذارده شده است.
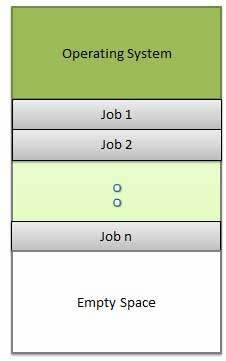
چند برنامگی
اشتراک پردازنده وقتی یک یا دو برنامه در حافظه به طور همزمان وجود داشته باشند، به نام چند برنامگی (multiprogramming) نامیده میشود. در چندبرنامگی تصور میشود که یک پردازنده مشترک منفرد وجود دارد. چند برنامگی موجب افزایش استفاده از CPU از طریق سازماندهی وظایف میشود به طوری که CPU همواره کاری برای اجرا داشته باشد.
در شکل زیر وضعیت حافظه در یک سیستم چند برنامگی نمایش یافته است.
سیستم عامل فعالیتهای زیر را در خصوص چندبرنامگی اجرا میکند:
- سیستم عامل چندوظیفه را همزمان در حافظه نگهداری میکند.
- این مجموعه وظایف زیرمجموعهای از وظایفی هستند که در استخر (pool) وظایف قرار دارند.
- سیستم عامل یک به یک این وظایف را از حافظه برداشته و اجرا میکند.
- سیستمهای عامل چند برنامگی وضعیت همه برنامهها و منابع سیستم را با استفاده از برنامههای مدیریت حافظه رصد و کنترل میکنند تا مطمئن شوند که CPU هرگز بیکار نمیماند؛ مگر این که پروسسی برای اجرا وجود نداشته باشد.
مزایا
- استفاده بالا و مؤثر از CPU
- کاربر حس میکند که برنامهها تقریباً به طور همزمان از CPU استفاده میکنند.
معایب
- به زمانبندی CPU نیاز داریم
- برای گنجاندن وظایف زیاد در حافظه به مدیریت حافظه نیاز داریم.
تعاملپذیری
منظور از تعاملپذیری توانایی کاربران برای برقراری ارتباط با سیستم رایانهای است. سیستم عامل فعالیتهای زیر را در خصوص تعاملپذیری انجام میدهد:
- رابطی در اختیار کاربر قرار میدهد تا با سیستم تعامل کند.
- دستگاههای ورودی مانند کیبورد را مدیریت کرده و ورودیهای کاربر را دریافت میکند.
- دستگاههای خروجی مانند نمایشگر را مدیریت کرده و خروجی مناسب را به کاربر نمایش میدهد.
زمان پاسخدهی سیستم عامل باید کوتاه باشد، چون کاربر وظیفهای را تحویل داده و منتظر نتیجه است.
سیستم همزمان
سیستمهای همزمان معمولاً سیستمهای اختصاصی و توکار هستند. سیستم عامل فعالیتهای زیر را در خصوص سیستمهای همزمان انجام میدهد:
- در چنین سیستمهایی، سیستم عامل معمولاً اطلاعات را از دادههای سنسور خوانده و واکنش نشان میدهد.
- سیستم عامل باید پاسخ به رویدادها را در محدوده زمانی ثابتی تضمین کند تا عملکرد صحیحی صورت بپذیرد.
محیط توزیع یافته
منظور از یک محیط توزیع یافته، CPU ها یا پردازندههای مستقل چندگانهای در یک سیستم رایانهای هستند. یک سیستم عامل فعالیتهای زیر را در خصوص محیط توزیع یافته انجام میدهد:
- سیستم عامل منطق محاسباتی را میان چند پردازنده فیزیکی توزیع میکند.
- پردازندهها حافظه یا ساعت مشترکی ندارند. به جای آن هر پردازنده حافظه محلی خاص خود را دارد.
- سیستم عامل ارتباط بین پردازنده را مدیریت میکند. این پردازندهها از طریق خطوط ارتباطی مختلف با هم ارتباط برقرار میکنند.
Spooling
Spool اختصاری برای عبارت «عملیات جانبی همزمان روی خط» (simultaneous peripheral operations on line) است. منظور از اسپول کردن، قرار دادن دادههای وظایف مختلف ورودی/خروجی در یک بافر است. این بافر ناحیه خاصی از حافظه روی هارددیسک است که دستگاههای ورودی/خروجی به آن دسترسی دارند.
سیستم عامل فعالیتهای زیر را در خصوص محیط توزیع یافته انجام میدهد:
- دادههای دستگاههای ورودی/خروجی را مدیریت میکند، چون این دستگاهها نرخهای دسترسی متفاوتی دارند.
- سیستم عامل بافرِ اسپولینگ را نگهداری میکند. این بافر ایستگاه انتظاری برای دادهها است تا زمانی که دستگاههای کندتر هنوز دادههای خود را ارسال نکردهاند، منتظر بمانند.
- محاسبات موازی را اجرا میکند، چون در طی فرایند اسپول کردن، یک رایانه میتواند وظایف ورودی/خروجی دیگری را به صورت موازی اجرا کند. بدین ترتیب این امکان پدید میآید که رایانه دادهها را از یک نوار بخواند، آنها را روی یک دیسک یا روی یک پرینتر نوار مغناطیسی بنویسد و همزمان وظایف محاسباتی خود را نیز اجرا کند.

مزایا
- عملیات اسپول کردن از دیسک به عنوان یک بافر بسیار بزرگ استفاده میکند.
- اسپول کردن امکان همپوشانی عملیات ورودی/خروجی را برای
- منبع: فرادرس
راه اندازی اولیه سرورهای اوبونتو ۱۸.۰۴ — از صفر تا صد
زمانی که یک سرور جدید اوبونتو 18.04 را میخواهید راه اندازی اولیه کنید، چند گام پیکربندی وجود دارند که باید به منظور تنظیم اولیه طی کنید. بدین ترتیب امنیت و قابلیت استفاده از سرور افزایش مییابد و مبنای استواری برای اقدامات بعدی پدید میآید.
گام اول – ورود به عنوان root
برای ورود به سرور باید آدرس IP عمومی سرور را بدانید. همچنین باید رمز عبور را نیز بدانید. اگر کلید SSH را برای احراز هویت نصب کردهاید، به جای رمز عبور میتوانید از کلید خصوصی حساب کاربری root کنید. اگر تاکنون وارد سرور نشده باشید، میتوانید با استفاده از دستور زیر وارد حساب کاربری root بشوید. دقت کنید که باید بخش هایلایت شده دستور را با آدرس IP عمومی سرور خود جایگزین کنید:
ssh root@your_server_ipهشداری که در مورد احراز هویت میزبان ارائه میشود را بپذیرید. اگر از رمز عبور برای احراز هویت استفاده میکنید، باید رمز عبور root را برای ورود به حساب خود وارد نمایید. اگر از کلید SSH استفاده میکنید که از حفاظت «عبارت رمزی» (passphrase) برخوردار است، برای احراز هویت استفاده میکنید، باید این عبارت رمزی را نخستین باری که در هر نشست از کلیدتان استفاده میکنید وارد نمایید. اگر نخستین باری است که با یک روز عبور وارد سرور خود میشوید، همچنین ممکن است از شما تقاضا شود که رمز عبور root را تغییر دهید.
کاربر root
کاربر root همان کاربر مدیر در محیط لینوکس محسوب میشود و دسترسیهای بسیار گستردهای دارد و به دلیل همین دسترسیهای گسترده حساب کاربریِ root معمولاً توصیه میشود که در کاربردهای روزمره از این حساب استفاده نشود. بخشی از دلیل این مسئله آن است که قدرت موجود در حساب کاربری root موجب میشود که افراد خرابکار بتوانند از آن برای ایجاد تغییرات مخرب استفاده کند و یا حتی برخی تغییرات مخرب به طور ناخواسته ایجاد شوند.
در گام بعدی روش ایجاد یک حساب کاربری با حیطه نفوذ پایینتر برای کارهای روزمره معرفی میشود. روش کسب دسترسیهای خاص در موارد نیاز هم آموزش داده خواهد شد.
گام دوم – ایجاد یک کاربر جدید
زمانی که وارد حساب کاربری root شدید، آماده هستید که یک حساب کاربری جدید بسازید که از این پس از آن برای ورود به سرور استفاده خواهید کرد. در دستور زیر یک کاربر جدید به نام Sammy ایجاد میشود. اما شما باید نام کاربری که خودتان قصد دارید استفاده کنید را جایگزین نمایید:
adduser Sammyاز شما چند سؤال پرسیده میشود که اولین مورد به رمز عبور این حساب مربوط است. یک رمز عبور قوی وارد کنید. پر کردن اطلاعات دیگر اختیاری است و میتوانید با زدن دکمه اینتر از فیلدهایی که نمیخواهید پر کنید رد شوید.
گام سوم – کسب دسترسیهای مدیریتی
اینک ما یک حساب کاربری جدید داریم که دسترسیهای معمولی دارد. با این حال، گاهی اوقات ممکن است لازم باشد وظایفی را اجرا کنیم که به دسترسیهای مدیریت نیاز دارد. برای این که در چنین مواردی لازم نباشد از حساب کاربری معمولی خود خارج شویم و دوباره وارد حساب کاربری root شویم، میتوانیم چیزی به نام superuser تنظیم کنیم که دسترسیهای root را به حساب کاربری ما اضافه میکند. بدین ترتیب کاربر معمولی ما میتواند با اشاره به کلیدواژه sudo در ابتدای دستورات خود، دستورهایی را که در حیطه اختیارات کاربر مدیر است اجرا کند.
برای افزودن آن دسترسیها به کاربر جدید باید این کاربر را به گروه sudo اضافه کنیم. در اوبونتو 18.04، به طور پیشفرض کاربران به گروه sudo تعلق دارند و اجازه استفاده از دستورهای sudo را دارند. به عنوان کاربر root دستور زیر را اضافه کنید تا کاربر جدید به گروه sudo اضافه شود (کلمه هایلایت شده زیر را با کاربر جدید جایگزین کنید):
usermod -aG sudo Sammyاینک اگر به عنوان کاربر معمولی وارد شده باشید، میتوانید از ذکر کلیدواژه sudo پیش از دستورها برای اجرای اقدامهایی که به دسترسیهای مدیریتی نیاز دارند استفاده کنید.
گام چهارم – راهاندازی اولیه فایروال
سرورهای اوبونتو 18.04 میتوانند از فایروال UFW برای اطمینان یافتن از این که اتصالها تنها به سرویسهای خاص مجاز است استفاده کنند. با استفاده از این اپلیکیشن میتوان یک فایروال بسیار ابتدایی راهاندازی کرد. اپلیکیشنهای مختلف میتوانند پروفایل دسترسیهای مورد نیاز خود را هنگام نصب در UFW ثبت کنند. UFW از این پروفایلها برای مدیریت اپلیکیشنها با استفاده از نامهایشان استفاده میکند. OpenSSH سرویسی است که به شما امکان میدهد به سرور خود وصل شوید و پروفایل خود را در UFW ثبت کرده است. این وضعیت را با اجرای دستور زیر میتواند مشاهده کنید:
ufw app list
خروجی
Available applications: OpenSSH
باید اطمینان حاصل کنیم که فایروال امکان اتصال SSH را میدهد تا بتوانید دفعه بعد هم وارد سرور شوید. با اجرای دستور زیر این اتصالها مجاز خواهند شد:
ufw allow OpenSSH
پس از آن میتوانیم فایروال را با اجرای دستور زیر فعال کنیم:
ufw enable
حرف y را وارد کرده و اینتر را بزنید تا ببینید که اتصالهای SSH همچنان مجاز هستند:
ufw status
خروجی
Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6))
از آنجا که فایروال هم اینک همه اتصالها را به جز SSH مسدود ساخته است، اگر سرویسهای دیگر را نصب و پیکربندی کنید باید تنظیمات فایروال را بهروزرسانی کنید تا امکان ورود ترافیک برای آن سرویسها وجود داشته باشد.
گام پنجم – فعالسازی دسترسیهای بیرونی برای کاربر معمولی
اینک که کاربر معمولی را برای کاربردهای روزانه پیکربندی کردیم، باید مطمئن شویم که میتوانیم مستقیماً با استفاده از SSH وارد اکانت خود شویم. توصیه میکنیم تا زمانی که مطمئن نشدهاید میتوانید وارد حساب کاربری جدید شده و از sudo استفاده کنید، از حساب root خارج نشوید، چون بدین ترتیب میتوانید عیبیابی کرده و تغییرات ضروری را با حساب کاربری root صورت دهید. فرایند پیکربندی دسترسی SSH برای کاربر جدید به این نکته وابسته است که حساب کاربری root در سرور از کدام یک از گزینههای رمز عبور یا کلیدهای SSH برای احراز هویت استفاده میکند.
اگر حساب root از رمز عبور برای احراز هویت استفاده میکند
اگر با استفاده از یک رمز عبور وارد حساب کاربری root شدهاید، در این صورت برای SSH رمز عبور فعال شده است. شما میتوانید با باز کردن یک پنجره ترمینال جدید و استفاده از SSH با نام کاربری جدید وارد حساب کاربری جدید خود شوید:
ssh sammy@your_server_ipپس از وارد کردن رمز عبور کاربر جدید، وارد این حساب خواهید شد. به خاطر داشته باشید که اگر لازم است دستوری را با دسترسیهای مدیریت اجرا کنید، باید در ابتدای آن از کلیدواژه sudo استفاده کنید:
sudo command_to_runاز شما خواسته میشود که رمز عبور کاربر معمولی خود را هنگام استفاده از sudo برای نخستین بار در هر نشست وارد کنید. برای بهبود امنیت سرور قویاً توصیه میکنیم که از کلیدهای SSH به جای احراز هویت به روش رمز عبور استفاده کنید. بدین منظور میتوانید از «آموزش مقدماتی مدیریت سرور لینوکس» بهره بگیرید.
اگر حساب root از کلیدهای SSH برای احراز هویت استفاده میکند
اگر با استفاده از کلیدهای SSH وارد حساب کاربری root خود شدهاید، در این صورت احراز هویت به روش رمز عبور برای SSH غیرفعال شده است. شما باید یک کپی از کلید عمومی محلی خود را به فایل ssh/authorized_keys./~ اضافه کنید تا بتوانید با موفقیت وارد سرور شوید. از آنجا که کلید عمومی از قبل در فایل ssh/authorized_keys./~ روی سرور قرار گرفته است، میتوانیم این فایل و ساختار دایرکتوری را در همین نشست موجود به کاربر جدید کپی کنیم.
سادهترین روش برای کپی فایلها با مالکیت و مجوزهای صحیح استفاده از دستور rsync است. این دستور دایرکتوری کاربر root را با حفظ مجوزها و اصلاح مالکان کپی میکند و همه این کارها صرفاً در یک دستور صورت میگیرد. اطمینان حاصل کنید که بخش هایلایت شده در دستور زیر با نام کاربری جدید شما جایگزین شده است:
rsync --archive --chown=sammy:sammy ~/.ssh /home/Sammy
دقت کنید که آدرس مبدأ و مقصد در دستور rsync وقتی اسلش (/) انتهایی را قید میکنید با وضعیتی که این / وجود نداشته باشد متفاوت خواهد بود. زمانی که از rsync استفاده میکنید، مطمئن شوید که دایرکتوری مبدأ (ssh./~) شامل اسلش انتهایی نیست؛ یعنی نباید به صورت /ssh./~ باشد.
اگر تصادفاً اسلش به انتهای آدرس مبدأ اضافه شده باشد، دستور rsync به جای این که کل ساختار دایرکتوری ssh./~ را کپی کند، صرفاً محتوای دایرکتوری ssh./~ حساب root را به دایرکتوری home کاربر sudo کپی خواهد کرد. بدین ترتیب فایلها در مکان نادرستی قرار میگیرند و SSH نمیتواند آنها را یافته و مورد استفاده قرار دهد. اینک میتوانید یک ترمینال جدید باز کید و از SSH با استفاده از نام کاربری جدید برای ورود به سرور استفاده کنید:
ssh sammy@your_server_ip
اینک میتوانید بدون وارد کردن رمز عبور وارد حساب کاربری جدید خود بشوید. به خاطر داشته باشید که اگر لازم باشد دستوری را با دسترسیهای مدیریت اجرا کنید باید پیش از آن عبارت sudo را وارد کنید:
sudo command_to_runدر این صورت از شما خواسته میشود که رمز عبور sudo را هنگام استفاده برای اولین بار در هر نشست وارد کنید و به طور دورهای نیز در مواد آتی این رمز عبور پرسیده میشود. اینک شما توانستهاید سرور خود را به طور اصولی راهاندازی کنید و میتوانید هر گونه نرمافزار دیگری که برای آن لازم دارید را نصب کنید.
منیع: فرادرس
CPU چگونه کار می کند؟ — به زبان ساده
درک کارکرد اغلب قطعات رایانه مانند RAM، دیسک ذخیرهسازی، وسایل جانبی و همچنین نرمافزارهایی که در مجموع به کارکرد صحیح رایانه کمک میکنند، کار سادهای است. اما قلب هر سیستم رایانهای CPU است که حتی از نظر بسیاری از کارشناسان رایانه نیز به عنوان قطعهای جادویی نگریسته میشود. در این نوشته تلاش میکنیم کارکرد این جزء رایانه را توصیف کنیم.

نکتهای که پیش از آغاز این مقاله باید در خاطر داشته باشیم این است که اغلب CPU های مدرن از نظر اندازه بزرگی، بسیار پیچیدهتر از مواردی هستند که در این نوشته بررسی خواهیم کرد. در واقع درک همه بخشهای یک تراشه با بیش از یک میلیارد ترانزیستور برای هر فردی ناممکن است. با این وجود، مفاهیم مقدماتی در مورد هماهنگی همه بخشهای یک CPU در مورد همه CPU ها یکسان است و درک این مقدمات باعث میشود که درک بهتری از CPU های مدرن نیز به دست بیاورید.
آغاز از موارد کوچک

کارکرد رایانهها به روش دودویی یا باینری است. رایانهها فقط دو حالت را درک میکنند، روشن و خاموش. آنها برای اجرای محاسبات به زبان باینری از قطعهای به نام ترانزیستور استفاده میکنند. ترانزیستور تنها در صورتی اجازه عبور جریان منبع از خود را میدهد که روی گیت آن جریانی اعمال شده باشد. این وضعیت اساس یک سوئیچ باینری را تشکیل میدهد که بسته به سیگنال ورودی ثانویه، اتصال را قطع میکند.
رایانههای مدرن از میلیاردها ترانزیستور برای اجرای محاسبات خود استفاده میکنند؛ اما در پایینترین سطح شما تنها به تعداد معدودی از ترانزیستورها برای تشکیل ابتداییترین اجزا که گیت (gate) نامیده میشوند نیاز دارید.
گیتهای منطقی

با گرد هم آوردن صحیح چند ترانزیستور میتوان یک گیت منطقی ساخت. گیتهای منطقی دو ورودی باینری میگیرند و با اجرای یک عملیات روی آنها، مقدار خروجی را بازگشت میدهند. برای مثال، گیت OR در صورتی مقدار True بازمیگرداند که یکی از ورودهایش true باشد. گیت AND بررسی میکند که آیا هر دو ورودی true هستند یا نه و XOR نیز زمانی مقدار true بازمیگرداند که یکی از ورودیهایش true باشند. نسخههای N این گیتهای منطقی (یعنی NOR، NAND و XNOR)، نمونههای معکوس این گیتهای مقدماتی هستند.
محاسبات ریاضی با استفاده از گیتها
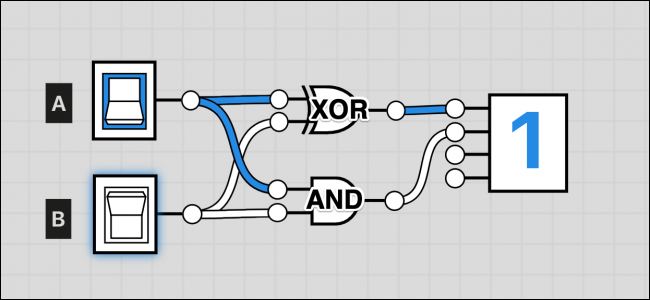
صرفاً به کمک دو گیت میتوان یک عمل جمع ابتدایی را اجرا کرد. نمودار فوق یک نیمجمعکننده (half adder را نمایش میدهد). گیت XOR در این مدار زمانی روشن میشود که صرفاً یکی از ورودیهایش true شده باشد و نه هر دو آنها. گیت AND زمانی روشن میشود که هر دو ورودی روشن باشند؛ اما زمانی که ورودی نباشد خاموش میماند. بنابراین اگر هر دو روشن باشند، XOR خاموش میماند و گیت AND روشن میشود و پاسخ صحیح که 2 است به دست میآید:
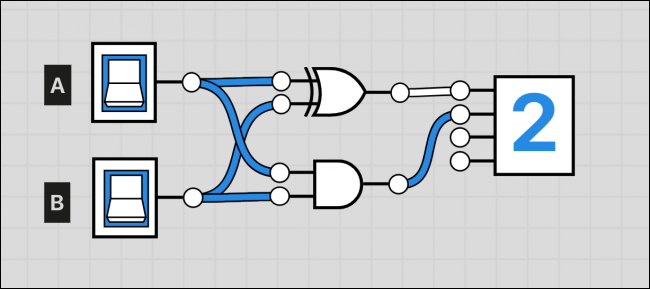
بدین ترتیب با این تنظیمات ساده به سه خروجی متمایز 0، 1 و 2 دست مییابیم. اما با یک بیت هیچ چیزی بزرگتر از 1 را نمیتوانیم ذخیره کنیم و این ماشین با توجه به این که صرفاً یکی از سادهترین مسائل ریاضی را حل میکند، فایده چندانی نخواهد داشت. اما دقت کنید که این مدار صرفاً یک نیمجمعکننده است و اگر دو مورد از آنها را با استفاده از یک ورودی دیگر به هم متصل کنید، میتوانید یک تمامجمعکننده (Full Adder) به دست آورید:
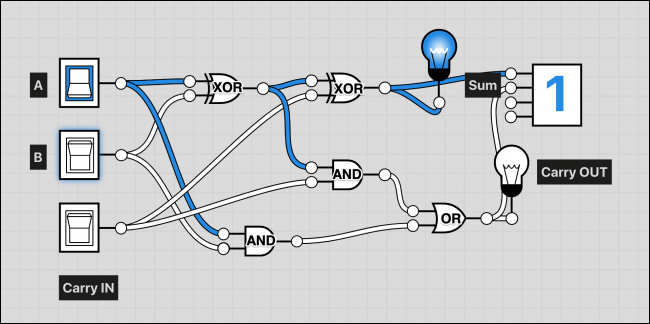
مدار تمامجمعکننده سه ورودی دارد که دو مورد از آنها اعدادی هستند که باید جمع شوند و یک مورد نیز ورودی نَقلی (carry in) است. این جزء نقلی زمانی که خروجی از حد قابل قبول برای ذخیره در یک بیت منفرد تجاوز میکند، مورد استفاده قرار میگیرد. آدرس کامل در یک زنجیره ذخیره میشود و عنصر نقلی از یک جمعکننده به جمعکننده دیگر ارسال میشود. در نهایت رقم نقلی به نتیجه گیت XOR در نیمجمعکننده اول اضافه میشود و یک گیت OR دیگر نیز برای مدیریت هر دو حالت در موارد نیاز وجود دارد.
زمانی که هردو ورودی روشن باشند، رقم نقلی روشن میشود و آن را به تمامجمعکننده بعدی در زنجیره اضافه میکند.
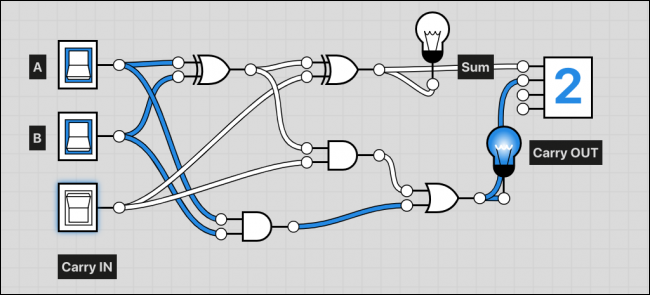
و بدین ترتیب عمل جمع انجام مییابد. بهرهگیری از بیتهای بیشتر صرفاً به معنی افزودن ایجاد آدرسهای کامل جدید در زنجیرهای طولانیتر است.
اجرای موارد دیگری از عملیات ریاضی نیز با استفاده از جمع امکانپذیر است. ضرب در واقع همان تکرار عمل جمع است، تفریق از طریق نوعی معکوسسازی بیت میسر است و تقسیم صرفاً تکرار عمل تفریق است. با این که اغلب رایانههای مدرن، راهحلهای مبتنی بر سختافزاری برای اجرای موارد پیچیدهتر عملیات ریاضی دارند؛ اما شما میتوانید از نظر فنی همه آنها را با استفاده از تمامجمعکننده نیز انجام دهید.
باس (Bus) و حافظه
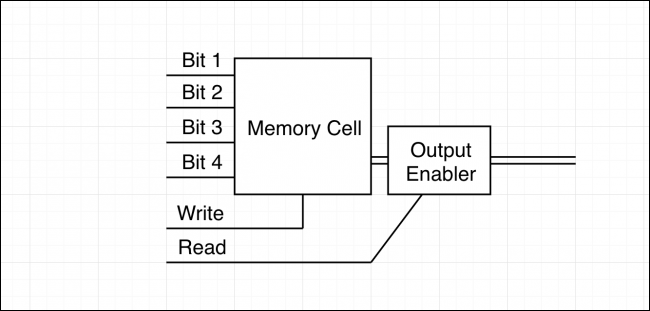
اینک رایانه ما چیزی به جز یک ماشین حساب بد نیست! دلیل این مسئله آن است که این ماشین حساب نمیتواند هیچ چیز را به خاطر بیاورد و با خروجی خود نیز هیچ کاری انجام نمیدهد. در تصویر فوق یک سلول حافظه را مشاهده میکنید که همه این کارها را میتواند انجام دهد. البته در پسِ این شِماتیک تعداد زیادی گیتهای NAND قرار دارند و در عمل نیز بسته به تکنیک ذخیرهسازی ممکن است کاملاً متفاوت باشد؛ ولی در هر حال کارکرد آن به همین شکل است. شما به این سلول یک ورودی میدهید، بیت نوشتن (write) را روشن میکنید و این سلول، ورودی را درون خود ذخیره میکند. البته ما همواره به عمل خواندن یک سلول حافظه هم نیاز داریم. این کار از طریق یک فعالساز (enabler) که مجموعهای از گیتهای AND برای هر بیت از اطلاعات است میسر میشود. این enabler به ورودی دیگری که بیت خواندن (read) است مرتبط است. بیتهای خواندن و نوشتن غالباً به صورت set و enable نیز خوانده میشوند.
کل این بسته به صورت مجموعهای به نام ثبّات (register) نامیده میشود. این ثباتها به باس (گذرگاه) وصل میشوند که مجموعهای از سیمها است که در کل سیستم میچرخند و به همه اجزا اتصال یافتهاند. در همه رایانههای مدرن باس وجود دارد، و برای بهبود عملکرد چندوظیفگی از باس های چندگانه نیز کمک گرفته میشود.
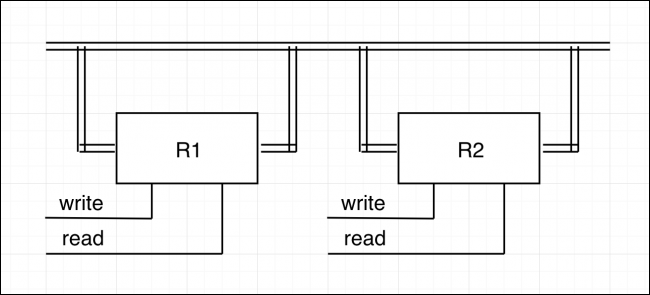
هر ثبات نیز یک بیت خواندن و نوشتن دارد؛ اما در این تنظیمات، ورودی و خروجی چیز یکسانی هستند. این وضعیت در عمل خوب است. برای مثال اگر بخواهیم محتوای R1 را به R2 کپی کنیم، باید بیت خواندن را برای R1 روشن کنیم که باعث میشود محتوای R1 به باس انتقال یابد. در حالی که بیت خواندن روشن است، باید بیت نوشتن R2 را روشن کنید تا محتوای باس به R2 کپی شود.
ثباتها برای ساخت RAM نیز مورد استفاده قرار میگیرند. رم غالباً به شکل شبکهای طراحی میشود که سیمهای آن در دو جهت کشیده شدهاند:

دیکودرها یک ورودی باینری را میگیرند و شماره سیم مربوطه را روشن میکنند. برای مثال، 11 همان عدد 3 به زبان باینری است و بالاترین عدد 2 بیتی محسوب میشود، از این رو دیکودر باید بالاترین سیم را روشن کند. در هر تقاطع ثباتهایی وجود دارند. همه اینها به باس مرکزی و همچنین به یک ورودی خواندن و نوشتن مرکزی متصل هستند. هر دو ورودی خواندن و نوشتن تنها زمانی روشن میشوند که دو سیم که از روی ثبات میکنند نیز روشن باشند و بدین ترتیب امکان انتخاب ثباتهایی که قرار است خوانده و نوشته شوند ممکن میشود. در این مورد نیز باید اشاره کنیم که RAM های مدرن بسیار پیچیدهتر هستند؛ اما همچنان از این تنظیمات استفاده میکنند.
ساعت، stepper و دیکودر
ثباتها در همه جا استفاده میشوند و ابزاری مقدماتی برای جابجایی دادهها و ذخیرهسازی اطلاعات در CPU محسوب میشوند. اما این کار چگونه صورت میپذیرد؟
ساعت (Clock) نخستین جزئی در هسته CPU است که در بازههای معین که برحسب هرتز یا چرخه بر ثانیه اندازهگیری شده است، روشن و خاموش میشود. این همان سرعتی است که هنگام تبلیغ CPU ها مشاهده میکنید. یک CPU 5 گیگاهرتز میتواند 5 میلیارد چرخه را در هر ثانیه اجرا کند. سرعت ساعت در اغلب موارد معیار خوبی برای محاسبه میزان سریع بودن CPU محسوب میشود.
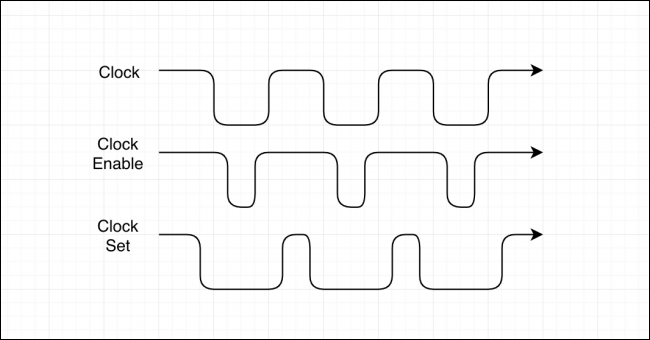
ساعت سه جزء متفاوت دارد، ساعت پایه، ساعت فعالسازی و ساعت set. ساعت پایه در نیمی از چرخه روشن میشود و در نیمه دیگر خاموش میشود. ساعت فعالسازی برای روشن کردن ثباتها استفاده میشود و باید مدت بیشتری روشن بماند تا مطمئن شویم که دادهها فعال شدهاند. ساعت set همواره باید همزمان با ساعت enable روشن باشد، چون در غیر این صورت دادهها ممکن است به اشتباه نوشته شوند.
ساعت به stepper متصل است که از یک تا بیشترین گام را میشمارد و زمانی که چنین کرد، خود را ریست میکند. ساعت همچنین به گیتهای AND هر ثباتی که CPU میتواند بنویسد متصل است:

این گیتهای AND به خروجی جزء دیگر یعنی دیکودر دستورالعمل نیز اتصال دارند. دیکودر دستورالعمل، یک دستورالعمل مانند «مقدار R2 را برابر با R1 تنظیم کن» دریافت میکند و آن را به چیزی دیکود میکند که CPU بتواند آن را درک کند. این دیکودر یک ثبات درونی دارد که «ثبات دستورالعمل» (Instruction Register) نام دارد و همان جایی است که عملیات جاری در آن ذخیره میشود. طرز کار دقیق این دیکودر به سیستمی که در حال اجرا در میآید وابسته است؛ اما زمانی که دستورالعمل را کدگشایی کرد، set صحیح را روشن میکند و بیتها را برای ثباتهای صحیح فعال میسازد که بر مبنای ساعت تنظیم میشوند.
دستورالعملهای برنامه در RAM (یا در سیستمهای مدرن در کش L1 که به CPU نزدیکتر است) نگهداری میشوند. از آنجا که برنامه در ثباتهایی ذخیره شده است، مانند هر متغیر دیگری میتوان آن را دستکاری کرد و به بخشهای مختلف برنامه jump کرد. برنامهها به همین ترتیب دستورالعملهای خود را با حلقهها و دستورهای if دریافت میکنند. دستورالعمل jump مکان کنونی RAM که دیکودر دستورالعمل، مشغول خواندن است را به مکان دیگری تغییر میدهد.
همه اینها چطور با هم کار میکنند؟

اینک تصویر بسیار سادهای که از فرایند کاری CPU ارائه کردیم به پایان رسیده است. باس اصلی کل سیستم را شامل میشود و به همه ثباتها اتصال مییابد. تمام جمع کنندهها همراه با دستهای از عملیات دیگر در یک واحد منطقی محاسبات (ALU) تجمیع میشوند. این ALU اتصالهایی به باس دارد و ثباتهایی نیز دارد که عدد دومی که عملیات روی آن صورت میگیرد را ذخیره میکنند.
برای اجرای یک محاسبه، دادههای برنامه از RAM سیستم وارد بخش کنترل میشوند. بخش کنترل دو عدد را از RAM میخواند، عدد نخست را در ثبات دستورالعمل ALU ذخیره میکند و سپس عدد دوم را در باس ذخیره میسازد. به طور همزمان یک کد دستورالعمل به ALU که وظیفه آن را تعیین میکند. در این هنگام ALU همه محاسبات را انجام داده و نتیجه را در ثبات دیگری که CPU میتواند آن را خوانده و ادامه پردازش را پیگیری کند، ذخیره میکند.