طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیپیکربندی BIND به عنوان سرور DNS خصوصی روی اوبونتو — راهنمای جامع
بخش مهمی از بحث مدیریت پیکربندی سرور شامل تأمین روشی آسان برای بررسی رابطهای شبکه و آدرسهای IP بر اساس نام از طریق راهاندازی یک «سیستم نام دامنه» (DNS) مناسب است. استفاده از نامهای دامنه جامعالشرایط (FQDN) به جای آدرسهای IP برای اشاره به آدرسهای داخل شبکه باعث میشود که پیکربندی سرویسها و اپلیکیشنها آسانتر شده و قابلیت نگهداری فایلهای پیکربندی افزایش یابد. راهاندازی DNS شخصی برای شبکه خصوصی روشی عالی برای بهبود مدیریت سرورها محسوب میشود.
در این راهنما به بررسی شیوه راهاندازی سرور DNS داخلی با استفاده از نرمافزار سرور نام (BIND (BIND9 روی اوبونتو 18.04 میپردازیم. این سرور نام میتواند از سوی سرورهای کلاینت شما برای resolve کردن نامهای میزبانی و آدرسهای IP خصوصی مورد استفاده قرار گیرد. بدین ترتیب روشی متمرکز برای مدیریت نامهای میزبانی داخلی و آدرسهای IP خصوصی فراهم میشود که هنگام نیاز به گسترش محیط کاری به بیش از چند میزبان امری کاملاً ضروری به حساب میآید.
پیشنیازها
برای مطالعه این راهنما باید زیرساختهای زیر را داشته باشید. دقت کنید که همه سرورها باید در یک دیتاسنتر باشند و شبکه خصوصی بین آنها فعال شده باشد:
- یک سرور با نسخه تازه نصب شده اوبونتو 18.04 به عنوان سرور DNS اولیه به نام ns1
- (توصیه شده) سرور اوبونتو 18.04 دوم به عنوان سرور DNS ثانویه به نام ns2
- سرورهای دیگر در همان دیتاسنتر که از سرورهای DNS استفاده خواهند کرد.
روی هر یک از این سرورهای اضافی باید دسترسیهای مدیریتی از طریق کاربر sudo پیکربندی شده باشد و از یک فایروال نیز استفاده شود.
اگر با مفاهیم DNS آشنایی ندارید توصیه میکنیم، دستکم بخشی از مطالبی را که در ادامه آمدهاند را مطالعه کنید:
- مفاهیم DNS و انواع سرورهای آن — راهنمای جامع
- پیکربندی Bind به عنوان سرور DNS برای درخواستهای Authoritative-Only — به زبان ساده
- پیکربندی Bind به عنوان یک سرور کش یا فوروارد DNS روی اوبونتو — از صفر تا صد
زیرساختها و اهداف نمونه
با توجه به اهداف این مقاله، موارد زیر جزو فرضیههای ما هستند:
- ما دو سرور داریم که به عنوان سرورهای نام ما استفاده خواهند شد. در این راهنما، این سرورها را ns1 و ns2 خواهیم نامید.
- دو سرور کلاینت دیگر نیز داریم که از زیرساخت DNS که ایجاد میکنیم، استفاده خواهند کرد. این سرورها را host1 و host2 مینامیم. البته شما میتوانید هر تعداد سرور که دوست دارید به این زیرساخت اضافه کنید.
- همه این سرورها در یک دیتاسنتر قرار دارند. ما فرض میکنیم که نام این دیتاسنتر nyc3 است.
- همه این سرورها دارای شبکهبندی خصوصی هستند و در subnet 10.128.0.0./16 قرار دارند. البته شما باید این موارد را بنا به مشخصات سرورهای خودتان تغییر دهید.
- همه سرورها به پروژهای که روی دامنه «example.com» قرار دارد اتصال یافتهاند. از آنجا که سیستم DNS ما به طور کامل داخلی و خصوصی است، نیازی به خرید یک نام دامنه نیست. با این حال استفاده از یک دامنه میتواند به جلوگیری از بروز تداخل با دامنههای قابل مسیریابی عمومی کمک کند.
با فرضیات فوق بدیهی است که طرح نامگذاری به نام «nyc3.example.com» برای اشاره به subnet یا zone خصوصی مناسب خواهد بود. از این رو FQDN برای host1 به صورت host1.nyc3.example.com خواهد بود. در جدول زیر جزییات مربوطه به طور کامل ارائه شده است:
| میزبان | نقش | FQDN خصوصی | آدرس IP خصوصی |
|---|---|---|---|
| ns1 | Primary DNS Server | ns1.nyc3.example.com | 10.128.10.11 |
| ns2 | Secondary DNS Server | ns2.nyc3.example.com | 10.128.20.12 |
| host1 | Generic Host 1 | host1.nyc3.example.com | 10.128.100.101 |
| host2 | Generic Host 2 | host2.nyc3.example.com | 10.128.200.102 |
دقت کنید که احتمالاً تنظیمات موجود شما متفاوت است؛ اما نامهای نمونه و آدرسهای IP که برای نمایش شیوه پیکربندی یک سرور DNS ارائه شدهاند، نمونهای از یک DNS داخلی کاملاً عملیاتی را نشان میدهند. شما میتوانید به سادگی این تنظیمات را با جایگزینی نامهای میزبانی و آدرسهای IP خصوصی در محیط موجود خود مورد استفاده قرار دهید. لزومی نیست که از نام منطقه دیتاسنتر در طرح نامگذاری خود استفاده کنید؛ اما دلیل استفاده ما از چنین خصوصیتی این است که نشان دهیم میزبانها همگی متعلق به شبکه خصوصی یک دیتاسنتر واحد هستند. اگر شما از چند دیتاسنتر استفاده میکنید، میتوانید یک DNS داخلی درون هر دیتاسنتر متناظر ایجاد کنید.
در انتهای این راهنما ما یک سرور DNS اصلی به نام ns1 و یک سرور DNS اختیاری ثانویه به نام ns2 خواهیم داشت که به عنوان پشتیبان عمل میکند. کار خود را با نصب سرور DNS اصلی آغاز میکنیم.
نصب BIND روی سرورهای DNS
دقت کنید مواردی که به رنگ قرمز هایلایت شدهاند، در اغلب موارد متغیرهایی هستند که شما باید مقادیرشان را بر اساس مشخصات سرورهای خودتان جایگزین نمایید. برای نمونه اگر متغیری را به صورت host1.nyc3.example.com دیدید، باید به جای آن FQDN سرور خود را وارد کنید. به طور مشابه به جای host1_private_IP آدرس IP سرور خودتان را جایگزین کنید.
روی هر دو سرور DNS به نامهای ns1 و ns2، بسته apt را با وارد کردن دستور زیر بهروزرسانی کنید:
sudo apt-get update
اینک BIND را نصب میکنیم:
sudo apt-get install bind9 bind9utils bind9-doc
تنظیم BIND در حالت IPv4
پیش از ادامه مراحل باید BIND را به حالت IPv4 تنظیم کنیم، چون شبکهبندی خصوصی ما به طور انحصاری از IPv4 استفاده میکند. روی هر دو سرور تنظیمات پیشفرض bind9 را با وارد کردن دستور زیر ویرایش میکنیم:
sudo nano /etc/default/bind9
مقدار «4-» را به انتهای پارامتر OPTIONS اضافه میکنیم. بدین ترتیب به صورت زیر در میآید:
...
OPTIONS="-u bind -4"هنگام پایان کار، فایل را ذخیره کرده و ببندید. سپس BIND را ریاستارت کنید تا تغییرات اعمال شوند:
sudo systemctl restart bind9
اینک که BIND نصب شده است میتوانیم سرور DNS اصلی را پیکربندی کنیم.
پیکربندی سرور DNS اصلی
پیکربندی BIND شامل چندین فایل است که همه آنها در فایل پیکربندی اصلی به نام named.conf گنجانده شدهاند. نام این فایلها با named آغاز میشود، زیرا این نام پروسسی است که BIND اجرا میکند (اختصاری برای «domain name daemon» محسوب میشود). ما کار خود را با پیکربندی فایل options آغاز میکنیم.
پیکربندی فایل Options
روی سرور ns1 فایل named.conf.options را برای ویرایش باز کنید:
sudo nano /etc/bind/named.conf.options
در بالاتر از بلوک options یک ACL جدید به نام «trusted» ایجاد کنید. ACL، اختصاری برای عبارت «لیست کنترل دسترسی» (access control list) است.
این همان جایی است که لیستی از کلاینتهایی را تعریف میکنیم که اجازه کوئری بازگشتی DNS را دارند. این لیست شامل سرورهای متعلق به شما در همان دیتاسنتر ns1 است. با استفاده از آدرسهای IP خصوصی نمونهای که قبلاً معرفی کردیم، ns1، ns2، host1 و hst2 را به لیست کلاینتهای مورد اعتماد خود اضافه میکنیم:
acl "trusted" {
10.128.10.11; # ns1 - can be set to localhost
10.128.20.12; # ns2
10.128.100.101; # host1
10.128.200.102; # host2
};
options {
. . .
اینک که لیست کلاینتهای DNS مورد اعتماد خود را ایجاد کردیم، باید بلوک options را ویرایش کنیم. در حال حاضر آغاز بلوک مانند زیر است:
. . .
};
options {
directory "/var/cache/bind";
. . .
}
زیر دایرکتیو directory خطوط پیکربندی هایلایت شده را اضافه کنید و آدرسهای IP سرور ns1 خود را جایگزین کنید. بدین ترتیب چیزی مانند زیر خواهد بود:
. . .
};
options {
directory "/var/cache/bind";
recursion yes; # enables resursive queries
allow-recursion { trusted; }; # allows recursive queries from "trusted" clients
listen-on { 10.128.10.11; }; # ns1 private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
forwarders {
8.8.8.8;
8.8.4.4;
};
. . .
};
زمانی که کارتان پایان یافت، فایل named.conf.options را ذخیره کرده و ببندید. پیکربندی فوق تعیین میکند که صرفاً سرورهای متعلق به شما (یعنی سرورهای trusted) میتوانند به سرورهای DNS در مورد دامنههای خارجی کوئری بزنند.
در ادامه فایل محلی را نیز پیکربندی میکنیم تا zone های DNS را تعیین کنیم.
پیکربندی فایل محلی (local)
روی سرور ns1 فایل named.conf.local را برای ویرایش باز کنید:
sudo nano /etc/bind/named.conf.local
این فایل به جز چند کامنت باید چیز دیگری نداشته باشد. در این فایل زونهای فوروارد و معکوس خود را تعیین میکنیم. زونهای دیاناس حوزه خاصی را برای مدیریت و تعریف رکوردهای DNS اختصاص میدهند. از آنجا که دامنههای ما درون زیردامنه «nyc3.example.com» قرار دارند، ما از آن به عنوان زون فوروارد خود استفاده خواهیم کرد. از آنجا که آدرسهای IP خصوصی همگی در فضای IP 10.128.0.0/16 قرار دارند، یک زون معکوس راهاندازی میکنیم تا جستجوهای معکوس درون این محدوده را تعریف کنیم.
زون فوروارد را با خطوط زیر اضافه میکنیم. دقت کنید که نامهای زون خود را جایگزین کنید و آدرسهای IP خصوصی سرور DNS ثانویه را در دایرکتیو allow-transfer اضافه کنید:
zone "nyc3.example.com" { type master; file "/etc/bind/zones/db.nyc3.example.com"; # zone file path allow-transfer { 10.128.20.12; }; # ns2 private IP address - secondary };
با فرض این که subnet خصوصی به صورت 10.128.0.0/16 است، زون معکوس را با افزودن خطوط زیر میتوانید ایجاد کنید. دقت کنید که نامهای زون معکوس ما با 128.10 آغاز میشود که معکوس 10.128 است:
. . . }; zone "128.10.in-addr.arpa" { type master; file "/etc/bind/zones/db.10.128"; # 10.128.0.0/16 subnet allow-transfer { 10.128.20.12; }; # ns2 private IP address - secondary };
اگر سرورهای شما روی چند subnet گسترش یافتهاند؛ اما همگی روی یک دیتاسنتر هستند؛ باید اطمینان حاصل کنید که یک زون اضافی و همچنین فایل زون برای هر subnet متمایز ایجاد کردهاید. زمانی که ویرایش همه زونهای مطلوب پایان یافت، فایل named.conf.local را ذخیره کرده و ببندید.
اینک که زونها در BIND مشخص شدند، باید فایلهای زون فوروارد و معکوس متناظر را ایجاد کنیم.
ایجاد فایل forward zone
فایل زون فوروارد جایی است که رکوردهای DNS برای بررسیهای دیاناس فوروارد ذخیره میشوند. یعنی برای مثال هنگامی که DNS یک کوئری نام برای «host1.nyc3.example.com» دریافت میکند، در فایل زون فوروارد به دنبال آدرس IP متناظر برای resolve کردن host1 میگردد.
ابتدا یک دایرکتوری ایجاد میکنیم تا فایلهای زون خود را درون آن قرار دهیم. بر اساس پیکربندی named.conf.local، این مکان باید etc/bind/zones/ باشد:
sudo mkdir /etc/bind/zones
اینک فایل زون فوروارد خود را بر اساس فایل زون نمونه db.local طراحی میکنیم. آن را بر اساس دستورهای زیر به مکان مناسبی کپی کنید:
sudo cp /etc/bind/db.local /etc/bind/zones/db.nyc3.example.comاینک فایل فوروارد خود را ویرایش میکنیم:
sudo nano /etc/bind/zones/db.nyc3.example.com
در ابتدا این فایل چیزی شبیه زیر است:
$TTL 604800
@ IN SOA localhost. root.localhost. (
2 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost. ; delete this line
@ IN A 127.0.0.1 ; delete this line
@ IN AAAA ::1 ; delete this lineدر اولین گام باید رکورد SOA را ویرایش کنیم. بنابراین FQDN سرور ns1 را به جای localhost قرار میدهیم و سپس root.localhost را با admin.nyc3.example.com جایگزین میکنیم. هر زمان که یک فایل زون را ویرایش میکنید، باید شماره سریال آن را پیش از ریاستارت کردن پروسس named افزایش دهید. ما این مقدار را به 3 افزایش میدهیم و بنابراین به صورت زیر در میآید:
@ IN SOA ns1.nyc3.example.com. admin.nyc3.example.com. (
3 ; Serial
. . .سپس سه رکورد انتهای فایل (پس از SOA) را حذف میکنیم. اگر مطمئن نیستید که کدام خطها را باید حذف کنید، دقت کنید که در بخش فوق آنها را با «delete this line» مشخص ساختهایم.
در انتهای فایل رکوردهای سرور نام با خطوط زیر را اضافه کنید. دقت کنید که موارد مورد نظر را با مقادیر خودتان جایگزین کنید و این که ستون دوم مشخص میکند اینها رکوردهای NS هستند:
. . .
; name servers - NS records
IN NS ns1.nyc3.example.com.
IN NS ns2.nyc3.example.com.اینک رکورد A را به میزبانهایی که به این زون تعلق دارند اضافه کنید. این مورد شامل همه سرورهایی است که میخواهیم نام آنها با «nyc3.example.com» خاتمه یابد. دقت کنید که باید نامها و آدرسهای IP خصوصی مورد نظر خودتان را جایگزین کنید. رکوردهای A را برای ns1، ns2، host1 و host2 با استفاده از نامها و آدرسهای IP خصوصی مورد نظر این راهنما، به صورت زیر اضافه کردهایم:
. . . ; name servers - A records ns1.nyc3.example.com. IN A 10.128.10.11 ns2.nyc3.example.com. IN A 10.128.20.12 ; 10.128.0.0/16 - A records host1.nyc3.example.com. IN A 10.128.100.101 host2.nyc3.example.com. IN A 10.128.200.102
فایل db.nyc3.example.com را ذخیره کرده و خارج شوید. فایل زون فوروارد نمونه نهایی در انتها به صورت زیر خواهد بود:
$TTL 604800 @ IN SOA ns1.nyc3.example.com. admin.nyc3.example.com. ( 3 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; ; name servers - NS records IN NS ns1.nyc3.example.com. IN NS ns2.nyc3.example.com. ; name servers - A records ns1.nyc3.example.com. IN A 10.128.10.11 ns2.nyc3.example.com. IN A 10.128.20.12 ; 10.128.0.0/16 - A records host1.nyc3.example.com. IN A 10.128.100.101 host2.nyc3.example.com. IN A 10.128.200.102
اینک به پیکربندی فایل(های) زون معکوس میپردازیم:
ایجاد فایل(های) Reverse Zone
زون معکوس که رکوردهای DNS PTR در آن تعریف میشود، به منظور پاسخدهی به جستجوهای DNS معکوس هست. یعنی هنگامی که DNS یک کوئری برای مثال بر اساس آدرس 10.128.100.101 دریافت میکند به فایل (های) زون معکوس نگاه میکند تا FQDN متناظر را که در این مورد «host1.nyc3.example.com» است، بیابد.
روی سرور ns1 برای هر زون معکوس که در فایل named.conf.local تعیین شده است، یک فایل زون معکوس ایجاد میکنیم. فایل (های) زون معکوس بر اساس فایل زون نمونه db.127 ایجاد میشوند. آن را با دستور زیر به مکان مناسبی کپی کنید. دقت کنید که فایل زون معکوس خود را طوری نامگذاری کنید که متناسب با تعریف زون معکوس شما باشد:
sudo cp /etc/bind/db.127 /etc/bind/zones/db.10.128فایل زون معکوس را که متناظر با زون (های) معکوس تعریف شده در named.conf.local است ویرایش میکنیم:
sudo nano /etc/bind/zones/db.10.128در ابتدا این فایل مانند زیر است:
$TTL 604800
@ IN SOA localhost. root.localhost. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS localhost. ; delete this line
1.0.0 IN PTR localhost. ; delete this lineهمانند روش ویرایش فایل زون فوروارد باید رکورد SOA را تغییر داده و مقدار سریال را یک واحد افزایش دهیم. بدین ترتیب فایل به صورت زیر در میآید:
@ IN SOA ns1.nyc3.example.com. admin.nyc3.example.com. (
3 ; Serial
. . .اینک دو رکورد انتهای فایل (پس از رکورد SOA) را ویرایش میکنیم. اگر مطمئن نیستید که کدام خطها باید حذف شوند؛ این خطوط با کامنت «delete this line» در بخش فوق مشخص شدهاند.
در انتهای فایل؛ سرور نام خود را با خطوط زیر اضافه کنید. دقت کنید که نام خود را جایگزین کنید. همچنین توجه داشته باشید که ستون دوم تعیین میکند که اینها رکوردهای NS هستند:
. . .
; name servers - NS records
IN NS ns1.nyc3.example.com.
IN NS ns2.nyc3.example.com.سپس رکوردهای PTR را برای همه سرورهایی که آدرس IP آنها در subnet فایل زون مورد ویرایش قرار دارد، اضافه کنید. در مثالی که ما بررسی میکنیم این موارد شامل همه میزبانها میشوند، زیرا همه آنها در subnet با آدرس 10.128.0.0/16 قرار دارند. توجه داشته باشید که ستون نخست شامل دستکم دو بخش از آدرس IP خصوصی سرور به طور معکوس است. مطمئن شوید که تامها و آدرس IP خصوصی خودتان را جایگزین میکنید:
. . . ; PTR Records 11.10 IN PTR ns1.nyc3.example.com. ; 10.128.10.11 12.20 IN PTR ns2.nyc3.example.com. ; 10.128.20.12 101.100 IN PTR host1.nyc3.example.com. ; 10.128.100.101 102.200 IN PTR host2.nyc3.example.com. ; 10.128.200.102
فایل زون معکوس را ذخیره کرده و خارج شوید. اگر لازم است فایلهای زون معکوس دیگری اضافه کنید، مراحل فوق را در مورد آنها نیز تکرار کنید.
فایل زون معکوس نهایی ما چیزی شبیه زیر خواهد بود:
$TTL 604800 @ IN SOA nyc3.example.com. admin.nyc3.example.com. ( 3 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; name servers IN NS ns1.nyc3.example.com. IN NS ns2.nyc3.example.com. ; PTR Records 11.10 IN PTR ns1.nyc3.example.com. ; 10.128.10.11 12.20 IN PTR ns2.nyc3.example.com. ; 10.128.20.12 101.100 IN PTR host1.nyc3.example.com. ; 10.128.100.101 102.200 IN PTR host2.nyc3.example.com. ; 10.128.200.102
بدین ترتیب کار ویرایش فایلها به پایان رسیده است و از این رو در مرحله بعد فایلهای خود و خطاهای احتمالی را بررسی میکنیم.
بررسی ساختار پیکربندی BIND
دستور زیر را برای بررسی ساختار فایلهای named.conf* اجرا کنید:
sudo named-checkconf
اگر فایلهای پیکربندی named شما دارای خطاهای ساختاری نباشند، بدون مشاهده هیچ گونه خطایی به خط اعلان فرمان باز میگردید. اما اگر مشکلاتی در فایلهای پیکربندی وجود داشته باشند، باید پیام خطا را بررسی کرده و به بخش «پیکربندی سرور DNS اصلی» این راهنما بازگشته و پس از رفع خطا مجدداً دستور named-checkconf را اجرا کنید.
دستور named-checkzone برای بررسی صحیح بودن فایلهای زون اجرا میشود. آرگومان نخست این دستور نام یک زون است و آرگومان دوم نیز فایل زون متناظر با آن خواهد بود که هر دو باید در فایل named.conf.local تعریف شده باشند.
برای نمونه جهت بررسی پیکربندی زون فوروارد «nyc3.example.com»، دستور زیر را اجرا کنید. دقت کنید که موارد هایلایت شده را با مشخصات سرورهای خودتان جایگزین کنید:
sudo named-checkzone nyc3.example.com db.nyc3.example.com
برای بررسی پیکربندی زون معکوس «128.10.in-addr.arpa»، دستور زیر را اجرا کنید. عددها را تغییر دهید تا متناظر با زون معکوس و فایل شما باشند:
sudo named-checkzone 128.10.in-addr.arpa /etc/bind/zones/db.10.128
زمانی که مطمئن شدید همه فایلهای پیکربندی و زون بدون خطا هستند، آماده هستید تا سرویس BIND را ریاستارت کنید.
ریاستارت کردن BIND
با دستور زیر BIND را ریاستارت کنید:
sudo systemctl restart bind9
اگر فایروال UFW را فعال کردهاید، دسترسی به BIND را با دستور زیر باز کنید:
sudo ufw allow Bind9
سرور DNS اصلی شما اینک راهاندازی شده و به کوئریهای DNS پاسخ میدهد. پس در ادامه به پیکربندی و راهاندازی سرور DNS ثانویه میپردازیم.
پیکربندی سرور DNS ثانویه
در اغلب موارد، راهاندازی یک سرور DNS ثانویه که در صورت از کار افتادن سرور اصلی به کوئریها پاسخ میدهد، ایده مناسبی محسوب میشود. خوشبختانه پیکربندی سرور DNS ثانویه بسیار آسانتر است.
روی سرور ns2 فایل named.conf.options را باز کنید:
sudo nano /etc/bind/named.conf.options
در ابتدای فایل، ACL را با آدرسهای IP خصوص همه سرورهای مورد اعتماد ایجاد کنید:
acl "trusted" {
10.128.10.11; # ns1
10.128.20.12; # ns2 - can be set to localhost
10.128.100.101; # host1
10.128.200.102; # host2
};
options {
. . .زیر دایرکتیو directory خطوط زیر را اضافه کنید:
recursion yes;
allow-recursion { trusted; };
listen-on { 10.128.20.12; }; # ns2 private IP address
allow-transfer { none; }; # disable zone transfers by default
forwarders {
8.8.8.8;
8.8.4.4;
};فایل named.conf.options را ذخیره کرده و ببندید. اینک این فایل باید دقیقاً مانند فایل named.conf.options روی سرور ns1 باشد، به جز این که طوری پیکربندی شده است تا به آدرس IP خصوصی ns2 گوش دهد. سپس فایل named.conf.local را باز کنید:
sudo nano /etc/bind/named.conf.local
زونهایی که متناظر با زونهای master روی سرور DNS اصلی هستند تعریف کنید. توجه داشته باشید که در این مورد نوع برابر با «slave» خواهد بود و بنابراین فایل شامل مسیر نیست و دایرکتیوهای masters وجود دارند که باید برابر با آدرس IP خصوصی DNS اصلی تنظیم شوند. اگر چندین زون معکوس در سرور DNS اصلی تعریف کردهاید، باید مطمئن شوید که همه آنها را در این جا اضافه کردهاید:
zone "nyc3.example.com" { type slave; file "db.nyc3.example.com"; masters { 10.128.10.11; }; # ns1 private IP }; zone "128.10.in-addr.arpa" { type slave; file "db.10.128"; masters { 10.128.10.11; }; # ns1 private IP };
اینک فایل named.conf.local را ذخیره کرده و ببندید. دستور زیر را برای بررسی درستی فایلهای پیکربندی اجرا کنید:
sudo named-checkconf
زمانی که بررسی پایان یافت، BIND را ریاستارت کنید:
sudo systemctl restart bind9
با تغییر دادن فایروال UFW به صورت زیر به اتصال DNS اجازه عبور بدهید:
sudo ufw allow Bind9
اینک سرورهای DNS اصلی و ثانویه برای resolve کردن شبکه خصوصی و آدرسهای IP مربوطه پیکربندی شده است. در ادامه سرورهای کلاینت را برای استفاده از سرورهای DNS خصوصی پیکربندی میکنیم.
پیکربندی کلاینتهای DNS
پیش از آن که همه سرورهای موجود در ACL به نام «trusted» بتوانند به سرورهای ACL کوئری بزنند، باید هر یک از آنها را برای استفاده از ns1 و ns2 به عنوان سرورهای نام پیکربندی کنیم. این فرایند به نوع سیستم عامل بستگی دارد؛ اما در مورد اغلب توزیعهای لینوکس شامل افزودن سرورهای نام به فایل /etc/resolv.conf است.
کلاینتهای اوبونتو 18.04
شبکهبندی روی سیستم عامل اوبونتو 18.04 با استفاده از Netplan پیکربندی میشود که امکان نوشتن پیکربندی شبکه استاندارد شده و اِعمال آن در مورد نرمافزار شبکهبندی ناسازگار بکاند (backend) را میدهد. برای پیکربندی DNS، باید فایل پیکربندی Netplan را ویرایش کنیم.
ابتدا دایرکتیو مرتبط با شبکه خصوصی خود را با کوئری کردن subnet خصوصی با دستور ip address بیابید:
ip address show to 10.128.0.0/16خروجی
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 10.128.100.101/16 brd 10.128.255.255 scope global eth1
valid_lft forever preferred_lft foreverدر این مثال، رابط خصوصی eth1 نام دارد. سپس فایلی به نام 00-private-nameservers.yaml در مسیر /etc/netplan ایجاد میکنیم:
sudo nano /etc/netplan/00-private-nameservers.yaml
محتوای زیر را درون این فایل قرار میدهیم. دقت کنید که باید رابط شبکه خصوصی، آدرس سرورهای DNS به نام ns1 و ns2 و زون DNS خودتان را جایگزین کنید:
network:
version: 2
ethernets:
eth1: # Private network interface
nameservers:
addresses:
- 10.128.10.11 # Private IP for ns1
- 10.132.20.12 # Private IP for ns2
search: [ nyc3.example.com ] # DNS zoneدفت کنید که Netplan از فرمت سریالسازی دادهها به صورت YAML برای فایلهای پیکربندی خود استفاده میکند. از آنجا که YAML از تورفتگی و اسپیس برای تعریف ساختار داده خود استفاده میکند، باید مطمئن شوید که تعریف شما از ساختار تورفتگی مناسبی برخوردار است تا خطایی پیش نیاید.
در این مرحله فایل را ذخیره کرده و خارج شوید. سپس باید با دستور netplan try به Netplan بگوییم که تلاش کند از فایل پیکربندی جدید استفاده کند. اگر مشکلی وجود داشته باشد که موجب از دست رفتن شبکهبندی شود، Netplan پس از مدت مشخصی، به طور خودکار تغییرهای ایجاد شده را لغو کرده و وضعیت را به حالت قبل باز میگرداند:
sudo netplan try
خروجی
Warning: Stopping systemd-networkd.service, but it can still be activated by: systemd-networkd.socket Do you want to keep these settings? Press ENTER before the timeout to accept the new configuration Changes will revert in 120 seconds
اگر شمارش معکوس در انتهای خروجی به صورت صحیحی صورت بگیرد، پیکربندی جدید دستکم تا حدی که اتصال SSH شما را قطع نکند، اجرا میشود. با زدن دکمه اینتر پیکربندی جدید را بپذیرید.
اینک resolver DNS سیستم را بررسی کنید تا مشخص شود که آیا پیکربندی DNS اعمال شده است یا نه:
sudo systemd-resolve –status
به سمت پایین اسکرول کنید تا بخشی که به رابط شبکه خصوصی شما مربوط است را ببینید. احتمالاً آدرسهای IP خصوصی سرورهای DNS در ابتدا فهرست شدهاند و سپس مقادیر fallback آماده است. دامنه شما باید در بخش «DNS Domain» مشاهده شود:
خروجی
. . .
Link 3 (eth1)
Current Scopes: DNS
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNS Servers: 10.128.10.11
10.128.20.12
67.207.67.2
67.207.67.3
DNS Domain: nyc3.example.com
. . .
کلاینت شما اینک باید طوری پیکربندی شده باشد که از سرورهای DNS داخلی استفاده کند:
کلاینتهای اوبونتو 16.04 و دبیان
روی سرورهای لینوکس اوبونتو 16.04 و دبیان، شما باید فایل /etc/network/interfaces را ویرایش کنید:
sudo nano /etc/network/interfaces
درون این فایل خط dns-nameservers را یافته و سرورهای نام خود را به ابتدای فهرست اضافه کنید. زیر این خط یک گزینه dns-search اضافه کنید که به دامنه اصلی زیر ساخت شما اشاره میکند. در مورد این راهنما این گزینه برابر با «nyc3.example.com» است:
. . .
dns-nameservers 10.128.10.11 10.128.20.12 8.8.8.8
dns-search nyc3.example.com
. . .زمانی که ویرایشتان پایان یافت، فایل را ذخیره کرده و خارج شوید.
اینک باید سرویسهای شبکه را با دستورهای زیر ریاستارت کنید تا تغییرات جدید اعمال شوند. اطمینان حاصل کید که eth0 را با نام رابط شبکه خودتان جایگزین کردهاید:
sudo ifdown --force eth0 && sudo ip addr flush dev eth0 && sudo ifup --force eth0
بدین ترتیب شبکه بدون قطع اتصال کنونی ریاستارت میشود. در صورتی که همه چیز درست باشد باید خروجی به صورت زیر را مشاهده کنید:
خروجی
RTNETLINK answers: No such process Waiting for DAD... Done
با وارد کردن دستور زیر مطمئن شوید که تنظیمات مورد نظر شما اعمال شده است:
cat /etc/resolv.conf
دران بخش باید سرورهای نام و همچنین دامنه جستجوی خود را در فایل /etc/resolv.conf ببینید:
خروجی
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8) # DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN nameserver 10.128.10.11 nameserver 10.128.20.12 nameserver 8.8.8.8 search nyc3.example.com
اینک کلاینت شما طوری پیکربندی شده است که از سرورهای DNS استفاده کند.
کلاینتهای CentOS
روی سرورهایی که توزیعهای CentOS، RedHat و Fedora را اجرا میکنند باید فایل /etc/sysconfig/network-scripts/ifcfg-eth0 را ویرایش کنید. دقت کنید که به جای eth0 باید نام رابط شبکه خصوصی خود را وارد کنید:
sudo nano /etc/sysconfig/network-scripts/ifcfg-eth0به دنبال گزینههای DNS1 و DNS2 بگردید و آنها را برابر با آدرسهای IP خصوصی سرورهای نام اصلی و ثانویه خود تعیین کنید. یک پارامتر DOMAIN اضافه کنید که به دامنه اصلی زیر ساخت شما اشاره میکند. در این راهنما ما از مقدار «nyc3.example.com» استفاده میکنیم:
. . . DNS1=10.128.10.11 DNS2=10.128.20.12 DOMAIN='nyc3.example.com' . . .
پس از پایان ویرایش، فایل را ذخیره کرده و ببندید. سپس سرویس شبکه را با دستور زیر ریاستارت کنید:
sudo systemctl restart network
این دستور ممکن است چند ثانیه معلق بماند؛ اما پس از مدت اندکی به اعلان باز میگردید. در این مرحله با وارد کردن دستور زیر بررسی کنید که تغییرات اعمال شده است یا نه:
cat /etc/resolv.conf
در خروجی باید سرورهای نام و دامنه جستجو را مشاهده کنید:
nameserver 10.128.10.11 nameserver 10.128.20.12 search nyc3.example.com
اینک کلاینتهای شما میتوانند به سرورهای DNS وصل شده و از آنها استفاده کنند.
تست کردن کلاینتها
با استفاده از nslookup میتوانید بررسی کنید که کلاینتها قادر به کوئری زدن به سرورهای نام هستند یا نه. این وضعیت را روی همه کلاینتهایی که در ACL با نام «trusted» ذکر شدهاند بررسی کنید. در مورد کلاینتهای CentOS، باید این ابزار را نصب کنید:
sudo yum install bind-utils
ابتدا با یک جستجوی فوروارد آغاز میکنیم
forward lookup
برای نمونه ما میتوانیم با دستور زیر یک جستجوی فوروارد برای بازیابی آدرس IP نام host1.nyc3.example.com اجرا کنیم:
nslookup host1
کوئری کردن host1 به host1.nyc3.example.com بسط مییابد، زیرا گزینه search به زیردامنه خصوصی شما تعیین شده است و کوئریهای DNS تلاش میکنند تا زیردامنه را پیش از گشتن جاهای دیگر بررسی کنند. خروجی دستور فوق به صورت زیر خواهد بود:
خروجی
Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: Name: host1.nyc3.example.com Address: 10.128.100.101
سپس میتوانیم به بررسی جستجوهای معکوس بپردازیم.
Reverse Lookup
برای تست کردن Reverse Lookup باید آدرس IP خصوصی host1 را کوئری کنیم:
nslookup 10.128.100.101
در خروجی دستور فوق چیزی مانند زیر را باید مشاهده کنید:
خروجی
11.10.128.10.in-addr.arpa name = host1.nyc3.example.com. Authoritative answers can be found from:
اگر همه نامها و آدرسهای IP به مقادیر صحیح resolve شوند، این بدان معنی است که فایلهای زون به طور صحیحی پیکربندی شدهاند. اگر با مقادیر ناخواستهای مواجه شدید، باید اطمینان حاصل کنید که فایلهای زون روی سرور DNS اصلی را مورد بازنگری قرار دادهاید.
اینک شما موفق شدهاید سرورهای DNS داخلی را به طرز صحیحی راهاندازی کنید. در ادامه مواردی در خصوص مبحث نگهداری رکوردهای زون را ارائه میکنیم.
نگهداری رکوردهای DNS
اینک که یک DNS داخلی عملیاتی داریم، باید رکوردهای DNS را طوری نگهداری کنیم که به درستی محیط سرور ما را بازتاب دهد.
افزودن میزبان به DNS
هر زمان که یک میزبان را به محیط خود (در همان دیتاسنتر) اضافه میکنید باید آن را به DNS نیز اضافه کنید. فهرستی از مراحل این کار را در ادامه میبینید:
سرور نام اصلی
- فایل زون فوروارد: یک رکورد A برای میزبان جدید اضافه کنید و مقدار سریال را افزایش دهید.
- فایل زون معکوس: یک مقدار PTR برای میزبان جدید اضافه کنید و مقدار سریال را افزایش دهید.
- آدرس IP خصوصی میزبان جدید را به ACL با عنوان «trusted» اضافه کنید (named.conf.options).
در نهایت فایلهای پیکربندی را تست کنید:
sudo named-checkconf sudo named-checkzone nyc3.example.com db.nyc3.example.com sudo named-checkzone 128.10.in-addr.arpa /etc/bind/zones/db.10.128
سپس BIND را مجدداً بارگذاری نمایید:
sudo systemctl reload bind9
اینک سرور اصلی شما برای استفاده از میزبان جدید پیکربندی شده است.
سرور نام ثانویه
آدرس IP خصوصی میزبان جدید را به ACL با عنوان «trusted» اضافه کنید (named.conf.options).
ساختار پیکربندی را بررسی کنید:
sudo named-checkconf
سپس BIND را مجدداً بارگذاری کنید:
sudo systemctl reload bind9
اینک سرور ثانویه اتصالها از میزبان جدید را میپذیرد.
پیکربندی میزبان جدید برای استفاده از DNS
- فایل etc/resolv.conf/ را طوری پیکربندی کنید تا از سرورهای DNS استفاده کند.
- با استفاده از nslookup تست کنید.
حذف میزبان از DNS
اگر یک میزبان را از محیط خود حذف کردهاید، یا میخواهید آن را از DNS خارج سازید، کافی است همه مواردی که در بخش فوق اضافه کردید را حذف نمایید. یعنی همه گامهای فوق را به صورت معکوس اجرا کنید.
سخن پایانی
اینک شما میتوانید رابطهای شبکه خصوصی خود را به جای آدرسهای IP با استفاده از نامشان مورد اشاره قرار دهید. این امر موجب میشود که پیکربندی سرویسها و اپلیکیشنها آسانتر شود، زیرا دیگر لازم نیست آدرسهای IP خصوصی آنها را به خاطر داشته باشید و خواندن و درک فایلها نیز آسانتر میشود. ضمناً اینک میتوانید پیکربندی خود را در یک مکان منفرد یعنی سرور DNS اصلی طوری تغییر دهید که به سرور جدیدی اشاره کند و نیاز نیست که انواع فایلهای پیکربندی مختلف را ویرایش کنید و همین امر موجب سهولت نگهداری میشود.
زمانی که DNS داخلی خود را راهاندازی کردید و فایلهای پیکربندی از FQDN های خصوصی برای تعیین اتصالهای شبکه استفاده کردند، بسیار ضروری است که سرورهای DNS به طرز صحیحی نگهداری شوند. اگر هر دوی این سرورها از کار بیفتند، سرویسها و اپلیکیشنهای شما دیگر به درستی کار نخواهند کرد. به همین دلیل است که توصیه میشود دستکم یک سرور DNS ثانویه راهاندازی شود تا به عنوان پشتیبان مورد استفاده قرار گیرد.
منبع: فرادرس
پردازشها در سیستم عامل — راهنمای جامع
پردازش در واقع به یک برنامه در حال اجرا گفته میشود. اجرای یک پردازش میبایست به صورت ترتیبی انجام بگیرد. پردازشها به صورت نهادی تعریف میشوند که واحد پایهایِ کار پیادهسازی شده در سیستم را نشان میدهند. به بیان سادهتر برنامههای رایانهای در فایلهای متنی نوشته میشوند و هنگامی که روی سیستم عامل اجرا میشوند به پردازش تبدیل میشوند و همه وظایف اشاره شده در برنامه را به مرحله اجرا در میآورند.
زمانی که یک برنامه در حافظه بارگذاری و به یک پردازش تبدیل میشود، میتوان آن را به چهار بخش تقسیم کرد: پشته، هیپ، متن و داده. در تصویر زیر طرح سادهای از پردازش درون حافظه اصلی نمایش یافته است:

| بخش پردازش | توضیح |
|---|---|
| پشته | شته در پردازش شامل دادههای موقتی مانند پارامترهای متد/تابع، آدرسهای بازگشتی و متغیرهای محلی است. |
| هیپ | هیپ حافظهای است که به صورت دینامیک در طی زمان اجرا تخصیص مییابد. |
| متن | بخش متنی پردازش شامل فعالیت جاری است که بر اساس مقدار Program Counter و محتوای رجیسترهای پردازنده نمایش مییابد. |
| دادهها | در این بخش متغیرهای گلوبال و استاتیک وجود دارند. |
برنامه
برنامه قطعهای از کد است که میتواند از یک خط منفرد یا میلیونها خط تشکیل یافته باشد. یک برنامه رایانهای معمولاً به وسیله برنامهنویس رایانه و به یک زبان خاص برنامهنویسی نوشته میشود. برای نمونه در ادامه برنامه سادهای به زبان C را مشاهده میکنید:
یک برنامه رایانهای مجموعهای از دستورالعملها است که هنگام اجرا، وظیفه خاصی را توسط رایانه به انجام میرساند. زمانی که یک برنامه را با یک پردازش مقایسه میکنیم، نتیجه میگیریم که پردازش، وهله دینامیکی از یک برنامه رایانهای محسوب میشود.
بخشی از برنامه رایانهای که وظیفه کاملاً تعریفشدهای را اجرا میکند به نام الگوریتم شناخته میشود. مجموعهای از برنامههای رایانهای، کتابخانهها و دادههای مرتبط به نام نرمافزار نامیده میشوند.
چرخه عمر پردازشها
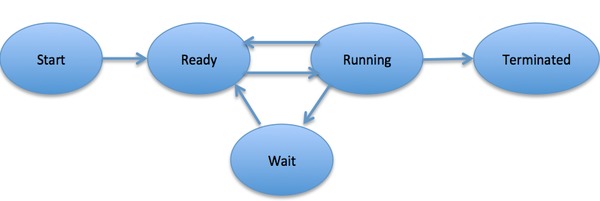
زمانی که یک پردازش اجرا میشود، حالتهای مختلفی را تجربه میکند. این مراحل بسته به نوع سیستم عامل متفاوت هستند و نام این مراحل نیز استاندارد خاصی ندارد.
به طور کلی یک پردازش در هر زمان یکی از حالتهای زیر را میتواند داشته باشد:
| حالت | توضیح |
|---|---|
| آغاز (Start) | حالت اولیه یک پردازش است که در حالت آغاز یا ایجاد است. |
| آماده (Ready) | در این حالت پردازش منتظر انتساب یافتن به یک پردازنده است. پردازشهای آماده در انتظار این هستند که زمان پردازنده از سوی سیستم عامل به آنها اختصاص یابد تا بتوانند اجرا شوند. پردازش پس از مرحله آغاز و یا پس از وقفهای که در آن سیستم عامل، زمان CPU را به پردازش دیگری اختصاص داده است، ممکن است وارد این حالت شوند. |
| اجرا (Running) | زمانی که زمان پردازنده از سوی سیستم عامل به پردازش اختصاص یافت، پردازش وارد حالت اجرا میشود و دستورالعملهای آن از سوی پردازنده اجرا میشوند. |
| انتظار (Waiting) | پردازش در صورتی که نیاز باشد منتظر منابعی مانند ورودی کاربر یا دسترسی به یک فایل بماند وارد حالت انتظار میشود. |
| خاتمه یا خروج (Terminated or Exit) | زمانی که اجزای پردازش پایان مییابد یا از سوی سیستم عامل به آن پایان داده میشود، به حالت خاتمه میرود و بدین ترتیب از حافظه اصلی خارج میشود. |
بلوک کنترل پردازش (PCB)
بلوک کنترل پردازش نوعی ساختمان داده است که از سوی سیستم عامل برای هر پردازش نگهداری میشود. PCB به وسیله یک شناسه پردازش (PID) مشخص میشود. PCB همه اطلاعات مورد نیاز برای پیگیری روند پردازش را که شامل موارد زیر هستند شامل میشود.
| اطلاعات | توضیح |
|---|---|
| حالت پردازش | حالت کنونی پردازش مانند این که آماده، در حال اجرا، و یا انتظار است را شامل میشود. |
| مجوزهای پردازش | این اطلاعات برای فعالسازی یا غیر فعالسازی دسترسی پردازش به منابع سیستم ضروری است |
| شناسه پردازش | شناسهای یکتا برای هر پردازش است که از سوی سیستم عامل تخصیص داده میشود. |
| اشارهگر (Pointer) | یک اشارهگر به پردازش والد است. |
| شمارنده برنامه (Program Counter) | شمارنده برنامه یک اشارهگر به آدرس دستورالعمل بعدی که باید در پردازش اجرا شود محسوب میشود. |
| ثباتهای CPU | شامل ثباتها یا رجیسترهای مختلف CPU است که باید برای اجرای پردازش در حالت اجرایی نگهداری شوند. |
| اطلاعات مدیریت حافظه | این اطلاعات شامل جدول page، محدودیت حافظه، جدول Segment است و به حافظه مورد استفاده از سوی سیستم عامل وابسته است. |
| اطلاعات Accounting | شامل مقدار CPU مورد استفاده برای اجرای پردازش، محدودیت زمانی، شناسه اجرایی و غیره است. |
| اطلاعات وضعیتهای IO | شامل فهرستی از دستگاههای ورودی/خروجی تخصیص یافته به پردازش است. |
| معماری PCB | به طور کامل به نوع سیستم عامل وابسته است و در سیستمهای عامل مختلف میتواند شامل اطلاعات متفاوتی باشد. در ادامه نمودار سادهای از یک PCB را مشاهده میکنید: |

PCB پردازش در طی چرخه عمر پردازش حفظ میشود و تنها زمانی حذف میشود که پردازش خاتمه یابد.
طراحی شبکه تصاویر واکنش گرا با CSS Grid Layout — از صفر تا صد
شما به عنوان یک توسعهدهنده فرانتاند حتماً تاکنون تجربیاتی در زمینه CSS داشتهاید، اما اغلب ما این روزها کار با CSS را از طریق فریمورکهایی مانند Bootstrap انجام میدهیم. برخی موقعیتها وجود دارند که مجبور خواهیم بود مستقیماً با CSS کار کنیم و یکی از آنها مواردی است که بخواهیم با سیستم Grid Layout کار کنیم. در این مقاله به طور عمده در مورد شیوه استفاده از CSS Grid Layout جهت ساختن یک شبکه از تصاویر صحبت خواهیم کرد.
ما قصد نداریم همه مشخصههای Grid Layout را بررسی کنیم، بلکه روی آن مشخصههایی متمرکز میشویم که برای اجرای وظیفه فوق مورد نیاز هستند.
CSS Grid Layout به چه معنی است؟
Grid Layout در CSS یک سیستم طرحبندی دوبُعدی برای وب است. شبکهها امکان سازماندهی محتوا در ردیفها و ستونها را به ما میدهند. طرحبندی یک صفحه وب با یک هدر، یک نوار کناری، ناحیه محتوای اصلی و یک فوتر (مانند تصویر 1 زیر) را تصور کنید. این اجزای صفحه وب نیازمند طرحبندی صحیحی روی صفحه هستند. Grid در CSS به ما کمک میکند که این کار را چنان که با بررسی یک مثال از شبکه تصاویر خواهیم دید، انجام دهیم.

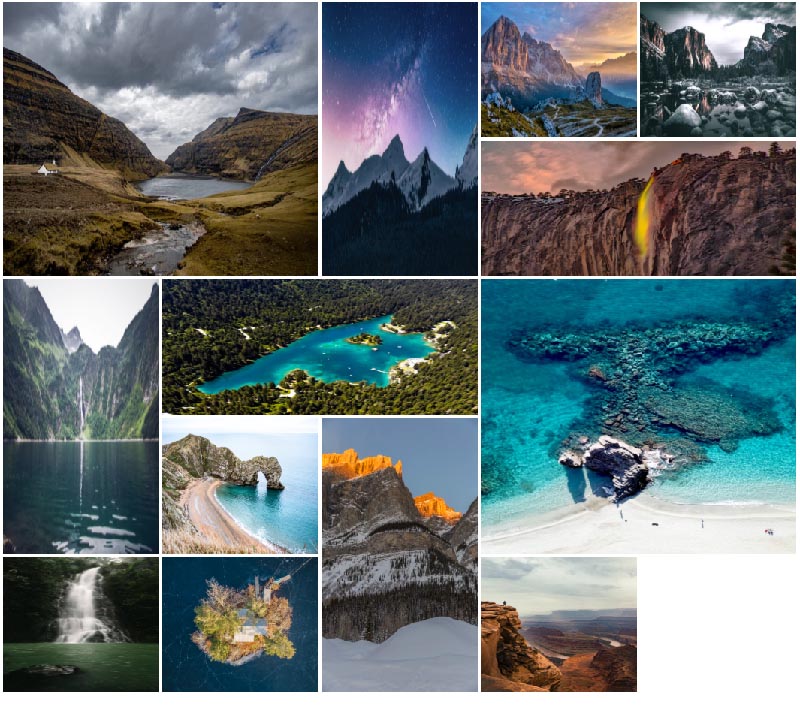
در تصویر زیر شبکه تصاویری که از آن صحبت کردیم و میخواهیم بسازیم را مشاهده میکنید.

خوب هر چه تا اینجا در مورد تئوری صحبت کردیم کافی است. اینک نوبت کار عملی فرا رسیده است.
یک پوشه روی سیستم خود ایجاد کرد و نامی برای آن تعیین کنید. ما پوشه خودمان را Photogrid مینامیم. پوشه را در ویرایشگر متنی محبوب خود باز کنید. ما از VSCode استفاده میکنیم. 2 فایل ایجاد کنید که نام یکی index.html و دیگری main.css است. ما استایل های مورد نیاز را در فایل main.css مینویسیم. کد زیر را به فایل index.html کپی کنید:
همان طور که در قطعه کد فوق میبینید، 13 div ایجاد کردهایم که هر کدام یک تصویر دارد و از سرویس عکس Unsplash واکشی میشود. div کانتینر کلاسی از نوع container. دارد. توجه کنید که برخی از فرزندان div کانتینر، دارای کلاسهایی مانند big ،.vertical. و horizontal. هستند. ما این div-ها را به طرز متفاوتی سبکبندی خواهیم کرد. اینک نوبت به استایلدهی شبکه تصاویر رسیده است.
ایجاد استایل برای شبکه تصاویر
در فایل main.css استایلهایی برای شبکه تصاویر خود ایجاد میکنیم و کار خود را با کلاس container آغاز میکنیم.
در ادامه به اختصار در مورد کارکرد هر یک از مشخصههای فوق صحبت میکنیم.
توضیح مشخصههای استایل
برای این که با هر کانتینر مانند یک کانتینر شبکه رفتار شود، باید نوع display به صورت grid و یا grid-inline برای شبکههای درونخطی تعریف شده باشد. مشخصه grid-template-columns به تعریف ستونهایی از کانتینر شبکه میپردازد. شما میتوانید عرض ستون را با استفاده از یک کلیدواژه مانند auto-fit یا یک طول مانند 50px تعریف کنید. در مورد مثال فوق ما مقدار grid-template-columns را درون یک متد ()repeat تعریف میکنیم.
متد repeat نشان دهنده یک فرگمان تکراری از یک tracklist است. بنابراین یک مقدار مانند (repeat(3، 80px سه ستون ایجاد میکند که هر یک عرضی برابر با 80 پیکسل دارند. کلیدواژه auto-fit به مدیریت اندازههای ستون میپردازد. بدین ترتیب میتوانیم بیشتری تعداد ممکن ستونها را در ردیفی با طول مفروض قرار دهیم. برای نمونه یک مقدار grid-template-columns به صورت (repeat(auto-fit، 100px بیشترین تعداد ستونهایی که در div-های کانتینر شبکه وجود دارند با تنظیمات عرض 80 پیکسل تولید میکند. در نهایت تابع minmax به تعریف کمینه و بیشینه عرض هر ستون میپردازد. minmax برای ایجاد صفحههای واکنشگرا بسیار مفید است.
The grid-auto-rows اندازه یک ردیف شبکه را که به صورت صریح ایجاد شده است تعیین میکند. بنابراین بر اساس قطعه کد CSS فوق این بدان معنی است که هر div که در کانتینر شبکه داریم ارتفاعی برابر با 200 پیکسل خواهد داشت.
grid-gap اندازه فاصله بین ستونها و ردیفها را تعیین میکند. در مثال مورد بررسی، grid-gap آن مقدار 5 پیکسل هم برای فاصله بین ستونها و هم بین ردیفها است.
مشخصه grid-auto-flow به کنترل طرز کار الگوریتم auto-placement میپردازد و دقیقاً تعیین میکند که آیتمهای با جایگذاری خودکار چگونه در شبکه جابجا میشوند. در مثال مورد بررسی، ما از الگوریتم بستهبندی dense استفاده کردهایم که تلاش میکند آیتمهای کوچکی را که در ادامه میآیند، ابتدا در جاهای خالی شبکه پر کند. کامنت کردن آن خط موجب بروز برخی فضاهای خالی در شبکه ما خواهد شد.
تکمیل کد شبکه تصاویر
همان طور که میبینید توضیحهای فوق برای چند خط کد کمی زیاد محسوب میشوند، اما خوشبختانه شما اینک با فرایند کار به خوبی آشنا شدهاید. اکنون باید پا را فراتر گذاشته و شبکه تصاویر را تکمیل کنیم. ابتدا باید مطمئن شویم که همه تصاویر به طور صحیحی در div-ها قرار میگیرند. به این منظور کد زیر را در فایل CSS پس از کلاس container. قرار دهید.
این کد به تعیین عرض و ارتفاع همه تصاویر در شبکه بر اساس 100% کانتینرهایشان میپردازد. در نهایت به استایلدهی div-ها با کلاسهای verical ،.horizontal. و .big میپردازیم.
در این بخش به صحبت در مورد مشخصههای CSS در قطعه کد فوق میپردازیم.
مشخصه CSS به نام grid-column یک مشخصه اختصاری برای grid-column-start و grid-column-end است که اندازه شبکه و موقعیت درون شبکه را تعیین میکند. کلیدواژه span تعداد ردیفها یا ستونهایی که یک grid-column یا grid-row باید پوشش دهد تعیین میکند.
در مثال فوق، برای این که طول برخی تصاویر دو برابر بزرگتر باشد، مقدار grid-column را برای کلاس horizontal. برابر با span 2 و برای کلاس vertical. نیز برابر با span 2 تعیین میکنیم تا ارتفاع برخی تصاویر دو برابر از بقیه باشد. div-های دارای کلاس big. در هر دو گستره ردیف و ستون اندازهای دو برابر معمول دارند. اینک فایل index.html را در یک مرورگر باز کنید و خروجی را مشاهده کنید.
اگر علاقهمند هستید کد کامل را بینید، میتوانید به فایلهای زیر رجوع کنید:
فایل index.html
فایل main.css
نسخه نهایی باید چیزی مانند تصویر زیر باشد:
توجه داشته باشید که CSS Grid Layout مشخصههای زیاد دیگری دارد که احتمالاً مورد توجه شما قرار خواهند گرفت. بنابراین میتوانید بررسی آن را با مطالعه مستندات (+) آغاز کنید.
منبع: فرادرس
گزاره break و continue در ++C — راهنمای کاربردی
دو گزاره به نام گزاره break و continue در زبان برنامهنویسی ++C وجود دارند که به طور خاص برای تغییر در گردش نرمال یک برنامه استفاده میشوند. در برخی موارد میخواهیم که اجرای یک حلقه برای یک شرایط تست خاص رد شود و یا بدون بررسی شرط حلقه بیدرنگ خاتمه یابد. برای مطالعه بخش قبلی این سری مقالات آموزشی به لینک زیر مراجعه کنید:
حلقه while و do…while در ++C — راهنمای کاربردی
برای نمونه ممکن است بخواهیم روی دادههای افرادی با سنین مختلف به جز سنین بالاتر از 65 حلقهای تعریف کنیم. همچنین ممکن است بخواهیم نخستین فردی که 20 سال سن دارد را بیابیم. در چنین مواردی از گزارههای ;continue و ;break استفاده میکنیم.
گزاره break در ++C
گزاره break در ++C موجب خاتمه بیدرنگ یک حلقه میشود. این حلقه میتواند هر نوعی از قبیل for ،while و do..while و همچنین گزارهی switch شود.
ساختار break
در استفادههای عملی گزاره break تقریباً همواره درون بدنه یک گزاره شرطی یعنی if…else در حلقه استفاده میشود.
طرز کار گزاره break چگونه است؟

مثال 1: break در ++C
برنامه ++C برای افزودن همه اعداد وارد شده از سوی کاربر تا زمانی که کاربر عدد 0 وارد نماید:
خروجی
Enter a number: 4 Enter a number: 3.4 Enter a number: 6.7 Enter a number: -4.5 Enter a number: 0 Sum = 9.6
در برنامه فوق، عبارت تست همواره صحیح است. از کاربر تقاضا میشود که عدد دیگری را وارد کند هنگامی که کاربر مقدار 0 وارد میکند، عبارت تست درون گزاره if نادرست است و بدنه else اجرا میشود که موجب خاتمه حلقه میشود. در نهایت مجموع نمایش پیدا میکند.
گزاره continue در ++C
در برخی موارد ضروری است که از شرایط تست خاصی درون یک حلقه رد شویم. در چنین مواردی گزاره continue در زبان برنامهنویسی ++C استفاده میشود.
ساختار continue
در عمل گزاره ;continue تقریباً همیشه درون یک گزاره شرطی استفاده میشود.
کار با گزاره continue

مثال 2: گزاره continue در ++C
برنامه ++C برای نمایش عدد صحیح از 1 تا 10 به جز 6 و 9.
خروجی
1 2 3 4 5 7 8 10
در برنامه فوق، زمانی که i برابر با 6 یا 9 باشد، اجرای گزاره زیر درون حلقه با استفاده از گزاره ;Continue رد میشود:
cout << i << "\t";
بدین ترتیب به پایان بخش دیگری از مطالب راهنمای مفاهیم برنامهنویسی زبان ++C میپردازیم. برای مشاهده بخش بعدی این سری مطالب به لینک زیر رجوع کنید:
منبع: فرادرس
آموزش سوئیفت (Swift): کاربرد Enum با ژنریک و بستار – بخش پانزدهم
در این بخش از سری مقالات آموزش برنامهنویسی سوئیفت قصد داریم به صورت فشرده برخی از مفاهیم مهم این زبان برنامهنویسی شامل استفاده از Enum به همراه ژنریک و بستارها را با هم ترکیب کنیم و با روش عملی استفاده از آنها در کدنویسی آشنا شویم.
در بخش قبلی با مبانی روشهای ایجاد خطاهای سفارشی و استفاده از آنها در کد برای جلوگیری از کرش کردن برنامه آشنا شدیم. برای مطالعه بخش قبلی میتوانید به لینک زیر مراجعه کنید:
Enum به همراه ژنریک و بستار
در بخشهای قبلی این سری آموزشی در مورد Enum-ها صحبت کردیم و گفتم که Enum گزینههای مختلفی در اختیار شما قرار میدهد که میتوانید از میان آنها انتخاب کنید و به نوعی حالتهای مختلف را منحصر به آن گزینهها بکنید. ما میتوانیم از مقادیر متناظر با حالتهای Enum برای تعریف کردن نوعی که در زمان استفاده از Enum وهلهسازی خواهد شد استفاده کنیم.
چنان که میبینید امکان بسیار جالبی است. اگر ندانیم چه نوعی وارد خواهد شد، میتوانیم از ژنریک استفاده کنیم.
بدین ترتیب میتوانیم در زمان ایجاد یک address یا coordinate از هر نوع که میخواهیم، استفاده کنیم.

اکنون به بررسی روش استفاده ترکیبی از Enum به همراه ژنریک و بستار میپردازیم. این ترفند جالبی است که برنامهنویسان حرفهای از آن در کدهای خود استفاده میکنند.
البته اگر بگوییم درک طرز کار این روش آسان است، دروغ گفتهایم. حتی با وجود تورفتگیها، میبینیم که درک کد فوق دشوار است. اما جای نگرانی نیست، زیرا در ادامه، همه این موارد را جزء به جزء توضیح میدهیم.
Struct Download
این Struct منطق ما را نگهداری میکند. این Struct میتواند یک کلاس باشد، زیرا وظیفه اجرای فراخوانیهای شبکه را بر عهده دارد.
بدین ترتیب دو گزینه در اختیار ما قرار میگیرد که یکی (success(anything. و دیگری (failure(someError. است.
این متدی است که یک تابع میگیرد. آن تابع یک حالت را از Enum به نام Result میگیرد و چیزی هم بازگشت نمیدهد.
let session
این دستور یک «نشست» (Session) از URLSession با یک پیکربندی ephemeral میسازد. منظور از ephemeral این است که تنها در حافظه وجود دارد و به عبارتی معادل مرور خصوصی وب است.
let url
این دستور یک URL از رشتهای که به آن ارسال کردهایم، میسازد. این رشته میتواند هر صفحه وبی که میخواهید از آن دانلود کنید باشد.
کد فوق وظیفهای در اختیار ما قرار میدهد که با آن میتوانیم دادههای مورد نظر خود را دانلود کنیم. آن را میتوان مانند اسبی تصور کرد که میتوانیم آن را به هر کجا که میخواهیم برانیم. Data شامل دادههای باینری (0 و 1) است که دریافت میکنیم. response هدرهای پاسخی است که دریافت میشود و در ادامه در مورد آن بیشتر توضیح میدهیم.
error در صورت ناموفق بودن درخواست بازگشت مییابد و درک این نکته مهم است. چون در صورت دریافت یک خطای 404 (صفحه یافت نشد) در فراخوانی، میتوانید اطلاعات مربوطه را از response دریافت کنید. حتی اگر خطای 500 دریافت شود که به معنی ناموفق بودن چیزی در سرور است همچنان میتوان آن را در response مشاهده کرد. error برای ما به این معنی است که نتوانستهایم آن کاری را که میخواستیم اجرا کنیم و حتی درخواست را مقداردهی کنیم. بنابراین error به معنی خطای ما و نه خطای دیگران است.
این یک بررسی قبل از اجرا محسوب میشود. اگر خطایی دریافت شود، دیگر نیازی به اجرا نخواهد بود و کافی است با بازگشت خطا از همینجا خارج شویم.
ما قبلاً در مورد DispatchQueue.main.async صحبت کردهایم، بنابراین در اینجا میخواهیم فقط کد زیر را توضیح دهیم:
اعتبارزدایی
این کد اقدام به اعتبارزدایی و لغو میکند، یعنی هر کاری که انجام میدادید را متوقف کرده و session را پاک میکند، چون دیگر نیازی به آن نداریم. اما اگر بخواهیم defer را توضیح دهیم، باید بگوییم که defer برای اجرا کردن یک قطعه کد استفاده میشود و مهم نیست که چه کاری انجام مییابد، صرفاً باید قبل از اجرا شدن، تا زمانی که متد پایان مییابد صبر کند. در واقع شبیه به یک deinit برای متدها، تابعها و بستارها است.
سپس از (!completion(.failure(error استفاده میکنیم. completion از نام پارامتر در start میآید. failure. حالتی از Enum با نام Result و !error خطای به اجبار باز شده است که از بستار دریافت شده است. در این موقعیت این بهکارگیری اجبار، کار درستی محسوب میشود، چون قبلاً تهی نبودن آن را بررسی کردهایم و از آنجا که این کد اجرا میشود، به این معنی است که تهی نبوده است. در ادامه بررسیهای دیگری را نیز اجرا میکنیم.
دسترسی مستقیم به حالت
متأسفانه سوئیفت دسترسی مستقیم به «حالت» (State) کد ایجاد نمیکند؛ اما HTTPURLResponse چنین امکانی در اختیار ما قرار میدهد و میتوانیم نوع پاسخ را به یک HTTPURLResponse تغییر دهیم و باید موفق باشد. در این حالت بیدرنگ بررسی میکنیم که آیا پاسخ موفقی به صورت زیر داریم یا نه:
اگر هر دوی آنها درست باشند، در این صورت میتوانیم دادهها را به صورت امنی باز پس بفرستیم تا تجزیه شوند و یا هر کار دیگری که قصد انجام آن وجود دارد اجرا شود. ابتدا با استفاده از DispatchQueue.main.async مطمئن میشویم که این کار را روی صف اصلی انجام میدهیم و سپس از دستگیره completion استفاده میکنیم تا این کار را با ((!completion(.success(data به صورت باز کردن اجباری دادهها اجرا کنیم، چون هر سه پارامتر بستار، مقادیر غیر optimal هستند.
در انتهای تابع Start اقدام به فراخوانی ()task.resume میکنیم که وظیفه داده را اجرا میکند. زمانی که این فراخوانی پایان یافت، همه آن کد را که قبلاً بررسی کردیم اجرا میکنیم.
برای این که متوجه شوید همه این موارد در سمت دیگر که Start را فراخوانی میکنیم، چه طور به نظر میرسند، میتوانید کد زیر را ملاحظه کنید:
سخن پایانی
بدین ترتیب در این مقاله با ارائه یک مثال با روش اجرای یک فراخوانی شبکه آشنا شدیم. روش استفاده از قدرت Enum-ها به همراه تابعها و ژنریک ها برای کمک به بازگشت بستار نمایش یافت. همچنین نگاهی به escaping@ داشتیم و با طرز استفاده از آن بیشتر آشنا شدیم.
این راهحل شبکه یک راهحل بهینه نیست و صرفاً یکی از راهحلهای ممکن محسوب میشود. روشهای مختلفی برای اجرای این کار وجود دارد و بسته به شیوه استفاده از بستارها در Enum-ها ممکن است مسیرهای متفاوتی ایجاد شود.
با این که ممکن است در نگاه نخست کمی دشوار به نظر برسد، اما اگر چند بار آن را تمرین کنید با طرز کار آن آشنا میشوید. البته امکان تکمیل خودکار کد نیز در صورتی که به آن توجه داشته باشید کمک زیادی به این فرایند یادگیری میکند.
ما تا به این جا صحبتهای زیادی در مورد انواعِ مقداری داشتیم. سوئیفت عاشق انواعِ مقداری خود است؛ اما نوع دیگری از دادهها به نام انواعِ ارجاعی نیز وجود دارند انواع ارجاعی فریبنده هستند و در صورتی که به طرز صحیحی استفاده نشوند میتوانند خطرناک باشند. در بخش بعدی در مورد inout ،Lazy و Getters و Setters صحبت خواهیم کرد. inout به طور کامل در مورد ارجاعها است، Lazy به ارتقای عملکرد کد کمک میکند و getters و setters موجب تغییر در شیوه دسترسی به دادهها میشوند. موارد فوق در موقعیتهای مختلف برنامهنویسی مفید هستند. برای مطالعه بخش بعدی این نوشته به لینک زیر رجوع کنید: