طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیقابلیت های پیشرفته جداول HTML — راهنمای کاربردی
در بخش قبلی این سری مقالات به بررسی جداول HTML پرداختیم. در این بخش برخی از قابلیتهای پیشرفتهتر جداول HTML مانند کپشن، جمعبندی و گروهبندی ردیفها در عنوان جدول یا بخشهای بدنه و فوتر را بررسی میکنیم. همچنین بحث دسترس پذیری جداول HTML برای کاربران دچار نقص بینایی را بیشتر مورد بررسی قرار میدهیم. برای مطالعه بخش قبلی این مجموعه مطلب آموزشی، روی لینک زیر کلیک کنید:
پیشنیاز مطالعه این مقاله آشنایی با مبانی HTML است. انتظار میرود با مطالعه این مطلب با قابلیتهای پیشرفتهتر جداول HTML و دسترسپذیری جداول آشنا شوید.
ارائه توضیح مختصر راجع به جدول با <caption>
با قرار دادن عنصر <caption> و تعریف تودرتوی آن در عنصر <HTML> میتوان یک کپشن (توصیف کوتاه راجع به محتوای جدول) برای جدول تعریف کرد. این عنصر باید درست پس از تگ باز <table> قرار گیرد.
چنان که از مثال کوتاه فوق مشخص است، کپشن به منظور ارائه توصیفی کوتاه از محتوای جدول ارائه میشود. این وضعیت برای همه خوانندگانی که قصد دارند ایده سریعی از فایده جدول داشته باشند، مفید خواهد بود و میتوانند به سرعت با محتوای جدول آشنا شوند. همچنین افراد نابینا نیز میتوانند از محتوای جدول آگاه شوند. به جای این که یک ابزار قرائت صفحه محتوای سلولهای مختلف را بخواند تا این افراد بتوانند در مورد جدول کسب اطلاع بکنند، میتوانند از کپشن استفاده کنند و تصمیم بگیرند که میخواهند جزییات بیشتری از راجع به آن بخوانند یا نه. مجدداً تأکید میکنیم که یک کپشن مستقیماً زیر تگ <table> قرار میگیرد.
نکته: خصوصیت summary روی عنصر <table> نیز میتواند مفید باشد و توصیفی از جدول ارائه کند. این خصوصیت نیز از سوی ابزارهای قرائت صفحه خوانده میشود، اما ما توصیه میکنیم از <caption> استفاده کنید. summary در HTML5 منسوخ شده و کاربران بینا نمیتوانند آن را بخوانند، چون روی صفحه نمایش پیدا نمیکند.
مثال کاربردی: افزودن <caption>
در این بخش به بررسی مجدد مثالی میپردازیم که در بخش قبلی این مقاله ملاحظه کردیم. جدول زمانی مدرسه معلم زبان را از کد زیر کپی کرده و روی سیستم خود در فایلی به نام timetable-fixed.html بچسبانید:
یک کپشن مناسب برای جدول درج کنید. کد را ذخیره کرده و آن را در یک مرورگر باز کنید تا تغییرات حاصل شده را مشاهده کنید.
افزودن ساختار با <thead> ،<tfoot> و <tbody>
زمانی که جدولها ساختار پیچیدهتری مییابند، بهتر است از تعاریف ساختاری بیشتری در ایجاد آنها بهره بگریم. یک روش مشخص استفاده از عناصر <thead> ،<tfoot> و <tbody> است که امکان نشانهگذاری بخشهای هدر، فوتر و بدنه جدول را فراهم میسازد.
این عناصر موجب نمیشوند که جداول دسترسپذیری بیشتری برای ابزارهای قرائت صفحه پیدا کنند و از این نظر ذاتاً ارزش چندانی برای بهبود دیداری ندارند. با این حال، برای استایلدهی و طرحبندی جداول کاملاً مفید هستند و به عنوان قلابهایی برای افزودن CSS به جدول عمل میکنند. برای این که برخی مثالهای جالب در اختیار شما قرار دهیم، باید بگوییم که وقتی جدولی بسیار طولانی میشود، میتوانید در هر بازه نمایشی از جدول یک هدر و یک فوتر قرار دهید. همچنین میتوانید بدنه جدول را در یک صفحه منفرد نمایش دهید و محتوای یکسانی را با اسکرول به سمت بالا و پایین داشته باشید.
برای استفاده از آنها به صورت زیر میتوان عمل کرد:
- عنصر <thead> باید بخشی از جدول را که هدر نام دارد در بربگیرد. این بخش به طور معمول نخستین ردیفی است که عناوین ستونها را شامل میشود، اما لزوماً همیشه چنین نیست. اگر از عنصر استفاده کنید، هدر جدول باید درست زیر آنها قرار گیرد.
- عنصر <tfoot> باید بخشی از جدول را که فوتر نام دارد در بر بگیرد. برای نمونه این بخش میتواند ردیف نهایی باشد که جمعبندی ردیفهای قبلی محسوب میشود. میتوان فوتر جدول را درست در انتهای جدول یا آن را دقیقاً زیر هدر قرار دارد. در هر حال مرورگر آن را در انتهای جدول رندر خواهند کرد.
- عنصر <tbody> باید بخشهایی از جدول را در بر بگیرد که در هدر یا فوتر جدول قرار ندرند. این بخش دقیقاً زیر هدر یا گاهی اوقات زیر فوتر قرار میگیرد و این حالت به تصمیم شما در مورد ساختاربندی جدول بستگی دارد.
نکته: <tbody> همواره و در همه جدولها وجود دارد، هرچند آن را در کد خود به صراحت نیاورده باشید. برای بررسی این موضوع یکی از مثالهای قبلی را که شامل <tbody> نیست باز کنید و به کد HTML در بخش ابزارهای توسعهدهنده مرورگر نگاه کنید. در این حالت مشاهده خواهید کرد که مرورگر این عنصر را به جای شما اضافه میکند. ممکن است کنجکاو باشید که چه لزومی برای گنجاندن این عنصر وجود دارد، دلیل آن این است که بدین ترتیب کنترل بیشتری روی ساختاربندی و استایلدهی جدول خواهید داشت.
مثال کاربردی: افزودن ساختار جدول
در این بخش عناصری جدیدی را که بررسی کردیم، در عمل مورد استفاده قرار میدهیم. قبل از هر چیز یک کپی از کدهای زیر برداشته و روی سیستم خود در فایلهایی با نامهای spending-record.html و minimal-table.css بچسبانید:
فایل spending-record.html
فایل minimal-table.css
این فایل HTML را در مرورگر باز کنید. چنان که میبینید ظاهر مناسبی دارد، اما همچنان نیاز به بهبود دارد. ردیف SUM شامل جمعبندی مقادیر صرف شده است و به نظر میرسد در مکان نامناسبی قرار گرفته است. برخی جزییات کد نیز مفقود هستند.
ردیف هدرها را در یک عنصر <thead> قرار دهید و ردیف SUM را نیز درون عنصر <tfoot> قرار دهید و بقیه کد درون عنصر <tbody> قرار میگیرد. کد را ذخیره و صفحه را رفرش کنید. در ادامه میبینید که افزودن عنصر <tfoot> موجب میشود که ردیف SUM به انتهای جدول برود. سپس خصوصیت colspan را اضافه کنید تا سلول SUM روی چهار ستون نخست گسترش یابد، بنابراین تعداد واقعی در انتهای ستون Cost ظاهر میشود.
در ادامه استایلدهی اضافی سادهای به جدول اضافه میکنیم تا ایدهای از میزان مفید بودن این عناصر برای بهکارگیری کد CSS به دست آوریم. درون بخش عنوان سند HTML یک عنصر <style> خالی میبینیم. درون این عنصر خطوط کد CSS زیر را اضافه کنید:
کد را ذخیره و صفحه را رفرش کنید و نگاهی به نتیجه بیندازید. اگر عناصر <tbody> و <tfoot> در مکان خود نباشند باید سلکتورها و قواعد پیچیدهای برای اعمال استایل ها بنویسید.
جدول تکمیلشده شما چیزی مانند زیر خواهد بود:
کد جدول فوق به صورت زیر است:
جداول تودرتو
امکان تعریف تودرتوی یک جدول درون جدول دیگر وجود دارد و به این منظور کافی است که ساختار کامل را شامل عنصر <html> تعریف کنید. البته این روش چندان توصیه نمیشود، چون موجب خواهد شد که نشانهگذاری پیچیدهتر شود و ابزارهای قرائت صفحه دسترسپذیری کمتری به جدول داشته باشند. در موارد زیادی میتوان سلول/ردیف/ستونهای بیشتری در همان جدول موجود درج کرد. با این حال در پارهای موارد برای نمونه در صورتی که بخواهید محتوا را به سادگی از منابع دیگر ایمپورت کنید، این وضعیت ناگزیر خواهد بود.
در ادامه کد نشانهگذاری یک جدول تودرتوی ساده را ملاحظه میکنید:
خروجی کد فوق چیزی مانند زیر خواهد بود:
| title1 | title2 | title3 | |||
|---|---|---|---|---|---|
| cell2 | cell3 | |||
| cell4 | cell5 | cell6 |
جداول HTML برای کاربران دچار نقص بینایی
در این بخش شیوه استفاده از جدولهای داده را جمعبندی میکنیم. یک جدول میتواند ابزار کارآمدی باشد و دسترسی سریعی به دادهها بدهد. همچنین امکان بررسی و مقایسه مقادیر مختلف را فراهم میسازد. با صرفاً یک نگاه گذرا به جدول زیر میتوان دریافت که چند عدد حلقه در ماه آگوست اخیر در Gent فروخته شده است. برای درک این اطلاعات باید اتصال دیداری بین دادههای این و هدرهای ردیف و / یا ستونهای آن برقرار کنیم.
| Clothes | Accessories | |||||
|---|---|---|---|---|---|---|
| Trousers | Skirts | Dresses | Bracelets | Rings | ||
| Belgium | Antwerp | 56 | 22 | 43 | 72 | 23 |
| Gent | 46 | 18 | 50 | 61 | 15 | |
| Brussels | 51 | 27 | 38 | 69 | 28 | |
| The Netherlands | Amsterdam | 89 | 34 | 69 | 85 | 38 |
| Utrecht | 80 | 12 | 43 | 36 | 19 | |
اما اگر شما نتوانید آن ارتباطهای دیداری را ایجاد کنید چطور؟ در این صورت چگونه میتوانید یک جدول مانند جدول فوق را بخوانید؟ افراد دچار نقص بینایی غالباً از یک ابزار قرائت صفحه استفاده میکنند که اطلاعات روی صفحه وب را برای آنها میخواند. این وضعیت زمانی که متن ساده باشد هیچ مشکلی ایجاد نمیکند، اما تفسیر یک جدول برای فرد نابینا میتواند چالشی جدی محسوب شود. در هر حال، نشانهگذاری صحیح میتواند آن ارتباطهای دیداری را با ارتباطهای برنامهنویسی شده جایگزین کند.
نکته: بر اساس آمار سازمان بهداشت جهانی در سال 2017، حدود 235 میلیون فرد در دنیا با نوعی نقص بینایی زندگی میکردهاند. در همین راستا در این بخش از مقاله تکنیکهای بیشتری معرفی میکنیم که به کمک آنها میتوانید جدولها را تا بیشترین حد ممکن دسترسپذیر کنید.
استفاده از هدرهای ردیف و ستون
ابزارهای قرائت صفحه همه هدرها را شناسایی میکنند و از آنها برای ایجاد ارتباط برنامهنویسی شده بین هدرها و سلولهایی که با آنها ارتباط دارند کمک میگیرند. ترکیب هدرهای ردیف و ستون میتواند جدول را مانند روشی که فرد بینا جدول را تفسیر میکند، ارائه دهد.
در بخش قبلی (+) این مقاله با روش درج هدر در جدول آشنا شدیم.
خصوصیت scope
مبحث جدیدی که در این مقاله بررسی میکنیم خصوصیت scope است که میتوان با استفاده از عنصر <th> به جدول اضافه کرد. این خصوصیت به ابزارهای قرائت صفحه اعلام میکند که هدر مربوط به کدام سلولها است و آیا هدری برای ردیف یا ستون خاص محسوب میشود یا نه. اگر به مثال سوابق مصارف خود بازگردیم بدین ترتیب میتوانیم بدون هیچ ابهامی هدرهای ستون را به صورت زیر تعریف کنیم:
هر ردیف یک هدر دارد که به صورت زیر تعریف میشود (در صورتی که خواسته باشیم علاوه بر هدر ستون، هدر ردیف نیز اضافه کنیم):
ابزارهای قرائت صفحه نشانهگذاریهایی که به این صورت ساختاربندی شده باشند را شناسایی میکنند و برای نمونه به کاربران خود اجازه میدهند که کل ستون یا ردیف را به صورت یکباره بخوانند.
scope دو مقدار ممکن دیگر نیز دارد که colgroup و rowgroup نام دارند. این مقادیر برای عناوینی استفاده میشوند که روی چندین ستون یا ردیف قرار میگیرند. اگر نگاهی دوباره به جدول Items Sold August 2016 در آغاز این بخش از جدول داشته باشیم، میبینیم که سلول Clothes روی سلولهای rousers ،Skirts و Dresses قرار میگیرند. همه این سلولها باید به صورت هدر <th> نشانهگذاری شوند. از این رو Clothes عنوانی است که در ابتدای جدول قرار میگیرد و سه زیرعنوان دیگر را تعریف میکند. بدین ترتیب Clothes میتواند یک خصوصیت بگیرد، در حالی که سلولهای دیگر دارای خصوصیت scope=”col”هستند.
خصوصیتهای id و headers
یک جایگزین برای استفاده از خصوصیت scope استفاده از خصوصیتهای id و headers برای ایجاد ارتباط بین هدرها و سلولها است. این روش به صورت زیر مورد استفاده قرار میگیرد:
- یک id یکتا به هر عنصر <th> اضافه میشود.
- یک خصوصیت headers به هر عنصر <td> اضافه شود. هر خصوصیت headers باید شامل فهرستی از id-ها برای همه عناصر <th> باشد که به عنوان یک هدر برای سلول عمل میکنند و با فاصله از هم جدا میشوند.
- بدین ترتیب جدول HTML یک تعریف صریح از موقعیت هر سلول در جدول پیدا میکند که به وسیله هدر (های) هر ستون و ردیف که بخشی از آن هستند تعریف میشود و تا حدودی شبیه به یک «صفحه گسترده» (Spreadsheet) است. برای این که این تکنیک به درستی کار کند، جدول باید واقعاً به هر دو هدر ردیف و ستون نیاز داشته باشد.
اگر به مثال «هزینههای مصرفی» بازگردیم، دو قطعه کد قبلی را میتوان به صورت زیر بازنویسی کرد:
نکته: این روش ارتباط بسیار دقیقی بین سلولهای هدر و داده برقرار میکند، اما از نشانهگذاری بسیار زیادی استفاده شده است و هیچ پیشبینی برای خطا وجود ندارد. رویکرد scope برای اغلب جدولها کافی به نظر میرسد.
مثال کاربردی: کار کردن با scope و headers
در این تمرین نهایی ابتدا یک کپی از فایل زیر برداشته و در سیستم خود در فایلی با نام items-sold.html درج کنید.
فایل items-sold.html
همچنین کد زیر را در فایلی با نام minimal-table.css ذخیره کنید:
اکنون تلاش کنید، خصوصیت scope مناسب را اضافه کنید تا جدول به شکل صحیحتری نمایش پیدا کند. در نهایت کپی دیگری از فایلهای اولیه ایجاد کنید و این بار با استفاده از خصوصیتهای id و headers جدول را دسترسپذیر تر بسازید.
نکته: در نهایت کار خود را با دو کد زیر مقایسه کنید:
فایل کامل شده مثال هزینههای مصرفی با استفاده از scope
فایل کامل شده مثال هزینههای مصرفی با استفاده از headers
جمعبندی
چند نکته دیگر نیز وجود دارند که باید در مورد جداول HTML بدانید، اما همه موارد مهمی که تا به این جا واقعاً باید میدانستید در این مقاله ارائه کردهایم. در بخش بعدی این سری مقالات به بررسی روشهای استایلدهی جداول خواهیم پرداخت.
ب
منبع: فرادرس
آموزش سوئیفت (Swift): آشنایی با Getter و Setter — بخش شانزدهم
در بخش قبلی این سری مقالات آموزش زبان برنامهنویسی سوئیفت با کاربرد ژنریکها به همراه بستار و Enum آشنا شدیم. در این بخش قصد داریم از همه این مباحث جدا شویم و در مورد چند موضوع صحبت کنیم که موجب میشوند کد سوئیفت کارایی بیشتری پیدا کند. بدین ترتیب قصد آشنایی با Getter و Setter ،inout و lazy را داریم. برای مطالعه بخش قبلی این مجموعه مطلب آموزشی به لینک زیر رجوع کنید:
inout
Inout کلیدواژهای است که وقتی استفاده میشود که پارامترهایی به تابعها ارسال میشوند. در واقع inout زمانی مورد استفاده قرار میگیرد که بخواهیم یک متغیر را به یک تابع ارسال کنیم و مقدار آن متغیر را بدون ایجاد متغیر جدید تغییر دهیم. در کد زیر با روش تغییر یک مقدار با و بدون inout آشنا میشویم:
هنگامی که یک تابع استاندارد بدون استفاده inout ایجاد شود، متغیر ارسالی «تغییرناپذیر» (immutable) است و امکان اصلاح آن وجود نخواهد داشت. به بیان دیگر به صورت یک ثابت ارسال میشود. کلیدواژه inout امکان تغییر دادن متغیر ارسالی را میدهد، زیرا با ارجاع ارسال شده است و نه با مقدار، چرا که در این صورت باید یک & در ابتدای آن وجود میداشت. اگر میخواهید در این رابطه بیشتر بدانید به مطلب زیر رجوع کنید:
در مثال فوق هنگامی که از یک تابع بدون inout استفاده کنیم، از آنجا که number به (:multiply(number:by ارسال شده است، در واقع به صورت number ارسال نشده است بلکه مقدار کنونی number که 10 است ارسال شده است. آن را میتوان به صورت زیر فراخوانی کرد:
اگر به تابعی که از inout استفاده میکند نگاه کنیم، میبینیم که سه تغییر رخ داده است، نخستین تغییر این است که هیچ نوع بازگشتی وجود ندارد. دوم این که از کلیدواژه در کنار نوع پارامتر استفاده کردهایم (inout Int). تغییر سوم این است که هیچ گزاره return در بدنه تابع ما وجود ندارد.
زمانی که تابع inout را فراخوانی میکنیم مجبور نیستیم که یک مقدار بازگشتی انتساب دهیم، زیرا هیچ مقداری بازگشت نمییابد. به جای آن زمانی که تابع inout را فراخوانی میکنیم، در واقع مکان متغیر را در حافظه ارسال میکنیم. برای این که موضوع روشنتر شود، باید بگوییم که وقتی از &secondNumber استفاده میکنیم، secondNumber به آدرس حافظه 0x01 انتساب مییابد. این وضعیت در عمل به صورت زیر ترجمه میشود:
البته نباید سردرگم شوید، چون وقتی به آدرس 0x01 نگاه میکنیم تا مقدار مورد نظر را ببینیم، همچنان مقدار «عدد دوم» (secondNumber) را میبینیم که 5 است.
درون تابع inout همه چیز به طرز متفاوتی عمل میکند. ما از number *= multiplier برای تغییر مقدار ذخیره شده در آدرس secondNumber استفاده میکنیم، زیرا مقدار را مستقیماً تغییر میدهیم و مقدار تغییر یافته در هر جایی در برنامه که ارجاعی به secondNumber صورت گرفته باشد، اعمال خواهد شد. جنبه مثبت این وضعیت آن است که مصرف حافظه کمی دارد و باید صرفاً نگران این متغیر که شامل مقدار number است نگران باشید.
جنبه منفی این رویکرد برای استفاده از inout آن است که همه انواع ارجاع را ناممکن میسازد. اگر secondNumber را در جایی از برنامه که ارجاع یافته تغییر دهید، ممکن است نخواهید در همه جاهای دیگر مقدار آن تغییر پیدا کند.
به عنوان مثال عملیتر، اگر بخواهیم یک مقدار را در userData فوقالذکر ارسال کنیم که از نوع Data است و شامل برخی اطلاعات باشد که لازم باشد در جای دیگری در اپلیکیشن به آن ارجاع دهیم، آن را به صورت یک پارامتر inout به یک تابع ارسال میکنیم و بدین ترتیب دادهها تغییر مییابند و دادههای اولیه نیز همچنان در موارد نیاز در دسترس خواهند بود. اگر بعدها به userData مراجعه کنیم و انتظار داشته باشیم که همان مقدار را داشته باشد ممکن است متوجه شویم که تغییر یافته است. بهترین حالت این است که اپلیکیشن تغییر را مدیریت کند و موارد مقتضی را بر همین مبنا اجرا کند. بدترین حالت این است که اپلیکیشن به دلیل تهی بودن یک مقدار یا این که نوع داده ذخیره شده در مکان حافظه تغییر یافته است، از کار بیفتد.
استفاده کردن یا نکردن از inout تصمیم شخصی شما است. هر چند این پارامتر گزینه کاملاً امنی محسوب نمیشود، اما بدان معنی نیست که هرگز نباید از آن استفاده کرد. این پارامتر در مواردی که محاسباتی را اجرا میکنید و نمیخواهید به طور پیوسته نتیجه برخی تابعها را هر بار که یک تابع را در محاسبات خود اجرا میکنید به currentResult انتساب دهید، عالی خواهد بود.

Lazy
هنگامی که یک کلاس را ایجاد میکنیم، تقریباً همواره مشخصههایی میسازیم که از سوی آن کلاس استفاده میشود. این مشخصهها میتوانند صرفاً یک فلگ باشند که روشن یا خاموش میشوند تا حالت کنونی کلاس را تعیین کنند و یا میتوانند چیزی بزرگتر مانند یک کلاس دیگر باشند که این کلاس برای اجرای برخی کارها از آن بهره میگیرد. به مثال زیر توجه کنید:
این مثال چیز بزرگی به نظر نمیرسد، با استفاده از این کلاس در واقع از یک CLLocationCoordinate2d برای نمایش مکانی روی نقشه استفاده میکنیم.
اگر بخواهید بدانید CLLocationCoordinate2d چیست، باید بگوییم که یک struct شامل طول و عرض جغرافیایی مکان به همراه برخی متدهای ساده است. هم طول و هم عرض جغرافیایی به صورت CLLocationDegrees هستند که صرفاً یک «نوع مستعار» (typealias) برای این نوع Double محسوب میشود. به بیان سادهتر CLLocationCoordinate2d یک روش برای ارائه دو مقدار Double است که مکانی را روی نقشه تعیین میکنند و در مجموع بسیار سبک است.
در سوی دیگر MKMapView، حافظه زیادی اشغال میکند. فقط بارگذاری یک نقشه و بزرگنمایی به یک مختصات باعث مصرف چندین مگابایت از حافظه میشود. زمانی که از یک نقشه در برنامههای خود استفاده میکنیم، تقریباً 2000 annotation بارگذاری میشود و هنگامی که کمی در نقشه بگردیم مصرف حافظه تا 430 مگابایت افزایش پیدا میکند. پس چنان که میبینید نماهای نقشه تا حدودی پرهزینه هستند. همان طور که حدس میزنید این نمای نقشه همان نمایی است که هنگام باز کردن اپلیکیشن Maps در گوشی خود مشاهده میکنید.
خبر خوب این است که iPhone-ها و iPad-ها امروزه چندین گیگابایت حافظه دارند و لذا این مسئله چندان بزرگ به حساب نمیآید، اما با این حال همچنان میتوان این وضعیت را بهینهسازی کرد. این همان جایی است که مشخصههای با ذخیرهسازی Lazy به کار میآیند.
سناریویی را تصور کنید که یک «نما» (view) در اپلیکیشن خود داریم و این نما میتواند یک نقشه را نمایش دهد یا ندهد. اگر نقشه را نمایش ندهد قطعاً دوست نداریم صدها مگابایت داده را در حافظه بارگذاری کنیم، اما همچنان میخواهیم که بتوانیم در صورت نیاز نقشه را در اپلیکیشن خود و همچنین در تابعهایی دیگری که نما را مالکیت میکنند داشته باشیم. در مثال زیر طرز کار این رویکرد را میتوانید ملاحظه کنید:
کلیدواژه lazy در ابتدای ()var mapView = MKMapView جایی است که بخش اصلی داستان اتفاق میافتند. این کلیدواژه به برنامه اعلام میکند که آماده شود چون ممکن است mapView در این نما استفاده شود. زمانی که زمان استفاده از نمای نقشه فرا برسد، کد ایجاد آن به صورت فوق خواهد بود.
در ادامه کد میبینیم که وقتی کاربر روی یک دکمه برای نمایش نقشه ضربه بزند، ()createView را فراخوانی میکنیم. این متد شامل منطقی است که در پشت صحنه نوشتهایم تا نمایی را که نقشه را نمایش میدهد به نمای جاری اضافه کنیم. زمانی که از (view.addSubview(mapView استفاده میکنیم، کد mapView فراخوانی میشود که mapView را ایجاد میکند و در صورت نیاز میتوانیم تابعها را روی mapView فراخوانی کنیم.
اگر این نما ایجاد نشده باشد و یک تابع را روی mapView فراخوانی کنیم، mapView در آن زمان ایجاد خواهد شد. بنابراین Lazy اساساً ایجاد mapView را تا زمانی که واقعاً ضروری باشد به تعویق میاندازد. مشخصههای Lazy میتوانند به صورت «بستار» (closure) ها نیز باشند. در واقع این حالتی است که عموماً مورد استفاده قرار میگیرند و بدین ترتیب از محاسبات اضافی تا زمانی که واقعاً ضروری نباشد جلوگیری میکنند. این حالت را در پشته Core Data به طور مکرر مشاهده میکنید. با این حال اگر از چیزی سر در نیاوردید لازم نیست، نگران باشید، چون فعلاً روی lazy تمرکز داریم.
کانتینرهای دائمی ممکن است لازم باشند یا نباشند؛ اما لازم نیست آنها را از همان ابتدا مستقیماً ایجاد کنیم. به جای آن صبر میکنیم تا زمانی فرا رسد که قبل از ایجاد کردن آن، عملاً لازم باشد که دادهها را در پایگاه داده ذخیره یا از آن بارگذاری کنیم. بدین منظور از یک closure استفاده میکنیم که کانتینر دائمی را با کمترین مراحل مورد نیاز برای ایجاد کانتینر ایجاد کند.
استفاده از Lazy زیبا است و غالباً باید در جاهایی استفاده شود که مفید باشد. نباید نگران باشید که رویههای ساده با استفاده از Lazy پیچیده میشوند، چون در هر صورت امکان Lazy ساختن ثابتها وجود ندارد. اگر تلاش کنید یک ثابت را به صورت Lazy تعریف کنید، Xcode شما را مأیوس خواهد کرد.

Getter و Setter
Getter-ها و Setter-ها بخشی از «مشخصههای محاسبه شده» (Computed Properties) هستند. آنها خویشاوند نزدیک مشاهدهگرهای مشخصه به نام didSet و willSet محسوب میشوند. چنان که احتمالاً به خاطر دارید didSet و willSet جهت اجرای وظایف اضافی در زمان تغییر یافتن یک مشخصه محاسبه شده استفاده میشوند. Getter-ها و Setter-ها منطقی در اختیار ما قرار میدهند که میتوانیم برای تعیین یک مقدار یا بازیابی آن مورد استفاده قرار دهیم. به مثال زیر توجه کنید:
در مثال فوق، number پیادهسازی پیشفرض get و set را ارائه میکند که در صورت عدم اضافه شدن { get set } به انتها میتوانستیم داشته باشیم. تنها دلیل استفاده از آنها روشنتر شدن موضوع بوده است. حفظ انسجام کد همواره خوب است و اگر مشخصهای دارید که تنها get دارد، در این صورت بهتر است { get set } را روی مشخصههایی اضافه کنید که قابلیت get و set داشته باشند.
زمانی که تنها از { get } استفاده میکنیم در واقع صرفاً امکان بازیابی مقدار را داریم و نمیتوانیم مقدار را تعیین کنیم. این وضعیت مشابه یک ثابت است، گرچه عموماً محاسبه مشخصههای دیگر را نیز بازگشت میدهد. در ادامه چند مثال را میبینید که در آنها میتوان از { get } استفاده کرد.
در مثال فوق ما یک نرخ ساعتی و همچنین تعداد ساعتهای کارکرد را داریم که با استفاده از دستورهای زیر قابل تعیین هستند:
سپس میتوانیم دریافتی کارمند را با استفاده از دستور زیر به دست آوریم:
در ادامه مثالی پیچیدهتر را بررسی میکنیم.
در کد فوق چند فاصله اضافی درج کردهایم تا خوانایی بهتری داشته باشد. در این مثال یک setter خصوصی در ابتدای (private(set داریم. بدین ترتیب مطمئن میشویم که مقدار صحیحی تعیین شده است. ما هرگز یک «دریافتی» (earnings) منفی یا 0 نخواهیم داشت، بنابراین میتوانیم مطمئن باشیم که earnings مقدار مثبتی دارد و این که قبل از تعیین مقدار واقعی earnings و hoursWorked مقداری کارکرد داشتهایم. سپس از setter مربوط به earnings برای بهروزرسانی مقدار hourlyRate استفاده میکنیم.
این کد برای بهروزرسانی دریافتیها از کارمندان و تعداد ساعتهای کارکرد استفاده میشود، اما اگر یک کارمند اضافهکاری داشته باشد چطور؟ در این حالت میتوانیم یک مورد دیگر به صورت زیر بسازیم:
اما این بدان معنی است که باید به خاطر بسپاریم آیا hoursWorked یا hourlyRate را تنظیم کردهایم یا نه و بنابراین میتوانیم بررسی کنیم که کدام مورد نیازمند بهروزرسانی است.
اگر در موقعیتی مانند این قرار گرفتید، احتمالاً استفاده از getter و setter ایده بدی خواهد بود و به جای آن میتوانید از مشاهدهگر مشخصه به نام didset برای هر دو متغیر hoursWorked و hourlyRate استفاده کنید. در این حالت همچنان میتوان دریافتیها را در یک setter خصوصی نگهداری کرد، اما استفاده نکردن از setter خصوصی برای بهروزرسانی مقادیر در عمل آسانتر است.
از کد فوق استفاده کنید و ببینید آیا میتوانید آن را به نحوی بازسازی و اصلاح کنید که بتوان از دو تابع برای بهروزرسانی دریافتیها و ساعتهای کاری یا نرخ دستمزد استفاده کرد. به این ترتیب struct کارمند قابلیت استفاده بیشتری مییابد. حتی میتوان از آن برای محاسبه تغییرها برای پرداختهای شخصی نیز استفاده کرد. برای نمونه با افزودن یک فلگ isPaidHourly میتوان ساعتها را در صورت false بودن به صورت خودکار روی 40 تنظیم کرد و متدی برای بهروزرسانی کارگران مزدبگیر داشت.
نکته: با این که میتوان از optional-ها و اعلان متدی مانند زیر استفاده کرد:
اما بهتر است آن را به چند بخش تقسیم کنید تا بهروزرسانی هدفمندتری در مورد مقدار و یا ساعتهای کاری یا نرخ دستمزد داشته باشید و اجازه دهید مشاهدهگرهای مشخصه به جای شما عمل بهروزرسانی را اجرا کنند.
روش دیگر این است که از setter-های خصوصی از طریق مشخصههای محاسبه شده استفاده کنید. بدین ترتیب برای مثال زمانی که لازم میشود مجذور عددی محاسبه شود با تعیین عدد، به صورت خودکار مربع آن محاسبه خواهد شد.
جمعبندی
ما در این مقاله با مفاهیم inout ،lazy و get و set آشنا شدیم. همچنین روش استفاده از آنها و بهترین کاربردشان را دیدیدم. Inout زمانی استفاده میشود که بخواهیم یک مقدار را با ارجاع ارسال کنیم. اپل در مستندات خود (+) یک راهنما در مورد این موضوع منتشر کرده است.
Lazy زمانی استفاده میشود که بخواهیم یک مقداردهی با تأخیر برای هر چیزی داشته باشیم که شاید همیشه در زمان بارگذاری یک کلاس یا struct مورد استفاده قرار نمیگیرد. برای کسب اطلاعات بیشتر در این خصوص میتوانید به این صفحه از مستندات اپل (+) مراجعه کنید.
از مشخصههای محاسبه شده زمانی استفاده میشود که بخواهید نوعی از کار را پس از بازیابی یا تعیین یک مقدار اجرا کنید. همچنین کاربرد دیگر آن زمانی است که بخواهید تعیین یک متغیر را به صورت عمومی رد کنید و مطمئن شوید که مقدار آن برای کاربردی که طراحی شده مناسب است. برای کسب اطلاعات بیشتر در این مورد نیز میتوانید به این صفحه (+) از مستندات مراجعه کنید. بدین ترتیب به پایان بخش شانزدهم از این سری مقالات آموزشی میرسیم. تنها دو بخش از این سری باقی مانده و یک خبر خوب و یک خبر بد برای شما داریم.
ابتدا خبر خوب را میگوییم، شما اینک با همه مبانی مقدماتی ایجاد یک اپلیکیشن و انتشار آن در اپاستور آشنا شدهاید. اما خبر بد این است که نباید تلاش کنید تا یک اپلیکیشن را در اپاستور منتشر کنید، چون شما جنبه بسیار مهمی از انتشار اپلیکیشن را هنوز نیاموختهاید. در مطلب ابتدایی این سری در مورد مراحل مختلف و چرخه عمر توسعه یک اپلیکیشن صحبت کردیم. درست پس از توسعه اپلیکیشن وارد سه فاز میشویم که هدف همه آنها آزمودن کارکرد اپلیکیشن است.
در مراحل بعدی در مورد تست کردن اپلیکیشن صحبت خواهیم کرد. تست کردن با اختلاف زیادی مهمترین کاری است که باید در اپلیکیشن انجام دهید. البته نوشتن کد نیز مهم است؛ اما اگر اپلیکیشن شما طراحی شده باشد تا کاری را انجام دهد و نتواند آن کار را انجام دهد، همه تلاشهای شما بیثمر خواهد بود. بنابراین انتشار بیدرنگ اپلیکیشن کار اشتباهی است و ابتدا باید آن را تست کرد. برای مطالعه بخش بعدی به لینک زیر مراجعه کنید:
منبع: فرادرس
الگوریتم بازی مار و پله همراه با کد — به زبان ساده
بازی مار و پله (Snakes and Ladders)، یک بازی باستانی هندی است که اکنون یک بازی کلاسیک جهانی محبوب محسوب میشود. این بازی قابل انجام بین دو یا تعداد بیشتری بازیکن است. صفحه بازی مار و پله، شطرنجی است؛ در این بازی، در برخی از خانهها نردبانهایی وجود دارد که فرد را به خانههای بالاتر میرساند و در بعضی از خانهها، مارهایی وجود دارد که فرد را اصطلاحا نیش میزنند و به خانههای پایینتری انتقال میدهند (جایی که دم مار در آن قرار دارد). بازی به این صورت انجام میشود که هر بازیکن تاس میاندازد و با توجه به عددی که میآید، تعداد خانههایی را به جلو حرکت میکند. بسته به عدد تاس، ممکن است فرد در یک خانه عادی، دارای نربان و یا دارای مار قرار بگیرد. در «مساله مار و پله» (Snake and Ladder Problem)، هدف پیدا کردن کمترین تعداد دفعات پرتاب تاس لازم برای رسیدن به مقصد (آخرین خانه در صفحه شطرنجی) از مبدا (اولین خانه) است. این مساله کمی با بازی تختهای متداول مار و پله که افراد بازی میکنند متفاوت است و در آن، بازیکن بر عددی که در پرتاب تاس به دست میآید کنترل دارد و باید اعدادی را پیدا کند که با کمترین تعداد پرتاب تاس به خانه نهایی برسد. در ادامه، الگوریتم بازی مار و پله (در واقع الگوریتم لازم برای حل این مساله) ارائه و پیادهسازی آن در زبانهای برنامهنویسی «پایتون» (Python)، «جاوا» (Java)، «سیپلاسپلاس» (++C) و «سیشارپ» (#C) انجام شده است.
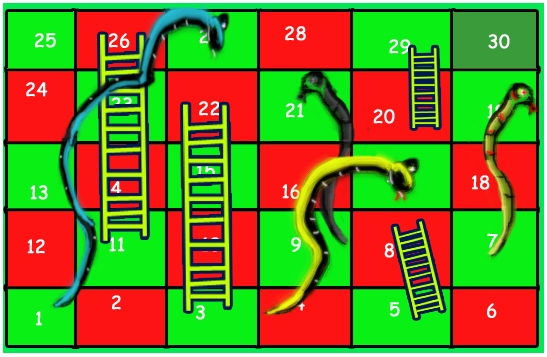
الگوریتم بازی مار و پله
برای مثال، در صفحه بازی موجود در تصویر بالا، تعداد پرتابهای تاس لازم برای رسیدن از خانه ۱ به خانه ۳۰ برابر با سه است. گامهای زیر برای آنکه بازیکن با سه پرتاب تاس به نتیجه برسد انجام میشود.
- ابتدا تاس دو انداخته میشود تا بازیکن از خانه یک به خانه سه برود و با استفاده از نردبان به خانه ۲۲ برسد.
- سپس، تاس ۶ انداخته میشود تا فرد از خانه ۲۲ به خانه ۲۸ برسد.
- در نهایت، با انداختن تاس ۲، بازیکن به خانه ۳۰ (مقصد نهایی) میرسد.
برخی از دیگر راهکارهای موجود برای حل مساله مار و پله (با کمترین تعداد پرتاب تاس) عبارتند از: (2, 2, 6)، (2, 4, 4) و (2, 3, 5).
ایده موجود برای حل این مساله در حالت کلی آن است که صفحه بازی به صورت یک گراف جهتدار در نظر گرفته شود. اکنون، مساله یافتن کوتاهترین مسیر در گراف است. هر «راس» (Vertex) از گراف، دارای «یالی» (Edge) به شش راس بعدی است؛ اگر راسهای بعدی دارای نردبان یا مار نباشند. اگر هر یک از شش راس دارای مار یا نردبان باشند، یال از راس کنونی به راس بالای نردبان یا دم مار متصل میشود. با توجه به اینکه همه یالها دارای وزنهای برابری هستند، میتوان کوتاهترین مسیر را با استفاده از «جستجوی اول عمق» (Breadth First Search) کشف کرد. در ادامه، پیادهسازی ایده بالا با استفاده از زبانهای برنامهنویسی گوناگون انجام شده است. ورودی با دو چیز نمایش داده شده است: N که تعداد خانههای صفحه بازی است و آرایه [move[0…N-1 با اندازه N. یک ورودی [move[i برابر با ۱- است اگر هیچ مار یا نردبانی از i وجود نداشته باشد؛ در غیر این صورت، [move[i حاوی اندیس سلول مقصد برای مار یا نردبان در i است.
پیاده سازی الگوریتم بازی مار و پله در ++C
پیاده سازی الگوریتم بازی مار و پله در پایتون
پیاده سازی الگوریتم بازی مار و پله در جاوا
خروجی:
Min Dice throws required is 3
پیچیدگی زمانی راهکار بالا از درجه (O(N است؛ زیرا هر سلول تنها یکبار به «صف» (Queue) اضافه و کم میشود و یک فرایند معمول افزودن به صف یا حذف کردن از آن از درجه زمانی (O(1 است.
منبع: فرادرس
آموزش پایتون با ساخت اپلیکیشن های واقعی
پایتون یک زبان برنامهنویسی سطح بالا و نسبتاً جدید محسوب میشود؛ عمده شهرت و محبوبیت این زبان برنامهنویسی به دلیل ساختار سادهاش است که موجب شده هم یادگیری آسانی داشته باشد و هم در میان حوزههای مختلفی از علوم که نیاز به محاسبات و برنامهنویسی دارند نفوذ گستردهای پیدا کند. در این مطلب به جمعبندی سری مقالات آموزش پایتون مجله فرادرس پرداختهایم.
چنان که پیشتر در مقاله «برترین و محبوبترین زبانهای برنامهنویسی در سال 2۰1۸» در مجله فرادرس دیدیم، زبان پایتون با در نظر گرفتن شاخصهای مختلف در رتبه سومین زبان محبوب در طی سال گذشته قرار گرفته است.
کاربردهای این زبان برنامهنویسی چندمنظوره چنان متنوع هستند که امروزه در هر جایی از علوم داده تا برنامهنویسی بکاند اپلیکیشنها میتوان آن را مشاهده کرد. بسیاری از افراد حتی آن را به عنوان جایگزینی برای پکیجهای نرمافزاری از قبیل matlab مورد استفاده قرار میدهند. در هر حال قدر مسلم این است که پایتون با سرعت بالایی در حال رشد و نفوذ در حوزههای مختلف برنامهنویسی است و انتظار میرود در سالهای آتی حتی بر این محبوبیت گسترده نیز افزوده شود.
فهرست مقالات آموزش پایتون با ساخت اپلیکشین های واقعی
ما در مجله فرادرس در طی ماههای اخیر 9 مطلب پروژه محور در زمینه معرفی کاربردهای مختلف زبان برنامهنویسی پایتون منتشر کردهایم که در آنها با طرح یک مسئله و حل کردن آن، طرز استفاده عملی از این زبان برنامهنویسی را نشان دادهایم. در ادامه فهرستی از این مطالب و خلاصهای از شرح کار هر کدام را ملاحظه میکنید.
نخستین اپلیکیشن پایتون که توسعه دادیم یک اپلیکیشن دیکشنری است. در این آموزش با روش کار با دادهها در قالب JSON و همچنین طرز تبدیل آنها به رشته و تابعهای مختلف پایتون برای کار با رشتهها آشنا شدیم. ما در این آموزش موفق شدیم امکانات پیشرفتهای برای تصحیح خطاهای کاربر در هنگام وارد کردن کلمه و جستجوی آن طراحی کنیم.
بخش دوم آموزش پروژه محور پایتون اختصاص به طراحی یک وب اپلیکیشن برای نمایش نقشه دارد. مهمترین نقطه قوت پایتون این است که برای هر کاری دهها کتابخانه آماده وجود دارد که میتوانید از آنها استفاده کنید. ما در این آموزش برای نمایش نقشه از کتابخانه Folium کمک میگیریم. بدین ترتیب یا مراحل نصب کتابخانه، افزودن نشانگر منفرد و چندگانه، تغییر رنگ نشانگرها و آیکونها و بارگذاری نقشه بسته به موقعیت آشنا میشویم.
در بخش سوم مجموعه مقالات آموزش پروژه محور پایتون در مجله فرادرس با روش ساخت یک مسدودکننده وبسایت آشنا میشویم. این مسدودکنندها در محیطهای سازمانی و یا مدارس بسیار مفید هستند و از دسترسی کاربران به برخی وبسایتها جلوگیری میکنند. بدین منظور با مفهوم فایل hosts در سیستمهای عامل مختلف آشنا میشویم. همچنین مقداری کدنویسی میکنیم تا بتوانیم قواعد خاصی را روی شبکه محلی کاربر پیادهسازی کنیم.
در بخش چهارم مجموعه مقالات آموزش پایتون از کتابخانه Flask در این زبان برنامهنویسی به منظور طراحی یک وبسایت استفاده میکنیم. این کتابخانه در واقع یک میکرو فریمورک برای طراحی فرانتاند است. این کتابخانه به طور عمده به همراه پایگاه داده MongoDB استفاده میشود که کنترل بیشتری روی پایگاه داده و سابقه کارها ایجاد میکند. پس از طراحی وبسایت آن را روی پلتفرم Heroku منتشر میکنیم. به این منظور نیاز به برخی پیکربندیهای خاص داریم که آنها نیز به طور کامل توضیح داده شدهاند. در نهایت ما با چند گام ساده موفق خواهیم شد یک وبسایت ابتدایی را به صورت آنلاین داشته باشیم.
در ادامه سری مطالب آموزش پایتون با ساخت اپلیکیشن های واقعی در مجله فرادرس در بخش پنجم آن یک اسکریپت پایتون مینویسیم که برای تحلیل احساسات توییتر افراد مختلف در مورد یک موضوع خاص استفاده میشود. بدین منظور از یک کتابخانه «پردازش زبان طبیعی» (Natural Language Processing) به نام TextBlob استفاده شده است. سادگی کار با کتابخانههای پایتون حیرتانگیز است به طوری که در این راهنما صرفاً با نوشتن 15 خط کد موفق شدهایم، یک اپلیکیشن تحلیل احساسات در پایتون بنویسیم.
وب اسکرپینگ یکی از حوزههای بسیار مهم در رشته علوم داده محسوب میشود. اهمیت این حوزه از آن جهت است که در اغلب موارد دادههایی که ما نیاز داریم به طور آماده و تمیز در اختیار ما قرار ندارند، بلکه باید آنها را گردآوری و پاکسازی کنیم. در این مقاله با روش گشتن در میان صفحههای وب و گردآوری و استخراج دادههای مطلوب آشنا میشویم. به این منظور از کتابخانه BeautifulSoup پایتون استفاده شده است.
در بخش هفتم این سری مقالات آموزش پایتون با ساخت اپلیکیشنهای واقعی با روش طراحی فرانتاند یک وبسایت ساده و انتشار آن روی Heroku آشنا شدیم. در این مطلب میخواهیم روی بکاند وبسایت و طراحی پایگاه داده آن متمرکز شویم. بدین منظور از Flask استفاده میکنیم. Flask یک میکرو فریمورک برای توسعه وب است و در اغلب موارد در زمان کار با پایگاه داده نیز استفاده میشود. ما در این مقاله یک صفحه وب ایجاد میکنیم که با استفاده از آن میتوانیم ورودی کاربر را بگیریم و آن را در پایگاه داده ذخیره کنیم.
در بخش هشتم از این سری مقالات آموزش پروژه محور پایتون به معرفی کتابخانه OpenCV میپردازیم. این کتابخانه مشهور پایتون به منظور پیادهسازی الگوریتمهای بینایی ماشین طراحی شده است. با استفاده از OpenCV میتوانید اپلیکیشنهای مختلفی برای تشخیص چهره و موارد دیگر بنویسید. در این بخش با روشهای بارگذاری تصاویر، تغییر اندازه تصاویر و تشخیص چهره در تصاویر و ویدئوهای زنده آشنا خواهیم شد.
اپلیکیشنهای مالی بخش بزرگی از حجم اپلیکیشنهای تولیدشده در دنیا را تشکیل میدهند. پایتون نیز به عنوان یک زبان برنامهنویسی چندمنظوره از این بازار بینصیب نمانده است در این مقاله با کتابخانه Bokeh آشنا میشویم که به منظور طراحی و رسم نمودارهای مالی مورد استفاده قرار میگیرد. این راهنما به توضیح انواع گوناگون نمودارهای مالی و اصطلاحهای مربوطه پرداخته است.
سخن پایانی
زبان برنامهنویسی پایتون چنان که اشاره شد به عنوان یک زبان سطح بالا و چندمنظوره در عرصههای مختلف محبوبیت زیادی کسب کرده است. شما با مطالعه سری مقالات فوق تقریباً با اکثر این حوزهها آشنا میشوید. یکی از بزرگترین دلایل رشد روزافزون محبوبیت پایتون ابتدا سادگی ساختار و دستور زبان آن و در وهله دوم وجود جامعه کاربری بسیار پویا و کتابخانههای مختلف است. همانگونه که در سری مقالات فوق مشاهده کردید، برای بسیاری از امور در پایتون لازم نیست از صفر شروع به کدنویسی بکنید، چون حتماً یک کتابخانه آماده وجود دارد که بخش زیادی از دشواری کار را از روی دوش شما بر دارد.
منبع: فرادرس