طراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیطراحی سایت و برنامه نویسی
آموزش طراحی سایت و برنامه نویسیگزاره های شرطی ساده و تودرتو در ++C — به زبان ساده
در مطلب پیشین مروری داشتیم بر تاریخچه، کاربردها و اهمیت زبان برنامه نویسی C++ که میتوانید آن را با عنوان «آموزش ++C — راهنمای شروع یادگیری» مطالعه کنید. در این مقاله، با روش نوشتن گزاره های شرطی ساده و تودرتو در ++C به کمک عبارتهای مختلف if…else آشنا میشویم.

گزاره if در ++C
گزاره if به ارزیابی عبارت تست درون پرانتز میپردازد. اگر عبارت تست، درست ارزیابی شود، گزارههای درون بدنه if اجرا میشوند. اگر عبارت تست نادرست ارزیابی شود، گزارههای درون بدنه if رد میشوند.
طرز کار گزاره if چگونه است؟

فلوچارت گزاره if

تصاویر فوق طرز کار یک گزاره if را نمایش میدهند.
مثال 1: گزاره if در ++C
خروجی 1
Enter an integer: 5 You entered a positive number: 5 This statement is always executed.
خروجی 2
Enter a number: -5 This statement is always executed.
گزاره if…else در ++C
گزاره if…else کدهای درون بدنه گزاره if را در صورتی اجرا میکند که عبارت تست درست ارزیابی شود و در صورتی که نادرست ارزیابی شود، بدنه else اجرا میشود. اگر عبارت تست نادرست ارزیابی شود، کدهای درون بدنه else اجرا میشود و کدهای درون بدنه if رد میشوند.
طرز کار گزاره if…else چگونه است؟

فلوچارت گزاره if…else

مثال 2: گزاره if…else در ++C
خروجی
Enter an integer: -4 You entered a negative integer: -4. This line is always printed.
گزاره If…else تودرتو در ++C
گزاره If…else بسته به این که عبارت تست درست یا نادرست باشد، دو کد متفاوت را اجرا میکند. برخی اوقات باید از میان بیش از دو گزینه انتخاب کنیم.
گزاره If…else تودرتو امکان بررسی چندین عبارت تست و اجرای کدهای مختلف برای بیش از دو شرایط متفاوت را در اختیار ما قرار میدهد.
ساختار If…else تودرتو
مثال 3: if…else تودرتو در ++C
خروجی
Enter an integer: 0 You entered 0. This line is always printed.
عملگر شرطی/سهتایی (؟)
عملگر سهتایی روی 3 عملوند عمل میکند و میتواند به جای گزاره if…else استفاده شود. کد زیر را در نظر بگیرید:
در صورت استفاده از عملگر سهتایی به جای کد فوق میتوان کدی به صورت زیر نوشت:
عملگر سهتایی در مورد شروط کوتاهتر، خوانایی بیشتری نسبت به یک گزاره if…else دارد. برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:منبع: فرادرس
انتشار لاراول (Laravel Broadcasting) چگونه کار می کند؟ — راهنمای کاربردی
در این مقاله به بررسی مفهوم انتشار لاراول میپردازیم. این قابلیت باعث میشود بتوانید در زمان وقوع اتفاقی در سمت سرور اعلانهایی به سمت کلاینت ارسال کنید. در این مطلب قصد داریم از کتابخانه شخص ثالث Pusher برای ارسال اعلانها به سمت کلاینت بهره بگیریم. اگر تاکنون با موقعیتی مواجه شدهاید که در زمان وقوع اتفاقی در سمت سرور میبایست اعلانهایی از سمت سرور به کلاینت ارسال میکردید، در واقع نیازمند استفاده از سازوکار انتشار لاراول (Laravel Broadcasting) بودهاید.
برای نمونه تصور کنید که یک اپلیکیشن پیامرسان را پیادهسازی کردهاید که به کاربران امکان میدهد پیامهایی به همدیگر ارسال کنند. اینک زمانی که کاربر الف پیامی را به کاربر ب میفرستد، باید بیدرنگ این موضوع را به کاربر ب اطلاع دهید. برای مثال میتوانید یک پنجره باز کنید یا یک کادر هشدار روی سیستم کاربر ب نمایش دهید تا پیام تازه خود را مشاهده کند.
پیادهسازی انتشار لاراول
این یک کاربرد مناسب برای بررسی مفهوم انتشار لاراول است و از این رو در این مقاله اقدام به پیادهسازی آن خواهیم کرد. اگر کنجکاو هستید که سرور چگونه میتواند اعلانهایی را به کلاینت ارسال کند، باید بگوییم که لاراول به این منظور در پسزمینه از سوکتها استفاده میکند. بنابراین پیش از ادامه مقاله و وارد شدن به مراحل عمیقتر پیادهسازی، ابتدا گردش کار سوکتها را مورد بررسی قرار میدهیم.
- در ابتدا به یک سرور نیاز دارید که از پروتکل web-sockets پشتیبانی کند و به کلاینت امکان ایجاد یک وب سوکت را بدهد.
- شما میتوانید سرور خود را راهاندازی کنید و یا این که از یک سرویس شخص ثالث ماند Pusher استفاده کنید. ما در این مقاله از روش دوم استفاده میکنیم.
- کلاینت یک اتصال وب سوکت به سرور وب سوکت برقرار کرده و به محض برقراری موفق اتصال، یک شناسه یکتا دریافت میکند.
- زمانی که اتصال با موفقیت برقرار شد، کلاینت در کانالهای به خصوصی ثبت نام میکند و بدین ترتیب امکان دریافت رویدادها را به دست میآورد.
- در نهایت کلاینت در کانالی که ثبت نام کرده است روی رویدادهایی که دوست دارید در مورد آنها پیامهایی دریافت کنید ثبت نام میکند.
- اینک در سمت سرور زمانی که یک رویداد خاص اتفاق بیفتد، ما با ارسال نام کانال و نام رویداد، این موضوع را به سرور وب سوکت اطلاع میدهیم.
- در پایان سرور وب سوکت این رویداد را به کلاینتهای ثبت نام کننده در آن کانال خاص اطلاعرسانی میکند.
اگر از مشاهده همه این مراحل دچار نگرانی شدهاید، باید اعلام کنیم که جای نگرانی نیست. ما در ادامه این مقاله همه این مراحل را به صورت گام به گام با کمک همدیگر طی خواهیم کرد.
در ادامه نگاهی به فایل پیکربندی پیشفرض انتشار در مسیر config/broadcasting.php خواهیم داشت:
لاراول به صورت پیشفرض در هسته خود از آداپترهای چندگانه انتشار پشتیبانی میکند.
در این مقاله، قصد داریم از آداپتر انتشار Pusher استفاده کنیم. برای مقاصد دیباگ کردن میتوانید از آداپتر log نیز استفاده کنید. اما توجه داشته باشید که در صورت استفاده از آداپتر log، کلاینت دیگر نمیتواند اعلانهای رویداد را دریافت کند، چون همه آنها در فایل laravel.log ثبت میشوند.
در بخش بعدی مستقیماً وارد مراحل پیادهسازی عملی کاربردهایی خواهیم شد که در بخش قبل مورد اشاره قرار دادیم.
تنظیم پیشنیازها
در فرایند انتشار یا broadcasting انواع مختلفی از کانالها وجود دارند که شامل کانالهای عمومی، خصوصی و presence میشوند. زمانی که یک رویداد به صوت عمومی انتشار مییابد، میبایست از کانال عمومی استفاده کرد. به طور عکس کانال خصوصی زمانی مورد استفاده قرار میگیرد که بخواهیم اعلانهای رویداد به برخی کانالهای خصوصی معین محدود شوند.
در زمینه مثالی که ما مورد بررسی قرار میدهیم، قصدمان این است که هر زمان کاربران پیام جدیدی دریافت کردند، یک اعلان به آنها ارسال شود. برای این که یک کاربر شرایط دریافت اعلانهای انتشار را داشته باشد، باید وارد حساب خود شده باشد. از این رو باید از کانال خصوصی در این مثال استفاده کنیم.
قابلیت احراز هویت در هسته مرکزی لاراول
قبل از هر چیز، باید سیستم احراز هویت پیشفرض لاراول را فعال کنیم تا قابلیتهایی مانند ثبت نام، ورود به حساب و موارد مشابه به صورت آماده در اختیار ما قرار بگیرند. اگر در این خصوص دچار ابهاماتی هستید بهتر است به مستندات رسمی (+) این بخش مراجعه کنید.
نصب و پیکربندی Pusher SDK
از آنجا که ما قصد داریم از سرویس شخص ثالث Pusher به عنوان سرور وب سوکت خود استفاده کنیم، باید یک حساب کاربری در این سرویس (+) ایجاد کنید و مطمئن شوید که اطلاعات احراز هویت API را پس از ثبت نام به دست آوردهاید.
سپس باید SDK مربوط به Pusher را برای PHP نصب کنیم تا اپلیکیشن لاراول ما بتواند اعلانهایی به سرور وب سوکت Pusher ارسال کند. در ریشه اپلیکیشن لاراول دستور زیر را اجرا کنید تا به صورت یک پکیج کامپوزر نصب شود:
composer require pusher/pusher-php-server "~3.0"
اینک فایل پیکربندی انتشار را طوری تغییر میدهیم که آداپتر Pusher به عنوان درایور انتشار پیشفرض ما فعال شود.
همان طور که میبینید، ما درایور انتشار پیشفرض را به Pusher تغییر دادهایم. همچنین گزینههای پیکربندی کلاستر و رمزنگاری را نیز که در ابتدا از حساب Pusher دریافت کرده بودیم، اضافه کردهایم. ضمناً برخی مقادیر را نیز از «متغیرهای محیطی» (environment variables) به دست میآوریم. بنابراین باید مطمئن شویم که متغیرهای زیر را در فایل env. به طرز صحیحی تنظیم کردهایم.
BROADCAST_DRIVER=pusher
PUSHER_APP_ID={YOUR_APP_ID}
PUSHER_APP_KEY={YOUR_APP_KEY}
PUSHER_APP_SECRET={YOUR_APP_SECRET}سپس باید چند تغییر در بخشهای مختلف فایلهای اصلی لاراول ایجاد کنیم تا با جدیدترین SDK مربوط به Pusher سازگار شود. البته ایجاد تغییر در فریمورک اصلی توصیه نمیشود؛ اما ما صرفاً مواردی را که باید انجام یابند مشخص میسازیم. فایل زیر را باز کنید:
vendor/laravel/framework/src/Illuminate/Broadcasting/Broadcasters/PusherBroadcaster.php
عبارت ;use Pusher را با ;use Pusher\Pusher عوض کنید. سپس فایل زیر را باز کنید:
vendor/laravel/framework/src/Illuminate/Broadcasting/BroadcastManager.php
و تغییر مشابهی را در قطعه کد زیر اعمال کنید:
در نهایت با حذف کامنت از خط زیر در فایل config/app.php، سرویس انتشار را فعال کنید:
تا به اینجا ما موفق شدهایم کتابخانههای مربوط به سرور را نصب کنیم. در بخش بعدی قصد داریم کتابخانههای کلاینت مورد نیاز را نیز نصب کنیم.
نصب و پیکربندی کتابخانههای Pusher و Laravel Echo
در فرایند انتشار، مسئولیت سمت کلاینت این است که در کانالها ثبت نام کند و منتظر شنیدن رویدادهای مورد نظر باشد. این کار در پسزمینه با باز کردن یک اتصال جدید به سرور وب سوکت صورت میپذیرد.
خوشبختانه نیاز نیست هیچ گونه کتابخانه پیچیده جاوا اسکریپت را نصب کنیم، چون لاراول از قبل یک کتابخانه کلاینت مفید در این زمینه دارد. Laravel Echo کتابخانه سمت کلاینت لاراول است که امکان کار کردن با سوکتها را در اختیار ما قرار میدهد. ضمناً این کتابخانه از سرویس Pusher که در این مقاله مورد استفاده قرار میدهیم نیز پشتیبانی میکند.
شما میتوانید Laravel Echo را با استفاده از ابزار مدیریت بسته NPM نصب کنید. البته اگر node و npm را روی سیستم خود نصب ندارید، ابتدا باید آنها را نصب کنید. بقیه کار کاملاً آسان است و در دستور زیر مشخص شده است:
npm install laravel-echo
ما به دنبال فایل node_modules/laravel-echo/dist/echo.js هستیم که باید آن را به مسیر public/echo.js کپی کنیم.
البته شاید به نظر شما انجام این همه کار برای دریافت یک فایل جاوا اسکریپت، اضافهکاری باشد. در این صورت اگر نمیخواهید این مسیر را طی کنید، میتوانید این فایل echo.js را از این آدرس گیتهاب (+) دانلود کنید. بدین ترتیب کار ما در بخش تنظیم کتابخانههای سمت کلاینت به پایان میرسد.
تنظیم فایل بکاند
اگر به خاطر داشته باشید در ابتدا گفتیم که قصد داریم اپلیکیشنی بسازیم که به کاربران امکان ارسال پیام به همدیگر را میدهد. از سوی دیگر اعلانهایی به کاربرانی که وارد حساب خود شدهاند، ارسال میکنیم تا آنها را از دریافت پیام جدید از سوی کاربران دیگر مطلع سازیم. در این بخش فایلهایی را که برای پیادهسازی این موارد لازم هستند ایجاد میکنیم.
در آغاز کار یک مدل Message ایجاد میکنیم که پیامهای ارسالی از سوی کاربران به همدیگر را نگهداری میکند.
php artisan make:model Message –migration
همچنین چند فیلد دیگر مانند to ،from و message به جدول messages اضافه میکنیم. بنابراین فایل migration خود را پیش از اجرای دستور migrate به صورت زیر تغییر میدهیم:
اکنون میتوانیم دستور migrate را اجرا کنیم تا جدول پیامها در پایگاه داده ایجاد شود:
php artisan migrate
هر زمان که میخواهیم یک رویداد سفارشی را در لاراول ایجاد کنیم، باید یک کلاس برای آن بسازیم. بر اساس نوع رویداد، لاراول واکنش متناسب را نشان میدهد و اقدامات لازم را اجرا میکند.
اگر رویداد یک رویداد نرمال باشد، لاراول «کلاسهای شنونده» (Listener classes) مرتبط را فراخوانی میکند. در سوی دیگر، اگر رویداد از نوع انتشار باشد، لاراول آن رویداد را به سرور وب سوکت ارسال میکند که در فایل config/broadcasting.php پیکربندی شده است. از آنجا که ما در این مقاله از سرویس Pusher استفاده میکنیم، لاراول رویدادها را به سرور Pusher ارسال میکند. از دستور آرتیزان زیر برای ایجاد یک کلاس رویداد سفارشی به نام NewMessageNotification استفاده میکنیم:
php artisan make:event NewMessageNotification
دستور فوق کلاس app/Events/NewMessageNotification.php را ایجاد میکند. محتوای این فایل را با کد زیر عوض میکنیم:
نکته مهمی که باید توجه داشته باشید این است که کلاس NewMessageNotification اینترفیس ShouldBroadcastNow را پیادهسازی میکند. از این رو زمانی که یک رویداد رخ میدهد، لاراول میداند که این رویداد باید انتشار یابد.
در واقع، میتوان یک اینترفیس ShouldBroadcast را نیز پیادهسازی کرد و لاراول رویداد را به صف رویدادها اضافه میکند. این رویداد زمانی که نوبتش شود، از سوی ورکر صف رویداد پردازش میشود. در مورد مثال خودمان، قصد داریم آن را مستقیماً منتشر کنیم و به همین دلیل از اینترفیس ShouldBroadcastNow استفاده میکنیم.
در این مثال، ما میخواهیم اعلانی به کاربر نمایش داده شود که به اطلاع وی میرساند پیامی دریافت کرده است و از این رو مدل Message در آرگومان سازنده ارسال میشود. بدین ترتیب دادهها به همراه رویداد ارسال میشوند.
سپس یک متد broadcastOn وجود دارد که نام کانالی را تعریف میکند که رویداد در آن منتشر خواهد شد. در مورد مثال خودمان از یک کانال خصوصی استفاده شده است، زیرا میخواهیم انتشار رویداد به کاربرانی که وارد حساب کاربری خودشان شدهاند محدود باشد.
متغیر this->message->to$ به ID کاربری اشاره میکند که قرار است رویداد برای وی انتشار یابد. بدین ترتیب بهتر است که نام کانال چیزی مانند {user.{USER_ID باشد.
در مورد کانالهای خصوصی، کلاینت باید خود را پیش از برقراری اتصال با سرور وب سوکت، احراز هویت کند. بدین ترتیب اطمینان پیدا میکنیم که رویدادهایی که روی کانال خصوصی منتشر میشوند صرفاً به کلاینتهای احراز هویت شده ارسال میشوند. در مثال مورد بررسی، این بدان معنی است که تنها کاربرانی که وارد حساب کاربری خود شدهاند، خواهند توانست در کانال {user.{USER_ID ثبت نام کنند.
اگر از کتابخانه کلاینت Echo لاراول برای ثبت نام استفاده میکنید، شانس آوردهاید، زیرا این کتابخانه به طور خودکار بخش احراز هویت را انجام میدهد و کافی است مسیرهای کانال را تعریف کنید. در ادامه یک مسیر برای کانال خصوصی خود در فایل routes/channels.php اضافه میکنیم:
همان طور که شاهد هستید، ما مسیر {user.{toUserId را برای کانال خصوصی خود تعریف کردهایم. آرگومان دوم متد کانال باید یک تابع «بستار» (Closure) باشد. لاراول به طور خودکار کاربری که اینک وارد حساب خود شده را به عنوان آرگومان نخست تابع بستار ارسال میکند و آرگومان دوم نیز معمولاً از نام کانال واکشی میشود.
زمانی که کلاینت تلاش کند در کانال خصوصی {user.{USER_ID ثبت نام کند، کتابخانه Echo لاراول احراز هویت ضروری را در پسزمینه با استفاده از شیء XMLHttpRequest که به صوت XHR شناختهشدهتر است، انجام میدهد. بدین ترتیب ما کار تنظیمات را به پایان بردیم و اینک نوبت تست پیادهسازی است.
تنظیم فرانتاند
در این بخش فایلهایی را که برای تست پیادهسازی ما ضروری هستند ایجاد میکنیم. ابتدا یک فایل کنترلر را در مسیر app/Http/Controllers/MessageController.php با محتوای زیر ایجاد میکنیم:
در متد index ما از ویوی broadcast استفاده میکنیم و از این رو فایل ویوی resources/views/broadcast.blade.php را نیز ایجاد میکنیم:
البته باید مسیرها را در فایل routes/web.php نیز اضافه کنیم:
Route::get('message/index', 'MessageController@index');
Route::get('message/send', 'MessageController@send');در متد سازنده کلاس کنترلر میتوانید ببینید که از میانافزار auth استفاده کردهایم تا مطمئن شویم که متدهای کنترلر به کاربران لاگین کرده دسترسی دارند. سپس متد index برای رندر کردن ویوی broadcast استفاده میشود. در ادامه مهمترین بخش کد را در فایل ویو مینویسیم:
در ابتدا کتابخانههای ضروری کلاینت که Laravel Echo و Pusher هستند را بارگذاری میکنیم. این کتابخانهها به ما امکان میدهند که یک اتصال وب سوکت با سرور وب سوکت Pusher برقرار سازیم. سپس با ارائه اطلاعات ضروری دیگر مرتبط با Pusher، وهلهای از Echo را به عنوان آداپتر انتشار خود میسازیم.
در ادامه از متد خصوصی Echo برای ثبت نام در کانال خصوصی {user.{USER_ID استفاده میکنیم. همان طور که قبلاً گفتیم، کلاینت پیش از ثبت نام در کانال خصوصی، باید هویت خود را احراز کند. از این رو شیء Echo مراحل مورد نیاز احراز هویت را با ارسال XHR در پسزمینه با پارامترهای ضروری انجام میدهد. در نهایت لاراول تلاش میکند که مسیر {user.{USER_ID را بیابد و این مسیر باید با مسیری که در فایل routes/channels.php وجود دارد، مطابقت داشته باشد.
اگر همه چیز به خوبی پیش برود، باید یک اتصال وب سوکت با سرور وب سوکت Pusher باز شود و رویدادهای روی کانال {user.{USER_ID از این پس در آن فهرست شوند. بدین ترتیب قادر خواهیم بود همه رویدادهای ورودی را در این کانال دریافت کنیم.
در مورد مثال خودمان میخواهیم به رویداد NewMessageNotification گوش کنیم و از این رو از متد listen شیء Echo برای دستیابی به آن استفاده میکنیم. برای این که همه چیز ساده بماند، تنها در مورد پیامهایی هشدار میدهیم که از سوی سرور Pusher دریافت شده باشند. بنابراین اکنون همه چیز را برای دریافت رویدادها از سرور وب سوکت تنظیم کردهایم. در ادامه از طریق متد send در فایل کنترلر برخی رویدادهای انتشار را ایجاد میکنیم. کد متد send به صورت زیر است:
ما در مثال خودمان، قصد داریم زمانی که کاربران لاگینکرده پیامی دریافت میکنند به آنها هشداری بدهیم. بنابراین تلاش میکنیم که این رفتار را در متد send شبیهسازی کنیم.
در این زمان، از تابع کمکی event برای ایجاد یک رویداد NewMessageNotification استفاده میکنیم. از آنجا که رویداد NewMessageNotification از نوع ShouldBroadcastNow است، لاراول پیکربندی پیشفرض انتشار را از فایل config/broadcasting.php بارگذاری میکند. در نهایت لاراول رویداد NewMessageNotification را به سرور وب سوکت پیکربندی شده روی کانال انتشار میدهد.
در این مثال، رویداد به سرور وب سوکت Pusher روی کانال {user.{USER_ID انتشارمی یابد. اگر ID کاربر پذیرنده 1 باشد، این رویداد روی کانال user.1 انتشار پیدا میکند.
همان طور که قبلاً بررسی کردیم، ما از قبل یک تنظیمات داریم که به رویدادهای روی این کانال گوش میدهد. بنابراین میتوانیم این رویداد را دریافت کنیم و کادر هشدار برای کاربر مربوطه نمایش پیدا میکند. در ادامه مراحل مورد نیاز برای تست این مثال کاربردی که ساختهایم را مورد بررسی قرار میدهیم. در مرورگر خود به آدرس زیر بروید:
http://your-laravel-site-domain/message/index
اگر هنوز وارد نشدهاید، به صفحه لاگین هدایت خواهید شد و زمانی که وارد حساب کاربری خود شدید، ویوی broadcast را میبینید که قبلاً تعریف کردهایم و تاکنون کاربردی نداشته است. در واقع لاراول از قبل مقداری از کارها را در پسزمینه برای شما انجام داده است. از آنجا که ما تنظیمات Pusher.logToConsole ارائه شده از سوی کتابخانه کلاینت Pusher را فعال کردهایم، این کتابخانه همه موارد را در کنسول مرورگر به منظور دیباگ کردن، لاگ میکند. با مراجعه به صفحه http://your-laravel-site-domain/message/index بررسی میکنیم که چه مواردی برای ما لاگ شدهاند:
همان طور که می بینید یک اتصال وب سوکت با سرور وب سوکت Pusher باز شده است و برای شنیدن رویدادها روی کانال خصوصی ثبت نام صورت گرفته است. البته شما میتوانید در مثال خودتان بر مبنای ID کاربری که گزارش را تهیه کرده است، نام کانال متفاوتی داشته باشید. اینک این صفحه را بار نگه میداریم و به متد send میرویم تا تست کنیم.
سپس URL زیر را در برگه دیگری از همان مرورگر یا در یک مرورگر دیگر باز کنید:
http://your-laravel-site-domain/message/send
اگر قصد دارید از مرورگر متفاوتی استفاده کنید، باید دوباره وارد حساب کاربری خود شود تا به این صفحه دسترسی داشته باشید. به محض این که آدرس فوق را باز کنید، میتوانید یک پیام هشدار را در برگه دیگر با آدرس http://your-laravel-site-domain/message/index ملاحظه کنید.
اینک به کنسول میرویم تا ببینیم چه اتفاقی رخ داده است:
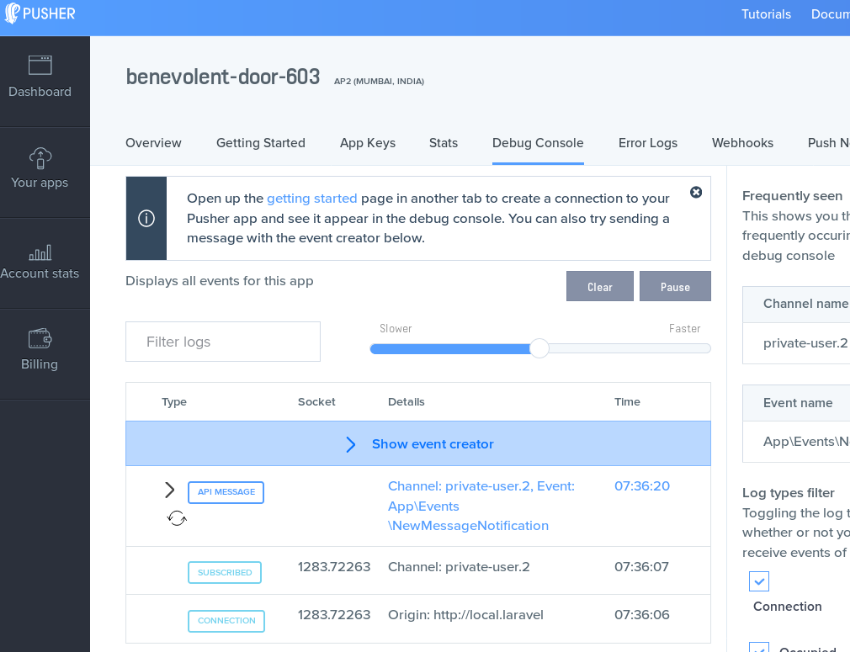
همان طور که میبینید این پیام لاگ نشان میدهد که رویداد App\Events\NewMessageNotification از سوی سرور وب سوکت Pusher روی کانال private-user.2 دریافت شده است.
در واقع شما میتوانید اتفاقاتی را که رخ داده است در حساب Pusher خود نیز ببینید. به این منظور به حساب کاربری Pusher خود بروید و به بخش application مراجعه کنید. زیر بخش Debug Console میتوانید پیامهایی را که لاگ شدهاند ببینید:
بدین ترتیب به پایان این مقاله راهنما میرسیم. امیدواریم از طولانی شدن این مقاله خسته نشده باشید، چون در طی آن تلاش کردیم همه چیز را به بهترین نحو ممکن توضیح دهیم.
سخن پایانی
در این مقاله با یکی از قابلیتهای لاراول آشنا شدیم که کمتر مورد بررسی قرار گرفته است و آن قابلیت انتشار لاراول است. این قابلیت به ما امکان میدهد که اعلانهای آنی را با استفاده از وب سوکتها ارسال کنیم. در طی این مقاله ما یک مثال واقعی برای نمایش مفاهیم فوق ساختیم.
منبع: فرادرس
آموزش پایتون: مفاهیم OpenCV برای تشخیص چهره و حرکت — راهنمای مقدماتی
شکی نیست که علم داده (به طور کلی) موضوع مهمی در زمینه علوم محسوب میشود و بر اساس آمارهای مختلف مشخص شده است که دانشمندان داده، پایتون را دوست دارند. یادگیری برخی جنبههای علم داده و پایتون با همدیگر یک ایده عالی محسوب میشود. به همین دلیل است که قصد داریم در بخشهای باقیمانده این سری مطالب آموزشی روی کاربردهای واقعی علم داده با بهرهگیری از پایتون متمرکز شویم. ما در این مقاله ابتدا مفهوم بینایی ماشین را توضیح میدهیم. البته این بدان معنی نیست که قصد داریم یک سیستم برای اتومبیلهای خودران بسازیم؛ بلکه میخواهیم در این مقاله کوتاه چندین نکته را در خصوص مفاهیم مقدماتی OpenCV بیاموزیم.
برای مطالعه قسمت قبلی این مجموعه مطلب روی لینک زیر کلیک کنید:
مسیر پیش رو طولانی است و لذا هر جا که احساس خستگی کردید کمی استراحت کنید. ابتدا باید OpenCV را نصب کنیم که اختصاری برای عبارت کتابخانه «بینایی ماشین متنباز» (Open Source Computer Vision) است. برای نصب آن کافی است دستور زیر را وارد کنید:
pip3 install opencv-python –user
گام 1: بارگذاری، نمایش و تغییر اندازه تصاویر
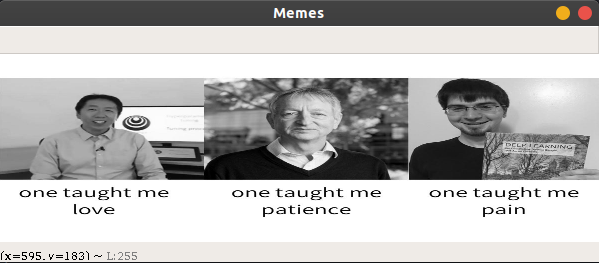
کار خود را با این مراحل ساده آغاز میکنیم. از آنجا که بینایی ماشین کلاً به تصاویر و ویدئوها مربوط میشود، ابتدا چند کار مانند بارگذاری، نمایش دادن، تغییر دادن اندازه تصاویر و نوشتن (ذخیره) آنها را مورد بررسی قرار میدهیم. احتمالاً تاکنون در شبکههای اجتماعی با برخی تصاویر که نوشتههای خندهداری روی آنها نوشته شده است مواجه شدهاید. این تصاویر meme نام دارند و از آنجا که meme زبانی است که همه ما درک میکنیم، در ابتدا از ساخت یک meme آغاز میکنیم.

تغییر دادن اندازه تصویر
تغییر دادن اندازه تصویر کار آسانی است. ما تابع cv2.resize را فراخوانی میکنیم و تصویر خود را به صورت آرگومان نخست و اندازه مطلوب را به صورت آرگومان دوم ارسال میکنیم. اینک برای نمایش و ذخیرهسازی تصویر، باید موارد زیر را درک کنیم.
- cv2.imshow یک پنجره برای نمایش تصویر ایجاد میکند که آرگومان نخست نام آن پنجره و آرگومان دوم تصویری است که باید نمایش یابد.
- cv2.imwrite برای ذخیرهسازی تصویر تولید شده استفاده میشود.
- cv2.waitKey برای دانستن این که چه زمانی باید از پنجره خارج شویم استفاده میشود. 0 به این معنی است که با زدن هر کلیدی خارج میشوید. با این وجود میتوانیم زمان خاصی را نیز به صورت (cv2.waitKey(2000 تعریف کنیم که به صورت خودکار پس از 2 ثانیه بسته شود.
- cv2.destroyAllWindows همه پنجرههای فعال را میبندد.
گام 2: تغییر دستهای اندازه تصاویر
ما ربات نیستم و بلکه انسانیم و از این رو موجوداتی هوشمند محسوب میشویم. ما دوست نداریم همه تصاویر را به صورت تک به تک تغییر اندازه بدهیم و به جای آن از عقل خود کمک میگیریم. بدین ترتیب کارها به روشی بسیار آسانتر انجام مییابند. GLOB در کد زیر همه تصاویر با پسوند jpg. درون دایرکتوری را پیدا میکند:
گام 3: تشخیص چهره در تصاویر
آیا تاکنون با نوعی فناوری تشخیص چهره مواجه شدهاید. این فناوری امروزه بسیار متداول شده است و در بخش دوربین گوشیهای تلفن همراه و یا روی برخی از نرمافزارها که روی لپتاپ نصب میکنیم از طریق وبکم آن استفاده میشود. در این زمان شاهد کادرهای سبز رنگی هستیم که پیرامون چهره افراد موجود در تصاویر نقش میبندد. شاید کنجکاو باشید که طرز کار این نرمافزارها چگونه است. البته نکته خاصی در مورد طرز کار آنها وجود ندارد، برای این که کد ما نیز چنین کاری انجام دهد، صرفاً باید دو بخش دیگر به نامهای Cascade Classifier و Detect Multi-Scale به آن اضافه کنیم و این کار را در ادامه انجام خواهیم داد.
()cv2.CascadeClassifier
این یک ابزار «طبقهبندی آبشاری» (Cascade Classifier) است که به وسیله چند صد نمای ساده «مثبت» از یک شیء خاص (یعنی چهره) و تصاویر «منفی» دلخواه با همان اندازه آموزش دیده است. به محض این که ابزار طبقهبندی، آموزش دید، میتواند روی یک تصویر جدید استفاده شده و شیء مورد نظر را تشخیص دهد. در این مقاله، ما ابزار طبقهبندی frontface از پیش آموزش دیده را برای تشخیص چهره در تصویر استفاده خواهیم کرد.
()face_cascade.detectMultiScale
از این ابزار برای دانستن مکان دقیق چهره در تصویر استفاده میشود. ما اینجا دو پارامتر داریم. در ادامه با ماهیت آنها آشنا شده و فایدهشان را بررسی میکنیم. اندازه تصویر را طوری تغییر میدهد که وقتی چهرههای بزرگتر یا کوچکتر وجود داشته باشند، الگوریتم بتواند آنها را تشخیص دهد.
از یک گام کوچک مانند 1.05 برای تغییر اندازه استفاده کنید. 1.05 به این معنی است که اندازه تصویر به اندازه 5 درصد کاهش مییابد و بدین ترتیب احتمال تطبیق اندازه با مدل تشخیص افزایش مییابد.
minNeighbors
این پارامتر روی کیفیت چهرههای تشخیص یافته تأثیر دارد. هر چه مقادیر بالاتر باشد تعداد تشخیصها کاهش مییابد؛ اما کیفیت آنها بالاتر میرود.

اگر به خروجی نگاه کنید، چهار مقدار در شیء چهره وجود دارد. اگر این چهار مقدار را میبینید بدان معنی است که یک چهره تشخص داده شده است. اما چهره کجای تصویر است؟ پاسخ این سؤال در همان چهار مقدار است. دو مقدار نخست 241 و 153 هستند که مختصات X و Y چهره تشخیص داده شده (گوشه سمت چپ-بالا) است. دو مقدار بعدی یعنی 206 و 206 به ترتیب عرض و ارتفاع ناحیهای هستند که چهره در آن قرار دارد.
اینک که میدانیم چهره در کجای تصویر قرار دارد، میتوانیم آن را طوری نشانهگذاری کنیم که قابل تمییز باشد. بدین منظور از ()cv2.rectangle برای نشانهگذاری این کادر استفاده خواهیم کرد. پارامترهای آن بدین صورت است که پارامتر اول خود تصویر است. پارامتر دوم نقطه آغازین چهره تشخیص داده شده است که توضیح دادیم. پارامتر سوم گوشه مقابل پارامتر دوم است و در نهایت پارامتر آخر ضخامت کادری است که ترسیم خواهد شد.

بدین ترتیب میبینید که الگوریتم ما تصویر چهره الون ماسک را در حال سیگار کشیدن تشخیص داده است.
گام 4: دریافت ویدئو
اینک یک گام به سمت جلو حرکت میکنیم و تلاش میکنیم یک ویدئو را به دست آوریم. ویدئو چیزی به جز مجموعهای از تصاویر نیست و از این رو مجموعهای از فریمها نامیده میشود. همان طور که در کد زیر میبینید ما متد VideoCapture کتابخانه cv2 را فراخوانی و مقدار 0 را به آن ارسال میکنیم که به معنی دریافت ویدئو از وب کم لپتاپ است. frame آرایهای از نخستین تصویر/فریم ویدئو ترسیم میکند.
اما اگر بخواهیم ویدئوی واقعی را که وبکم ما دریافت میکند ببینیم باید چه کار کنیم؟ بدین منظور کافی است از متد cv2.imshow استفاده کنید و از چرخه تکرار همانند روشی که در زمان تغییر اندازه دستهای تصاویر استفاده کردیم، بهره بگیرید.
در این کد (waitKey(1 به این معنی است که فریمها هر 1 میلیثانیه یک بار دریافت میشوند. زمانی که حرف q را وارد کنید این حلقه متوقف شده و دریافت ویدئو متوقف میشود. در تصویر زیر عملکرد واقعی این کد را در زمان روشن بودن وبکم مشاهده میکنید.
در تصویر فوق به میزان سرعت تغییر فریمها در ویدئو توجه کنید. اینک که میدانیم چگونه یک ویدئو را دریافت کنیم نوبت آن رسیده است که به بررسی چگونگی شناسایی اشیا به صورت آنی شامل چهرهها بپردازیم.
گام 5: تشخیص حرکت
ابتدا به بررسی تئوریک تشخیص حرکت میپردازیم و سپس اقدام به کدنویسی آن میکنیم. اگر نکتهای را متوجه نشدید، صرفاً به مطالعه خود ادامه بدهید، چون زمانی که به انتهای این بخش برسیم همه چیز برایتان معنی خواهد یافت.
چرا الگوریتم تشخیص حرکت را بررسی میکنیم؟
اگر بخواهیم صادق باشیم، دلیل این مسئله آن است که این سادهترین الگوریتم است. همچنین در موارد مختلف کارایی زیادی دارد. برای نمونه اگر بخواهید یک کودک یا سگ را مورد نظارت قرار دید، به دو مرحله نیاز دارید. ابتدا باید اشیا را به صورت آنی تشخیص دهید و سپس باید زمانی که این اشیا وارد فریم شده و یا از آن خارج میشوند را ثبت کنید.
مرحله اول: تشخیص شیء
- ابتدا یک فریم را ثبت میکنیم که به صوت یک فریم پسزمینه استاتیک/خالی است و از این تصویر به عنوان تصویر مبنا استفاده میکنیم تا آن را با تصاویر دیگر مقایسه کرده و تشخیص دهیم که آیا چیزی بین فریم اول و فریمهای بعدی تغییر یافته است یا نه.
- زمانی که تصویر مبنا تعیین شد، نوبت آن رسیده است که وقتی شیء وارد فریم میشود آن را شناسایی کنیم. دقت کنید که در این روش در «فریم تغییرات» (delta frame) تصویر مبنا یک پسزمینه استاتیک به رنگ سیاه است و اینک به رنگ خاکستری تغییر یافته است. فریم دوم دلتا جایی است که از فریم استاتیک ارائه شده در مرحله قبلی استفاده کردهایم و متوجه تغییر یافتن مکان سوژه در تصویر شدهایم.
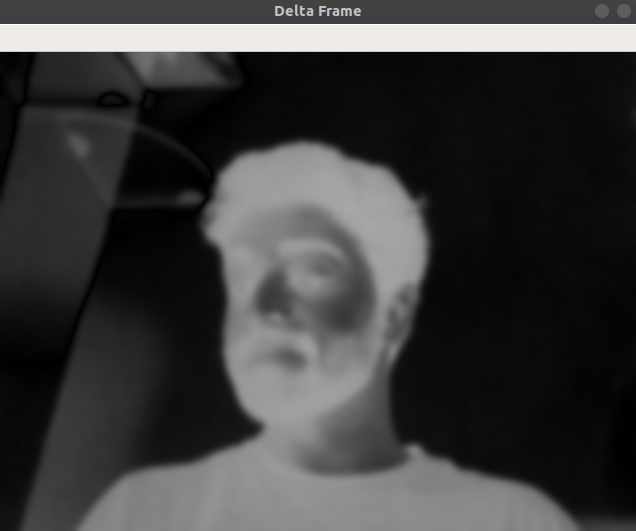

در ادامه نسخه بهبودیافتهای از فریم دلتا وجود دارد که فریم آستانه است. اگر اختلاف بین فریم قبلی و این فریم بیش از (مثلاً) 100 باشد، این پیکسلها به صورت سفید در میآیند. همان طور که میبینید، چهره موجود در این تصویر به صورت پیکسلهای سفید در آمده است در حالی که پسزمینه سیاه است.
طرز کار تشخیص حرکت یک شیء در تصویر اساساً به همین شکل است. ما ابتدا کانتورها (یعنی نقاطی که جابجا شده) تصویر سفید را مییابیم و اگر مساحت ناحیه کانتور بیش از 500 پیکسل باشد، در این صورت آن را به معنی تغییر مکان شیء ثبت میکنیم. بدین ترتیب آن شیءها را با کادرهایی مشخص میسازیم. کد نهایی به همراه توضیحات به صورت زیر است:
مرحله دوم: ثبت زمان وقوع حرکت
فرض کنید مشغول رصد حرکات یک سگ هستیم. ما روی مکانی که وی معمولاً قرار دارد یک دوربین تنظیم کردهایم. اینک قصد داریم زمان را ثبت کنیم تا بدانیم این سگ چند بار از جای خود بلند میشود تا خانه را به هم بریزد.
به این منظور ابتدا باید نقاطی را که شیء وارد فریم شده و از آن خارج میشود ثبت کنیم. ما یک شیء به نام status ایجاد میکنیم و آن را برابر با 0 و 1 (به ترتیب خطوط 20 و 47) قرار میدهیم.
اینک مقادیر را در یک لیست (خط 52) ذخیره میکنیم. این لیست مانند تصویر زیر خواهد بود. دو مورد اول none هستند، زیرا این یک فریم استاتیک است. سری صفرها به این معنی است که شیء مورد نظر در فریم نیست و سپس سریهای 1 به این معنی است که شیئی در تصویر وجود دارد.
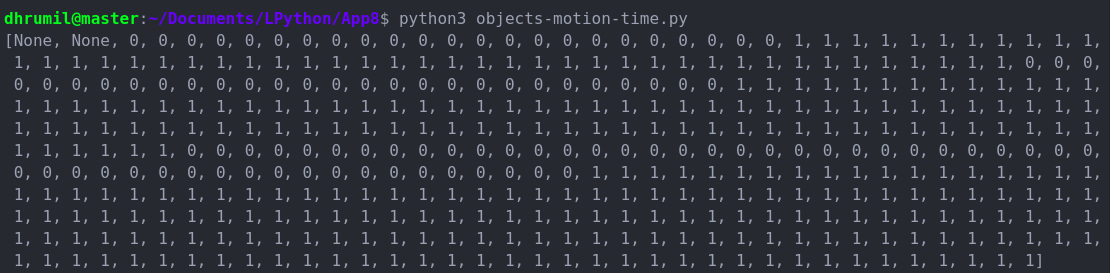
اما ما به همه این موارد نیاز نداریم. ما تنها میخواهیم مواردی را ثبت کنیم که شیء مورد نظر وارد فریم شده و از آن خارج شده است. بنابراین باید هر بار عنصر آخر را با عنصر ماقبل آخر مقایسه کنیم تا ببینیم آیا از 0 به 1 یا برعکس تغییر یافته است یا نه. اگر چنین باشد، در این صورت آن زمان را (در خطوط 54 تا 57) ذخیره میکنیم و در نهایت زمان را به دیتافریم الحاق و آن را روی سیستم ذخیره میکنیم. نتیجهای که ما به دست آوردهایم چیزی مانند تصویر زیر است. شما میتوانید آن را بر اساس نیازهای خود تنظیم سفارشی بکنید.

سخن پایانی
بینایی رایانه رشتهای است که هر روز پیشرفتهای زیادی در آن رخ میدهد. ما مطمئن هستیم که شما از برخی از این موارد آگاه هستید. علاوه بر آن، شما اینک با روش دستکاری تصاویر، طرز شناسایی یک چهره در تصاویر، چگونگی تشخیص اشیا به صورت همزمان (که کاربردهای واقعی آن در مواردی مانند اتومبیلهای خودران است) و شیوه ثبت زمان ورود و خروجی شیء به فریم آشنا هستید. بدین ترتیب شما با مطالعه این مقاله پیشرفت زیادی کردهاید و موفق شدهاید دانش نظری/مفهومی خود را به یک دانش عملی تبدیل کنید.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
کار با JSON در جاوا اسکریپت — راهنمای کاربردی
JSON اختصاری برای عبارت «نشانهگذاری شیء جاوا اسکریپت» (JavaScript Object Notation) است. JSON استانداردی برای قالببندی مبتنی بر متن است که دادههای ساختیافته را بر اساس ساختار شیء جاوا اسکریپت نمایش میدهد. این نشانهگذاری به طور معمول برای انتقال دادهها در وباپلیکیشنها استفاده میشود. این انتقال شامل ارسال برخی دادهها از سرور به کلاینت است و از این رو میتواند روی یک صفحه وب نمایش یابد. شما در موارد مختلف با آن مواجه خواهید شد و از این رو در این مقاله هر آنچه که برای کار با JSON در جاوا اسکریپت نیاز دارید ارائه میکنیم. این موارد شامل تجزیه JSON برای دسترسی به دادههای آن و همچنین ایجاد JSON است.
پیشنیازها
- سواد مقدماتی رایانه
- درک پایه از HTML و CSS
- آشنایی با مبانی جاوا اسکریپت و شیءگرایی در جاوا اسکریپت
هدف از این مقاله درک شیوه کار کردن با دادههای ذخیره شده به صورت JSON و ایجاد شیءهای JSON است. برای مطالعه قسمت قبلی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید.
JSON چیست؟
JSON یک قالب مبتنی بر متن است که از ساختار شیء جاوا اسکریپت پیروی میکند و از سوی «داگلاس کراکفورد» (Douglas Crockford) ترویج یافته است. علیرغم این که این قالب کاملاً شبیه به ساختار لفظی شیء جاوا اسکریپت است، اما میتواند مستقل از جاوا اسکریپت نیز استفاده شود. بسیاری از محیطهای برنامهنویسی امکان خواندن (تجزیه) و تولید JSON را میدهد.
JSON در قالب رشته است و زمانی که بخواهید دادهها را روی یک شبکه منتقل کنید، بسیار مفید خواهد بود. این قالب هنگامی که بخواهید به دادههایش دسترسی پیدا کنید، باید به شیء بومی جاوا اسکریپت تبدیل شود. این مشکل بزرگی نیست و جاوا اسکریپت شیء JSON را ارائه کرده است که متدهایی برای تبدیل بین این دو نوع دارد.
نکته: تبدیل کردن یک رشته به شیء بومی به نام «تجزیه کردن» (parsing) نامیده میشود؛ در حالی که تبدیل کردن یک شیء بومی به یک رشته جهت ارسال کردن روی یک شبکه به نام «رشته سازی» (stringification) نامیده میشود.
یک شیء JSON میتواند در فایل خاص خود ذخیره شود که اساساً یک فایل متنی با پسوند json. و نوع MIME به صورت application/json است.
ساختار JSON
همان طور که پیشتر توضیح دادیم، JSON رشتهای است که قالب آن تا حدود زیادی شبیه به قالب لفظی شیء جاوا اسکریپت است. شما میتوانید برخی انواع داده ابتدایی مانند رشته، اعداد، آرایهها، مقادیر بولی، و دیگر شیءهای لفظی را که در شیء جاوا اسکریپت وجود دارند، درون JSON قرار دهید. بدین ترتیب امکان ساخت یک سلسلهمراتب داده مانند زیر وجود دارد:
اگر این شیء را درون یک برنامه جاوا اسکریپت بارگذاری کنید (برای نمونه درون یک متغیر به نام superHeroes تجزیه کنید)، در ادامه میتوانید با استفاده از همان نشانهگذاری نقطه/براکت که در شیءهای جاوا اسکریپت مشاهده کردید، به دادههای درون آن دسترسی داشته باشید. برای نمونه:
برای دسترسی به دادههایی که در سطوح عمیقتری از سلسلهمراتب قرار دارند، کافی است نامهای مشخصهها و اندیسهای آرایهها را با هم ترکیب کنید. برای نمونه برای دسترسی به سومین superpower از دومین hero که در فهرست members قرار دارد به صورت زیر عمل میکنیم:
- ابتدا نام متغیر یعنی superHeroes را داریم.
- درون آن میخواهیم به مشخصه members دسترسی داشته باشیم و از این رو از [“members”] استفاده میکنیم.
- members شامل آرایهای است که شیءهایی در آن قرار گرفتهاند و ما میخواهیم به شیء دوم درون آرایه دسترسی داشته باشیم و از این رو از [1] استفاده میکنیم.
- درون این شیء میخواهیم به مشخصه powers دسترسی داشته باشیم و بنابراین از [“powers”] استفاده میکنیم.
- درون مشخصه powers آرایهای وجود دارد که شامل superpower-های قهرمان منتخب است. ما به superpower سوم نیاز داریم و از این رو از اندیس [2] استفاده میکنیم.
آرایههای JSON
در بخش قبل اشاره کردیم که متن JSON اصولاً شباهت به شیء جاوا اسکریپت دارد و این بیان تا حدود زیادی صحیح است. دلیل این که میگوییم تا «حدود زیادی» این است که یک آرایه نیز در واقع یک JSON معتبر محسوب میشود. برای نمونه به کد زیر توجه کنید:
کد فوق یک JON کاملاً معتبر است. کافی است با آغاز از یک اندیس آرایه به آیتمهای آن دسترسی داشته باشید. برای نمونه میتوانید از کد زیر استفاده کنید:
نکات دیگر
- JSON قطعاً یک قالب داده است، چون شامل داده است و هیچ متدی ندارد.
- JSON نیازمند گیومههای جفتی (” “) پیرامون نام رشتهها و مشخصهها است و گیومههای تکی (‘ ‘) معتبر نیستند.
- حتی یک کاما یا دونقطه منفرد نیز میتواند باعث نامعتبر شدن کل یک فایل JSON شود و آن را از کار بیندازید. هنگامی که میخواهید از هر نوع دادهای استفاده کنید، ابتدا باید آن را اعتبار سنجی کنید. با این حال JSON-های تولید شده از سوی رایانه عموماً اشکالی دارند؛ مگر این که اشکالی در برنامه تولیدکننده آنها وجود داشته باشد. شما میتوانید JSON را با استفاده از یک اپلیکیشن مانند JSONLint (+) اعتبارسنجی کنید.
- JSON میتواند در عمل از هر نوع دادهای که برای قرار گرفتن درون JSON معتبر است، ایجاد شود و محدود به شیء یا آرایه نیست. بنابراین برای مثال، یک رشته یا عدد منفرد نیز میتواند یک شیء معتبر JSON باشد.
- برخلاف کد جاوا اسکریپت که در آن مشخصههای شیء ممکن است به صورت خارج از گیومه باشند، درون JSON تنها رشتههای درون گیومه میتوانند به عنوان مشخصه استفاده شوند.
مثال کاربردی
بدین ترتیب مثالی را بررسی میکنیم که شیوه بهرهبرداری از دادههای JSON روی یک وبسایت را به ما نشان میدهد. در ابتدا کد زیر را کپی کرده و در فایلی با نام heroes.heml روی سیستم خود ذخیره کنید:
همچنین کد زیر را کپی کرده و در فایلی با نام style.css در کنار فایل فوق روی سیستم خود ذخیره کنید:
فایل دوم شامل CSS سادهای برای شبکهبندی صفحه html ما است و فایل اول نیز یک کد HTML کاملاً ساده body به صورت زیر را شامل میشود:
همچنین یک <script> وجود دارد که کد جاوا اسکریپت موردنیاز خود در این تمرین را درون آن مینویسیم. در حال حاضر این فایل تنها شامل دو خط است که ارجاعهایی به عناصر <header> و <section> به دست آورد و آنها را در متغیرهایی به صورت زیر ذخیره میکند:
دادههای JSON که در این مثال استفاده میکنیم به صورت زیر هستند:
این دادهها در این آدرس (+) قابل دسترسی هستند. ما قصد داریم این دادهها را در صفحه خود بارگذاری کرده و از نوعی دستکاری DOM برای نمایش آن به صورت زیر استفاده کنیم:

به دست آوردن JSON
برای به دست JSON باید از یک API به نام XMLHttpRequest که غالباً XHR نامیده میشود استفاده کنیم. این یک شیء کاملاً مفید جاوا اسکریپت است که به ما امکان میدهد درخواستهای شبکه برای بازیابی منابع (مانند تصاویر، متن، JSON و حتی قطعه کدهای HTML) را از طریق جاوا اسکریپت از سرور داشته باشیم. این بدان معنی است که میتوانیم بخشهای کوچکی از محتوا را بدون نیاز به بارگذاری مجدد کل صفحه، بهروزرسانی کنیم. بدین ترتیب میتوانیم صفحههایی با واکنشگرایی بالاتر داشته باشیم. این وضعیت هیجانانگیز به نظر میرسد؛ اما بررسی این موضوع خارج از حیطه این مقاله است.
در آغاز قصد داریم URL مربوط به JSON را که میخواهیم بازیابی کنیم در یک متغیر ذخیره کنیم. به این منظور کد زیر را به انتهای کد جاوا اسکریپت خود اضافه کنید:
برای ایجاد درخواست، باید یک وهله از شیء درخواست جدید از سازنده XMLHttpRequest ایجاد کنیم. این کار با استفاده از کلیدواژه new انجام مییابد. کد زیر را پس از خط آخر اضافه کنید:
ما باید یک درخواست جدید را با استفاده از متد ()open باز کنیم. به این منظور کد زیر را اضافه کنید:
پارامترهای XMLHttpRequest
این کد دستکم دو پارامتر میگیرد. پارامترهای اختیاری دیگری نیز وجود دارند. ما برای این مثال ساده تنها به دو پارامتر اجباری نیاز داریم.
- متد HTTP که برای ایجاد درخواست شبکه مورد نیاز است و در این مورد GET مناسب است، چون میخواهیم صرفاً برخی دادههای ساده را بازیابی کنیم.
- URL-ی که درخواست به آن ارسال میشود و این همان URL است که فایل JSON در آن قرار دارد و قبلاً در متغیری ذخیره کردهایم.
سپس دو خط زیر را اضافه میکنیم. در این کد مقدار responseType را به صورت JSON تنظیم میکنیم و بدین ترتیب XHR میداند که سرور، کد JSON بازگشت خواهد داد و این که باید در پشت صحنه آن را به شیء جاوا اسکریپت تبدیل کند. سپس باید این درخواست را به متد ()send ارسال کنیم:
آخرین بخش کد شامل نوشتن پاسخهای بازگشتی از سرور و سپس کار کردن با آنها است. کد زیر را در ادامه کدهای قبلی وارد کنید:
ما در این کد پاسخ به درخواست خود را که در مشخصه response قرار دارد، در یک متغیر به نام superHeroes ذخیره میکنیم. این متغیر اینک شامل شیء جاوا اسکریپت مبتنی بر JSON است. سپس این شیء را به دو فراخوانی تابع ارسال میکنیم. مورد نخست آن است که عنصر <header> را با دادههای صحیح پر میکند و تابع دوم آن است که یک کارت اطلاعاتی را برای هر قهرمان در تیم پر میکند و آن را درون <section> قرار میدهد.
ما کد خود را درون یک دستگیره رویداد قرار میدهیم که وقتی رویداد بارگذاری شیء درخواست رخ بدهد اجرا میشوند. دلیل این امر آن است که رویداد load زمانی رخ میدهد که پاسخ با موفقیت بازگشت یافته باشد. اجرای این کار به این ترتیب تضمین میکند که request.response هنگامی که به آن نیاز داریم، قطعاً در دسترس ما خواهد بود.
پر کردن مقادیر header
اینک که دادههای JSON را بازیابی و آنها را به شیء جاوا اسکریپت تبدیل کردهایم، میتوانیم با نوشتن دو تابع که در بخش فوق اشاره کردیم، از آنها بهرهبرداری کنیم. قبل از هر چیز تعریف تابع زیر را به کد قبلی اضافه کنید:
ما این پارامتر را jsonObj مینامیم تا به خودمان یادآوری کنیم که این شیء جاوا اسکریپت ریشه در JSON دارد. در این کد ابتدا یک عنصر <h1> با متد ()createElement میسازیم و خصوصیت textContent آن را برابر با مشخصه squadName شیء قرار میدهیم. سپس با استفاده از ()appendChild آن را به شیء الحاق میکنیم. در ادامه عملیات مشابهی را با یک پاراگراف انجام میدهیم یعنی آن را ایجاد، محتوای متنی آن را تعیین کرده و آن را به هدر الحاق میکنیم. تنها تفاوت در این است که متن آن برابر با رشته مرکب از دو مشخصه homeTown و formed شیء است.
ایجاد کارتهای اطلاعاتی hero
در ادامه تابع زیر را به انتهای کد خود اضافه میکنیم که کارتهای ابرقهرمانها را ایجاد کرده و نمایش میدهد:
در ابتدای این قطعه کد، مشخصه members شیء جاوا اسکریپت را در یک متغیر جدید ذخیره میکنیم. این آرایه شامل چند شیء است که محتوای اطلاعاتی در مورد هر قهرمان است. سپس یک حلقه for میسازیم که روی همه اشیای آرایه میچرخد. در مورد هر شیء موارد زیر را میتوان برشمرد:
- چند عنصر جدید ایجاد میشوند: یک <article>، یک <h2>، سه <p> و یک <ul>.
- مقدار <h2> شامل name قهرمان کنونی است.
- سه پاراگراف را با مقادیر secretIdentity و age پر میکنیم و یک خط با عبارت «:Superpowers» مینویسیم که این اطلاعات را در لیست نمایش دهد.
- مشخصه powers در متغیر جدید دیگری به نام superPowers ذخیره میشود. این متغیر شامل آرایهای است که «قدرتهای ماورایی» (Superpowers) قهرمان کنونی را ذخیره میکند.
- از حلقه for دیگری برای تعریف یک چرخه روی superpower-های قهرمان کنونی استفاده میکنیم. برای هر مورد یک عنصر <li> اضافه میکنیم که superpower قهرمان درون آن قرار میگیرد و سپس listItem را با استفاده از ()appendChild درون عنصر <ul> قرار میدهیم.
- آخرین کاری که باید انجام دهیم، این است که <h2>, <p>-ها و <ul> را درون <article> قرار میدهیم و سپس <article> را درون <section> اضافه میکنم. ترتیب اضافه کردن این موارد به همان صورت که اشاره کردیم حائز اهمیت است، چون به این ترتیب درون HTML نمایش خواهد یافت.
نکته: اگر در اجرای این تمرین با مشکل مواجه شدید، میتوانید با مراجعه به کد زیر اشکال خود را پیدا کنید:
اگر در پیگیری نشانهگذاری نقطه/براکت که برای دسترسی به شیء جاوا اسکریپت استفاده کردهایم، مشکل دارید، میتوانید به کد JSON که پیشتر ارائه کردیم مراجعه کنید و در زمان بررسی کد جاوا اسکریپت آن را مورد بررسی قرار دهید.
تبدیل بین اشیا و متن
مثال فوق بر حسب دسترسی به شیء جاوا اسکریپت ساده است، زیرا درخواست XHR را طوری تنظیم کردهایم که با دستور زیر پاسخ JSON را مستقیماً به شیء جاوا اسکریپت تبدیل کند:
اما برخی اوقات چندان خوششانس نیستیم، در برخی موارد یک رشته JSON خام دریافت میکنیم و باید آن را خودمان به یک شیء تبدیل کنیم. زمانی که میخواهیم یک شیء جاوا اسکریپت را روی شبکه ارسال کنیم، باید آن را قبل از ارسال به (یک رشته) JSON تبدیل کنیم. خوشبختانه این دو مسئله در زمینه توسعه وب چنان رایج هستند که شیء داخلی JSON در مرورگرها دو متد برای آن در نظر گرفته است:
- ()parse: یک رشته JSON را به عنوان پارامتر میپذیرد و شیء جاوا اسکریپت متناظر را بازگشت میدهد.
- ()stringify: یک شیء را به عنوان پارامتر میپذیرد و رشته JSON معادل را بازگشت میدهد.
مورد اول را در قطعه کد کامل که در بخش قبلی ارائه کردیم میتوانید ببینید. این متد دقیقاً همان کاری را انجام میدهد که ما قبلاً ساختیم به جز این که XHR طوری تنظیم شده که یک متن JSON خام را بازگشت دهد و سپس از ()parse برای تبدیل آن به یک شیء جاوا اسکریپت واقعی استفاده میشود. قطعه کد اصلی به صورت زیر است:
همان طور که احتمالاً حدس میزنید، ()stringify به طور معکوس عمل میکند. خطوط زیر را در کنسول جاوا اسکریپت مرورگر خود، یک به یک وارد کنید تا کارکرد آن را در عمل مشاهده نمایید:
ما در این کد یک شیء جاوا اسکریپت ایجاد و سپس محتوای آن را بررسی و در نهایت آن را با استفاده از ()stringify به یک شیء JSON تبدیل میکنیم. سپس متغیر مقدار بازگشتی را در یک متغیر جدید ذخیرهسازی میکنیم و آن را دوباره مورد بررسی قرار میدهیم.
جمعبندی
در این مقاله، یک راهنمای مقدماتی در مورد استفاده از JSON در برنامهها ارائه شده است که شامل شیوه ایجاد و تجزیه JSON و نحوه دسترسی به دادههای درون آن میشود. در مقاله بعدی شروع به بررسی جاوا اسکریپت شیءگرا میکنیم.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی روی لینک زیر کلیک کنید:
پانداس (Pandas) — از صفر تا صد
«پانداس» (Pandas)، یک کتابخانه «متنباز» (Open Source) با گواهینامه BSD است که کارایی بالا، ساختاری با قابلیت استفاده آسان و ابزارهای تحلیل داده برای «زبان برنامهنویسی پایتون» (Python Programming Language) را فراهم میکند. در واقع، میتوان گفت پانداس یک کتابخانه قدرتمند برای تحلیل، «پیشپردازش» (PreProcessing) و «بصریسازی» (Visualization) دادهها است. گفته میشود که کاربران این کتابخانه از سال ۲۰۱۴ تا ۲۰۱۸، از ۵ میلیون به ۱۰ میلیون نفر افزایش پیدا کردهاند و اکنون دیگر این کتابخانه به ابزاری که «باید» از آن برای کارهای مربوط به «علم داده» (Data Science) در پایتون استفاده کرد، مبدل شده است. حامی مالی پروژه پانداس، سازمان ناسودبر «NumFOCUS» است.
در مطلب «دیتافریم (DataFrame) در کتابخانه Pandas — راهنمای مقدماتی» به مفهوم دیتافریم که ساختار پایهای دادهها در کتابخانه پانداس است و روش کار با آن در پایتون پرداخته شد. در این مطلب، ضمن معرفی کتابخانه پانداس و نسخههای گوناگون آن، به بیان مزایای استفاده از این کتابخانه پرداخته شده است. سپس، روش نصب کتابخانه پانداس بیان، ساختارهای داده موجود در آن معرفی و روش وارد کردن (Import) دادهها با بهرهگیری از این کتابخانه، تشریح شده است.
«دانشمندان داده» (Data Scientists) زمان زیادی را صرف پاکسازی و دیگر پیشپردازشهای دادهها میکنند تا دادهها را برای انجام تحلیلهای گوناگون قابل استفاده کنند. یکی از کتابخانههای اصلی پایتون برای آمادهسازی و پیشپردازش دادهها، پانداس (Pandas) است. بنابراین در این مطلب، به طور خلاصه چگونگی پیشپردازش دادهها با بهرهگیری از پانداس نیز مورد بررسی قرار گرفته است. در نهایت، برخی از توابع و متدهای پایهای برای کار روی دیتافریمها نیز مورد بررسی قرار گرفتهاند که از این جمله میتوان به ()value_counts() ،groupby() ،merge() ،describe() ،concat و ()count اشاره کرد. این متدها و توابع، به دستهبندی و اکتشاف دیتافریمها در حین فرایند تحلیل کمک شایان توجهی میکنند.
نسخههای گوناگون کتابخانه پانداس
تاکنون، نسخههای گوناگونی از کتابخانه پانداس منتشر شده است که برخی از آنها نسبت به نسخههای پیشین خود تغییرات قابل توجهی داشتهاند و در برخی از آنها تنها چند اشکال جزئی رفع شده است. آخرین نسخه منتشر شده از این کتابخانه، ۰.۲۴ است که در ماه مارس سال ۲۰۱۹ انتشار یافت. در Pandas 0.24، علاوه بر اشکالزدایی، تغییراتی در «رابط کاربردی برنامهنویسی» (Application Programming Interface) و نوع افزونههای آن به وقوع پیوسته است. به طور کلی، این نسخه نسبت به نسخه پیشین خود، بهبودهای قابل توجهی داشته است.
مزایای استفاده از پانداس
در ادامه، برخی از مزایای استفاده از کتابخانه پانداس (Pandas) بیان شده است.
- این کتابخانه میتواند دادهها را با بهرهگیری از ساختارهای Series و DataFrame که ارائه میکند، به قالبی که برای تحلیل دادهها مناسب هستند، مبدل سازد.
- بسته پانداس حاوی چندین متد برای پالایش مناسب دادهها است.
- پانداس دارای ابزارهای گوناگونی برای انجام عملیات ورودی/خروجی است و میتواند دادهها را از فرمتهای گوناگونی شامل MS Excel ،TSV ،CSV و دیگر موارد بخواند.
نصب Pandas
توزیع استاندارد پایتون با ماژول Pandas ارائه نمیشود. برای استفاده از این ماژول شخص ثالث، ابتدا باید آن را نصب کرد. یک ویژگی خوب کتابخانه پانداس آن است که میتوان آن را با بهرهگیری از pip نصب کرد. برای نصب پانداس، میتوان قطعه کد زیر را مورد استفاده قرار داد.
افرادی که «آناکوندا» (Anaconda) را روی سیستم خود نصب دارند، میتوانند از دستور زیر برای نصب کتابخانه Pandas استفاده کنند:
اکیدا توصیه میشود که کاربران، آخرین نسخه از این کتابخانه را نصب کنند؛ ولی اگر کسی قصد دارد نسخه قدیمیتری از این کتابخانه را نصب کند، باید ورژن مورد نظر خودش را در هنگام نصب دقیقا مشخص کند. نمونه کدی که در آن نسخه ۰.۲۳.۴ نصب شده، در ادامه آمده است.
ساختار دادهها در پانداس
پانداس (Pandas) دارای دو ساختار اصلی برای ذخیرهسازی دادهها است که عبارتند از:
- Series
- دیتافریم (DataFrame)
Series در پانداس
یک series مشابه با آرایه یکبُعدی است. series میتواند دادهها از هر نوعی را ذخیره کند. مقادیری که در series قرار میگیرند قابل تغییر هستند؛ اما اندازه series پانداس، غیر قابل تغییر است. به اولین عنصر در series، اندیس ۰ تخصیص داده خواهد شد و اندیس آخرین عنصر در series برابر با N-1 است که در آن، N تعداد کل عنصرهای موجود در سری است. برای ساخت Series پانداس، ابتدا باید بسته پانداس را با استفاده از دستور import پایتون، «وارد» (import) کرد.
برای ساخت Series، متد ()pd.Series فراخوانی میشود و یک آرایه، چنانکه در زیر نمایش داده شده، پاس داده میشود.
سپس، دستور print برای نمایش دادن محتوای Series مورد استفاده قرار میگیرد.
خروجی:
0 1 1 2 2 3 3 4 dtype: int64
میتوان مشاهده کرد که دو ستون وجود دارد، ستون اول حاوی مقادیری است که از اندیس صفر شروع میشوند و ستون دوم حاوی مقادیری است که به series اضافه شدهاند. ستون اول اندیس عناصر را نشان میدهد. کاربر ممکن است هنگام نمایش series با خطا مواجه شود. دلیل اصلی این خطا آن است که پانداس به دنبال اطلاعاتی میگردد که نمایش دهد. بنابراین، کاربر باید اطلاعات خروجی سیستم را فراهم کند. این خطا را میتوان با اجرای کد به صورت زیر حل کرد.
یک Series ممکن است از آرایه «نامپای» (numpy) ساخته شود. در ادامه یک آرایه numpy ساخته میشود و سپس، این آرایه به Series پانداس «تبدیل» (Convert) میشود.
خروجی:
0 apple 1 orange 2 mango 3 pear dtype: object
کار با وارد کردن کتابخانههای لازم، از جمله numpy آغاز شده است. سپس، تابع ()array فراخوانی شده تا یک آرایه از میوهها ساخته شود. پس از آن، از تابع ()Series پانداس استفاده شده و آرایهای که کاربر تمایل دارد آن را به یک series تبدیل کند به آن پاس داده میشود. در نهایت، تابع ()print برای نمایش Series مورد استفاده قرار میگیرد.
دیتافریم
ساختار داده دیتافریم (DataFrame) در پانداس را میتوان به عنوان یک جدول در نظر گرفت. دیتافریم، دادهها را در سطرها و ستونها سازماندهی میکند و از آنها یک ساختار داده دوبُعدی میسازد. ستونها میتوانند حاوی مقادیری از انواع گوناگون باشند و در عین حال، اندازه دیتافریم قابل تغییر است؛ بنابراین میتوان آن را ویرایش کرد. برای ساخت دیتافریم، میتوان کار را از پایه شروع کرد و یا ساختار دادههایی مانند آرایههای نامپای (Numpy) را به یک دیتافریم مبدل ساخت. در ادامه، کد مربوط به چگونگی ساخت یک DataFrame از پایه، آورده شده است.
خروجی:
Column1 Column2 Column3 Column4 0 1 a 1.2300 True 1 4 column 23.5000 False 2 8 with 45.6000 True 3 7 a 32.1234 False 4 9 string 89.4530 True
در مثال بالا، یک دیتافریم با نام df ساخته شده است. ستون اول دیتافریم (DataFrame) حاوی مقادیر صحیح، دومین ستون حاوی یک رشته، ستون سوم حاوی مقادیر «ممیز شناور» (Floating Point) و ستون چهارم حاوی مقادیر «بولی» (Boolean) است. دستور (print(df محتوای دیتافریم را با استفاده از کنسول به کاربر نمایش میدهد و این امکان را فراهم میکند تا کاربر این محتوا را بررسی و تایید کند. اگرچه، هنگام نمایش دیتافریم، ممکن است کاربر متوجه شود که یک ستون اضافی در آغاز جدول وجود دارد که عناصر آن از ۰ شروع میشوند (اندیسها). برای ساخت دیتافریم، باید متد ()pd.DataFrame به صورتی که در مثال بالا نمایش داده شده فراخوانی شود. ساخت یک DataFrame از لیست یا یک مجموعه از لیستها، کاری دشوار است. اکنون فقط باید متد ()pd.DataFrame فراخوانی شود و سپس، متغیر لیست به عنوان تنها آرگومان به آن پاس داده میشود. مثال زیر در همین راستا قابل توجه است.
خروجی:
0 0 4 1 8 2 12 3 16 4 20
در این مثال، لیستی با عنوان mylist با توالی از پنج عدد صحیح ساخته شده است. سپس، متد ()DataFrame فراخوانی شده و نام لیست به عنوان آرگومان به آن پاس داده شده است. این همان جایی است که تبدیل لیست به دیتافریم اتفاق میافتد. سپس، محتوای دیتافریم پرینت میشود. دیتافریم دارای یک ستون پیشفرض است که اندیسها را نمایش میدهد و در آن، اندیس اول از صفر شروع میشود و اندیس آخر N-1 است و در آن، N تعداد کل عناصر موجود در دیتافریم به حساب میآید. مثال دیگری از این مورد، در ادامه آورده شده است.
خروجی:
Item Price 0 Phone 2000.0 1 TV 1500.0 2 Radio 800.0
در اینجا، لیستی از عناصر با مجموعهای از ۳ عنصر ساخته شده است. برای هر عنصر، یک نام و قیمت وجود دارد. سپس، لیست به متد ()DataFrame پاس داده میشود تا آن را به یک شی DataFrame مبدل سازد. در این مثال، نام ستونها برای دیتافریم نیز تعیین شده است. مقادیر عددی نیز به مقادیر ممیز شناور تبدیل میشوند زیرا آرگومان dtype از نوع ممیز شناور «float» تعریف شده است. برای دریافت خلاصه دادههای آیتمها، میتوان تابع ()describe را روی متغیر دیتافریم که df است فراخوانی کرد.
خروجی:
Price count 3.000000 mean 1433.333333 std 602.771377 min 800.000000 25% 1150.000000 50% 1500.000000 75% 1750.000000 max 2000.000000
تابع ()describe جزئیات آماری متداولی مانند میانگین، انحراف معیار، عنصر حداقل، عنصر حداکثر و دیگر جزئیات را ارائه میکند. این تابع راهکار خوبی برای کسب اطلاعات سریع و کلی پیرامون دادههایی محسوب میشود که کاربر در حال کار با آنها است؛ به ویژه اگر پیرامون این دادهها اطلاعات زیادی نداشته باشد. همچنین، راهکار خوبی برای مقایسه سریع دو مجموعه داده مجزا که حاوی دادههای مشابهی هستند، محسوب میشود.
وارد کردن دادهها
معمولا، نیاز به استفاده از کتابخانه پانداس برای کار با دادههایی است که در یک فایل «اکسل» (Excel) یا CSV ذخیره شدهاند. این کار نیاز به آن دارد که فایل این دادهها باز و دادههای آن در پانداس وارد (Import) شوند. خوشبختانه، پانداس متدهای زیادی را فراهم میکند که میتوان از آنها برای بارگذاری دادهها از چنین منابعی در دیتافریم پانداس استفاده کرد.
وارد کردن دادههای CSV
یک فایل CSV (این عبارت، سرنامی برای Comma Separated Value است) یک فایل متنی با مقادیری است که به وسیله کاما (,) از یکدیگر جدا شدهاند. این نوع فایل بسیار شناخته شده و استانداردی است که اغلب مورد استفاده قرار میگیرد. از کتابخانه پانداس میتوان برای خواندن فایل CSV به صورت کامل یا بخشهایی از آن، استفاده کرد. برای مثال، یک فایل CSV با نام cars.csv ساخته میشود. این فایل باید حاوی دادههای زیر باشد.
Number,Type,Capacity SSD,Premio,1800 KCN,Fielder,1500 USG,Benz,2200 TCH,BMW,2000 KBQ,Range,3500 TBD,Premio,1800 KCP,Benz,2200 USD,Fielder,1500 UGB,BMW,2000 TBG,Range,3200
میتوان دادهها را کپی کرد و در ویرایشگر متنی مانند «نُتپد» (Notepad) چسباند؛ سپس، این فایل را با نام cars.csv در همان پوشهای که اسکریپتهای پایتون ذخیره میشوند، ذخیره کرد. پانداس حاوی متدی با عنوان read_csv است که برای خواندن مقادیر CSV در یک دیتافریم پانداس مورد استفاده قرار خواهند گرفت. این متد، مسیر (PATH) به فایل CSV را به صورت آرگومان دریافت میکند. کد زیر برای خواند فایل cars.csv مورد استفاده قرار میگیرد.
خروجی:
Number Type Capacity 0 SSD Premio 1800 1 KCN Fielder 1500 2 USG Benz 2200 3 TCH BMW 2000 4 KBQ Range 3500 5 TBD Premio 1800 6 KCP Benz 2200 7 USD Fielder 1500 8 UGB BMW 2000 9 TBG Range 3200
در اینجا، فایل CSV در دایرکتوری اسکریپت پایتون ذخیره شده است، بنابراین نام فایل به متد read_csv پاس داده میشود و این متد میداند که باید پوشه کاری جاری را بررسی کند. اگر فایل در مسیر متفاوتی ذخیره شده است، باید اطمینان حاصل کند که مسیر درستی را به عنوان آرگومان متد پاس داده است. این مسیر میتواند مانند cars.csv/.. نسبی و یا مانند Users/nicholas/data/cars.csv/ مطلق باشد. در برخی موارد، ممکن است هزاران سطر در مجموعه داده وجود داشته باشد. در چنین مواردی، بهتر است به جای کل مجموعه داده، تنها چند خط اول در کنسول چاپ شود. این کار میتواند با فراخوانی متد ()head روی دیتافریم به صورتی که در زیر نشان داده شده، انجام شود.
برای دادههای بالا، دستور تنها پنج سطر اول مجموعه داده را باز میگرداند و این امکان را فراهم میکند که کاربر، بخش کوچکی از دادهها را مورد بررسی قرار دهد. خروجی کد بالا در زیر نشان داده شده است.
خروجی:
Number Type Capacity 0 SSD Premio 1800 1 KCN Fielder 1500 2 USG Benz 2200 3 TCH BMW 2000 4 KBQ Range 3500
متد ()loc ابزار مناسبی است که به کاربر کمک میکند تا تنها سطرهای معینی را در مجموعه داده بخواند. این مورد، در مثال زیر نمایش داده شده است.
خروجی:
Type 0 Premio 4 Range 7 Fielder
در اینجا، از متد ()loc برای خواندن عناصر در اندیس ۰، ۴ و ۷ از ستون Type، استفاده شده است. گاهی ممکن است تنها نیاز به خواندن ستون خاصی باشد و دیگر ستونها خوانده نشوند. این کار با استفاده از متد ()loc انجام شده که در مثال زیر نشان داده شده است.
خروجی:
Type Capacity 0 Premio 1800 1 Fielder 1500 2 Benz 2200 3 BMW 2000 4 Range 3500 5 Premio 1800 6 Benz 2200 7 Fielder 1500 8 BMW 2000 9 Range 3200
در اینجا از متد ()loc برای خواندن همه سطرهای (بخش : ) متعلق به تنها دو ستون از مجموعه داده، یعنی ستونهای Type و Capacity که در آرگومان تعیین شدهاند، استفاده شده است.
وارد کردن دادههای اکسل
علاوه بر متد read_csv، پانداس از تابع read_excel نیز استفاده میکند که میتواند برای خواندن دادههای Excel در یک دیتافریم پانداس استفاده شود. در این مثال، از فایل اکسل با نام workers.xlsx همراه با جزئیات کارگران شرکت استفاده شده است. کد زیر را میتوان برای بارگذاری محتوای فایل اکسل در یک دیتافریم پانداس استفاده کرد.
خروجی:
ID Name Dept Salary 0 1 John ICT 3000 1 2 Kate Finance 2500 2 3 Joseph HR 3500 3 4 George ICT 2500 4 5 Lucy Legal 3200 5 6 David Library 2000 6 7 James HR 2000 7 8 Alice Security 1500 8 9 Bosco Kitchen 1000 9 10 Mike ICT 3300
پس از فراخوانی تابع read_excel، نام فایل به عنوان آرگومان به آن پاس داده میشود. read_excel برای باز کردن/بارگذاری فایل و سپس، تجزیه دادهها مورد استفاده قرار میگیرد. همانطور که از مثال پیشین مشهود است، تابع ()print به کاربر کمک میکند تا محتوای دیتافریم را نمایش دهد. همچنین، همانطور که در مثال مروبط به کار با فایل CSV بیان شد، این تابع را میتوان با متد ()loc ترکیب کرد تا به خواندن سطرها و ستونهای خاصی از فایل اکسل کمک کند. برای مثال:
خروجی:
از متد ()loc برای بازیابی مقادیر Name و Salary از عناصر در اندیسهای ۱، ۴ و ۷ استفاده شده است. همچنین، Pandas این امکان را برای کاربر فراهم میکند تا از دو فایل اکسل به طور همزمان بخواند. فرض میشود که دادههای قبلی در Sheet1 هستند و دادههای دیگری در Sheet2 از همان فایل اکسل قرار دارند. کدی که در ادامه آمده، نشان میدهد که چگونه میتوان از دو شیت به طور همزمان خواند.
خروجی:
Sheet 1: ID Name Dept Salary 0 1 John ICT 3000 1 2 Kate Finance 2500 2 3 Joseph HR 3500 3 4 George ICT 2500 4 5 Lucy Legal 3200 5 6 David Library 2000 6 7 James HR 2000 7 8 Alice Security 1500 8 9 Bosco Kitchen 1000 9 10 Mike ICT 3300 Sheet 2: ID Name Age Retire 0 1 John 55 2023 1 2 Kate 45 2033 2 3 Joseph 55 2023 3 4 George 35 2043 4 5 Lucy 42 2036 5 6 David 50 2028 6 7 James 30 2048 7 8 Alice 24 2054 8 9 Bosco 33 2045 9 10 Mike 35 2043
اتفاقی که در کد بالا میافتد آن است که تابع ()read_excel با کلاس پوششدهنده ExcelFile ترکیب شده است. متغیر x هنگامی ساخته شده است که کلاس wrapper با کلیدواژه پایتون with فراخوانی شده است؛ این کلیدواژه برای باز کردن موقتی فایل مورد استفاده قرار میگیرد. از ExcelFile متغیر x، دو متغیر دیگر s1 و s2 ساخته شده است تا محتوایی که از Sheetهای مختلف خوانده میشوند، با بهرهگیری از آنها نمایش داده شوند. سپس، از دستور print برای نمایش محتوای دو «کاربرگ» (sheet) در کنسول استفاده شده است. دستور print خالی، یعنی ٰ(“”)print، برای چاپ کردن یک خط خالی بین کاربرگها مورد استفاده قرار میگیرد.
پیشپردازش دادهها
دستکاری/پیشپردازش دادهها (Data Wrangling)، فرایند پردازش دادهها برای آمادهسازی آنها جهت استفاده در گام بعدی است. به عنوان مثالی از فرایند پیشپردازش دادهها میتوان به ادغام کردم (Merging)، گروهبندی (Grouping) و الحاق (Concatenation) اشاره کرد. این نوع دستکاری معمولا بدین دلیل در علم داده مورد نیاز است که دادهها را به فرمی مبدل کند که برای انجام تحلیلها و کار با الگوریتمها مناسبتر هستند.
ادغام
کتابخانه پانداس این امکان را برای کاربر فراهم میکند که اشیای دیتافریم را با تابع ()merge به یکدیگر متصل کنند. در ادامه، دو دیتافریم ساخته و روش ادغام کردن آنها با یکدیگر نمایش داده شده است. در ادامه، کد مربوط به دیتافریم df1 آورده شده است.
خروجی:
subject_id student_name 0 1 John 1 2 Emily 2 3 Kate 3 4 Joseph 4 5 Dennis
کد زیر، مربوط به ساخت دومین دیتافریم، df2، است:
خروجی:
subject_id student_name 0 4 Brian 1 5 William 2 6 Lilian 3 7 Grace 4 8 Caleb
اکنون، نیاز به ادغام دو دیتافریم یعنی df1 و df2 در امتداد مقادیر subject_id است. در اینجا، به سادگی تابع ()merge به صورتی که در زیر نشان داده شده فراخوانی میشود.
خروجی:
subject_id student_name_x student_name_y 0 4 Joseph Brian 1 5 Dennis William
کاری که merging انجام میدهد، آن است که سطرها از هر دو دیتافریم را با مقادیر یکسان برای ستونهایی که کاربر برای ادغام استفاده میکند، باز میگرداند. راهکارهای متعددی برای استفاده از تابع pd.merge وجود دارد که در این مقاله پوشش داده نشدهاند. از جمله این موارد میتوان به نوع دادههای قابل ادغام، چگونگی ادغام آنها، نحوه مرتبسازی در صورت نیاز و دیگر موارد اشاره کرد.
Groupby در پانداس
پانداس به طور متداول برای اکتشاف و سازماندهی حجم زیادی از دادههای جدولی مورد استفاده قرار میگیرد. اغلب اوقات، کاربران برای انجام تحلیلهای بیشتر نیاز به سازماندهی دیتافریمهای پانداس در زیرگروههای گوناگون پیدا میکنند. برای مثال، ممکن است که کاربر دادههای «تابلوی بورس» (Stock Ticker) را در دیتافریم داشته باشد. دیتافریم پانداس مذکور، احتمالا به صورت زیر خواهد بود.
>>> df date symbol open high low close volume 0 2019-03-01 AMZN 1655.13 1674.26 1651.00 1671.73 4974877 1 2019-03-04 AMZN 1685.00 1709.43 1674.36 1696.17 6167358 2 2019-03-05 AMZN 1702.95 1707.80 1689.01 1692.43 3681522 3 2019-03-06 AMZN 1695.97 1697.75 1668.28 1668.95 3996001 4 2019-03-07 AMZN 1667.37 1669.75 1620.51 1625.95 4957017 5 2019-03-01 AAPL 174.28 175.15 172.89 174.97 25886167 6 2019-03-04 AAPL 175.69 177.75 173.97 175.85 27436203 7 2019-03-05 AAPL 175.94 176.00 174.54 175.53 19737419 8 2019-03-06 AAPL 174.67 175.49 173.94 174.52 20810384 9 2019-03-07 AAPL 173.87 174.44 172.02 172.50 24796374 10 2019-03-01 GOOG 1124.90 1142.97 1124.75 1140.99 1450316 11 2019-03-04 GOOG 1146.99 1158.28 1130.69 1147.80 1446047 12 2019-03-05 GOOG 1150.06 1169.61 1146.19 1162.03 1443174 13 2019-03-06 GOOG 1162.49 1167.57 1155.49 1157.86 1099289 14 2019-03-07 GOOG 1155.72 1156.76 1134.91 1143.30 1166559
فرض میشود که کاربر قصد دارد این اطلاعات سهام را بر مبنای نماد-به-نماد به جای ترکیب دادههای آمازون (“AMZN”) با گوگل (“GOOG”) یا حتی اپل (“AAPL”)، تحلیل کند. در اینجا است که متد Groupby پانداس مفید واقع میشود. میتوان از Groupby برای تقسیمبندی دادهها در زیرمجموعهها به منظور انجام تحلیلهای بعدی استفاده کرد.
کاربردهای پایهای Groupby در پایتون
در ادامه، برخی از کاربردهای مفید و پایهای Groupby در پایتون همراه با مثالهایی تشریح خواهد شد. ابتدا، در مفسر پایتون کد زیر وارد میشود.
>>> import pandas as pd >>> import numpy as np >>> url = 'https://gist.githubusercontent.com/alexdebrie/b3f40efc3dd7664df5a20f5eee85e854/raw/ee3e6feccba2464cbbc2e185fb17961c53d2a7f5/stocks.csv' >>> df = pd.read_csv(url) >>> df date symbol open high low close volume 0 2019-03-01 AMZN 1655.13 1674.26 1651.00 1671.73 4974877 1 2019-03-04 AMZN 1685.00 1709.43 1674.36 1696.17 6167358 2 2019-03-05 AMZN 1702.95 1707.80 1689.01 1692.43 3681522 3 2019-03-06 AMZN 1695.97 1697.75 1668.28 1668.95 3996001 4 2019-03-07 AMZN 1667.37 1669.75 1620.51 1625.95 4957017 5 2019-03-01 AAPL 174.28 175.15 172.89 174.97 25886167 6 2019-03-04 AAPL 175.69 177.75 173.97 175.85 27436203 7 2019-03-05 AAPL 175.94 176.00 174.54 175.53 19737419 8 2019-03-06 AAPL 174.67 175.49 173.94 174.52 20810384 9 2019-03-07 AAPL 173.87 174.44 172.02 172.50 24796374 10 2019-03-01 GOOG 1124.90 1142.97 1124.75 1140.99 1450316 11 2019-03-04 GOOG 1146.99 1158.28 1130.69 1147.80 1446047 12 2019-03-05 GOOG 1150.06 1169.61 1146.19 1162.03 1443174 13 2019-03-06 GOOG 1162.49 1167.57 1155.49 1157.86 1099289 14 2019-03-07 GOOG 1155.72 1156.76 1134.91 1143.30 1166559
در کد بالا، کتابخانههای «پانداس» (Pandas) و «نامپای» (NumPy) «وارد» (Import) میشوند. سپس، یک دیتافریم پایهای با دانلود کردن دادههای CSV از یک URL، راهاندازی شده است. مجموعه داده در کنسول چاپ (Print) میشود تا مشاهده شود که چه مواردی در آن موجود هستند. اکنون، باید دیتافریم را بر اساس «نمادهای سهام» گروهبندی کرد. سادهترین و متداولترین راهکار برای استفاده از groupby، پاس دادن یک یا تعداد بیشتری نام ستون است. در این مثال، «symbol» به عنوان نام ستون برای گروهبندی مورد استفاده قرار میگیرد.
درک تفسیر خروجی بر اساس گروههای چاپ شده، میتواند کمی سخت باشد. در خروجی بالا، میتوان مشاهده کرد که سه گروه AMZN ،AAPL و GOOG وجود دارند. برای هر گروه، اندیسهای سطرهای متعلق به هر گروه در دیتافریم اصلی، وجود دارند. ورودی groupby کاملا انعطافپذیر است. کاربر میتواند در صورت تمایل، گروهبندی را بر اساس چندین ستون انجام دهد. برای مثال، اگر ستون سال وجود داشت، میتوان از ستونهای نمادهای سهام و سال برای گروهبندی دادهها و تحلیل سال به سال سهام هر شرکت استفاده کرد.
استفاده از تابع سفارشی در Groupby پانداس
در مثال پیشین، نام ستون به متد groupby پاس داده شد. همچنین، کاربر میتواند تابع خودش را به هر متد groupby پاس بدهد. این تابع یک شماره اندیس برای هر داده در دیتافریم دریافت میکند و باید مقداری را بازگرداند که برای گروهبندی مورد استفاده قرار میگیرد. این امر میتواند انعطافپذیری بالایی را برای گروهبندی با استفاده از منطق پیچیده فراهم آورد. به عنوان مثال، میتوان تصور کرد که کاربر قصد دارد سطرها را بسته به اینکه قیمت سهام در یک روز خاص افزایش یافته است یا خیر، گروهبندی کند. این کار به صورت زیر انجام میشود.
ابتدا، تابعی تعریف میشود که increased نام نهاده شده و اندیسها را دریافت میکند. این تابع، اگر «قیمت بسته شدن بورس» (Close Value) برای آن سطر در دیتافریم بالاتر از «قیمت بازگشایی بورس» (Open Value) باشد، مقدار «True» را باز میگرداند؛ در غیر این صورت، مقدار «False» را باز میگرداند. هنگامی که تابع به متد ()groupby پاس داده شد، دیتافریم بسته به آنکه قیمت تعطیلی بورس بیشتر از قیمت بازگشایی آن در همان روز بوده یا نه، در دو گروه تقسیمبندی میشود.
عملیات روی گروههای پانداس
پس از آنکه گروهها با استفاده از تابع groupby ساخته شدند، میتوان برخی از عملیات کارآمد دستکاری دادهها را در گروههای نتیجه انجام داد. در مثالی که بالاتر مطرح شد، گروههایی از تابلوی سهام بر اساس نماد ساخته شدند. اکنون، میانگین حجم معاملات برای هر نماد محاسبه خواهد شد.
برای تکمیل این وظیفه، کاربر باید ستونهایی که میخواهد در آن عملیات انجام دهد (“volume”) را تعیین کند و سپس، از متد agg پانداس برای اعمال تابع میانگین استفاده کند. نتیجه، مقدار میانگین برای هر سه نماد است. بدین شکل، میتوان مشاهده کرد که حجم معاملات AAPL یک مرتبه بزرگتر از حجم معاملات AMZN و GOOG است.
تکرار و انتخاب گروهها
تکرار، الگوی برنامهنویسی هستهای است و تعداد کمی از زبانها دارای نحو مناسبتری برای تکرار، نسبت به پایتون هستند. مقایسهگرهای لیست و مولدهای توکار موجود در پایتون، تکرار و حلقه زدن را در پایتون به کاری دلانگیز مبدل میکنند. groupby در پانداس نیز تفاوتی ندارد زیرا پشتیبانی خوبی برای تکرار فراهم میکند. میتوان در شی نتایج groupby با استفاده از حلقه for تکرار انجام داد.
هر تکرار در شی groupby دو مقدار را باز میگرداند. اولین مقدار شناساگر گروه است که در واقع، مقدار ستون(هایی) است که گروهبندی شدهاند. دومین مقدار خود گروه است که یک شی دیتافریم محسوب میشود.
متد get_group در پانداس
اگر کاربر انعطافپذیری بسیاری برای دستکاری یک گروه مجرد نیاز دارد، میتواند از متد get_group برای بازیابی یک گروه مجرد استفاده کند.
در مثال بالا، باید از متد get_group برای بازیابی همه سطرهای AAPL استفاده شود. برای بازیابی یک گروه مشخص، شناساگر گروه به متد get_group پاس داده میشود. این متد، یک دیتافریم Pandas باز میگرداند که میتواند در صورت نیاز توسط کاربر دستکاری شود.
درک شکل دادهها با Count و value_counts در پانداس
در صورتی که کاربر با یک دیتافریم بزرگ کار میکند، نیاز به استفاده از اکتشافات گوناگون برای درک شکل دادهها دارد. در این بخش، دو متد count و value_counts پانداس برای ارزیابی دیتافریم مورد استفاده قرار خواهند گرفت. متد count تعداد مقادیر در هر ستون از DataFrame را نشان میدهد. با استفاده از دیتافریم بالا، خروجی زیر حاصل میشود.
>>> df.count() date 15 symbol 15 open 15 high 15 low 15 close 15 volume 15 dtype: int64
خروجی برای کاربر مفید نیست، زیرا هر یک از ۱۵ سطر دارای یک مقدار برای هر ستون هستند. اگرچه، این کار در صورتی میتواند مفید باشد که مجموعه داده تعداد بیشتری از مقادیر را از دست بدهد. با استفاده از متد count میتوان به شناسایی ستونهایی که غیر کامل هستند کمک کرد. از آنجا، میتوان تصمیم گرفت که یک ستون دارای مقادیر ناموجود را از پردازشها حذف کرد یا مقادیری برای مقادیر ناموجود یافت و جایگزین کرد.
متد value_counts در پایتون
در این مثال، value_counts مفیدتر است. این متد تعداد مقادیر یکتا را برای یک ستون خاص باز میگرداند. اگر کاربر، مقادیر پیوستهدارد (مانند ستونهای دیتافریم بالا)، میتواند از آرگومان اختیاری bins برای جداسازی مقادیر در bins نیمه باز استفاده کند. اکنون، میتوان از متد value_counts پانداس برای نمایش شکل ستون volume استفاده کرد.
در خروجی بالا، پانداس (Pandas) چهار bins (دسته) جدا برای ستون حجم (volume) ساخته است و تعداد سطرهایی که در هر bin قرار دارند را نشان میدهد. ()counts و ()value_counts ابزارهای مناسبی برای درک سریع شکل دادهها هستند.
الحاق
«الحاق» (Concatenation) دادهها، که در واقع به معنای افزودن یک مجموعه از دادهها به دیگری است، به وسیله فراخوانی تابع ()concat قابل انجام است. در ادامه، چگونگی الحاق مجموعه دادهها با استفاده از دو دیتافریم پیشین که در بالا معرفی شدند یعنی df1 و df2، هر یک با دو ستون subject_id و student_name، بیان شده است.
خروجی:
آمار توصیفی
چنانکه پیشتر نشان داده شد، با استفاده از تابع ()describe، آمار توصیفی برای ستونهای عددی ارائه میشود، اما ستونهای حاوی کاراکتر توسط این تابع در نظر گرفته نمیشوند. در ادامه، ابتدا یک دیتافریم ساخته میشود که در آن، اسامی دانشآموزان و رتبه آنها در ریاضیات (Math) و انگلیسی (English) نمایش داده شده است.
خروجی:
English Maths Name 0 64 76 John 1 78 54 Alice 2 68 72 Joseph 3 58 64 Alex
اکنون، فقط نیاز به فراخوانی تابع ()describe روی دیتافریم و دریافت سنجههای گوناگون مانند میانگین، انحراف معیار، میانه، عنصر بیشینه، عنصر کمینه و دیگر موارد است. کد زیر در این راستا قابل توجه است.
خروجی:
English Maths count 4.000000 4.000000 mean 67.000000 66.500000 std 8.406347 9.712535 min 58.000000 54.000000 25% 62.500000 61.500000 50% 66.000000 68.000000 75% 70.500000 73.000000 max 78.000000 76.000000
همانطور که مشهود است، متد ()describe به طور کامل ستون Name را نادیده گرفت است، زیرا مقادیر آن عددی نیستند. این کار به کاربر کمک میکند تا بدون داشتن دغدغه حذف ستونهای حاوی مقادیر غیر عددی به منظور دریافت آمارهای مربوط به مقادیر عددی، بتواند با دادهها کار کند.
نتیجهگیری
پانداس یک کتابخانه بسیار مفید به ویژه برای علم داده است. توابع گوناگون پانداس به سادهسازی فرایند پیشپردازش دادهها کمک قابل توجهی میکنند. در این مطلب، مقدمهای بر توابع و کارکردهای اصلی این کتابخانه پایتون ارائه شد. از جمله متدهای اصلی کتابخانه پانداس که در این مطلب مورد بررسی قرار گرفت میتوان به count ،value_counts ،groupby و برخی از دیگر موارد اشاره کرد.
https://blog.faradars.org/pandas-from-zero-to-hero/