طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیالگوریتم های مهم پایتون که باید آنها را بدانید — راهنمای کاربردی
برخی الگوریتمهای خاص هستند که استفاده زیادی در زمان برنامهنویسی دارند. در این راهنما به بررسی چند الگوریتم مهم پایتون که جزء رایجترین انواع این الگوریتمها هستند به همراه مثال میپردازیم. این الگوریتمها شامل جستجو، مرتبسازی و افزودن/حذف کردن آیتم به لیست پیوندی هستند. ایدههای پیرامون این مثالها در مورد الگوریتمهای زیاد دیگری نیز صدق میکند. درک این سه مثال و الگوریتم به شما کمک میکنند تا اطلاعات خوبی در مورد روش برخورد با مسائل مرتبط با الگوریتمهای دیگر نیز کسب کنید و در این زمینه اعتماد به نفس داشته باشید.
جستجوی دودویی
«جستجوی دودویی» (Binary Search) یک الگوریتم ضروری جستجو است که روی آرایههای مرتب اجرا میشود و اندیس یک مقدار را که به دنبالش هستیم بازگشت میدهد. این کار به صورت زیر اجرا میشود:
- نقطه میانی آرایه مرتب را پیدا کنید.
- نقطه میانی را با مقدار مورد نظر مقایسه کنید.
- اگر نقطه میانی بزرگتر از مقدار مورد نظر باشد، جستجوی باینری در نیمه راست آرایه تکرار میشود.
- اگر نقطه میانی کوچکتر از مقدار مورد جستجو باشد، جستجوی باینری روی نیمه چپ آرایه تکرار میشود.
- این مراحل را تا زمانی که نقطه میانی برابر با مقدار مورد نظر باشد یا این که بدانیم مقدار مورد جستجو در آرایه وجود ندارد تکرار میکنیم.
از روی مراحل فوق مشخص است که راهحل ما میتواند به صورت «بازگشتی» (recursive) باشد. ما در هر تکرار یک آرایه کوچکتر را به متد خود ارسال میکنیم تا این که تنها یک مقدار که مورد نظر ما است باقی بماند. بخشهای دشوار این راهحل اندیسگذاری صحیح آرایه و ردگیری افست اندیس در هر تکرار است به طوری که بتوان اندیس مقدار مورد جستجو را در آرایه اصلی پیدا کرد. در کد زیر نسخهای از الگوریتم جستجوی دودویی را مشاهده میکنید:
جستجوی دودویی پیچیدگی زمانی برابر با (O(logn دارد. میدانیم که در این حالت وقتی اندازه آرایه ورودی را دو برابر کنیم، باید یک تکرار بیشتر برای یافتن مقدار مطلوب در الگوریتم خود اضافه کنیم. به همین دلیل است که جستجوی باینری چنین الگوریتم کارآمدی در علوم رایانه محسوب میشود.
مرتبسازی ادغامی
«مرتبسازی ادغامی» (Merge Sort) از روششناسی مشابه «تقسیم و حل» (divide and conquer) برای مرتبسازی کارآمد آرایهها بهره میگیرد. مراحل زیر در مورد شیوه پیادهسازی مرتبسازی ادغامی است.
- اگر آرایه تنها یک عنصر داشته باشد، بازگرد زیرا چنین آرایهای مرتب محسوب میشود.
- آرایه را به طور متوالی دو نیمه تقسیم کن، تا این که دیگر نتوان بیش از آن تقسیم کرد.
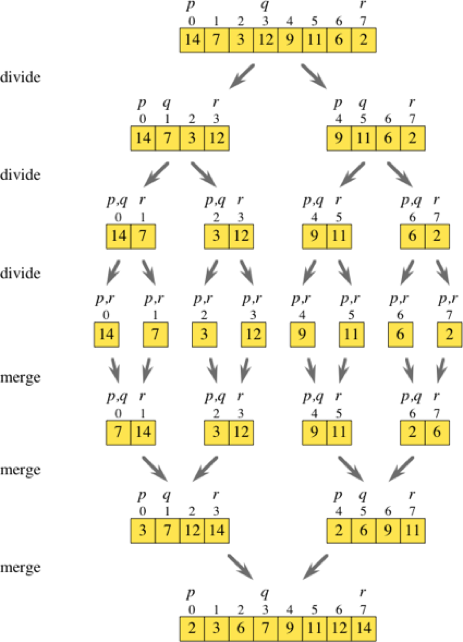
- آرایههای کوچکتر را به صورت مرتب با هم ادغام کن تا این که به آرایه اصلی مرتبسازی شده برسی.
برای پیادهسازی مرتبسازی ادغامی، دو متد را تعریف خواهیم کرد. یکی از متدها اختصاص به افراز کردن آرایه دارد و دیگری وظیفه ادغام کردن مجدد دو آرایه مرتب را به صورت یک آرایه مرتبسازی شده بر عهده دارد. متد تقسیم کردن (merge_sort) به صورت بازگشتی فراخوانی میشود تا این که آرایه تنها یک عنصر طول داشته باشد. سپس این آرایههای فرعی با هم ترکیب میشوند تا نهایتاً یک آرایه مرتب بازگشت یابد. به مثال زیر توجه کنید:
مرتبسازی ادغامی دارای پیچیدگی زمانی (O(nlog n است که بهترین پیچیدگی زمانی برای یک الگوریتم مرتبسازی محسوب میشود. ما میتوانیم با بهرهگیری از تقسیم و حل کردن، کارآیی مرتبسازی را که اصولاً یک پردازش پرهزینه از نظر محاسباتی است به میزان زیادی افزایش دهیم.
افزودن و حذف کردن آیتم از لیست پیوندی
لیست پیوندی یکی از ساختمانهای داده بنیادی در علوم کامپیوتر محسوب میشود که دلیل آن به خاطر زمان ثابت درج و حذف است. با استفاده از گرهها و اشارهگرها میتوانیم برخی پردازشها را به روشی کارآمدتر از زمانی که از آرایه استفاده میکردیم اجرا کنیم. به نمودار شماتیک زیر توجه کنید:

یک لیست پیوندی از گرههایی تشکیل یافته است که هر یک بخشی از دادهها و یک اشارهگر به گره بعدی دارند. این وضعیت در Ruby با یک struct به نام Node نمایش پیدا میکند که دو آرگومان به نامهای data: و:next_node دارد. اینک کافی است دو متد به نامهای insert_node و delete_node تعریف کنیم که یک گره head و یک location برای مکانی که حذف/درج رخ میدهد میپذیرد.
متد insert_node یک آرگومان دیگر به نام node نیز دارد که همان struct گرهی است که میخواهیم درج کنیم. سپس حلقهای تعریف میکنیم تا موقعیتی را که میخواهیم آیتمی را در آن درج یا حذف کنیم بیابیم. زمانی که به مکان مطلوب برسیم، اشارهگرها را طوری مجدداً چیدمان میکنیم تا عملیات درج/حذف ما را بازتاب دهند.
در یک لیست پیوندی میتوان آیتمها را از میانه یک مجموعه بدون نیاز به تغییر دادن بقیه ساختمان داده در حافظه حذف کرد و این وضعیت کارایی بیشتری نسبت به ساختمان داده آرایه ایجاد میکند. بدین ترتیب میبینیم که با انتخاب بهترین ساختمان داده بر اساس نیازها میتوان به کارایی مناسبی دست یافت.
سخن پایانی
سه نسخه الگوریتمی که در این مقاله معرفی کردیم، تنها جزء کوچکی از الگوریتمهای بنیادی هستند که باید برای خلق برنامههای کارآمد و موفقیت در مصاحبههای فنی بدانید. لیستی از الگوریتمهای دیگر که در این زمینه توصیه میشود مطالعه کنید به شرح زیر هستند:
- الگوریتم Quicksort
- پیمایش یک درخت جستجوی دودویی
- درخت کمینه پوشا
- الگوریتم Heapsort
- معکوس سازی یک رشته به صورت درجا
البته مفاهیم دیگری نیز وجود دارند که باید بیاموزید، بنابراین توصیه میکنیم به تمرین کردن و درک مثالهای بیشتری از الگوریتمها ادامه بدهید.
منبع: فرادرس
همه چیز درباره Git LFS — به زبان ساده
اغلب ما نخستین باری که با LFS در Git مواجه شدیم، در زمان کار روی پروژههای علوم داده بوده است. شاید با خود بپرسید Git خود به اندازه کافی دشوار است، آیا باید یکی دیگر از قابلیتهای آن را نیز یاد بگیریم؟ شاید هم کنجکاو هستید که Git LFS چیست و چرا باید آن را بیاموزید. در این صورت توصیه میکنیم، در ادامه این مقاله با ما همراه باشید تا به پاسخ سؤالهایتان برسید.
ابتدا مقدمه کوتاهی در مورد اهمیت LFS و کاربرد آن بیان میکنیم. تصور کنید مشغول کار روی یک پروژه تحلیل دادههای فیلم برای نمونه از وبسایت OMDB ،Rotten Tomatoes و IMDB هستید. اما زمانی که کارها را روی گیتهاب میبرید در زمان آپلود کردن مجموعه داده IMDB با خطایی مانند زیر مواجه میشوید:
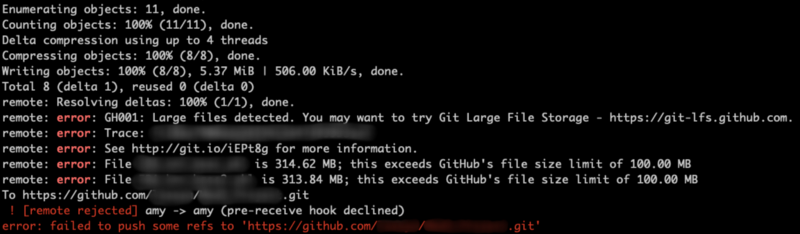
در این زمان است که متوجه میشوید گیت و گیتهاب محدودیت اندازه فایل 100 مگابایت دارند. فایلهایی با اندازههای بزرگتر از 50 مگابایت پیام هشدار دریافت میکنند، اما میتوان آنها را push کرد.
نخستین راهکاری که در این حالت به صورت طبیعی به ذهن میرسد این است که کار را با ارسال تک به تک فایلها ادامه دهد. اما اگر این راهکار به هر دلیلی ممکن نباشد، باید گزینه بعدی یعنی ذخیرهسازی به روش Large File Storage را در گیت بررسی کنیم. برای این که Git LFS را درک کنیم باید ابتدا گیت را بشناسیم. بنابراین قبل از بررسی LFS اندکی در مورد گیت توضیح میدهیم.
گیت چیست؟

گیت یک سیستم کنترل نسخه توزیع یافته است، یعنی کل سابقه ریپازیتوری در طی فرایند کلون کردن به کلاینت انتقال مییابد.
اگر بخواهیم این موضوع را کمی بیشتر باز کنیم، باید ابتدا سیستم کنترل نسخه را توضیح دهیم. «سیستم کنترل نسخه» (Version Control System) ابزاری است که به مدیریت تغییرها در کد منبع، فایلها و دیگر اَشکال اطلاعات میپردازد. بدین ترتیب تغییرها به صورت commit ردگیری میشوند. Commit در واقع تصاویری از ویرایشها در نقاط زمانی مشخص هستند. در سوی دیگر یک سیستم کنترل نسخه توزیع یافته نوعی از سیستم کنترل نسخه است که امکان انتقال همه کدبیس شامل همه سوابق (و همه تغییرها) به رایانه هر توسعهدهنده را فراهم میسازد. بدین ترتیب هر توسعهدهنده میتواند روی پروژهای کار کند و همزمان کل تایملاین ویرایشهای انجام یافته روی پروژه را ببیند.
تاریخچه گیت
گیت نخستین بار در سال 2005 از سوی «لینوس تروالدز» (Linus Torvalds) و در نتیجه توقف استفاده از سیستم کنترل نسخه Bitkeeper خلق شد. دلیل توقف لینوس و همکارانش نیز این بود که Bitkeeper دیگر رایگان نبود و پولی شده بود. بر اساس گزارشها لینوس پس از تلاش برای یافتن یک سیستم کنترل نسخه رایگان جایگزین برای Bitkeeper تصمیم گرفت تا سیستم کنترل نسخه خود را بسازد که کوچک و سریع (کمتر از سه ثانیه زمان بگیرد) باشد و از انشعاب پشتیبانی کند. همچنین این سیستم باید کاملاً مخالف سیستمهای کنترل نسخه همزمان و شامل safeguards برای صحت دادهها میبود.
از آنجا که گیت ساخته شده است تا کوچک و سریع باشد، در ابتدا صرفاً برای پشتیبانی از سورس کد ساخته شد و از فایلهای بزرگ پشتیبانی نمیکرد. توجه کنید که گیت یک سیستم کنترل نسخه است یعنی هر بار که پروژهای کلون یا pull میشود همه سابقه کامل تغییرهای یک پروژه انتقال مییابد. زمانی که یک کامیت اضافه میشود، به سوابق افزوده میشود و موجب افزایش اندازه فایل کلی پروژه میشود و در طی زمان این مقدار بسیار افزایش مییابد.
با این وجود، رشتههای زیادی وجود دارند که در آن پروژههایی با فایلهای بزرگ ایجاد میشوند و این حالت شامل حوزه فایلهای موسیقی، تصویر و مجموعههای دادههای علمی نیز میشود. بنابراین اینک سؤال این است که در چنین موقعیتهایی چه باید کرد؟ این همان نقطهای است که Git LFS به کارمی آید.
«ذخیرهسازی فایل بزرگ» Git یا LFS به چه معنا است؟

Git LFS یک اکستنشن گیت است که در Go برنامهنویسی شده و از سوی توسعهدهندگانی در Atlassian و Github و همچنین مشارکتکنندگان اوپنسورس جهت دور زدن محدودیت اندازه فایل در گیت ساخته شده است. این کار از طریق ذخیرهسازی فایلهای بزرگ در یک مکان مجزا از ریپازیتوری و قرار دادن اشارهگرهای فایل در ریپازیتوری که مستقیماً به محل فایل اشاره میکنند صورت میپذیرد.
بهترین روش برای درک طرز کار LFS این است که ابتدا برای لحظهای همه چیز را در مورد Github ،Bitbucket ،Gitlab و همه ریپازیتوریهای ریموت فراموش کنیم. در این مرحله صرفاً روی رایانه محلی تمرکز میکنیم که در تصویر زیر با شکل یک نمایشگر با سه بخش Working Copy ،Local Repository و LFS Cache نمایش یافته است.
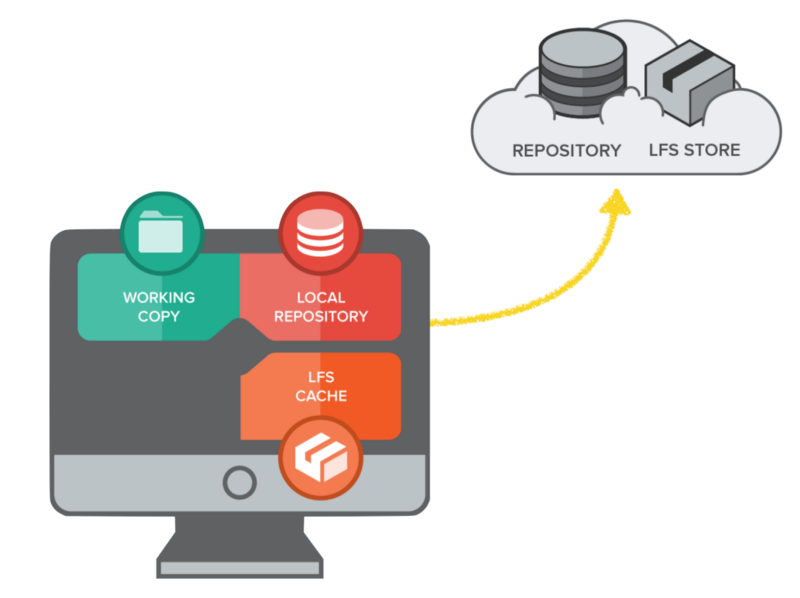
ریپازیتوری محلی
«ریپازیتوری محلی» (local repository) آن دایرکتوری یا پوشهای است که روی رایانه خود میبینید و با استفاده از دستور git init به عنوان ریپازیتوری گیت مقداردهی شده و یا از ریپازیتوری ریموت کلون شده است. «کپیِ کاری» (Working Copy) یک بازنمایی از فایلها و پوشههایی است که در ریپازیتوری محلی ویرایش میشوند. LFS Cache مکان ذخیرهسازی مجزایی است که در ریپازیتوری محلی ویرایش میشود. LFS Cache فضای ذخیرهسازی مجزایی برای فایلهای بزرگ است که از طریق گیت push میشوند. این اصطلاحها را به ذهن خود بسپارید، چون در زمان توضیح طرز کار Git LFS در بخش بعدی به کار خواهند آمد.
کار با Git LFS
نکته مهم در مورد Git LFS این است که میتوان در آن همچنان از دستورهای عادی و گردش کار معمولی گیت که کاملاً شناخته شده هستند استفاده کرد. تنها تغییر در این مورد برخی دستورهای اضافی و مکان ذخیرهسازی مجزایی هستند که باید در خاطر داشت.
اکنون که اطلاعاتی در مورد گیت و Git LFS داریم، در ادامه به بررسی روش استفاده از آن میپردازیم. دو سناریو در این خصوص وجود دارد، اما ابتدا باید Git LFS را از طریق Homebrew با دستور زیر دانلود کنیم:
brew install git-lfs
در مورد سیستمهای غیر مَک نیز امکان دانلود از طریق وبسایت (+) وجود دارد.
سناریوی اول
در این سناریو از Git LFS پس از دریافت پیام خطایی در زمان استفاده از دستورهای معمولی گیت استفاده میکنیم.
در این مثال یک ریپازیتوری جدید داریم که یک فایل داده بزرگ (1.9 گیگابایت) در آن قرار دادهایم. ما میخواهیم مطمئن شویم که هر تغییری در مورد فایلهای داده ردگیری میشود و در نهایت به صورت ریموت پشتیبانگیری خواهد شد. ابتدا از دستورهای معمولی گیت برای stage کردن فایل (git add) استفاده میکنیم، یک کپی از تغییرها را در ریپازیتوری محلی (git commit) ذخیره میکنیم و کپی را به ریپازیتوری ریموت ارسال میکنیم (git push). خروجی این دستورها به صورت زیر است:
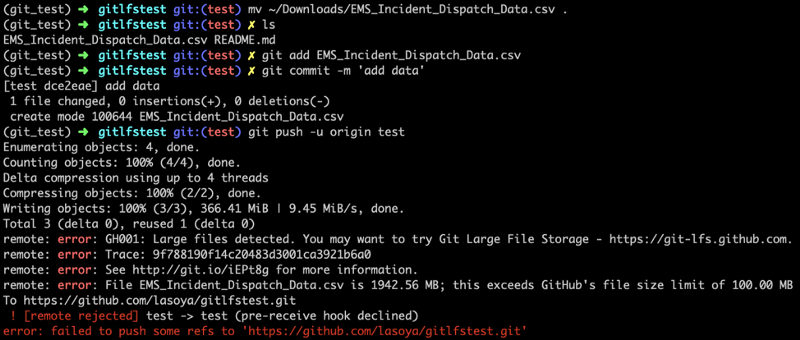
این خطا را چگونه میتوان حل کرد؟ یک راهحل این است که تغییرها را با استفاده از git reset بازگردانی کنیم و یا از ذخیره فایل صرفنظر کنیم و آن را به صورت zip و با اندازه کوچکتر دربیاوریم و یا این که مسیر خود را با Git LFS ادامه دهیم. گزینه دیگر این است که از همان جایی که کار متوقف شده اقدام به یکپارچهسازی Git LFS بکنیم و بدین ترتیب امکان ادامه فرایند وجود خواهد داشت. ما در این بخش این مسیر را دنبال میکنیم.
گام 1
نخستین گام در این مسیر آن است که Git LFS را نصب کرده و از طریق اجرای دستور زیر، ریپازیتوری خاصی را برای آن فعالسازی کنیم:
git lfs install
با این که قبلاً Git LFS را روی سیستم خود نصب کردهایم، اما باید به آن اعلام کنیم که کدام ریپازیتوری ها به خدماتش نیاز دارند. برای قیاس یک شرکت ارائهدهنده سرویس ذخیرهسازی را در نظر بگیرید. چنین شرکتهایی در دسترس ما هستند تا آیتمهایی را در آنها ذخیره کنیم، اما به صورت خودکار به سراغ ما نمیآیند تا فایلهایمان را ذخیرهسازی کنند. بلکه ما باید ابتدا با عقد قرارداد یک رابطه با این شرکت برقرار کنیم. همین حالت در اینجا نیز صدق میکند. برای فعالسازی سرویسهای Git LFS در یک ریپازیتوری خاص یا اعلام این که سرویسهای Git LFS برای کدام ریپازیتوری باید فعال شود از دستور زیر استفاده میکنیم:
git lfs install

گام 2
با دستور زیر به Git LFS اعلام کنید که کدام فایلها باید ردگیری شوند:
git lfs track “*.file_extension”
در این مورد نیز باید به Git LFS اعلام کنیم که کدام فایلها و یا کدام انواع فایلها را میخواهیم ردگیری کند، بدین ترتیب فایلها میتوانند در مکان دیگری به جز ساختار گیت خیره شوند تا از دریافت پیام خطای قبلی جلوگیری شود. به این منظور دستور فوق را اجرا کنید.
برای مثال اگر لازم است همه فایلهای CSV ردگیری شوند دستور زیر را اجرا کنید:
git lfs track “*.csv”
یا اگر لازم است همه فایلهای jpeg ردگیری شوند، دستور زیر را وارد کنید:
git lfs track “*.jpg”
کاراکتر ستاره (*) نشاندهنده همه فایلها است. استفاده از گیومه نیز برای اجرای این کد ضروری است. بدون وجود گیومه با خطای زیر مواجه میشویم:
![]()
همان طور که وقتی از یک شرکت ذخیرهسازی میخواهیم شروع به ذخیرهسازی آیتم بکند، یک صورتحساب برای ما ارسال میکند، در این مورد نیز وقتی یک فایل را با Git LFS ردگیری کنیم، یک فایل gitattributes. ایجاد خواهد شد. اگر فایل gitattributes. از قبل موجود باشد، این فایل به صورت یک خط جدید در آن اضافه میشود.
![]()
گام 3
در این بخش با دستورهای Git add ،commit و push فایل gitattributes. را در ریپازیتوری خود قرار میدهیم.
Git LFS نیز همانند فایل gitattributes.، فایلهای جدید را ردگیری میکند، و تغییرهای صورت گرفته به صورت خودکار در فایل gitattributes. بهروزرسانی میشوند. برای این که مطمئن شویم تغییرها ردگیری میشوند، هر بار که فایل gitattributes. بهروزرسانی میشود، باید stage و commit شود چون در غیر این صورت ممکن است در ادامه با خطایی مواجه شویم.
گام 4
اینک میخواهیم با رمز اصلی این سناریو که استفاده از git LFS برای انتقال کامیتها از گیت به Git LFS است آشنا شویم.
آنچه موجب میشود بتوانیم در حالت کنونی و بدون نیاز به undo کردن کامیتها و راهاندازی مجدد فرایند از Git LFS استفاده کنیم، یک خط کد جالب است که امکان انتقال یا «migrate» کامیتها از گیت به Git LFS را فراهم میسازد. برای این که بتوانیم کامیتها را انتقال دهیم باید دستور زیر را اجرا کنیم:
git lfs migrate import — include “*.file_extension”
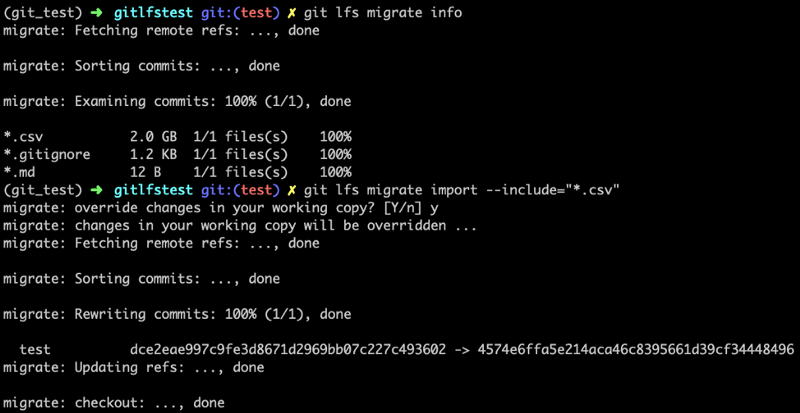
برای دیدن انواع فایلی که در کامیتها هستند و میتوانند از سوی Git LFS ردگیری شوند، میتوانیم دستور زیر را اجرا کنیم:
git lfs migrate info
با انتقال دادن کامیتها، میتوانیم به مرحله بعدی برویم و تغییرها را به گیتهاب push کنیم. در این خصوص در بخش بعدی بیشتر توضیح میدهیم:
نکته مهم: انتقال کامیتها شامل بازنویسی سابقه هستند. میتوان یک تگ اضافه کرد تا از بازنویسی تغییرهای لیست شده در سابقه جلوگیری کرد، اما این کار از اجرا شدن آن خط کد جلوگیری خواهد کرد.
گام 5
در نهایت دستور git push را اجرا میکنیم تا تغییرها را به گیتهاب پوش کنیم و کامیت بزرگ (یعنی فایلهای بزرگ) نیز به Gif LFS کامیت شوند.
پس از انتقال کامیتها به Git LFS در حال حاضر یک ریپازیتوری محلی گیت داریم که با یک تغییر بهروزرسانی شده است. در این مورد یک فایل داده جدید اضافه شده است که به وسیله اشارهگر فایل به Git LFS اشاره دارد. همچنین یک کش Git LFS محلی وجود دارد که اینک به ذخیره سای فایل داده میپردازد. در مرحله بعدی تغییرها را به گیتهاب پوش میکنیم. ریپازیتوری گیت محلی که دارای فایلهایی در چارچوب محدودیت اندازه تعیین شده باشند (یعنی فایلهای کد منبع و فایل اشارهگر) در گیتهاب ذخیره میشوند که میزبان گیت مشخص شده در تصویر زیر است و کش Git LFS در فضای ذخیرهسازی Git LFS روی کلود ذخیره میشود.

سناریوی دوم: استفاده از Git LFS از ابتدا
اگر بدانیم که فایلهای بزرگی در ریپازیتوری وجود دارند، میتوانیم از Git LFS از همان ابتدا استفاده کنیم و مراحل 1 تا 3 بررسی شده فوق را طی کنیم. پس از طی این مراحل به دستورهای معمولی گیت به صورت git add ،git commit بازمیگردیم تا تغییرها را در ریپوی محلی stage و ذخیره کنیم. سپس گام 5 فوق را اجرا میکنیم تا تغییرها را به گیتهاب و دیگر میزبانهای گیت و فضای ذخیره ریموت Git LFS پوش کنیم.
سخن پایانی
چنانکه مشاهده کردید روش Git LFS برای دور زدن مشکل ذخیرهسازی فایلهای بزرگ در سیستم کنترل نسخه گیت کاملاً سرراست است. کافی است پنج گام فوق را به خاطر بسپارید تا این فرایند را طی کنید. pull کردن تغییرها از یک ریپاریتوزی ریموت نیز کاملاً سر راست است. در این حالت همان دستورهای گیت که معمولاً استفاده میکنیم، یعنی git pull یا git fetch و git merge مورد نیاز هستند.
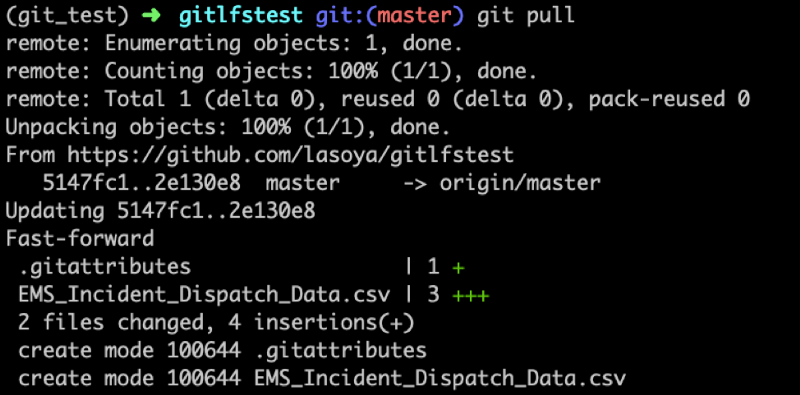
با استفاده از git pull میتوان تغییرها را که شامل فایل داده ذخیره شده در Git LFS میشود، روی سیستم محلی بارگذاری کرد. زمانی که تغییرها را از ریپازیتوری ریموت pull میکنیم، تغییرهای ریپازیتوری ریموت و هر شیء دیگری که در Git LFS ذخیره شده باشد، نیز روی رایانه محلی pull میشوند.
شاید همه موارد فوق در مواجهه نخست کمی سردرگمکننده به نظر برسند، بنابراین در ادامه نکاتی را که میتوان در این مقاله جمعبندی کرد، ارائه کردهایم.
- افرادی که به نظرشان گیت پیچیده میآید، باید بدانند که این مطلب بر پیچیدگی موضوع میافزاید. این مهمترین چالش این افراد در زمان یادگیری Git LFS خواهد بود. یادگیری دقیق دستورهای گیت، گردش کار گیت و شیوه تطبیق آن با Git LFS کلید یادگیری گامهای طرحشده در این آموزش است.
- حتی در زمان استفاده از Git LFS نیز محدودیت اندازه فایل 2 گیگابایت وجود دارد که از سوی گیتهاب تعیین شده است. هر چیزی بزرگتر از این، باید روی فضای ذخیرهسازی ابری دیگری قرار گیرد.
- Git LFS یک پروژه فعال اپنسورس است که به صورت مداوم بهبود مییابد. در گیتهاب این پروژه لیستی از issue-های جاری وجود دارد (+) که در حال حل هستند.
- همچنین برخی issue-ها وجود دارند که در زمان تلاش برای ادغام تداخلها بروز مییابند. بنابراین بهتر است پیش از push کردن تغییرها و ادغام آنها یک مشورت درون تیمی وجود داشته باشد.
- توجه داشته باشید که فایلهای بزرگتر در زمان push شدن به ریپازیتوری ریموت ممکن است کمی کند باشند.
منبع: فرادرس
همه چیز درباره Git LFS — به زبان ساده
اغلب ما نخستین باری که با LFS در Git مواجه شدیم، در زمان کار روی پروژههای علوم داده بوده است. شاید با خود بپرسید Git خود به اندازه کافی دشوار است، آیا باید یکی دیگر از قابلیتهای آن را نیز یاد بگیریم؟ شاید هم کنجکاو هستید که Git LFS چیست و چرا باید آن را بیاموزید. در این صورت توصیه میکنیم، در ادامه این مقاله با ما همراه باشید تا به پاسخ سؤالهایتان برسید.
ابتدا مقدمه کوتاهی در مورد اهمیت LFS و کاربرد آن بیان میکنیم. تصور کنید مشغول کار روی یک پروژه تحلیل دادههای فیلم برای نمونه از وبسایت OMDB ،Rotten Tomatoes و IMDB هستید. اما زمانی که کارها را روی گیتهاب میبرید در زمان آپلود کردن مجموعه داده IMDB با خطایی مانند زیر مواجه میشوید:
در این زمان است که متوجه میشوید گیت و گیتهاب محدودیت اندازه فایل 100 مگابایت دارند. فایلهایی با اندازههای بزرگتر از 50 مگابایت پیام هشدار دریافت میکنند، اما میتوان آنها را push کرد.
نخستین راهکاری که در این حالت به صورت طبیعی به ذهن میرسد این است که کار را با ارسال تک به تک فایلها ادامه دهد. اما اگر این راهکار به هر دلیلی ممکن نباشد، باید گزینه بعدی یعنی ذخیرهسازی به روش Large File Storage را در گیت بررسی کنیم. برای این که Git LFS را درک کنیم باید ابتدا گیت را بشناسیم. بنابراین قبل از بررسی LFS اندکی در مورد گیت توضیح میدهیم.
گیت چیست؟
گیت یک سیستم کنترل نسخه توزیع یافته است، یعنی کل سابقه ریپازیتوری در طی فرایند کلون کردن به کلاینت انتقال مییابد.
اگر بخواهیم این موضوع را کمی بیشتر باز کنیم، باید ابتدا سیستم کنترل نسخه را توضیح دهیم. «سیستم کنترل نسخه» (Version Control System) ابزاری است که به مدیریت تغییرها در کد منبع، فایلها و دیگر اَشکال اطلاعات میپردازد. بدین ترتیب تغییرها به صورت commit ردگیری میشوند. Commit در واقع تصاویری از ویرایشها در نقاط زمانی مشخص هستند. در سوی دیگر یک سیستم کنترل نسخه توزیع یافته نوعی از سیستم کنترل نسخه است که امکان انتقال همه کدبیس شامل همه سوابق (و همه تغییرها) به رایانه هر توسعهدهنده را فراهم میسازد. بدین ترتیب هر توسعهدهنده میتواند روی پروژهای کار کند و همزمان کل تایملاین ویرایشهای انجام یافته روی پروژه را ببیند.
تاریخچه گیت
گیت نخستین بار در سال 2005 از سوی «لینوس تروالدز» (Linus Torvalds) و در نتیجه توقف استفاده از سیستم کنترل نسخه Bitkeeper خلق شد. دلیل توقف لینوس و همکارانش نیز این بود که Bitkeeper دیگر رایگان نبود و پولی شده بود. بر اساس گزارشها لینوس پس از تلاش برای یافتن یک سیستم کنترل نسخه رایگان جایگزین برای Bitkeeper تصمیم گرفت تا سیستم کنترل نسخه خود را بسازد که کوچک و سریع (کمتر از سه ثانیه زمان بگیرد) باشد و از انشعاب پشتیبانی کند. همچنین این سیستم باید کاملاً مخالف سیستمهای کنترل نسخه همزمان و شامل safeguards برای صحت دادهها میبود.
از آنجا که گیت ساخته شده است تا کوچک و سریع باشد، در ابتدا صرفاً برای پشتیبانی از سورس کد ساخته شد و از فایلهای بزرگ پشتیبانی نمیکرد. توجه کنید که گیت یک سیستم کنترل نسخه است یعنی هر بار که پروژهای کلون یا pull میشود همه سابقه کامل تغییرهای یک پروژه انتقال مییابد. زمانی که یک کامیت اضافه میشود، به سوابق افزوده میشود و موجب افزایش اندازه فایل کلی پروژه میشود و در طی زمان این مقدار بسیار افزایش مییابد.
با این وجود، رشتههای زیادی وجود دارند که در آن پروژههایی با فایلهای بزرگ ایجاد میشوند و این حالت شامل حوزه فایلهای موسیقی، تصویر و مجموعههای دادههای علمی نیز میشود. بنابراین اینک سؤال این است که در چنین موقعیتهایی چه باید کرد؟ این همان نقطهای است که Git LFS به کارمی آید.
«ذخیرهسازی فایل بزرگ» Git یا LFS به چه معنا است؟
Git LFS یک اکستنشن گیت است که در Go برنامهنویسی شده و از سوی توسعهدهندگانی در Atlassian و Github و همچنین مشارکتکنندگان اوپنسورس جهت دور زدن محدودیت اندازه فایل در گیت ساخته شده است. این کار از طریق ذخیرهسازی فایلهای بزرگ در یک مکان مجزا از ریپازیتوری و قرار دادن اشارهگرهای فایل در ریپازیتوری که مستقیماً به محل فایل اشاره میکنند صورت میپذیرد.
بهترین روش برای درک طرز کار LFS این است که ابتدا برای لحظهای همه چیز را در مورد Github ،Bitbucket ،Gitlab و همه ریپازیتوریهای ریموت فراموش کنیم. در این مرحله صرفاً روی رایانه محلی تمرکز میکنیم که در تصویر زیر با شکل یک نمایشگر با سه بخش Working Copy ،Local Repository و LFS Cache نمایش یافته است.
ریپازیتوری محلی
«ریپازیتوری محلی» (local repository) آن دایرکتوری یا پوشهای است که روی رایانه خود میبینید و با استفاده از دستور git init به عنوان ریپازیتوری گیت مقداردهی شده و یا از ریپازیتوری ریموت کلون شده است. «کپیِ کاری» (Working Copy) یک بازنمایی از فایلها و پوشههایی است که در ریپازیتوری محلی ویرایش میشوند. LFS Cache مکان ذخیرهسازی مجزایی است که در ریپازیتوری محلی ویرایش میشود. LFS Cache فضای ذخیرهسازی مجزایی برای فایلهای بزرگ است که از طریق گیت push میشوند. این اصطلاحها را به ذهن خود بسپارید، چون در زمان توضیح طرز کار Git LFS در بخش بعدی به کار خواهند آمد.
کار با Git LFS
نکته مهم در مورد Git LFS این است که میتوان در آن همچنان از دستورهای عادی و گردش کار معمولی گیت که کاملاً شناخته شده هستند استفاده کرد. تنها تغییر در این مورد برخی دستورهای اضافی و مکان ذخیرهسازی مجزایی هستند که باید در خاطر داشت.
اکنون که اطلاعاتی در مورد گیت و Git LFS داریم، در ادامه به بررسی روش استفاده از آن میپردازیم. دو سناریو در این خصوص وجود دارد، اما ابتدا باید Git LFS را از طریق Homebrew با دستور زیر دانلود کنیم:
brew install git-lfs
در مورد سیستمهای غیر مَک نیز امکان دانلود از طریق وبسایت (+) وجود دارد.
سناریوی اول
در این سناریو از Git LFS پس از دریافت پیام خطایی در زمان استفاده از دستورهای معمولی گیت استفاده میکنیم.
در این مثال یک ریپازیتوری جدید داریم که یک فایل داده بزرگ (1.9 گیگابایت) در آن قرار دادهایم. ما میخواهیم مطمئن شویم که هر تغییری در مورد فایلهای داده ردگیری میشود و در نهایت به صورت ریموت پشتیبانگیری خواهد شد. ابتدا از دستورهای معمولی گیت برای stage کردن فایل (git add) استفاده میکنیم، یک کپی از تغییرها را در ریپازیتوری محلی (git commit) ذخیره میکنیم و کپی را به ریپازیتوری ریموت ارسال میکنیم (git push). خروجی این دستورها به صورت زیر است:
این خطا را چگونه میتوان حل کرد؟ یک راهحل این است که تغییرها را با استفاده از git reset بازگردانی کنیم و یا از ذخیره فایل صرفنظر کنیم و آن را به صورت zip و با اندازه کوچکتر دربیاوریم و یا این که مسیر خود را با Git LFS ادامه دهیم. گزینه دیگر این است که از همان جایی که کار متوقف شده اقدام به یکپارچهسازی Git LFS بکنیم و بدین ترتیب امکان ادامه فرایند وجود خواهد داشت. ما در این بخش این مسیر را دنبال میکنیم.
گام 1
نخستین گام در این مسیر آن است که Git LFS را نصب کرده و از طریق اجرای دستور زیر، ریپازیتوری خاصی را برای آن فعالسازی کنیم:
git lfs install
با این که قبلاً Git LFS را روی سیستم خود نصب کردهایم، اما باید به آن اعلام کنیم که کدام ریپازیتوری ها به خدماتش نیاز دارند. برای قیاس یک شرکت ارائهدهنده سرویس ذخیرهسازی را در نظر بگیرید. چنین شرکتهایی در دسترس ما هستند تا آیتمهایی را در آنها ذخیره کنیم، اما به صورت خودکار به سراغ ما نمیآیند تا فایلهایمان را ذخیرهسازی کنند. بلکه ما باید ابتدا با عقد قرارداد یک رابطه با این شرکت برقرار کنیم. همین حالت در اینجا نیز صدق میکند. برای فعالسازی سرویسهای Git LFS در یک ریپازیتوری خاص یا اعلام این که سرویسهای Git LFS برای کدام ریپازیتوری باید فعال شود از دستور زیر استفاده میکنیم:
git lfs install
گام 2
با دستور زیر به Git LFS اعلام کنید که کدام فایلها باید ردگیری شوند:
git lfs track “*.file_extension”
در این مورد نیز باید به Git LFS اعلام کنیم که کدام فایلها و یا کدام انواع فایلها را میخواهیم ردگیری کند، بدین ترتیب فایلها میتوانند در مکان دیگری به جز ساختار گیت خیره شوند تا از دریافت پیام خطای قبلی جلوگیری شود. به این منظور دستور فوق را اجرا کنید.
برای مثال اگر لازم است همه فایلهای CSV ردگیری شوند دستور زیر را اجرا کنید:
git lfs track “*.csv”
یا اگر لازم است همه فایلهای jpeg ردگیری شوند، دستور زیر را وارد کنید:
git lfs track “*.jpg”
کاراکتر ستاره (*) نشاندهنده همه فایلها است. استفاده از گیومه نیز برای اجرای این کد ضروری است. بدون وجود گیومه با خطای زیر مواجه میشویم:
![]()
همان طور که وقتی از یک شرکت ذخیرهسازی میخواهیم شروع به ذخیرهسازی آیتم بکند، یک صورتحساب برای ما ارسال میکند، در این مورد نیز وقتی یک فایل را با Git LFS ردگیری کنیم، یک فایل gitattributes. ایجاد خواهد شد. اگر فایل gitattributes. از قبل موجود باشد، این فایل به صورت یک خط جدید در آن اضافه میشود.
![]()
گام 3
در این بخش با دستورهای Git add ،commit و push فایل gitattributes. را در ریپازیتوری خود قرار میدهیم.
Git LFS نیز همانند فایل gitattributes.، فایلهای جدید را ردگیری میکند، و تغییرهای صورت گرفته به صورت خودکار در فایل gitattributes. بهروزرسانی میشوند. برای این که مطمئن شویم تغییرها ردگیری میشوند، هر بار که فایل gitattributes. بهروزرسانی میشود، باید stage و commit شود چون در غیر این صورت ممکن است در ادامه با خطایی مواجه شویم.
گام 4
اینک میخواهیم با رمز اصلی این سناریو که استفاده از git LFS برای انتقال کامیتها از گیت به Git LFS است آشنا شویم.
آنچه موجب میشود بتوانیم در حالت کنونی و بدون نیاز به undo کردن کامیتها و راهاندازی مجدد فرایند از Git LFS استفاده کنیم، یک خط کد جالب است که امکان انتقال یا «migrate» کامیتها از گیت به Git LFS را فراهم میسازد. برای این که بتوانیم کامیتها را انتقال دهیم باید دستور زیر را اجرا کنیم:
git lfs migrate import — include “*.file_extension”
برای دیدن انواع فایلی که در کامیتها هستند و میتوانند از سوی Git LFS ردگیری شوند، میتوانیم دستور زیر را اجرا کنیم:
git lfs migrate info
با انتقال دادن کامیتها، میتوانیم به مرحله بعدی برویم و تغییرها را به گیتهاب push کنیم. در این خصوص در بخش بعدی بیشتر توضیح میدهیم:
نکته مهم: انتقال کامیتها شامل بازنویسی سابقه هستند. میتوان یک تگ اضافه کرد تا از بازنویسی تغییرهای لیست شده در سابقه جلوگیری کرد، اما این کار از اجرا شدن آن خط کد جلوگیری خواهد کرد.
گام 5
در نهایت دستور git push را اجرا میکنیم تا تغییرها را به گیتهاب پوش کنیم و کامیت بزرگ (یعنی فایلهای بزرگ) نیز به Gif LFS کامیت شوند.
پس از انتقال کامیتها به Git LFS در حال حاضر یک ریپازیتوری محلی گیت داریم که با یک تغییر بهروزرسانی شده است. در این مورد یک فایل داده جدید اضافه شده است که به وسیله اشارهگر فایل به Git LFS اشاره دارد. همچنین یک کش Git LFS محلی وجود دارد که اینک به ذخیره سای فایل داده میپردازد. در مرحله بعدی تغییرها را به گیتهاب پوش میکنیم. ریپازیتوری گیت محلی که دارای فایلهایی در چارچوب محدودیت اندازه تعیین شده باشند (یعنی فایلهای کد منبع و فایل اشارهگر) در گیتهاب ذخیره میشوند که میزبان گیت مشخص شده در تصویر زیر است و کش Git LFS در فضای ذخیرهسازی Git LFS روی کلود ذخیره میشود.
سناریوی دوم: استفاده از Git LFS از ابتدا
اگر بدانیم که فایلهای بزرگی در ریپازیتوری وجود دارند، میتوانیم از Git LFS از همان ابتدا استفاده کنیم و مراحل 1 تا 3 بررسی شده فوق را طی کنیم. پس از طی این مراحل به دستورهای معمولی گیت به صورت git add ،git commit بازمیگردیم تا تغییرها را در ریپوی محلی stage و ذخیره کنیم. سپس گام 5 فوق را اجرا میکنیم تا تغییرها را به گیتهاب و دیگر میزبانهای گیت و فضای ذخیره ریموت Git LFS پوش کنیم.
سخن پایانی
چنانکه مشاهده کردید روش Git LFS برای دور زدن مشکل ذخیرهسازی فایلهای بزرگ در سیستم کنترل نسخه گیت کاملاً سرراست است. کافی است پنج گام فوق را به خاطر بسپارید تا این فرایند را طی کنید. pull کردن تغییرها از یک ریپاریتوزی ریموت نیز کاملاً سر راست است. در این حالت همان دستورهای گیت که معمولاً استفاده میکنیم، یعنی git pull یا git fetch و git merge مورد نیاز هستند.
با استفاده از git pull میتوان تغییرها را که شامل فایل داده ذخیره شده در Git LFS میشود، روی سیستم محلی بارگذاری کرد. زمانی که تغییرها را از ریپازیتوری ریموت pull میکنیم، تغییرهای ریپازیتوری ریموت و هر شیء دیگری که در Git LFS ذخیره شده باشد، نیز روی رایانه محلی pull میشوند.
شاید همه موارد فوق در مواجهه نخست کمی سردرگمکننده به نظر برسند، بنابراین در ادامه نکاتی را که میتوان در این مقاله جمعبندی کرد، ارائه کردهایم.
- افرادی که به نظرشان گیت پیچیده میآید، باید بدانند که این مطلب بر پیچیدگی موضوع میافزاید. این مهمترین چالش این افراد در زمان یادگیری Git LFS خواهد بود. یادگیری دقیق دستورهای گیت، گردش کار گیت و شیوه تطبیق آن با Git LFS کلید یادگیری گامهای طرحشده در این آموزش است.
- حتی در زمان استفاده از Git LFS نیز محدودیت اندازه فایل 2 گیگابایت وجود دارد که از سوی گیتهاب تعیین شده است. هر چیزی بزرگتر از این، باید روی فضای ذخیرهسازی ابری دیگری قرار گیرد.
- Git LFS یک پروژه فعال اپنسورس است که به صورت مداوم بهبود مییابد. در گیتهاب این پروژه لیستی از issue-های جاری وجود دارد (+) که در حال حل هستند.
- همچنین برخی issue-ها وجود دارند که در زمان تلاش برای ادغام تداخلها بروز مییابند. بنابراین بهتر است پیش از push کردن تغییرها و ادغام آنها یک مشورت درون تیمی وجود داشته باشد.
- توجه داشته باشید که فایلهای بزرگتر در زمان push شدن به ریپازیتوری ریموت ممکن است کمی کند باشند.
منبع: فرادرس
پیاده سازی درخت دودویی در کاتلین (Kotlin) — از صفر تا صد
در این راهنما عملیات مقدماتی را برای یک درخت دودویی با استفاده از زبان برنامهنویسی کاتلین معرفی میکنیم. بدین ترتیب با پیادهسازی درخت دودویی در کاتلین آشنا میشویم.
تعریف
در حوزه برنامهنویسی، درخت دودویی به درختی گفته میشود که در آن هر گره بیش از دو گره فرزند نداشته باشد. هر گره شامل مقادیری داده است که کلید نامیده میشود. ما میتوانیم بدون از دست دادن تعمیمپذیری، ملاحظه خود را محدود به مواردی کنیم که کلیدها صرفاً اعداد صحیح باشند. بنابراین میتوانیم یک نوع داده بازگشتی به صورت زیر تعریف کنیم:
این نوع داده شامل یک مقدار (کلید فیلد با مقدار صحیح) و یک ارجاع اختیاری به گرههای فرزند چپ و راست است که از همان نوع والد خود هستند. چنان که مشاهده میکنیم به دلیل ماهیت لینک شده، کل درخت دودویی را میتوان با صرفاً یک گره که گره ریشه نامیده میشود توصیف کرد.
در صورتی که مقداری محدودیت روی ساختار درخت اعمال کنیم، همه چیز جالبتر خواهد شد. در این راهنما فرض میکنیم که درخت، یک درخت دودویی مرتب است (که به نام درخت جستجوی دودویی نیز شناخته میشود). این بدان معنی است که گرهها با نوعی ترتیب چیدمان یافتهاند. ما فرض میکنیم که همه شرایط زیر در مورد درخت ما صدق میکنند:
- درخت شامل هیچ کلید تکراری نیست.
- در هر گره، کلید بزرگتر از کلید گرههای زیردرخت چپ آن است.
- در هر گره، کلید کمتر از کلید گرههای زیردرخت راست آن است.
عملیات مقدماتی
برخی از رایجترین عملیات این نوع درخت شامل موارد زیر هستند:
- جستجو برای یک گره با مقدار مفروض
- درج یک مقدار جدید
- حذف یک مقدار موجود
- بازیابی گرهها با ترتیب معین
گشتن
زمانی که درخت مرتب باشد، فرایند گشتن (Lookup) بسیار کارآمد میشود. اگر مقدار مورد جستجو برابر با مقدار گره جاری باشد، در این صوت گشتن به پایان میرسد. اگر مقدار مورد جستجو بزرگتر از گره جاری باشد، در این صورت باید زیردرخت چپ کنار گذاشته شود و صرفاً زیردرخت راست جستجو شود:
توجه کنید که مقدار مورد نظر ممکن است در میان کلیدهای درخت حضور نداشته باشد و از این رو نتیجهی جستجو ممکن است مقدار null بازگشت دهد. همچنین توجه داشته باشید که ما از کلیدواژه when در Kotlin استفاده کردهایم که معادل جاوای آن به همراه گزاره switch-case است، اما قدرت و انعطافپذیری بسیار بیشتری دارد.
درج
از آنجا که درخت امکان حضور هیچ نوع کلید تکراری را نمیدهد، درج یک مقدار جدید کاملاً آسان است:
- اگر مقدار قبلاً موجود باشد، هیچ اقدامی صورت نمیگیرد.
- اگر مقدار موجود نباشد، در گرهی درج میشود که جایگاه راست یا چپ آن خالی است.
بنابراین میتوانیم به صورت بازگشتی درخت را به دنبال زیردرختهایی که میتوانند این مقدار را در خود بپذیرند مورد جستجو قرار دهیم. زمانی که مقدار کمتر از کلید گره جاری باشد، زیردرخت چپ آن را در صورت وجود برمیداریم. اگر موجود نباشد، بدان معنی است که مکان درج مقدار مورد نظر را یافتهایم. این همان فرزند چپ گره جاری است.
در حالتی که مقدار بزرگتر از کلید گره جاری باشد، به طور مشابه عمل میکنیم. تنها حالت ممکن این است که مقدار برابر با کلید گره جاری باشد. این بدان معنی است که مقدار مورد نظر از قبل در درخت وجود دارد و کار دیگری لازم نیست انجام دهیم:
حذف
ابتدا باید گرهی را که شامل مقدار مفروض است شناسایی کنیم. همانند فرایند گشتن، میتوانیم درخت را در جستجوی گره اسکن کنیم و ارجاعی به والد گره مورد نظر نگه داریم:
سه حالت متمایز وجود دارند که ممکن است در زمان تلاش برای حذف گره از درخت دودویی با آنها مواجه شویم. ما این حالتها را بر مبنای تعداد گرههای فرزند غیر تهی دستهبندی کردهایم.
هر دو گره فرزند تهی باشند
مدیریت این حالت کاملاً آسان است و تنها حالتی است که ممکن است نتوانیم گره را حذف کنیم، چون اگر گره همان گره ریشه باشد امکان حذف آن وجود نخواهد داشت. در غیر این صورت کافی است گره متناظر والد را برابر با null قرار دهیم.
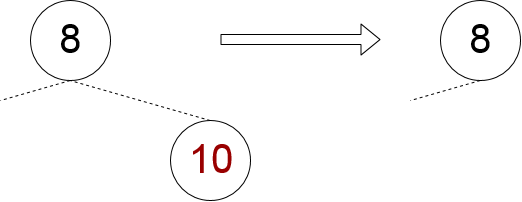
پیادهسازی این رویکرد به صورت زیر است:
یک فرزند تهی و دیگری غیر تهی باشد
در این حالت، باید همواره تنها گره فرزند را به گرهی که قرار است حذف شود انتقال دهیم.
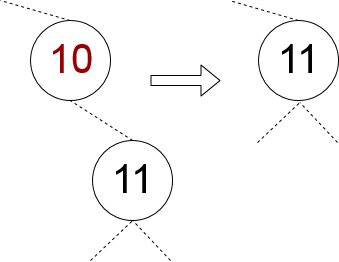
پیادهسازی آن به صورت زیر است:
هر دو گره غیر تهی هستند
این حالت پیچیدهتر است، زیرا باید گرهی را پیدا کنیم که جایگزین گرهی میشود که میخواهیم حذف کنیم. یک روش برای یافتن این گره جایگزین آن است که یک گره را از زیردرخت چپ با بزرگترین کلید برداریم. روش دیگر دقیقاً متقارن روش فوق است. ما باید گرهی را در زیردرخت راست با کوچکترین کلید برداریم. ما در این نوشته از رویکرد اول استفاده میکنیم:
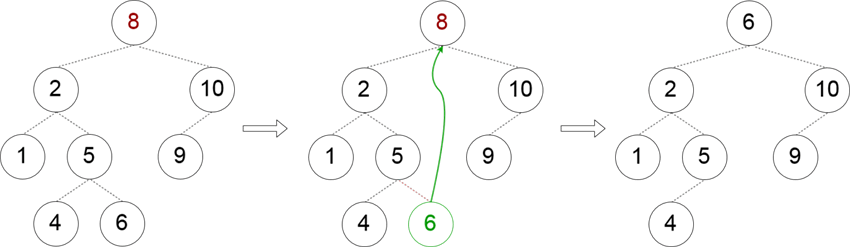
زمانی که گره جایگزین پیدا شد، میتوانیم ارجاع به آن را از گره والدش حذف کنیم. این بدان معنی است که وقتی برای گره جایگزین جستجو میکنیم، باید والد آن را نیز بازگشت دهیم:
پیمایش
روشهای مختلفی برای بازدید از گرهها وجود دارد. رایجترین روشها شامل روش «عمق-اول» (depth-first)، «عرض-اول» (breadth-first) و «سطح-اول» (level-first) است. در این مقاله ما تنها روش عمق-اول را بررسی میکنیم که میتواند یکی از حالتهای زیر را داشته باشد:
- پیش ترتیبی (اول گره والد و سپس گره چپ و سپس گره راست را بازدید میکنیم)
- میان ترتیبی (ابتدا فرزند چپ، سپس گره والد و سپس فرزند راست را بازدید میکنیم)
- پس ترتیبی (ابتدا فرزند چپ را بازدید میکنیم و سپس فرزند راست و در نهایت گره والد)
همه انواع پیمایش در کاتلین میتوانند به روشی ساده اجرا شوند. به عنوان نمونه برای پیمایش پیشترتیبی میتوان به صورت زیر استفاده کرد:
توجه کنید که کاتلین امکان الحاق آرایهها را با استفاده عملگر + فراهم میسازد. البته این پیادهسازی فاصله زیادی با یک روش کارآمد دارد، چون tail-recursive نیست و در مورد درختهای با عمق زیاد ممکن است استثنای سرریز پشته را ایجاد کند.
سخن پایانی
در این راهنما با شیوه ساخت و پیادهسازی عملیات مقدماتی یک درخت جستجوی دودویی با استفاده از کاتلین آشنا شدیم. همچنین برخی سازههای کاتلین را که در جاوا موجود نیستند و میتوانند مفید واقع شوند را معرفی کردیم. کد کامل این مطلب را میتوانید در این صفحه گیتها
منبع: فرادرس
آموزش سوئیفت (Swift) — مجموعه مقالات مجله فرادرس
سوئیفت یک زبان برنامهنویسی چندمنظورهی چند پارادایمی و کامپایل شونده است که از سوی شرکت اپل توسعه یافته است. از این زبان جهت برنامهنویسی سیستمهای عامل تحت مالکیت این شرکت مانند iOS ،macOS ،watchOS و tvOS استفاده میشود. تا قبل از سوئیفت، زبان رسمی برنامهنویسی اپل Objective-C بود که سوئیفت در سال 2014 جایگزین آن شد. این زبان به وسیله فریمورک کامپایلر متن-باز LLVM ساخته شده و از نسخه 6 Xcode در IDE رسمی اپل جای گرفته است. در این مقاله به جمعبندی مجموعه مقالات آموزش سوئیفت مجله فرادرس پرداختهایم.
تاریخچه نسخههای مختلف
چنان که اشاره شد سوئیفت در کنفرانس WWDC اپل در سال 2014 معرفی شد و این زبان که در ابتدا تحت مالکیت اپل قرار داشت در ادامه و در نسخه 2 خود در سال 2015 تحت لایسنس آپاچی 2 به صورت متن-باز برای پلتفرمهای اپل و لینوکس عرضه شد.
از نسخه 3 به بعد ساختار سوئیفت دچار تحولات زیادی شد و پایداری کد در اولویت توسعه تیم اصلی قرار گرفت. نسخه 4 سوئیفت در سال 2017 چند تغییر در کلاسها و ساختارهای درونی آن معرفی کرد. کد نوشته شده در نسخههای قبلی سوئیفت را میتوان با استفاده از کارکرد مهاجرت داخلی Xcode به نسخه جدید ارتقا داد. نسخه 5 سوئیفت در مارس 2019 عرضه شده و یک اینترفیس باینری پایدار روی پلتفرمهای اپل ارائه کرده که به محیط زمان اجرای سوئیفت امکان مشارکت در سیستمهای عامل اپل را میدهد. کدهای این نسخه با نسخه 4 سازگار است.
فهرست مجموعه مقالات آموزش سوئیفت
ما در مجله فرادرس در طی هفتههای اخیر سری مقالاتی در خصوص آشنایی با این زبان برنامهنویسی ارائه کردیم که در این نوشته به جمعبندی آنها میپردازیم.
در بخش نخست مطالب آموزش برنامهنویسی سوئیفت برخی توضیحات کلی در مورد این سری مقالات آموزشی عرضه کردیم و توضیح دادیم که شامل چه مواردی میشود و نمیشود و هدف از این سری مقالات آموزشی چیست. همچنین با برخی مفاهیم مقدماتی برنامهنویسی مانند انواع داده و میزان مصرف حافظه آنها آشنا شدیم.
در بخش دوم سری مقالات آموزش برنامهنویسی سوئیفت به بررسی عمیقتر انواع داده که شامل: «انواع مقداری» (Value Types)، «انواع ارجاعی» (Reference Types) و همچنین اشارهگرها (Pointers) میشود پرداختهایم. همچنین توضیح دادیم که اشارهگرها احتمالاً یکی از دشوارترین مفاهیم برنامهنویسی محسوب میشوند و سعی کردیم آنها را به سادهترین زبان ممکن بیان کنیم.
در این مقاله نیز به ادامه معرفی مباحث مقدماتی زبان برنامهنویسی سوئیفت پرداختیم، اما تلاش کردیم در این مطلب شما را آماده سازیم تا برنامهای بنویسید که مسائل ریاضیاتیتان را حل کند. این مسائل ریاضیاتی از موارد بسیار ساده تا محاسبات مالی پیچیده را شامل میشد.
در بخش چهارم از سری مقالات آموزش برنامهنویسی سوئیفت با مفهوم تصمیمگیری در فرایند برنامهنویسی آشنا شدیم و نقش گزارههای شرطی در پیادهسازی این تصمیمگیریها را توضیح دادیم. همچنین با انواع حلقهها شامل حلقه while و حلقههای for-in آشنا شدیم.
در بخش پنجم سری مقالات آموزش سوئیفت توضیح دادهایم که برخی از گزارههای if کاملاً طولانی هستند و در صورتی که بخواهیم کارهای مختلف در یک گزاره if انجام دهیم، واقعاً حجم بالایی پیدا میکنند و خواندنشان دشوار میشود. در این نوشته به بررسی این موضوع و راهحلهای آنها پرداختهایم.
در این بخش از سری مطالب آموزش سوئیفت در مورد دو شیء جدید که نوع داده هستند و به عنوان کانتینرهایی به مجزا نگهداشتن کد و خوانایی هر چه بیشتر آن کمک میکنند صحبت کردهایم. همچنین توضیح دادیم چنین نیست که هر چه کد به اجزای بیشتری تقسیم شود، خوانایی آن افزایش مییابد، بلکه یک نقطه تعادل وجود دارد. کلاسها و struct-ها به ساختن این نقطه تعادل کمک میکنند.
در این بخش از سری مقالات آموزش سوئیفت تمرکز ما روی این بوده است که شما آن دانشی را کسب کنید که وقتی کلاسها را در برنامههای خودتان میبینید، ایدهای از چگونگی آغاز به کار با آنها داشته باشید. لذا در این نوشته به بررسی مفاهیم Initialization و De-initialization،Override و Reference Counting پرداختهایم.
در این بخش از سری مقالات آموزش زبان سوئیفت مفهوم تبدیل نوع به همراه باز کردن امن Optional-ها و کنترل دسترسی را مورد بررسی قرار دادهایم. به این منظور برخی از ابزارهایی که به طور مکرر در کدها استفاده میشوند را معرفی کردهایم.
در این نوشته از سری مقالات آموزش برنامهنویسی سوئیفت تلاش کردهایم مفاهیمی که در بخش قبلی مطرح شدند را کمی بازتر کنیم و یک بار دیگر به جمعبندی مفاهیم پروتکل و اکستنشن و همچنین زیرنویس میپردازیم، اما این بار کاربردهای عملی آنها در اپلیکیشنهای مختلف را بررسی میکنیم.
بخش دهم از سری مقالات آموزش برنامهنویسی سوئیفت یکی از بخشهای کلیدی آن محسوب میشود لذا شما تا به اینجا با اغلب مفاهیم تئوریک مقدماتی آشنا شدهاید و آماده هستید که برخی مفاهیم عمیقتر را یاد بگیرید. بنابراین ساختار کد، روش مدیریت تابعها، ثابتها و متغیرها، خوانایی کد، تقسیم کد به اجزای مختلف، نامگذاری متغیرها و اصول اساسی کدنویسی شامل پنهانسازی اطلاعات، تزویج سست و قانون دیمیتر را معرفی کردهایم.
در مطلب قبل در مورد خوانایی کد صحبت کردیم، اما فرصت کافی نشد که به همه موارد پرداخته شود، اما مبانی قضیه ارائه شد و از این رو زمانی که به کدهایی که قبلاً نوشتهاید رجوع کنید، احتمالاً به سرعت میتوانید دریابید که چه چیزی میخواستهاید بنویسید. این مبحث بزرگی است و شاید یک نوشته کامل را بتوان به بحث ساختار کد و خوانایی آن اختصاص داد. در نوشته قبل صرفاً به ارائه سرفصلهای آن پرداختیم و در این بخش به بررسی چند مفهوم دیگر سوئیفت پرداختهایم که شما را اندکی بیشتر با چارچوب کدنویسی در این زبان برنامهنویسی آشنا میکنند.
در این بخش از سری مقالات آموزش زبان برنامهنویسی سوئیفت به معرفی مفاهیم جدیدی مانند اسامی مستعار نوع میپردازیم که به خواناتر ساختن کد و کاهش اندازه کد کمک میکنند. همچنین با تفاوت Self و self به جز کوچک/بزرگ بودن حرف اول آشنا میشویم.
در این بخش از سری مقالات آموزش زبان سوئیفت در مورد ژنریک ها صحبت کردهایم. ژنریکها امکان ایجاد تابعهایی با قابلیت استفاده مجدد میدهند که میتوانند در انواع متفاوتی استفاده شوند. تنها نکته این است که این نوع باید با کاری که قرار است اجرا شود متناسب باشد.
در این بخش از سری مقالات آموزش برنامهنویسی سوئیفت به موضوع مدیریت خطا خواهیم پرداخت. بدین ترتیب نکات مهم مدیریت خطا، گزینه try و انواع آن، شیوه ایجاد خطا، و شیوه ایجاد دوباره آن آشنا میشویم.
در این بخش از سری مقالات آموزش برنامهنویسی سوئیفت به صورت فشرده برخی از مفاهیم مهم این زبان برنامهنویسی شامل استفاده از Enum به همراه ژنریک و بستارها را مرور کردهایم و با روش عملی استفاده از آنها در کدنویسی آشنا میشویم.
در این بخش از مقالات سوئیفت در مورد چند موضوع صحبت میکنیم که موجب میشوند کد سوئیفت کارایی بیشتری پیدا کند. بدین ترتیب به بررسی مفاهیم Getter و Setter و همچنین inout و lazy میپردازیم. در عین حال روش استفاده از آنها و بهترین کاربردشان را بررسی میکنیم.
در این بخش از سری مقالات آموزش زبان سوئیفت با مفهوم تست کردن اپلیکیشن و روشهای آن آشنا میشویم. تست کردن مهم است و ارتباط تنگاتنگی با رویکرد TDD دارد. TDD اختصاری برای عبارت «Test-driven Development» (توسعه تست-محور) است. توسعه تست-محور یک روش رایج برای نوشتن اپلیکیشن است و بهخاطرسپاری این فرمول نیز آسان است.
این بخش هجدهم و پایانی سری مقالات آموزش زبان سوئیفت مجله فرادرس محسوب میشود. شما با مطالعه هفده بخش قبلی این سری مقالات آموزش زبان برنامهنویسی سوئیفت با مبانی آن آشنا شدید. اینک و با مطالعه این بخش با موضوع معماری MVC میتوانید شروع به نوشتن عملی اپلیکیشنهای خود بکنید. این مقاله به این منظور نوشته شده است که شیوه استفاده مؤثر از معماری MVC را به شما آموزش دهد. MVC اختصاری برای عبارت «مدل، نما، کنترلر» (Model-View-Controller) است.
جمعبندی
بدین ترتیب شما با مطالعه هجده مقاله فوق با ساختار زبان برنامهنویسی سوئیفت آشنا میشوید. سوئیفت جایگزینی برای زبان برنامهنویسی قدیمیتر اپل یعنی Objective-C است که در آن از مفاهیم نظری برنامهنویسی مدرن استفاده شده و ساختار سادهتری دارد. سوئیفت به طور پیشفرض از اشارهگرها و دیگر عوامل دسترسی نا ایمن برخلاف Objective-C بهره نمیگیرد. همچنین ساختار شبیه Smalltalk برای ساخت فراخوانیهای متد با سبک نمادگذاری نقطهای و سیستم «فضای نام» (namespace) دارد که برای برنامه نویسان مسلط به زبانهای شیءگرا مانند جاوا یا سی شارپ آشناتر است. ضمناً در آن از پارامترهای با نام استفاده میشود و مفاهیم کلیدی زبان Objective-C مانند پروتکلها، بستارها و دستهبندیها حفظ شده و در اغلب موارد با نسخههای مدرنتری جایگزین شده که امکان استفاده از این مفاهیم در ساختارهای زبان مانند انواع شمارشگر (enums) را فراهم میسازد.
منبع: فرادرس