طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیچگونه یک پایگاه داده مناسب انتخاب کنیم؟ — راهنمای مقدماتی
گام حیاتی در آغاز هر پروژه پایگاه داده شامل انتخاب از میان پایگاههای داده رابطهای یا غیر رابطهای، نظریه CAP و مواردی از این دست است. زمانی که یک پروژه پایگاه داده سازمانی را استارت میزنید بهتر است برای انتخاب پایگاه داده مناسب نهایت دقت خود را به خرج بدهید. با ظهور مفهوم کلانداده، اینک گزینههای بسیار زیادی برای رفع نیازهای مدیریت داده وجود دارند و انتخاب پایگاه داده صحیح به معنی انجام کارهای زیر است:
- ابتدا و قبل از هر کار دیگر باید درک کنید که پایگاه داده شما تحت چه الزاماتی از پروژه کار خواهد کرد.
- شما با چه نوع از پایگاه داده میتوانید تنها برخی از نیازهای مرتبط را رفع کنید.
- عملکرد پایگاه داده تنها پس از آن که موفق شدید همه نیازهای پایگاه دادهای خودتان را با نوع پایگاه داده مناسب تطبیق دهید مطرح میشود.
- همواره یک نقطه موازنه بین سازگاری، در دسترس بودن، و تحمل تسهیم وجود دارد.
درک موازنه
دلیل این که امروزه گزینههای پایگاه داده زیادی وجود دارند ناشی از نظریه CAP است. CAP اختصاری برای سه عبارت «consistency ،availability ،partition tolerance» یعنی سازگاری، در دسترس بودن و تحمل تسهیم است.
- سازگاری یعنی هر درخواست خواندن، جدیدترین نسخههای نوشته شده را بازگشت دهد.
- در دسترس بودن یعنی گره غیر پاسخگو، باید در طی مدت زمانی معقول پاسخگو شود.
- تحمل تسهیم یعنی سیستم علیرغم بروز شکست در شبکه یا گره بتواند به کار خود ادامه دهد.
در هر لحظه از زمان تنها دو مورد از این سه الزام میتوانند برقرار باشند.
پایگاههای داده رابطهای
پایگاههای داده رابطهای به طور سنتی، سازگاری و در دسترس بودن بالایی دارند و این به هزینه کاهش تحمل تسهیم به دست میآید. این پایگاههای داده برای نوشتن بهینهسازی شدهاند. مثالهایی از پایگاههای داده رابطهای به صورت SQL Server ،MySQL ،PostgresSQL و IBM DB2 است.
پایگاههای داده غیر رابطهای
پایگاههای داده غیر رابطهای جهت افزایش «در دسترس بودن و تحمل تسهیم» و یا «سازگاری و تحمل تسهیم» توسعه یافتهاند. این نوع از پایگاههای داده جهت خواندن بهینهسازی شدهاند. مثالهایی از پایگاههای داده غیر رابطهای شامل Memcached ،Redis ،Coherence ،Hbase ،BigTable ،Accumulo ،MongoDB و CouchDB است.
در سیستمهای پیچیده که حجم عملیات خواندن و نوشتن هر دو بالا است، داشتن ترکیبی از پایگاههای داده رابطهای و غیر رابطهای برای جداسازی وظایف خواندن در برابر نوشتن جهت بهینهسازی CAP ضروری است.
سؤالهای مهمی که باید پرسید
گام بعدی در مسیر انتخاب پایگاه داده مناسب این است که فهرستی از سؤالها در رابطه با الزامات کسبوکار خود بپرسید. برخی از این سؤالها در فهرست زیر ارائه شدهاند:
- در دادههای شما چه تعداد رابطه وجود دارد؟
- سطح پیچیدگی دادههای شما چه قدر است؟
- دادهها به چه میزان تغییر مییابند؟
- اپلیکیشن شما به چه میزان به داده کوئری میزند؟
- اپلیکیشن شما به چه میزان به روابط بین دادهها کوئری میزند؟
- کاربران شما به چه میزان دادهها را بهروزرسانی میکنند؟
- کاربران شما به چه میزان منطق موجود در دادهها را بهروزرسانی میکنند؟
- اپلیکیشن شما در صورت بروز یک فاجعه غیرمترقبه چه قدر حیاتی خواهد بود؟
درک مزایا و معایب
پایگاههای داده رابطهای برای نوشتن بهینهسازی شدهاند. بدین ترتیب بهترین عملکرد آنها در زمینه سازگاری و در دسترس بودن است.
مزیتهای پایگاههای داده رابطهای
- سادگی
- سهولت بازیابی دادهها
- یکپارچگی دادهها
- انعطافپذیری
معایب پایگاههای داده رابطهای
- هزینه بالا: راهاندازی و نگهداری این پایگاههای داده پرهزینه است.
- محدودیتهای ساختاری: پایگاههای داده رابطهای در طول فیلدها محدودیت دارند. بدین ترتیب ذخیرهسازی حجم بالایی از اطلاعات در یک فیلد دشوار خواهد بود.
- جداسازی: چندین پایگاه داده رابطهای را میتوان به سادگی به «جزیرههای اطلاعات» تبدیل کرد. اتصال به پایگاههای داده زمانی که با هم ارتباط برقرار میکنند میتواند دشوار باشد.
پایگاههای داده غیر رابطهای برای عملیات خواندن بهینهسازی شدهاند. آنها خصوصیتهای «در دسترس بودن و تحمل تسهیم» و یا «سازگاری و تحمل تسهیم» را عرضه میکنند.
مزیتهای پایگاههای داده غیر رابطهای
- انعطافپذیری: حجم بالایی از دادههای ساختیافته، نیمه ساختیافته و غیر ساختیافته را ذخیره میکنند.
- برنامهنویسی چابک: در این نوع پایگاههای داده میتوان به سرعت قطعه کدهای کوتاهی نوشت و آن را اجرایی کرد.
- مقیاسپذیری ارزان: معماری پایگاههای داده غیر رابطهای به طرز مؤثری بدون هزینه سربار زیاد قابل گسترش است.
معایب پایگاههای داده غیر رابطهای
- سازگاری دادهها: پایگاههای داده غیر رابطهای تراکنشهای ACID را اجرا نمیکنند. در عوض آنها بر «سازگاری نهایی» تکیه دارند. مزیت عملکردی این پایگاههای داده به هزینه کاهش سازگاری به دست میآید.
- استانداردسازی: هیچ اینترفیس برنامهنویسی خاصی برای پایگاههای داده مختلف وجود ندارد. هر یک از آنها دارای زبان متفاوتی نسبت به بقیه هستند.
- مقیاسپذیری: هیچ یک از پایگاههای داده غیر رابطهای در خودکارسازی فرایند sharding، یا گسترش پایگاه داده در چند گره عملکرد مناسبی ندارند. این وضعیت موجب بروز محدودیتهایی در مقیاسپذیری به سمت بالا یا پایین برای وضعیتهای با تقاضای پرنوسان میشود.
درک انواع مختلف پایگاههای داده غیر رابطهای
امروزه انواع متفاوتی از پایگاههای داده غیر رابطهای وجود دارند. این پایگاههای داده در دستهبندیهای خاصی جای میگیرند. هر دسته از پایگاههای داده غیر رابطهای برای مقصود خاصی طراحی شدهاند.
کلید/مقدار: این نوع از پایگاههای داده بهترین عملکرد خود را در طرحبندیهای ساده برای پایگاههای داده نشان میدهند. این نوع برای عملیات خواندن و نوشتن زیاد و با بهروزرسانی کم مناسب است. بهترین عملکرد این نوع پایگاه داده در زمانی است که کوئریها یا منطق تجاری غیر پیچیدهای وجود داشته باشند. مثالهایی از این نوع پایگاههای داده شامل Redis ،Dynamo DB و Cosmos DB است.
سند: این نوع از پایگاههای داده بهترین عملکرد خود را در یک طرحبندی انعطافپذیر نمایش میدهند. در این طرحبندی دادهها در قالب XML یا JSON ذخیره میشوند. در این وضعیت میتوان عملکرد خواندن بالایی داشت و میتوان بین عملکرد خواندن و عملکرد نوشتن تعادلی برقرار ساخت. همچنین امکان استفاده از اندیس برای بیشینهسازی عملکرد حافظه در این نوع از پایگاههای داده وجود دارد.
مثالهایی این نوع پایگاههای داده شامل MongoDB ،DynamoDB و Couchbase است.
گراف: این نوع از پایگاههای داده زمانی که طرحبندی پایگاه داده پیچیدهای دارید عالی هستند. شما باید منطق تجاری را بین گرهها به طور مکرر نمایش دهید. پایگاههای داده گراف امکان ناوبری بین گرهها را میدهند.
Neo4j ،Cosmos Db و Amazon Neptune مثالهایی از این نوع پایگاه داده محسوب میشوند.
اکنون که درک نسبتاً جامعی از موارد لازم در هنگام انتخاب پایگاه داده برای پروژههای سازمانی خود به دست آوردید، میتوانید بسته به نیازهای اپلیکیشنتان یک یا چند مورد از آنها را انتخاب کنید. بدین ترتیب انتخاب شما انتخاب فردی خواهد بود که همه نیازهای تجاری مختلفی که ممکن است داشته باشد را لحاظ میکند.
ا
منبع: فرادرس
آموزش سوئیفت (Swift): نوشتن تست — بخش هفدهم
در این مقاله از سری مقالات آموزش سوئیفت بر روی مبحث نوشتن تست متمرکز خواهیم بود. شاید فکر کنید نوشتن تست یک کار اختیاری است و هیچ منطقی را اجرا نمیکند که به همراه اپلیکیشن عرضه شود. اگر واقعاً این گونه فکر میکنید، قطعاً در مصاحبه استخدامی خود مردود خواهید شد. با ما همراه باشید تا دلیل این مسئله را بازگو کنیم. برای مطالعه بخش قبلی این مجموعه مطلب آموزشی میتوانید به لینک زیر رجوع کنید:
نوشتن تست
تست کردن مهم است و ارتباط تنگاتنگی با رویکرد TDD دارد. TDD اختصاری برای عبارت «Test-driven Development» (توسعه تست-محور) است. توسعه تست-محور یک روش رایج برای نوشتن اپلیکیشن است و بهخاطرسپاری این فرمول نیز آسان است.
- یک حالت تست شکست بنویسید.
- کد کافی بنویسید و از نوشتن کد اضافی برای پاس کردن تست اجتناب کنید.
- تست کنید تا پاس شدن حالت را تضمین کنید.
روشهای دیگری نیز برای تست کردن وجود دارند. میتوانید از گزارههای پرینت ساده برای نمایش نتایج قبل و بعد از اجرای کد استفاده کنید که روش خوبی برای تست کردن است. همچنین میتوانید اپلیکیشن خود را اجرا کنید تا مطمئن شوید که هیچ چیزی خراب نمیشود که در واقع کمترین حالت مورد نیاز برای تست است و احتمالاً به هر حال آن را اجرا خواهید کرد.
ما در این مقاله صرفاً به پوشش روش TDD میپردازیم. پیش از آن که کار خود را آغاز کنیم باید با دو اصطلاح جدید آشنا شوید: «Test Ratio» (نسبت تست) و «Code Coverage» (پوشش کد).
نسبت تست به نسبت تعداد خطوط کد به خطوط تستهای نوشتهشده گفته میشود. افراد زیادی هستند که میگویند هر 1 خط کد باید با 3 خط تست شود، یعنی این نسبت باید 1:3 باشد.
پوشش کد یعنی چه میزان از کد برحسب درصد تست شده است. IDE-های زیادی به نمایش پوشش کد میپردازند که کدبیس را برحسب وضعیت تست نمایش میدهد. رنگ سبز به معنی وجود تست برای کد و رنگ قرمز به معنی عدم وجود تست است.
برخی افراد بر این باورند که به صورت پیشفرض همه کدها باید تست شوند. اما شاید این دیدگاه چندان صحیح نباشد، چون لزومی وجود ندارد که تابعهای موجود در سوئیفت و دیگر کتابخانهها که خودشان شامل تست هستند مجدداً تست شوند. برای نمونه لازم نیست برای یک گزاره print یا دیگر متدهای استاتیک مانند ()Date.init تست نوشت. در واقع صرفاً لازم است که کد خودتان را تست کنید. تنها استثنا در این مورد کدهای افراد دیگری است که تست نداشته باشند.
نحوه نوشتن تست چیزی شبیه زیر است:
کد فوق را خط به خط بررسی میکنیم. import XCTest اقدام به ایمپورت کردن کتابخانه ارائه شده از سوی اپل برای تست کردن میکند. testable import ViewController @testable یک خصوصیت است که دامنه دسترسی این ماژول را افزایش میدهد. در واقع این دستور سطح دسترسی را از internal یا private به open تغیر میدهد اما تنها برای تستهای لوکال کار میکند. دستور import ViewController گزاره ایمپورتی است که شامل کلاس مورد نظر برای تست است.
{ … } class ViewControllerTests: XCTestCase کلاسی تعریف میکند که همه کارکردهای خود را از XCTestCase به ارث میبرد. اگر از هرکدام از مشخصهها استفاده کنید، چه کلاس دیگر باشد و چه برخی از ثابتها یا متغیرهایی که غالباً در کاربردهای تست استفاده میشود به جای Testing properties here// آن مشخصهها را بنویسید.
()override func setUp را میتوان به عنوان ()viewDidLoad برای حالتهای تست تصور کرد. زمانی که شروع به تست کردن میکنید، این کد کلاسها را ایجاد میکند یا از متغیرها وهله میسازد.
()override func tearDown معادل {} deinit در کنترلرهای نما است. هر چیزی را که ممکن است موجب ایجاد نشت حافظه شود پاک کنید، Timer مثال خوبی از آن چیزی است که باید حذف شود.
()func test_multiplyByTwoReturnsFour یکی از قراردادهای نامگذاری فراوانی است که وجود دارد، اما این نام گذاری مقصود تست را مشخص میکند. موارد تست را همواره با عبارت test آغاز کنید. استفاده از _ اختیاری است، اما به افزایش خوانایی کمک میکند. در ادامه multiplyByTwo آن چیزی است که قرار است انجام دهیم و ReturnsFour آن چیزی است که انتظار داریم دریافت کنیم. اگر موارد تست را به این ترتیب بنویسید همواره میدانید که هر مورد تست برای چه چیزی استفاده میشود و چه نتیجهای از آن انتظار میرود. اما اگر در نهایت صرفاً اعداد فرد و گرد شده بازگشت یابند چطور؟ بدین ترتیب میتوان مورد تستی مانند {} func test_getOddFromMultiplyByTwo_ReturnsFive نوشت.
در نهایت دستور (XCTAssertEqual(value، value را میبینیم که مورد تست واقعی است که برابر بودن هر دو مقدار را تست میکند. XCTAssert یک پیشوند رایج است و از این رو اگر شروع به نوشتن XCT بکنید امکان تکمیل خودکار در Xcode تعدادی از متدهایی که میتوانید استفاده کنید را به شما پیشنهاد میکند. در این حالت اگر هر دو مقدار برابر باشند تست پاس میشود و در غیر این صورت ناموفق خواهد بود.
برخی تستهای رایج دیگر شامل XCTAssertNotEqual ،XCTAssertNil و XCTAssertNotNil هستند.
تست کردن تنها به بررسی این که اشیای مختلف باید چگونه باشند محدود نمیشود بلکه میتوان به اندازهگیری عملکرد نیز پرداخت. این نوع از تست یکی از مفیدترین تستها است زیرا پس از این که مطمئن شدیم کار درستی انجام میدهیم باید اطمینان پیدا کنیم که آن را به طرز صحیحی نیز انجام میدهیم. بدین ترتیب میتوانیم به مرور کد خود را بهبود بخشیم.
برخلاف تستهای تأییدی ما، نیازی نیست که بخش بازگشتی مورد انتظار را در اعلان متد بگنجانیم. به جای آن کافی است آن را با بلوک { }test_functionNamePerformance(). measure عوض کنیم که باید صرفاً شامل کدی باشد که میخواهیم اندازهگیری کنیم. اگر قرار باشد یک متغیر به (:getFactorial(of ارسال کنیم، در این صورت آن را خارج از بلوک اندازهگیری وهلهسازی میکنیم، مگر این که بخواهیم آن را در اندازهگیریهای خود بگنجانیم.
(getFactorial(of: 45 =_ به فراخوانی متد getFactorial با ورودی 45 میپردازد. از آنجا که نیازی به ذخیرهسازی مقدار نداریم از =_ استفاده میکنیم که نوعی جابجایی نتایج به /dev/null محسوب میشود. برای ما مهم نیست که این مقدار چیست و در اینجا به آن اهمیتی نمیدهیم.
آنچه در اینجا برای ما مهم است، این است که تابع فاکتوریل چه قدر طول میکشد تا کار خودش را اجرا بکند. زمانی که این کد را اجرا کنید موارد تست 10 بار اجرا میشوند.
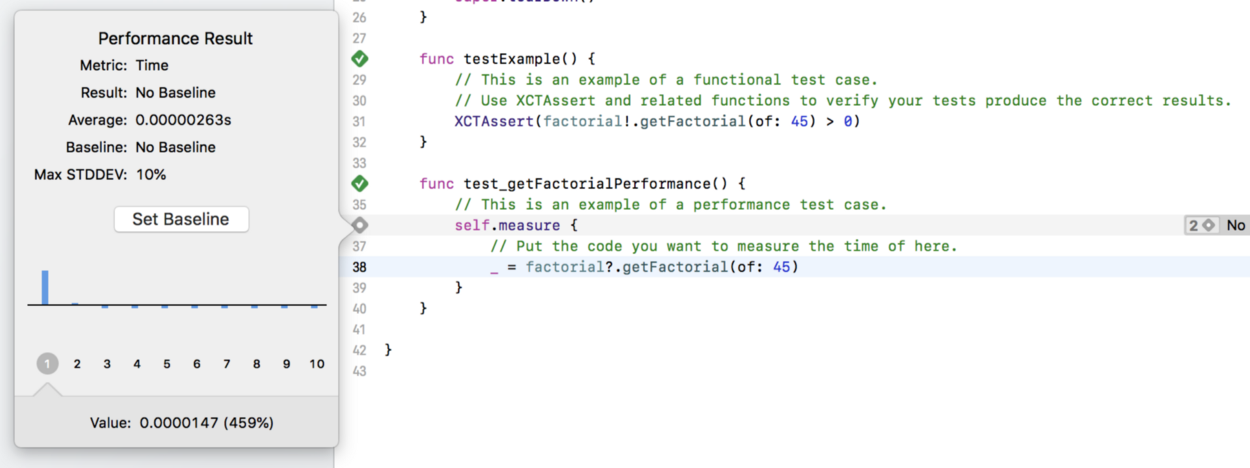
در اجرای نخست این کد تابع را در طی 0.00000263 اجرا میکند. این زمان کاملاً سریع است اما در طی این مدت بهینهسازیهایی رخ میدهند. در ادامه اجراهای بعد را میبینیم.
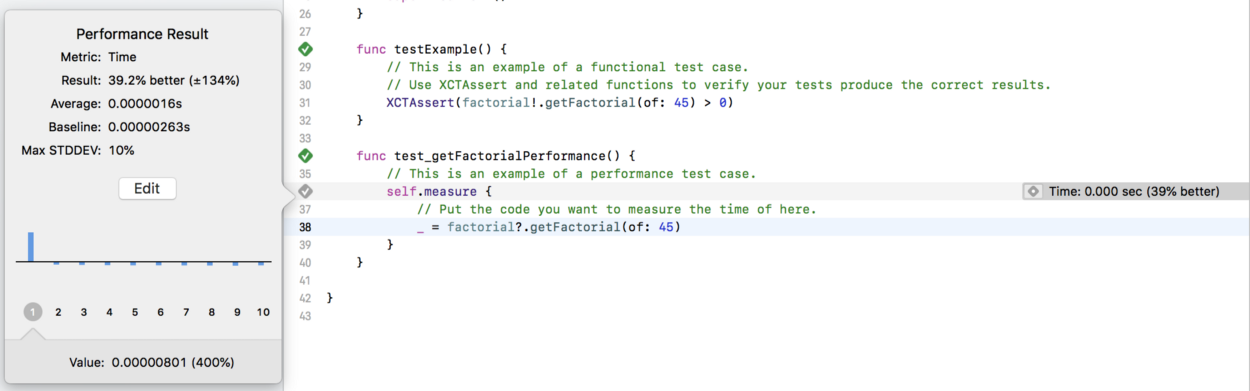
در اجرای دوم، ما این تابع را 39 درصد بهتر اجرا کردهایم، اما هیچ چیز تغییر نیافته است. دلیل این امر آن است که بهینهسازیها قبلاً صورت گرفتهاند و صرفاً از آنها مجدداً استفاده کردهایم. این جا مکان خوبی برای تنظیم مبدأ جدید است بنابراین ویرایش را کلیک میکنیم و مبدأ جدید را پذیرفته و آن را ذخیره میکنیم. در اجراهای بعدی به ترتیب 6% عملکرد بدتر، 0% بهتر، 2% بهتر، و 7% بهتر بدون تغییر دادن هیچ خطی از کد به دست آمدند. بنابراین مبدأ خوبی برای ما محسوب میشود. از این جا میتوانیم تغییرات خود را ایجاد کرده و سپس اندازهگیریها را تست کنیم تا ببینیم آیا تغییرات ما موجب عملکرد بهتر یا بدتر میشوند.
با این که راهنمای صریحی در مورد آن چه بهینهسازی خوب شمرده میشود وجود ندارد اما تصور ما این است هر تغییری که موجب بهبود در طی 10 اندازهگیری (100 اجرا) شود مناسب است. اگر کدی در طی چند اجرای نخست بهبود مناسبی نشان دهد بهتر است آن تغییر را حفظ کنید.
زمانی که در مورد تست کردن Unit Testing صحبت میکنیم، در واقع همان فرایندی است که در بخش فوق توضیح دادیم. همچنان یک حالت تست کردن عمومی نیز وجود دارد که به تست کارکرد کلی عملکرد اپلیکیشن چنان که انتظار میرود میپردازید. UI Testing نوع دیگری از تست کردن است که بخش UI را در برمیگیرد، اما از آنجا که این راهنما صرفاً در مورد مفاهیم مقدماتی تست کردن است بررسی آن خارج از دامنه این مقاله خواهد بود. در نهایت باید اشاره کنیم که یک تست پذیرش کاربر (UAT) نیز وجود دارد که برای اطمینان یافتن از این که کاربر از امکانات اپلیکیشن راضی است اجرا میشود. این تست عموماً از طریق تیمهای پرسش و پاسخ (QA) اجرا میشود و کسبوکار یا مخاطبان منتخب از کاربران نهایی را شامل میشود. این تست امکان اجرای سناریوهای بیشتری در اپلیکیشن را میدهد که برای تست کردن بیشتر استفاده میشوند و به سؤالاتی در مورد شیوه استفاده از اپلیکیشن و زمان عرضه نهایی آن پاسخ میدهد.
سخن پایانی
ما در این مقاله با مفاهیم مقدماتی تست کردن آشنا شدیم و دیدیم که چگونه میتواند به نوشتن کدهای بهتر کمک کند، چه اهمیتی در چرخه توسعه دارد و چگونه عملکرد کد را اندازهگیری میکند. تستهای بیشتر شامل استفاده از ابزارهای Xcode است که میتوان از آنها برای اندازهگیری حافظه، CPU و استفاده از دیسک بهره گرفت، اما اینها جزء مباحث پیشرفته هستند. در بخش بعدی در مورد معماری Model View Controller صحبت میکنیم.
معماری مدل، نما-کنترلر یا به اختصار MVC به صورت گستردهای برای یادگیری آموزش کدنویسی به افراد مبتدی استفاده میشود. این سادهترین روش برای یادگیری شیوه استفاده از چندین فایل در یک پروژه است. با این که روشهای دیگری نیز وجود دارند که میتوان استفاده کرد، اما این سادهترین نوع معماری محسوب میشود. زمانی که آماده انتقال از MVC باشید تقریباً به طور طبیعی شروع به نوشتن یک سبک معماری متفاوت برحسب نیازهای اپلیکیشن خود میکنید. برای مطالعه بخش بعدی (پایانی) به اینک زیر مراجعه کنید:
منبع: فرادرس
حل مساله n وزیر با الگوریتم پس گرد (Backtracking) — به زبان ساده
در این مطلب، به روش حل مساله n وزیر با الگوریتم پس گرد (Backtracking) پرداخته میشود. همچنین، کدهای پیادهسازی روش مذکور در زبانهای گوناگون، ارائه شدهاند. در بازی شطرنج، وزیر میتواند به میزان نامحدودی به طور افقی، عمودی و قطری حرکت کند. در مساله n وزیر، هدف آن است که n وزیر در یک صفحه شطرنج n×n به گونهای قرار بگیرند که هیچ یک زیر ضرب دیگری نباشد. اولین مساله n وزیر در سال ۱۸۴۸ و با عنوان مساله ۸ وزیر مطرح شد. در سال ۱۸۵۰، «فرانز نائوک» (Franz Nauck) اولین راهکار برای مساله ۸ وزیر را ارائه کرد. او، مساله 8 وزیر را به مساله n وزیر تعمیم داد که در واقع همان قرارگیری n وزیر در یک صفحه شطرنج n×n است، به صورتی که یکدیگر را تهدید نکنند. ریاضیدانان متعددی روی مساله ۸ وزیر و حالت تعمیم یافته آن یا همان n وزیر کار و سعی کردند آن را حل کنند که از این جمله میتوان به «کارل فریدریش گاوس» (Carl Friedrich Gauss) اشاره کرد. «اس گانتر» (S. Gunther) در سال ۱۸۷۴ یک روش قطعی برای حل این مساله ارائه کرد و «جیمز گلشیر» (James Whitbread Lee Glaisher) راهکار ارائه شده توسط گانتر را بهبود بخشید.
سرانجام و در سال ۱۹۷۲، «ادسخر ویبه دِیکسترا» (Edsger W. Dijkstra) الگوریتم «اول عمق پسگرد» (Depth-First Backtracking) را برای حل این مساله معرفی کرد. حل مساله ۸ وزیر به لحاظ محاسباتی بسیار پرهزینه است، زیرا تنها در یک صفحه 8×۸ برای هشت وزیر، ۴,۴۲۶,۱۶۵,۳۶۸ حالت ممکن قرارگیری در صفحه شطرنج وجود دارد که از میان آنها، تنها ۹۲ مورد راه حل مساله است. بنابراین، با افزایش مقدار n، پیچیدگی محاسباتی افزایش پیدا میکند. البته، روشهایی برای کاهش پیچیدگی محاسباتی جهت حل این مساله ارائه شده است؛ اما به طور کلی، مساله n وزیر از جمله مسائل «انپی» (Non Deterministic Polynomial | NP) در حوزه «هوش مصنوعی» (Artificial Intelligence) محسوب میشود.
شایان توجه است که در مساله n وزیر، برای n=2 و n=۳ پاسخی وجود ندارد. همچنین، الزاما تعداد راهکارهای موجود برای مساله با افزایش N افزایش پیدا نمیکنند. برای مثال، مساله ۶ وزیر، تعداد پاسخهای کمتری نسبت به حالت ۵ وزیر دارد. در ادامه، روش حل مساله n وزیر برای N=4 نمایش داده شده است؛ سپس، یک الگوریتم ساده برای حل آن معرفی و در نهایت، مساله ۴ وزیر با استفاده از «الگوریتم پَسگرد» (Backtracking Algorithm) حل شده است. پیادهسازی الگوریتم پسگرد برای حل مساله N وزیر با زبانهای برنامهنویسی C++/C، پایتون و جاوا انجام شده است.

خروجی مورد انتظار، یک ماتریس دودویی است که در آن ۱ برای محلهایی که وزیر در آن قرار گرفته و ۰ برای محلهای فاقد وزیر است. برای مثال، ماتریس خروجی زیر، برای مساله ۴ وزیر است که تصویر آن در بالا وجود دارد.
{ 0, 1, 0, 0}
{ 0, 0, 0, 1}
{ 1, 0, 0, 0}
{ 0, 0, 1, 0}الگوریتم ساده برای حل مساله N وزیر
الگوریتم ساده برای حل مساله n وزیر، همه پیکربندیهای ممکن برای وزیرها روی صفحه را تولید میکند و پیکربندی را چاپ میکند که محدودیتهای داده شده را ارضا میکند.
الگوریتم پَسگرد
در الگوریتم «پَسگرد» (Backtracking)، ایده آن است که وزیرها یکی یکی در ستونهای متفاوت قرار بگیرند و کار از چپترین ستون آغاز میشود. هنگامی که یک وزیر در ستون قرار میگیرد، بررسی میشود که آیا وزیر جدید قرار داده شده با سایر وزیرهای قرار گرفته در صفحه تصادم دارد یا خیر. در ستون کنونی، اگر سطری پیدا شود که هیچ ضربی بین وزیر جدید و سایر وزیرها وجود نداشته باشد، وزیر در آنجا قرار داده میشود. در غیر این صورت، پسگرد اتفاق میافتد و false بازگردانده میشود. الگوریتم پَسگرد برای حل مساله n وزیر، به صورت زیر است:
- از چپترین ستون شروع کن.
- اگر همه وزیرها قرار گرفتهاند،
- True را بازگردان
- همه سطرها در ستون کنونی را بررسی کن. اقدامات زیر را برای هر سطر آزموده شده انجام بده.
- اگر وزیر بتواند به صورت امن در این سطر قرار بگیرد، آن را [row, column] به عنوان بخشی از راهکار علامتگذاری کن و به طور بازگشتی بررسی کن که آیا قرار دادن وزیر در اینجا منجر به راهکار میشود.
- اگر قرار دادن وزیر در [row, column] منجر به راهکار میشود، true را بازگردان.
- اگر قرار دادن وزیر منجر به یک راهکار شود، نشانهگذاری آن را بردار [row, column] (پسگرد) و به مرحله a برو و سطر دیگری را بررسی کن.
- اگر همه سطرها مورد بررسی قرار گرفتند و هیچ یک پاسخ نبودند، false را به trigger backtracking (عامل عقبنشینی) بازگردان.
پیادهسازی مساله N وزیر در ++C/C
پیاده سازی مساله N وزیر در پایتون
پیاده سازی مساله N وزیر در جاوا
0 0 1 0 1 0 0 0 0 0 0 1 0 1 0 0
آموزش سوئیفت (Swift): نوشتن تست — بخش هفدهم
در این مقاله از سری مقالات آموزش سوئیفت بر روی مبحث نوشتن تست متمرکز خواهیم بود. شاید فکر کنید نوشتن تست یک کار اختیاری است و هیچ منطقی را اجرا نمیکند که به همراه اپلیکیشن عرضه شود. اگر واقعاً این گونه فکر میکنید، قطعاً در مصاحبه استخدامی خود مردود خواهید شد. با ما همراه باشید تا دلیل این مسئله را بازگو کنیم. برای مطالعه بخش قبلی این مجموعه مطلب آموزشی میتوانید به لینک زیر رجوع کنید:
نوشتن تست
تست کردن مهم است و ارتباط تنگاتنگی با رویکرد TDD دارد. TDD اختصاری برای عبارت «Test-driven Development» (توسعه تست-محور) است. توسعه تست-محور یک روش رایج برای نوشتن اپلیکیشن است و بهخاطرسپاری این فرمول نیز آسان است.
- یک حالت تست شکست بنویسید.
- کد کافی بنویسید و از نوشتن کد اضافی برای پاس کردن تست اجتناب کنید.
- تست کنید تا پاس شدن حالت را تضمین کنید.
روشهای دیگری نیز برای تست کردن وجود دارند. میتوانید از گزارههای پرینت ساده برای نمایش نتایج قبل و بعد از اجرای کد استفاده کنید که روش خوبی برای تست کردن است. همچنین میتوانید اپلیکیشن خود را اجرا کنید تا مطمئن شوید که هیچ چیزی خراب نمیشود که در واقع کمترین حالت مورد نیاز برای تست است و احتمالاً به هر حال آن را اجرا خواهید کرد.
ما در این مقاله صرفاً به پوشش روش TDD میپردازیم. پیش از آن که کار خود را آغاز کنیم باید با دو اصطلاح جدید آشنا شوید: «Test Ratio» (نسبت تست) و «Code Coverage» (پوشش کد).
نسبت تست به نسبت تعداد خطوط کد به خطوط تستهای نوشتهشده گفته میشود. افراد زیادی هستند که میگویند هر 1 خط کد باید با 3 خط تست شود، یعنی این نسبت باید 1:3 باشد.
پوشش کد یعنی چه میزان از کد برحسب درصد تست شده است. IDE-های زیادی به نمایش پوشش کد میپردازند که کدبیس را برحسب وضعیت تست نمایش میدهد. رنگ سبز به معنی وجود تست برای کد و رنگ قرمز به معنی عدم وجود تست است.
برخی افراد بر این باورند که به صورت پیشفرض همه کدها باید تست شوند. اما شاید این دیدگاه چندان صحیح نباشد، چون لزومی وجود ندارد که تابعهای موجود در سوئیفت و دیگر کتابخانهها که خودشان شامل تست هستند مجدداً تست شوند. برای نمونه لازم نیست برای یک گزاره print یا دیگر متدهای استاتیک مانند ()Date.init تست نوشت. در واقع صرفاً لازم است که کد خودتان را تست کنید. تنها استثنا در این مورد کدهای افراد دیگری است که تست نداشته باشند.
نحوه نوشتن تست چیزی شبیه زیر است:
کد فوق را خط به خط بررسی میکنیم. import XCTest اقدام به ایمپورت کردن کتابخانه ارائه شده از سوی اپل برای تست کردن میکند. testable import ViewController @testable یک خصوصیت است که دامنه دسترسی این ماژول را افزایش میدهد. در واقع این دستور سطح دسترسی را از internal یا private به open تغیر میدهد اما تنها برای تستهای لوکال کار میکند. دستور import ViewController گزاره ایمپورتی است که شامل کلاس مورد نظر برای تست است.
{ … } class ViewControllerTests: XCTestCase کلاسی تعریف میکند که همه کارکردهای خود را از XCTestCase به ارث میبرد. اگر از هرکدام از مشخصهها استفاده کنید، چه کلاس دیگر باشد و چه برخی از ثابتها یا متغیرهایی که غالباً در کاربردهای تست استفاده میشود به جای Testing properties here// آن مشخصهها را بنویسید.
()override func setUp را میتوان به عنوان ()viewDidLoad برای حالتهای تست تصور کرد. زمانی که شروع به تست کردن میکنید، این کد کلاسها را ایجاد میکند یا از متغیرها وهله میسازد.
()override func tearDown معادل {} deinit در کنترلرهای نما است. هر چیزی را که ممکن است موجب ایجاد نشت حافظه شود پاک کنید، Timer مثال خوبی از آن چیزی است که باید حذف شود.
()func test_multiplyByTwoReturnsFour یکی از قراردادهای نامگذاری فراوانی است که وجود دارد، اما این نام گذاری مقصود تست را مشخص میکند. موارد تست را همواره با عبارت test آغاز کنید. استفاده از _ اختیاری است، اما به افزایش خوانایی کمک میکند. در ادامه multiplyByTwo آن چیزی است که قرار است انجام دهیم و ReturnsFour آن چیزی است که انتظار داریم دریافت کنیم. اگر موارد تست را به این ترتیب بنویسید همواره میدانید که هر مورد تست برای چه چیزی استفاده میشود و چه نتیجهای از آن انتظار میرود. اما اگر در نهایت صرفاً اعداد فرد و گرد شده بازگشت یابند چطور؟ بدین ترتیب میتوان مورد تستی مانند {} func test_getOddFromMultiplyByTwo_ReturnsFive نوشت.
در نهایت دستور (XCTAssertEqual(value، value را میبینیم که مورد تست واقعی است که برابر بودن هر دو مقدار را تست میکند. XCTAssert یک پیشوند رایج است و از این رو اگر شروع به نوشتن XCT بکنید امکان تکمیل خودکار در Xcode تعدادی از متدهایی که میتوانید استفاده کنید را به شما پیشنهاد میکند. در این حالت اگر هر دو مقدار برابر باشند تست پاس میشود و در غیر این صورت ناموفق خواهد بود.
برخی تستهای رایج دیگر شامل XCTAssertNotEqual ،XCTAssertNil و XCTAssertNotNil هستند.
تست کردن تنها به بررسی این که اشیای مختلف باید چگونه باشند محدود نمیشود بلکه میتوان به اندازهگیری عملکرد نیز پرداخت. این نوع از تست یکی از مفیدترین تستها است زیرا پس از این که مطمئن شدیم کار درستی انجام میدهیم باید اطمینان پیدا کنیم که آن را به طرز صحیحی نیز انجام میدهیم. بدین ترتیب میتوانیم به مرور کد خود را بهبود بخشیم.
برخلاف تستهای تأییدی ما، نیازی نیست که بخش بازگشتی مورد انتظار را در اعلان متد بگنجانیم. به جای آن کافی است آن را با بلوک { }test_functionNamePerformance(). measure عوض کنیم که باید صرفاً شامل کدی باشد که میخواهیم اندازهگیری کنیم. اگر قرار باشد یک متغیر به (:getFactorial(of ارسال کنیم، در این صورت آن را خارج از بلوک اندازهگیری وهلهسازی میکنیم، مگر این که بخواهیم آن را در اندازهگیریهای خود بگنجانیم.
(getFactorial(of: 45 =_ به فراخوانی متد getFactorial با ورودی 45 میپردازد. از آنجا که نیازی به ذخیرهسازی مقدار نداریم از =_ استفاده میکنیم که نوعی جابجایی نتایج به /dev/null محسوب میشود. برای ما مهم نیست که این مقدار چیست و در اینجا به آن اهمیتی نمیدهیم.
آنچه در اینجا برای ما مهم است، این است که تابع فاکتوریل چه قدر طول میکشد تا کار خودش را اجرا بکند. زمانی که این کد را اجرا کنید موارد تست 10 بار اجرا میشوند.
در اجرای نخست این کد تابع را در طی 0.00000263 اجرا میکند. این زمان کاملاً سریع است اما در طی این مدت بهینهسازیهایی رخ میدهند. در ادامه اجراهای بعد را میبینیم.
در اجرای دوم، ما این تابع را 39 درصد بهتر اجرا کردهایم، اما هیچ چیز تغییر نیافته است. دلیل این امر آن است که بهینهسازیها قبلاً صورت گرفتهاند و صرفاً از آنها مجدداً استفاده کردهایم. این جا مکان خوبی برای تنظیم مبدأ جدید است بنابراین ویرایش را کلیک میکنیم و مبدأ جدید را پذیرفته و آن را ذخیره میکنیم. در اجراهای بعدی به ترتیب 6% عملکرد بدتر، 0% بهتر، 2% بهتر، و 7% بهتر بدون تغییر دادن هیچ خطی از کد به دست آمدند. بنابراین مبدأ خوبی برای ما محسوب میشود. از این جا میتوانیم تغییرات خود را ایجاد کرده و سپس اندازهگیریها را تست کنیم تا ببینیم آیا تغییرات ما موجب عملکرد بهتر یا بدتر میشوند.
با این که راهنمای صریحی در مورد آن چه بهینهسازی خوب شمرده میشود وجود ندارد اما تصور ما این است هر تغییری که موجب بهبود در طی 10 اندازهگیری (100 اجرا) شود مناسب است. اگر کدی در طی چند اجرای نخست بهبود مناسبی نشان دهد بهتر است آن تغییر را حفظ کنید.
زمانی که در مورد تست کردن Unit Testing صحبت میکنیم، در واقع همان فرایندی است که در بخش فوق توضیح دادیم. همچنان یک حالت تست کردن عمومی نیز وجود دارد که به تست کارکرد کلی عملکرد اپلیکیشن چنان که انتظار میرود میپردازید. UI Testing نوع دیگری از تست کردن است که بخش UI را در برمیگیرد، اما از آنجا که این راهنما صرفاً در مورد مفاهیم مقدماتی تست کردن است بررسی آن خارج از دامنه این مقاله خواهد بود. در نهایت باید اشاره کنیم که یک تست پذیرش کاربر (UAT) نیز وجود دارد که برای اطمینان یافتن از این که کاربر از امکانات اپلیکیشن راضی است اجرا میشود. این تست عموماً از طریق تیمهای پرسش و پاسخ (QA) اجرا میشود و کسبوکار یا مخاطبان منتخب از کاربران نهایی را شامل میشود. این تست امکان اجرای سناریوهای بیشتری در اپلیکیشن را میدهد که برای تست کردن بیشتر استفاده میشوند و به سؤالاتی در مورد شیوه استفاده از اپلیکیشن و زمان عرضه نهایی آن پاسخ میدهد.
سخن پایانی
ما در این مقاله با مفاهیم مقدماتی تست کردن آشنا شدیم و دیدیم که چگونه میتواند به نوشتن کدهای بهتر کمک کند، چه اهمیتی در چرخه توسعه دارد و چگونه عملکرد کد را اندازهگیری میکند. تستهای بیشتر شامل استفاده از ابزارهای Xcode است که میتوان از آنها برای اندازهگیری حافظه، CPU و استفاده از دیسک بهره گرفت، اما اینها جزء مباحث پیشرفته هستند. در بخش بعدی در مورد معماری Model View Controller صحبت میکنیم.
معماری مدل، نما-کنترلر یا به اختصار MVC به صورت گستردهای برای یادگیری آموزش کدنویسی به افراد مبتدی استفاده میشود. این سادهترین روش برای یادگیری شیوه استفاده از چندین فایل در یک پروژه است. با این که روشهای دیگری نیز وجود دارند که میتوان استفاده کرد، اما این سادهترین نوع معماری محسوب میشود. زمانی که آماده انتقال از MVC باشید تقریباً به طور طبیعی شروع به نوشتن یک سبک معماری متفاوت برحسب نیازهای اپلیکیشن خود میکنید. برای مطالعه بخش بعدی (پایانی) به اینک زیر مراجعه کنید:
منبع: فرادرس
اعتبارسنجی فرم با قلاب های React — به زبان ساده
چند قلاب ریاکت وجود دارند که در این نوشته به بررسی آنها میپردازیم. همچنین یک قلاب سفارشی میسازیم که تنها از قلاب useState برای اعتبار سنجی فرم استفاده میکند. اگر میخواهید مثال عملی آن را ببینید به این صفحه (+) مراجعه کنید. ایده کار این است که یک قلاب سفارشی ایجاد کنیم که برخی دادههای اولیه، اعتبارسنجی و اعتبارسنجی کنندهها را دریافت کند. کد نهایی این قلاب به صورت زیر خواهد بود. در ادامه طرز کار آن و همچنین شیوه استفاده از قلاب های React برای اعتبارسنجی یک فرم را بررسی میکنیم.
به طور کلی این قلاب یک آرایه با 2 بخش «حالت» (State) و 3 تابع بازگشت میدهد. در ادامه هر یک از این موارد را بررسی میکنیم.
متغیر فرم، حالت را به همراه تابع nChange و onClick برای همه بخشهای حالت نمایش میدهد و این بدان معنی است که دادههای اولیه فرم به صورت زیر در اختیار ما است:
متغیر فرم که از سوی قلاب بازگشت مییابد به صورت زیر خواهد بود:
بخش اعتبارسنجی پاسخهای اعتبارسنجی حاصل از valida-js را نگهداری میکند.
3 تابع دیگر به صورت زیر هستند:
- validate: همه formData را به یک باره اعتبارسنجی میکند.
- getData: یک شیء بازگشت میدهد که دارای همان امضای مقدار اولیه ارسالی به قلاب است.
- setData: دادهها را از روی حالت تنظیم میکند و یک شیء با همان امضای پارامتر اولیه قلاب ارسال میکند.
استفاده از قلاب
ابتدا قلاب را از npm ایمپورت میکنیم و سپس آنها را درون تابع کامپوننت قرار میدهیم.
قلاب به نام useValidatedForm را میتوان دستکم در دو پارامتر مورد استفاده قرار داد که یکی دادههای اولیه برای فرم است (که باید طرحبندی کامل دادهها باشد) و پارامتر دوم آرایه قواعد اعتبارسنجی است. این قواعد اعتبارسنجی برای valida-js استفاده خواهد شد.
اینک مقدار بازگشتی از قلاب و شیوه مقداردهی اولیه آن را میدانیم. در ادامه فرم کوچکی را به وسیله آن مینویسیم:
بخشهای مهم به شرح زیر هستند:
در ابتدا بررسی میکنیم که در صورتی که مشخصهای خطا داشته باشد، چگونه باید آن را بخوانیم. شاید بهتر بود که یک تابع برای انجام این کار مینوشتیم، اما فعلاً از همین منطق ساده استفاده میکنیم. اگر آرایهای از خطاهای یک مشخصه، طولی بلندتر از 0 داشته باشید به این معنی است که خطایی رخ داده است و در غیر این صورت فرض ما این است که خطایی وجود ندارد.
بخش مهم دیگر به صورت زیر است:
جایی که شیء ورودی firstName را افراز میکنیم به این معنی است که props را به ورودی value، دستگیره onClick و دستگیره onChange میفرستیم. به این ترتیب قصد داریم متادیتای مشخصه را بهروزرسانی کنیم. همچنین مقدار ورودی را زمانی که کاربر در ورودی مینویسد بهروز کرده و اعتبارسنجی در مورد مشخصه خاص فرم را نیز بهروزرسانی میکنیم. از این رو validation.errors.firstName نیز در این حالت بهروزرسانی میشود.
یکی از موضوعات شگفتانگیز در این مورد آن است که اینک میتوانیم کامپوننتهای کنترل را بسازیم و validation.property، form.property و منطق دقیق را برای قرار دادن خطا و کلاسها در آنجا ارسال کنیم.
در این مثال تنها از یکی از قلابهای موجود روی React یعنی useState استفاده کردیم، اما شما میتوانید به بررسی قلابهای دیگر و روش استفاده از آنها نیز بپردازید.
منبع: فرادرس