طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیخطایابی نرم افزار — پادکست پرسش و پاسخ
بسیاری از افراد هنگام برنامهنویسی و یا کار با نرمافزارهای گوناگون با خطاها و مشکلاتی مواجه میشوند. رفع این خطاها و مشکلات، به دغدغه مهمی برای فرد مبدل میشود؛ اما بعضا از راهکار مناسب برای درک چرایی مشکل و رفع آن آگاه نیستند و استفاده نمیکنند. دکتر «سید مصطفی کلامی هریس»، در پادکستی که در ادامه آمده، به موضوع خطایابی نرم افزار پرداختهاند. نسخه متنی این پادکست نیز در همین مطلب قرار دارد. البته، منبع اصلی همچنان فایل صوتی محسوب میشود.
پادکست پیرامون خطایابی نرم افزار
ذخیره کردن این فایل صوتی: لینک دانلود
نسخه نوشتاری
یکی از موضوعات مهمی که من همیشه در دورههای آموزشی برنامهنویسی، در آموزشهای گوناگون، در هر کلاس درسی و به طور کلی در هر جایی که فرصت بوده به آن اشاره میکنم این است که کاربر با هر نرمافزاری که کار میکند – مثلا «متلب» (MATLAB) یا هر کامپایلری – ممکن است در هر جا خطایی به کاربر نمایش داده میشود. این متن خطا مهمترین چیزی است که فرد باید در آن لحظه بخواند. خیلی وقتها پاسخ کاربر و پاسخ اشکال موجود، در همانجا است. یعنی مثلا در متن خطا گفته شده این کار را باید انجام دهید و واقعا با انجام همان کار مشکل حل میشود.
مواقعی نیز وجود دارد که در متن پیام خطا کار خاصی توصیه نشده، ولی با مطالعه همان متن و جستجوی آن در گوگل میتوان به نتیجه رسید؛ زیرا افراد زیادی با خطای مشابهی مواجه شدهاند و پرسش خود پیرامون آن را مطرح کردهاند و یک عده از افراد نیز به این پرسشها پاسخ دادهاند و یا بلاخره در سایت سازنده همان نرمافزار یا زبان برنامهنویسی این موضوع به بحث گذاشته شده که چطور میتوان این خطا را رفع کرد. به همین دلیل، این موضوع بسیار حائز اهمیت است. اولا، کاربر یک سری چیزهایی یاد میگیرد، زیرا متن خطا ممکن است حاوی مطلب مهمی باشد و اغلب با رنگ قرمز و علامت هشداری نمایش داده میشود تا توجه فرد را به طور کامل به خود جلب کند. ولی متاسفانه بسیاری از افراد و شاید بیش از نود درصد افراد اصلا این پیغام را نمیخوانند و مشکلات نیز از همین امر نشات میگیرد. این افراد معمولا میگویند برنامه ما به مشکل بر خورده است. برای مثال در طول یک هفته بیش از بیست نفر به من پیام دادهاند و گفتهاند که برنامه آنها به مشکل برخورد کرده است. اما متن خطا را نمیخوانند؛ در حالیکه بسیاری از مواقع، جواب سوال و راهکار مشکل آنها همانجا است.
این یک مشکل خیلی شایع است و فکر میکنم لازم است این روحیه ایجاد شود که اول خطا را بخوانیم و خودمان سعی کنیم مشکل را حل کنیم و اگر نشد، متن خطا را در گوگل جستجو کنیم. به این شکل، اولا فرد چیزهایی میآموزد که در هیچ کتاب و کلاس درسی به او یاد نمیدهند. دوما، همین تعامل با نرمافزار و جستجوها است که موجب عمیق شدن دانش فرد میشود. این را اگر مد نظر داشته باشیم، خیلی چیزها بهتر و سریعتر حل میشوند و یک موضوع دیگر هم این است که بدین شکل سرعت کار فرد بالا میرود و ضمنا بعد از مدتی مهارتی در فرد ایجاد میشود که نه تنها مشکلات او را حل میکند، بلکه موجب میشود تا بتواند به دیگران نیر کمک کند. این موضوع بسیار مهمی است و به طور کل، موضوع ارزشمندی است که دانش خیلی ارزشمندی را فرد با بهرهگیری از آن به دست میآورد.
یعنی بحث ماهیگیری که در ضرب مثلها میگویند همین است. بدین شکل فرد واقعا ماهیگیری را یاد میگیرد. واقعا این روحیه به افراد چیزهای زیادی را میآموزد. سعی کنید این ویژگی را حتما پرورش بدهید. فکر میکنم برای افرادی که کار برنامهنویسی انجام میدهند، شروع آن با خواندن متن خطا است. همین مورد اگر رعایت شود، فکر میکنم خیلی از مشکلات برای بسیاری از افراد حل خواهد شد.
برای دانلود کردن و شنیدن دیگر پادکستهای دکتر سید مصطفی کلامی هریس در مجله فرادرس، روی این لینک [+] کلیک کنید.
منبع: فرادرس
آرگومان های پیش فرض در ++C — به زبان ساده
در این مقاله با معنی آرگومان های پیش فرض و روش استفاده از آنها و اعلانهای ضروری برای کاربردشان آشنا میشوید. در برنامهنویسی ++C میتوانید مقادیر پیشفرض را برای پارامترهای تابع ارائه کنید.
ایده تشکیلدهنده آرگومان پیشفرض ساده است. اگر تابعی به وسیله آرگومان(های) ارسالی فراخوانی شود آن آرگومانها از سوی تابع استفاده میشوند. اما اگر آرگومان(ها) در زمان فراخوانی یک تابع ارسال نشوند، در این صورت مقادیر پیشفرض مورد استفاده قرار میگیرند. مقادیر پیشفرض در پروتوتایپ تابع به آرگومانها ارسال میشوند. برای مطالعه بخش قبلی این مجموعه مطلب آموزشی روی لینک زیر کلیک کنید:
کار کردن با آرگومانهای پیشفرض

مثال
در ادامه به یک مثال در همین رابطه میپردازیم.
آرگومان پیشفرض
خروجی
No argument passed: * First argument passed: # Both argument passed: $$$$$
در برنامه فوق، میتوانید مقدار پیشفرض انتساب یافته به آرگومانها را ببینید:
در ابتدا، تابع ()display بدون ارسال هیچ پارامتری فراخوانی میشود. در این حالت، تابع ()display از هر دو آرگومان c = * و n = 1 استفاده میکند.
سپس در دفعه دوم تنها آرگومان نخست با استفاده از تابع ارسال میشود. در این حالت، تابع از مقدار پیشفرض نخست ارسالی استفاده نمیکند. بدین ترتیب از پارامتر واقعی ارسالی به عنوان آرگومان نخست # = c استفاده میکنیم و مقدار پیشفرض n=1 به عنوان آرگومان دوم میگیرد.
زمانی که ()display برای بار سوم فراخوانی میشود، هر دو آرگومان ارسال میشوند، آرگومانهای پیشفرض مورد استفاده قرار نمیگیرند. بنابراین مقدار $ = c و n=5 استفاده میشوند.
خطاهای رایج هنگام استفاده از آرگومان پیشفرض
در این حالت، c و d نیز باید مقادیر پیشفرض بگیرند. اگر میخواهید یک آرگومان پیشفرض منفرد داشته باشد، باید مطمئن شوید که آرگومان به عنوان آخرین مورد است.
مهم نیست که از آرگومانهای پیشفرض چگونه استفاده میکنید، چون یک تابع باید همواره طوری نوشته شود که تنها یک منظور را اجرا کند.
اگر تابع شما با بیش از یک چیز یا منطق پیوند دارد، بیش از حد پیچیده محسوب میشود و بهتر است که از overload کردن تابع برای جداسازی منطق بهره بگیرید.
منبع: فرادرس
آشنایی با آپاچی اسپارک (Spark) و پایتون — راهنمای مقدماتی
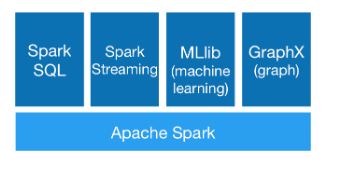
آپاچی اسپارک یک فریمورک متن-باز است که از زمان معرفیاش در AMPLab در دانشگاه برکلی در سال 2009 موج بزرگی راه انداخته است، چون هسته مرکزی آن یک موتور پردازش توزیعیافته کلانداده است که میتواند به خوبی مقیاسبندی شود.
مقدمهای بر آپاچی اسپارک
به بیان ساده با رشد دادهها، امر مدیریت دادههای استریمینگ بزرگ و توانایی پردازش و اجرای عملیات دیگر مانند یادگیری ماشین، ضرورت یافته و آپاچی اسپارک نیز این کار را به خوبی انجام میدهد. برخی کارشناسان میگویند که آپاچی اسپارک در آیندهای نزدیک به یک پلتفرم آماده برای محاسبات استریم تبدل میشود.
اغلب افراد دچار این سوءتفاهم هستند که اسپارک جایگزینی برای هادوپ (Hadoop) است، اما باید بدانند که اسپارک تنها یک رقیب برای فریمورک map-reduce هادوپ محسوب میشود. بدین ترتیب با توجه به سریعتر بودن اسپارک یکی از کوتاهترین مسیرهای یادگیری را برای توسعهدهندگان دارد و با در نظر گرفتن این نکته که از سوی شرکتهای بزرگی در بازار استفاده میشود، یک مهارت ساده و مؤثر جهت ارتقا در رزومه هر توسعهدهندهای به حساب میآید.
چنان که در ادامه خواهیم دید، پردازش توزیعیافته یکی از قابلیتهای کلیدی اسپارک است، اما تنها قابلیت آن نیست.
از آنجا که اسپارک بسیار محبوب است، میتوان انتظار داشت که ارائهدهندگان مختلفی به عرضه سرویسهای اسپارک به روشهای مختلف بپردازند. برخی اوقات گزینههایی که وجود دارند بسیار گسترده و سردرگمکننده هستند، بنابراین هیجان و شوق برای یادگیری یک چیز جدید در تلاش برای یافتن گزینهای صحیح از دست میرود.
نکته قابل توجه
در این مقاله، ما به برسی مشخصههای اسپارک و شیوه استفاده از آن برای استریم کردن دادهها نمیپردازیم. به جای آن به ارائه فهرستی از گزینههای ممکن برای آغاز به کار با اسپارک میپردازیم. سپس انتخاب را بر عهده شما میگذاریم تا ماجراجویی خود را آغاز کنید.
پیشنهاد میکنیم پیش از تلاش برای امتحان کردن گزینههای معرفی شده، این مقاله را به طور کامل تا انتها بخوانید. ایده کار این است که گزینههای موجود را درک کنید و سپس گزینهای را که به بهترین وجه نیازهای شما را برآورده میسازد انتخاب کنید و به کار با آن بپردازید.
1. نصب لوکال
نخستین گزینهای که وجود دارد تنظیم لوکال اسپارک است. اگر طرفدار سرویسهای آنلاین نیستید، میتوانید از این گزینه استفاده کنید. در محیط لوکال شما کنترل کاملی روی همه چیز دارید، اما به خاطر داشته باشید که این مسیر زمانبر است.
اگر زمان برایتان مهم است و حوصله سر و کله زدن با نصب موارد مختلف را ندارید، بهتر است از دردسر دوری کنید و به گزینههای 2 و 3 این مقاله مراجعه نمایید.
آن چه برای نصب لوکال نیاز دارید یک نرمافزار Virtual Box، سیستم اوبونتو و زمان و صبر به مقدار کافی است.
Virtual Box (+) اپلیکیشنی است که امکان اجرای یک رایانه مجازی روی سیستم را به شما میدهد. این جایی است که ما اوبونتو، یک سیستم عامل مبتنی بر لینوکس و اسپارک را نصب خواهیم کرد. اگر هم اینک از سیستم اوبونتو استفاده میکنید میتوانید این مرحله را رد کنید.
نرمافزار Virtual Box را از این لینک (+) دانلود کنید و میزبان را بسته به سیستم عامل خود ویندوز یا OS X انتخاب نمایید. زمانی که دانلود پایان یافت، روی فایل دابل کلیک کنید و با پیگیری دستورالعملها و تنظیمات پیشفرض آن را نصب کنید.
در ادامه به این لینک (+) بروید و اوبونتو را دانلود کنید. البته اوبونتو دسکتاپ ترجیح بیشتری دارد. پس از این مرحله، باید یک فایل دانلود شده iso. در اختیار داشته باشید.
بدین ترتیب میتوانید به اپلیکیشن Virtual box بروید. این نرمافزار در ابتدا اساساً خالی است. میتوانید با کلیک کردن روی دکمه New یک ماشین مجازی جدید به آن اضافه کنید. برای این ماشین یک نام تعیین کرده، گزینه Linux را انتخاب کنید و در ادامه Next را بزنید.
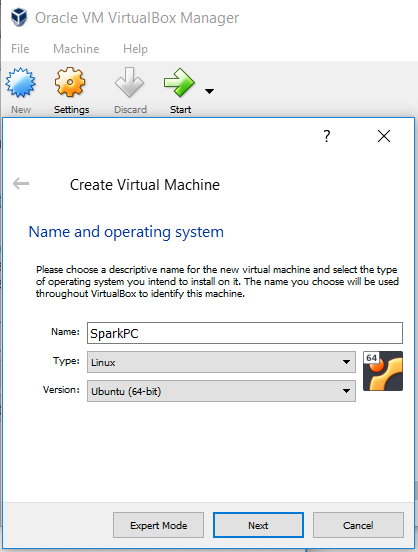
پس از این مرحله، وارد یک سری از گزینهها میشوید که میتوانید برای ماشین تنظیم کنید. قبل از هر چیز اندازه حافظه قرار دارد که میتوانید آن را روی مقدار پیشفرض رها کنید، اما بسته به مشخصات سیستم میتوانید مقدار معقولی RAM به ماشین مجازی خود اختصاص دهید.
در وهله دوم نوبت به هارد دیسک میرسد. این گزینه را نیز میتوانید روی مقدار پیشنهادشده 8 گیگابایت رها کنید و گزینه ایجاد یک ماشین مجازی جدید را کلیک کنید و VDI (یعنی ایمیج دیسک ویرچوال باکس) را در پنجره نوع فایل هارد دیسک انتخاب نمایید و next را بزنید.
در وهله سوم نوبت به فضای ذخیرهسازی میرسد. شما میتوانید اندازه با تخصیص دینامیک یا ثابت را انتخاب کنید. اندازه ثابت پیشنهاد میشود، چون سرعت ورودی/ خروجی بهتری دارد. 20 گیگابایت میتواند مقدار مناسبی باشد. در ادامه روی Create کلیک کنید.
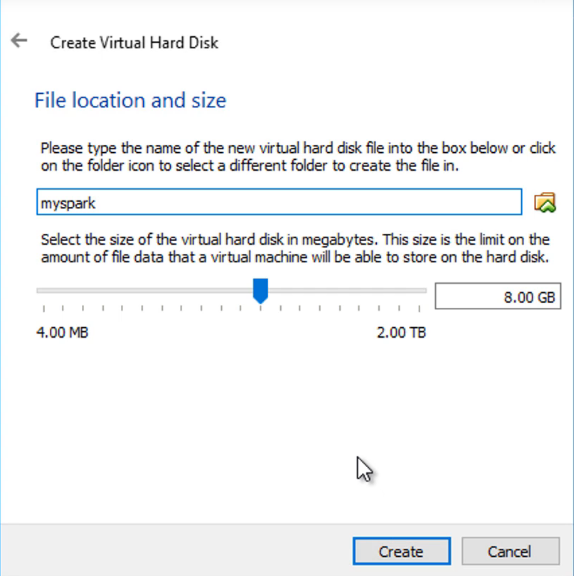
زمانی که روی Create کلیک کردید، ایجاد ماشین کمی طول میکشد. زمانی که ماشین مجازی آماده شد، میتوانید به صفحه اصلی ویرچوال باکس بازگردید، چنان که میبینید ماشین جدیدی که تنظیم کردیم اینک ایجاد شده است.

به صورت پیشفرض این ماشین خاموش است، اما میتوانید آن را با دو بار کلیک کردن روشن کنید. در طی نخستین زمان روشن شدن از شما خواسته میشود که دیسک آغازین را انتخاب کید. این امر مهمی است و جایی است که به ایمیج Ubuntu.iso که قبلاً دانلود کردهاید اشاره میکنید. فایل Ubuntu.iso را انتخاب کرده و روی start کلیک کنید. بدین ترتیب اوبونتو روی ماشین مجازی نصب میشود. در این مسیر گزینههای نصب زیادی در اختیار شما قرار میگیرند و میتوانید آن را سفارشیسازی کرده و یا مقادیر پیشفرض را حفظ کنید. در هر صورت مشکلی وجود ندارد و در انتها یک سیستم عامل آماده به کار در اختیار شما قرار میگیرد که البته از نوع مجازی است.
نخستین کاری که باید درون ماشین مجازی انجام دهید این است که مطمئن شود پایتون از قبل نصب شده است. به این منظور به اپلیکیشن ترمینال اوبونتو بروید و عبارت python3 را وارد کرده و اینتر کنید. بدین ترتیب یک خروجی مانند تصویر زیر باید مشاهده کنید:
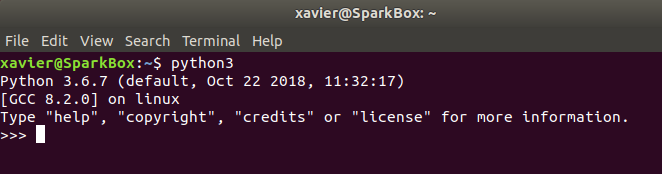
نسخه پایتون ممکن است متفاوت باشد، اما تا زمانی که بالاتر از 3 باشد مشکلی وجود ندارد.
سپس قصد داریم یک سری نرمافزارها را نصب کنیم که برای اجرای اسپارک روی ماشین مجازی ضروری هستند.
Jupyter Notebook
نصب ژوپیتر نتبوک یکی از سادهترین روشها برای تعامل با پایتون و نوشتن کد خوب محسوب میشود. به این منظور روی همان ترمینال یا یک پنجره جدید، دستور زیر را وارد کنید:
pip3 install jupyter
این دستور باید سیستم ژوپیتر نتبوک را نصب کند. زمانی که کار پایان یافت، میتوانید با وارد کردن دستور زیر در ترمینال آن را تست کنید:
jupyter notebook
بدین ترتیب اینترفیس ژوپیتر نتبوک در یک مرورگر باز میشود. این امر نشان میدهد که نصب نتبوک کامل بوده است.
جاوا
اکنون نوبت به نصب جاوا رسیده است که برای اجرای اسپارک ضروری است. در یک پنجره ترمینال دیگر این دستورها را یکی پس از دیگری وارد کنید:
sudo apt-get update sudo apt-get install default-jre
نخستین دستور مکانیسم apt-get ما را بهروزرسانی خواهد کرد و پس از آن جاوا با استفاده از دستور دوم نصب میشود.
اسکالا
به طور مشابه اسکالا را نیز نصب میکنیم.
sudo apt-get install scala
برای تست کردن این نکته که آیا نصب موفق بوده است یا نه میتوانید دستور زیر را وارد کنید که به نسخه اسکالای نصب شده اشاره میکند:
scala –version
نصب Py4j
اکنون نوبت به نصب یک کتابخانه پایتون رسیده است که جاوا و اسکالا را به پایتون وصل میکند:
pip3 install py4j
اسپارک و هادوپ
اکنون که به انتها رسیدهایم باید اسپارک و هادوپ را نصب کنیم. به این منظور به این لینک (+) بروید و نسخه اسپارک را مستقیماً دانلود کنید. مطمئن شوید که این گام را روی ماشین مجازی انجام میدهید تا مستقیماً روی آن دانلود شود.
یک ترمینال جدید باز کنید و مطمئن شوید که در همان مکانی قرار دارید که فایلها دانلود شده بودند. میتوانید به پوشه صحیح cd کرده و دستور زیر را اجرا کنید (توجه داشته باشید که نام فایل بسته به نسخه اسپارک مورد استفاده میتواند متفاوت باشد):
sudo tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz
دستور فوق اساساً پکیج را از حالت فشرده خارج میکند و پوشههای مورد نیاز را میسازد. سپس باید به پایتون اعلام کنیم که کجا میتواند اسپارک را پیدا کند. دستورهای زیر را در ترمینال وارد کرده و پس از هر خط اینتر را بزنید. به مسیر SPARK_HOME دقت کنید، چون باید مکانی باشد که پوشه unzip شده در آن قرار دارد.
export SPARK_HOME=’home/ubuntu/spark-2.1.0-bin-hadoop2.7' export PATH=@SPARK_HOME:$PATH export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH export PYSPARK_DRIVER_PYTHON=”jupyter” export PYSPARK_DRIVER_PYTHON_OPTS=”notebook” export PYSPARK_PYTHON=python3
اگر در تمام طول این مسیر با ما همراه بوده و دستورها را اجرا کرده باشید، اینک همه چیز آماده شده است. یک پنجره ترمینال باز کنید و به مسیر زیر cd کنید:
cd /spark-2.1.0-bin-hadoop2.7/python
زمانی که در دایرکتوری صحیح قرار گرفتید، ژوپیتر نتبوک را باز کنید:
jupyter notebook
اکنون باید مرورگر خود را ببینید که با سیستم ژوپیتر نتبوک باز شده است. یک نتبوک جدید پایتون ایجاد کنید و در یک سلول خالی دستور زیر را وارد کرده و Ctrl+Enter بزنید.
import pyspark

اینک ماشین مجازی ما به همراه اسپارک نصب شده آماده است و میتوانیم کار خود را آغاز کنیم.
2. Databricks
Databricks پلتفرمی است که از سوی خالقان اصلی آپاچی اسپارک ساخته شده و روشی عالی برای بهرهبرداری از قدرت اسپارک در یک مرورگر محسوب میشود. Databricks زحمت نصب دشوار و استفاده از توان محاسباتی اسپارک در مرورگر را از دوش ما بر میدارد. اگر میخواهید به سرعت با اسپارک آشنا شود این بهترین راهی است که میتوانید امتحان کنید. اگر نصب لوکال یک غذای خانگی باشد، Databricks را میتوان یک بشقاب غذای لذیذ آماده تصور کرد. اینک تنها چیزی که نیاز دارید یک مرورگر و یک اتصال اینترنتی خوب است.
با این که Databricks به منظور استفاده از سوی شرکتهایی که به سمت کلانداده و محاسبات توزیع یافته حرکت میکنند طراحی شده است، اما یک نسخه کامیونیتی نیز دارد که برای منظور ما مناسب است.
برای شروع کار به این لینک (+) بروید و در نسخه کامیونیتی ثبت نام کنید. شما باید آدرس ایمیل خود را اعتبارسنجی کنید تا بتوانید برای نخستین بار وارد شوید. زمانی که این کار را انجام دادید امکان کار با محیط نتبوک پایتون که از قبل نصب شده را خواهید یافت.

هنگامی که لاگین کردید، روی Create a Blank Notebook کلیک کنید تا کار را آغاز کنید. در این هنگام یک ژوپیتر نتبوک عرضه میشود که میتوان کد پایتون را در هر سلول آن وارد کرده و به صورت مستقل اجرا کرد.
Databricks برای اسپارک ساخته شده است و نیازی به نگرانی در مورد نصب موارد اضافی وجود ندارد. شما میتوانید بیدرنگ عبارت spark را در سلول نخست وارد کنید و با زدن کلیدهای Ctrl+Enter یا دکمه پخش کوچک در سمت راست سلول آن را اجرا کنید:

در نخستین دفعه اجرا از شما خواسته میشود که یک کلاستر را لانچ و اجرا کنید. این کار را انجام دهید و پس از آن میبینید که چیزی مانند تصویر فوق ظاهر میشود. اینک میتوانید سلولهای اضافی ایجاد کرده و به ارزیابی اسپارک ادامه دهید. شما اینک میتوانید به بررسی مجموعه دادهها پرداخته و عملیات مختلف یادگیری ماشین را اجرا کنید.
نکته: ابزار Databricks به دلایل مختلف جالب است و مهمتر از همه این که مخزن داده عظیمی ارائه میکند که با استفاده از آن میتوانید همه قدرتش را مورد آزمایش قرار دهید.
برای بررسی اجمالی آن چه که Databricks ارائه میکند، باید با استفاده از دستور magic به «file system» مربوط به Databricks بروید. در یک سلول جدید عبارت fs% را وارد کنید و سپس ls را وارد کرده و سلول را اجرا کنید. بدین ترتیب مسیرهای dbfs را به صورت فهرستبندی شده مشاهده میکنید:

سپس روی ls /databricks-datasets/ کلیک کنید تا همه مجموعه دادههای موجود را ببینید. اگر به هر کدام از آنها علاقهمند هستید میتوانید به سادگی از آنها در کد خود استفاده کنید. برای نمونه ما دادههای ساده people/people.json/ را دوست داریم و میخواهیم از آن در کد خود استفاده کنیم. این کار به صورت زیر میسر است:
data = spark.read.json(“/databricks-datasets/samples/people/people/.json”)
به بررسی این پلتفرم بپردازید و مجموعههای داده مختلف را امتحان کنید، مسلماً ناامید نخواهید شد. شاید این سادهترین روش استفاده از اسپارک باشد.
3. Google Colab
Google Colaboratory (+) یک محیط رایگان ژوپیتر نتبوک است که شباهت زیادی به Databricks دارد و به طور کامل روی کلود اجرا میشود، اما همه شهرت آن از این ناشی نمیشود که یک سیستم رایگان نتبوک است، بلکه بخش عمده آن ناشی از ارائه GPU رایگان است. بله درست شنیدهاید، Colab امکان استفاده رایگان از GPU را فراهم میسازد. این یک پیشنهاد عالی برای افرادی است که میخواهند یادگیری ماشین را بیاموزند. البته این موضوع مجزایی است و با موضوع مقاله ما که معرفی اسپارک است ارتباط مستقیمی ندارد.
برای استفاده از Google Colab به یک مرورگر وب، یک اتصال اینترنتی خوب و یک حساب گوگل نیاز دارید. به این لینک (+) بروید و از طریق حساب گوگل وارد شوید تا صفحهای برای ایجاد «New Python 3 Notebook» مشاهده کنید. در ادامه یک نتبوک بسازید.
این مرحله ما را وارد سرزمین آشنایی میکند که یک نتبوک پایتون یا یک سلول خالی است. Google Colab برخلاف Databricks آماده استفاده با اسپارک است و از این رو نیازی به همان تنظیمات اندک آغازین هم نداریم. اگر pyspark را در سلول خالی اجرا کنید با خطایی به صورت زیر مواجه خواهید شد.
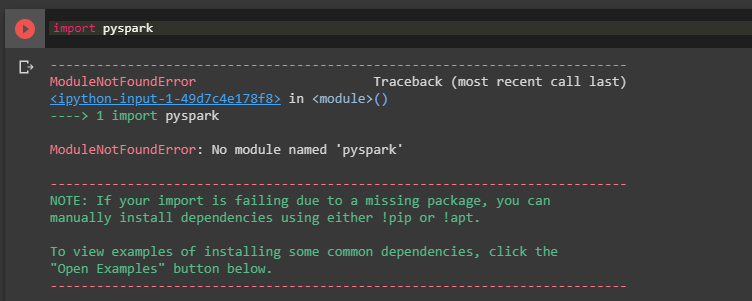
در ادامه این خطا را اصلاح میکنیم. Google Colab هم شبیه به یک ماشین مجازی و هم یک نتبوک عمل میکند. دستور زیر را در یک سلول خالی وارد کرده و با زدن Ctrl+Enter جاوا را نصب میکنیم:
!apt install openjdk-8-jdk-headless -qq > /dev/null
با استفاده از علامت (!) در ابتدای دستور آن را در یک پوسته (Shell) اجرا میکنیم و نشان میدهیم که یک کد پایتون نیست. اینک اسپارک و هادوپ را دانلود میکنیم.
!wget -q http://www-eu.apache.org/dist/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
زمانی که دانلود پایان یافت، میتوانید با اجرای ls -l! همانند یک پوسته لینوکسی در عمل ببینید که آیا فایل دانلود شده یا نه.

چنان که میبینید فایل با فرمت یک فایل zip دانلود شده، پس باید آن را از حالت فشرده خارج کنیم:
!tar xf spark-2.3.3-bin-hadoop2.7.tgz
اکنون قبل از شروع به کار با اسپارک باید چند کار دیگر نیز انجام دهیم که تنظیم متغیرهای جاوا و اسپارک به صورت زیر است:
import os os.environ[“JAVA_HOME”] = “/usr/lib/jvm/java-8-openjdk-amd64” os.environ[“SPARK_HOME”] = “/content/spark-2.3.3-bin-hadoop2.7”
این همه کاری است که برای راهاندازی نیاز داریم. اکنون به بررسی کد نمونه زیر میپردازیم:
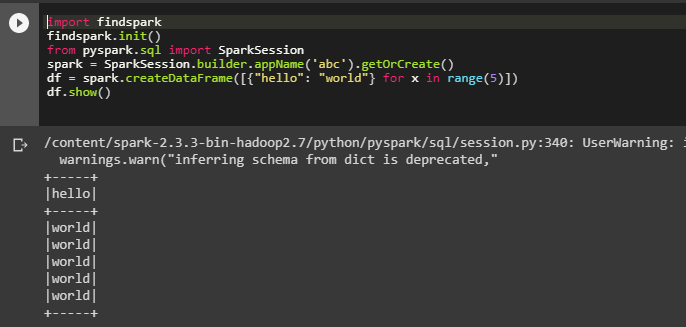
کد فوق با ایجاد یک SparkSession جدید اقدام به مقداردهی اسپارک میکند و سپس یک فریم داده جدید اسپارک به صورت on fly با استفاده از list comprehension پایتون میسازد و در نهایت فریم داده نمایش مییابد. آن را در یک سلول جدید امتحان کنید.
سخن پایانی
بدین ترتیب به پایان این مقاله رسیدهایم و امیدواریم راهنمای اطلاعات تنظیم اسپارک مورد توجه شما قرار گرفته باشد. ما نهایت تلاش خود را کردهایم که کل فرایند برای خواننده روشن باشد و از این رو امیدواریم بتوانید بدون نگرانی در مورد حجم بالای اطلاعات، اسپارک را نصب و راهاندازی کنید و صرفاً روی شروع کار متمرکز شوید.
منبع: فرادرس
یافتن دور همیلتونی با الگوریتم پس گرد — به زبان ساده
«مسیر همیلتونی» (Hamiltonian Path) در یک گراف غیر جهتدار، مسیری است که در آن هر «راس» (Vertex) دقیقا یکبار مشاهده میشود. یک «دور همیلتونی» یا «مدار همیلتونی» (Hamiltonian Cycle | Hamiltonian Circuit)، یک مسیر همیلتونی است که در آن از آخرین راس به اولین راس یک «یال» (Edge) وجود دارد. در ادامه، روشی جهت بررسی اینکه آیا در یک گراف داده شده، دور همیلتونی وجود دارد یا خیر بررسی میشود. همچنین، در صورت وجود دور، مسیر آن را چاپ میکند. در واقع، با استفاده از یک روش ساده و یک روش «پسگرد» (Backtracking)، بررسی میشود که آیا در یک گراف دور همیلتونی وجود دارد یا خیر و در صورت وجود، مسیر در خروجی چاپ میشود. ورودی و خروجی تابع لازم برای این کار به صورت زیر هستند.
یافتن دور همیلتونی در گراف
برای یافتن دور همیلتونی در گراف، به طور کلی به صورت زیر عمل میشود.
ورودی:
یک آرایه دوبُعدی [graph[V][V که در آن V تعداد راسها در گراف و [graph[V][V «ماتریس همسایگی» (Adjacency Matrix) گراف است. مقدار [graph[i][j در صورت وجود یک یال مستقیم از راس i به راس j برابر با یک و در غیر این صورت، [graph[i][j برابر با صفر است.
خروجی:
یک آرایه [path[V باید حاوی یک مسیر همیلتونی باشد. [path[i باید راس i در مسیر همیلتونی را نمایش دهد. همچنین، کد باید مقدار false را در صورت عدم وجود دور همیلتونی در گراف، بازگرداند.
برای مثال، دور همیلتونی در گراف زیر به صورت {۰ ،۳ ،۴ ،۲ ،۱ ، ۰} است.
(0)--(1)--(2) | / \ | | / \ | | / \ | (3)-------(4)
گراف زیر حاوی هیچ دور همیلتونی نیست.
(0)--(1)--(2) | / \ | | / \ | | / \ | (3) (4)
الگوریتم ساده (Naive Algorithm)
الگوریتم سادهای که در زیر ارائه شده، همه پیکربندیهای ممکن برای راسها را ارائه میکند و پیکربندی که محدودیت های داده شده را ارضا میکند، باز میگرداند. به تعداد !n، پیکربندی ممکن وجود دارد.
یافتن دور همیلتونی با الگوریتم پسگرد (Backtracking Algorithm)
این الگوریتم یک آرایه مسیر خالی میسازد و راس ۰ را به آن اضافه میکند. در ادامه، دیگر راسها را با آغاز از راس ۱ به آرایه اضافه میکند؛ اما پیش از اضافه کردن یک راس، بررسی میکند که آیا با راس پیشین اضافه شده مجاور است یا خیر و همچنین، بررسی میکند که راس، پیش از این به آرایه اضافه نشده باشد. اگر چنین راسی پیدا شود، یال به عنوان بخشی از راهکار اضافه میشود. اگر راس پیدا نشود، مقدار false بازگردانده میشود.
پیادهسازی الگوریتم پسگرد برای مساله یافتن دور همیلتونی در گراف
در ادامه، پیادهسازی الگوریتم پسگرد برای مساله یافتن دور همیلتونی در گراف در زبانهای برنامهنویسی گوناگون ارائه شده است.
++C
C
پایتون
جاوا
سی شارپ
خروجی:
Solution Exists: Following is one Hamiltonian Cycle 0 1 2 4 3 0 Solution does not exist
توجه به این نکته لازم است که قطعه کد بالا، همیشه دورهایی که از صفر شروع میشوند را چاپ میکند. نقطه شروع نباید اهمیتی داشته باشد، زیرا یک دور میتواند از هر راسی آغاز شود. افرادی که قصد تغییر دادن نقطه شروع را دارند، باید دو تغییر در کد بالا اعمال کنند. تغییر «;path[0] = 0» به «;path[0] = s» که در آن، s نقطه شروع جدید است. همچنین، باید حلقه «(++for (int v = 1; v < V; v» در ()hamCycleUtil، به «(++for (int v = 0; v < V; v» تغییر پید
منبع: فرادرس